References
- Programming Massively Parallel Processors
Contents
- Histogram
- atomicAdd의 사용
- Memory Coalescing을 고려한 Histogram 커널
- Atomic 연산에 의한 시간지연 문제
- Privatized Histogram Kernel
히스토그램(histogram)은 데이터 항목의 빈도를 연속적인 숫자 간격으로 표시하는 것입니다. 히스토그램의 일반적인 형태에 데이터 항목의 빈도는 수평축에 상승하는 직사각형 또는 막대의 높이로 표시됩니다.
예를 들어, "programming massively parallel processors"라는 문장에서 알파벳의 빈도를 표시하기 위해서 히스토그램이 사용될 수 있습니다. 간단하게 살펴보기 위해서 문장이 모두 소문자로 구성되었다고 가정한다면, 해당 문장에서는 'a'가 4번, 'b'가 0번, 'c'가 1번 등장한다는 것을 알 수 있습니다. 알파벳 4개씩 묶어서 표신한다고 하면, 히스토그램은 아래의 이미지처럼 나타낼 수 있습니다.

히스토그램은 데이터 집합의 요약된 정보를 제공해줍니다. 위 예제에서는 문장이 중간 위치에 해당하는 알파벳들이 집중적으로 나온다는 것을 확인할 수 있습니다. 이처럼 히스토그램의 모양을 살펴보면 데이터 집합에 유의미한 현상이 있는지 빠르게 확인할 수 있습니다.
히스토그램은 아래의 코드처럼 시퀀셜한 방법으로 쉽게 계산할 수 있습니다. 아래 코드에서는 단순화를 위해 소문자만을 인식합니다. 아래 코드는 각 문자로부터 인덱스를 계산하고, 4개씩 묶어서 카운트하고 있습니다.
void sequential_Histogram(char* data, int n, int* histo) { for (int i = 0; i < n; i++) { int alphabet_pos = data[i] - 'a'; if (alphabet_pos >= 0 && alphabet_pos < 26) histo[alphabet_pos/4]++; } }
위 코드는 매우 간단하고 효율적입니다. 데이터 배열의 원소들은 for루프에서 순차적으로 액세스되므로 DRAM에서 데이터를 가지고 올 때, CPU 캐시 라인이 잘 사용될 것입니다. 또한, histo 배열은 크기가 작기 때문에 CPU의 L1 캐시에서 위치하여 매우 빠르게 업데이트할 수 있을 것입니다.
Atomic Operation
히스토그램을 병렬로 계산하기 위한 첫 번째 방법은 입력 배열을 섹션별로 누나고 각 스레드가 섹션 중의 하나를 할당받아서 해당 섹션을 처리하도록 하는 것입니다. 아래 그림은 각 섹션의 크기를 6으로 하고, 4개의 스레드를 사용하여 각 스레드가 할당된 섹션을 처리하는 모습을 보여주고 있습니다.
각 스레드는 할당된 섹션을 반복하여 각 문자의 인터벌 카운트를 증가시킵니다. 위 그림은 첫 번째 반복에서 4개의 스레드에 의해 수행되는 동작을 보여주고 있습니다. 스레드 0, 1, 3은 모두 동일한 인터벌 카운터(m~p)를 업데이트해야 하는데, 이는 output interference(출력 간섭)라고 합니다. 병렬처리에서 이러한 출력 간섭을 안전하게 처리하기 위해서는 race condition과 atomic operation의 개념을 이해하고 있어야 합니다. 아마 스레드나 다른 병렬 처리에 대해서 이미 알고 있다면 해당 내용에 대해서는 잘 알고 있으리라 생각됩니다.
histo 배열에서 인터벌 카운터의 증가는 메모리 위치에 대한 업데이트, 즉, 읽기-수정-쓰기(read-modify-write) 작업입니다. read-modify-write 작업은 동시에 수행되는 스레드에서 안전하게 수행되도록 해주어야 합니다.
