References
- Professional CUDA C Programming
Contents
- Parallel Reduction
- Neighbored vs Interleaved Approach
- Unrolling Loops
- Use template parameter in device functions (템플릿 파라미터 사용)
Divergent Wraps (예제 : Sum Reduction)
Divergent Wraps (예제 : Sum Reduction)
References Programming Massively Parallel Processors https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Contents Warp Partioning Divergence Branch (Divergent Warps) Sum Reduction..
junstar92.tistory.com
이전 포스팅에서 Sum Reduction을 살펴보면서, divergence 문제를 어떻게 해결할 수 있는지 살펴봤습니다. 이번에 다시 한번 더 parallel reduction을 통해 branch divergence 문제를 해결하는 방법과 Nsight Compute를 통해서 수치적으로 어떻게 성능이 향상되는지 살펴보겠습니다.
전체 코드는 아래 github 링크를 참조하시기 바랍니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/reduction/reduceInteger.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
때때로, control flow는 스레드 인덱스에 영향을 받습니다. warp내의 조건문은 warp divergence를 일으키고, 이는 커널 성능을 저하시킵니다. 이러한 문제는 데이터 액세스 패턴을 조정하여 피할 수 있습니다.
The Parallel Reduction Problem
N개의 정수로 이루어진 배열을 더할 때, 간단하게 아래의 sequential code로 구현할 수 있습니다.
int sum = 0;
for (int i = 0; i < N; i++)
sum += array[i];N이 너무 크다면 위 코드는 너무나 느려집니다.
덧셈은 교환 법칙과 결합 법칙이 성립하기 때문에 배열 요소들은 어떤 순서로도 더할 수 있습니다. 이러한 이유로 다음과 같은 방법을 통해 병렬로 덧셈을 수행할 수 있습니다.
- input vector를 작은 단위로 분할
- 스레드가 각 단위의 부분합을 계산하도록 함
- 각 단위의 부분합을 더해서 최종합 계산
병렬 덧셈을 달성하는 일반적인 방법은 iterative pairwise implementation을 사용하는 것입니다. 하나의 덩어리가 한 쌍의 요소만을 포함하고, 스레드는 이 두 요소를 합하여 부분합을 계산합니다. 그런 다음 이 결과를 원래 입력에 다시 저장합니다. 그리고 새롭게 입력된 값들을 다음 반복에서 더할 입력으로 사용합니다. 매 반복마다 입력이 반으로 줄어들기 때문에 출력의 크기가 1이 될 때 최종합이 계산됩니다.
매 반복에서 output 요소가 저장되는 위치에 따라서 pairwise parallel sum은 두 가지 유형으로 구분될 수 있습니다.
- Neighbored pair: 요소가 바로 이웃한 요소와 쌍을 이룸
- Interleaved pair: 주어진 stride만큼 떨어진 요소와 쌍을 이름
아래 그림은 neighbored pair 구현을 보여줍니다. 커널에서 하나의 스레드는 매 단계마다 두 개의 이웃한 요소를 할당받고, 하나의 부분합을 생성합니다. 만약 N개의 요소가 있다면, N-1번의 덧셈이 요구되고 \(log_2 N\) 단계로 이루어집니다.

아래 그림은 interleaved pair 구현을 보여줍니다. 매 스텝마다 입력 길이의 절반만큼 떨어진 요소들이 각 스레드에 할당됩니다.

