References
- Programming Massively Parallel Processors
Contents
- Tiling 기법
- Tiled Matrix Multiplication
- 병렬화의 제한 요소인 메모리 크기
지난 포스팅에서 CUDA의 메모리에 관해서 알아봤습니다.
CUDA의 메모리 Access와 Type (예제 : matrix multiplication)
그리고 행렬 곱 커널을 구현하여 CUDA를 사용한 행렬 곱 프로그램을 작성해봤습니다. 하지만, 작성된 커널은 GPU 하드웨어의 성능을 온전히 사용하지 못한다고 했습니다. 이번 포스팅에서 이 성능을 어떻게 더 끌어올릴 수 있는지 살펴보도록 하겠습니다.
Tiling for reduced memory traffic
CUDA에서 디바이스 메모리를 사용할 때는 장단점이 존재합니다. 전역 메모리(Global Memory)는 큰 용량을 가지는 대신 느리고, 반면에 공유 메모리는 빠르지만, 용량이 작습니다. 흔히 사용되는 방법은 데이터를 타일(tile)이라고 부르는 작은 부분집합들로 분할하여 각 타일을 공유 메모리에 위치하도록 하는 것입니다. 이때 중요한 기준은 서로 다른 타일에 대한 커널 계산이 독립적으로 수행될 수 있어야 한다는 것 입니다. 주의해야할 것은 모든 자료구조가 타일들로 분할될 수 있는 것은 아닙니다.
Tiling의 개념은 지난 포스팅에서 살펴봤던 행렬 곱을 통해서 살펴볼 수 있습니다.

위 이미지는 여러 개의 블록들을 사용한 행렬 곱셈에 대한 간단한 예시를 보여주고 있는데, 지난 포스팅에서 구현했던 행렬 곱 커널 함수에 해당합니다. 이미지에서 행렬 M, N, P는 아래 커널 함수에서 각각 A, B, C에 대응됩니다.
__global__
void matrixMul(const float *A, const float *B, float *C, const int M, const int K, const int N)
{
int Row = blockIdx.y * blockDim.y + threadIdx.y;
int Col = blockIdx.x * blockDim.x + threadIdx.x;
if (Row < M && Col < N) {
float value = 0.0;
for (int i = 0; i < K; i++) {
value += A[(Row * K) + i] * B[(N * i) + Col];
}
C[(Row * N) + Col] = value;
}
}
간단히 살펴보기 위해서 4개의 2x2 블록들로 행렬 P를 계산한다고 가정하고, block(0,0)의 4개의 스레드에서의 연산을 살펴보겠습니다. 4개의 스레드는 각각 \(P_{0,0}, P_{0,1}, P_{1,0}, P_{1,1}\)을 계산합니다.
block(0,0)의 thread(0,0), thread(0,1)에 액세스되는 행렬 M과 N의 요소들은 위 이미지에서 검은색 화살표로 강조되어 표시되어 있습니다. thread(0,0)은 \(M_{0,0}\)과 \(N_{0,0}\), \(M_{0,1}\)과 \(N_{1,0}\), \(M_{0,2}\)과 \(N_{2,0}\), 그리고 \(M_{0,3}\)과 \(N_{3,0}\)에 액세스합니다.

위 이미지는 block(0,0)의 스레드들에 의해서 액세스되는 전역 메모리를 보여주고 있습니다. 각 스레드는 행으로 나열되어 있고, 접근 순서대로 액세스되는 행렬 M,N의 각 요소들을 열 방향으로 나열하고 있습니다. 각 스레드에서는 실행 중에 4개의 행렬 M 요소와 4개의 행렬 N 요소를 액세스합니다. 위 이미지를 살펴보면, 네 개의 스레드들이 접근하는 행렬 M과 N의 요소들이 상당히 많이 중복되고 있다는 것을 볼 수 있습니다. 예를 들어, thread(0,0)과 thread(0,1)은 둘 다 행렬 M의 첫 번째 행의 요소들에 액세스하고 있습니다. 유사하게, thread(0,1)과 thread(1,1)은 행렬 N의 두 번째 열의 요소들에 액세스하고 있습니다.
