References
- Professional CUDA C Programming
- https://docs.nvidia.com/nsight-compute/NsightComputeCli/index.html
Contents
- Matrix Addition 예제
- Active Warp 측정
- Memory Operations 측정
WARP Execution
References Professional CUDA C Programming https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/issueefficiency.htm Contents Warps 이해하기 Wa..
junstar92.tistory.com
지난 포스팅에 이어서, 이번에 warp execution의 동작을 조금 더 잘 이해하기 위해서 행렬 덧셈 커널을 다양한 execution configurations를 사용하여 비교해보도록 하겠습니다. 그리고, Nsight Compute를 사용해 커널의 여러 가지 성능을 측정도 수행할 예정입니다.
전체 코드는 아래 링크를 참조해주시기 바랍니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/matrixAdd/matrixAdd2.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
사용되는 커널은 아래의 sumMatrixOnGPU2D 입니다.
__global__
void sumMatrixOnGPU2D(float* A, float* B, float* C, int NX, int NY)
{
unsigned int ix = blockDim.x*blockIdx.x + threadIdx.x;
unsigned int iy = blockDim.y*blockIdx.y + threadIdx.y;
unsigned int idx = iy*NX + ix;
if (ix < NX && iy < NY) {
C[idx] = A[idx] + B[idx];
}
}사용되는 행렬의 크기는 \(2^{14} \times 2^{14}\) 입니다.
그리고 커널을 실행할 때 사용할 block dimension은 커맨드 입력이 주어지지 않는다면 (32, 32)입니다. 변경하려면 실행할 때 커맨드 라인 argument로 지정할 수 있습니다. 전체 코드는 위 링크를 참조해주세요.
int main(int argc, char** argv)
{
...
// setup data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
...
// invoke kernel at host
int dimx = 32;
int dimy = 32;
if (argc > 2) {
dimx = atoi(argv[1]);
dimy = atoi(argv[2]);
}
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
...
}
이제 다음의 커맨드로 컴파일합니다.
nvcc -O3 -arch=sm_75 -o matrixAdd2 matrixAdd2.cu -I..컴파일이 완료되면, 실행 가능한 파일이 생성됩니다.
Checking Active Warps
먼저, 기본적인 특정 스레드 configuration으로 성능을 평가해보겠습니다. 사용할 스레드 블록의 크기는 (32, 32) / (32, 16) / (16, 32) / (16, 16) 입니다.
제 노트북으로 실행한 결과입니다.

교재에서는 스레드 블록 별로 성능의 차이가 약간 발생하는데, 수치상으로 성능의 차이는 확인할 수 없는 것 같습니다.
이전 포스팅에서 active warp의 수를 최대한으로 유지해야 GPU를 최대한으로 활용할 수 있다고 했습니다.
nvprof를 사용하면 '--metrics achieved_occupancy' 옵션으로 사이클 당 평균 active warp의 수와 SM에서 지원하는 최대 warp 수의 비율을 측정할 수 있습니다. 저의 경우에는 nvprof를 사용할 수 없었기 때문에 Nsight Compute를 통해 이를 측정했습니다.
Nsight Compute를 사용하면, '--metrics sm__warps_active.avg.pct_of_peak_sustained_active'를 사용하면 동일하게 측정할 수 있습니다.
ncu.bat --metrics sm__warps_active.avg.pct_of_peak_sustained_active ./matrixAdd2.exe 32 32
성능의 차이가 거의 나지 않기 때문에 active warp의 비율 또한 큰 차이는 없습니다. 다만, 블록의 수가 증가할수록 이 비율이 커질 줄 알았습니다만, (32, 32)일 때의 비율이 (16, 32)일 때의 비율보다 크게 나와서 의외였습니다. 그래도 (16, 16)일 때 블록의 수가 더 많기 때문에 비율이 조금 더 큰 것을 볼 수 있는 것 같습니다.
하지만 가장 높은 achieved occupancy라고, 가장 빠르지는 않습니다. 그러므로 높은 occupancy가 항상 높은 성능을 가지는 것도 아닙니다.
Checking Memory Operations
sumMatrixOnGPU2D 커널은 두 번의 메모리 load와 한 번의 메모리 store, 총 3개의 메모리 연산(C[idx] = A[idx] + B[idx])이 있습니다. 이 메모리 연산의 효율성도 측정할 수 있습니다.
nvprof의 경우에는 '--metrics gld_throughput'으로 측정할 수 있으며, Nsight Compute의 경우에는 l1tex__t_bytes_pipe_lsu_mem_global_op_ld.sum.per_second metrics을 사용하여 측정할 수 있습니다.
ncu.bat --metrics l1tex__t_bytes_pipe_lsu_mem_global_op_ld.sum.per_second ./matrixAdd2.exe 32 32위 커맨드로 Global Memory Load 효율을 측정한 결과는 다음과 같습니다.