예를 들어, 항공권을 예매할 때, 예약 가능한 좌석을 찾고(read), 예매할 좌석을 고르고(modify), 좌석 상태를 예약 불가능한 상태로 변경(write)하는 것이라고 볼 수 있습니다. 이러한 상황에서 아래와 같은 좋지 않은 시나리오가 발생할 수 있습니다.
- 두 고객이 동시에 같은 항공편의 좌석 리스트를 읽음
- 두 고객이 동시에 9C라는 좌석을 선택
- 두 고객의 좌석 9C의 상태를 예약불가능상태로 변경
이러한 시퀀스를 수행한 후에, 두 고객 모두 9C 좌석을 예매했다고 결론을 내리게 되는데 이러한 상황은 문제를 발생시킬 수 있습니다. (실제 항공 예약 프로그램의 결함으로 발생할 수 있습니다.)
위와 같은 바람직하지 않은 결과는 관련된 태스크의 상대적인 타이밍에 따라 두 개 이상의 업데이트가 동시에 발생했을 때 결과가 달라지는 race condition이라는 현상에 의해서 발생합니다. 아래 그림은 두 개의 스레드가 동일한 histo 배열 원소를 업데이트하려고 했을 때의 race condition을 보여줍니다.
(A)는 스레드 2가 Time 4에서 시퀀스를 시작하기 전에 스레드 1이 Time 1~3 동안 read-modify-write 시퀀스를 모두 완료한 시나리오를 보여줍니다. 각 연산 앞에 괄호 안에 있는 숫자는 각 대상의 값입니다. (A) 시나리오는 정상적으로 histo[x]의 값이 0에서 2로 시퀀스가 종료되는 것을 보여줍니다.
반면에 (B)의 경우에는 두 스레드의 read-modify-write 시퀀스가 서로 겹칩니다. 스레드 1인 Time 4에서 새로운 값을 histo[x]에 write합니다. 하지만 스레드 2가 Time 3에서 histo[x]를 읽은 값은 0입니다. 그 결과 스레드 2에서 최종적으로 계산되는 New 값은 2가 아닌 1이 됩니다. 여기서 문제는 스레드 2가 스레드 1의 업데이트가 완료되기 전에 histo[x]의 값을 읽어서 발생하고, 스레드 1에 의한 업데이트가 소실되었습니다.
병렬 실행 중에 스레드는 서로 상대적인 순서로 실행될 수 있습니다. 위 예제에서 스레드 2가 스레드 1보다 먼저 업데이트 시퀀스를 시작할 수도 있다는 것을 의미합니다.
누가 먼저 수행하던간에 위와 같은 시퀀스에서는 부정확한 결과를 초래할 수 있습니다.
이와 같은 문제는 스레드 1과 스레드 2의 연산을 서로 겹치지 못하도록 막아서 해결할 수 있습니다. 즉, 위 그림에서 (A) 시나리오만을 허용하고 (B)와 같은 시나리오가 발생하지 않도록 하는 것입니다.
이러한 제약은 atomic operation을 통해서 수행할 수 있습니다.
메모리 위치에서 atomic 연산은 해당 메모리 위치에서 read-modify-write 작업이 다른 read-modify-write 작업과 겹치지 않도록 수행하는 연산입니다. 연산의 read, modify, write가 분리될 수 없는 단위를 형성하기 때문에 atomic 이라는 이름이 붙었습니다. 실제로 atomic 연산은 하드웨어의 지원을 받아서 현재 작업이 완료될 때까지 다른 스레드가 동일한 위치에서 동작하지 못하도록 합니다. 따라서 위 예제에서 (B)와 같은 가능성을 제거하게 됩니다.
atomic 연산은 특정한 순서로 스레드가 실행되도록 하지는 않습니다. 따라서 위 예제에서 Thread 1이 먼저 수행되거나 Thread 2가 먼저 수행되는 건 상관이 없고 둘 다 허용됩니다. 두 스레드 중 하나라도 먼저 동일한 메모리 위치에서 atomic 연산을 시작하면 선행 스레드가 이 연산을 완료할 때까지 다른 스레드는 해당 메모리 위치에 대한 연산을 수행할 수 없습니다.
atomic 연산은 수행되는 연산에 따라 명명되는데, 위 예제에서는 메모리 위치에 값을 더하기 때문에 atomic add라고 합니다. 다른 연산 명령으로는 subtraction, increment, decrement, minimum, maximum, logical and, logical or 등이 있습니다.
