References
- 확률과 통계 강의 1강 (KOWC - 한양대학교 이상화 교수님)
- Fundamentals of Applied Probability and Random Processs (Oliver Ibe)
Contents
- Conditional Probability
- Total Probability
- Bayes' Theorem
기본 확률 개념
References 확률과 통계 강의 (KOWC - 한양대학교 이상화 교수님) Fundamentals of Applied Probability and Random Processs (Oliver Ibe) Contents Sample Space and Events Definitions of Probability Set The..
junstar92.tistory.com
지난 강의에서 Sample Space(표본 공간)와 Events(사건)의 정의에 대해 알아봤습니다. Sample Space은 무작위 실험이 수행될 때 가능한 모든 결과의 모음으로써, 집합(set)으로 표현됩니다. 아래에서는 이 공간을 \(S\)로 표현하도록 하겠습니다. 그리고 Events(사건)은 \(S\)의 부분 집합입니다(\(A \subset S\)).
이때, \(P(A)\)는 A가 발생할 확률을 의미하고, 정확한 표현은 \(\text{prob}(\text{outcome } \in A)\)로 표현할 수 있습니다.
Conditional Probability
이번 포스팅에서 살펴볼 조건부 확률(conditional probability)은 말 그대로 조건이 있는 확률입니다. 조건부 확률은 다음과 같이 표현합니다.
\[P(B|A)\]
\(B|A\)에서 오른쪽에 있는 A가 바로 조건입니다. 따라서, \(P(B|A)\)는 A라는 조건이 있을 때, B가 발생할 확률을 의미합니다. 잘 알다시피, 조건부 확률은 아래의 식으로 변환될 수 있습니다.
\[P(B|A) = \frac{P(B \cap A)}{P(A)}\]
위 식을 잘 살펴보면, 분자에 해당되는 \(P(B \cap A)\)는 A라는 사건과 B라는 사건의 교집합이므로, A라는 사건과 B라는 사건이 동시에 발생할 확률입니다. 분모는 그대로 A에 해당하는 사건의 확률입니다. 의미를 잘 살펴보면, A라는 사건이 발생했을 때, B가 발생할 확률이므로 A라는 사건이 새로운 Sample Space가 되는 것과 동일한 의미입니다.
엄밀히 따지면 위 식은 다음과 같이 작성할 수 있습니다.
\[\frac{P(B \cap A)}{P(A)} = \frac{P(B \cap A | S)}{P(A|S)}\]
즉, 분자에 해당하는 것은 S(전체 표본 공간)라는 조건에서 A와 B 사건이 동시에 발생할 확률이며, 분모는 S라는 조건에서 A라는 사건이 발생할 확률입니다. 따라서, 기본적으로 전체 표본 공간이라는 조건이 항상 따라다니는데 전체 표본 공간 S는 생략하여 적지 않는 것 뿐입니다.
Total Probability
Total Probability(전체 확률)의 법칙은 집합 \(S\)의 파티션(partition)을 \(\{A_1, A_2, \cdots, A_n\}\)이라고 하고, 각 사건들이 서로 배반 사건(mutually exlusive)일 때, 다음의 식을 만족한다는 것입니다.
\[P(A) = P(A_1) + P(A_2) + \cdots + P(A_n)\]
이때, \(\{A_1, A_2, \cdots, A_n\}\)은 전체 집합 S의 파티션(partition)이라고 했습니다. 여기서 파티션 조건에 의해서.
\[P(A_1) = P(A_1 \cap A)\]
로 표현할 수 있습니다.
여기서 오른쪽 항에 조건부 확률 정의를 사용하여 다시 표현하면,
\[P(A_1 \cap A) = P(A|A_1)P(A_1)\]
로 표현할 수 있습니다.
위 식을 모든 배반 사건들(\(A_1, A_2, \cdots\))에 적용하면, Total Probability는 아래와 같이 다시 작성할 수 있습니다.
\[P(A) = \sum_{i=1}^{n}P(A|A_i)P(A_i)\]
일반적으로 \(P(A|A_i)\)와 같은 확률은 실험 등을 통해서 이미 알고 있는 확률이며, 이를 사전 확률(prior probability or prior)이라고 합니다. 그리고 이를 이용하여 A와 관련된 문제들을 풀어내는 것이 Total Probability의 목적입니다.
Bayes' Theorem
베이즈 정리(bayes' theorem)는 주로 Total Probability에서 언급한 사전 확률 \(P(A|A_i)\)에서 조건이 바뀐 \(P(A_i|A)\)를 구할 때 자주 사용됩니다. 정의는 다음과 같습니다.
\[P(B|A) = \frac{P(B \cap A)}{P(A)} = \frac{P(A|B)P(B)}{P(A)}\]
\(P(A|B) = \frac{P(A \cap B)}{P(B)}\)이기 때문에, 이를 이용하여 위 식의 두 번째 항의 분자를 변형하여 세 번째 항이 유도되었습니다.
