References
- Professional CUDA C Programming
Contents
- Coalescing Global Memory Accesses
- Matrix Transpose Kernels
- Matrix Transpose with Shared Memory
- Matrix Transpose with Padded Shared Memory
- Matrix Transpose with Unrolling
Shared Memory (2) - Square/Rectangular Shared Memory
Shared Memory (3) - Reduction with Shared Memory
지난 포스팅들에 이어 Shared Memory에 대한 4번째 포스팅입니다
Coalescing Global Memory Accesses
지금까지 Shared Memory의 이점들에 대해서 알아보고 있는데, Share Memory를 사용하면 non-coalesced global memory 액세스를 피할 수 있습니다. Matrix Transpose가 이에 대한 좋은 예제인데, transpose 커널들을 비교하며 진행해보도록 하겠습니다.
Baseline Transpose Kernel
먼저 뒤에서 살펴볼 커널들을 비교하기 위한 baseline 커널인 matrix transpose의 naive 구현을 먼저 살펴보겠습니다. 이 커널은 오직 global memory만을 사용합니다.
__global__ void naiveGmem(float* in, float* out, const int nRows, const int nCols) { // matrix coordinate (ix, iy) unsigned int row = blockIdx.y * blockDim.y + threadIdx.y; unsigned int col = blockIdx.x * blockDim.x + threadIdx.x; // transpose with boundary test if (row < nRows && col < nCols) { out[col*nRows + row] = in[row*nCols + col]; } }
col은 이 커널의 2D thread configuration의 innermost 차원(x차원)에 속하기 때문에, global memory read operation은 warp내에서 병합됩니다. 반면에 global memory write operation은 이웃 스레드 간에 strided access로 수행됩니다. naiveGmem 커널의 성능은 이번 포스팅에서 측정하는 matrix transpose의 하한값이 됩니다.
write operation이 병합된(coalesced) 액세스를 수행하도록 변경하면 이는 copy 커널이 됩니다. read와 write가 모두 병합되지만 I/O의 양은 동일하게 수행합니다. 따라서, copy 커널인 copyGmem은 성능의 상한값이 됩니다.
__global__ void copyGmem(float* in, float* out, const int nRows, const int nCols) { // matrix coordinate (ix, iy) unsigned int row = blockIdx.y * blockDim.y + threadIdx.y; unsigned int col = blockIdx.x * blockDim.x + threadIdx.x; // transpose with boundary test if (row < nRows && col < nCols) { out[row*nCols + col] = in[row*nCols + col]; } }
커널 테스트에서 matrix의 사이즈는 4096 x 4096으로 설정하고, 2D thread block은 32x16 차원을 사용합니다.
전체 코드와 main 코드는 아래 링크의 코드를 참조해주세요 !
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
위 두 코드를 실행한 결과는 다음과 같습니다.

naiveGmem이 copyGmem보다 약 3배가량 느립니다. naiveGmem은 global memory에 4096의 stride를 가지고 write를 수행하기 때문에 하나의 warp로부터 store memory operation는 32 global memory transaction으로 처리됩니다.
이는 nsight compute의 global load/store transcation per request 메트릭으로 확인해볼 수 있습니다.
실행 커맨드는 다음과 같습니다.
ncu.bat --metrics l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_ld.ratio,l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_st.ratio ./transposeRectangular.exe아래는 nvidia 공식 문서에서 설명하고 있는데 sector/request 에 대한 설명입니다.
만약 이 값이 32라면 이는 각 스레드가 모두 다른 sector에 액세스한다는 의미입니다. 이상적으로 warp 내에서 하나의 정렬된 32 bit 값을 각 스레드가 액세스한다면, 이 값은 4가 되며 이는 모든 연속된 8개의 스레드들이 동일한 sector에 액세스한다는 것을 의미합니다. (값이 높으면 uncoalesced memory accesses가 있다는 것을 의미합니다.)
Matrix Transpose with Shared Memory
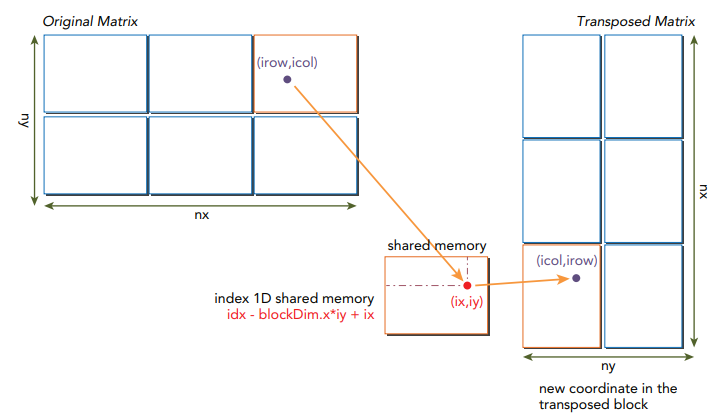
strided global memory 액세스를 피하기 위해서, 2D shared memory를 사용하여 원본 행렬로부터 데이터를 캐싱할 수 있습니다. 2D shared memory로부터 읽은 column은 global memory에 저장되는 전치된 행렬의 row로 전달할 수 있습니다. naive 구현은 shared memory에서 bank conflict를 발생시키는 반면, 병합되지 않은 global memory 액세스보다는 성능이 더 좋습니다. 아래 그림은 행렬 전치(matrix transpose)에서 shared memory가 어떻게 사용되는지 보여줍니다.
아래 구현된 커널 transposeSmem은 shared memory를 사용하여 행렬 전치를 수행합니다.
__global__ void transposeSmem(float* in, float* out, const int nRows, const int nCols) { // static shared memory __shared__ float tile[BDIMY][BDIMX]; // coordinate in original matrix unsigned int row = blockIdx.y * blockDim.y + threadIdx.y; unsigned int col = blockIdx.x * blockDim.x + threadIdx.x; // linear global memory index for original matrix unsigned int offset = row * nCols + col; if (row < nRows && col < nCols) { // load data from global memory to shared memory tile[threadIdx.y][threadIdx.x] = in[offset]; } __syncthreads(); // thread index in transposed block unsigned int bidx, irow, icol; bidx = threadIdx.y * blockDim.x + threadIdx.x; irow = bidx / blockDim.y; icol = bidx % blockDim.y; // coordinate in transposed matrix row = blockIdx.x * blockDim.x + irow; col = blockIdx.y * blockDim.y + icol; // linear global memory index for transposed matrix unsigned int transposed_offset = row * nRows + col; __syncthreads(); // transpose with boundary test if (row < nCols && col < nRows) { // store data to global memory from shared memory out[transposed_offset] = tile[icol][irow]; } }
위 커널은 크게 5가지의 스텝으로 진행됩니다.
