References
- Professional CUDA C Programming
Contents
- Reducing Global Memory Access
- Parallel Reduction with Shared Memory
- Parallel Reduction with Unrolling
- Parallel Reduction with Dynamic Shared Memory
- Effective Bandwidth
지난 두 포스팅에 이어서 Global Memory Access를 줄이기 위해 Shared Memory를 사용하는 것에 대해 알아보도록 하겠습니다.
Shared Memory (2) - Square/Rectangular Shared Memory
Reducing Global Memory Access
Shared Memory를 사용하는 중요한 이유 중의 하나는 data를 on-chip에 캐시하기 위해서 입니다. 이를 통해 커널에서 global memory에 액세스하는 횟수를 감소시킬 수 있습니다.
Warp의 Branch Divergence (reduction problem)
Warp의 Branch Divergence (reduction problem)
References Professional CUDA C Programming Contents Parallel Reduction Neighbored vs Interleaved Approach Unrolling Loops Use template parameter in device functions (템플릿 파라미터 사용) Divergent..
junstar92.tistory.com
위의 포스트에서 Global Memory를 사용한 parallel reduction 커널들을 아래의 두 가지 관점에서 살펴봤습니다.
- How to avoid warp divergence by rearranging data access patterns
- How to unroll loops to keep sufficient operations in flight to saturate instruction and memory bandwidth
이번 포스팅에서는 global memory의 액세스를 줄이기 위해 program-managed cache로써 shraed memory를 사용하여 reduction kernel의 성능을 더욱 향상시키는 방법에 대해서 알아보겠습니다.
이전에 구현한 reduction kernel 함수들은 아래의 링크에서 확인하실 수 있습니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/reduction/reduceInteger.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
또한, 아래에서 사용될 모든 커널과 main 실행 함수는 아래 링크에서 확인하실 수 있습니다.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
Parallel Reduction with Shared Memory
먼저 앞으로 살펴볼 커널들과 성능 비교의 기준이 될 Global Memory를 사용하는 reduce 커널 reduceGmem을 먼저 살펴보겠습니다. 이 커널은 오직 global memory만을 사용하였고, 내부 for 루프를 unroll하였습니다.
__global__ void reduceGmem(int* g_iData, int* g_oData, unsigned int n) { // set thread ID unsigned int tid = threadIdx.x; // boundary check unsigned int idx = blockDim.x * blockIdx.x + threadIdx.x; if (idx >= n) return; // convert global data pointer to the local pointer of this block int* iData = g_iData + (blockDim.x * blockIdx.x); // in-place reduction in global memory if (blockDim.x >= 1024 && tid < 512) iData[tid] += iData[tid + 512]; __syncthreads(); if (blockDim.x >= 512 && tid < 256) iData[tid] += iData[tid + 256]; __syncthreads(); if (blockDim.x >= 256 && tid < 128) iData[tid] += iData[tid + 128]; __syncthreads(); if (blockDim.x >= 128 && tid < 64) iData[tid] += iData[tid + 64]; __syncthreads(); // unrolling warp if (tid < 32) { volatile int* vsmem = iData; vsmem[tid] += vsmem[tid + 32]; vsmem[tid] += vsmem[tid + 16]; vsmem[tid] += vsmem[tid + 8]; vsmem[tid] += vsmem[tid + 4]; vsmem[tid] += vsmem[tid + 2]; vsmem[tid] += vsmem[tid + 1]; } // write result for this block to global memory if (tid == 0) g_oData[blockIdx.x] = iData[0]; }
이 커널은 크게 4가지 과정으로 수행됩니다.
먼저 해당되는 스레드 블록에 할당되는 데이터의 첫 지점을 찾기 위해 global input에서의 offset을 계산합니다.
int* iData = g_iData + (blockDim.x * blockIdx.x);다음으로 32개의 원소가 남을 때까지 in-place reduction을 수행합니다.