다음 코드는 interleaved pair 방법을 재귀로 구현한 코드입니다.
int recursiveReduce(int *data, int const size)
{
if (size == 1)
return data[0];
int const stride = size / 2;
for (int i = 0; i < stride; i++)
data[i] += data[i + stride];
return recursiveReduce(data, stride);
}여기서는 코드에서 덧셈이 수행되지만, 덧셈뿐만 아니라 결합 법칙과 교환 법칙이 성립하는 어떠한 연산도 가능합니다. 예를 들어, input 배열의 최대/최소값이나, 평균, 곱셈도 가능합니다.
이렇게 교환/결합 연산을 수행하는 것을 일반적으로 reduction problem이라고 합니다. Parallel Reduction은 이 연산을 병렬로 실행하는 것이며, 가장 일반적인 병렬 패턴 중의 하나입니다. 이전 포스팅에서 살펴본 것처럼 이미 봤을 수도 있지만 다양한 Parallel reduction 커널을 구현하고 성능에 어떠한 영향을 미치는지 살펴보고 실제로 측정해보도록 하겠습니다.
Divergence in Parallel Reduction
처음에는 neighbored pair 방법으로 구현한 커널에 대해서 살펴보겠습니다.
이 방법은 아래 그림처럼, 각 스레드가 이웃한 요소 두 개를 서로 더해서 부분합을 생성합니다.
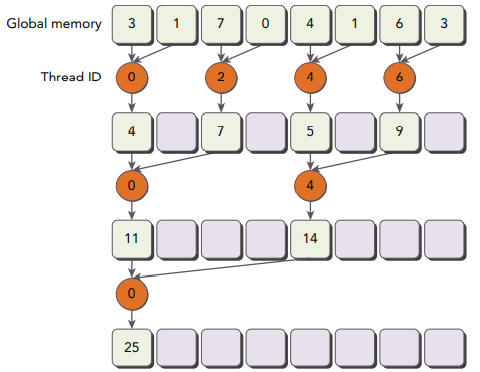
이 커널에서는 두 개의 global memory 배열을 사용합니다. 하나는 reduce를 수행할 전체 배열을 저장하는 큰 배열이고, 다른 하나는 각 스레드 블록에서 부분합을 저장할 작은 배열입니다. 각 스레드 블록은 독립적으로 배열의 부분을 연산합니다. 루프에서 하나의 반복은 하나의 reduction 단계를 수행하며, 따라서, 각 단계에서 전역 메모리의 값이 부분합으로 대체됩니다.
동일한 스레드 블록의 스레드가 다음 반복을 수행하기 전에는 현재 반복에서의 모든 부분합들이 전역 메모리에 저장되도록 보장해야합니다. 따라서 매 반복의 끝에서는 __syncthreads()를 통해 동기화를 시켜줍니다. 다음 반복에서의 스레드들은 이전 단계에서 생성된 값을 사용합니다. 마지막 단계 이후에 전체 스레드 블록의 합이 전역 메모리에 저장되도록 합니다.
// Neighbored Pair Implementation with divergence
__global__
void reduceNeighbored(int *g_iData, int *g_oData, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x);
// bound check
if (idx >= n)
return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if ((tid % (2*stride)) == 0) {
iData[tid] += iData[tid + stride];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0)
g_oData[blockIdx.x] = iData[0];
}두 개의 이웃한 요소들의 거리인 stride는 처음에는 1로 초기화됩니다. 매 reduction 단계 이후에 이 거리는 2배가 됩니다. 첫 번째 단계 이후에, iData의 짝수 번째 요소들은 부분합들로 값이 변경됩니다. 두 번째 단계 이후에서는 iData의 매 4번째 떨어진 요소들이 부분합 결과로 변경됩니다. 스레드 블록간에는 동기화가 필요없기 때문에, 각 스레드 블록에서 생성되는 부분합은 host로 다시 전달되어서 이들을 순차적으로 더해주어야 합니다.

