이번 포스팅에서는 많은 스레드들이 효율적으로 액세스할 수 있도록 데이터를 구성하고 배치하는 방법에 대해서 알아보도록 하겠습니다. 지난 포스팅들에서는 데이터가 먼저 host에서 device의 global memory(전역 메모리)로 복사되고, 커널에서는 blockIdx와 threadIdx를 사용하여 각 스레드가 전역 메모리에서 데이터의 일부분에 액세스하는 것을 살펴봤습니다. 여기까지의 내용은 CUDA 커널의 기본적인 것들이라, 이 방법으로는 하드웨어가 가지는 잠재적인 성능의 극히 일부분만 사용할 수 있습니다.
성능이 좋지 못한 것은 일반적으로 DRAM(Dynamic Random Access Memory)으로 구현되는 전역 메모리의 접근 지연시간(access latency)가 매우 길고(수백 사이클의 클럭), 액세스 대역폭(access bandwidth)도 유한하기 때문입니다. 이론적으로는 많은 수의 스레드들을 실행함으로써 메모리에 액세스하는 지연시간을 감내할 수 있지만, 전역 메모리로의 액세스가 너무 많아서 데이터의 흐름이 정체되는 상황이 쉽게 발생할 수 있습니다. 이런 경우, 일부 스레드를 제외한 모든 스레드가 진행되지 못하고, 따라서 SM(streaming multiprocessor)의 일부가 idle 상태가 되는 상황에 직면하게 됩니다. 이러한 데이터 정체를 피하기 위해서 CUDA에서는 메모리 접근을 위한 추가적인 리소스와 방법을 제공하여 전역 메모리에서 들어오고 나가는 트래픽의 대부분을 제거할 수 있도록 해줍니다. 이번 포스팅에서 CUDA 커널의 실행 효율을 높이기 위해 다양한 메모리 유형을 사용하는 방법에 대해 알아보겠습니다.
위 포스팅에서 간단하게 살펴봤던 이미지를 blur 처리해주는 blurKernel 함수의 일부분입니다. 위 커널에서 가장 많이 실행되는 부분의 예상되는 성능 수준을 계산하여 메모리 접근 효율성의 효과를 알아보도록 하겠습니다. 전체 코드는 아래 링크에서 확인하실 수 있습니다.
실행 시간 측면에서 위 커널의 가장 중요한 부분은 blurring patch로 주변 픽셀값들을 더하는 중첩된 for-loop입니다. inner loop가 반복될 때마다 한 번의 부동소수점(floating-point) 덧셈을 위해 한 번의 전역 메모리 액세스가 수행됩니다 (line 18). 전역 메모리 액세스는 in[] 배열의 요소를 가져옵니다. 그리고 가져온 요소 값을 pixVal에 누적시킵니다. 따라서 전역 메모리 액세스 작업에 대한 부동소수점 계산의 비율은 1:1이므로, 1.0으로 표현할 수 있습니다. 이 비율을 Compute-to-Global-Memory-Access(CGMA)라고 부르는데, 프로그램 한 영역 내에서 한 번의 전역 메모리 액세스 당 수행되는 부동소수점 연산의 개수로 정의됩니다.
CGMA 비율은 CUDA 커널의 성능에 큰 영향을 미칩니다. 최근 최신 장치에서의 전역 메모리 대역폭은 약 1,000GB/s(1TB/s) 입니다. 각 단정밀도(single-precision) 부동소수점 값이 4바이트라면, 초당 1000/4=250GB이하의 단정밀도 피연산자를 load할 수 있습니다. CGMA의 비율이 1.0이라면, 피연산자(ex, in[] 배열의 요소)가 GPU에 전달될 때의 이미지 blur 커널의 수행은 CGMA 비율에 의해서 제한됩니다. 이렇게 메모리 액세스 처리량(throughput)에 의해서 실행 속도가 제한되는 프로그램을 memory-bound 프로그램이라고 합니다. 이 이미지 커널 함수에서는 초당 250GB의 부동소수점 연산(Giba-byte FLoating-point OPerations per Second, GFLOPS)을 달성하지 못할 것입니다.
커널에서 더 높은 성능을 얻으려면 전역 메모리 액세스 수를 줄여서 CGMA 비율을 높여야합니다.
