References
- 리얼월드 알고리즘
Contents
- 다익스트라(데이크스트라) 알고리즘 구현
- 임의의 원소에 접근해 값 갱신(update)이 가능한 Heap(우선순위 큐) 구현
- 음의 가중치는 사용 불가
- 그래프의 지름
C++로 구현한 전체 코드는 아래를 참조바랍니다 !
https://github.com/junstar92/DataStructure_Algorithm/tree/master/Algorithm/Dijkstra
GitHub - junstar92/DataStructure_Algorithm
Contribute to junstar92/DataStructure_Algorithm development by creating an account on GitHub.
github.com
다익스트라(또는 데이크스트라) 알고리즘은 그래프의 최단 경로를 찾는 알고리즘입니다.
이 알고리즘에서는 그래프의 시작 노드에서 목적 노드까지의 최단 경로를 찾게 됩니다. 현실 세계의 많은 문제가 실제로는 최단 경로 문제이며, 문제의 정의에 따라서 알고리즘이 약간씩 달라집니다.
도로망 탐색 역시 최단 경로 문제로, 가능한 가장 짧은 경로로 도시들을 통과해 출발지에서 목적지에 도달하는 것이 목표입니다.
이 문제를 조금 더 자세히 살펴보고 알고리즘을 살펴보도록 하겠습니다.
격자의 교차점은 각 도시이고, 한 도시에서 다른 도시로 가는 데 소요되는 추정 시간이 값으로 주어진 격자를 탐색한다고 가정해봅시다.

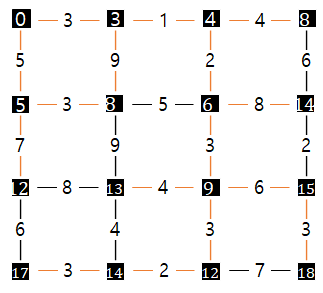
위 이미지는 이러한 격자를 보여주고 있습니다. 격자의 교차점(노드)은 각 도시를 나타내고 한 교차점에서 다른 교차점으로 가는 데 걸리는 시간(분)이 값으로 주어집니다. 이 값은 간선의 가중치가 됩니다. 격자를 단순하게 나타내기 위해서 각 노드에는 이름을 넣지 않았는데, 각 노드는 행과 열로 표현되고, 행과 열은 모두 0에서 시작하는 인덱스를 갖습니다.
즉, \(i\)행, \(j\)열의 특정 노드를 참조할 때는 노드 \((i, j)\)로 참조한다고 하겠습니다.
시작 지점에서 목적 지점까지 탐색하는 문제를 풀 때, 격자의 한 점에서 임의의 다른 점으로의 최단 경로를 찾는 일반적인 문제로 생각할 수 있는데, 이것을 단일 출발지 최단 경로 문제라고 합니다. 이를 해결하려면 이전 글에서 언급했던 완화(relaxation) 기술을 적용해야 합니다.
2021.10.06 - [Data Structure & Algorithm/알고리즘] - [그래프] 가중치 그래프와 임계 경로(Critical Path)
[그래프] 가중치 그래프와 임계 경로(Critical Path)
References 리얼월드 알고리즘 Contents 가중치 그래프(weighted graph) 임계 경로(critical path) 가중치 그래프 Weighted Graph 이전 글들에서 그래프 자료구조와 위상 정렬에 대해서 살펴봤습니다. 2021.10.04..
junstar92.tistory.com
초기에 우리가 알고 있는 유일한 거리는 시작 노드까지의 거리가 0이라는 것입니다. 이 거리를 제외한 다른 모든 거리에 대한 추정값은 가장 큰 값인 \(\infty\)로 초기화합니다. 그런 다음 가장 낮은 추정값을 갖는 노드를 선택하는데, 초기에 가장 낮은 추정값을 갖는 노드는 시작 노드입니다. 그 후 시작 노드에 연결된 모든 이웃 노드들을 조사하면서, 현재 노드에서 각 이웃 노드로의 간선의 가중치를 찾고, 그 가중치가 이웃 노드의 현재 추정값보다 작다면 이웃 노드의 추정값을 가중치로 바꿉니다.