- Warp가 global memory에 저장된 원본 행렬의 블록으로부터 병합된 row read를 수행
- row-major 순으로 1에서 읽은 데이터를 shared memory에 write. 따라서, bank conflict가 발생하지 않음
- 스레드 블록에서 read/write operation이 동기화된 후에, global memory로부터 데이터를 전달받은 2D shared memory가 완성
- Warp는 2D shared memory 배열로부터 column read를 수행. shared memory에 패딩이 없기 때문에 bank conflict가 발생
- global memory에 저장되는 transposed matrix의 row에 병합된 write를 수행
각 스레드가 global과 shared memory로부터 올바른 데이터를 전달하기 위해서 여러 인덱스들이 각 스레드에서 계산되어 사용됩니다. 주어진 스레드로부터, 먼저 thread 인덱스와 block 인덱스를 기반으로 원본 행렬의 좌표를 계산합니다.
// coordinate in original matrix unsigned int row = blockIdx.y * blockDim.y + threadIdx.y; unsigned int col = blockIdx.x * blockDim.x + threadIdx.x;
그리고 이 행렬의 좌표로부터 global memory 배열의 인덱스를 계산합니다.
// linear global memory index for original matrix unsigned int offset = row * nCols + col;
col이 스레드 블록의 innermost 차원이기 때문에, 32개의 스레드로 구성된 warp는 offset을 사용하여 global memory로부터 병합된 read를 수행할 수 있습니다.
유사하게, 전치 행렬의 좌표는 다음과 같이 계산할 수 있습니다.
// coordinate in transposed matrix row = blockIdx.x * blockDim.x + irow; col = blockIdx.y * blockDim.y + icol;
원본 행렬에서 스레드의 좌표 계산과 비교해보면, 크게 2가지 차이점이 있습니다.
하나는 전치 행렬에서 블록의 offset 계산에서 사용된 내장된 blockDim과 blockIdx의 용도가 서로 바뀝니다. thread configuration의 x 차원은 전치 행렬에서 column 좌표를 계산하는데 사용되고, y 차원은 row 좌표를 계산하는데 사용됩니다.
다른 차이점으로는 새로운 변수 irow와 icol이 추가되었습니다. 이 변수는 전치된 블록에 대응되는 인덱스입니다.
bidx = threadIdx.y * blockDim.x + threadIdx.x; irow = bidx / blockDim.y; icol = bidx % blockDim.y;
이를 사용하여 전치 행렬에 저장할 때 사용되는 global memory 인덱스는 다음과 같이 계산됩니다.
unsigned int transposed_offset = row * nRows + col;
계산된 offset들을 사용하여 warp는 global memory로부터 read하고 2D shared memory 배열인 tile에 다음과 같이 write 합니다.
if (row < nRows && col < nCols) { // load data from global memory to shared memory tile[threadIdx.y][threadIdx.x] = in[offset]; }
global memory로 부터의 read는 병합되며, shared memory banks로의 write에서 conflict는 발생하지 않습니다.
그리고 warp는 shared memory로부터 column read를 수행하고, global memory에 연속적인 write를 수행합니다.
if (row < nCols && col < nRows) { // store data to global memory from shared memory out[transposed_offset] = tile[icol][irow]; }
global memory에 대한 write는 병합됩니다만, shared memory로부터의 read는 bank conflict를 유발합니다. 이는 tile에서 column을 따라서 warp가 데이터를 read하기 때문입니다. 아래에서 이러한 bank conflict를 메모리 padding을 사용하여 해결하는 방법에 대해 알아보겠습니다.
아래 그림은 인덱스를 계산하는 방법을 보여줍니다. 여기서 ny는 nRows, nx는 nCols, ix는 icol, iy는 irow에 해당됩니다.
위 커널 함수를 추가하고 실행한 결과입니다.

그리고, nsight compute로 측정한 request당 global memory load/store transaction 결과입니다.
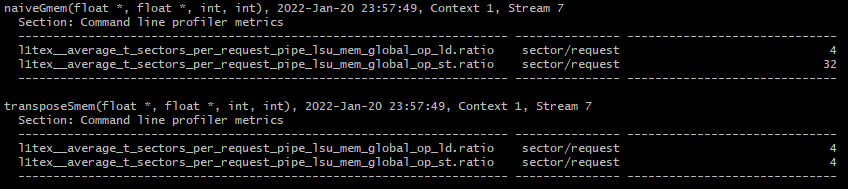
global memory store에 대한 값이 32에서 4로 감소하였습니다. 이는 shared memory의 값을 global memory에 row-major 순으로 저장하도록 변경되었기 때문입니다.
shared memory load/store transaction도 측정해보도록 하겠습니다. 다음의 커맨드로 이를 측정할 수 있습니다.
ncu.bat --metrics l1tex__data_pipe_lsu_wavefronts_mem_shared_op_ld.sum,l1tex__data_pipe_lsu_wavefronts_mem_shared_op_st.sum ./transposeRectangular.exe
계산하면 load transcation과 store transaction의 비율은 8:1 입니다. 따라서, 2D shared memory 배열의 column으로부터의 read가 bank conflict를 발생한다는 것을 확인할 수 있습니다.
Matrix Transpose with Padded Shared Memory
2D shared memory 배열 tile의 각 row에 column padding을 추가하면, 원본 배열의 동일한 column에 위치하는 데이터 원소를 shared memory bank에 고르게 분배할 수 있습니다. 패딩되어야하는 columns의 수는 device compute capability와 스레드 블록의 사이즈에 따라 다릅니다. 현재 테스트에서는 32x16의 스레드 블록을 사용하여 커널을 수행하고 있기 때문에 2개의 column 패딩을 추가해주어야 합니다.
Padding Column을 추가한 transposeSmemPad 커널 함수는 다음과 같습니다. 사용되는 매크로 IPAD의 값은 2 입니다.