입력 배열의 사이즈를 16M(\(2^24\ = 16777216))으로 설정하고 1D 그리드와 1D 블록으로 커널을 구성하도록 합니다.
실행 코드는 포스팅 상단에 있는 github 링크의 main 함수를 참조해주세요 !
다음의 커맨드로 컴파일을 하고, 실행해보겠습니다.
nvcc -O3 -arch=sm_75 -o reduceInteger reduceInteger.cu -I..
위의 결과를 baseline으로 아래에서 성능을 향상시켜보도록 하겠습니다.
Improving Divergence in Parallel Reduction
reduceNeighbored 커널에서 아래의 조건문을 살펴봅시다.
if ((tid % (2 * stride)) == 0)이 구문은 짝수 인덱스의 스레드에 대해서만 오직 true이기 때문에 매우 많은 divergent warps를 유발합니다. 첫 번째 반복에서, 모든 스레드들이 스케쥴링되어 있지만, 오직 짝수 스레드만이 if의 body를 실행합니다. 두 번째 반복에서는 전체 스레드의 1/4만 활성화됩니다. 이는 각 스레드의 배열 인덱스를 조정하여 인접한 스레드가 덧셈을 수행하도록 변경하여 warp divergence를 줄일 수 있습니다.
위의 그림과 비교했을 때, 아래 그림에서 부분합들이 저장되는 위치는 변경되지 않았지만, 동작하는 스레드가 변경되었습니다.
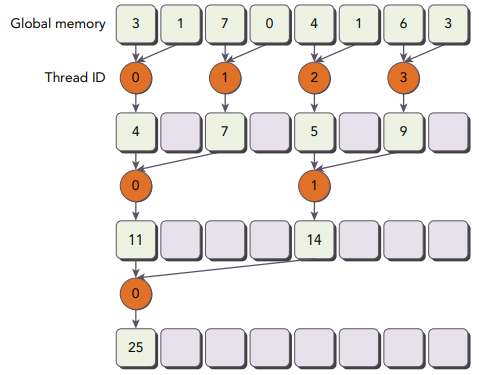
이를 구현한 코드는 다음과 같습니다.
// Neighbored Pair Implementation with less divergence
__global__
void reduceNeighboredLess(int *g_iData, int *g_oData, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x);
// bound check
if (idx >= n)
return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
// convert tid into local array index
int index = 2 * stride * tid;
if (index < blockDim.x)
iData[index] += iData[index + stride];
__syncthreads();
}
// write result for this block to global mem
if (tid == 0)
g_oData[blockIdx.x] = iData[0];
}커널의 다음 구문을 살펴보면, 각 스레드의 배열 접근 인덱스를 설정하고 있습니다.
int index = 2 * stride * tid;stride의 값이 2배가 되기 때문에, 다음 구문은 스레드 블록의 처음 절반만이 덧셈을 수행하도록 합니다.
if (index < blockDim.x)
512개의 스레드로 구성된 스레드 블록에서 첫 번째 8개의 warp들이 reduction의 첫 번째 단계를 수행합니다. 그리고 남은 8개의 warp들은 아무것도 하지 않습니다. 두 번째 단계에서는 처음 4개의 warp만 reduction을 수행하고 나머지 12개의 warp들은 아무것도 하지 않습니다. 그러므로, Divergence가 완전히 사라지지 않았습니다. Divergence는 오직 각 라운드에서 스레드의 총 개수가 warp의 크기보다 작을 때만 마지막 다섯 라운드에서 발생합니다. 아래에서 이 문제를 해결하는 방법에 대해서 알아보겠습니다.
새롭게 구현한 reduceNeighboredLess 커널을 실행해보도록 하겠습니다. 마찬가지로 실행 코드는 main함수를 참조해주시기 바랍니다.