이때, 최단 경로에서 이웃 노드의 이전 노드는 현재 방문한 노드가 되게 합니다.(최단 경로를 찾기 위해)
이렇게 노드를 반복적으로 조사하다가 더 조사할 노드가 없으면 종료하게 됩니다.
아래와 같은 방식으로 진행됩니다 !
까만색 박스가 현재 노드, 주황색 박스가 현재 위치에서의 이웃 노드 탐색이고, 이웃 노드에는 시작 노드에서의 최단 거리가 갱신됩니다.

조금만 설명을 덧붙이면, 왼쪽 상단의 노드 (0, 0)부터 시작하고 이때의 경로 추정값은 0이 됩니다. 가장 낮은 경로 추정값을 갖는 노드인 왼쪽 상단 노드 (0, 0)을 선택하여 방문하고, 이 노드의 이웃 노드의 가중치를 확인합니다. 이웃 노드인 (0, 1)의 가중치는 3이고, 아래의 (1, 0)의 가중치는 5입니다. 이웃 노드의 현재 추정값((\\infty\))보다 낮으므로 두 노드의 추정값을 각각 3과 5로 변경합니다. 그리고 두 이웃 노드 중에 추정치가 낮은 노드인 (0, 1)을 방문하고 그 이웃 노드에 대한 추정값을 계산합니다. 이런 식으로 이웃 노드의 추정값을 갱신하고 갱신할 노드가 더 없을 때까지 이 작업을 계속합니다.
시작 노드에서 다른 모든 노드까지의 최단 경로는 아래와 같습니다.

그리고 알고리즘이 따라간 경로들을 주황색으로 표시해보면 트리를 형성하는데, 이처럼 노드가 그래프의 노드들이고 간선이 그래프 간선 집합의 부분 집합인 트리를 신장 트리(spanning tree)라고 합니다.
신장 트리는 여러 가지 프로그램에서 중요하고, 특히 최소 가중치를 갖는 신장 트리, 즉 신장 트리를 구성하는 간선의 가중치 합이 최소가 되는 신장 트리가 중요합니다.
이러한 신장 트리를 최소 신장 트리(minimum spanning tree; MST)라고 합니다.
지금까지 설명한 최단 경로 방법을 사용하면 신장 트리를 유도할 수 있지만, 이 신장 트리가 반드시 최소 신장 트리는 아닙니다.
다익스트라(데이크스트라) 알고리즘
앞에서 최단 경로를 계산하는 방법은 다익스트라 또는 데이크스트라 알고리즘입니다.
이 알고리즘은 1956년에 발견하고 1959년에 발표한 네덜란드의 컴퓨터 과학자 에츠허르 데이크스트라(다익스트라)의 이름을 딴 것입니다.
이 알고리즘은 다음과 같습니다.
알고리즘은 그래프와 그래프에서의 시작 노드를 입력으로 받고 배열 두 개를 반환합니다.

이 알고리즘은 다음에 방문할 노드 정보를 유지하는 데 최소 우선순위 큐를 사용합니다. 다만, 단순한 우선순위 큐가 아닌 노드와 거리를 우선순위 큐에 넣어야합니다.
그리고, 큐에 존재하는 값을 갱신하는 기능이 존재해야 합니다 !
갱신하지 않고, 우선순위 큐에 그냥 추가해도 되지만, 그렇게 되면 루프(while)를 더 많이 돌게 됩니다.
이 경우에는 최적화를 위해서 방문한 노드를 체크해서 이미 방문한 노드인 경우에는 루프를 넘어가는 동작이 추가로 필요합니다. (우선순위 큐의 원소를 갱신하기 위해서 따로 Heap을 아래서 구현했으니 참조바랍니다 !)
위 알고리즘에서 필요한 작업들은 다음과 같습니다.