위의 공식에서 \(P(A|B)\)는 사전 확률(prior probability)로 주어져 있으며, \(P(B)\)도 알 수 있는 상황이며 분모 \(P(A)\)는 Total Probability를 통해 구할 수 있습니다.
파티션(partition)에 다시 적용하여, \(P(A_i|A)\)를 구할 때 베이즈 정리를 사용할 수 있습니다. 즉, 어떤 A라는 사건이 발생했을 때, A라는 전체 집합 중에서 특별한 사건 \(A_i\)가 발생할 확률을 구하라는 문제입니다.
각각의 경우의 수를 구하는 문제가 아니기 때문에 베이즈 정리를 사용하여 사전에 알려진 확률들의 식으로 변형하여 해당 확률을 구할 수 있습니다.
\[P(A_i|A) = \frac{P(A|A_i)P(A_i)}{P(A)}\]
분자에 해당하는 부분은 어떤 파티션으로부터 \(A\)에 대한 사전 조건, 즉, Prior Probability가 주어져있다고 가정하고 구할 수 있고, 분모는 Total Probility를 통해 구할 수 있습니다.
이처럼 조건들의 위치를 바꾸어서 문제를 푸는 수학적인 방법을 베이즈 정리라고 합니다.
주로 베이즈 정리는 다음과 같은 상황에서 사용됩니다.
\(P(A_i|A)\)에서 조건인 A를 observation data, 즉, 우리가 이미 관측한 데이터라고 할 때, 이 데이터가 어디에서부터 왔는지에 대한 가능성을 알아볼 때 사용합니다. 관측 데이터를 output이라고 생각하면 \(A_i\)는 우리가 현재 알지 못하는 original data(input)이라고 볼 수 있습니다.
따라서, \(A\)라는 결과가 나왔을 때, 이 결과가 \(A_i\)로부터 오게 된 것인지 아닌지 가능성을 찾는 것이라고 정리할 수 있습니다.
Example: Binary Symmetric Channel
예제를 통해서 조금 더 살펴보겠습니다.
이 예제에서는 binary로 표현되는 시그널을 전달하는 통신 시스템을 예로 들고 있습니다. 디지털에서는 0과 1로 표현할 수 있지만, 여기서는 input과 output을 구분할 수 있도록 input을 \(x_1, x_2\)으로, output은 \(y_1, y_2\)로 표현하도록 하겠습니다. 디지털로 생각하면 \(x_1\)과 \(y_1\)은 0, \(x_2\)와 \(y_2\)는 1로 생각할 수 있습니다.
이를 그림으로 표현하면 다음과 같습니다.
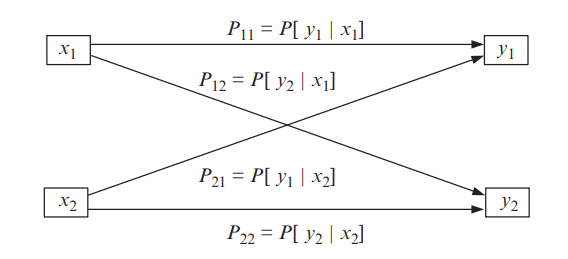
\(P_{11}\)은 송신측에서 0을 보냈을 때, 수신측에서 0을 받을 확률을 의미하며 \(P_{22}\)는 송신측에서 1을 보냈을 때, 수신측에서 1을 받을 확률을 의미합니다. 여기서 \(P_{11} = P_{22} = 1\)이라면, 아무런 문제가 없습니다. 하지만, 신호를 전달할 때, 노이즈나 다른 영향으로 인해 에러가 발생하게 되고, 송신측에서 0으로 보냈다고 했지만 수신측에서는 1이 도착할 수도 있게 됩니다. 이 때의 확률을 \(P_{12}\)로 표현합니다. 반대로 송신측에서 1을 보냈지만 수신측에서 0을 받을 확률은 \(P_{21}\)로 표현하고 있습니다.
이때, \(P_{11} = P_{22}, P_{12} = P_{21}\)을 만족할 때, 이를 Symmetric하다고 합니다.
여기서 베이즈에 대한 이야기를 해보자면, input \(x_1, x_2\)가 original data가 되고 output \(y_1, y_2\)는 observation data가 됩니다.
먼저 그림에서 표현하는 각각의 확률들에 대해 살펴볼텐데, 결론부터 이야기하면 이 확률들이 바로 조건부 확률이 됩니다.
송신측에서 \(x_1\), 즉, 0을 계속 보내고, 수신측에서는 0을 보내는 것을 알고 있으면서 어떤 것이 도착하는지 살펴봅니다. 만약 수신측에서 받은 신호가 모두 0이라면 \(P_{11}\)이 1이 되겠지만, 에러가 발생할 때가 있을 것입니다. 이를 relative frequency처럼 경험적으로 실제로 측정합니다. \(P_{11}\)은 0을 보냈을 때 0을 받을 확률이며, 이를 수학적으로 표현하면 다음과 같습니다.
\[P_{11} = P(y_1 | x_1)\]
나머지 확률들에 대해서도 수학적으로 표현하면 다음과 같습니다.
\[\begin{align*} P_{22} = P(y_2 | x_2) \\ P_{12} = P(y_2|x_1) \\ P_{21} = P(y_1|x_2) \end{align*}\]
그리고, 송신측에서 \(x_1\)을 보냈을 때, 수신측에서는 \(y_1\)이나 \(y_2\) 중 하나를 받게 되므로, \(P_{11} + P_{12}\)는 1이 됩니다. 마찬가지로 \(P_{21} + P_{22}\)도 1이 됩니다.
