해당 내용은 Coursera의 딥러닝 특화과정(Deep Learning Specialization)의 두 번째 강의 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization를 듣고 정리한 내용입니다. (Week 3)
- Hyperparameter tuning
[Tuning process]
이전 강의에서 NN을 적용하는데 다양한 Hyperparameter를 세팅하는 것을 알아보았고, 이번 강의에서는 최적의 Hyperparameter를 찾는 방법에 대해서 알아보도록 하겠다.

Hyperparameter는 위와 같이 다양하게 있으며, 각 Hyperparameter의 중요성은 다르다고 할 수 있다.
예를 들어, Adam Optimization의 하이퍼파라미터인 은 거의 변경하지 않고 기본값을 사용하기 때문에 튜닝할 필요가 거의 없다.
하이퍼파라미터 중에서 가 가장 중요하며, 다음으로 노란색 박스의 하이퍼파라미터(, # of hidden units, mini-batch size)가 중요하고, 다음으로는 보라색 박스인 # of layer, learning rate decay가 중요하다고 할 수 있다.
우리가 하이퍼파라미터 값을 튜닝하려고 할 때, 하이퍼파라미터는 어떻게 설정해서 탐색해야할까?
머신러닝 알고리즘 개발 초기에, 2개의 하이퍼파라미터가 있는 경우에 아래 왼쪽과 같이 격자판(grid) 형식으로 샘플링하는 경우가 많았다. 여기서는 5x5 grid로 설정했는데, 즉, 25개의 point가 있으며, 이 point에서 가장 잘 동작하는 것으로 고르는 것이다. 이 방법은 하이퍼파라미터의 개수가 비교적 많지 않은 경우에 잘 동작하는 편이다.

딥러닝의 경우에 추천하는 방법은 각 point의 위치를 오른쪽 이미지처럼 임의로 선택하는 것이다.
이 방법을 사용하는 이유는, 어떤 하이퍼파라미터가 해결하려는 문제에서 가장 중요한지 미리 알 수 없기 때문이다.
극단적인 예를 들어서, 하이퍼파라미터1은 learning rate인 이고 하이퍼파라미터2는 Adam 알고리즘의 이라고 해보자. 이런 경우에는 는 매우 중요하고 은 거의 중요하지 않을 것이다. 따라서, 왼쪽같이 격자판 형식으로 샘플링을 진행하면 25개의 모델을 학습했지만, 5개의 값으로만 시도할 수 있을 것이다.
반대로 샘플링을 무작위로 진행한다면, 각각 25개의 를 시도하게 된다.
정리를 하자면,
우리가 작업하는 app에서 어떤 하이퍼파라미터가 더 중요한지 미리 알아내기 어렵기 때문에, 격자판 형식으로 샘플링하는 것보다 무작위로 샘플링하는 방법이 더 많은 하이퍼파라미터 값을 탐색해볼 수 있기 때문에, 더 광범위하게 학습을 진행할 수 있다.
- Coarse to find
하이퍼파라미터를 샘플링하는 경우에 Coarse to find searching 방법이 자주 사용되는데, 이 방법의 아이디어는 다음과 같다.
Coarse to find는 위와 같이 샘플링된 point를 탐색해서 파란색 사각형 내부에서 잘 동작한다고 알아냈을 때, 이 사각형 포인트로 줌인하여 파란색 사각형 공간에 대해서 밀도를 높혀서 샘플링을 또 다시 샘플링해서 탐색하는 방법이다.
Course to find searching은 임의의 샘플링을 진행하고, 충분히 탐색한 후에 선택적으로 사용하면 된다.
[Using an appropriate scale to pick hyperparameters]
이번에는 범위가 다른 하이퍼파라미터에서 조금 더 효율적으로 하이퍼파라미터를 탐색하는 방법에 대해서 알아볼 것이다. 단순히 임의로 하이퍼파라미터를 샘플링하는 것은 특정한 유효한 범위에서 탐색하는 것이 아니기 떄문에 조금 비효율적이기 때문에, 적합한 scale을 선택해서 하이퍼파라미터를 탐색하는 것이 중요하다.
만약 우리가 hidden unit의 개수인 의 값을 탐색한다고 가정해보자. 그리고 잘 동작하는 범위는 50 ~ 100이라고 가정하자. 이 경우에는 특정 hidden unit의 개수가 50~100사이의 값으로 선택하는 것이 비교적 합리적인 방법이라고 할 수 있다.