- CreatePQ() : 빈 우선순위 큐를 생성
- InsertInPQ(pq, n, d) : 우선순의 큐 pq에 거리 d를 갖는 노드 n을 삽입
- ExtractMinFromPQ(pq) : 우선순위 큐 pq에서 최단 거리를 갖는 노드를 반환하고 제거
- SizePQ(pq) : 우선순위 큐 pq에 존재하는 원소의 수를 반환
- UpdatePQ(pq, n, d) 노드 n과 연관된 저장된 거리를 거리 d로 변경하고 우선순위 큐를 갱신
그리고 이 알고리즘은 두 개의 추가 자료구조로 배열 pred와 dist를 사용하는데, pred[i]는 시작 노드 s에서 노드 i에 이르기까지 발견한 최단 경로에서 노드 i의 앞에 오는 노드를 가리킵니다. dist[i]는 노드 i까지 이르는 최단 경로의 거리를 담고 있습니다.
알고리즘의 1~10행에서는 자료 구조를 초기화하여 모든 노드가 이전 노드를 가지고 있지 않고(-1로 세팅), 현재까지 최단 경로는 9행에서 0으로 설정된 시작 노드까지의 경로입니다. 따라서 모든 다른 노드까지의 거리는 시작 노드를 제외하고는 \(\infty\)로 초기화됩니다. 10행에서는 루프의 현재 노드 v를 우선순위 큐에 추가합니다.
11~17행의 루프는 우선순위 큐가 비어있지 않다면 계속해서 반복됩니다.
우선순위 큐에서 최단 거리 원소를 추출하고(12행), 13~17행의 내부 루프에서 더 나은 경로 추정값을 갖는 이웃 노드에 대해서 경로 추정값을 완화(relaxation)합니다. 만약 14행에서 현재 노드 u의 이웃 노드 v까지의 거리가 dist[u]와 w(u, v)의 합이 dist[v]보다 작은지 확인합니다. dist[v]가 더 크다면, v까지의 거리(dist[v])를 해당 경로의 거리로 갱신(15행)하고, 경로에서 v의 이전 노드를 u로 갱신합니다(16행). 이웃 노드에 대한 경로 추정값을 갱신하면 17행에서 우선순위 큐에서 거리를 갱신합니다.
더 이상 큐에 반복할 자료가 없다면, 루프는 끝이나고 두 개의 배열 pred와 dist를 반환합니다(18행).
여기서 각 노드는 우선순위 큐에서 정확히 한 번만 제거된다는 점을 눈여겨봐야합니다. 이는 우선순위 큐에서 노드를 꺼낼 때 노드에 이웃한 모든 노드가 적어도 큐에서 꺼낸 노드까지의 경로만큼 최단 경로 추정값으로 갱신되기 때문입니다.
(우선순위 큐의 값을 갱신하는 것이 아닌, 새롭게 추가하는 경우에는 여러 번 제거될 수 있습니다.)
임의의 원소 접근 및 값 갱신이 가능한 Heap 구현
위의 설명에서 우선순위 큐에서 원소에 접근하여 거리 추정값을 갱신하는 기능이 필요하다고 했습니다.
C++의 <queue> 헤더에서 제공하는 priority_queue의 경우에는 자료구조 내의 임의의 원소에 접근이 불가능하기 때문에 갱신이 불가능합니다.
물론, 갱신하지 않고 그냥 원소를 추가해도 알고리즘이 동작하는데 문제는 없으나, 제가 이 기능을 사용해보고 싶었기 때문에 임의의 원소에 접근하여 값을 갱신하는 기능을 가진 우선순위 큐를 구현해보았습니다.
기본적으로 배열(vector)을 사용하여서 힙을 구성했고, 각 노드가 힙 데이터의 어느 인덱스에 위치하는지 pos 변수(vector)에 저장하면서, 해당 노드가 힙의 어디에 위치하는지 찾아갈 수 있도록 하였습니다. 만약 해당 노드가 힙 데이터에 존재하지 않는다면 위치는 -1로 설정됩니다. 나머지 코드는 일반적인 힙 구현과 유사합니다.