CUDA에서 메모리 위치에 대한 atomic add 연산을 지원하기 위해서 atomicAdd 라는 API를 제공합니다.
이 함수는 전역 또는 공유 메모리 주소를 인자로 전달받고, 해당 위치의 값에 val을 더하고 그 결과를 동일한 주소의 메모리에 저장하는 atomic 연산 명령어입니다. 이 함수는 해당 주소의 이전 값을 반환합니다.
아래 코드는 위에서 설명한 방법으로 병렬 히스토그램 계산을 수행하는 CUDA 커널 함수입니다.
__global__ void histo_kernel(char* data, int n, int* histo) { int i = blockDim.x*blockIdx.x + threadIdx.x; int section_size = (n - 1) / (blockDim.x * gridDim.x) + 1; int start = i*section_size; for (int k = 0; k < section_size; k++) { if (start + k < n) { int alphabet_pos = data[start+k] - 'a'; if (alphabet_pos >= 0 && alphabet_pos < 26) atomicAdd(&histo[alphabet_pos/4], 1); } } }
line 4에서 각 스레드의 전역 스레드 인덱스를 계산하고, line 5에서 각 스레드에서 처리되는 데이터의 수를 계산합니다. 만약 1000개의 문자가 입력으로 주어지고 256개의 스레드를 가진 1개의 블록으로 병렬 히스토그램 커널을 수행하면, 로 한 스레드당 4개의 요소를 처리하고, 처음 250개의 스레드만 활성화될 것입니다.
line 6에서는 각 스레드에서 처리할 데이터의 시작 포인트를 계산합니다. 1000개의 입력과 256개의 스레드로 구성된 하나의 블록이라면 각 스레드에서 처리되는 데이터의 시작 지점은 i*4가 됩니다. 스레드 0은 0, 스레드 8은 32, 이런식으로 시작 지점이 계산되겠습니다.
line 8의 for 루프는 시퀀스 코드와 유사합니다. 이는 각 스레드가 할당된 섹션에 대해서 시퀀셜한 히스토그램 계산을 수행하기 때문입니다. 그리고 for문 내부에서 alphabet_pos의 계산이 첫 번째 if (start + k < n)에 의해서 보호됩니다. 이는 유효한 입력 데이터만을 액세스하도록 보장해줍니다.
그리고 line 12에서 atomicAdd() 함수를 사용하여 histo[alphabet_pos/4]의 값을 1 증가시킵니다. 만약 atomicAdd 함수가 아닌 단순히 histo[alphabet_pos/4]++; 로 값을 증가시키면 race conditon이 발생하여 잘못된 결과를 도출합니다.
아래의 결과는 atomicAdd 함수를 사용하지 않고, 1000개의 입력을 256개의 스레드로 구성된 하나의 블록으로 병렬 히스토그램 커널을 실행했을 때의 결과입니다. 1000개의 입력을 count하면 최종 histo 배열의 모든 원소의 값이 1000이 되어야 하는데, 41로 나오고 있습니다.

동일한 함수를 atomicAdd만 사용하여 실행시켜보면,

정상적으로 1000으로 카운트하는 것을 볼 수 있습니다.