__global__ void transposeSmemPad(float* in, float* out, const int nRows, const int nCols) { // static shared memory __shared__ float tile[BDIMY][BDIMX + IPAD]; // coordinate in original matrix unsigned int row = blockIdx.y * blockDim.y + threadIdx.y; unsigned int col = blockIdx.x * blockDim.x + threadIdx.x; // linear global memory index for original matrix unsigned int offset = row * nCols + col; if (row < nRows && col < nCols) { // load data from global memory to shared memory tile[threadIdx.y][threadIdx.x] = in[offset]; } __syncthreads(); // thread index in transposed block unsigned int bidx, irow, icol; bidx = threadIdx.y * blockDim.x + threadIdx.x; irow = bidx / blockDim.y; icol = bidx % blockDim.y; // coordinate in transposed matrix row = blockIdx.x * blockDim.x + irow; col = blockIdx.y * blockDim.y + icol; // linear global memory index for transposed matrix unsigned int transposed_offset = row * nRows + col; __syncthreads(); // transpose with boundary test if (row < nCols && col < nRows) { // store data to global memory from shared memory out[transposed_offset] = tile[icol][irow]; } }
shared memory 배열인 tile은 이제 각 row에 2개의 추가된 column을 포함합니다.
위 커널을 추가하고, 실행한 결과는 다음과 같습니다.

Padding이 없는 커널보다 조금 더 빨라졌고, effecitve bandwidth 또한 증가하였습니다.
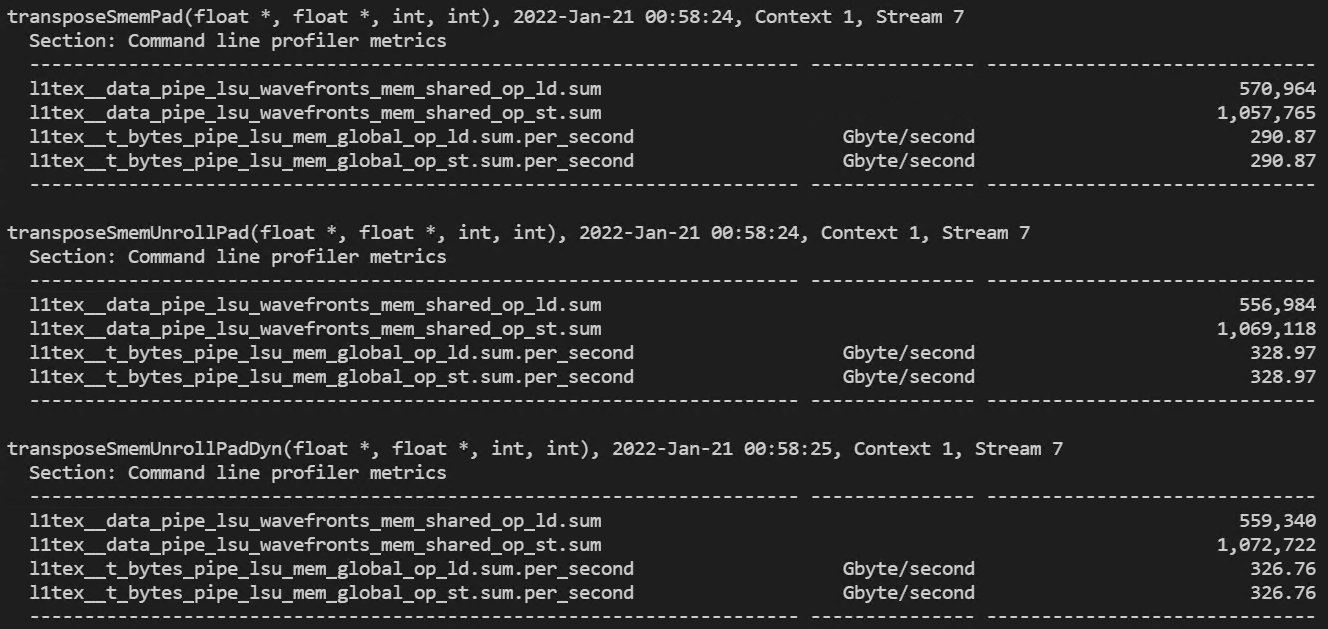
다음으로 shared memory transaction을 측정해보도록 하겠습니다.
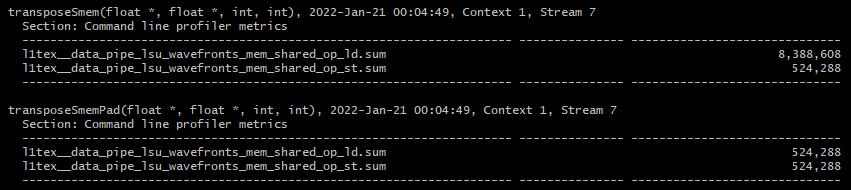
padding이 없을 때에는 load와 store의 transaction 비율이 8:1이었지만, padding을 추가하면 이 비율은 1:1이 됩니다.
Matrix Transpose with Unrolling
다음으로 살펴볼 transpose 커널은 unroll 기법을 적용하여 2개의 데이터 블록을 처리합니다. 각 스레드는 이제 각 데이터 블록만큼 stride된 2개의 원소를 전치시킵니다. 이 커널의 목적은 동시에 더 많은 load/store를 수행하여 디바이스의 memory bandwidth를 향상시키는 것입니다.
커널은 다음과 같습니다.
__global__ void transposeSmemUnrollPad(float* in, float* out, const int nRows, const int nCols) { // static shared memory with padding __shared__ float tile[BDIMY * (2 * BDIMX + IPAD)]; // coordinate in original matrix unsigned int row = blockIdx.y * blockDim.y + threadIdx.y; unsigned int col = 2 * blockIdx.x * blockDim.x + threadIdx.x; // linear global memory index for original matrix unsigned int offset = row * nCols + col; // thread index in transposed block unsigned int bidx = threadIdx.y * blockDim.x + threadIdx.x; unsigned int irow = bidx / blockDim.y; unsigned int icol = bidx % blockDim.y; // coordinate in transposed matrix unsigned int transposed_row = 2 * blockIdx.x * blockDim.x + irow; unsigned int transposed_col = blockIdx.y * blockDim.y + icol; // linear global memory index for transposed matrix unsigned int transposed_offset = transposed_row * nRows + transposed_col; if (col + BDIMX < nCols && row < nRows) { // load two rows from global memory to shared memory unsigned int row_idx = threadIdx.y * (2 * BDIMX + IPAD) + threadIdx.x; tile[row_idx] = in[offset]; tile[row_idx + BDIMX] = in[offset + BDIMX]; } __syncthreads(); if (transposed_row + BDIMX < nCols && transposed_col < nRows) { // store two rows to global memory from two columns of shared memory unsigned int col_idx = icol * (2 * BDIMX + IPAD) + irow; out[transposed_offset] = tile[col_idx]; out[transposed_offset + nRows * BDIMX] = tile[col_idx + BDIMX]; } }
위 커널에서 shared memory 배열 tile은 column padding을 추가하여 1차원으로 선언됩니다.