위의 matrixMul 커널 함수를 보면 thread(0,0)과 thread(0,1)이 모두 행렬 M의 첫 번째 행 요소들(\(M_{0, k}\))을 전역 메모리에서 읽도록 작성되어 있습니다. 만약 thread(0,0)과 thread(0,1)이 어떠한 방법을 사용하여 행렬 M의 행 요소들을 전역 메모리에서 한 번만 읽도록 할 수 있다면, 전역 메모리에 대한 전체 액세스 횟수를 반으로 줄일 수 있을 것입니다. 현재 구현된 커널 함수에서는 하나의 블록을 수행할 때 행렬 M과 N의 모든 요소들을 정확히 두 번씩 액세스하고 있습니다.
이 행렬 곱셈에서 전역 메모리 액세스는 행렬의 차수에 비례해서 감소될 수 있다는 것을 보여줍니다. Width x Width개의 블록을 사용한다면, 전역 메모리 액세스는 Width배 만큼 감소됩니다. 만약 16x16 블록을 사용한다면, 전역 메모리 액세스는 1/16으로 감소됩니다.
많은 전역 메모리 액세스로 성능이 안좋은 것은 교통 체증과 유사합니다. 교통 체증의 근본원인은 좁은 도로에 너무 많은 차들이 비집고 돌아다니기 때문입니다. 이러한 교통 체증을 줄이기 위한 대부분의 해결책은 도로 위의 자동차들을 줄이는 것인데, 미국에서는 카풀을 권장합니다.
Tiled 알고리즘은 카풀과 매우 유사합니다. 데이터 값에 액세스하는 스레드는 차량 이용자이고, DRAM access 요청은 차량으로 간주할 수 있습니다. DRAM access 요청 속도가 DRAM 시스템의 대역폭을 초과하면 정체가 발생하고 idle 상태가 되는 산술 유닛(arithmetic units)이 발생합니다. 만약 여러 스레드가 동일한 DRAM 위치의 데이터를 액세스할 경우, Tiled 알고리즘은 카풀과 유사하게 동일한 액세스 요청을 결합하여 하나의 액세스 요청으로 만들어줄 수 있습니다.
하지만, 카풀을 하려면 서로의 스케쥴을 맞춰야하는 것처럼 스레드에서도 유사한 실행 스케쥴이 필요합니다. 아래의 이미지가 스레드들의 스케쥴에 관하여 보여주는데, 중앙에 위치하는 셀은 DRAM을 의미합니다.
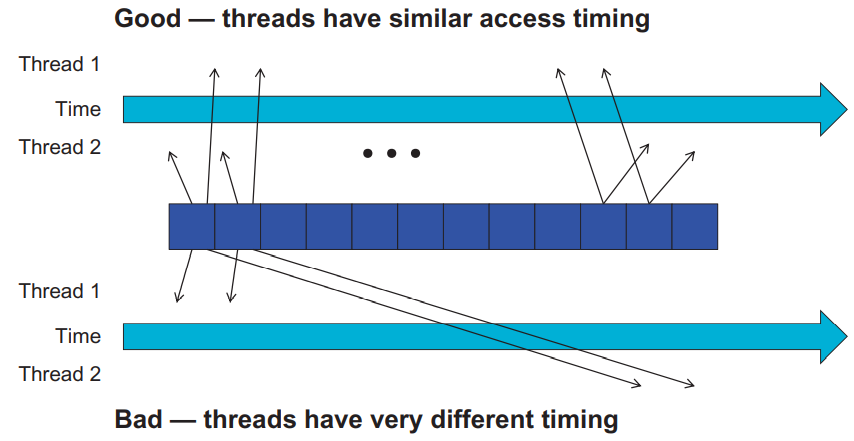
위 이미지에서 위쪽은 유사한 타이밍에 동일한 데이터에 액세스하는 두 개의 스레드를 보여주고 있으며, 아래는 서로 다른 타이밍에 동일한 데이터에 액세스하는 두 개의 스레드를 보여줍니다. 다른 타이밍에 동일한 데이터에 액세스하는 것은 바람직하지 않은데, 이는 DRAM에서 가져온 데이터를 스레드2에서 사용할 때까지 on-chip 메모리에 오랫동안 저장하고 있어야하기 때문입니다. 보통 많은 수의 데이터를 저장하므로, 이는 과도한 on-chip 메모리 사용이 요구됩니다.
