References
- Algorithms (Sanjoy Dasgupta)
Contents
- Search Problems
- NP-Complete Problems
Search Problems
현재 참고 중인 교재(Algorithms)에서 그래프에서의 최단 경로, 최소 신장 트리, 이분 매칭, 최장 증가 부분 수열, 네트워크 플로우 등의 알고리즘에 대해 살펴봤었습니다. 이러한 알고리즘들은 실행 시간이 입력 데이터 크기에 대한 다항식(ex, \(n, n^2, n^3\))이었으며, 따라서 효율적인 알고리즘이라 할 수 있습니다.
이와 같은 알고리즘을 좀 더 이해하기 위해 알고리즘이 해결하려는 문제를 다른 방법으로 접근해보겠습니다. 이 문제들에서 가능한 솔루션(path, tree, matching)의 수는 모두 지수승으로 표현되는 수 입니다. 즉, 이분 매칭 문제의 경우에는 n명의 소년과 n명의 소녀들을 매칭하는 방법을 찾는 문제이므로 가능한 솔루션의 수는 총 n!가지가 됩니다. 또한 정점의 수가 n인 그래프는 총 \(n^{n-1}\)가지의 신장 트리를 가질 수 있고, 일반적인 그래프에서 정점 s에서 t로 가는 경로의 수도 지수승으로 표현되는 숫자입니다. 따라서 이러한 문제를 풀기 위해 가능한 솔루션들을 하나씩 차례로 모두 검사하는 방법은 틀림없이 원하는 최적의 솔루션을 구할 수 있지만, 실행 시간은 당연히 지수승 시간이 됩니다. 하지만 실행 시간이 \(2^n\)이거나 이보다 더 큰 알고리즘은 실용성이 없습니다.
효율적인 알고리즘에 대한 탐구는 입력 데이터로부터 검색 공간(search space)를 극적으로 좁혀 이러한 전수 탐색 방법이 아닌 다른 영리한 방법을 찾는 것입니다.
그리디 알고리즘이나 동적 프로그래밍, 선형 계획법 등의 방법들은 모두 지수 복잡도 문제를 더 빠르게 해결해주는 기법입니다. 하지만 이번 포스팅에서 다루는 내용은 꽤 당혹스러운 문제들이 많습니다. 이러한 문제들도 역시 탐색 문제의 일종으로 가능한 솔루션이 지수승인 상황에서 특정 성질을 갖는 솔루션을 찾는 문제입니다. 그러나 알아볼 문제의 경우에는 지름길을 찾는 것이 불가능보이는 문제들이 많습니다. 즉, 지금부터 다룰 문제들은 그 문제에 대한 가장 빠른 알고리즘이 모두 지수 복잡도를 갖는 문제들이며, 모두 궁극적으로 전수 탐색 방법보다 더 낫다고 할 수 없는 문제들입니다.
몇 가지 예시 문제들을 살펴보겠습니다.
Satisfiability (SAT)
Satisfiability(충족 가능성 문제, SAT라고 칭함)는 실용적인 측면에서 매우 중요한 문제입니다. 이 문제는 Chip Testing, 컴퓨터 설계부터 이미지 분석, 소프트웨어 공학에 이르기까지 응용 분야가 매우 넓습니다. 또한 매우 어려운 문제입니다.
SAT 문제는 다음과 같은 형식으로 주어집니다.
\[(x \vee y \vee z) (x \vee \bar{y}) (y \vee \bar{z}) (z \vee \bar{x}) (\bar{x} \vee \bar{y} \vee \bar{z})\]
이 식은 CNF(Conjunctive Normal Form, 논리곱 표준형)으로 표현된 부울식입니다.
CNF는 and 연산자로 연결된 절(clause, 괄호로 묶인 것들)들로 구성되며, 하나의 절은 or 연산자(\(\vee\))로 연결된 문자(literal, 리터럴)로 구성됩니다. 리터럴은 부울 변수(예를 들어 x) 혹은 not 연산자가 붙어 부정된 변수(예를 들어 \(\bar{x}\))입니다.
이 문제는 만족하는 true assignment를 찾는 것인데, 각 변수에 false 또는 true를 할당하여 모든 절이 true인 리터럴을 포함하도록 하는 것입니다. 따라서 SAT 문제는 다음과 같습니다: CNF로 주어진 부울식에 대하여, 만족하는 true assignment를 찾거나 true assignment가 불가능하다는 것을 보여라.
예를 들어, 위에서 주어진 CNF의 경우에는 모든 변수에 true를 배정할 때 마지막 절을 제외하고 모든 절이 만족(true가 됨)합니다. 위의 부울식에서 모든 절을 만족시키는 true assignment가 있을까요?
조금만 생각하면 이 부울식이 true를 갖도록(즉, 만족하도록) 각 변수에 true나 false를 할당하는 것이 불가능하다는 사실을 알아낼 수 있습니다(가운데 3개의 절은 세 변수가 모두 true이던지 false, 즉, 동일한 값을 가져야 모두 true가 됨). 위의 경우에서는 true assignment가 불가능하다는 알아낼 수 있지만, 일반적인 경우에는 이러한 결정을 어떻게 내릴 수 있을까요? 물론 true assignment의 모든 가능한 경우를 하나씩 찾아볼 수 있지만, n개의 변수가 있는 CNF의 경우 가능한 경우의 수는 지수승, 즉, \(2^n\) 입니다.
SAT 문제는 전형적인 탐색 문제(search problem)입니다. 하나의 사례(instance, I)가 주어지고, 정답(solution, S)을 찾을 것을 요구합니다. 만약 그러한 정답이 존재하지 않으면 존재하지 않는다고 결정해야 합니다.