위 커널의 실행 코드는 아래 링크에서 확인하실 수 있습니다. 이 코드에서 입력 데이터의 초기값은 랜덤하게 'a'부터 'z'값으로 설정됩니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/histogram/histogram.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
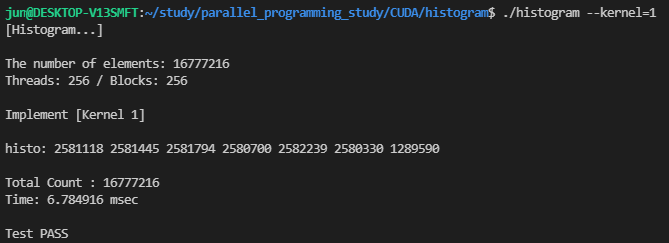
16,666,216개의 입력과 256개의 스레드, 256개의 블록으로 실행하면 다음의 결과를 얻을 수 있습니다.
Memory Coalescing을 고려한 히스토그램 커널
위에서 구현한 병렬 히스토그램 커널은 입력 데이터의 요소를 연속된 요소들의 섹션으로 나누고, 각 블록의 스레드에 할당합니다. 이러한 파티셔닝 전략을 블록 파티셔닝(block partitioning)이라고 합니다. 이렇게 데이터를 연속된 블록으로 분할하는 것은 직관적이고 간단한 방법입니다. CPU에서는 병렬 수행에 적은 수의 스레드만이 실행될 수 있으므로, 보통 블록 파티셔닝의 가장 좋은 방법이 됩니다. 각 CPU 캐시는 일반적으로 적은 수의 스레드만을 지원하므로 서로 다른 스레드에 의한 캐시 간섭이 거의 없습니다.
하지만 GPU의 경우, SM에 동시에 활성화되노 스레드의 수가 많으면 일반적으로 캐시에서 너무 많은 간섭이 발생하여 스레드에 의한 시퀀셜한 액세스(for문)에 캐시 라인의 데이터를 계속 사용할 수 있다고 확신할 수 없습니다. 오히려, memory coalescing(메모리 병합)을 가능하게 위해서 워프의 스레드가 연속적인 위치에 접근하도록 해야합니다.
즉, 입력 데이터를 분할하는 방법에 약간의 수정이 필요합니다.
아래 이미지는 텍스트 히스토그램 예제에서 바람직한 액세스 패턴을 보여줍니다.
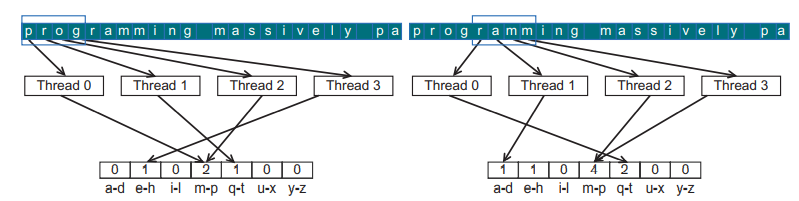
위 이미지에서 첫 번째 반복동안 4개의 스레드는 0부터 3까지의 문자('prog')에 액세스합니다. 메모리 병합 덕분에, 모든 요소들은 한번의 DRAM 액세스에 의해 fetch됩니다. 두 번째 반복에서는 4개의 스레드가 'ramm'이 하나의 병합된 메모리 요청에 의해 액세스됩니다. 여러 위치에 대한 메모리 액세스를 하나로 병합하여 요청하기 때문에 캐시와 SM 사이의 대역폭을 더욱 효율적으로 활용할 수 있게 됩니다.
아래 코드는 방금 설명한 데이터 파티셔닝 방법을 적용한 새로운 병렬 히스토그램 커널입니다.
__global__ void histo_kernel_2(char* data, int n, int* histo) { int tid = blockDim.x*blockIdx.x + threadIdx.x; for (int i = tid; i < n; i += blockDim.x*gridDim.x) { int alphabet_pos = data[i] - 'a'; if (alphabet_pos >= 0 && alphabet_pos < 26) atomicAdd(&histo[alphabet_pos/4], 1); } }
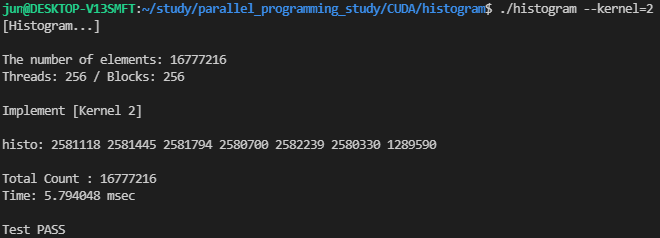
처음 살펴본 커널과 동일한 조건으로 수정된 커널을 수행해보면, 성능이 약간 향상되었음을 확인할 수 있습니다.