병렬 컴퓨팅에서 Tiling은 스레드에 의해 액세스되는 메모리 위치와 그 액세스 타이밍을 지역화하는 기법입니다. 이는 각 스레드의 긴 액세스 시퀀스를 단계별로 나누고, barrier synchronization을 사용하여 유사한 액세스 타이밍을 갖도록 합니다.
Tilied Matrix Multiplication
이제 행렬 곱 연산에 tiling을 적용한 알고리즘을 살펴보겠습니다. 기본적인 아이디어는 스레드들이 내적 계산을 위해 각 행렬의 요소들을 사용하기 전, 사용되는 행렬 M과 N 요소의 부분 집합을 먼저 공유 메모리로 읽어 들이도록 하는 것입니다. 이때, 공유 메모리의 크기는 상당히 작아서, 행렬 M과 N 요소들을 공유 메모리로 읽어 들일 때 공유 메모리의 용량을 초과하지 않도록 조심해야 합니다. 이러한 제약 조건은 행렬 M과 N을 더 작은 타일로 분할하여 만족시킬 수 있습니다. 간단한 형태로 타일의 크기는 블록의 크기와 동일하게 설정하면 됩니다.
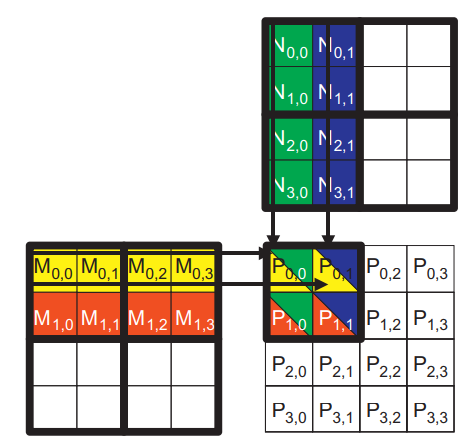
위 이미지에서 M과 N을 2x2 타일로 나누었습니다. 이제 각 스레드는 내적 계산을 수행할 때 단계별로 수행하게 되는데, 각 단계에서 한 블록의 모든 스레드들은 M의 타일 하나와 N의 타일 하나를 협력하여 공유 메모리로 읽어들입니다.
아래 이미지는 각 단계에서 Block(0,0)의 스레드들의 실행을 보여줍니다. 행렬 M 요소를 위한 공유 메모리 배열은 Mds, 행렬 N 요소를 위한 공유 메모리 배열은 Nds입니다.

1단계의 시작에서 block(0,0)의 4개의 스레드들은 서로 협력하여 M의 타일을 공유 메모리로 읽어드립니다. thread(0,0)은 \(M_{0,0}\)을 \(Mds_{0,0}\)으로, thread(0,1)은 \(M_{0,1}\)을 \(Mds_{0,1}\)으로, thread(1,0)은 \(M_{1,0}\)을 \(Mds_{1,0}\)으로, thread(1,1)은 \(M_{1,1}\)을 \(Mds_{1,1}\)로 로드합니다. N 타일도 이와 유사하게 읽어드립니다. M과 N의 타일을 공유 메모리로 읽어들인 후에, 이 요소들은 내적을 계산하기 위해서 사용됩니다. 공유 메모리에 위치하는 각 값은 두 번씩 사용됩니다. 예를 들어, thread(1,1)에 의해서 로드된 \(Mds_{1,1}\)은 thread(1,0)과 thread(1,1)에서 사용됩니다. 이렇게 전역 메모리의 값을 공유 메모리에 로드하여 여러 번사용할 수 있도록 함으로써 전역 메모리에 대한 액세스 횟수를 줄입니다. 위 예시에서는 절반으로 줄어들며, 만약 N x N 크기의 타일을 사용한다면, N배 감소됩니다.