그리고 다익스트라 알고리즘에 사용할 용도로 급하게 구현해서, 사용되는 자료형은 노드와 거리 정보를 담고 있는 IDX_DIST 구조체입니다. 만약 다른 자료형이 필요하시면 간단하게 수정해서 사용하시면 될 것 같습니다 !
class Heap {
public:
void push(const IDX_DIST& data);
void pop();
IDX_DIST top() const;
int size() const;
void update(int node, int dist);
Heap(int num_node) : max_size(num_node * 10), num_data(0), num_node(num_node)
{
this->heapData.resize(this->max_size);
this->pos.resize(this->num_node, -1);
}
private:
std::vector<IDX_DIST> heapData;
int max_size;
int num_data;
int num_node;
std::vector<int> pos;
void _sinkUp(int idx);
void _sinkDown(int idx);
};
void Heap::push(const IDX_DIST& data)
{
if (this->num_data == this->max_size)
return;
this->heapData[this->num_data] = data;
this->pos[data.node] = this->num_data;
this->_sinkUp(this->num_data);
++this->num_data;
return;
}
void Heap::pop()
{
if (this->num_data == 0)
return;
this->pos[this->heapData[0].node] = -1;
this->heapData[0] = this->heapData[--this->num_data];
this->pos[this->heapData[0].node] = 0;
this->_sinkDown(0);
return;
}
IDX_DIST Heap::top() const
{
if (this->num_data == 0)
return {};
return this->heapData[0];
}
int Heap::size() const
{
return this->num_data;
}
void Heap::update(int node, int dist)
{
if (this->pos[node] == -1) {
exit(-1);
}
int position = this->pos[node];
int prev_dist = this->heapData[position].dist;
this->heapData[position].dist = dist;
if (prev_dist < dist)
_sinkDown(position);
else
_sinkUp(position);
return;
}
void Heap::_sinkUp(int idx)
{
int child = idx;
int parent = (idx - 1) / 2;
while (parent >= 0 && this->heapData[child] < this->heapData[parent]) {
IDX_DIST tmp = this->heapData[parent];
this->heapData[parent] = this->heapData[child];
this->heapData[child] = tmp;
// update position
this->pos[this->heapData[parent].node] = parent;
this->pos[this->heapData[child].node] = child;
child = parent;
parent = (child - 1) / 2;
}
return;
}
void Heap::_sinkDown(int idx)
{
int parent = idx;
int child = 2 * parent + 1;
bool placed = false;
while (!placed && child < this->num_data)
{
if (child < this->num_data - 1 && this->heapData[child + 1] < this->heapData[child]) {
child += 1;
}
if (this->heapData[parent] < this->heapData[child]) {
placed = true;
}
else {
IDX_DIST tmp = this->heapData[parent];
this->heapData[parent] = this->heapData[child];
this->heapData[child] = tmp;
// update position
this->pos[this->heapData[parent].node] = parent;
this->pos[this->heapData[child].node] = child;
}
parent = child;
child = 2 * parent + 1;
}
return;
}다익스트라 알고리즘 구현
이전 글에서 그래프 자료구조를 구현해둔 것이 있어서, 그것을 사용하려고 했으나 비효율적인 부분들이 많아서 새롭게 그래프를 표현하는 구조체를 사용하였습니다.
먼저 Dijkstra.hpp 헤더파일 입니다.
#ifndef __DIJKSTRA_HPP__
#define __DIJKSTRA_HPP__
#include <vector>
#define INF 123456789
typedef struct _idx_dist {
int node;
int dist;
bool operator()(const struct _idx_dist& a, const struct _idx_dist& b) const {
return a.dist < b.dist;
}
bool operator<(const struct _idx_dist& o) const {
return dist < o.dist;
}
} IDX_DIST;
typedef struct _graph {
int num_node;
std::vector<std::vector<IDX_DIST>> adjs;
} GRAPH;
void init_graph(GRAPH& graph, int num_node);
void add_edge(GRAPH& graph, int u, int v, int d, bool direction = false);
std::pair<std::vector<int>, std::vector<int>> dikstra(GRAPH& graph, int s);
#endifINF는 다익스트라 알고리즘에서 사용하는 거리의 최대값입니다.