큰 차이는 없지만, 수치상으로 (16, 16)이 가장 높은 load 처리량을 보여주고 있습니다. 마찬가지로 load 처리량이 높다고, 높은 성능이라는 것은 아닙니다.
다음으로 Global load efficiency를 측정해보겠습니다. nvprof로는 'gld_efficiency' metrics으로 측정할 수 있고, Nsight Compute로는 'smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct'로 측정할 수 있습니다.
이는 required global memory load 처리량 대비 requested globa memory load 처리량의 비율입니다.
ncu.bat --metrics smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct ./matrixAdd2.exe 32 32
모두 100%로 측정됩니다. 메모리를 요구하는대로 바로바로 요청했다고 해석할 수 있을 것 같습니다.
그렇다면 block.x를 더 조절하면 결과는 어떨까요 ?
더 다양한 범위의 thread configuration으로 테스트를 해보도록 하겠습니다.
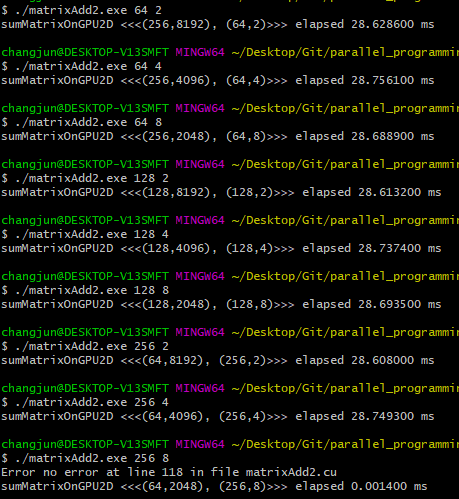
여러 크기의 thread block으로 테스트한 결과입니다. 대부분 유사한 성능을 보여주고 있습니다. 마지막의 (256, 8)로는 커널을 실행할 수 없는데, 이는 제 GPU에서 블록당 최대 스레드의 개수가 1024개이기 때문입니다.
유의미한 성능의 차이는 보여주지 않고 있습니다.
다음으로 각 크기에서 achieved_occupancy를 측정해보도록 하겠습니다.
(64, 2) / (64, 4) / (64, 8)일 때의 결과입니다.
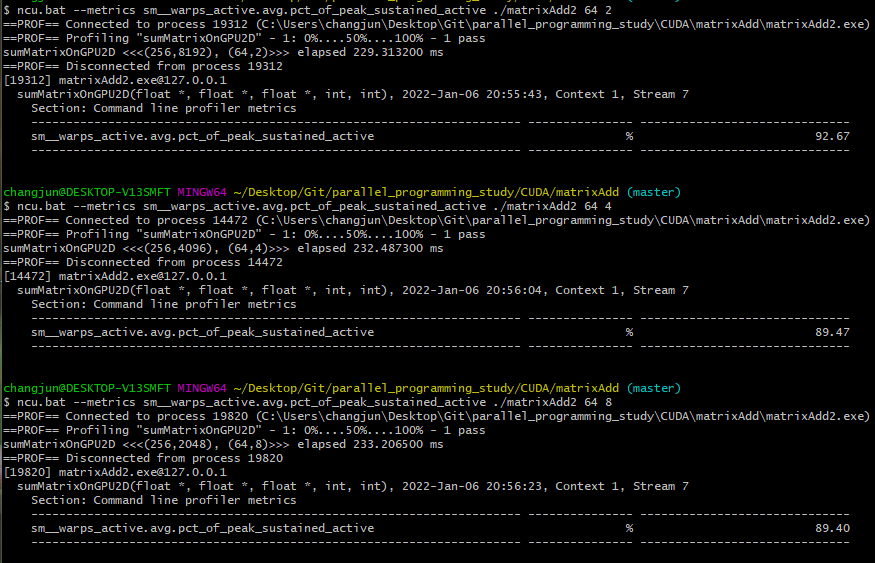
다음은 (128, 2) / (128, 4) / (128, 8)일 때의 결과입니다.

다음은 (256, 2) / (256, 4) 일 때의 결과입니다.

(128, 8)일 때 가장 좋은 결과를 보여주고 있으며, (256, 4)일 때도 높은 occupancy를 보여줍니다.
여러 가지 조건으로 성능을 측정했지만, 유의미한 성능의 차이는 크게 보이지 않고 그 결과 또한 비교할만큼의 큰 차이를 보여주지 않았습니다. 최근 디바이스들의 성능이 다들 좋아져서 그런 것도 있겠지만, 다음에는 조금 더 복잡한 커널을 통해서 분석하는 기회를 가지도록 하겠습니다. 이번 포스팅에서는 Nsight Compute에 대한 사용법을 조금이나마 익히는 것으로 만족합니다.. ! ㅠ
'NVIDIA > CUDA' 카테고리의 다른 글
| Nested Reduction (Dynamic Parallelism) (0) | 2022.01.11 |
|---|---|
| Warp의 Branch Divergence (reduction problem) (0) | 2022.01.08 |
| WARP Execution (3) | 2022.01.05 |
| CUDA Dynamic Parallelism (동적 병렬) (2) | 2022.01.01 |
| Graph Search (Breadth-First Search) (0) | 2021.12.30 |




댓글