다른 예시로, NN의 layer 개수를 결정하려고 하면, 우리는 layer의 개수가 2 ~ 4개가 잘 동작한다고 생각할 수 있고, 그렇다면 2,3,4 사이에서 선택하는 것이 합리적일 수 있을 것이다.
이렇게 임의의 방법으로 샘플링하는 경우, 적절한 범위의 값으로 샘플링하는 것이 합리적일 것이다. 물론, 모든 하이퍼파라미터에 적용되는 것은 아니다.
이번에는 learning rate 를 탐색한다고 해보자. 이 경우에는 0.0001에서 1 사이의 값으로 임의로 균일화되게 샘플링을 진행하면, 약 90%의 값이 0.1과 1 사이에 있을 것이다. 즉, 샘플링의 90% 정도를 0.1에서 1 사이의 값에 집중하게 되는 것이고, 10% 정도만이 0.0001과 0.1 사이의 값에 집중하는 것이다.
이런 방법을 적절하지 않기 때문에, 위 방법 대신에 하이퍼파라미터를 linear scale이 아닌 log scale을 적용해서 탐색하는 것이 더 적합할 것이다.
파이썬에서는 -4 * np.random.rand()로 -4에서 0사이의 값을 임의로 균일하게 선택하고, 10의 지수로 사용하면, 0.0001에서 1 사이의 값을 더 적절하게 샘플링할 수 있다.
[Hyperparameters for exponentially weighted averages]
Exponentially Weighted Averages의 하이퍼파라미터 샘플링은 조금 헷갈릴 수 있는데 한 번 알아보도록 하자. 적절한 의 값은 0.9에서 0.999사이의 값이라고 하면, 우리가 탐색해야되는 범위도 0.9 ~ 0.999가 된다.
위와 같은 범위에서 균등하게 탐색하려면 linear scale이 아닌 log scale로 탐색을 해야한다.
가장 쉬운 방법은 1-의 범위를 찾는 것이고, 즉, 0.001 ~ 0.1 사이의 값을 찾는 것이다.
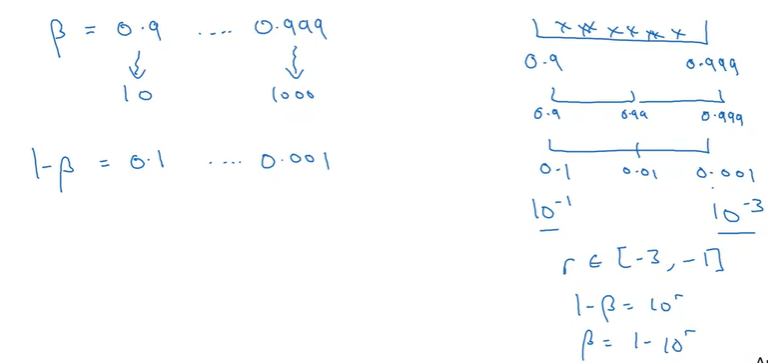
-3 ~ -1 사이의 값을 임의로 샘플링해서 10의 지수승으로 사용한 다음에 이 값을 1에서 빼면, 우리가 탐색하려는 의 범위가 될 것이다.
여기서 수학적으로 왜 linear scale로 샘플링을 하게 되면 안되는 지 알아보도록 하자.
결과적으로 EWA에서 의 값은 1에 가까워질수록 결과에 민감해진다.
만약 beta의 값이 0.9000에서 0.9005로 0.0005가 증가하더라도, 이 것은 10개 example에 대한 평균이라고 할 수 있다. 크게 결과값에 영향을 주지 않은 것처럼 보인다.
반면에 beta의 값이 0.9990에서 0.9995로 동일하게 0.0005가 증가하면, 결과에 많은 차이를 보이게 된다. 0.999는 1000개의 example에 대한 평균이지만, 0.9995는 2000개의 example에 대한 평균이 되기 때문에 결과값이 큰 차이를 보이게 될 것이다.
그래서 linear scale로 샘플링을 진행하게 되면, beta가 1에 근접한 범위에서 대부분 샘플링할 것이기 때문에 적절하지 않은 것이다.