조금 더 구체적으로, 탐색 문제는 주어진 사례 I에 대해 제안된 임의의 솔루션 S가 맞는지 아닌지를 빠른 시간 내에 검증할 수 있는 성질을 가져야 합니다. 이 성질은 무엇을 의미할까요? 의미하는 바 중 하나는 S가 최소한 I의 길이에 대한 다항식으로 S가 표현될 정도로 간결해야 합니다. 빠른 시간 내에 검증할 수 있다는 것은 입력 I와 S를 받아서 S가 I의 솔루션인지 여부를 판단하는 다항 시간 복잡도의 알고리즘이 존재한다는 것을 말합니다. SAT의 경우에는 S로 지정된 배정(assignment)가 I의 모든 절을 충족하는지 여부만 확인하면 되므로 검증 알고리즘이 다항식 시간 복잡도를 가지는 것이 명백합니다.
이렇게 제안된 솔루션을 검증하는 효율적인 알고리즘을 탐색 문제를 정의하는 것으로 생각하는 것이 아래의 내용을 이해하는데 유용할 것입니다. 따라서 탐색 문제를 다음과 같이 정의합니다.

탐색 문제는 사례 I와 제안된 솔루션 S를 입력으로 받아 \(|I|\)에 대한 다항식 시간 안에 실행되는 알고리즘 C로 명시된다. 또한, S가 I의 해가 될 필요충분 조건은 C(I, S) = true인 것이다.
SAT 탐색 문제의 중요성을 인식하고, 리서처들은 지난 50년 동안 이를 해결하는 효율적인 방법을 찾기 위해 열심히 노력했지만, 아무도 성공하지 못하였습니다. 지금까지 알려진 가장 효율적인 알고리즘은 여전히 최악의 입력 케이스에 대해 지수 시간 복잡도를 갖습니다.
그러나 SAT 문제의 변형 중에는 효율적인 알고리즘이 발견된 것들이 있습니다.
예를 들어, 모든 절이 최대 하나의 positive 리터럴만 포함하는 CNF 부울식을 호른식(Horn formula)이라고 하는데, 만족하는 true assignment가 존재하는 경우 그리디 알고리즘을 통해 이를 찾을 수 있습니다.
또 다른 문제는 모든 절이 2개의 변수로만 구성되어 있는 문제입니다. 이러한 문제를 2-SAT 문제라고 하며, 이 문제가 주어지면 이를 그래프로 변환한 다음 SCC(Strongly Connected Component)를 찾음으로써 선형 시간 내에 문제를 풀 수 있습니다. 2-SAT에 대한 알고리즘은 다른 포스팅으로 살펴보도록 하겠습니다(교재의 9장에서 설명합니다).
2-SAT 문제는 모든 절이 2개의 변수(ex, x와 y로만)만 가지고 있는 문제입니다. 만약 모든 절이 3개의 변수만 가지고 있다면 3-SAT 문제가 되며, 위에서 본 CNF 부울식도 3-SAT 문제입니다. 하지만 아직 3-SAT 문제를 푸는 효율적인 알고리즘은 발견되지 않았습니다.
The Traverling Salesman Problem(외판원 문제, TSP)
외판원 문제는 1에서 n까지의 정점과 \(\frac{n(n-1)}{2}\)개의 모든 정점들간의 거리, 그리고 여행 예산 b가 주어집니다. 여기서 예산을 넘지 않는 비용으로 모든 도시를 여행하는 경로, 즉, 각 정점을 정확히 한 번씩 통과하는 cycle을 찾거나 그러한 경로가 존재하지 않는다면 존재하지 않는다고 판단하는 것이 주어진 문제의 솔루션입니다.
즉, TSP 문제를 풀기 위해 정점들 간 거리들의 총합이 b를 넘지 않는 정점들의 순열 \(\tau(1), \cdots \tau(n)\)을 찾아야 합니다. 즉, 다음 식을 만족하는 순열을 찾는 것입니다.
\[d_{\tau(1),\tau(2)} + d_{\tau(2), \tau(3)} + \cdots + d_{\tau(n), \tau(1)} \leq b\]
TSP 문제의 예는 아래 그림과 같습니다(거리가 너무 큰 것은 생략되어 있음).

위에서 언급한 탐색 문제의 정의에 따라, TSP를 다음의 탐색 문제로 정의한 방법에 주목해봅시다.
주어진 사례 I에서 예산 이내의 여행 경로를 찾거나 혹은 존재하지 않음을 찾음
그러나 실제 TSP 문제는 최단 경로를 찾는 최적화 문제인데, 왜 위와 같은 방식으로 표현할까요?
이번 포스팅에서는 여러 문제들을 비교하고 연관시키는 것인데, 탐색 문제가 SAT와 같은 진짜 탐색 문제뿐 아니라 TSP와 같은 최적화 문제까지도 포함하기 때문에 탐색 문제의 프레임워크가 도움이 됩니다.
최적화 문제와 탐색 문제는 서로 치환될 수 있기 때문에 최적화 문제를 탐색 문제로 변환하는 것은 그 문제의 난이도를 전혀 변경하지 않습니다. 최적화 TSP 문제를 해결하는 알고리즘은 탐색 문제도 쉽게 해결할 수 있습니다. 즉, 최적 여행 경로를 찾고, 그 경로의 경비가 주어진 예산 이하라면 이를 반환하고, 그렇지 않으면 해가 없다고 답하면 됩니다.
역으로 탐색 문제를 푸는 알고리즘으로 최적화 문제를 풀 수도 있습니다. 그 이유를 살펴보기 위해, 먼저 최적 경로의 경비를 알고 있다고 가정하겠습니다. 그러면 이 경비를 예산으로 사용하여 탐색 문제의 알고리즘을 호출함으로써 경로를 찾을 수 있습니다. 그러면 최적의 경비는 어떻게 알 수 있을까요? 예를 들어, 이진 탐색(binary search)를 사용하여 최적 경비를 쉽게 찾을 수 있습니다.