typedef struct _idx_dist {
int node;
int dist;
bool operator()(const struct _idx_dist& a, const struct _idx_dist& b) const {
return a.dist < b.dist;
}
bool operator<(const struct _idx_dist& o) const {
return dist < o.dist;
}
} IDX_DIST;그리고, IDX_DIST라는 구조체를 정의했는데, 이 구조체는 우선순위 큐에서 저장될 데이터를 담고 있습니다. 우선순위 큐 내에서는 값을 비교하는 연산이 필요하므로, operator()와 operator<를 미리 구현해두었습니다. 위 처럼 구현하게 되면 비교 연산에서 오름차순으로 정렬이 되어서 우선순위 큐의 top에 최솟값이 위치하게 됩니다.
다음은 그래프 자료구조로 사용할 구조체입니다.
typedef struct _graph {
int num_node;
std::vector<std::vector<IDX_DIST>> adjs;
} GRAPH;
void init_graph(GRAPH& graph, int num_node);
void add_edge(GRAPH& graph, int u, int v, int d, bool direction = false);많이 익숙하실 수 있는데, 노드의 총 개수(0 ~ num_node - 1까지의 노드)와 각 노드의 인접 노드의 정보(인접 노드 인덱스와 거리)를 저장하는 이중 배열 형태의 vector를 사용했습니다.
그리고 init_graph를 통해 초기화를 수행하고, add_edge 함수를 통해서 그래프의 간선을 추가할 수 있습니다.
(해당 코드 구현은 깃허브를 참조바랍니다 !)
마지막은 다익스트라 알고리즘이 동작하는 함수입니다. 이 함수는 두 vector 배열을 반환하는데, 첫 번째 vector는 노드의 앞에 위치하는 노드를 담고 있는 pred이고, 두 번째 vector는 시작 노드에서부터의 각 노드까지의 거리를 담고 있는 dist입니다. 매개변수로는 그래프 구조체와 시작 노드의 인덱스를 받습니다.
std::pair<std::vector<int>, std::vector<int>> dikstra(GRAPH& graph, int s);
그럼 바로 이 함수가 어떻게 구현되는지 살펴보겠습니다.
std::pair<std::vector<int>, std::vector<int>> dikstra(GRAPH& graph, int s)
{
if (graph.num_node < s) {
exit(-1);
}
std::vector<int> pred(graph.num_node, -1);
std::vector<int> dist(graph.num_node, INF);
std::vector<int> cnt(graph.num_node, 0);
Heap pq(graph.num_node);
dist[s] = 0;
for (int i = 0; i < graph.num_node; i++) {
pq.push({ i, dist[i] });
}
while (pq.size() != 0) {
auto idx_dist = pq.top();
pq.pop();
int& u = idx_dist.node;
cnt[u]++;
for (auto& adj : graph.adjs[u]) {
int& v = adj.node;
if ((dist[u] != INF) && (dist[v] > dist[u] + adj.dist)) {
dist[v] = dist[u] + adj.dist;
pred[v] = u;
pq.update(v, dist[v]);
}
}
}
return { pred, dist };
}시작노드가 주어진 노드 인덱스 범위를 넘어서면 안되기 때문에, 처음에 예외처리를 해주었습니다.
그리고 line 7 ~ 16에서 자료구조 초기화를 수행합니다. 반환될 pred와 dist 크기를 노드의 개수로 설정해주고, pred의 초기값을 -1로, 그리고 dist의 초기값을 \(\infty\)로 설정합니다. 실제 컴퓨터 언어에서는 무한대가 존재하지 않기 때문에 임의로 123,456,789로 최대값을 설정해서 초기화를 수행합니다.
(cnt 벡터를 사용했는데, 실제로 각 노드가 우선순위 큐에서 한 번씩 제거됬는지 확인하기 위해 사용하였습니다.)