[Hyperparameters tuning in practice: Pandas vs. Caviar]
하이퍼파라미터 탐색 Tip
딥러닝은 오늘날 많은 분야에서 적용되어 있는데, 한 분야에서 사용되는 적절한 하이퍼파라미터가 다른 분야에 적용(cross-fertilization)이 될 수 있다.
예를 들어서, 컴퓨터 비전의 아이디어(Confonets or ResNets)들이 Speech분야(NLP)에 성공적으로 적용되기도 했다.
이런 결과를 보면서 딥러닝의 개발은 다른 영역, 분야의 다양한 논문을 더 많이 읽고, cross-fertilization의 영감을 얻는 것도 유용하다.
그리고, 모델을 학습하고 적절한 하이퍼파라미터의 값을 찾았더라도, 시간이 지나면서 데이터가 변하거나, 데이터센터의 서버를 업그레이드하거나, 이러한 변화들 때문에 우리가 찾은 하이퍼파라미터의 값이 더 이상 최적의 파라미터가 아니게 될 수 있다. 그렇기 때문에 retesting하거나 하이퍼파라미터를 re-evaluate하는 것을 추천한다.(몇개월에 한번)
다음으로 하이퍼파라미터는 탐색하는 방법에 대해서 알아보자.
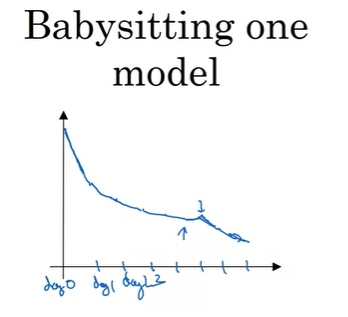
2가지의 방법이 있는데, 하나는 Babysitting one model이다.
이 방법은 데이터의 양이 매우 많고, 연산을 위한 Resource가 많이 없을 때 적용되며, Resource는 CPU나 GPU를 의미하고, 충분하지 않아서 한 번에 1가지 모델만 학습할 수 있을 경우를 의미한다.
예를 들어서, day 0일때, 파라미터를 임의로 초기화시키고 학습을 한다. 그리고 learning curve(cost J에 대한 그래프)를 보면서, 적절하게 동작한다면 감소하는 learning curve를 볼 수 있을 것이다. 그렇게 day 1이 지나면서 cost가 감소하는 것을 확인하고 learning speed를 약간 높힐 수 있고, day 2의 결과를 확인한다. day 2의 성능도 좋다는 것을 확인할 수도 있는데, 이런 방식으로 진행하다가 보면 어느날에는 learning speed가 너무 컸다는 것을 깨달을 수 있는데, 이렇게 되면 이전 모델로 다시 돌아갈 것이다.
설명했듯이 이 방법은 하루씩 babysitting을 하는 것이고, 한 가지 모델을 학습하고 성능을 확인하면서 learning speed를 조정해준다.
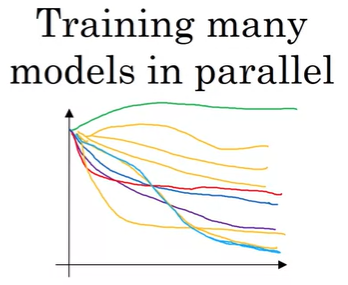
다른 방법으로는 Training many models in parallel인데, 이 방법은 parallel 방식으로 여러 모델을 한 번에 학습하는 방법이다. 어느 한 모델에 대해서 어떤 하이퍼파라미터의 값을 설정해서 학습할 수 있고, 또 다른 모델은 다른 하이퍼파라미터의 값으로 설정해서 학습할 수 있다. 따라서 여러 모델에 대한 그래프인 아래와 같은 learning curve를 얻을 수 있을 것이다.
위와 같은 방법은 동물들이 번식하는 방법으로 비유해서, Babysitting one model방법은 panda approach라 부르고 Training many models in parallel방법은 Caviar approach라고 불리기도 한다.
이 2개의 방법을 고르는 방법은, 우리가 얼마나 resource를 가지고 있느냐에 따라 달라진다. 만약 충분한 CPU/GPU resource가 있다면 여러 개의 모델은 parallel하게 한 번에 학습시킬 수 있으면 Caviar approach를 선택해도 무방하다. 다만, 어느 영역, 예를 들어서 온라인 광고 설정이나 컴퓨터 비전 영역에서는 데이터가 무수히 많아서 학습하려는 모델이 매우 방대해서 한 번에 여러 모델들을 학습시키기가 매우 어려울 수도 있어서, Panda approach를 사용하는 경우도 있다.