최적화 문제도 최적의 성질을 갖는 해를 찾는다는 점에서 탐색 문제라고 할 수 있지 않을까요? 그렇다면 여기서 예산을 도입하는 이유가 무엇일까라는 미묘한 의문이 제기됩니다.
그 이유는 탐색 문제에 대한 해는 인식하기 쉬워야 하기 때문입니다. 즉, 다항식 시간 이내에 검사가 가능해야 한다는 것입니다. TSP에 대한 잠재적인 솔루션이 주어질 때, 주어진 솔루션이 경로(모든 정점이 정확히 한 번씩 방문하는가)인가 그리고 경로의 총 길이가 예산 b보다 크지 않은가라는 성질을 검사하는 것은 쉽습니다. 그러나 이 솔루션이 최적인지는 어떻게 검사할 수 있을까요?
SAT와 마찬가지로, TSP에 대해 알려진 다항식 시간 알고리즘은 거의 한 세기에 걸쳐 리서처들이 많은 노력을 기울였음에도 불구하고 없습니다. 물론 (n-1)!가지의 모든 경로를 일일히 시도하는 지수 시간 복잡도의 알고리즘은 존재하며, 아래 포스팅에서 여전히 지수 시간 복잡도지만, 조금 더 빠른 동적 계획법 알고리즘을 살펴보았습니다.
[DP] 외판원 문제 (Traverling Salseman Problem)
효율적인 알고리즘이 존재하는 MST 문제는 여기서 극명하게 대조적입니다. 탐색 문제로 MST를 변환하면 TSP 경우와 마찬가지로 거리에 대한 행렬과 그 한계 b가 주어지고, 가중치 합이 다음을 만족하는 트리 T를 찾는 문제가 됩니다.
\[\sum_{(i, j) \in T} d_{ij} \leq b\]
TSP는 '트리는 분기될 수 없고, 따라서 경로(path)가 되어야 한다'라는 한 가지 조건이 더 붙은 MST 문제의 매우 어려운 사촌쯤 되는 문제로 여겨질 수 있습니다. 트리 구조에 대한 추가적인 제약이 훨씬 더 어려운 문제로 바뀌게 되는 결과를 초래합니다.
Euler and Rudrata
오일러는 1735년 어느 마을의 다리를 걷다가, 어디에서 출발하든 어던 길을 선택하든 모든 다리들을 정확히 한 번씩 지나는 것이 불가능하다는 것을 깨달았습니다. 오일러는 그 이유를 발견했는데, 먼저 공원의 지도를 4개의 육지를 정점으로, 그리고 7개의 다리를 간선으로 하여 아래와 같은 그래프로 변환하였습니다.
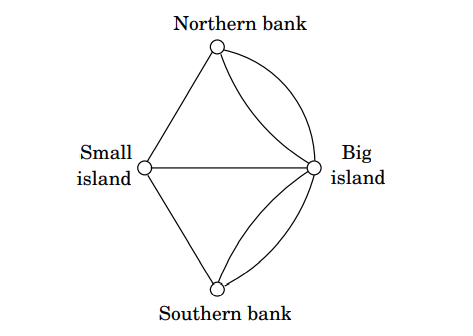
이 그래프는 주어진 두 정점 간에 여러 개의 간선이 존재합니다. 이 그래프에서 모든 간선을 정확히 한 번씩 사용하는 경로(정점은 여러 번 반복해도됨)를 찾는 것이 문제의 목적입니다. 다시 말하면, 어떠한 그래프가 연필을 종이에서 한 번도 떼지 않고 그릴 수 있는 그래프인가 찾는 문제(한붓 그리기)입니다.
오일러가 발견한 답은 다음과 같이 간단하고, 우아하며 직관적입니다. (a) 그래프는 연결되어 있고 (b) 출발 정점과 도착 정점을 제외한 모든 정점은 차수가 짝수라면 모든 간선을 정확히 한 번씩 사용하는 경로를 찾을 수 있습니다. 이러한 이유로 위의 문제에서는 모든 정점의 차수가 홀수이기 때문에 다리를 정확히 한 번씩 밟고 지나가는 것이 불가능합니다.
주어진 그래프에서 모든 간선을 정확히 한 번씩 포함하는 경로를 찾는 문제를 오일러 경로(Euler Path)라고 합니다. 오일러가 발견한 것을 조금만 생각하면 이 탐색 문제는 다항식 시간 내에 풀 수 있음을 알 수 있습니다.
오일러가 이 문제를 발견하기 100년 저네, 루드라타(rudrata)라는 사람은 다음과 같은 질문을 했습니다: 체스판에서 나이트의 이동(move)로 모든 사각형을 정확하게 한 번씩만 방문하고 시작 위치로 되돌아오는 것이 가능할까 ?
이 문제 역시 그래프 문제입니다. 즉, 이 그래프는 체스판의 사각형을 정점으로 나타내고(64개의 정점), 나이트가 한 번 움직여서 갈 수 있는 사각형들을 간선으로 연결하여 작성합니다. 아래 그림은 체스판의 좌상단에서의 그래프를 나타낸 것입니다.
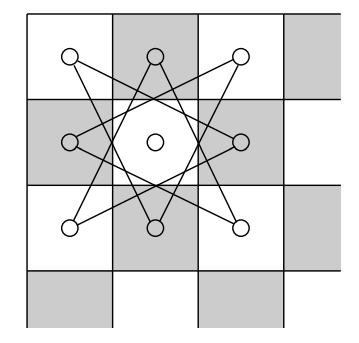
이 문제는 또 다른 그래프상의 탐색 문제입니다. 이 문제는 오일러 경로와는 달리 모든 정점을 정확히 한 번씩 방문하는 순회(cycle) 경로를 찾는 문제입니다. 그리고 체스판뿐만 아니더라도 임의의 그래프에 대해 이러한 질문이 주어질 수 있습니다. 그래서 루드라타 순회(Rudrata Cycle) 탐색 문제는 다음과 같이 정의됩니다.