마지막으로 시작 위치의 dist를 0으로 설정해주고, 15 ~ 17 line에서 모든 노드와 시작 노드에서의 거리를 우선순위 큐에 삽입해줍니다.
그리고 line 19부터 루프가 시작되는데, 이는 위에서 설명한 알고리즘과 동일하게 진행됩니다.
dist의 값이 가장 작은 데이터를 우선순위 큐에서 추출하고, 그 노드의 인접 노드들을 방문하면서 거리 추정값을 갱신합니다. 이때, 갱신한 거리 추정값이 존재한다면, 우선순위 큐에 존재하는 인접 노드와 관련된 거리 추정값을 update 해줍니다.(이를 위해서 Heap을 새로 구현하였습니다.)
(+ 만약 인접 노드의 거리가 \(\infty\)인 경우에는 수행되지 않습니다. 무한대에 얼마를 더해봐야 무한대이기 때문 !)
각 노드는 루프를 돌면서 한 번씩만 큐에서 제거되고, 루프를 종료하게 됩니다.
실제로 잘 동작하는지 테스트해보겠습니다. 테스트할 노드와 간선 정보는 아까 위에서 사용한 것과 동일합니다.
아까는 열과 행으로 각 노드를 표현했는데, 편의를 위해서 왼쪽 위부터 오른쪽으로 순차적으로 노드의 인덱스를 0, 1, 2, ... 15로 설정하도록 하겠습니다. 오른쪽 아래 마지막 노드가 15가 됩니다.
#include <iostream>
#include <stdio.h>
#include "Dijkstra.hpp"
int main(void) {
GRAPH graph;
init_graph(graph, 16);
add_edge(graph, 0, 1, 3);
add_edge(graph, 0, 4, 5);
add_edge(graph, 1, 2, 1);
add_edge(graph, 1, 5, 9);
add_edge(graph, 2, 3, 4);
add_edge(graph, 2, 6, 2);
add_edge(graph, 3, 7, 6);
add_edge(graph, 4, 5, 3);
add_edge(graph, 4, 8, 7);
add_edge(graph, 5, 6, 5);
add_edge(graph, 5, 9, 9);
add_edge(graph, 6, 7, 8);
add_edge(graph, 6, 10, 3);
add_edge(graph, 7, 11, 2);
add_edge(graph, 8, 9, 8);
add_edge(graph, 8, 12, 6);
add_edge(graph, 9, 10, 4);
add_edge(graph, 9, 13, 4);
add_edge(graph, 10, 11, 6);
add_edge(graph, 10, 14, 3);
add_edge(graph, 11, 15, 3);
add_edge(graph, 12, 13, 3);
add_edge(graph, 13, 14, 2);
add_edge(graph, 14, 15, 7);
int start_node = 0;
auto result = dikstra(graph, start_node);
printf("----- distance from start node %d -----\n\n", start_node);
for (int i = 0; i < graph.num_node; i++) {
printf(" %3d ", result.second[i]);
if ((i + 1) % 4 == 0)
printf("\n");
}
printf("\n");
return 0;
}예제 코드입니다.
start_node를 0으로 설정해서 다익스트라 함수를 실행하면, 위에서 살펴본 그래프의 결과와 동일한 결과를 얻은 것을 확인할 수 있습니다.

이 알고리즘에서 임의의 한 노드까지 최단 경로를 찾지 못할 가능성이 있을까요?
최단 경로 추정값인 dist[v]를 갖는 노드 v를 우선순위 큐에서 꺼낸다고 가정해봅시다. 그 추정값이 정확하지 않다면 지금까지 찾은 경로보다 더 짧지만, 아직 찾지 못한 다른 경로(u -> v)가 있을 것입니다.