__shared__ float tile[BDIMY * (2 * BDIMX + IPAD)];
각 스레드에서 input 행렬의 좌표와 global memory 배열에 액세스하기 위한 인덱스는 다음과 같이 계산됩니다.
// coordinate in original matrix unsigned int row = blockIdx.y * blockDim.y + threadIdx.y; unsigned int col = 2 * blockIdx.x * blockDim.x + threadIdx.x; // linear global memory index for original matrix unsigned int offset = row * nCols + col;
그리고 shared memory에 전치된 블록에서 배열에 액세스하기 위한 인덱스와 해당 블록에서의 좌표는 다음과 같이 계산할 수 있습니다.
// thread index in transposed block unsigned int bidx = threadIdx.y * blockDim.x + threadIdx.x; unsigned int irow = bidx / blockDim.y; unsigned int icol = bidx % blockDim.y;
shared memory 배열인 tile이 1차원이기 때문에 2차원 스레드 인덱스는 패딩된 1차원 shared memory에 액세스하기 위해서 다음과 같이 변환되어야 합니다.
unsigned int row_idx = threadIdx.y * (2 * BDIMX + IPAD) + threadIdx.x; unsigned int col_idx = icol * (2 * BDIMX + IPAD) + irow;
패딩된 메모리는 데이터를 저장하는데 사용하지 않기 때문에, 이 메모리들은 인덱스를 계산할 때 스킵됩니다.
마지막으로 전치 행렬에서의 output 행렬 좌표와 global memory 배열에 대응되는 인덱스를 계산합니다.
// coordinate in transposed matrix unsigned int transposed_row = 2 * blockIdx.x * blockDim.x + irow; unsigned int transposed_col = blockIdx.y * blockDim.y + icol; // linear global memory index for transposed matrix unsigned int transposed_offset = transposed_row * nRows + transposed_col;
이렇게 위에서 계산된 인덱스를 사용하여, 각 스레드는 global memory의 row에서 2개의 원소를 읽고, 이를 shared memory에 row로 저장합니다.
if (col + BDIMX < nCols && row < nRows) { // load two rows from global memory to shared memory unsigned int row_idx = threadIdx.y * (2 * BDIMX + IPAD) + threadIdx.x; tile[row_idx] = in[offset]; tile[row_idx + BDIMX] = in[offset + BDIMX]; }
shared memory에 저장하고 동기화를 시켜준 다음, shared memory의 column으로 2개의 원소를 읽고, 이를 global memory에 row로 저장합니다.
if (transposed_row + BDIMX < nCols && transposed_col < nRows) { // store two rows to global memory from two columns of shared memory unsigned int col_idx = icol * (2 * BDIMX + IPAD) + irow; out[transposed_offset] = tile[col_idx]; out[transposed_offset + nRows * BDIMX] = tile[col_idx + BDIMX]; }
github 코드에는 동일한 커널 함수에서 동적으로 shared memory를 선언한 커널 함수 transposeSmemUnrollPadDyn도 있으니, 참고하시길 바랍니다.
실행 결과는 다음과 같습니다.

예상과 다르게 transposeSmemPad보다 오히려 bandwidth가 더 떨어졌습니다. 이는 제 GPU에서 제한된 리소스들 때문이라고 예상하여, 조금 더 좋은 GPU에서 다시 테스트해봤습니다.

RTX 3080으로 테스트해 본 결과, transposeSmemPad 보다 조금 더 좋은 bandwidth가 측정되었습니다.
2개의 블록을 unrolling하여 더 많은 요청을 동시에 처리하여 read/write 처리량을 조금 향상되었습니다.
이를 확인하기 위해서 nsight compute를 통해 Device Memory Read/Write Throughput을 측정해보겠습니다.
ncu.bat --metrics dram__bytes_read.sum.per_second,dram__bytes_write.sum.per_second ./transposeRectangular.exe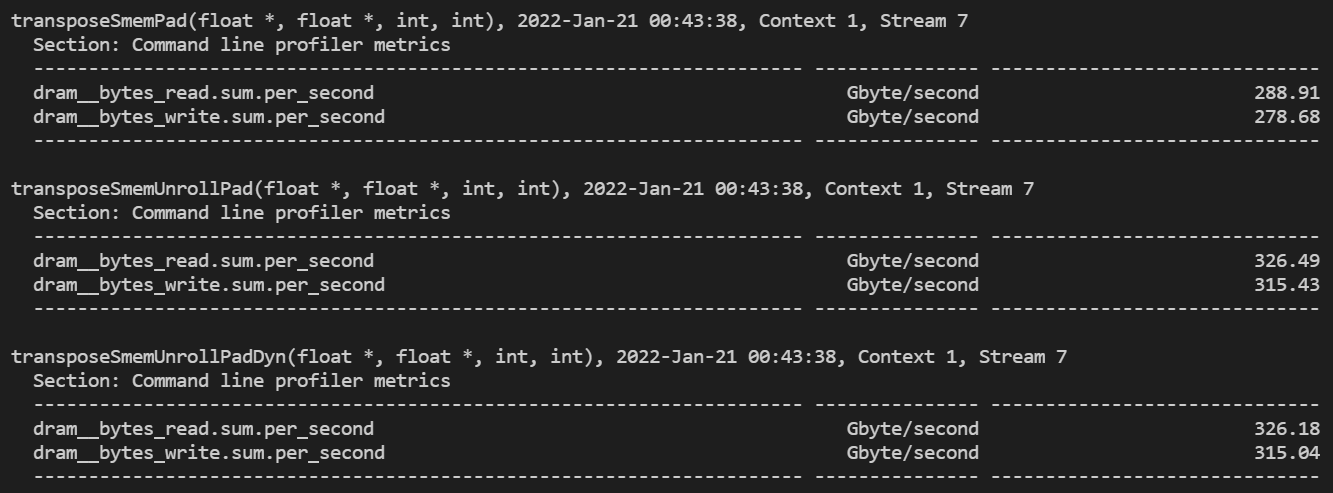
측정 결과는 위와 같습니다. Unrolling 기법을 적용하면, 적용하지 않았을 때보다 약 1.13배 가량 처리량이 증가한 것을 확인할 수 있습니다.