Matrix multiplication
행렬-행렬 곱셈 연산을 통해 살펴보도록 하겠습니다. 행렬 곱셈은 (i x j) 행렬 M과 (j x k) 행렬 N 사이의 곱셈으로 (i x k) 행렬 P가 결과입니다. 곧 보게 되겠지만, 행렬 곱셈에서 비교적 간단한 기법으로 전역 메모리 액세스를 줄일 수 있습니다. 행렬 곱 연산의 실행 속도는 전역 메모리 액세스가 감소되는 수준에 따라서 매우 다양합니다.
행렬 곱셈을 수행할 때 output 행렬 P의 각 원소는 행렬 M의 행 벡터와 행렬 N의 열벡터의 내적(inner product)입니다. PRow,Col의 계산은 위 그림처럼 행렬 M의 Row 행의 요소들과 행렬 N의 Col 열의 요소들을 사용합니다.
즉,
PRow,Col=∑MRow,k∗Nk,Col, for k = 0, 1, ..., Width - 1
이 커널 함수는 (M x K) 행렬 A와 (K x N) 행렬 B를 곱해서 (M x N) 행렬 C를 구하는 작업을 수행합니다.
thread-to-data mapping은 행렬 C를 위의 이미지처럼 Block_width x Block_width의 크기를 갖는 타일(tile)로 나눌 수 있습니다. 이렇게 함으로써 각 블록은 이 타일 중의 하나에 대해 연산을 수행합니다.
커널 함수에서 계산해야될 output 행렬의 Row와 Col이 결정되면, for-loop를 통해 곱셈에 사용되는 행렬 A의 행 벡터와 행렬 B의 열 벡터의 내적을 계산합니다. 계산되는 값은 value라는 스레드의 private 변수에 저장됩니다. 이 부분은 아마 잘 아실거라 생각하고, 자세한 설명은 넘어가도록 하겠습니다. (2차원 배열의 인덱스를 1차열 배열의 형태로 표현하고 있습니다.)
for-loop의 연산이 끝나면, 모든 스레드는 결과 값을 저장하고 있는 value의 값을 C[(Row * N) + Col]에 저장합니다. 따라서, 각 스레드는 1차원 인덱스로 표현된 행렬 P의 Row*Width+Col 인덱스에 해당되는 값을 처리합니다.
아래 이미지는 행렬 P의 크기가 4x4이고 블록의 크기가 2x2일 때, 커널이 생성한 스레드의 인덱스를 보여주고 있습니다.
A small execution example of matrixMul Kernel
행렬 곱의 결과인 행렬 P는 4개의 블록으로 나뉘고, 각 블록은 2x2배열의 스레드로 구성되어 있습니다. 각 스레드는 행렬 P의 요소 하나를 계산하는데, 위 예시에서 Block(0,0)의 Thread(0,0)은 P0,0을 계산하고, Block(1,0)의 Thread(0,0)은 P2,0을 계산합니다. 아래 이미지는 하나의 블록에서 이루어지는 행렬 곱 연산을 보여주고 있습니다.
Matrix multiplication actions of one thread block.
코드를 컴파일하고, 행렬의 크기를 M = 4096, K = 4096, N = 4096로 설정하여 프로그램을 실행하면,
저의 경우에는 위 스크린샷처럼 결과 출력이 나왔습니다.
코드를 통해서 행렬 곱 연산 코드의 예상되는 성능을 계산하여 CGMA를 추정할 수 있습니다. 코드에서 사용된 커널 함수에서 가장 많은 부분을 차지하는 것은 행 벡터와 열 벡터의 내적을 계산하는 for-loop일 것입니다.
for (int i = 0; i < K; i++) {
value += A[(Row * K) + i] * B[(N * i) + Col];
}
위 루프가 반복될 때마다 한 번의 부동소수점 곱셈, 한 번의 부동소수점 덧셈과 두 번의 전역 메모리 액세스가 수행됩니다. 전역 메모리 액세스에서 한 번은 행렬 A의 요소에 액세스하는 것이고, 다른 하나는 행렬 B의 요소에 액세스하는 것입니다. 액세스한 행렬 A과 B의 요소를 곱하고, 그 결과를 value에 더하는 연산으로 총 두 번의 부동소수점 연산이 있습니다. 따라서 compute-to-global-memory-access 비율은 1.0 입니다. 위에서 CGMA에 대해서 이야기할 때, 1.0의 비율로는 GPU 하드웨어의 성능을 충분히 이끌어내지 못한다고 했습니다. 아래에서 이 성능을 어떻게 끌어올리는 지 살펴보도록 하겠습니다.
현재 저의 경우에는 442.40 GFLOPS으로 성능이 추정되었습니다.