새롭게 구현한 커널이 이전 커널보다 약 1.7배 정도 더 빠른 것을 확인할 수 있습니닥.
두 커널에서 무엇이 차이가 나는지 Nsight Compute를 통해 각 warp에서 수행된 평균 instruction을 측정해서 비교해보도록 하겠습니다. nvprof를 사용한다면 '--metrics inst_per_warp'를 사용하여 실행하면 됩니다.
Nsight Compute CLI를 사용하면 다음의 커맨드로 측정할 수 있습니다.
ncu.bat --metrics smsp__average_inst_executed_per_warp.ratio ./reduceInteger.exe
결과는 위와 같습니다. 기존 커널이 새로운 커널보다 2배 이상의 명령어를 수행하고 있다는 것을 확인할 수 있습니다. 이는 기존 커널이 높은 divergence가 발생하고 있다는 것을 말해줍니다.
다음으로 global memory load 처리량을 측정해보겠습니다.
ncu.bat --metrics l1tex__t_bytes_pipe_lsu_mem_global_op_ld.sum.per_second ./reduceInteger.exe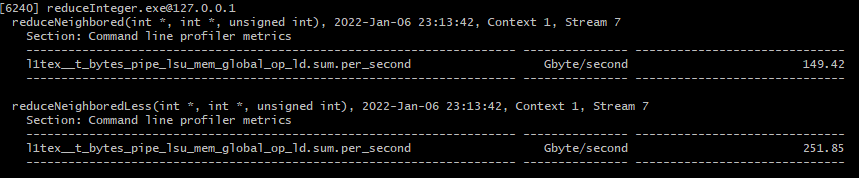
새롭게 구현한 커널이 더 높은 load 처리량을 보여줍니다.
Reducing with Interleaved Pairs
Interleaved pair 방법은 neighbored 방법과는 다르게 요소의 stride의 값을 다르게 사용합니다. stride는 처음에 스레드 블록 크기의 절반으로 시작하며, 매 반복마다 2배씩 감소합니다.

각 스레드는 매 라운드마다 현재 stride만큼 떨어진 요소 두 개를 더하여 부분합을 계산합니다. 바로 이전과 비교하면 작업을 수행하는 스레드는 변경되지 않았지만, 매 스레드에서 global memory에서의 load/store 위치가 변경되었습니다.
interleaved reduction의 커널 코드는 다음과 같습니다.
// Interleaved Pair Implementation with less divergence
__global__
void reduceInterleaved(int *g_iData, int *g_oData, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x);
// bound check
if (idx >= n)
return;
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (tid < stride)
iData[tid] += iData[tid + stride];
__syncthreads();
}
// write result for this block to global mem
if (tid == 0)
g_oData[blockIdx.x] = iData[0];
}line 16을 살펴보면, 두 요소 간의 stride는 처음에는 블록 사이즈의 절반으로 초기화되고, 매 라운드마다 2배씩 감소합니다. 그리고 line 18은 첫 번째 라운드에서 스레드 블록의 처음 절반만 덧셈을 수행하도록 하고, 두 번째 라운드에서는 스레드 블록의 처음 1/4만 덧셈을 수행하도록 합니다.
마찬가지로 실행 코드는 포스팅 상단 github 링크의 main 함수를 살펴보시길 바랍니다.

interleaved 방법을 사용한 커널은 처음 커널(Neighbored)보다 약 1.87배, 두 번째 커널(Neighbored2)보다 약 1.09배 빠릅니다. 이러한 성능의 향상은 주로 전역 메모리의 load/store 패턴이 감소된 결과입니다.
Nsight Compute로 global memory load 처리량을 살펴보면, 처음 두 커널과는 다르게 낮은 처리량을 보여주고 있습니다. 성능이 낮아졌다는 의미는 아니고, 더 적은 메모리 액세스로 동일한 작업을 수행하는 것으로 보입니다.