Atomic 연산에 의한 시간 지연 문제
지금까지 살펴본 두 개의 히스토그램 커널에서 사용된 atomic 연산은 동일한 위치에서의 동시 업데이트를 겹치지 않도록하여 업데이트의 정확성을 보장합니다. 아시다시피, 병렬 프로그램의 어떤 부분을 직렬화하면 실행 시간이 크게 증가하고 프로그램의 실행 속도도 느려집니다. 따라서 이러한 직렬화된 작업이 실행 시간은 최대한 적게 차지하도록 하는 것이 중요합니다.
DRAM 데이터의 액세스 시간은 수백의 클럭 사이클이 걸릴 수 있습니다. GPU는 zero-cycle context switching을 사용하여 이러한 지연시간을 기다리지 않도록 합니다. 메모리 액세스 지연시간이 서로 겹치는 스레드가 많은 한, 실행 속도는 메모리 시스템의 처리량에 의해 제한됩니다. 따라서 GPU는 DRAM Bursts, 뱅크, 채널을 최대한 활용해야 높은 메모리 처리량을 달성할 수 있습니다.
여기서, 높은 메모리 액세스 처리량의 핵심은 많은 DRAM 액세스가 동시에 진행되어야 한다는 것입니다. 하지만, 많은 atomic 연산이 동일한 메모리 위치를 업데이트하게 되면 DRAM 액세스를 동시에 수행할 수 없게 됩니다. 즉, 선행 스레드의 read-modify-write 시퀀스가 완료될 때까지 후행 스레드의 read-modify-write 시퀀스는 실행될 수 없고, 아래 그림처럼 동일한 메모리 위치에 대한 atomic 연산은 단위 시간동안 오직 하나만 실행됩니다.
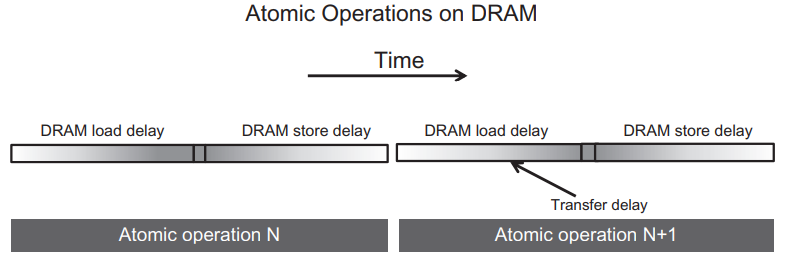
각 atomic 연산의 수행 시간은 대략 memory read 지연시간 + memory write 지연시간입니다. 위 그림에서 보여주는 read-modify-write 연산의 섹션 길이는 각 atomic 연산이 수행되는 최소한의 시간을 정의하고, 이는 작업이 수행될 수 있는 속도를 제한합니다.
예를 들어, 64-bit Double Data Rate DRAM interface, 8 channels, 1GHz clock freq, 액세스 지연시간이 200cycle인 메모리 시스템이 있다고 가정해보겠습니다. 메모리 시스템의 최대 액세스 처리량은 8(bytes/transfer) * 2(transfers per clock per channel) * 1G (clocks per second) * 8 (Channels) = 128GB/second 입니다. 각 액세스 데이터가 4바이트라고 가정한다면 시스템은 초당 32G 데이터 요소의 최대 액세스 처리량을 갖습니다.