CUDA를 사용하여 행렬 곱 연산 결과가 올바른지 검증하기 위해서 L2-norm error를 측정하였습니다. 측정 방법은 NVIDIA에서 제공하는 sample code를 참조하였습니다. 참고로, CPU에서 serial code로 계산할 결과와 비교해보면 약간의 오차가 발생합니다. 실제로 GPU와 CPU에서의 연산 값을 비교해보면,
위와 같은 오차가 발생합니다. 이에 관한 내용은 아래 링크의 유튜브 영상을 참조바랍니다 ! https://youtu.be/IJ_k8SCR3Y8
CUDA Memory Types
행렬 곱 연산의 성능을 향상하는 방법에 대해 알아보기 전에 CUDA Device의 메모리 종류에 대해서 알아보도록 하겠습니다. CGMA의 비율과 프로그램의 속도를 향상시키기 위해서 CUDA Device는 프로그래머가 사용할 수 있는 몇 가지 타입의 메모리를 지원합니다. 아래 이미지에서 이러한 메모리들을 보여주고 있습니다.
Overview of the CUDA device memory model.
전역 메모리와 상수 메모리(Constant Memory)는 이미지의 가장 아래쪽에 위치하고 있는데, 이 타입의 메모리는 host에서 CUDA API 함수 호출을 통해 읽기/쓰기가 가능합니다. 전역 메모리는 이미 많이 사용했으니 잘 아시리라 생각됩니다. 상수 메모리는 device에서 짧은 지연시간과 높은 대역폭을 가지는 읽기 전용 메모리입니다.
레지스터(register)와 공유 메모리(shared memory)는 on-chip 메모리입니다. 이런 종류의 메모리에 존재하는 변수는 병렬적으로 매우 빠른 액세스가 가능합니다. 레지스터는 개별 스레드에 할당되는데, 각 스레드는 자신의 레지스터에만 접근할 수 있습니다. 커널 함수는 각 스레드가 자신만의 빈번하게 사용되는 변수(private)를 담기 위해 레지스터를 주로 사용합니다. 공유 메모리 위치는 스레드 블록에 할당됩니다. 한 블록 내에 존재하는 모든 스레드는 그 블록에 할당된 공유 메모리 변수에 접근할 수 있습니다. 공유 메모리는 각 스레드들이 input data와 중간 결과를 공유하여 협동할 수 있는 효율적인 수단입니다. 이러한 메모리 타입 중의 하나로 CUDA 변수를 선언함으로써, 우리는 변수의 scope와 접근 속도를 결정할 수 있습니다.
레지스터, 공유 메모리, 전역 메모리의 차이를 조금 더 이해하기 위해서는 현대 프로세서에서 서로 다른 메모리 종류가 어떻게 실현되고 있는지 살펴보겠습니다. 사실상 모든 현대 프로세서는 1945년 John von Neumann(폰 노이만)이 제안한 모델에서 그 뿌리를 찾을 수 있으며, 그 모델(폰 노이만 모델)은 다음과 같습니다.
Memory vs. registers in a modern computer based on the von Neumann model
CUDA device도 예외는 아닙니다. CUDA의 전역 메모리는 위 이미지에서의 Memory와 같습니다. 전역 메모리는 Processor 칩 밖에 존재하며 DRAM 기술이 적용되어 있습니다. 따라서, 접근 지연 시간이 길고 비교적 낮은 대역폭을 가지고 있습니다. 레지스터는 폰 노이만 모델에서 Register File에 해당합니다. 이 메모리는 매우 짧은 접근 지연 시간을 가지고 전역 메모리에 비해서 매우 큰 대역폭을 가지고 있습니다. 일반적인 디바이스에서 Register File의 대역폭은 적어도 전역 메모리의 2배 이상입니다. 게다가 레지스터에 변수가 저장되면, 해당 변수에 대한 액세스는 더 이상 off-chip 전역 메모리 대역폭을 사용하지 않습니다. 이렇게 감소된 대역폭 사용은 CGMA의 비율의 증가로 이어집니다.
