이번 글에서는 coursera deep learning 3주차 과제였던 planar data classification을 tensorflow를 사용해서 구현해보도록 하겠습니다.
2020/09/25 - [Coursera 강의/Deep Learning] - [실습] Planar data classification with a hidden layer
[실습] Planar data classification with a hidden layer
해당 내용은 Coursera의 딥러닝 특화과정(Deep Learning Specialization)의 첫 번째 강의 Neural Networks and Deep Learning를 듣고 정리한 내용입니다. (Week 3) 3주차에서는 Planar data 분류기를 구현하는데,..
junstar92.tistory.com
planar data 분류인데, 평면상의 data(point)들을 분류하는 것입니다.
바로 시작해보도록 하겠습니다.
이번에는 따로 dataset이 존재하지 않고, 직접 dataset을 생성해서 진행합니다. dataset을 생성하는 함수는 coursera 강의 내에 존재하는 함수를 그대로 사용했습니다.
(함수가 필요하시면 댓글로 남겨주세요)
우선 필요한 package들을 import하고, 데이터를 불러옵니다.
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
X, Y = load_planar_dataset()그리고 dataset의 shape는 다음과 같습니다. 총 400개의 points가 존재하는 것을 볼 수 있고, X는 2차원 좌표값이며, Y는 0, 1의 값을 가지는 label입니다.
print(f'The shape of X is : {X.shape}')
print(f'The shape of Y is : {Y.shape}')

이 data를 좌표에 그려보면,
# visualize data
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Spectral)

위와 같은 그래프를 얻을 수 있습니다. 우리는 이 자주색?과 보라색을 분류해보도록 할 것입니다. sklearn으로 시도해보는건 위에 남겨드린 이전 글을 보시면 될 것이고, 우리는 바로 tensorflow로 구현을 해보도록 하겠습니다.
제목처럼 우리는 1개의 hidden layer를 가지는 neural network를 구현하는데, 구성되는 network는 다음과 같습니다.

input으로부터 hidden layer와 output layer를 거쳐서 label이 1이될 확률을 구하게 됩니다. 여기서 hidden layer의 activation function은 tanh함수를 사용하고, output layer의 activation function은 sigmoid함수를 사용합니다.
한 개의 샘플 \(x^{(i)}\)에 대해서 아래와 같은 과정이 진행되는 것이죠.

cost function은 이전 게시글과 마찬가지로 cross entropy를 사용하는데, 이번에는 직접 수식으로 구하는 것이 아닌, 내장된 함수를 사용해보도록 하겠습니다.
구현 자체는 아주 간단합니다.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(4, activation='tanh'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1.2),
loss='binary_crossentropy',
metrics=['accuracy'],)tf.keras.models.Sequential을 사용해서 layer를 쌓아주는데,
첫 번째는 activation unit이 4개이고, activation function이 tanh인 layer이고,
두 번째 layer는 activation unit이 1개이고, activation function이 sigmoid인 layer가 됩니다.
+) tf.keras.models.Sequential의 interface는 아주 간단합니다. 인자(argument)로는 layers와 name, 이렇게 두 가지가 있는데, 두 인자 모두 optional입니다. 위의 경우에는 layers를 사용했는데, layers는 layer들의 list를 인자로 받습니다.
만약, layers에 인자를 입력하지 않는다면, 아래와 같은 방식으로 add 메소드를 사용해서 추가할 수 있습니다.
name은 아마 모델의 이름을 지정하는 것 같은데, 그래프 시각화를 할 때 유용하게 사용되는 것 같습니다.

그리고 model.compile을 통해서 training을 위한 최적화 알고리즘, loss 등의 configuration을 설정합니다.