그러나 특정 메모리 위치에서 atomic 연산을 수행할 때 얻을 수 있는 가장 높은 처리량은 400사이클마다 atomic 연산 1회입니다 (200 사이클 for read / 200 사이클 for write). 이를 시간을 기준으로하는 처리량을 계산하면, 1/400 (atomics/clock) * 1G (clocks per second) = 2.5M (atomics/second)가 됩니다. 이는 대부분의 사용자들이 GPU 메모리 시스템에서 기대하는 것보다 훨씬 낮은 수치입니다.
실제로 모든 atomic 연산이 단일 메모리 위치에서 수행되는 것은 아닙니다. 위 예제 코드에서는 히스토그램에 7개의 구간이 있습니다. 입력 문자(알파벳)이 균일하게 분포되어 있다면 atomic 연산은 histo[] 배열 요소에 고르게 분포할 것입니다. 따라서, 처리량이 7 * 2.5M = 17.5M (atomics/second)로 증가하게 됩니다. 현실에서 알파벳 문자는 편향된 분포를 갖는 경향이 있기 때문에 실제 성능은 17.5M보다는 낮은 성능을 얻을 것입니다.
위에서 살펴본 두 종류의 히스토그램 커널의 경우 atomic 연산이 실행 속도에 상당한 영향을 미칠 것입니다. 이 처리량은 GPU에서 제공하는 일반적인 최대 처리량의 극히 일부입니다. 따라서, 히스토그램 계산의 속도를 향상시키기 위해서 또 다른 최적화가 필요합니다.
atomic 연산으로 인해 메모리 액세스 지연시간이 길어지므로, 이를 해결하기 위해서는 스레드가 서로 경쟁하는 위치에 대한 메모리 액세스 대기 시간을 줄여야 합니다.
캐시 메모리는 메모리 액세스 대기 시간을 줄여주는 주요 도구입니다. 최신 GPU는 모든 SM이 공유하는 LL(last level) 캐시에서 atomic 연산이 수행될 수 있도록 해줍니다. atomic 연산 중에 업데이트된 변수가 LL 캐시에 존재한다면 이 캐시에서 바로 업데이트됩니다. 만약 LL 캐시에서 찾을 수 없는 경우 cache miss를 트리거하고 캐시로 해당 변수를 가지고 옵니다. atomic 연산에 의해 업데이트되는 변수들은 많은 스레드에 의해 액세스되는 경향이 있기 때문에 이러한 변수들은 일단 DRAM에서 가져오면, 캐시에 남아있는 경향이 있습니다. LL 캐시에 대한 액세스 시간은 수백 사이클이 아닌 수십 사이클로 처리되므로, LL 캐시에서 atomic 연산의 처리는 성능을 수십 배 이상 향상시켜줍니다.
Priavatization
공유 메모리에 데이터를 저장함으로써 메모리에 액세스하는 지연 시간을 크게 줄일 수 있습니다. 공유 메모리는 각 SM의 private 메모리이며 액세스 지연시간이 매우 짧습니다 (a few cycle). 이러한 지연 시간의 감소는 atomic 연산의 처리량의 증가로 직결됩니다. 문제는 공유 메모리의 private한 특성으로 인해 한 스레드 블록에서의 업데이트는 다른 블록에서 알 수 없다는 것입니다. 따라서, 각 스레드 블록에서의 히스토그램 값 업데이트를 합쳐주는 작업이 필요합니다.
일반적으로 privatization이라고 불리는 기법은 병렬 컴퓨팅에서 output interference 문제를 해결하기 위해 사용됩니다. 이 기법의 아이디어는 스레드간 경쟁이 심한 output 데이터 구조를 private 복사본으로 복사하여 각 스레드가 이 private 복사본을 업데이트하도록 하는 것입니다. 이 기법은 장법은 private 본사본에 대한 경쟁은 기존보다 훨씬 적고 지연시간이 훨씬 짧다는 것입니다. 대신 이렇게 private 복사본에 저장된 결과값들은 연산이 완료된 후에 원본 데이터에 병합하는 추가 작업이 필요합니다. 따라서, 이 장단점 사이에서 신중하게 균형을 맞추어야 합니다. (일반적으로 privatization은 개별 스레드가 아닌 스레드의 subsets에서 수행됩니다.)