- Batch Normalization
[Normalizing activations in a network]
Batch Normalization은 하이퍼파라미터 탐색을 더 쉽게 만들어주고, Neural Network를 더욱 견고하게 한다.
어떻게 Batch Normalization이 동작하는지 살펴보자.
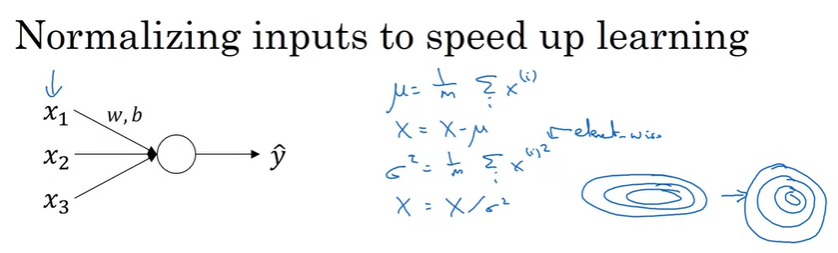
Logistic Regression이나 Linear Regression에서의 Normalization은 input의 평균과 분산을 조절해서 더 동그란 모습으로 cost를 변형해서 GD의 속도를 높혀준다.
deep한 moel의 경우에는 입력이 x만 있는 것이 아니라, activation도 있는데, 이 경우에 Batch Normalization 알고리즘을 적용한다.
위 NN에서 ouput layer의 이전 layer의 입력은 이고, 이 값을 Normalization을 할 수 있는 지가 문제이다. 그리고 이 방법은 을 더 빨리 학습시키는 방법이고, 는 의 학습에 영향을 준다.
이 방법이 Batch Normalization이고 줄여서 Batch Norm이라고 한다. 엄밀히 이야기하자면 가 아닌 를 Normalization하는 것인데(를 Normalization해도됨), 이 방법을 어떻게 적용하는지 살펴보도록 하겠다.
어떤 hidden layer 에서 hidden unit 값 가 주어졌을 때, 평균(mean)과 분산(variance)와 Normalization은 다음과 같이 구할 수 있다.(은 생략함)
마지막의 와 는 모델에서 학습하는 parameter이고, Gradient Descent/Momentum/RMSprop/Adam을 통해서 학습할 수 있다.
와 를 사용하지 않으면 normalization을 통해서 hidden unit은 항상 평균이 0, 분산이 1이 되므로 이것은 올바르지 않기 때문에 와 를 통해서 의 평균을 원하는 값이 되도록 해준다. 즉, 각 hidden unit이 다른 평균과 분산을 갖도록 한다.
만약 activation function이 sigmoid이고, 평균이 0, 분산이 1로 normalization을 했다면 a의 값은 linear한 영역에 밀집되어서 정상적으로 학습이 되지 않을 것이다.

추가적으로 만약 로 설정한다면, 가 되는 것과 동일하다.(기존 input값 유지)
이렇게 normlization을 통해서, 를 사용해서 모델에 fitting하면 된다.

[Fitting Batch Norm into a neural network]
어떻게 Batch Norm이 deep neural network에 적용되는지 살펴보자.
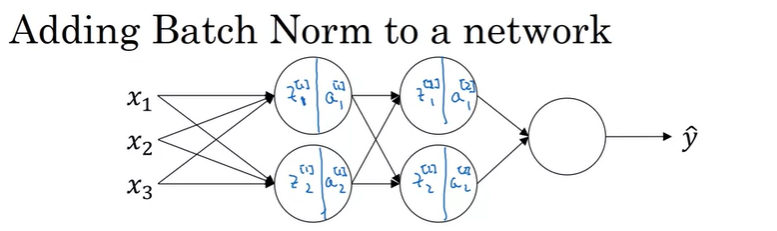
위와 같은 NN이 있을 때, Batch Norm을 적용하면 FP는 다음과 같이 진행할 수 있다.