reduceInterleaved 커널은 reduceNeighboredLess 커널과 같은 warp divergence를 유발합니다. 실제로 branch efficiency를 측정해보면, 동일한 값이 나오는 것을 확인할 수 있습니다.
ncu.bat --metrics smsp__sass_average_branch_targets_threads_uniform.pct ./reduceInteger.exe
smsp__sass_average_branch_targets_threads_uniform.pct는 총 branch에서 non-divergnet branch의 비율을 의미합니다.
Unrolling Loops
Loop Unrolling은 branch frequency와 loop maintenance instruction 줄여서 루프 실행을 최적화하는 기술입니다. Loop Unrolling에서는 하나의 구문이 루프를 사용하여 반복적으로 실행하는 것이 아니라, 루프의 body가 여러 줄의 코드로 작성됩니다. 따라서, 루프는 반복 횟수가 감소하거나 완전히 제거됩니다. 이렇게 루프의 body로 만들어진 복사본의 수를 loop unrolling factor라고 하는데, 이를 둘러싸는 루프의 반복 횟수는 loop unrolling factor로 나누어서 계산합니다. Loop Unrolling 루프를 실행하기 전에 반복 횟수를 알고 있는 sequential array processing 루프의 성능을 향상시키는데 가장 효과적입니다.
아래는 Loop Unrolling의 예시입니다.
for (int i = 0; i < 100; i++)
a[i] = b[i] + c[i];루프의 body를 한번 복사한다면, 반복 횟수는 원래 루프의 절반으로 감소됩니다.
for (int i = 0; i < 100; i += 2) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
}
Loop Unrolling으로부터 얻을 수 있는 성능의 향상 이유는 high-level 코드로는 쉽게 알 수는 없습니다. 성능의 향상은 컴파일러의 low-level instruction 개선과 최적화를 통해서 얻을 수 있습니다. 예를 들어, 위 예제 코드에서 조건 i < 100은 원래 루프에서 100번 체크되지만, Loop Unrolling이 적용되면 50번만 체크됩니다. 또한 각 루프의 문장에서 수행되는 read/write는 독립적이기 때문에, CPU에서 메모리 작업을 동시에 실행할 수 있습니다.
CUDA에서 Unrolling은 다양한 것들을 의미할 수 있습니다. 하지만 목표는 같습니다. instruction의 오버헤드를 줄이고, 더 독립적인 instruction들을 만들어서 성능을 향상시킵니다. 그 결과, 파이프라인에 더 많은 동시 연산들이 추가되어서 더 높은 instruction 포화도와 메모리 대역폭을 이끌어냅니다.
Reducing with Unrolling
reduceInterleaved 커널의 각 스레드 블록은 처리해야되는 전체 데이터의 하나의 block만을 처리합니다. 만약 수동으로 하나의 스레드 블록으로 2개의 data block을 처리하도록 unrolling하면 어떨까요?
다음 커널 함수는 reduceInterleaved 커널을 약간 수정한 버전입니다. 각 스레드 블록은 2개의 data block을 더합니다. 이는 cyclic paritioning의 예이며, 각 스레드는 하나 이상의 data block에서 수행되고, 각 data block에서의 하나의 요소를 처리합니다.
// unrolling 2
__global__ void reduceUnrolling2(int *g_iData, int *g_oData, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x*2 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x * 2);
// unrolling 2
if (idx + blockDim.x < n)
g_iData[idx] += g_iData[idx + blockDim.x];
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (tid < stride)
iData[tid] += iData[tid + stride];
__syncthreads();
}
// write result for this block to global mem
if (tid == 0)
g_oData[blockIdx.x] = iData[0];
}line 11-12 코드는 커널의 시작 부분에서 덧셈을 수행합니다. 각 스레드는 이웃한 data block으로부터 하나의 요소를 더합니다. 이는 data block 전체에 걸쳐서 reduction 루프의 반복이 감소되는 것과 동일합니다.
동일한 데이터를 처리하는데 스레드 블록의 절반만 필요하므로, Global 배열 인덱스는 아래의 그림처럼 적절하게 조정됩니다.
unsigned int idx = blockDim.x*blockIdx.x*2 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x * 2);
이는 동일한 크기의 데이터에 대해 디바이스에서 수행되는 warp와 block-level의 병렬화가 덜하다라는 것을 의미합니다. 위 그림에서 각 스레드의 데이터 액세스를 보여주고 있습니다.
마찬가지로 자세한 실행 코드는 github 코드의 main 함수를 참조하시기 바랍니다. 여기서 하나의 스레드 블록이 2개의 data block을 처리하므로, 계산된 그리드에서 절반만 커널에서 수행되도록 해주어야 합니다. 따라서 커널은 다음과 같이 실행합니다.
reduceUnrolling2<<<grid.x / 2, block>>>(d_iData, d_oData, size);
코드 실행 결과는 다음과 같습니다.

첫 번째 커널(Neighbored)보다 약 3.3배 빠르게 실행됩니다. 만약 unrolling factor가 2가 아닌 4, 8이면 더 좋은 성능을 얻을 수 있을까요?
reduceUnrolling4와 reduceUnrolling8은 github 코드에서 확인하실 수 있습니다.