주어진 그래프에서 각 정점을 한 번씩만 방문하는 순회 경로를 찾거나, 그러한 경로가 존재하지 않는다는 것을 찾아라.
이 문제는 TSP 문제를 연상시키며, 다항식 알고리즘이 아직까지 발견되지 않았습니다.
오일러 문제의 정의와 루드라타 문제의 정의 간에는 두 가지 차이점이 있습니다. 첫째, 오일러 문제는 모든 간선을 방문하지만, 루드라타 문제는 모든 정점을 방문합니다. 둘째, 오일러 문제는 경로(path)를 요구하고 루드라타 문제는 순회(cycle)을 요구합니다. 이러한 차이점 가운데 어느 것이 두 문제 사이의 계산적 복잡도 상의 차이를 야기할까요? 두 번째 차이점은 순전히 미학적으로 보일 수 있기 때문에 첫 번째 차이점임에 틀림없습니다. 실제로 루드라타 경로(Rudrata Path) 문제를 루드라타 순회(Rudrata Cycle)과 똑같이 정의하되 순회가 아닌 모든 정점을 정확히 한 번만 방문하는 경로를 찾는 것이 목적인 문제로 정의하면, 루드라타 경로 문제와 순회 문제가 동일한 문제라는 것을 알 수 있습니다.
Cuts and bisections
컷(cut)은 제거되면 주어진 그래프를 비연결 그래프로 만드는 간선들의 잡합으로 정의됩니다. 작은 컷(small cut)을 찾는 것은 흥미로운 문제이며, 최소컷(minimum cut) 문제는 그래프와 예산(budget) b가 주어졌을 때, 간선의 수가 b개를 넘지 않는 컷을 찾는 것입니다. 예를 들어, 아래 그림의 경우에는 최소컷의 크기가 3입니다.
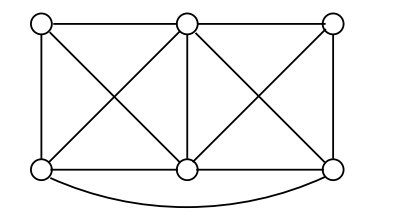
이 문제는 n-1개의 최대 유량(max-flow) 계산으로 다항식 시간에 해결될 수 있습니다. 즉, 각 간선에 용량 1을 부여하고, 임의의 한 정점을 소스(source)로 지정한 다음, 소스 이외의 나머지 정점들 각각에 대해 최대 유량(max-flow)를 구합니다. 그리고 가장 작은 유량이 가장 작은 컷에 해당합니다(max-flow min-cut thorem).
위의 그래프를 비롯한 많은 그래프들의 최소컷은 끝점을 공유하는 간선들로 이루어지는 경우가 많으며, 이러한 경우에는 그 최소컷을 제거하면 한쪽은 단 하나의 정점만 남게 됩니다. 이러한 최소컷보다는 그래프를 어느 정도 균등하게 분할하는 컷 중에서 가장 작은 컷이 유용한 경우가 많습니다. 좀 더 정확히 말하면 균형적인 컷(balanced cut) 문제는 다음과 같이 정의됩니다.
n개의 정점을 가진 그래프와 예산 b가 주어질 때, 정점들을 S와 T로 분할하라. 단, \(|S|, |T| \geq \frac{n}{3}\)이며 S와 T 사이의 간선의 수는 b를 넘지 않는다.
이 문제 또한 어려운 문제 중 하나입니다.
균형적인 컷(balanced cut)은 군집화(clustering)와 같은 다양하고 중요한 실용적인 문제에서 발생합니다. 예를 들어, 주어진 이미지를 구성 성분(consituent components)들로 분할하는 문제가 있습니다(구체적인 예로 푸른 하늘이 있는 풀밭에 서 있는 코끼리 이미지). 이러한 문제를 풀기 위해 각 픽셀을 정점으로 하고 이웃한 픽셀이면서 색깔이 비슷한 픽셀에 해당하는 정점들을 간선으로 연결한 그래프로 이미지를 표현할 수 있습니다. 그러면 하나의 구성 성분(예를 들어 코끼리)은 그래프에서 고도로 연결된 정점들의 집합으로 나타납니다. 그래서 균형적인 컷은 이미지의 구성 성분을 손상하지 않으면서 픽셀들을 군집화합니다. 예를 들어 첫 번째 균형적인 컷은 코끼리를 잔디와 구름으로부터 분할하고, 그 다음 균형적인 컷은 잔디와 구름을 분할합니다.
Integer Linear Programming
심플렉스(Simplex) 알고리즘은 다항식 시간은 아니지만, 선형계획법을 위한 다른 다항식 알고리즘이 있습니다. 따라서 선형계획법은 이론적으로나 실제적으로 효율적으로 풀 수 있는 문제입니다. 그러나 선형 목적 함수와 선형 부등식과 더불어 해가 정수이어야 한다는 제약을 추가하면 상황은 완전히 달라집니다. 이렇게 정수라는 제약이 추가된 문제를 정수 선형계획법(ILP)라고 합니다.
ILP 문제를 탐색 문제로 변환하면, 선형 부등식은 \(\mathbf{Ax} \leq b\), 단 \(\mathbf{A}\)는 m x n 행렬이고 \(\mathbf{b}\)는 m 벡터, 목적 함수인 n 벡터 \(\mathbf{c}\), 그리고 목표인 g(최대화 문제에서 예산에 해당)가 주어지고, \(\mathbf{Ax} \leq \mathbf{b}\)이고 \(\mathbf{c} \cdot \mathbf{x} \geq g\)인 음이 아닌 정수 벡터 \(\mathbf{x}\)를 찾는 문제가 됩니다.
