References
- Professional CUDA C Programming
Contents
- Warp Shuffle Instruction
- Parallel Reduction Using the Warp Shuffle Instruction
The Warp Shuffle Instruction
Kepler Architecture(compute capability 3.0 이상)부터, shuffle instruction이 도입되어 스레드들이 직접 동일 warp의 다른 스레드들의 레지스터를 읽을 수 있게 되었습니다.
Shuffle Instruction은 warp 내의 스레드들이 global이나 shared memory를 사용하지 않고 직접적으로 서로 data를 교환할 수 있게 해줍니다. 또한, shared memory보다 더 짧은 latency를 가지고 있으며, 데이터를 교환하기 위해 추가 메모리도 사용하지 않습니다. 그러므로, shuffle instruction은 어플리케이션에서 동일 warp 내 스레드끼리 데이터를 빠르게 주고 받을 수 있는 아주 유용한 방법입니다.
warp 내의 스레드들 간에 수행되는 Shuffle Instruction에서 먼저 warp의 lane이라는 개념을 알아보겠습니다. lane은 간단히 warp 내의 single thread를 가리킵니다. warp의 각 스레드는 [0, 32] 범위에서 유일한 lane index로 식별됩니다. 하지만, 동일한 스레드 블록에 있는 여러 스레드가 동일한 lane index를 가질 수는 있습니다.
그러나 thread index처럼 lane index를 위한 build-in 변수는 없습니다. lane index를 알기 위해서는 계산이 필요한데, 1차원 스레드 블록에서 lane index와 warp index는 다음과 같이 계산할 수 있습니다.
laneID = threadIdx.x % 32
warpID = threadIdx.x / 32예를 들어, 스레드 블록에서 스레드 1과 스레드 33은 둘 다 lane ID는 1이지만, 다른 warp ID를 가집니다.
2D 스레드 블록에서는 2D 스레드 좌표를 1D 스레드 좌표로 변환하고 위의 공식을 적용하여 lane과 warp index를 계산할 수 있습니다.
Variants of the Warp Shuffle Instruction
CUDA에는 두 가지의 shuffle instruction 세트가 있습니다. 하나는 integeer 변수를 위한 것이고 다른 하나는 float 변수를 위한 것입니다. 각 세트에는 4가지의 shuffle instruction이 있습니다.
먼저 warp 내에서 integer 변수를 교환하기 위한 기본 함수는 다음과 같습니다.
int __shfl(int var, int srcLane, int width=warpSize);내장된 instruction인 __shfl은 lane ID값(정확히는 shuffle ID)이 srcLane인 스레드로부터 전달된 var 값을 리턴합니다. srcLane의 의미는 width의 값에 따라서 달라집니다. 이 함수는 warp 내의 각 스레드가 특정 스레드에서 직접 값을 가져올 수 있도록 해줍니다. 이 작업은 warp 내의 모든 active 스레드에서 동시에 수행되며 스레드당 4 바이트의 데이터를 이동합니다.
선택적으로 width 변수는 2~32사이의 2의 거듭제곱 값으로 설정될 수 있습니다. 기본값은 warpSize(=32)로 설정되면, shuffle instruction은 전체 warp 내에서 수행되고 srcLane은 source thread의 lane index가 됩니다. 그러나 width를 설정하면 width개의 스레드를 포함하는 각 세그먼트로 분할되어 각 세그먼트에서 별도의 shuffle operation을 수행할 수 있습니다. width의 값이 32가 아닌 경우, 스레드의 lane ID와 shuffle operation에서의 ID는 같지 않습니다. 이런 경우에 1차원 스레드 블록에서 스레드의 shuffle ID는 다음과 같이 계산됩니다.
shuffleID = threadIdx.x % width;
예를 들어, 다음의 인자들로 워프의 모든 스레드에서 __shfl 함수가 호출된다고 가정해봅시다.
int y = __shfl(x, 3, 16);그러면 스레드 0~15는 스레드 3으로부터 x 값을 전달받고, 스레드 16~31은 스레드 19로부터 x 값을 전달받습니다. 간단하게, srcLane은 lane index를 width로 나눈 나머지를 가리킵니다.
아래 그림은 __shfl 함수가 지정된 lane으로부터 모든 스레드로 broadcast operation을 수행하는 것을 보여줍니다.

