References
- Professional CUDA C Programming
Contents
- Dynamic Parallelism
- Nested Reduction (reduction problem)
이번 포스팅에서는 지난 포스팅에서 살펴본 Sum Reduction을 동적 병렬(Dynamic Parallelism)을 사용한 커널로 구현할 예정입니다.
Warp의 Branch Divergence (reduction problem)
Warp의 Branch Divergence (reduction problem)
References Professional CUDA C Programming Contents Parallel Reduction Neighbored vs Interleaved Approach Unrolling Loops Use template parameter in device functions (템플릿 파라미터 사용) Divergent..
junstar92.tistory.com
이전에 Dynamic Parallelism에 관련한 포스트를 업로드했었는데, 이번에 다시 한 번 간단하게 동적 병렬에 대해 살펴보고, Reduction Problem을 동적 병렬로 해결하는 방법에 대해서 살펴보겠습니다.
이전에 업로드한 동적 병렬 관련 포스트와 비슷한 내용이니, 이전 글이 궁금하시면 아래 링크 참조바랍니다 !
CUDA Dynamic Parallelism (동적 병렬)
CUDA Dynamic Parallelism (동적 병렬)
References https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html Programming Massively Parallel Processors Contents Dynamic Parallelism Overview Memory Data Visibility Execution Environme..
junstar92.tistory.com
Dynamic Parallelism
CUDA Dynamic Parallelism은 GPU에서 직접 새로운 GPU 커널을 생성하고 동기화할 수 있도록 해줍니다. 동적 병렬을 사용하면, CPU(host)가 아닌 GPU(device)에서 직접 커널을 호출할 수 있습니다. 이때, CPU에서 호출하는 것과 동일한 문법이 사용됩니다.
동적 병렬에서 커널의 실행은 두 가지 타입으로 분류됩니다. 하나는 parent thread, parent thread block 또는 parent grid 인데, 이는 새로운 child grid라는 새로운 grid를 실행합니다. 다른 하나는 child thread, child thread block, 또는 child grid 입니다. 이는 parent로부터 실행되는 것들입니다. child grid는 반드시 parent thread, parent thread block, parent grid가 완료된 것으로 간주되기 전에 완료되어야 합니다. parent는 자신의 child grid 전체가 완료될 때까지 완료된 것으로 간주되지 않습니다.
아래 그림은 parent grid와 child grid의 scope를 보여주고 있습니다. parent grid는 host thread에 의해서 실행되고, child grid는 parent grid에 의해서 실행됩니다. child grid의 실행과 완료는 적절하게 nested되며, 이는 parent thread에 의해서 만들어진 child grid 전체가 완료될 때까지 완료된 것으로 간주되지 않는다는 것을 의미합니다. 만약 실행된 child grid에 대해 명시적인 동기화가 없다면, 런타임은 parent와 child 사이에 암묵적인 동기화를 보장합니다. 아래 그림에서는 barrier가 parent thread에서 설정되어, child grid와 명시적인 동기화를 수행하고 있습니다.
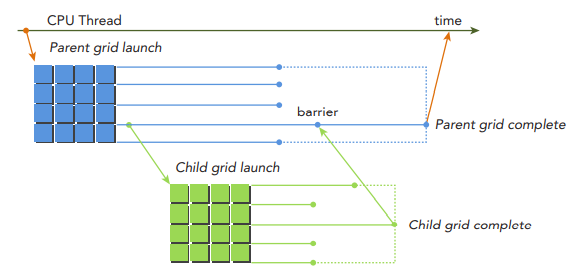
device thread에서의 grid 실행은 thread block 사이에서 visible합니다. 이는 동일한 블록의 thread들에서 실행되는 child grids에 대해서 thread(device)가 동기화한다는 것을 의미합니다. 블록 내의 모든 thread들에 의해서 생성된 child grid들이 완료될 때까지 thread block은 완료된 것으로 간주되지 않습니다. 만약 블록 내의 모든 thread들이 모든 child grid가 완료되기 전에 종료한다면, 이 child grid에 대한 암묵적인 동기화가 트리거됩니다.
parent가 child grid를 실행할 때, child는 parent thread block이 child에 대해 명시적으로 동기화할 때까지 실행을 시작한다고 보장하지는 않습니다.
parent와 child grids는 동일한 global, constant 메모리 공간을 공유하지만, local, shared 메모리는 공유하지 않습니다. parent와 child grids는 전역 메모리에 concurrent access를 가지며, child와 parent 사이에서는 weak consistency guarantees를 가집니다.