// in-place reduction in global memory if (blockDim.x >= 1024 && tid < 512) iData[tid] += iData[tid + 512]; __syncthreads(); if (blockDim.x >= 512 && tid < 256) iData[tid] += iData[tid + 256]; __syncthreads(); if (blockDim.x >= 256 && tid < 128) iData[tid] += iData[tid + 128]; __syncthreads(); if (blockDim.x >= 128 && tid < 64) iData[tid] += iData[tid + 64]; __syncthreads();
그리고 나서는 각 스레드 블록의 첫 번째 warp만을 사용하여 나머지 reduction을 수행합니다. 여기서 volatile qualifier를 사용하여 warp가 수행될 때 오직 최신 값만 읽혀지도록 합니다.
// unrolling warp if (tid < 32) { volatile int* vsmem = iData; vsmem[tid] += vsmem[tid + 32]; vsmem[tid] += vsmem[tid + 16]; vsmem[tid] += vsmem[tid + 8]; vsmem[tid] += vsmem[tid + 4]; vsmem[tid] += vsmem[tid + 2]; vsmem[tid] += vsmem[tid + 1]; }
마지막으로 스레드 블록에 할당된 input data의 최종 부분합을 다시 global memory에 write합니다.
// write result for this block to global memory if (tid == 0) g_oData[blockIdx.x] = iData[0];
모든 테스트에서 입력의 크기는 16M으로 설정하며, 블록의 크기는 128 스레드로 설정합니다.
nvprof로 프로파일링한 위 커널의 base result는 다음과 같습니다.

이제 shared memory를 사용한 reduceSmem 커널을 사용하여 비교해보도록 하겠습니다. 이 커널은 reduceGmem 커널과 거의 동일합니다만, in-place reduction을 수행할 때 global memory가 아닌 shared memory인 smem 배열을 사용합니다. smem은 thread block과 동일한 크기로 선언됩니다. (DIM은 매크로로 128로 설정됩니다.)
__shared__ int smem[DIM];각 스레드 블록은 global input data에서 할당된 data를 smem으로 초기화합니다.
smem[tid] = iData[tid]; __syncthreads();
reduceSmem 커널은 다음과 같이 구현됩니다.
__global__ void reduceSmem(int* g_iData, int* g_oData, unsigned int n) { __shared__ int smem[DIM]; // set thread ID unsigned int tid = threadIdx.x; // boundary check unsigned int idx = blockDim.x * blockIdx.x + threadIdx.x; if (idx >= n) return; // convert global data pointer to the local pointer of this block int* iData = g_iData + (blockDim.x * blockIdx.x); // set to smem by each threads smem[tid] = iData[tid]; __syncthreads(); // in-place reduction in global memory if (blockDim.x >= 1024 && tid < 512) smem[tid] += smem[tid + 512]; __syncthreads(); if (blockDim.x >= 512 && tid < 256) smem[tid] += smem[tid + 256]; __syncthreads(); if (blockDim.x >= 256 && tid < 128) smem[tid] += smem[tid + 128]; __syncthreads(); if (blockDim.x >= 128 && tid < 64) smem[tid] += smem[tid + 64]; __syncthreads(); // unrolling warp if (tid < 32) { volatile int* vsmem = smem; vsmem[tid] += vsmem[tid + 32]; vsmem[tid] += vsmem[tid + 16]; vsmem[tid] += vsmem[tid + 8]; vsmem[tid] += vsmem[tid + 4]; vsmem[tid] += vsmem[tid + 2]; vsmem[tid] += vsmem[tid + 1]; } // write result for this block to global memory if (tid == 0) g_oData[blockIdx.x] = smem[0]; }
다시 nvprof를 통해 수행 시간을 측정해보도록 하겠습니다.

shared memory를 사용한 커널이 약 1.28배 가량 더 빠르게 측정되고 있습니다.
이번에는 nsight compute를 통해 global memory의 load/store transactions를 측정하여 global memory에 대한 액세스가 얼마나 감소했는지 확인해보겠습니다.
이는 다음의 metrics 플래그를 추가하여 측정할 수 있습니다.
ncu.bat --metrics l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum,l1tex__t_sectors_pipe_lsu_mem_global_op_st.sum ./reduceInteger.exe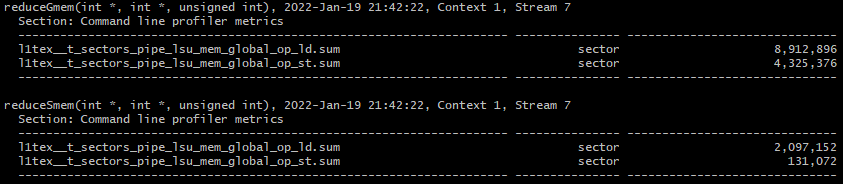
결과는 위와 같습니다. 명확하게 reduceGmem의 global memory 액세스가 reduceSmem에 비해서 많다는 것을 확인할 수 있습니다.