다른 shuffle operation으로는 __shfl_up이 있습니다.
int __shfl_up(int var, unsigned int delta, int width=warpSize)__shfl_up은 이를 호출한 스레드의 lane index에서 delta만큼 빼서 source lane index를 계산합니다. 그리고 source thread로에서 전달된 value의 값을 리턴합니다. 결과적으로 이 instruction은 warp 내의 var 값을 delta만큼 shift하는 것과 같습니다.
하지만, 아래 그림처럼 source가 존재하지 않는 스레드가 있기 때문에 delta가 2인 경우에 스레드 0~1의 값은 변경되지 않습니다.

세 번째 shuffle instruction은 __shfl_down 입니다.
int __shfl_down(int var, unsigned int delta, int width=warpSize)__shfl_down은 이를 호출한 스레드의 lane index에서 delta만큼을 더하여 source lane index를 계산하고, __shfl_up과 반대로 delta 만큼 shift 합니다. 마찬가지로 source가 존재하지 않는 스레드가 있으므로, 아래 그림과 같이 그런 스레드의 값은 변경되지 않습니다.

마지막 shuffle instruction은 __shfl_xor 입니다.
int __shfl_xor(int var, int laneMask, int width=warpSize)이 함수는 이를 호출한 스레드의 lane index와 laneMask를 XOR 연산하여 source lane index를 계산합니다. 그리고 해당 source thread로부터 전달된 var 값을 리턴합니다. 이 명령은 butterfly addressing pattern으로 데이터를 교환합니다.
이번 포스팅에서 살펴볼 모든 shuffle function은 단정도(single-precision) 부동소수점(floating-point)에서도 지원합니다. 부동소수점 shuffle function은 float var 인자를 취하고, float 값을 리턴합니다. 사용법은 integer shuffle function과 동일합니다.
이제 여러 예제들을 통해서 몇 가지 타입에 대한 shuffle instruction의 동작을 살펴보도록 하겠습니다.
아래에서 수행되는 커널들은 모두 16개의 스레드로 구성된 단일 1차원 블록으로 실행됩니다.
#define BDIMX 16아래의 커널들과 main 실행 함수는 아래 링크에서 참조하시길 바랍니다.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
Broadcast of a Value accross a Warp
아래 커널은 warp-level broadcast operation을 구현한 것입니다. 각 스레드는 value 변수라는 하나의 레지스터를 가지고 있습니다. source lane은 srcLane으로부터 지정되고, 이 값은 모든 스레드에서 동일합니다. 각 스레드는 직접 source thread로부터 값을 복사합니다.
__global__
void test_shfl_broadcast(int* in, int* out, const int srcLane)
{
int value = in[threadIdx.x];
value = __shfl(value, srcLane, BDIMX);
out[threadIdx.x] = value;
}0부터 15까지의 값을 가지는 배열에서 srcLane의 값을 2로 설정하여 커널을 수행하면,
test_shfl_broadcast<<<1,block>>>(d_in, d_out, 2);결과는 다음과 같습니다.

3번째 스레드(lane 2)의 값이 모든 스레드로 broadcast 되었습니다.
Shift Up within a Warp
다음 커널은 suffle shift-up operation을 구현한 것입니다.
__global__
void test_shfl_up(int* in, int* out, const unsigned int delta)
{
int value = in[threadIdx.x];
value = __shfl_up(value, delta, BDIMX);
out[threadIdx.x] = value;
}delta를 2로 설정하여 커널을 실행하면,
test_shfl_up<<<1,block>>>(d_in, d_out, 2);다음의 결과를 확인할 수 있습니다.

Shift Down within a Warp
다음은 shift-down operation을 수행하는 커널 함수입니다.
__global__
void test_shfl_down(int* in, int* out, const unsigned int delta)
{
int value = in[threadIdx.x];
value = __shfl_down(value, delta, BDIMX);
out[threadIdx.x] = value;
}
delta를 2로 설정하여 실행한 결과는 다음과 같습니다.