앞에서 설명한 것처럼 우선순위 큐에서 아직 꺼내지 않은 노드를 사용한 모든 경로에 대한 계산(거리 추정값)은 가장 짧은 경로를 찾기 위한 것입니다. 따라서, 우선순위 큐에서 이미 꺼낸 노드들을 사용한 v까지의 경로가 존재하고, 이 경로는 이미 발견했던 경로보다 더 짧은 경로이며 노드 v에서 끝납니다. 만약 u가 해당 경로에서 v 바로 앞에 있는 노드라면, 우선순위 큐에서 노드 u를 꺼냈을 때, dist[u] + weight(G, u, v) < dist[v] 이므로 최단 경로를 발견할 수 있습니다.
따라서 알고리즘에서 최단 경로를 놓칠 수 없습니다.
즉, 우선순위 큐에서 한 노드를 추출할 때에는 이미 이 노드에 다다르는 최단 경로를 발견한 상태이며, 알고리즘이 실행되면 동안 우선순위 큐에서 추출된 노드들의 집합은 올바른 최단 경로를 찾았던 노드들의 집합이 됩니다.
이처럼 다익스트라 알고리즘은 어떤 노드까지의 최단 경로를 찾는 데 사용할 수 있고, 어떤 노드가 우선순위 큐에서 추출되는 한 이 노드로의 최단 경로를 찾을 수 있으므로 특정 노드까지의 최단 경로만 관심이 있다면 알고리즘의 실행을 멈추고 결과를 반환해도 됩니다.
시간 복잡도
이 알고리즘의 시간 복잡도를 살펴보겠습니다.
우선 우선순위 큐에 관해서 살펴보면, 처음 모든 노드들과 그 노드들의 거리를 우선순위 큐에 넣고 업데이트하는 작업이 있습니다.
원래 연산에 \(O(logN)\)의 시간이 드는 우선순위 큐 입장에서 V개의 노드를 넣는 시간은
\[O(1) + O(log2) + O(log3) + \cdots + O(log(|V|-1)) + O(log|V|) = O(log|V|)\]
로 나타낼 수 있습니다.
루프안에서 총 V번 우선순위 큐에서 노드가 추출되고, 추출될 때마다 top의 위치를 갱신하는 작업을 수행하므로, 이 시간은 \(O(|V|log|V|)\)가 됩니다. 그리고 루프안에서 최단 거리 추정값을 발견했을 때, 우선순위 큐 내에서 해당 노드의 dist 값을 업데이트를 해주는데, 우선순위 큐 내에서 위치를 찾는 것은 pos 변수로 상수시간 내에 찾을 수 있고, 변경에 의해서 우선순위 큐의 순서가 업데이트되는데 이 시간이 원래 연산 시간인 \(O(log|V|)\)입니다. 루프를 통틀어서 최단 거리를 갱신하는 작업은 최대 \(O(|E|)\)번 이루어질 것이므로, 루프 내에서 최단 거리 추정값을 업데이트하는 데 걸리는 시간은 \(|E|log|V|\)가 걸리게 됩니다.
정리하면
\[O(log|V| + |V|log|V| + |E|log|V|) = O((1+|V|+|E|)log|V|)\]
인데, 모든 그래프 노드가 시작 노드에서 도달할 수 있다면, 노드 수는 간선의 수보다 더 많을 수가 없으며, 이 알고리즘의 시간 복잡도는
\[O(|E|log|V|)\]가 됩니다.
음의 가중치가 존재한다면 알고리즘 적용 불가 !
다익스트라 알고리즘은 방향 그래프와 무방향 그래프 모두에서 동작합니다.
만약 그래프 내에 순환(Cycle)이 존재한다면 경로의 길이에 더해져서 최단 경로가 아니게 되므로 문제가 되지 않습니다.
하지만 음의 가중치가 존재한다면 문제가 됩니다. 즉, 가중치가 실제 거리를 표현하는 게 아니라 양수와 음수 값을 모두 취할 수 있는 다른 척도를 나타낸다면 음의 가중치를 가질 수도 있습니다.
알고리즘의 정확한 실행은 길이가 증가하는 경로를 찾는 것에 포함됩니다. 음의 가중치가 존재한다면 앞으로 계산할 모든 경로가 우선순위 큐에서 노드를 추출할 때 이미 계산한 경로보다 짧지 않다고 확신할 수 없게 되므로, 음의 가중치가 존재한다면 다익스트라 알고리즘은 사용할 수 없습니다.