위 표에서 내적 계산이 두 단계에 걸쳐서 수행되고 있는 것을 볼 수 있습니다. 각 단계에서 입력 행렬 원소 두 쌍에 대한 곱이 Pvalue 변수에 누적됩니다. 위 표의 4번째 열은 1단계에서 계산되어 누적되는 값을 보여주고, 7번째 열은 2단계 계산을 보여줍니다. 일반적으로 입력 행렬의 차원이 Width이고 타일 사이즈가 TILE_WIDTH라면, 내적 연산은 Width/TILE_WIDTH 단계에 걸쳐서 수행됩니다. 이렇게 단계를 나누는 것이 전역 메모리에 대한 액세스를 줄이는 비법입니다. 각 단계는 입력 행렬값의 작은 부분집합에만 집중함으로써 스레드들은 그 부분집합을 공유 메모리에 협력하여 로드할 수 있고, 그 단계에서 중복되어 사용되는 입력 값들을 공유 메모리에 있는 값들을 사용하여 계산합니다.
각 단계에서 Mds와 Nds는 입력 값들을 저장할 때 재사용된다는 것에 유의해야 합니다. 각 단계마다 그 단계에 사용되는 M과 N의 부분집합을 담는데 동일한 Mds와 Nds가 사용됩니다. 이렇게 함으로써 훨씬 작은 공유 메모리로 전역 메모리에 대한 대부분의 액세스를 다룰 수 있습니다. 이는 각 단계마다 입력 행렬 원소들의 작은 부분집합에만 집중하기 때문인데, 이러한 집중된 액세스 형태를 지역성(locality)이라고 부릅니다.
matrixMulTiled 커널 함수
전역 메모리의 액세스를 줄이기 위해서 공유 메모리를 사용하는 tiling 기법을 적용한 행렬 곱 커널은 다음과 같이 구현할 수 있습니다. 아래 커널 함수는 위에서 살펴본 각 단계들을 구현하고 있습니다.
__global__
void matrixMulTiled(const float *A, const float *B, float *C, const int M, const int K, const int N)
{
__shared__ float Asub[TILE_WIDTH][TILE_WIDTH];
__shared__ float Bsub[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x, by = blockIdx.y;
int tx = threadIdx.x, ty = threadIdx.y;
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float Pvalue = 0;
for (int ph = 0; ph < ceil(K / (float)TILE_WIDTH); ++ph) {
if ((Row < M) && (ph*TILE_WIDTH + tx < K))
Asub[ty][tx] = A[Row*K + ph*TILE_WIDTH + tx];
else
Asub[ty][tx] = 0;
if ((Col < N) && (ph*TILE_WIDTH + ty < K))
Bsub[ty][tx] = B[(ph*TILE_WIDTH + ty)*K + Col];
else
Bsub[ty][tx] = 0;
__syncthreads();
for (int k = 0; k < TILE_WIDTH; k++) {
Pvalue += Asub[ty][k] * Bsub[k][tx];
}
__syncthreads();
}
if ((Row < M) && (Col < N))
C[Row*K + Col] = Pvalue;
}line 4-5에서 먼저 Mds와 Nds를 위한 공유 메모리 변수 Asub, Bsub을 선언합니다. 공유 메모리의 범위는 블록 내라는 것에 유의해야 합니다. 따라서 하나의 블록에 속하는 모든 스레드들은 동일한 Asub, Bsub 배열에 접근할 수 있습니다. 따라서, 각자 공유 메모리에 로드한 입력 값들을 서로 공유하여 사용할 수 있습니다.
line 7-8에서는 threadIdx와 blockIdx 변수를 빠르게 액세스하기 위해서 레지스터에 저장합니다 (커널 함수 내의 스칼라 지역 변수는 레지스터에 저장됩니다).
line 10-11은 해당 스레드가 생성하는 결과 행렬 C의 원소의 행 인덱스와 열 인덱스를 결정합니다. 각 블록은 타일 크기인 (TILE_WIDTH x TILE_WIDTH)만큼의 원소를 포함하기 때문에 행 인덱스는 by*TILE_WIDTH + ty, 열 인덱스는 bx*TILE_WIDTH + tx로 계산됩니다.
line 14는 최종적으로 C 원소를 계산하기 위한 각 단계를 반복하는 루프의 시작입니다. 루프에서 각 반복은 위에서 봤던 내적 계산을 위한 각 단계에 해당합니다. 따라서, 변수 ph는 내적을 위해 이미 수행된 단계에 수를 의미합니다. 각 단계에서는 A와 B의 타일 하나를 사용하는데 line15-22에서 해당 단계에서 사용되는 입력 행렬의 (타일 크기만큼) 부분집합을 공유 메모리로 읽어들이는 작업을 수행합니다.