텍스트 히스토그램을 다시 살펴보면, 각 스레드 블록에 대한 private 히스토그램을 만들 수 있습니다. 여기서 수백 개의 스레드가 짧은 지연시간을 가지는 공유 메모리에 저장된 히스토그램의 복사본에 값을 업데이트하는데, 이는 기존의 DRAM에 저장된 히스토그램에 수만 개의 스레드가 값을 업데이트하는 것과 대비하여 매우 빠르게 수행될 것입니다.
이렇게 경쟁하는 스레드가 감소하고 액세스 지연 시간이 단축되면 처리량이 크게 증가할 수 있습니다.
아래 코드는 privatization 기법을 적용한 히스토그램 커널 함수입니다. 여기서 n_bins는 히스토그램의 막대 개수를 의미합니다. (알파벳 소문자를 4개씩 묶었기 때문에, 코드에서 이 값은 7이 됩니다.)
__global__ void histo_privatized_kernel(char* data, int n, int* histo, int n_bins) { int tid = blockDim.x*blockIdx.x + threadIdx.x; // Privatized bins extern __shared__ int histo_s[]; if (threadIdx.x < n_bins) histo_s[threadIdx.x] = 0u; __syncthreads(); // histogram for (int i = tid; i < n; i += blockDim.x*gridDim.x) { int alphabet_pos = data[i] - 'a'; if (alphabet_pos >= 0 && alphabet_pos < 26) atomicAdd(&histo_s[alphabet_pos/4], 1); } __syncthreads(); // commit to global memory if (threadIdx.x < n_bins) { atomicAdd(&histo[threadIdx.x], histo_s[threadIdx.x]); } }
각 스레드 블록은 블록 내의 공유 메모리 배열인 histo_s에 값을 업데이트하게 됩니다. 전체 스레드가 경쟁했던 것과는 달리 이제 블록 내의 스레드끼리만 경쟁하게 되므로, 지연시간이 크게 감소하게 됩니다.
코드를 살펴보면, line 7-10에서 먼저 공유 메모리에 위치한 histo_s 배열의 값을 0으로 초기화해줍니다. 초기화가 모두 완료된 후에 각 스레드가 값을 업데이트하기 시작해야 하므로, 초기화 후에는 __syncthreads() 함수를 호출하여 동기화해주어야 합니다.
그리고 line 13-17에서 각 스레드에 할당된 데이터들을 처리하고, 그 결과를 histo_s 배열에 업데이트합니다. 블록 내 스레드끼리는 동일한 공유 메모리 위치에 액세스하므로, atomic 연산으로 histo_s 요소의 값을 업데이트해야 합니다.
이 연산이 끝나면, 이제 원본 데이터로 각 히스토그램 결과값을 업데이트합니다. 마찬가지로 전역 메모리에 위치한 histo 요소를 동시에 업데이트하므로, atomicAdd를 통해 값을 업데이트해야하는데, 히스토그램의 막대 개수가 7개이므로 경쟁하는 스레드의 총 개수는 7*gridDim.x개가 되고, 각 histo 요소 당 gridDim.x개의 스레드가 경쟁합니다. 이는 수만 개의 스레드가 전역 메모리 배열에 경쟁하던 상황에 비하면 매우 적습니다.
이 커널을 실행하면 다음의 성능 결과를 얻을 수 있습니다.
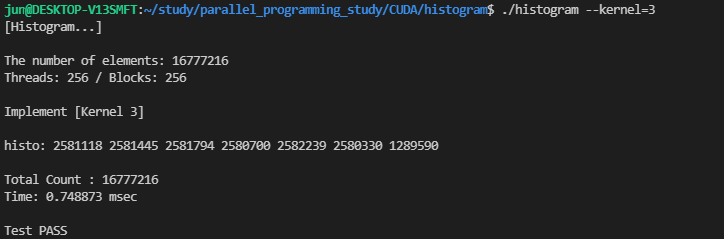
위에서 살펴본 커널은 약 5~6ms의 시간이 걸렸는데, privatization 기법을 적용한 커널의 수행 시간은 약 0.75ms로 속도가 약 8배 향상되었습니다.