Shift within a warp with Warp Around
다음 커널은 shift warp-around operation을 구현한 것입니다.
각 스레드의 source lane은 자신의 lane index에서 offset을 더하여 결정되므로 각 스레드에서는 다른 source lane을 갖습니다. 이 offset은 음수도 가능합니다.
__global__
void test_shfl_warp(int* in, int* out, const int offset)
{
int value = in[threadIdx.x];
value = __shfl(value, threadIdx.x + offset, BDIMX);
out[threadIdx.x] = value;
}offset을 2로 설정하여 실행하면, 원래의 값에서 왼쪽으로 shift된 결과를 볼 수 있습니다.

하지만 test_shfl_down에 의한 결과와는 다르게, 오른쪽 끝의 lane들도 값이 바뀐 것을 확인할 수 있습니다.
offset을 -2로 설정하고 실행해보겠습니다.

오른쪽으로 shift된 결과를 얻을 수 있으며, 마찬가지로 test_shfl_up 커널의 결과와는 다르게 왼쪽 끝의 lane들도 값이 변경되었습니다.
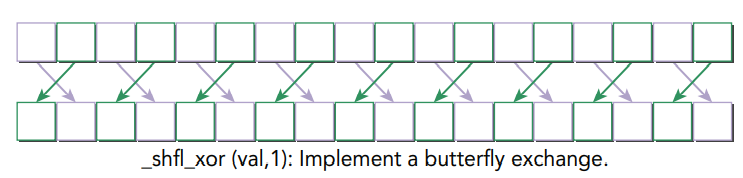
Butterfly Exchange across the Warp
다음은 두개의 스레드 간의 butterfly addressing pattern을 구현한 커널입니다.
__global__
void test_shfl_xor(int* in, int* out, const int mask)
{
int value = in[threadIdx.x];
value = __shfl_xor(value, mask, BDIMX);
out[threadIdx.x] = value;
}mask의 값을 1로 설정하여 실행한 커널의 결과는 다음과 같습니다.

Exchange Values of an Array across a Warp
커널 내에서 레지스터 배열을 사용하는 경우를 고려해보면, 워프 내에서 스레드들 간의 데이터 일부를 교환하는 경우가 발생할 수 있습니다. 이때, warp 내의 스레드 간의 배열의 원소들을 교환할 수 있는 shuffle instruction이 있습니다.
아래의 커널에서, 각 스레드는 크기가 SEGM=4인 레지스터들의 배열 value를 가지고 있습니다. 각 스레드는 global memory in으로부터 데이터들을 value로 읽어들이고, mask에 의해 결정된 이웃 스레드의 데이터들과 교환합니다. 그리고 교환한 데이터를 다시 global memory 배열인 out에 write합니다.
__global__
void test_shfl_xor_array(int* in, int* out, const int mask)
{
int idx = threadIdx.x * SEGM;
int value[SEGM];
for (int i = 0; i < SEGM; i++)
value[i] = in[idx + i];
value[0] = __shfl_xor(value[0], mask, BDIMX);
value[1] = __shfl_xor(value[1], mask, BDIMX);
value[2] = __shfl_xor(value[2], mask, BDIMX);
value[3] = __shfl_xor(value[3], mask, BDIMX);
for (int i = 0; i < SEGM; i++)
out[idx + i] = value[i];
}예제에서 커널 내부 배열의 크기는 4로 설정되었고, SEGM의 값이 4로 매크로를 통해 정의되어있습니다.
각 스레드가 4개의 원소를 가지고 있기 때문에, 블록 사이즈는 원래 크기의 1/4로 줄어들어야 합니다. 따라서, 커널은 다음과 같이 실행됩니다.
test_shfl_xor_array<<<1,BDIMX / SEGM>>>(d_in, d_out, 1);실행 결과는 다음과 같습니다.