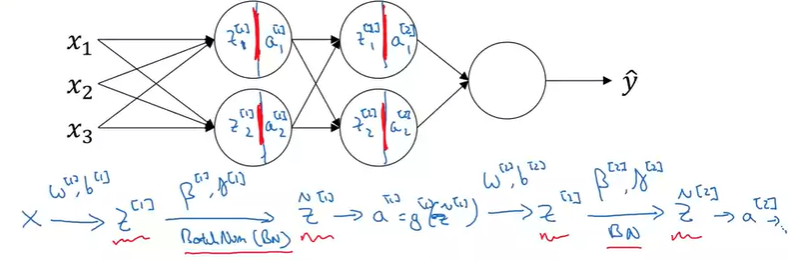
input x와 를 통해서 구하고, 를 통해서 Batch Norm을적용해서 를 구한다. 그리고 normalization이 적용된 을 activation function을 통해서 를 구한다. 그리고 다음 layer에서도 마찬가지로 진행하게 된다.
위에서 나타나는 파라미터는 다음과 같다.
여기서 는 Adam이나 momentum의 와는 다르다.
새로운 파라미터인 도 와 같은 방법으로 학습되며, GD뿐만아니라 Adam 등의 최적화 알고리즘이 적용되었을 때도 동일하다.
만약 Deep learning Framework를 사용하는 경우에는 직접 구현할 필요는 없다.
ex) if tensorflow -> use ft.nn.batch_normalization
mini-batch에서 batch norm을 적용하면 다음과 같이 적용된다. 위에서 적용한 batch norm과 동일하다. 주의해야할 점은 각 mini-batch의 데이터만으로 normalization을 적용해야한다.

그리고 파라미터에서 은 무시될 수 있는데, batch norm에서 평균값을 구하고, input에 평균값을 빼기 때문에 상수항을 더하는 것은 아무런 효과가 없어지기 때문이다. 따라서 이 파라미터를 제거하거나 0으로 설정할 수 있다.
는 bias나 이동에 영향을 주는 항이다.
Batch Norm을 mini-batch에 사용해서 Gradient Descent 진행은 아래와 같이 수행된다.
for t = 1, ... , # of mini-batch size
Compute forward propagation on
In each hidden layer, use Batch Norm to replace with
Use backward propagation to compute
Update parameters
(*parameter 는 제거가능)
물론 momentum, MRSprop, Adam 등의 최적화 알고리즘과도 같이 사용이 가능하다.
[Why does Batch Norm work?]
Batch Norm이 왜 잘 동작하는지 살펴보도록 하자.
첫 번째 이유는 아까 살펴보았듯이 input feature를 normalization하여서 평균을 0, 분산을 1로 만들어 주고, 이것이 학습의 속도를 증가시킨다. 모든 특성을 normalization하기 때문에, input feature x가 비슷한 범위를 갖게 되고, 이로 인해서 학습의 속도가 증가하는 것이다. 그리고, 이 normalization은 input layer뿐만 아니라 hidden unit에 대해서도 적용한다.
두 번째 이유는, batch normalization을 통해서 모델이 weight의 변화에 덜 민감해지기 때문이다.
우선 Logistic Regression으로 구현한 고양이 판별 예제를 살펴보도록 하자.

위와 같은 Logistic Regression에서 우리가 모든 데이터를 검은 고양이의 사진으로 학습을 진행했다고 가정한다면, 이 모델이 오른쪽의 색깔이 있는 고양이에 적용하면, 분류기가 잘 동작하지 않을 수 있다.
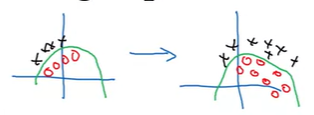
왼쪽은 검은 고양이사진 샘플일 때의 데이터 분포이고, 오른쪽은 색깔이 있는 고양이의 데이터 분포가 될 수 있다. 그래서 왼쪽의 샘플로들로만 학습된 모델의 경우에는 오른쪽 색깔이 있는 고양이에 대해서 일반화가 안되어서 분류가 잘 안될 수 있다. 이렇게 데이터의 분포가 변하는 것을 covariate shift라고 불리는데, 만약 입력 x의 분포도가 변경되면 학습 알고리즘을 다시 학습시켜야 할 수도 있다(위와 같이 판별 함수가 변경되지 않더라도).
그렇다면 이러한 covariate shift 문제가 Neural Network에는 어떻게 적용되는 지 한번 알아보도록 하자.