그러나 여기에는 불필요한 조건이 들어있습니다. 마지막 제약 조건인 \(\mathbf{c} \cdot \mathbf{x} \geq g\) 자체는 선형 부등식이며 따라서 \(\mathbf{Ax} \leq \mathbf{b}\)에 흡수될 수 있습니다. 따라서 ILP 문제를 다음과 같은 탐색 문제로 정의합니다.
\(\mathbf{A}\)와 \(\mathbf{b}\)가 주어질 때, 부등식 \(\mathbf{Ax} \leq \mathbf{b}\)를 만족하는 음이 아닌 정수 벡터 \(\mathbf{x}\)를 찾거나 존재하지 않음을 보여라.
이 문제의 실용 분야는 매우 많아서 수많은 과학자들이 이 문제를 풀려고 노력했지만, 아직까지 효율적인 알고리즘은 발견하지 못했습니다.
ILP의 일종이면서 풀리지 않는 문제가 있는데, 이 문제는 \(\mathbf{Ax} = 1\)을 만족하는 0과 1로만 구성된 벡터 \(\mathbf{x}\)를 찾는 것입니다. 여기서 \(\mathbf{A}\)는 0과 1로만 구성된 m x n 행렬이고 1은 모든 항이 1인 m 벡터입니다. Reduction(치환)에 의하여 이는 실제로 일종의 ILP라는 것이 명백합니다. 이 문제는 ZOE(ZERO-ONE Equation)이라고 부릅니다.
지금까지 몇 가지 중요한 탐색 문제들을 살펴봤습니다. 어떤 문제는 효율적인 알고리즘이 이미 발견된 쉬운 문제들이고 또 다른 어떤 문제는 이런 쉬운 문제들과 비슷하지만 차이점이 그 문제를 매우 어렵게 만드는 어려운 문제들이었습니다. 아래에서는 어려운 문제들을 몇 가지 더 소개하는데, 이 문제들은 이러한 모든 문제들간의 계산적 난이도 관계를 설정할 때 필요한 것들입니다. 아래의 NP-Complete에 대한 내용을 먼저 보고 아래 문제들을 살펴봐도 무관합니다.
Three-dimensional matching
이분 그래프 매칭(Bipartite Matching) 문제는 양 쪽에 n개의 노드들이 있는 이분 그래프가 주어질 때, n개의 분리된 간선들의 집합을 찾거나 그러한 집합이 존재하지 않는다는 것을 찾는 것입니다. 이 문제는 최대 유량 문제로 치환하여 이 문제를 효율적으로 해결할 수 있습니다.
(아래 포스팅에서 이분 매칭 문제에 대해 설명하는데, 필요하다면 참조바랍니다 !)
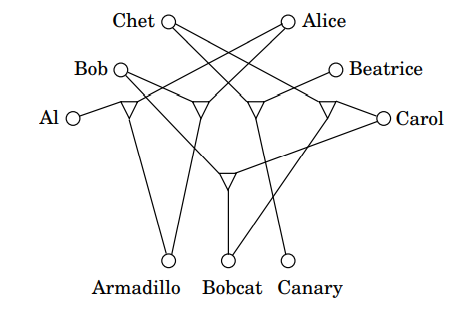
그러나 이분 매칭을 조금 일반화한 3D 매칭 문제가 있는데, 이 문제는 다항식 알고리즘이 아직 발견되지 않은 어려운 문제입니다. 이 문제의 예로는 n명의 소년, n명의 소녀, n마리의 애완동물이 주어지며, 각각 소년, 소녀, 애완동물을 (Triple)매칭시켜야 합니다. 문제의 목적은 n개의 분리된 트리플 매칭을 찾는 것입니다.
아래 그림에서 그러한 답을 찾을 수 있을까요?
Independent Set, Vertex Cover, and Clique
독립 집합(Independent Set) 문제는 그래프와 정수 g가 주어졌을 때, 서로 독립적인, 즉 간선으로 직접 연결되지 않은 g개의 정점을 찾는 문제입니다.
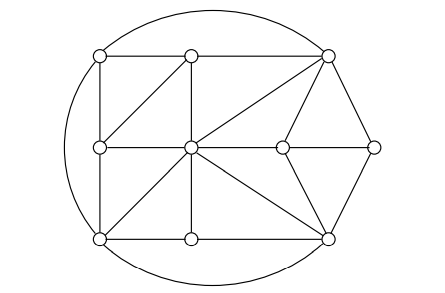
위 그림에서 3개의 정점으로 구성된 독립집합을 찾을 수 있을까요? 4개의 정점으로 구선된 독립집합도 찾을 수 있을까요? 만약 주어진 그래프가 트리라면 이러한 문제는 효율적으로 해결될 수 있으나 일반적인 그래프에서 이 문제를 푸는 것은 아직 다항식 알고리즘이 발견되지 않은 어려운 문제입니다.
이외에도 그래프에 관한 탐색 문제가 많이 존재합니다. 예를 들어, 정점 커버(Vertex Cover) 문제는 그래프와 예산 b가 주어질 때, 모든 간선을 덮는(접촉)하는 b개의 정점을 찾는 문제입니다. 위의 그래프에서 7개의 정점으로 모든 간선을 덮을 수 있을까요? 6개의 정점으로도 가능할까요?
정점 커버 문제는 집합 커버 문제의 특수한 경우입니다. 집합 커버 문제에서는 임의의 집합 E, E의 부분집합 \(S_1, \cdots, S_m\), 그리고 예산 b가 주어집니다. 문제의 목적은 합집합이 E인 b개의 부분집합들을 선택하는 것입니다.
정점 커버 문제는 그래프의 간선들의 집합을 E로 하고, 부분집합의 수는 정점의 수로 하며 각 정점마다 그 정점을 끝점으로 하는 간선들의 집합을 E의 부분집합 \(S_i\)로 하면 정점 커버 문제가 집합 커버 문제로 치환되기 때문에 정점 커버 문제는 집합 커버 문제의 특수한 경우입니다. 3D 매칭 또한 집합 커버 문제의 특수한 형태입니다.