Exposing More Parallelism
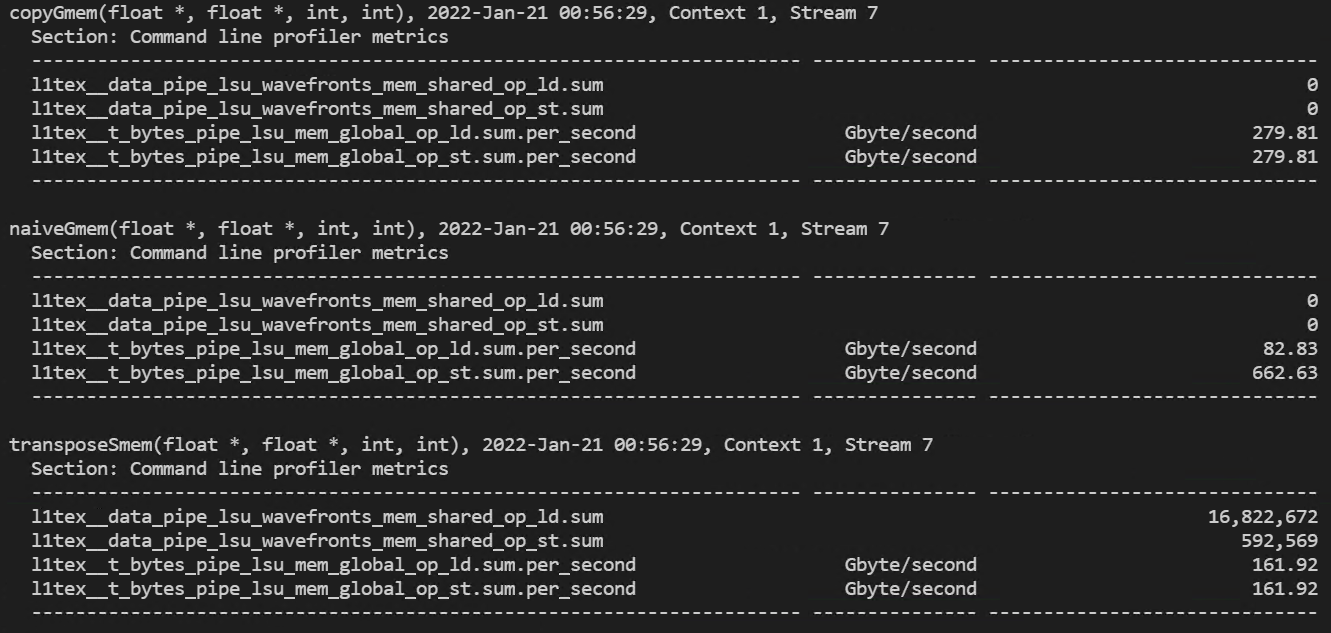
간단하지만 효과적인 최적화 방법은 execution configuration의 스레드 블록의 차원을 조정하는 것입니다. 위에서 32x16의 스레드 블록에서 커널들을 실행시켜봤는데, 이번에는 32x32와 16x16에서의 커널 결과를 간단하게 살펴보고 이번 포스팅을 마무리 하겠습니다.
- 32x16 thread block 실행 결과

(dram read/write 처리량)
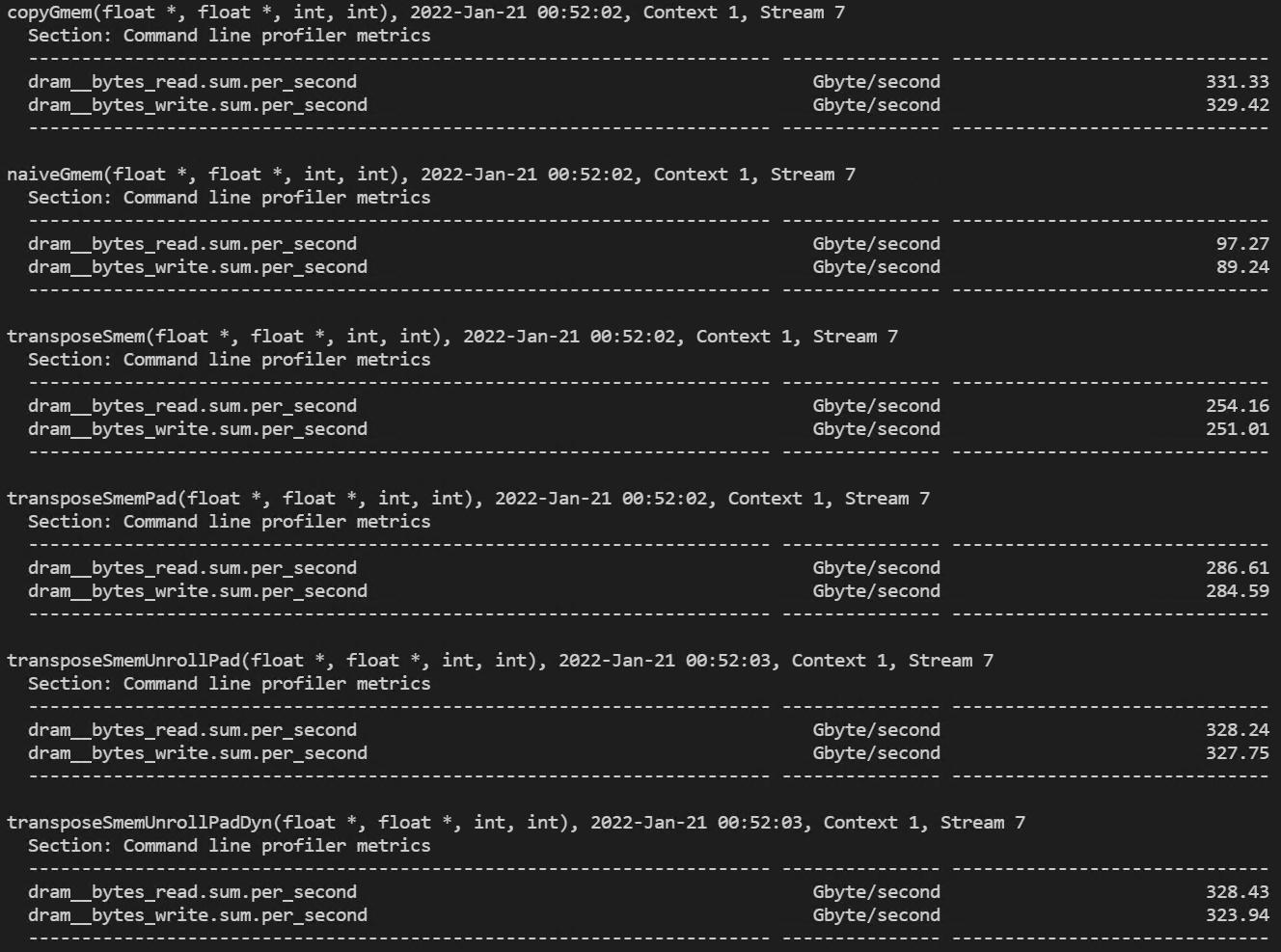