child grid의 실행에서 parent thread와 메모리의 view가 완전히 일치하는 두 가지 포인트가 있습니다.
하나는 child grid가 시작될 때이며, 다른 하나는 child grid가 종료할 때입니다. parent thread에서 child grid 호출 전의 모든 전역 메모리 동작은 child grid에서 visible 합니다. 그리고, child grid에서의 모든 메모리 동작은 child grid의 완료에 parent가 동기화한 후에 parent에 visible 하도록 보장됩니다.
Shared / Local 메모리는 thread block 또는 thread에 각각 private하고, parent와 child 사이에서 visiable/coherent 하지 않습니다. Local 메모리는 thread에 private한 공간이므로, 해당 thread 외부에서 visible하지 않습니다. 따라서, child grid를 실행할 때, local memory의 포인터를 argument로 전달하는 것은 유효하지 않습니다.
Nested Hello World on the GPU
동적 병렬을 간단하게 살펴보기 위해서 간단하게 병렬로 "Hello World"를 출력하는 커널을 구현해보겠습니다. 아래 그림은 동적 병렬을 사용하여 커널에 의해 구성된 중첩된 재귀 호출을 보여줍니다.
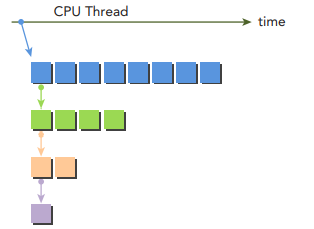
Host는 8개의 스레드로 구성된 하나의 스레드 블록의 parent grid를 호출합니다. 그리고 이 grid의 thread 0은 parent grid의 절반의 thread로 child grid를 호출합니다. 다음엔 첫 번째 child grid의 thread 0이 다시 절반의 thread로 새로운 child grid를 실행합니다. 계속해서 마지막 child grid에 thread가 하나만 남을 때까지 반복합니다.
구현한 커널 함수는 다음과 같습니다.
__global__
void nestedHelloWorld(int const iSize, int iDepth)
{
int tid = threadIdx.x;
printf("Resursion=%d: Hellow World from thread %d block %d\n", iDepth, tid, blockIdx.x);
// condition to stop recursive execution
if (iSize == 1)
return;
// reduce block size to half
int nThreads = iSize >> 1;
// thread 0 launches child grid recursively
if (tid == 0 && nThreads > 0) {
nestedHelloWorld<<<1, nThreads>>>(nThreads, ++iDepth);
printf("-------> nested execution depth: %d\n", iDepth);
}
}모든 스레드에 의해서 실행된 커널은 처음에 "Hello World"를 출력하면서 시작됩니다. 그리고 각 스레드는 본인이 종료되어야하는지 체크합니다. 만약 thread 개수가 1보다 크다면, 해당 블록에서 thread 0은 재귀적으로 절반의 스레드를 가진 child grid를 실행합니다.
다음의 main 함수로 컴파일 후, 실행해보겠습니다.,
#include <stdio.h>
#include <cuda_runtime.h>
int main(int argc, char** argv)
{
cudaSetDevice(0);
int size = 8;
int blockSize = 8;
int iGrid = 1;
if (argc > 1) {
iGrid = atoi(argv[1]);
size = iGrid * blockSize;
}
dim3 block(blockSize, 1);
dim3 grid((size + block.x - 1) / block.x , 1);
printf("Execution Configuration: grid %d block %d\n", grid.x, block.x);
nestedHelloWorld<<<grid, block>>>(block.x, 0);
cudaGetLastError();
cudaDeviceReset();
return 0;
}
컴파일 커맨드는 다음과 같습니다.
nvcc -arch=sm_75 -rdc=true -o nestedHelloWorld ./file_name.cu-arch 플래그로 compute capability 3.5 이상을 선택해줍니다. (동적 병렬은 compute capability 3.5 이상부터 지원됩니다.) 그리고 -rdc=true는 relocatable device code 생성을 강제합니다. 이는 동적 병렬을 위해 필수 사항입니다. relocatable device code에 관해서는 다음에 한 번 다루어 보도록 하겠습니다.. ! 일단 동적 병렬을 사용하는 코드는 이 플래그가 필요하다는 것만 알고 있으면 됩니다.
컴파일을 완료한 후 실행하면 다음의 출력을 확인할 수 있습니다.