전역 메모리와 레지스터의 미묘한 차이 중의 하나는 레지스터에 대한 액세스는 전역 메모리에 대한 액세스보다 더 적은 명령어로 이루어진다는 것입니다. 대부분의 현대 프로세서에서 산술 명령어들은 내장된 레지스터 피연산자(register operands)를 가지고 있습니다. 예를 들어, 하나의 부동소수점 덧셈 명령어는 다음과 같은 형식이고,
여기서 r2와 r3는 레지스터에서 입력 피연산자의 값을 찾을 수 있는 위치를 지정하는 레지스터의 번호입니다. 부동소수점 덧셈 연산의 결과가 저장되는 위치는 r1으로 지정됩니다. 그러므로 산술 명령어의 피연산자가 레지스터에 있을 때에는 피연산자 값을 산술 및 논리 유닛(ALU)에서 사용할 수 있도록 하기 위한 추가적인 명령(메모리 액세스 등)이 필요하지 않습니다.
반면에, 피연산자 값이 전역 메모리에 있는 경우, 프로세서는 ALU에서 피연산자 값을 사용할 수 있도록 메모리를 읽는 작업을 수행해야 합니다. 예를 들어, 부동소수점 덧셈 명령어의 첫 번째 피연산자가 전역 메모리에 있는 경우 관련된 명령어는 피연산자의 주소를 형성하기 위해서 아래와 같이 r4에 offset을 더하는 load 명령어가 있을 수 있습니다.
그런 다음 전역 메모리에 액세스하여 그 값을 레지스터 r2에 저장합니다. 피연산자 값이 r2에 위치하게 되면, 이제 fadd 명령어는 r2와 r3의 값을 사용하여 부동소수점 덧셈 연산을 수행한 다음 결과를 r1에 위치시킵니다. 프로세서는 clock 사이클당 제한된 수의 명령어를 fetch하고 실행할 수 있기 때문에 전역 메모리 액세스가 추가되면, 연산을 수행하는데 더 많은 시간이 걸릴 수 있습니다. 따라서 피연산자를 레지스터에 위치시켜야 실행 속도를 향상시킬 수 있습니다.
마지막으로, 피연산자 값을 레지스터에 위치시키는 것이 선호되는 또 다른 이유가 있습니다. 현대 컴퓨터에서 레지스터에 존재하는 값에 액세스하기 위하여 소비되는 에너지는 전역 메모리의 값에 접근하는 것보다 몇 배 더 적습니다.
다만, 각 스레드에서 사용할 수 있는 레지스터의 수는 GPU 디바이스에서 상당히 제한적입니다. 따라서, 이 한정된 리소스를 초과해서 사용하지 않도록 주의해야 합니다.
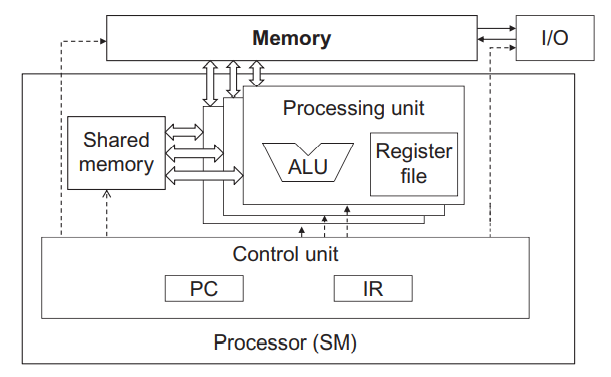
아래 이미지는 CUDA 디바이스에서의 공유 메모리와 레지스터를 보여주고 있습니다.
Share memory vs. registers in a CUDA device SM.
공유 메모리와 레지스터는 둘 다 on-chip 메모리이지만 기능과 액세스 cost 측면에서 상당한 차이가 있습니다. 공유 메모리는 프로세서(SM) 칩에 있는 메모리 공간의 일부로 설계되었습니다. 프로세서가 공유 메모리에 있는 데이터에 액세스할 때 전역 메모리의 데이터에 액세스하는 것과 유사하게 메모리 로드 작업을 수행해야 합니다. 그러나 공유 메모리는 칩 내부에 존재하기 때문에 전역 메모리보다 훨씬 짧은 대기시간과 높은 처리량으로 액세스할 수 있습니다. 공유 메모리는 메모리 로드 작업을 수행해야 하므로 레지스터보다는 대기시간이 길고 대역폭이 낮습니다.
(컴퓨터 구조 용어에서 공유 메모리는 scratchpad memory의 한 형태입니다.)