(global memory 처리량과 shared memory load/store transactions)
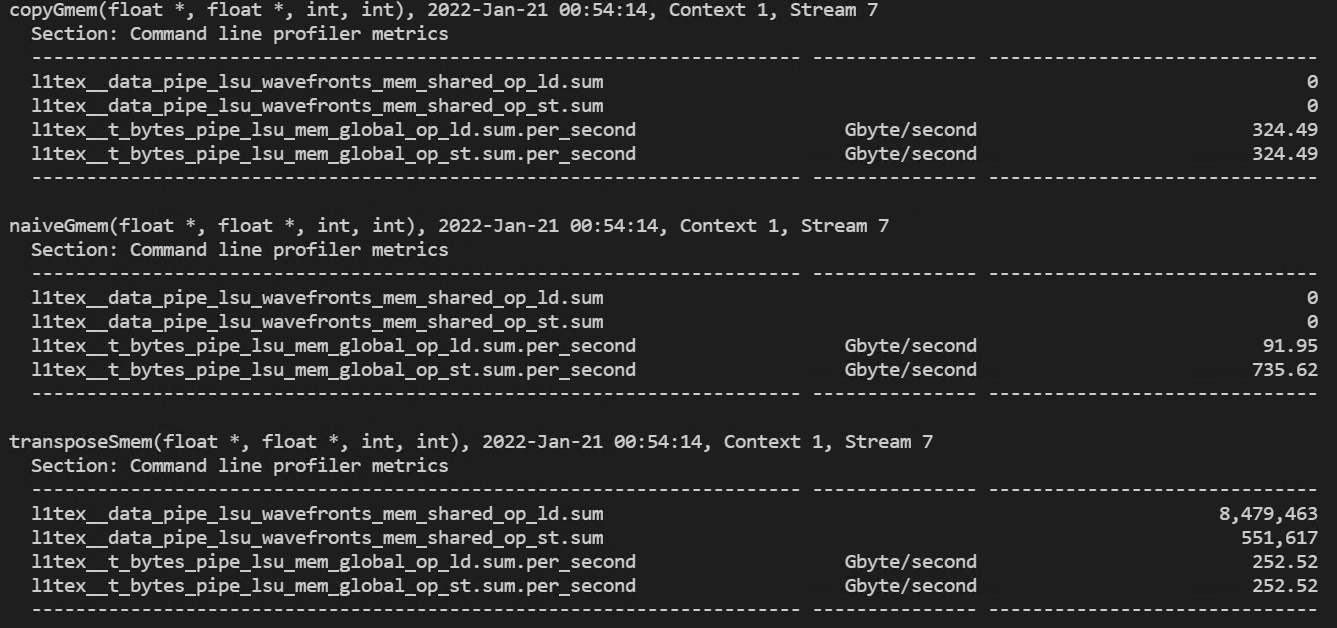
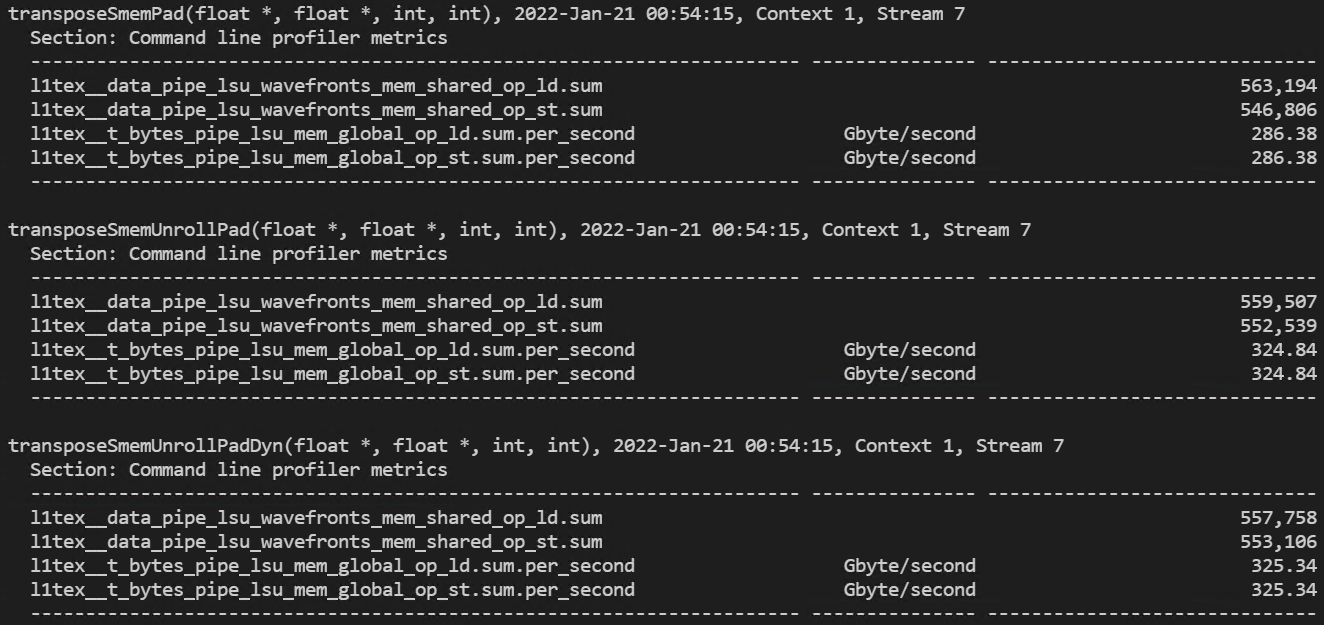
- 32x32 thread block 실행 결과

(dram read/write 처리량)
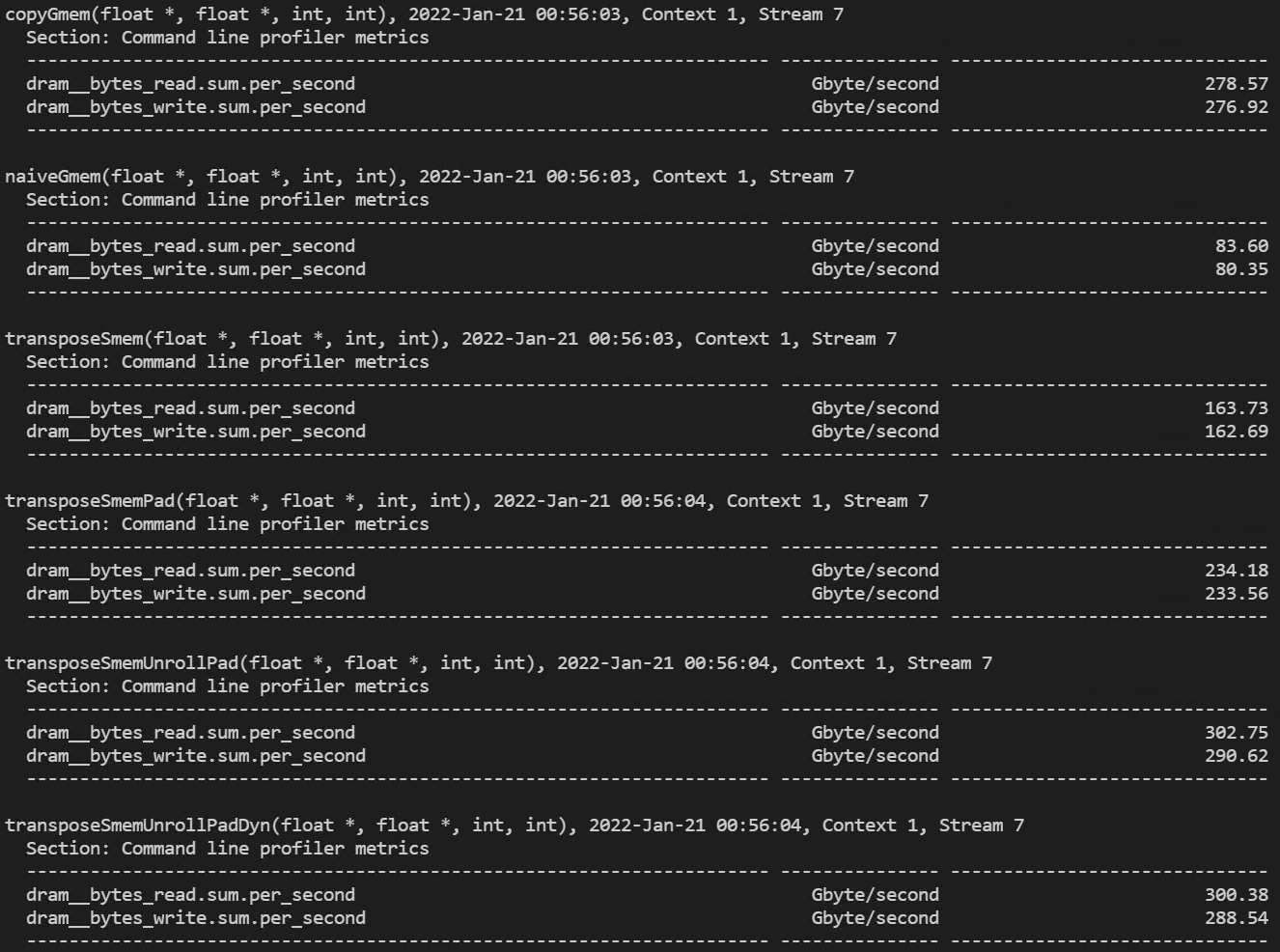
(global memory 처리량과 shared memory load/store transactions)