출력 메세지로부터, host에 의해서 실행된 parent grid가 1개의 블록과 8개의 스레드를 가진다는 것을 볼 수 있습니다. nestedHelloWorld 커널은 재귀적으로 3번 호출되며, 각 호출 당 스레드의 개수는 절반으로 감소합니다.
NVIDIA Visual Profiler(nvvp)를 사용하면, 아래처럼 child kernel들이 어떻게 실행되는지 Timeline으로 살펴볼 수 있습니다.

실제로 위의 결과를 살펴보고 싶어서, 여러 가지를 시도해봤으나 잘 되지 않았습니다. 제 노트북의 경우에는 compute capability가 7.5인데, Visual Profiler로 프로파일링을 하면 다음과 같은 경고가 나오면서, 제대로 결과가 나오지 않습니다.

Nsight Systems으로 유사한 결과를 얻을 수 있을 것으로 예상하고, 시도해보았으나 이 역시도 불가능했습니다. Nsight System 릴리즈 노트를 살펴보면, Volta 이상의 GPU 디바이스에서는 CDP(CUDA Dynamic Parallelism) 커널을 trace할 수 없다고 합니다.

이번에는 두 개의 블록을 가진 parent grid를 실행해보도록 하겠습니다.

child grid의 블록 ID가 모두 0이라는 것을 볼 수 있습니다.
아래 그림은 child grids가 어떻게 두 개의 초기 블록에서 재귀적으로 호출되는지 보여줍니다.
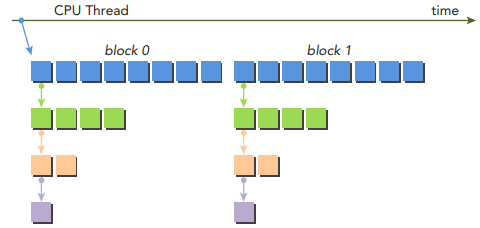
parent grid는 두 개의 블록으로 구성되는 반면, 모든 nested child grids는 하나의 블록만을 포함합니다. 이는 nestedHelloWorld의 thread configuration 때문입니다.
nestedHelloWorld<<<1, nThreads>>>(nThreads, ++iDepth);
아래와 같은 방식으로 child kernel을 호출할 수도 있습니다.