그래프의 또 다른 탐색 문제로 클릭(Clique) 문제가 있습니다. 이 문제는 그래프와 목표 g가 주어질 때, 정점의 개수가 g인 완전 그래프(모든 정점이 연결된)인 부분 그래프를 찾는 문제입니다. 위의 그래프에서 최대 클릭은 무엇일까요?
Longest Path
최단 경로 문제는 효율적으로 해결될 수 있음을 이미 알고 있습니다. 그렇다면 최장 경로(Longest Path) 문제는 어떨까요? 이 문제에서는 음이 아닌 가중치의 간선들을 갖는 그래프 G와 두 개의 정점(s, t), 그리고 목적 g가 주어집니다. 문제의 목적은 s에서 t로 가는 무게의 총합이 g 이상인 경로를 찾는 것입니다. 당연히 답으로 찾는 경로에는 반복되는 정점이 있어서는 안됩니다. 즉, simple path이어야 합니다.
이 문제에 대한 효율적인 알고리즘은 아직 발견되지 않았습니다.
Knapsack and Subset Sum
[DP] Knapsack Problem (0-1 Knapsack)
배낭 문제를 한 번 생각해봅시다. 배낭 문제에서는 n개의 물건 각각에 대한 무게 \(w_1, \cdots, w_n\)(모두 정수)와 가치 \(v_1, \cdots, v_n\)(모두 정수), 그리고 배낭의 용량 W와 목적 g가 주어집니다. 여기에서 g는 원래 배낭 문제에는 없는 변수인데 탐색 버전으로 변환시키기 위해 추가된 것입니다. 문제의 목적은 무게의 합이 W 이하이고, 가치의 합이 g 이상인 물건들의 집합을 찾는 것입니다. 지금까지 모든 문제들이 그랬던 것처럼 이러한 집합이 존재하지 않으면 존재하지 않는다고 말해주어야 합니다.
위 포스팅에서는 실행 시간이 O(nW)인 DP 알고리즘을 살펴봤었습니다. O(nW)에는 logW가 아닌 W 이므로 O(nW)는 입력 크기에 대해 지수적입니다. 물론 \(2^n\)가지의 모든 경우를 조사하는 전수 탐색 방법도 있습니다. 그렇다면 배낭 문제를 푸는 다항 시간 복잡도의 알고리즘도 존재할까요? 아직까지는 그러한 방법을 발견한 사람은 아무도 없습니다.
그러나 정수가 1진수(예를 들어, 12는 IIIIIIIIIIII로 쓰임)로 표현되는 배낭 문제가 있다고 가정해봅시다. 물론 1진수 표현은 비경제적이기는 하지만 문제가 될 것은 없는 문제이며, 이러한 문제를 Unary Knapsack(1진수 배낭) 문제라고 부릅니다. 이 문제를 푸는 다항식 알고리즘은 이미 발견되었습니다.
또 다른 변형으로 각 항목의 가치와 무게가 모두 같으면서 2진수로 제공되고, 목표인 g가 배낭의 용량 W와 같다고 가정해봅시다. 이 특별한 경우는 주어진 정수 집합에서 합이 W인 부분집합을 찾는 문제와 같습니다. 이 문제는 배낭 문제의 특수한 경우이므로 배낭 문제보다 더 어려울 수는 없습니다. 그렇다면 다항식 해가 존재하는 문제일까요? 지금까지 밝혀진 바로는 부분집합의 합(Subset Sum)이라고 일컬어지는 이 문제도 다항식 해가 발견되지 않은 어려운 문제입니다.
이 시점에서 우리는 질문을 하나 할 수 있습니다.
부분집합의 합(Subset Sum) 문제가 배낭 문제의 특수한 경우라면, 왜 이 문제에 관심을 가질까요?
그 이유는 단순함 때문입니다. 이번 포스팅과 다음 포스팅에 다룰 탐색 문제들간의 치환(reduction)에서 부분집합의 합이나 3SAT와 같이 개념적으로 간단한 문제들은 매우 중요한 역할을 합니다.
NP-Complete Problems
Hard problems, easy problems
요컨대, 세상은 탐색 문제로 가득 차 있으며, 그중 일부는 효율적으로 해결할 수 있는데 반해 다른 일부는 매우 어려워 보입니다. 다음 표에는 이러한 문제들을 보여주고 있습니다.
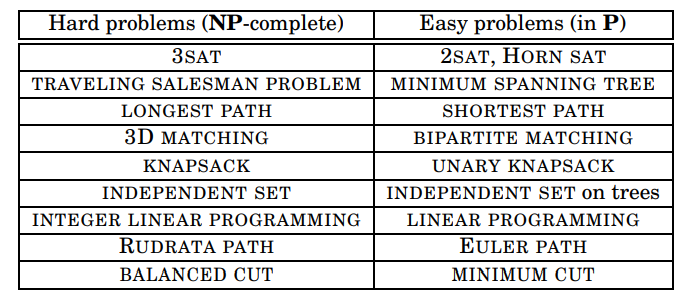
이 표를 생각해 볼만한 가치가 있습니다. 오른쪽에는 효율적으로 해결할 수 있는 문제들이 있으며, 왼쪽에는 수십 년 또는 수백 년 동안 효율적인 알고리즘을 찾지 못한 문제들이 나열되어 있습니다.
오른쪽 열의 문제들은 DP, Network flow, Graph Search, Greedy 등의 특화되고 다양한 알고리즘들로 해결할 수 있습니다. 이러한 문제들은 다양한 이유들로 인해 쉽습니다.
반면, 왼쪽의 문제들은 똑같은 이유로 모두 어렵습니다. 이 문제들의 핵심에서, 이 문제들은 단지 다른 변장을 하고 있을 뿐, 모두 같은 문제입니다. 이 문제들은 모두 동일하며, 다음 포스팅에서 살펴보겠지만 이 문제들은 각각 다른 문제들로 치환될 수 있습니다.