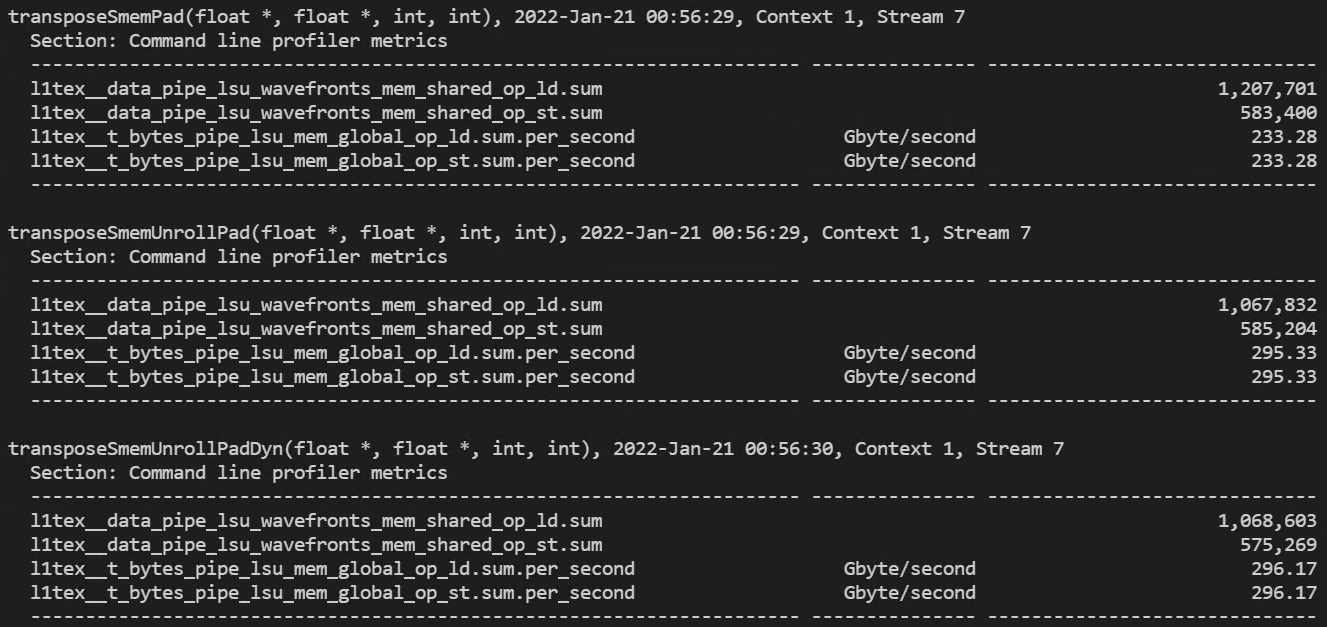
- 16x16 thread block 실행 결과

(dram read/write 처리량)
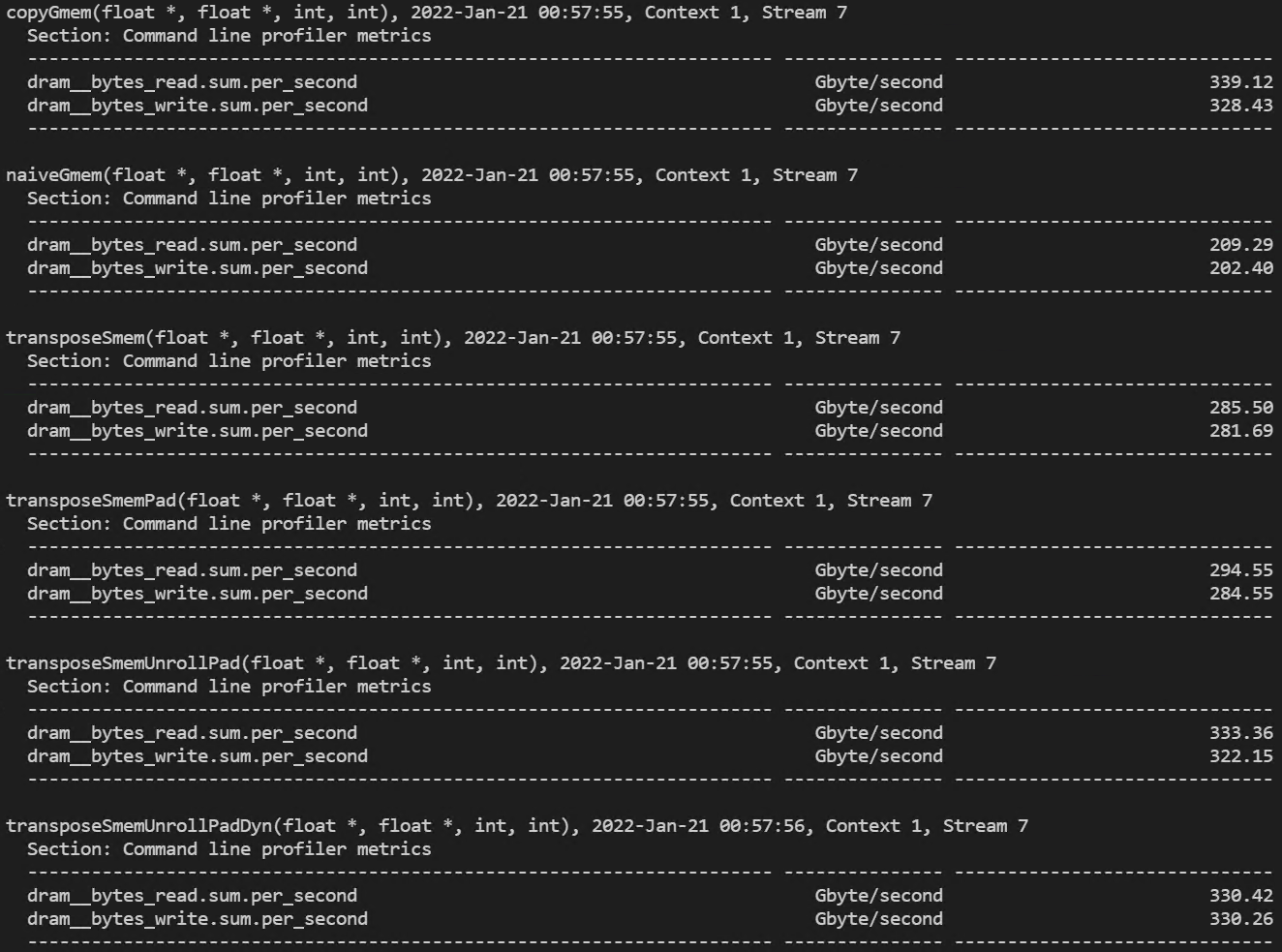
(global memory 처리량과 shared memory load/store transactions)
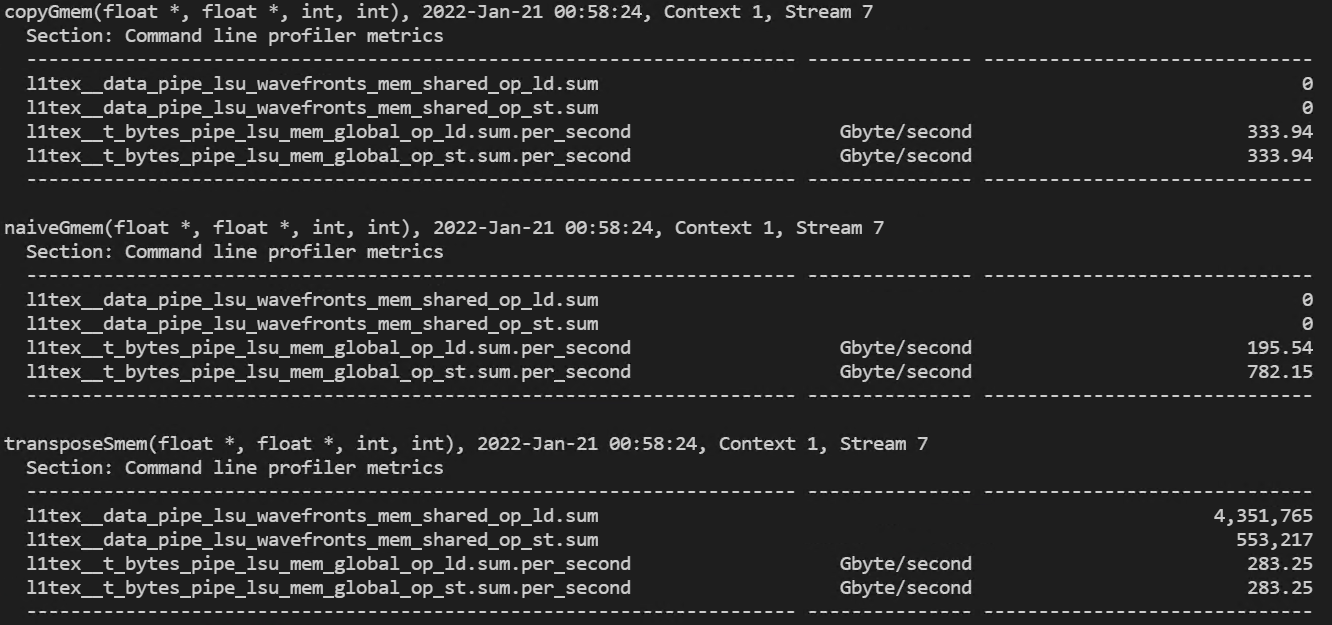
드라마틱한 성능의 변화를 보여주지는 않습니다.. !
'NVIDIA > CUDA' 카테고리의 다른 글
| Streams and Events (1) (0) | 2022.01.23 |
|---|---|
| Warp Shuffle Instruction (0) | 2022.01.23 |
| Shared Memory (3) - Reduction with Shared Memory (0) | 2022.01.20 |
| Shared Memory (2) - Square/Rectangular Shared Memory (0) | 2022.01.19 |
| Shared Memory (1) (0) | 2022.01.18 |




댓글