CUDA에서 공유 메모리와 레지스터 사이의 중요한 차이점 중의 하나는 공유 메모리에 있는 변수들은 한 블록 내의 모든 스레드에 의해 액세스가 가능하지만 레지스터 데이터는 스레드에 private합니다. 위의 이미지에서와 같이 CUDA 디바이스 SM은 일반적으로 여러 개의 Processing Unit을 사용하여 여러 개의 스레드가 동시에 수행될 수 있도록 합니다. 따라서, 공유 메모리는 한 블록 내의 스레드 간에 데이터를 효율적이고 높은 대역폭으로 공유할 수 있도록 설계되었습니다. 밑에서 스레드 간의 효율적인 데이터 공유가 어떠한 이점을 가지는지 알아보도록 하겠습니다.
이제 레지스터, 공유 메로리, 전역 메모리의 기능이나 지연시간, 대역폭이 다르다는 것을 알게됬습니다. 아래의 포는 프로그램 변수를 다양한 종류의 디바이스 메모리에 선언하는 CUDA 문법을 보여주고 있습니다.
위와 같은 각각의 선언은 선언된 CUDA 변수의 범위(Scope)와 수명(Lifetime)을 정의합니다. 변수의 범위는 그 변수를 접근할 수 있는 쓰레드의 범위를 명확히 합니다. 즉, 단일 스레드 전용인지 혹은 블록 내 모든 스레드, 혹은 모든 그리드의 모든 스레드들에 의해서 접근가능한 지를 알려줍니다. 만약 변수의 범위가 단일 스레드라면, 각 스레드마다 그 변수의 고유 버전(private version)이 생성되고, 각 스레드는 그 변수에 대한 자신의 고유 버전에만 접근할 수 있습니다. 예를 들어, 어떤 커널에서 선언한 변수의 범위는 단일 스레드인데, 이 커널이 백만 개의 스레드에 의해서 수행된다면 그 변수는 백만 개의 고유 버전이 생성되고, 각 스레드는 자신의 버전만을 초기화하고 사용하게 됩니다.
변수의 수명은 프로그램이 수행되는 시간동안 변수가 사용 가능한 기간을 의미합니다. 즉, 커널이 수행되는 동안 존재하거나 전체 프로그램 수행시간 동안에서 존재하느냐를 의미합니다. 만약 어떤 변수의 수명이 커널이 수행하는 동안 존재한다면, 이 변수는 커널 함수 내에서 선언되어야하며, 커널 코드에 의해서만 사용될 수 있습니다. 반면에 변수의 수명이 전체 프로그램에서 계속된다면, 이 변수는 함수 밖에서 선언되어야 합니다. 이러한 변수는 프로그램 실행 내내 유지되며모든 커널에서 사용할 수 있습니다.
배열이 아닌 변수를 스칼라 변수라고 하는데, 커널 함수와 디바이스 함수 내에서 선언된 모든 스칼라 변수들은 레지스터에 위치합니다. (Automatic variable은 지역 변수를 의미합니다.) 스칼라 변수의 범위는 개별 스레드 내에 속합니다. 커널 함수가 스칼라 변수를 선언할 때 해당 변수의 private copy가 커널 함수에서 실행되는 모든 스레드에 의해서 생성됩니다. 스레드가 종료되면, 스레드의 모든 스칼라 변수도 사라집니다. 아래 코드에서 blurRow, blurCol, curRow, curCol, pixels, pixVal은 모두 스칼라 변수이며, 이 범위에 속합니다.
스칼라 변수에 액세스하는 것은 매우 빠르고 병렬적이지만, 구현 시 레지스터의 제한된 용량을 초과하지 않도록 주의해야 합니다. 너무 많은 수의 레지스터를 사용하면 SM에 할당된 활성화되는 스레드 수에 안좋은 영향을 미칠 수 있습니다. 이에 대해서는 다른 글에서 알아보도록 하겠습니다.
커널 함수에서 선언되는 (automatic array variables)배열은 레지스터에 저장되지 않습니다. 이 배열은 전역 메모리에 저장되며, 긴 액세스 시간을 갖고 잠재적으로 트래픽이 발생할 수 있습니다. 스칼라 변수와 마찬가지로 배열의 범위는 각 스레드로 제한되며, 스레드가 종료되면 배열 또한 사라집니다. 일반적으로 커널 함수나 디바이스 함수 내에서 이 배열 타입은 거의 사용되지 않습니다.