예상한대로, 단일 스레드에서 더 많은 독립적인 메모리 load/store 연산을 수행하면 memory latency를 더 잘 숨길 수 있으므로 더 좋은 성능을 얻을 수 있습니다.
device memory read 처리량을 측정하면 이를 수치적으로 확인할 수 있습니다. nvprof를 사용하면 '--metrics dram_read_thoughput'으로 성능을 측정할 수 있습니다.
ncu.bat --metrics dram__bytes_read.sum.per_second ./reduceInteger.exe
결과는 위와 같습니다. 확실히 Unrolling을 더 적용할수록 device read throughput이 증가하는 것을 확인할 수 있습니다.
Reducing with Unrolled Warps
__syncthreads()는 블록 내 동기화를 위해 사용됩니다. reduction 커널에서 __syncthreads()는 각 라운드에서 다음 라운드로 넘어가기 전에 모든 스레드가 전역 메모리에 부분합을 저장했는지 확인하기 위해 사용됩니다.
그러나 32개 이하의 스레드가 남아 있는 경우(즉, 하나의 warp)를 고려해야합니다. Warp의 실행은 SIMT이기 때문에, 각 instruction 이후에는 암묵적인 warp 내 동기화가 있습니다.
따라서, reduction 루프의 마지막 6번의 반복을 다음과 같이 unrolling 할 수 있습니다.
if (tid < 32) {
volatile int *vmem = iData;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}이 warp unrolling은 loop control 및 스레드 동기화 로직 실행을 피하게 해줍니다.
여기서 주목해야되는 것은 vmem 변수가 volatile 지정자로 선언되었다는 것입니다. 이는 컴파일러에게 vmem[tid]를 다시 전역 메모리에 저장해야된다라는 것을 알려줍니다. 만약 volatile 지정자가 생략되면, 컴파일러나 캐시가 전역 또는 공유 메모리에 대한 read/write를 최적화할 수 있기 때문에 이 코드는 올바르게 동작하지 않습니다.
전역 메모리나 공유 메모리에 위치한 변수가 valatile로 선언되면, 컴파일러는 그 값이 언제든지 다른 스레드에 의해서 변경되거나 사용될 수 있다고 가정합니다. 따라서, volatile 변수에 대한 참조는 직접적으로 메모리에 읽기나 쓰도록 강제하며, 단순히 캐시나 레지스터에 읽고 쓰지 않습니다.
reduceUnrolling8을 기반으로, warp unrolling이 적용된 커널은 다음과 같이 작성할 수 있습니다.
// unrolling warps 8
__global__
void reduceUnrollWarps8(int *g_iData, int *g_oData, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x*8 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x * 8);
// unrolling 8
if (idx + 7*blockDim.x < n) {
int a1 = g_iData[idx];
int a2 = g_iData[idx + blockDim.x];
int a3 = g_iData[idx + 2*blockDim.x];
int a4 = g_iData[idx + 3*blockDim.x];
int b1 = g_iData[idx + 4*blockDim.x];
int b2 = g_iData[idx + 5*blockDim.x];
int b3 = g_iData[idx + 6*blockDim.x];
int b4 = g_iData[idx + 7*blockDim.x];
g_iData[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 32; stride >>= 1)
{
if (tid < stride)
iData[tid] += iData[tid + stride];
__syncthreads();
}
// unrolling warp
if (tid < 32) {
volatile int *vmem = iData;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
// write result for this block to global mem
if (tid == 0)
g_oData[blockIdx.x] = iData[0];
}
실행해보면 다음의 결과를 확인할 수 있습니다.

reduceUnrolling8보다 약간의 성능 향상이 존재하며, reduceNeighbored 커널보다는 약 5.3배 빠릅니다.
nvprof의 stall_sync metric은 __syncthreads()에 의해 중지된 warp를 측정할 수 있습니다.
Nsight Compute로는 다음의 커맨드로 측정할 수 있습니다.
ncu.bat --metrics smsp__warp_issue_stalled_barrier_per_warp_active.pct,smsp__warp_issue_stalled_membar_per_warp_active.pct ./reduceInteger.exesmsp__warp_issue_stalled_barrier_per_warp_active.pct는 barrier에 의해 기다리는 사이클 당 warps의 비율이고, smsp__warp_issue_stalled_membar_per_warp_active.pct는 memory barrier에 의해 기다리는 사이클 당 warps의 비율입니다.