한 가지 더 이야기하고 싶은 내용은, 히스토그램을 계산할 때 일부 데이터 집합은 일부 영역에 동일한 데이터 값이 많이 집중되어 있을 수 있습니다. 이와 같이 동일한 값의 빈도가 높으면 경쟁이 심해지고 병렬 히스토그램 계산의 처리량이 감소할 수 있습니다.
이러한 데이터 세트의 경우에 각 스레드가 히스토그램의 동일한 요소를 업데이트하는 경우 연속적으로 업데이트하는 것보다 누적한 값들을 한 번에 업데이트하는 것이 효과적인 최적화 방법이 될 수 있습니다. 이러한 집계(aggreegation)는 경쟁이 심한 히스토그램 요소의 atomic 연산의 수를 줄여서 처리량을 효과적으로 향상시킬 수 있습니다.
아래 코드는 위 내용을 적용한 히스토그램 커널입니다. 이전 커널에서 curr_index, prev_index, accumulator라는 레지스터 변수를 추가하여, for루프를 반복하면서 동일한 값이 나오면 accumulator에 값을 누적하고, 이전 값과 다른 값이 나올 때 histo_s 요소에 값을 업데이트합니다. 아마, 특정 범위의 값이 특정 지역에 몰려있다면 아래 커널은 꽤 효과적일 것이라고 추측됩니다.
__global__ void histo_privatized_aggregation_kernel(char* data, int n, int* histo, int n_bins) { int tid = blockDim.x*blockIdx.x + threadIdx.x; // Privatized bins extern __shared__ int histo_s[]; if (threadIdx.x < n_bins) histo_s[threadIdx.x] = 0u; __syncthreads(); int prev_index = -1; int accumulator = 0; // histogram for (int i = tid; i < n; i += blockDim.x*gridDim.x) { int alphabet_pos = data[i] - 'a'; if (alphabet_pos >= 0 && alphabet_pos < 26) { int curr_index = alphabet_pos/4; if (curr_index != prev_index) { if (prev_index != -1 && accumulator > 0) atomicAdd(&histo_s[prev_index], accumulator); accumulator = 1; prev_index = curr_index; } else { accumulator++; } } } if (accumulator > 0) atomicAdd(&histo_s[prev_index], accumulator); __syncthreads(); // commit to global memory if (threadIdx.x < n_bins) { atomicAdd(&histo[threadIdx.x], histo_s[threadIdx.x]); } }
기존과 동일한 환경에서 실행한 결과입니다.
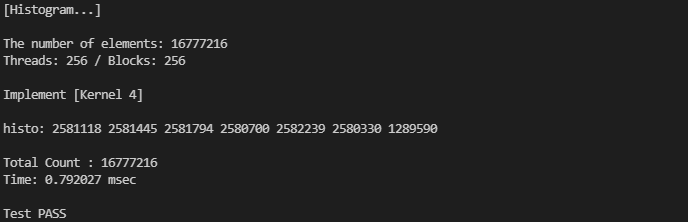
아무래도 무작위로 초기화된 값이다보니, 위에서 적용한 최적화의 효과가 크게 드러나지는 않습니다. 하지만, 동일한 값이 여러 번 반복되는 데이터의 경우에는 효과가 있을 거라고 생각합니다.
위에서 실행한 전체 코드는 아래 링크를 참조해주세요 !
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/histogram/histogram.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
'NVIDIA > CUDA' 카테고리의 다른 글
| Parallel Merge Sort (merge operation) (0) | 2021.12.24 |
|---|---|
| Sparse Matrix Computation (0) | 2021.12.21 |
| Parallel Prefix Sum (2) (0) | 2021.12.17 |
| Parallel Prefix Sum (1) (0) | 2021.12.15 |
| Tiled 2D Convolution (0) | 2021.12.14 |




댓글