아래 그림은 tiling 기법을 사용한 행렬 곱 연산에서 행렬 인덱스 계산을 보여줍니다.

각 블록의 TILE_WIDTH\(^2\) 스레드들은 서로 협력하여 TILE_WIDTH\(^2\)개의 행렬 M(커널 함수에서 A)의 원소들을 공유 메모리에 적재합니다. 따라서, 우리는 각 스레드가 적재해야하는 한 개의 행렬 M 원소를 정해주기만 하면 됩니다. 이것이 line 16과 20에 구현되어 있습니다.
line 24에서 __syncthreads()라는 barrier synchronization(배리어 동기화) 함수를 호출하여 같은 블록의 모든 스레드들이 입력 행렬의 타일들을 모두 공유 메모리로 적재 완료했음을 확실하게 합니다. 입력 행렬의 타일이 공유 메모리로 적재 완료되면, line 26의 루프는 공유 메모리의 값들을 가지고 내적을 수행합니다. 계산이 완료되면 line 30의 __syncthreads() 함수를 호출하여, 블록의 모든 스레드들이 다음 반복으로 넘어가서 입력 행렬의 다음 타일을 공유 메모리로 적재하기 전에 현재 반복에서 공유 메모리로 적재된 값들의 사용을 완료하도록 보장해줍니다.
내적의 모든 단계가 완료된 후에 각 스레드는 계산된 Pvalue 값을 결과 행렬에 저장하고 스레드는 종료됩니다.
(line 14-30의 중첩된 루프는 strip-mining 기법이라고 부릅니다.)
타일 알고리즘(tiled algorithm)의 효과는 상당합니다. 이 행렬 곱 연산 예제에서의 전역 메모리 액세스는 TILE_WIDTH배만큼 감소합니다. 만약 16x16 크기의 타일을 사용한다면 전역 메모리 액세스를 16배 줄일 수 있습니다. 이러한 감소를 통해 하드웨어의 대역폭을 충분히 활용하여 원래의 알고리즘보다 더욱 빠른 부동소수점 연산을 수행할 수 있습니다.
이전 글에서 타일 기법을 사용하지 않은 일반적인 행렬 곱 연산 결과는

442.40 GFLOPS의 성능을 보여줍니다.
반면에, 타일 기법을 사용하여 16x16 타일 크기로 행렬 곱 연산 수행 결과는

2354.13 GFLOPS의 성능을 보여줍니다. (빠른 결과를 위해서 연산 결과 검증은 생략하였습니다.)
성능은 단순하게 측정하기 위해서 전역 메모리 접근은 제외하고 순수한 행렬 곱 연산(덧셈, 내적)만 포함했습니다. 그래서 부동소수점 연산의 수가 4096 x 4096 x 4096 x 2 = 137,438,953,472 Ops로 계산되었습니다.
수치적인 측면만 보더라도 커널 함수의 수행 시간이 310.667 msec에서 58.382 msec로 약 5~6배 정도 향상된 것을 확인하실 수 있습니다.
전체 코드는 아래 링크에서 확인하실 수 있습니다 !
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
병렬화의 제한 요소인 메모리 크기
CUDA 레지스터와 공유 메모리가 전역 메모리의 액세스 횟수를 감소시키는데 효과적이더라도, 이 메모리의 용량을 초과해서 사용하지 않도록 주의해야 합니다. 각 CUDA 디바이스는 제한된 리소스를 제공하기 때문에 주어진 프로그램에서SM들에서 동시에 수행되는 스레드의 개수도 제한됩니다. 일반적으로 각 스레드가 더 많은 리소스를 요구할 때마다 각 SM에 할당되는 스레드 수는 줄어들고, 따라서 전체 프로세서에 할당되는 스레드의 개수도 줄어듭니다.