(다른 최단 경로 알고리즘을 사용해야합니다 -> 벨만-포드 알고리즘)
예시로, 음의 가중치를 갖는 아래의 그래프를 살펴보겠습니다.
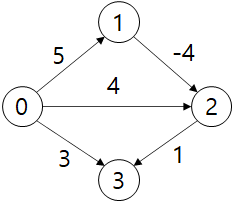
이 그래프로 다익스트라 알고리즘을 수행하면, 다음과 같이 진행됩니다.
(d/p는 경로 값 d와 이전 노드 p를 의미합니다.)

노드 0에서 노드 3까지 최단 경로는 전체 길이가 \(5-4+1=4\)인 \(0 \rightarrow 1 \rightarrow 2 \rightarrow 3\)입니다. 그러나 다익스트라 알고리즘에서 추적한 위 그림을 보면, 추적 결과에서 노드 0 이후에 노드 3, 노드 2를 먼저 꺼냈기 때문에 노드 1에서 오는 최단 경로를 갱신할 때 다시 추출할 수 없습니다.
그러므로 노드 3으로의 최단 경로는 절대 갱신되지 않거나 발견되지 않습니다.
각 간선의 가중치에 상수를 더하여 모든 간선이 양의 가중치를 갖게 하는 간단한 해결 방법을 생각할 수도 있는데, 이것도 제대로 동작하지 않습니다.

위의 경우 각 간선에 4를 더해서 표현했는데, 노드 0에서 노드 3까지의 최단 경로가 \(0 \rightarrow 3\)이 되므로 변환을 사용하여도 같은 결과를 얻을 수가 없습니다.
그래프의 지름
다익스트라 알고리즘으로 그래프의 다른 정보를 얻을 수 있습니다.
임의의 노드로부터 다른 노드까지의 모든 최단 경로를 간단하게 계산할 수 있는데, 이것을 모든 쌍의 최단 경로 문제(all paris shortest paths problem)이라고 합니다. 매번 다른 노드에서 시작하여 다익스트라 알고리즘을 \(|V|\)번 실행하기만 하면 됩니다.
그래프에 있는 모든 쌍의 노드들 사이 최단 경로를 계산하고 나면 전체 그래프의 토폴로지(Topology)에 대한 척도를 계산할 수 있습니다. 그래프의 지름은 두 노드 사이의 가장 긴 최단 경로의 길이입니다. 다른 노드 쌍을 연결하는 최단 경로가 d보다 작으며 그래프에서 길이 d인 노드들 사이에 최단 경로가 있는 두 개의 노드 v와 u가 있다면 그래프를 가로질러 이동할 수 있는 가장 긴 최단 경로는 v에서 u까지의 경로입니다. 토폴로지에서 지름은 두 점 사이의 가장 긴 거리로 이해되므로 그래프를 토폴로지로, 노드를 점으로 본다면 v에서 u까지의 경로는 토폴로지의 지름에 해당됩니다.
따라서 그래프의 지름을 계산하려면 먼저 모든 쌍의 최단 경로 알고리즘을 실행하고 반환된 결과 중에서 가장 긴 경로를 찾으면 되는데, 이때 경로의 길이가 바로 그래프의 지름입니다.
'Data Structure & Algorithm > 알고리즘' 카테고리의 다른 글
| [그래프] 플로이드-워셜 알고리즘(Floyd-Warshall Algorithm) (0) | 2021.10.11 |
|---|---|
| [그래프] 벨만-포드 알고리즘(Bellman-Ford Algorithm) (0) | 2021.10.10 |
| [그래프] 가중치 그래프와 임계 경로(Critical Path) (0) | 2021.10.06 |
| [그래프] 위상 정렬 Topological Sort (0) | 2021.10.05 |
| [암호] 디피-헬먼 키 교환 (모듈러 거듭제곱) (0) | 2021.09.27 |




댓글