Parallel Reduction Using the Warp Shuffle Instruction
Shared Memory (3) - Reduction with Shared Memory
위 포스팅에서 shared memory를 사용하여 reduction problem을 어떻게 해결할 수 있는지 살펴봤습니다.
이번 포스팅의 마지막으로 warp shuffle instruction을 사용하여 reduction problem을 해결하는 방법에 대해서 알아보겠습니다.
기본 아이디어는 간단합니다.
- Warp-level reduction
- Block-level reduction
- Grid-level reduction
스레드 블록은 여러 개의 warp를 가지고 있습니다. warp-level reduction에서 각 warp는 각자 reduction을 수행합니다. Shared memory를 사용하는 대신, 각 스레드는 레지스터를 사용하여 global memory로부터 하나의 데이터 원소를 저장합니다.
int mySum = g_iData[idx];Warp-level reduction은 다음의 inline 함수로 구현될 수 있습니다.
__inline__ __device__
int warpReduce(int mySum)
{
mySum += __shfl_xor(mySum, 16);
mySum += __shfl_xor(mySum, 8);
mySum += __shfl_xor(mySum, 4);
mySum += __shfl_xor(mySum, 2);
mySum += __shfl_xor(mySum, 1);
return mySum;
}이 함수로부터 값을 리턴받으면 각 warp의 sum을 thread index와 warp size에 기반하여 shared memory에 저장합니다.
int laneIdx = threadIdx.x % warpSize;
int warpIdx = threadIdx.x / warpSize;
// block-wide warp reduce
mySum = warpReduce(mySum);
// save warp sum to shared memory
if (laneIdx == 0)
smem[warpIdx] = mySum;
Block-level reduction에서, 블록은 동기화되고 나서, 동일한 warp reduction 함수를 사용하여 각 warp의 sum을 더합니다. 블록에 의해서 생성되는 최종 결과값은 블록의 첫 번째 스레드에 의해서 global memory에 저장됩니다.
__syncthreads();
// last warp reduce
mySum = (threadIdx.x < DIM) ? smem[laneIdx] : 0;
if (warpIdx == 0)
mySum = warpReduce(mySum);
// write reulst for this block to global mem
if (threadIdx.x == 0)
g_oData[blockIdx.x] = mySum;
Grid-level reduction은 host로 g_oData의 값들을 복사하여 host에서 reduction을 수행합니다.
완전히 구현된 reduceShfl 커널은 다음과 같습니다. 여기서 SMEMDIM(=4)은 블록의 x 차원(=128)을 warp(=32)의 크기로 나눈 값입니다.
__global__
void reduceShfl(int* g_iData, int* g_oData, unsigned int n)
{
// shared memory for each warp sum
__shared__ int smem[SMEMDIM];
// boundary check
unsigned int idx = blockDim.x * blockIdx.x + threadIdx.x;
if (idx >= n)
return;
// read from global memory
int mySum = g_iData[idx];
// caculate lane index and warp index
int laneIdx = threadIdx.x % warpSize;
int warpIdx = threadIdx.x / warpSize;
// block-wide warp reduce
mySum = warpReduce(mySum);
// save warp sum to shared memory
if (laneIdx == 0)
smem[warpIdx] = mySum;
__syncthreads();
// last warp reduce
mySum = (threadIdx.x < SMEMDIM) ? smem[laneIdx] : 0;
if (warpIdx == 0)
mySum = warpReduce(mySum);
// write reulst for this block to global mem
if (threadIdx.x == 0)
g_oData[blockIdx.x] = mySum;
}
위 커널과 실행 함수가 구현된 코드는 아래 링크를 참조해주세요.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
컴파일 후, nvprof로 성능을 측정해보면 다음의 결과를 확인하실 수 있습니다.

단순히 Shared Memory를 사용한 reduceSmem 커널에 비해서 약 1.4배 가량 빨라졌습니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| Streams and Events (2) - Concurrent Kernels (0) | 2022.01.24 |
|---|---|
| Streams and Events (1) (0) | 2022.01.23 |
| Shared Memory (4) - Matrix Transpose (0) | 2022.01.22 |
| Shared Memory (3) - Reduction with Shared Memory (0) | 2022.01.20 |
| Shared Memory (2) - Square/Rectangular Shared Memory (0) | 2022.01.19 |




댓글