다양한 인자들이 있지만, 오늘 사용하는 optimizer와 loss, metrics만 우선 살펴보겠습니다.
optimizer에는 String(optimizer의 이름)이나 optimizer instance가 인자로 입력될 수 있습니다. optimizer의 종류는 tf.keras.optimizers를 참조하시길 바랍니다. 우리는 Gradient Descent를 사용하기 때문에 tf.keras.optimizers.SGD를 사용했는데, String으로 'SGD'를 입력해도 되는데... 이런 경우에는 어떻게 learning rate를 조절하는 지 아직 확인을 못했습니다... !
loss의 경우에는 String(objective function의 이름), objective function, 또는 tf.keras.losses.Loss의 instance를 인자로 가질 수 있습니다. tf.keras.losses에 존재하는 loss function이나 직접 loss function을 구현해서 사용할 수도 있습니다(fn(y_true, y_pred)꼴로 생성하면 되는 것 같습니다.). 우리는 binary classification을 위한 loss function을 사용합니다.
metrics은 training과 testing 동안 모델을 평가하는 방법의 list를 인자로 갖습니다. 이 list에는 String(name of a built-in function) 또는 tf.keras.metrics.Metric의 instance가 됩니다. 정확도를 가지고 평가하기 때문에 'accuracy'로 입력하면 됩니다.
참고로 tf.keras.models에서 layer를 쌓을 때, weight의 shape는 입력에 따라 달라지기 때문에 단순이 layer만 구성했을 때에는 weight가 만들어지지 않습니다. 하지만, 첫 번째 층을 만들때 입력의 shape를 지정해주거나 the delayed-build pattern을 사용하면 weight가 만들어집니다. 그리고, deep learning에서는 파라미터를 random 초기화를 해야하는데, 이것은 layer를 추가할 때,

kernel_initializer, bias_initializer로 설정이 가능합니다. 인자로 지정하지 않는다면, 기본적으로 위와 같이 설정됩니다.
'glorot_uniform'으로 설정되어 있는데,

라고 합니다.. !
준비가 다 되었으면, 이제 .fit 메소드를 통해서 학습을 진행하면 됩니다. epochs는 학습이 한 번 완료되는 것을 의미하고, 총 10000번의 학습이 진행된다는 뜻입니다. 우리는 batch size를 따로 지정하지 않았기 때문에 매 epochs마다 400개의 example을 가지고 학습을 진행하게 됩니다. 마지막의 verbose는 진행 경과를 표시해주는데, 워낙 epochs가 크다보니 매 epoch마다 결과를 얻으려니까 멈춰버리더라구요.. 그래서 경과를 표시하지 않도록 0으로 설정해주었습니다.
history = model.fit(X, Y, epochs=10000, verbose=0)
model.evaluate(X, Y)학습을 완료하고 model.evaluate(X, Y)를 통해서 결과를 확인해줍니다.

88% 정도의 정확도를 가지고 있다고 나오네요. coursera에서 직접 구현해서 수행했을 땐 90%의 정확도가 나왔었는데, 아마 초기화 방법이 다르기 때문에 발생한 오차가 아닌가 조심스럽게 추측해봅니다.
+) fit 메소드는 History object를 반환합니다. 이 객체는 training 동안의 loss와 metrics의 값, 그리고 설정했다면 validation loss와 validation metrics value를 저장하고 있습니다. 여기에서는 매 epoch의 loss와 accuracy 값을 저장하고 있습니다. 따라서 history.history['loss']와 history.history['accuracy']를 사용해서 아래와 같은 그래프를 얻을 수도 있습니다. (아직 matplotlib을 잘 사용할 줄 몰라서... legend의 위치는 대강 잡았습니다.)
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(history.history['loss'], 'y', label='train loss')
acc_ax.plot(history.history['accuracy'], 'b', label='train acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
fig.legend(loc='center')

그리고 summary() 메소드를 사용하면 network의 구성을 잘펴볼 수 있습니다.
model.summary()

모델의 이름과 layer의 이름을 지정해주지 않았기 때문에 위와 같이 나오고.. hidden layer의 파라미터 W의 shape가 (2, 4), b의 shape이 (4, 1), 그리고 output의 W의 shape이 (1, 4), b의 shape이 (1, )이기 때문에 총 17개의 파라미터가 존재하는 것을 확인할 수 있습니다.
plot_decision_boundary(lambda x: model.predict(x) > 0.5, X, Y)분류한 결과를 matplotlib으로 나타내면, 아래와 같이 나타나게 됩니다.