(모든 Sample Space의 확률을 더하면 1이 되기 때문입니다.)
\(P_{11}, P_{12}, P_{21}, P_{22}\)와 같은 확률들은 실험적으로 사전에 구할 수 있으며, \(P(x_1)\)이나 \(P(x_2)\)도 마찬가지로 실험을 통해서 구할 수 있는 사전 확률이 됩니다.
이를 이용해서 여러 문제들을 풀 수 있는데, 아래의 문제들을 하나씩 살펴보도록 하겠습니다.
- \(P_{\text{error}}\)
에러가 발생하는 경우는 0(\(x_1\))을 보냈는데 1(\(y_2\))을 받는 경우와 1(\(x_2\))을 보냈는데 0(\(y_1\))을 받는 경우에 해당합니다. 따라서, 에러가 발생할 확률은 다음과 같습니다.
\[\begin{align*} P_{\text{error}} &= \text{Prob}(x_1 \text{ trans}, y_2 \text{ receive}) + \text{Prob}(x_2 \text{ trans}, y_1 \text{ receive}) \\ &= P(y_2|x_1)P(x_1) + P(y_1|x_2)P(x_2) \end{align*}\]
여기서 구한 확률은 조건에 상관없이 에러가 발생할 확률인데, 이를 unconditional error라고 합니다.
- \(y_2\)를 수신했을 때, 송신측에서 \(x_1\)을 보냈을 확률 \(P(x_1|y_2)\)
다시 이를 베이지안 측면에서 이야기해보면, 여기서 조건인 \(y_2\)는 우리가 실제로 받은 데이터이므로 observation data에 해당합니다. 이때, 우리가 받은 관측 데이터로부터 original 데이터가 무엇인지 확률적으로 가능성을 계산해보는 것이 이 문제의 핵심입니다. 그리고 이는 베이즈 정리를 통해 계산할 수 있습니다.
\[P(x_1|y_2) = \frac{P(y_2|x_1)P(x_1)}{P(y_2)}\]
\(P(x_1|y_2)\)를 직접 구할 수는 없지만, 베이즈 정리에 의해서 변형한 오른쪽 항에서 나타나는 확률들은 모두 사전에 주어지는 것들이기 때문에 사전 확률들을 이용하여 \(P(x_1|y_2)\)를 구할 수 있습니다.
분자는 그 자체로 \(x_1\)을 보냈을 때, \(y_2\)를 받는 확률을 의미하는 것이고, 분모는 수신측에서 \(y_2\)를 받는 확률입니다. 이때, \(y_2\)를 받는 확률에는 \(x_1\)을 전송했는데 \(y_2\)를 받는 확률과 \(x_2\)를 전송했는데 \(y_2\)를 받는 확률이 있을 것입니다. 이 두 가지가 \(y_2\)를 받는 모든 확률이 되고, 두 확률은 중복되지 않는 배반(mutually exclusive) 사건입니다.
\[P(x_1|y_2) = \frac{P(y_2|x_1)P(x_1)}{P(y_2)} = \frac{P(y_2|x_1)P(x_1)}{P(y_2|x_1)P(x_1) + P(y_2|x_2)P(x_2)}\]
식을 살펴보면, 분모는 Total Probability에 해당합니다. 그리고, 분모의 두 항 중 하나가 분자인 것을 확인할 수 있습니다.
이처럼 베이즈 정리와 Total Probability를 변환하여 여러 변형 문제들을 풀 수 있습니다.
- \(P(x_1 | \text{error})\)
이 확률은 에러가 발생했을 때, 송신측에서 \(x_1\)을 보냈을 확률을 구하는 것입니다. 당연히 분모는 위에서 구한 \(P_{\text{error}}\)가 될 것이고, 분자는 \(P_{\text{error}}\)의 항 중 하나가 될 것입니다.
\[P(x_1 | \text{error}) = \frac{P(\text{error}|x_1)P(x_1)}{P(\text{error})} = \frac{P(y_2|x_1)P(x_1)}{P(y_2|x_1)P(x_1) + P(y_1|x_2)P(x_2)}\]
'ML & DL > 확률과 통계' 카테고리의 다른 글
| 확률 분포 (Probability Distribution) (0) | 2022.05.30 |
|---|---|
| 확률 변수의 평균과 분산 (0) | 2022.05.28 |
| 확률 변수 (Random Variables) (0) | 2022.05.26 |
| 독립 사건과 순열 및 조합 (0) | 2022.05.24 |
| 기본 확률 개념 (0) | 2022.05.20 |




댓글