만약 어떤 디바이스가 각 SM에 최대 1536개의 스레드와 16384개의 레지스터를 사용할 수 있다고 가정해봅시다. 16384는 꽤 큰 수 이지만, 개별 스레드로 보면 한 스레드는 매우 제한된 개수의 레지스터만을 사용할 수 있습니다. 1536개의 스레드를 사용하기 위해서, 각 스레드는 오직 16384/1536 = 10개의 레지스터만을 사용해야 합니다. 만약 각 스레드가 11개의 레지스터를 사용한다면, SM에서 동시에 실행될 수 있는 스레드의 수는 감소합니다. 이러한 감소는 블록 단위로 이루어지는데, 각 블록이 512개의 스레드를 포함하고 있다면 한 번에 512개의 스레드씩 감소하게 됩니다. 따라서, 1536개에서 1024개로 줄어들게 되고 이는 SM에 할당될 수 있는 스레드의 1/3이 감소하게 된다는 것을 의미합니다. 이것은 스케쥴링이 가능한 워프의 수를 크게 감소시키고, 그 결과 긴 지연시간을 가진 연산들이 발생할 때 프로세서가 사용할 수 있는 작업을 찾는 능력을 감소시킵니다.
공유 메모리의 사용 또한 각 SM에 할당된 스레드의 개수를 줄일 수 있습니다. 마찬가지로 어떤 디바이스가 16384(16K) 바이트 크기의 공유 메모리를 가지고 있다고 가정해봅시다. 공유 메모리는 각 SM의 블록들에게 할당됩니다. 각 SM에는 최대 8개의 블록까지 허용된다고 가정해보겠습니다. 이 최대값에 다다르기 위해서는 각 블록은 2KB의 공유 메모리를 초과해서 사용하면 안됩니다. 만약 각 블록이 2KB를 초과해서 공유 메모리를 사용한다면, 각 SM에 할당될 수 있는 블록의 개수는 블록들 전체가 사용하는 공유 메모리의 총 크기가 16KB가 넘지 않는 만큼의 수가 됩니다. 예를 들어, 각 블록이 5KB의 공유 메모리를 사용한다면 각 SM에 할당된 블록의 개수는 3개를 넘을 수 없습니다.
이처럼 행렬 곱셈 예제에서 공유 메모리는 제한요소가 될 수 있습니다. 16x16 크기의 타일에 대해서 각 블록은 16x16x4=1KB의 용량이 Asub 배열을 위해 필요합니다. 마찬가지로 Bsub을 위해 1KB가 필요합니다. 따라서 각 블록은 2KB의 공유 메모리를 사용합니다. 16KB 공유 메모리로 한 SM당 8개의 블록이 동시에 할당될 수 있습니다. 하드웨어에서 제공하는 최대 블록의 수와 같기 때문에 여기서 타일 크기에 대해서 공유 메모리는 제한요소가 아닙니다. 이 경우에는 각 SM당 1536개까지의 스레드만 허용된다는 것이 진짜 제한요소가 됩니다. 이 제약으로 각 SM의 블록의 수는 6개가 됩니다(1536 / 256 = 6). 결과적으로 오직 6x2KB = 12KB의 공유 메모리가 사용됩니다. 이러한 제한사항은 디바이스마다 다르지만 이는 런타임에 결정되는 속성입니다.
디바이스 리소스는 다음에 device query를 통해서 어떻게 체크할 수 있는지 알아보도록 하겠습니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| Divergent Wraps (예제 : Sum Reduction) (0) | 2021.12.09 |
|---|---|
| Global Memory 대역폭(bandwidth) 활용 (2) | 2021.12.08 |
| CUDA의 메모리 Access와 Type (예제 : matrix multiplication) (1) | 2021.12.05 |
| CUDA Thread 동기화 및 스케쥴링 / 리소스 할당 (0) | 2021.12.04 |
| CUDA Programming Model (1) | 2021.12.03 |




댓글