추가적으로 파라미터 초기화를 동일하게 맞추기 위해서 파라미터 초기화에 seed를 설정해서 동일하게 맞추어 주고, hidden layer의 최적화 알고리즘으로 Adam을 사용했을 때는 아래와 같은 결과를 얻었습니다.
def Model(X, Y, epochs=10000, hidden_units=4, activation='tanh', opt='SGD'):
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(hidden_units, activation=activation, kernel_initializer=tf.initializers.glorot_uniform(seed=1)),
tf.keras.layers.Dense(1, activation='sigmoid', kernel_initializer=tf.initializers.glorot_uniform(seed=2))
])
if opt == 'SGD':
optimizer = tf.keras.optimizers.SGD(learning_rate=1.2)
elif opt == 'Adam':
optimizer = tf.keras.optimizers.Adam(learning_rate=1.2)
model.compile(optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(X, Y, epochs=epochs, verbose=0)
print(f'Result of activation:{activation}, optimizer:{opt}, num of hidden units:{hidden_units}')
model.evaluate(X, Y)
return model, history
m, h = Model(X, Y, epochs=10000, hidden_units=4, activation='tanh', opt='Adam')

예상과는 다르게 74.5%의 매우 낮은 결과가 나왔습니다.. 아마 overshooting이 일어났을 것이라고 추측이 되는데, loss 그래프를 살펴보도록 하겠습니다.
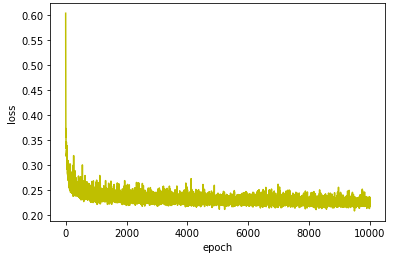
loss가 낮은 값에서 많이 요동치는걸로 봐선 overshooting은 아니고 global optima 주변을 계속 왔다갔다 하는 것으로 보입니다. 아마 learning rate를 감소시키면, 더 좋은 결과가 나올 것으로 예상됩니다.
이번에는 다시 SGD 최적화 알고리즘을 사용해서, hidden layer의 unit 수를 변경하면서 어떻게 결과가 변화하는지 살펴보겠습니다. 반복은 5000회로 감소시켰습니다.
initializer = tf.keras.initializers.GlorotUniform(seed=1)
def Model(X, Y, epochs=10000, hidden_units=4, activation='tanh', opt='SGD'):
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(hidden_units, activation=activation, kernel_initializer=initializer),
tf.keras.layers.Dense(1, activation='sigmoid', kernel_initializer=initializer)
])
if opt == 'SGD':
optimizer = tf.keras.optimizers.SGD(learning_rate=1.2)
elif opt == 'Adam':
optimizer = tf.keras.optimizers.Adam(learning_rate=1.2)
model.compile(optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(X, Y, epochs=epochs, verbose=0)
print(f'Result of activation:{activation}, optimizer:{opt}, num of hidden units:{hidden_units}')
model.evaluate(X, Y)
return model, historyhidden_layer_sizes = [1, 2, 3, 4, 5, 20, 50]
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(5, 2, i+1)
plt.title(f'Hidden Layer of size {n_h}')
m, h = Model(X, Y, epochs=5000, hidden_units=n_h, activation='tanh', optimizer='SGD')
plot_decision_boundary(lambda x: m.predict(x) > 0.5, X, Y)

hidden unit이 많아질수록 더 좋은 결과가 나오긴 하지만, 많다고 꼭 좋은 결과가 나오는 것은 아닌 것으로 보입니다.
+) 파라미터 초기화를 실행할때마다 동일하게 초기화하기 위해서 여러 초기화 방법을 찾아서 적용을 해보았으나... 제가 어떻게 사용하는지 제대로 모르는 것 같습니다... 위처럼 initializer = tf.keras.initializers.GlorotUniform(seed=1)를 사용해서 Dense에서 설정하기도 해보고, 전역으로 tf.random.set_seed를 사용해보기도 했지만... 매번 할때마다 조금씩 결과가 다르게 나왔습니다 ㅠ
이 부분은 조금 더 알아보아야할 것 같습니다.
'ML & DL > tensorflow' 카테고리의 다른 글
| Cat Classification (1) : simple neural network (0) | 2020.11.15 |
|---|---|
| tensorflow에서 random seed 설정 (1) | 2020.11.14 |
| Logistic Regression 예제(iris classification) (0) | 2020.11.13 |
| Linear Regression 간단한 예제 (4) | 2020.11.10 |
| TensorFlow 기본 동작 및 사용법 (0) | 2020.11.10 |




댓글