마지막 warp를 unrolling 함으로써, stall 되는 warp의 비율이 감소하는 것을 확인할 수 있습니다.
Reducing with Complete Unrolling
만약 컴파일 시간에 루프의 반복 횟수를 알고 있다면, 완전히 unrolling할 수 있습니다.
Fermi나 Kepler 아키텍처에서 블록당 최대 스레드 수는 1024이고, reduction 커널에서 루프의 반복 횟수는 스레드 블록 차원 크기에 따라 결정되므로 reduction 루프를 완전히 unroll할 수 있습니다.
다음은 reduceUnrollWarps8 커널 함수를 완전히 unroll하도록 수정한 커널입니다.
// complete unroll warp
__global__
void reduceCompleteUnrollWarps8(int *g_iData, int *g_oData, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x*8 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x * 8);
// unrolling 8
if (idx + 7*blockDim.x < n) {
int a1 = g_iData[idx];
int a2 = g_iData[idx + blockDim.x];
int a3 = g_iData[idx + 2*blockDim.x];
int a4 = g_iData[idx + 3*blockDim.x];
int b1 = g_iData[idx + 4*blockDim.x];
int b2 = g_iData[idx + 5*blockDim.x];
int b3 = g_iData[idx + 6*blockDim.x];
int b4 = g_iData[idx + 7*blockDim.x];
g_iData[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
// in-place reduction and complete unroll
if (blockDim.x >= 1024 && tid < 512)
iData[tid] += iData[tid + 512];
__syncthreads();
if (blockDim.x >= 512 && tid < 256)
iData[tid] += iData[tid + 256];
__syncthreads();
if (blockDim.x >= 256 && tid < 128)
iData[tid] += iData[tid + 128];
__syncthreads();
if (blockDim.x >= 128 && tid < 64)
iData[tid] += iData[tid + 64];
__syncthreads();
// unrolling warp
if (tid < 32) {
volatile int *vmem = iData;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
// write result for this block to global mem
if (tid == 0)
g_oData[blockIdx.x] = iData[0];
}
실행 결과는 다음과 같습니다.