__global__
void nestedHelloWorld2(int const iSize, int minSize, int iDepth)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
printf("Resursion=%d: Hellow World from thread %d block %d\n", iDepth, threadIdx.x, blockIdx.x);
// condition to stop recursive execution
if (iSize == minSize)
return;
// reduce block size to half
int nThreads = iSize >> 1;
// thread 0 launches child grid recursively
if (tid == 0 && nThreads > 0) {
int blocks = (nThreads + (blockDim.x/2) - 1) / (blockDim.x/2);
nestedHelloWorld2<<<blocks, blockDim.x/2>>>(nThreads, minSize, ++iDepth);
printf("-------> nested execution depth: %d\n", iDepth);
}
}main 함수에서 커널 호출은 다음과 같이 호출하면 됩니다.
nestedHelloWorld2<<<grid, block>>>(size, grid.x, 0);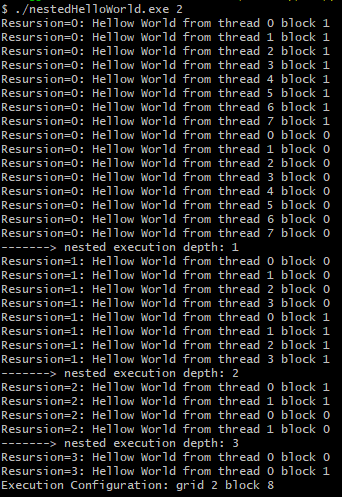
Nested Reduction
Reduction 문제는 기본적으로 재귀 함수로 표현할 수 있습니다. 이전 포스팅에서 이미 재귀 함수로 Reduction 문제를 구현해보았습니다. 커널 함수에서 CUDA Dynamic Parallelism을 사용하면 CUDA에서 재귀 reduction 커널을 쉽게 C처럼 구현할 수 있습니다.
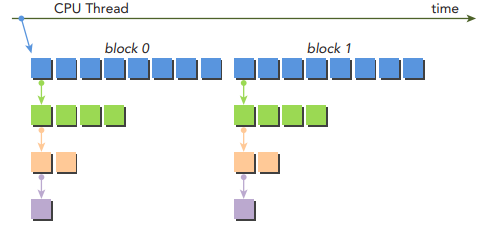
재귀 커널은 다음과 같이 구현할 수 있습니다. 이 커널은 위와 같이 thread 0에서 child grid를 실행하는 커널입니다.
__global__
void gpuRecursiveReduce(int *g_iData, int *g_oData, unsigned int iSize)
{
unsigned int tid = threadIdx.x;
int *iData = g_iData + blockIdx.x*blockDim.x;
int *oData = g_oData + blockIdx.x;
// stop condition
if (iSize == 2 && tid == 0) {
g_oData[blockIdx.x] = iData[0] + iData[1];
return;
}
// nested invocation
int iStride = iSize >> 1;
if (iStride > 1 && tid < iStride) {
// in-place reduction
iData[tid] += iData[tid + iStride];
}
__syncthreads();
// nested invocation to generate child grids
if (tid == 0) {
gpuRecursiveReduce<<<1, iStride>>>(iData, oData, iStride);
// sync all child grids launched in this block
cudaDeviceSynchronize();
}
__syncthreads(); // sync at block level again
}이전에 살펴본 nestedHelloWorld 커널처럼 원래 grid는 많은 block들을 포함하지만, parent에서 실행되는 모든 child grids는 parent의 thread 0에서 실행되는 하나의 블록만을 가지고 있습니다.
gpuRecursiveReduce 커널의 첫 번째 스텝은 global memory 주소 g_iData를 각 스레드의 local로 변환하는 것입니다. 그리고 stop condition을 체크하는데, 만약 stop condition을 만족한다면 결과값은 global memory로 다시 복사되고 parent 커널로 리턴됩니다. 만약 조건을 만족하지 못한다면, 현재 블록에 있는 스레드 절반이 in-place reduction을 수행합니다. in-place reduction이 완료된 후에는 모든 부분합이 완료되는 것을 보장하기 위해서 블록을 동기화시킵니다. 그리고 thread 0은 하나의 현재 블록의 스레드의 절반만큼 스레드를 가지는 child grid 생성합니다. child grid가 생성되고 실행되면 child grid를 기다리기 위한 barrier point 설정됩니다. 각 블록 당 하나의 스레드에 의해서 생성된 child grid는 하나이기 때문에 이 barrier point는 오직 하나의 child grid에 대해서 동기화합니다.
전체 코드와 main 함수는 아래 코드를 참조하시길 바랍니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/reduction/nestedReduce.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
코드를 아래 커맨드로 컴파일하고, 실행하면 다음과 같은 결과를 확인할 수 있습니다.
nvcc -arch=sm_75 -rdc=true -o nestedReduce nestedReduce.cu -I..
gpu Nested가 위 커널 함수를 실행한 결과입니다. 결과는 생각보다 느리며, cpu에서 수행한 것보다 느립니다.
출력 결과를 살펴보면, 커널은 초기에 2048개의 블록으로 시작합니다. 각 블록은 8번의 재귀를 수행하므로, 총 16384개의 child block이 생성되며, __syncthreads로 인한 블록 간의 동기화 또한 16384번 수행됩니다. 이렇게 많은 수의 커널과 동기화는 커널 성능을 저하시킵니다.
child grid가 생성되고 실행될 때, child grid의 memory view는 parent thread와 완전히 일치합니다. 각 child thread는 부분합을 계산하기 위해서 parent의 값만 필요하기 때문에, child grid가 실행되기 전에 수행되는 in-block 동기화는 불필요합니다.
모든 동기화를 제거한 버전의 커널은 다음과 같습니다.
__global__
void gpuRecursiveReduceNosync(int *g_iData, int *g_oData, unsigned int iSize)
{
unsigned int tid = threadIdx.x;
int *iData = g_iData + blockIdx.x*blockDim.x;
int *oData = g_oData + blockIdx.x;
// stop condition
if (iSize == 2 && tid == 0) {
g_oData[blockIdx.x] = iData[0] + iData[1];
return;
}
// nested invocation
int iStride = iSize >> 1;
if (iStride > 1 && tid < iStride) {
// in-place reducetion
iData[tid] += iData[tid + iStride];
if (tid == 0) {
gpuRecursiveReduceNosync<<<1, iStride>>>(iData, oData, iStride);
}
}
}위 커널을 추가하고, 다시 실행시켜보겠습니다.