Parallel Reduction with Unrolling
위의 커널들에서 각 스레드 블록은 data의 한 블록을 처리합니다. 이전 포스팅에서 unrolled block을 사용하여 커널의 성능을 향상시키는 것에 대해서 알아봤는데, 이번에 살펴볼 커널도 unrolling 기법을 사용합니다.
살펴볼 커널은 4개의 블록을 unroll 합니다. 즉, 각 스레드 블록은 4개의 data 블록을 처리합니다. 이렇게 unrolling을 사용하면 다음의 이점들을 기대할 수 있습니다.
- 스레드 당 더 많은 병렬 I/O를 통해 global memory 처리량을 증가시킬 수 있음
- global memory store transaction을 1/4로 감소시킬 수 있음
- 전체 커널 성능 향상
Shared Memory와 unrolling 기법을 사용한 커널 함수 reduceSmemUnroll은 다음과 같습니다.
__global__ void reduceSmemUnroll(int* g_iData, int* g_oData, unsigned int n) { // static shared memory __shared__ int smem[DIM]; // set thread ID unsigned int tid = threadIdx.x; // global index, 4 blocks of input data processed at a time unsigned int idx = blockDim.x * blockIdx.x * 4 + threadIdx.x; // unrolling 4 blocks int tmpSum = 0; // boundary check if (idx + 3 * blockDim.x < n) { int a1 = g_iData[idx]; int a2 = g_iData[idx + blockDim.x]; int a3 = g_iData[idx + 2 * blockDim.x]; int a4 = g_iData[idx + 3 * blockDim.x]; tmpSum = a1 + a2 + a3 + a4; } smem[tid] = tmpSum; smem[tid] = tmpSum; __syncthreads(); // in-place reduction in global memory if (blockDim.x >= 1024 && tid < 512) smem[tid] += smem[tid + 512]; __syncthreads(); if (blockDim.x >= 512 && tid < 256) smem[tid] += smem[tid + 256]; __syncthreads(); if (blockDim.x >= 256 && tid < 128) smem[tid] += smem[tid + 128]; __syncthreads(); if (blockDim.x >= 128 && tid < 64) smem[tid] += smem[tid + 64]; __syncthreads(); // unrolling warp if (tid < 32) { volatile int* vsmem = smem; vsmem[tid] += vsmem[tid + 32]; vsmem[tid] += vsmem[tid + 16]; vsmem[tid] += vsmem[tid + 8]; vsmem[tid] += vsmem[tid + 4]; vsmem[tid] += vsmem[tid + 2]; vsmem[tid] += vsmem[tid + 1]; } // write result for this block to global memory if (tid == 0) g_oData[blockIdx.x] = smem[0]; }
각 스레드가 4개의 원소를 처리하기 위해서 첫 번째로 global input data에 대한 offset을 다시 계산합니다.
// global index, 4 blocks of input data processed at a time unsigned int idx = blockDim.x * blockIdx.x * 4 + threadIdx.x;
새롭게 구한 offset으로 각 스레드는 4개의 원소를 읽고, 이들을 더해서 로컬 변수 tmpSum에 저장합니다. tmpSum은 shared memory를 초기화하는데 사용됩니다.
if (idx + 3 * blockDim.x < n) { int a1 = g_iData[idx]; int a2 = g_iData[idx + blockDim.x]; int a3 = g_iData[idx + 2 * blockDim.x]; int a4 = g_iData[idx + 3 * blockDim.x]; tmpSum = a1 + a2 + a3 + a4; } smem[tid] = tmpSum;
위의 unrolling을 통해 global memory load transaction의 수는 변하지 않습니다. 그러나 global memory store transaction의 수는 1/4로 감소합니다. 추가로 4번의 global load operation을 동시에 수행함으로써 GPU는 이들을 동시에 스케쥴링하여 잠재적인 global memory 활용을 향상시킵니다.