reduceUnrollWarps8 커널보다 약간의 성능 향상을 보여줍니다.
Reducing with Template Functions
수동으로 루프를 unroll할 수 있지만, 템플릿 함수를 사용하면 branch overhead를 더욱 줄일 수 있습니다. CUDA는 device function에 템플릿 파라미터를 지원합니다. 따라서, 다음과 같이 블록의 크기를 템플릿 함수의 매개변수로 지정할 수 있습니다.
template<unsigned int iBlockSize>
__global__
void reduceCompleteUnroll(int *g_iData, int *g_oData, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x*8 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *iData = g_iData + (blockIdx.x * blockDim.x * 8);
// unrolling 8
if (idx + 7*blockDim.x < n) {
int a1 = g_iData[idx];
int a2 = g_iData[idx + blockDim.x];
int a3 = g_iData[idx + 2*blockDim.x];
int a4 = g_iData[idx + 3*blockDim.x];
int b1 = g_iData[idx + 4*blockDim.x];
int b2 = g_iData[idx + 5*blockDim.x];
int b3 = g_iData[idx + 6*blockDim.x];
int b4 = g_iData[idx + 7*blockDim.x];
g_iData[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
// in-place reduction and complete unroll
if (iBlockSize >= 1024 && tid < 512)
iData[tid] += iData[tid + 512];
__syncthreads();
if (iBlockSize >= 512 && tid < 256)
iData[tid] += iData[tid + 256];
__syncthreads();
if (iBlockSize >= 256 && tid < 128)
iData[tid] += iData[tid + 128];
__syncthreads();
if (iBlockSize >= 128 && tid < 64)
iData[tid] += iData[tid + 64];
__syncthreads();
// unrolling warp
if (tid < 32) {
volatile int *vmem = iData;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
// write result for this block to global mem
if (tid == 0)
g_oData[blockIdx.x] = iData[0];
}reduceCompleteUnrollWarps8 커널과의 유일한 차이점은 블록 사이즈를 템플릿 파라미터로 변경한 것입니다. 블록 크기를 확인하는 if문은 컴파일 시간에 체크되며 조건이 참이 아닌 경우에 제거되므로 매우 효율적인 루프가 됩니다. 예를 들어, 스레드 블록의 크기가 256으로 커널이 호출되었다면 다음의 문장은
iBlockSize >= 1024 && tid < 512false가 됩니다. 따라서, 컴파일러는 이를 자동으로 제거합니다.
템플릿을 사용하는 경우에 이 커널은 반드시 switch-case 구조로 호출되어야 합니다. (컴파일 시간에 블록 사이즈 크기를 알 수 있도록)
switch (blockSize) {
case 1024:
reduceCompleteUnroll<1024><<<grid.x / 8, block>>>(d_iData, d_oData, size);
break;
case 512:
reduceCompleteUnroll<512><<<grid.x / 8, block>>>(d_iData, d_oData, size);
break;
case 256:
reduceCompleteUnroll<256><<<grid.x / 8, block>>>(d_iData, d_oData, size);
break;
case 128:
reduceCompleteUnroll<128><<<grid.x / 8, block>>>(d_iData, d_oData, size);
break;
case 64:
reduceCompleteUnroll<64><<<grid.x / 8, block>>>(d_iData, d_oData, size);
break;
}실행 결과는 다음과 같습니다.

템플릿 파라미터를 사용하지 않은 CompleteUnroll8 커널보다 아주 약간 빠르게 실행되는 것을 확인할 수 있습니다. 이정도 차이는 아마 실행할 때마다 더 빠른 커널은 변경될 수 있습니다.
결과를 살펴보면, 기존 커널과 비교해서 Unrolling 8이 가장 큰 상대적인 성능 향상을 가지고 왔습니다. 그리고 그 이후의 커널들과는 거의 대등한 성능을 보여주고 있습니다.
마지막으로 memory load/store 효율을 측정하고 이번 포스팅을 마무리하도록 하겠습니다.
ncu.bat --metrics smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct,smsp__sass_average_data_bytes_per_sector_mem_global_op_st.pct ./reduceInteger.exe
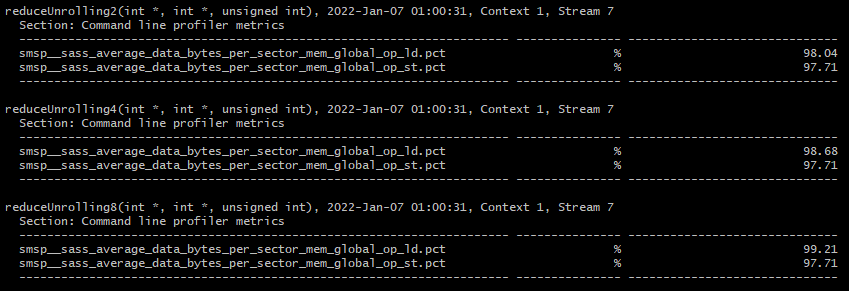

smsp__sass_average_data_bytes_per_sector_mem_global_op_st.pct는 global memory store 효율이고, smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct는 global memory load 효율입니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| CUDA Memory Model (0) | 2022.01.13 |
|---|---|
| Nested Reduction (Dynamic Parallelism) (0) | 2022.01.11 |
| Nsight Compute로 Warp 성능 측정하기 (0) | 2022.01.07 |
| WARP Execution (3) | 2022.01.05 |
| CUDA Dynamic Parallelism (동적 병렬) (2) | 2022.01.01 |




댓글