P and NP
이제 이 포스팅을 작성하는 이유인 핵심 개념들을 소개해보도록 하겠습니다. 위에서 탐색 문제(search problem)이 무엇인지는 이미 소개한 바 있습니다. 탐색 문제가 되기 위한 특징은 제안된 답이 맞는지 틀리는지 신속한 검사가 가능해야 합니다. 즉, 주어진 사례 I(the data specifying the problem to be solved)와 제안된 해 S를 입력으로 받아 S가 정말 I의 해라면 true 아니면 false를 출력하는 효율적인 검사 알고리즘 C가 있어야 합니다. 또한, C(I, S)의 실행 시간이 주어진 사례의 길이 \(|I|\)에 대한 다항식보다 크지 않아야 합니다. 모든 탐색 문제들의 집합을 비결정 다항식 문제(Nondeterministic Polynomial, 이하 NP)라고 합니다.
아마도 다항식 시간 내에 풀리는 많은 NP 탐색 문제들을 접해보았을 것입니다. 그러한 경우에는 문제의 사례 I를 입력으로 사용하고, 실행 시간이 \(|I|\)에 대한 다항식인 알고리즘이 존재합니다. 만약 I에 솔루션이 있다면 알고리즘은 해당 솔루션을 반환하고, I에 솔루션이 없다면 알고리즘은 솔루션이 없다고 알려줍니다. 다항식 시간에 풀 수 있는 모든 탐색 문제들의 집합을 다항식 문제(Polynomical, 이하 P)라고 합니다. 위의 그래프에서 오른쪽 열에 위치하는 모든 탐색 문제들은 P에 속합니다.
다항식 시간 내에 풀리지 않는 탐색 문제가 존재할까요? 다시 말하면, \(P \neq NP\) 일까요?
대부분의 알고리즘 리서처들은 그럴 것이라고 생각합니다. 지수 시간 복잡도의 탐색을 언제나 피할 수 있는 것이라고 믿는 것이나 수백 년 동안 풀리지 않는 이러한 어려운 모든 문제들을 다 해결할 수 있는 간단한 방법이 있으리라고 믿는 것은 어렵습니다. 또한 수학자들이 \(P \neq NP\)라고 믿는 또 다른 타당한 이유가 있습니다. 이 수학적 주장에 대한 증명을 찾는 작업 또한 탐색 문제이므로, 이 또한 NP라는 것입니다. 따라서 \(P = NP\)이면 모든 정리를 증명하는 효율적인 방법이 존재하는 것이 되며, 따라서 수학자들의 존재 이유가 없어지게 되는 것입니다. 이와 같이, \(P \neq NP\)라고 믿는 다양한 이유들이 있습니다. 그러나 이것을 증명하는 것은 극도로 어려운 문제로 판명되었으며, 수학 분야의 가장 관심이 높고 가장 중요한 미해결 문제들 중의 하나입니다.
Reductions (치환)
비록 \(P \neq NP\)라는 것을 받아들인다하더라도 위의 표에서 왼쪽 열에 있는 특정 문제들에 대해서는 어떨까요 ? 즉, 어떤 증거를 바탕으로 특정 문제들에 대하여 효율적인 알고리즘이 존재하지 않는다고 할 수 있을까요(수많은 수학자들과 컴퓨터 과학자들이 열심히 시도했지만 실패했다는 사실을 제외하고)? 이러한 증거는 하나의 탐색 문제를 다른 탐색 문제로 변환하는 치환에 의해 제공됩니다. 치환이 보여주는 것은 표의 왼쪽 열에 있는 문제들이 모두 서로 다른 단어로 표현되었을 뿐 어떤 의미에서는 모두 똑같은 문제라는 것입니다. 더 나아가 우리는 이러한 문제가 NP에서 가장 어려운 탐색 문제라는 것을 보여주기 위해 치환을 사용할 것입니다. 그중 하나라도 다항 시간 알고리즘을 가지고 있다면 NP의 모든 문제는 다항시간의 알고리즘으로 풀린다는 것을 보여줍니다. 따라서 \(P \neq NP\)라고 믿는다면, 이러한 모든 탐색 문제는 어려운 문제가 되는 것입니다.
선형 계획법과 치환 (1) - Examples of LP
선형 계획법과 치환 (2) - Network Flow, Bipartite Matching
이전 포스팅에서 치환을 정의하였고, 치환의 많은 예들을 살펴봤습니다. 이제 탐색 문제에 국한하여 치환을 재정의해보도록 하겠습니다.
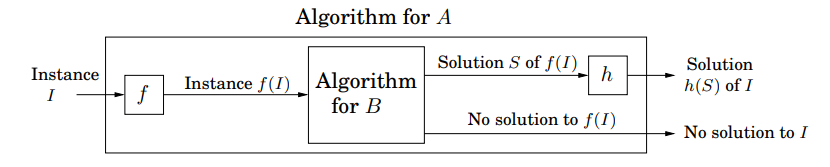
탐색 문제 A를 다른 탐색 문제 B로 치환한다는 것은 A의 사례 I를 B의 사례인 f(I)로 변환하는 다항식 시간 복잡도의 알고리즘 f와, f(I)의 해 S를 I의 해 h(S)로 변환하는 다항식 시간 복잡도의 알고리즘 h를 제공하는 것입니다. 이해를 위해 아래 그림을 참조바랍니다 !
이제 가장 어려운 탐색 문제의 집합을 정의할 수 있습니다.
어떤 탐색 문제는 모든 다른 탐색 문제들이 그 문제로 치환될 수 있으면 비결정 완전(NP-Complete)이라고 한다.