위 커널을 실행하기 위한 grid의 크기는 각 스레드에서 수행하는 작업량만큼 4배 감소되어야 합니다.
reduceSmemUnroll<<<grid.x / 4, block>>>(d_iData, d_oData, size);
이 커널을 추가하여 다시 nvprof로 수행 시간을 측정해보겠습니다.

unrolling을 사용한 reduceSmemUnroll 커널이 reduceSmem 커널보다 약 2.5배 빠르게 수행되는 것을 볼 수 있습니다.
마찬가지로 global memory의 load/store transaction을 측정해보겠습니다.
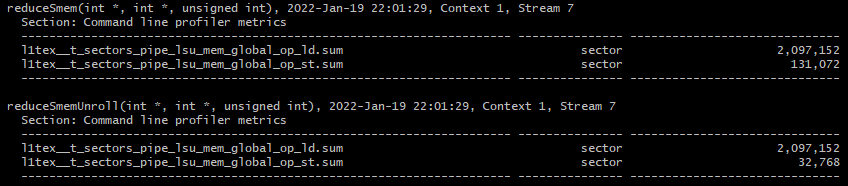
reduceSmemUnroll 커널의 store transactions 수가 reduceSmem 커널보다 4배 감소한 것을 볼 수 있습니다. load transaction의 수는 동일합니다.
마지막으로 global memory의 처리량을 살펴보겠습니다.
ncu.bat --metrics l1tex__t_bytes_pipe_lsu_mem_global_op_ld.sum.per_second,l1tex__t_bytes_pipe_lsu_mem_global_op_st.sum.per_second ./reduceInteger.exe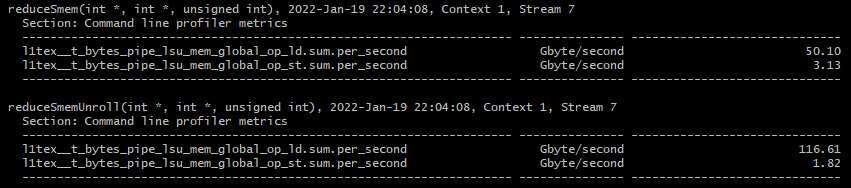
load throughput은 약 2.3배 증가했고, store throughput은 약 1.72배 감소하였습니다.
이는 동시에 처리되는 load 요청이 증가하였기 때문에 load throughput이 증가하였고, bus를 포화시킬만한 store 요청이 더 적기 때문에 store throughput이 감소하였습니다.
Parallel Reduction with Dynamic Shared Memory
이번에는 위에서 살펴본 reduceSmemUnroll 커널에서 static shared memory가 아닌 dynamic shared memory를 사용한 커널을 살펴보겠습니다.
커널은 거의 유사하며, shared memory은 다음과 같이 선언됩니다.
extern __shared__ int smem[];
커널 함수는 다음과 같습니다.
__global__ void reduceSmemUnrollDyn(int* g_iData, int* g_oData, unsigned int n) { // static shared memory extern __shared__ int smem[]; // set thread ID unsigned int tid = threadIdx.x; // global index, 4 blocks of input data processed at a time unsigned int idx = blockDim.x * blockIdx.x * 4 + threadIdx.x; // unrolling 4 blocks int tmpSum = 0; // boundary check if (idx + 3 * blockDim.x < n) { int a1 = g_iData[idx]; int a2 = g_iData[idx + blockDim.x]; int a3 = g_iData[idx + 2 * blockDim.x]; int a4 = g_iData[idx + 3 * blockDim.x]; tmpSum = a1 + a2 + a3 + a4; } smem[tid] = tmpSum; __syncthreads(); // in-place reduction in global memory if (blockDim.x >= 1024 && tid < 512) smem[tid] += smem[tid + 512]; __syncthreads(); if (blockDim.x >= 512 && tid < 256) smem[tid] += smem[tid + 256]; __syncthreads(); if (blockDim.x >= 256 && tid < 128) smem[tid] += smem[tid + 128]; __syncthreads(); if (blockDim.x >= 128 && tid < 64) smem[tid] += smem[tid + 64]; __syncthreads(); // unrolling warp if (tid < 32) { volatile int* vsmem = smem; vsmem[tid] += vsmem[tid + 32]; vsmem[tid] += vsmem[tid + 16]; vsmem[tid] += vsmem[tid + 8]; vsmem[tid] += vsmem[tid + 4]; vsmem[tid] += vsmem[tid + 2]; vsmem[tid] += vsmem[tid + 1]; } // write result for this block to global memory if (tid == 0) g_oData[blockIdx.x] = smem[0]; }
dynamic shared memory를 사용하므로, execution configuration에 다음과 같이 shared memory의 크기를 지정해주어야 합니다.