약 2배정도 빨라졌으나, 여전히 성능이 좋지는 못합니다.
다음으로, 어떻게 많은 수의 child grid의 실행에 의한 오버헤드를 줄일 수 있는지 알아보겠습니다. 현재 구현된 gpuRecursiveReduceNosync에서 각 블록은 child grid를 생성하고, 그 결과 많은 수의 grid의 실행이 발생합니다.
만약 아래와 같은 그림의 접근 방법을 사용하면 어떨까요?

위와 같은 접근 방법을 사용하면, 전체 병렬 수행의 양은 동일하지만, child grid 당 스레드 블록의 개수는 증가하고 child grid의 수는 감소합니다.
위 접근 방법을 사용한 커널은 다음과 같이 구현할 수 있습니다.
grid에서 첫 번째 블록의 첫 번째 스레드만 다음 child grid를 생성하도록 합니다. 이를 위해서 이전에 살펴본 두 개의 커널에서 추가되는 파라미터가 있습니다. 각 child kernel이 실행될 때마다, child block의 크기는 이전 크기의 절반으로 줄어들기 때문에, 처음 parent block의 크기를 파생되는 child grid들에게 전달해주어야 합니다. 이렇게 전달해준 parent block의 크기는 각 스레드들이 올바르게 전역 메모리에 접근하여 계산할 수 있도록 합니다.
__global__
void gpuRecursiveReduce2(int *g_iData, int *g_oData, int iStride, int const iDim)
{
int *iData = g_iData + blockIdx.x * iDim;
// stop condition
if (iStride == 1 && threadIdx.x == 0) {
g_oData[blockIdx.x] = iData[0] + iData[1];
return;
}
// in-place reduction
iData[threadIdx.x] += iData[threadIdx.x + iStride];
// nested invocation to generate child grids
if (threadIdx.x == 0 && blockIdx.x == 0)
gpuRecursiveReduce2<<<gridDim.x, iStride / 2>>>(g_iData, g_oData, iStride / 2, iDim);
}위 커널에서 작업을 수행하지 않는 idle thread은 모두 제거됩니다(첫 번째 커널인 gpuRecursiveReduce는 각 블록에서 절반의 스레드들이 작업을 수행하지 않습니다). 이는 첫 번째 커널이 소모하는 연산 리소스의 절반을 절약하고, 더 많은 스레드 블록들이 active될 수 있도록 해줍니다.
위 커널을 추가하고, 다시 컴파일 후 실행하면 다음의 결과를 확인하실 수 있습니다.

이전 커널들보다 훨씬 더 빨라진 것을 확인할 수 있고, 이제는 cpu의 속도보다 빠릅니다. 이러한 이유를 nvprof를 사용하면 실제로 확인이 가능한데, compute capability 7.0 이상의 디바이스에서는 현재 확인이 불가능한 것 같습니다 ㅠ
아래는 참고문서에서 보여주는 결과이며, device에서의 호출이 16384번에서 8번으로 줄어든 것을 확인할 수 있습니다.

전체 코드는 아래의 링크에서 확인하실 수 있습니다 !
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/reduction/nestedReduce.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
'NVIDIA > CUDA' 카테고리의 다른 글
| Pinned Memory (0) | 2022.01.14 |
|---|---|
| CUDA Memory Model (0) | 2022.01.13 |
| Warp의 Branch Divergence (reduction problem) (0) | 2022.01.08 |
| Nsight Compute로 Warp 성능 측정하기 (0) | 2022.01.07 |
| WARP Execution (3) | 2022.01.05 |




댓글