CUDA에서 변수를 선언할 때 '__shared__' 키워드가 있으면 공유 변수를 선언합니다. '__shared__' 앞에 '__device__'를 선택적으로 붙여도 동일한 효과를 갖습니다. 이러한 선언은 일반적으로 커널 함수나 디바이스 함수 안에서 사용됩니다. 공유 변수는 공유 메모리에 위치하고, 이 변수의 범위는 스레드 블록 내 입니다. 즉, 블록 내의 모든 스레드들은 동일한 버전의 공유 변수에 액세스할 수 있습니다. 즉, 공유 변수는 커널 실행 중에 각 블록에 의해 생성되고 사용됩니다. 공유 변수의 수명은 커널 수행 기간입니다. 커널이 실행을 종료할 때 공유 변수도 사라집니다. 앞서 언급한 것과 같이 공유 변수는 블록 내의 스레드가 서로 협력할 수 있는 효율적인 수단이 됩니다. 공유 메모리에 있는 공유 변수에 액세스하는 것은 매우 빠르고 병렬적으로 수행됩니다. 공유 변수는 커널 수행 단계에서 자주 사용되는 전역 메모리 데이터의 일부를 더 효율적으로 액세스하기 위해서 사용됩니다. 다음 글에서 공유 변수를 사용하여 더 향상된 행렬 곱 연산에 대해서 알아보도록 하겠습니다.
변수를 선언할 때, '__constant__'키워드가 오는 경우, CUDA는 상수 변수를 선언합니다. 선택적으로 '__device__'를 '__constant__' 앞에 추가하여 동일한 효과를 얻을 수 있습니다. 상수 변수는 어떤 함수든지 함수 외부에서 선언되어야 합니다. 상수 변수의 범위는 모든 그리드이므로,모든 그리드에 있는 모든 스레드가 동일한 상수 변수에 액세스할 수 있습니다. 상수 변수의 수명은 프로그램의 전체 수행 시간 동안입니다. 상수 변수는 커널 함수에 입력값을 제공하는 변수를 위해서 자주 사용됩니다. 상수 변수는 전역 메모리에 저장되지만, 효율적인 접근을 위해서 캐시됩니다. 적절한 액세스 패턴을 사용하면 상수 메모리에 액세스하는 것은 매우 빠르고 병렬적으로 수행됩니다. 현재 프로그램에서 상수 변수의 총 크기는64KBytes(65,536bytes)로 제한됩니다.
변수 선언에 '__device__' 키워드가 있다면, 해당 변수는 전역 변수이고 전역 메모리에 위치합니다. 전역 변수에 대한 액세스는 느립니다. 하지만 전역 변수는 모든 커널의 모든 스레드들이 액세스할 수 있습니다. 해당 변수의 내용도 전체 프로그램의 수행 기간 동안 계속 유지됩니다. 따라서, 전역 변수는 서로 다른 스레드 블록에 속한 스레드들이 협동하기 위한 방법으로 사용될 수 있습니다. 그러나 전역 메모리에 액세스할 때, 서로 다른 스레드 블록의 스레드들 간에 동기화하거나 스레드 간 데이터 일관성을 보장하는 유일하고 쉬운 방법은 현재 실행되는 커널을 종료하는 것뿐 입니다. 따라서, 전역 변수는 커널과 커널 사이에 정보를 전달하기 위한 목적으로 종종 사용됩니다.
CUDA에서 포인터는 전역 메모리의 데이터 객체를 가리키는데 사용됩니다. 커널과 디바이스 함수에서 포인터를 사용하는 방법은 대개 두 가지 경우입니다.
(1) 객체가 호스트 함수에 의해 할당된다면 그 객체에 대한 포인터는 cudaMalloc()에 의해서 초기화되고커널 함수의 파라미터로 전달할 수 있습니다. 위의 matrixMul 커널에서의 파라미터 A, B, C가 이에 해당합니다.
(2) 전역 메모리에 선언된 변수의 주소를 포인터 변수에 할당하는 것입니다. 예를 들어,
float *ptr = &GlobalVar;
과 같은 문장이 커널 함수 안에 있다면, 이는 GlobalVar의 주소를 지역 변수 ptr에 입력합니다.
지금까지 CUDA에서 메모리 액세스와 메모리 타입에 대해서 알아봤고, 행렬 곱 커널 함수를 구현해보았습니다. 하지만, 구현한 행렬 곱 커널은 전역 메모리에 대한 액세스가 너무 많아 하드웨어의 성능을 온전히 이끌어내지 못합니다. 계속 이어서 진행하려고 했으나, 글이 너무나 길어지는 것 같아 다음 글에서 어떻게 전역 메모리에 대한 액세스를 줄여서 성능을 향상시킬 수 있는지 알아보도록 하겠습니다.














댓글