reduceSmemUnrollDyn<<<grid.x / 4, block, DIM*sizeof(int)>>>(d_iData, d_oData, size);
커널의 수행 시간을 nvprof로 측정해보겠습니다.

reduceSmemUnroll과 큰 차이는 없지만, 다른 이전 커널들보다 여전히 빠릅니다.
Effective Bandwidth
Reduction 커널 성능은 memory bandwidth에 의해서 결정되므로 성능을 평가하기 위한 적절한 방법은 커널의 effective bandwidth를 평가하는 것입니다. effective bandwidth는 커널이 완료되는데 걸린 시간동안 수행된 I/O의 양(bytes) 입니다. memory-bound application에서 effective bandwidth는 실제 bandwidth 활용도를 평가하는 아주 좋은 방법이며, 다음과 같이 계산할 수 있습니다.
effective bandwidth = (bytes read + bytes wirtten) / (time elapsed x ) GB/s
위에서 살펴본 커널의 effective bandwidth는 다음과 같습니다.
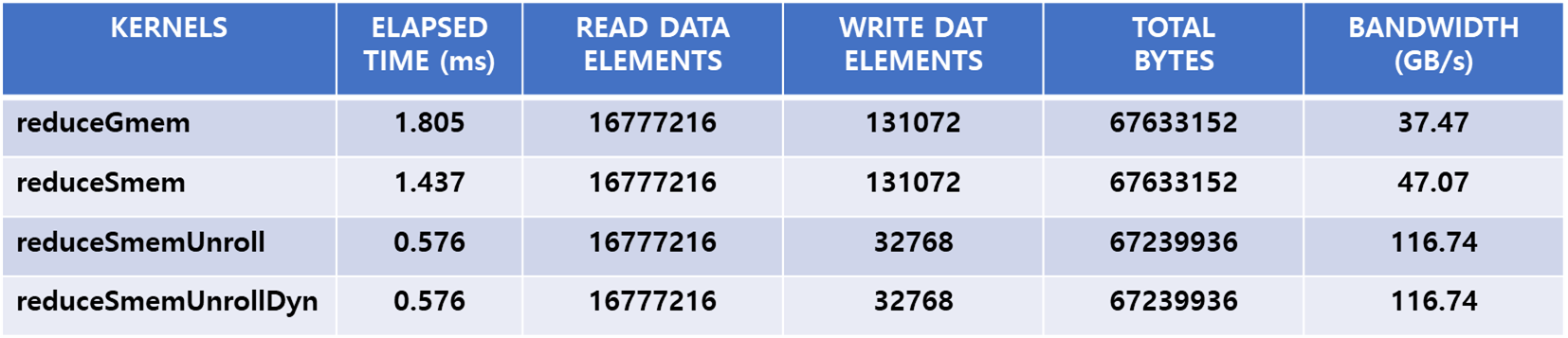
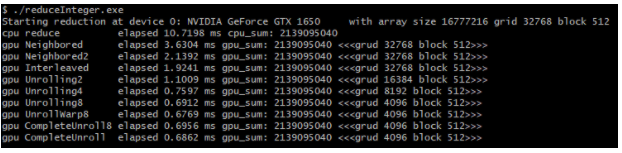
추가로 이전 포스팅에서 global memory로만 수행한 reduction 커널의 수행시간 결과는 다음과 같습니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| Warp Shuffle Instruction (0) | 2022.01.23 |
|---|---|
| Shared Memory (4) - Matrix Transpose (0) | 2022.01.22 |
| Shared Memory (2) - Square/Rectangular Shared Memory (0) | 2022.01.19 |
| Shared Memory (1) (0) | 2022.01.18 |
| Unified Memory (1) | 2022.01.17 |




댓글