이는 매우 강력한 필요조건(requirement)입니다. 즉, 어떤 문제가 NP-Complete가 되려면, 세상의 모든 탐색 문제를 푸는데 유용해야 합니다. 그러한 문제가 존재한다는 것은 놀랄만한 것입니다. 그러나 이러한 문제는 존재하고, 앞에서 본 표의 왼쪽에 보이는 문제들이 모든 그러한 문제들의 유명한 예시들입니다. 다음 포스팅에서는 이러한 문제들이 어떻게 서로 치환되는지, 그리고 다른 모든 탐색 문제들이 어떻게 이 문제들로 치환되는지 살펴볼 것입니다.
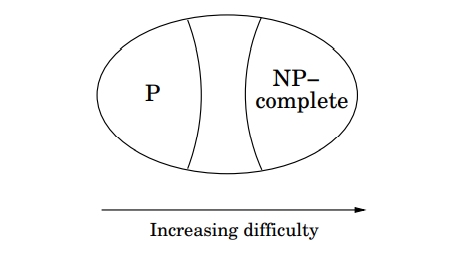
치환을 사용하는 두 가지 방법
일반적으로 문제 A에서 문제 B로 치환하는 목적은 명확했습니다. 즉, 해결 방법을 알고 있는 문제 B로 문제 A를 치환하여 문제 B의 해결 방법으로 문제 A를 해결하는 것입니다. 그러나 이번 포스팅과 다음 포스팅에서 살펴보는 치환은 이러한 목적이 아닙니다. 여기서는 문제 A가 어려운 문제라는 사실을 알고 있을 때, 치환으로 문제 B도 어렵다는 것을 증명하는 것이 목적입니다.
문제 A에서 B로의 치환을 다음과 같이 표기한다면,
\[A \rightarrow B\]
어려움(difficulty)은 화살표 방향으로 흐르고 효율적인 알고리즘은 반대 방향으로 흐른다고 말할 수 있습니다. 이러한 어려움의 전파를 통해 NP-Complete 문제가 어렵다는 것을 알 수 있습니다. 다른 모든 탐색 문제는 그 문제로 치환되고, 따라서 NP-Complete 문제는 모든 탐색 문제의 복잡성을 포함합니다. 만약 NP-Complete 문제들 중 단 하나만이라도 P에 속한다면 \(P = NP\) 입니다.
치환은 다음과 같은 조합의 성질을 갖습니다.
\[\text{If }A \rightarrow B \text{ and } B \rightarrow \text{, then } A \rightarrow C\]
이 성질을 증명하기 위해 우선 치환은 전처리 함수 f와 후처리 함수 h로 정의된다는 사실을 고려합니다. 만약 (\((f_{AB}, h_{AB})\)와 \((f_{BC}, h_{BC})\)가 각각 A에서 B, B에서 C로의 치환을 정의한다면, A에서 C로의 치환은 이들 두 함수의 조합으로 구할 수 있습니다.
이것은 문제 A가 NP-Complete라는 것을 알면, A를 B로 치환함으로써 새로운 탐색 문제 B도 NP-Complete라는 것을 증명할 수 있다는 것을 의미합니다. 이 사실만 밝히면 모든 NP 문제들이 A를 통해 B로 치환될 수 있음을 보여줍니다.
Factoring (소인수분해)
마지막으로 논의할 문제는 어려운 탐색 문제로 잘 알려진 소인수분해(factoring)입니다. 이 문제는 주어진 정수의 모든 소수를 분해해 내는 것입니다. 그러나 소인수분해의 어려움은 우리가 지금까지 보았던 다른 어려운 탐색 문제들과는 본질이 다릅니다. 예를 들어, 소인수분해가 NP-Complete라고 믿는 사람은 아무도 없습니다. 한 가지 주요한 차이점은 소인수분해의 경우에는 문제의 정의에 "존재하지 않으면 존재하지 않는다고 답하시오"라는 절이 들어 있지 않습니다. 왜냐면 모든 정수는 소수로 분해될 수 있기 때문입니다. 또 다른 점(무관할 수도 있음)은 소인수분해는 양자 계산(quantum computation)으로 다항식 시간 내에 풀 수 있다는 것이 밝혀졌지만, SAT, TSP 등 다른 NP-Complete 문제들은 아직 그렇다고 밝혀지지 않았습니다.
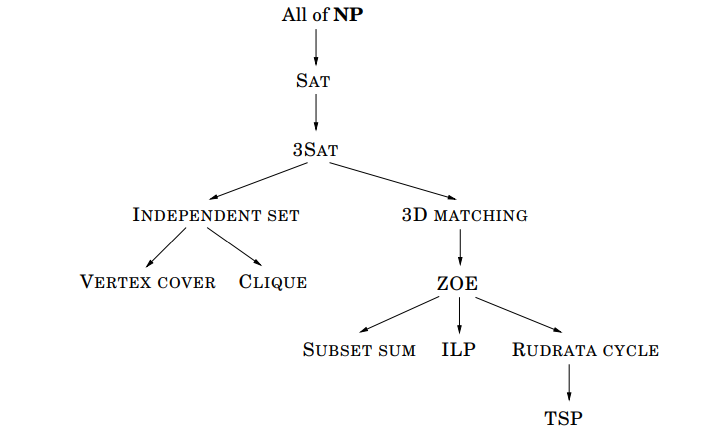
다음 포스팅에서는 위에서 살펴봤던 탐색 문제들이 아래 그림에서 보여주는 것처럼 서로 치환될 수 있다는 것에 대해 살펴보도록 하겠습니다.
'Data Structure & Algorithm > 알고리즘' 카테고리의 다른 글
| 2-SAT (1) | 2022.04.28 |
|---|---|
| NP-Complete Problems (2) (0) | 2022.04.25 |
| 강한 연결 요소 (Strongly Connected Component) (0) | 2022.04.22 |
| 이분 매칭 (Bipartite Matching) (0) | 2022.04.21 |
| 포드 풀커슨 / 에드몬드 카프 알고리즘 (0) | 2022.04.20 |




댓글