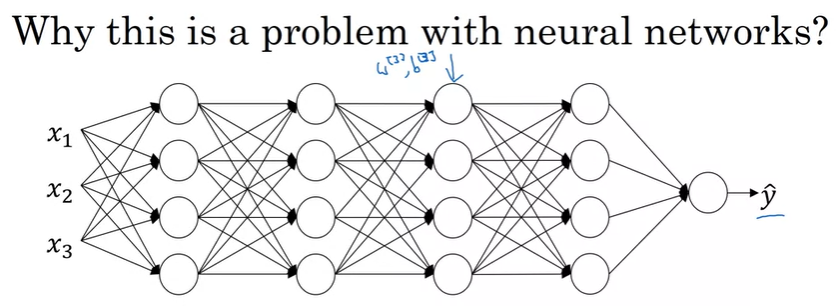
위와 같은 NN이 있다고 할 때, 우리는 일단 3번째 layer를 기준으로 살펴볼 것이다. 이 layer에서는 을 학습했을 것이다. 그리고 3번째 layer 기준으로 feature의 값을 이전 layer에서 계산된 값으로 사용하는데, hidden layer 3의 역할은 를 입력으로 사용해서, 이 값들을 통해서 값으로 매핑할 것이다.(GD를 진행하면서 이런 파라미터를 학습해서 네트워크가 값에 대해서 매핑을 잘할 수 있게 된다)
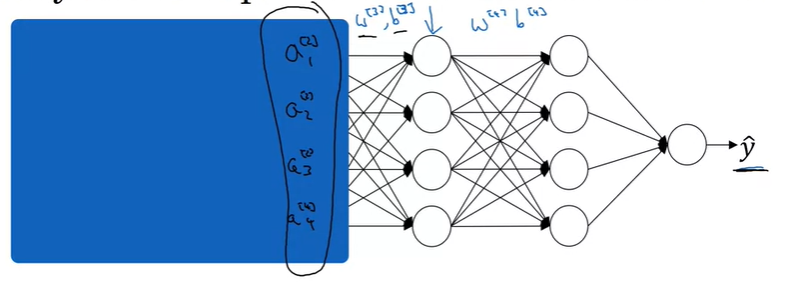
그럼 이제 layer 3 왼쪽의 network를 살펴보도록 하자.
input x에서부터 network는 를 사용할 것이고, 가 변경되면, 의 값들도 변경될 것이다.
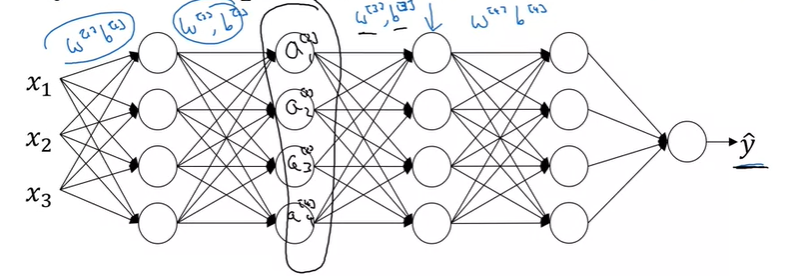
그렇다면 세번째 layer 기준에서 살펴보면, 는 항상 변하는 것이고, 언급했었던 covariate shift 문제가 발생하게 된다.
여기서 Batch Normalization의 역할이 이런 hidden unit의 분포가 변경되는 정도를 줄여준다.
엄밀히 말하자면 를 normalization하는 것인데, 가 이전 layer의 파라미터들을 업데이트하면서 변할 수 있는데, batch normalization은 이 값들이 변경되더라도 평균값과 분산은 똑같게 유지해준다.(평균 1, 분산 0으로 만들 수도 있으며, 다른 값으로 유지시키는 것도 가능. 이것은 를 통해서 조절)
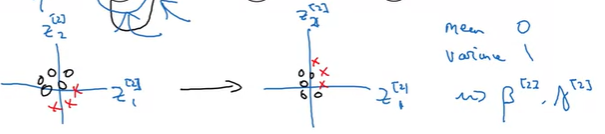
여기서 는 새로 학습해야하는 파라미터이다.
결과적으로 Batch Normalization은 input 값이 변해서 생기는 문제들을 줄여준다. 입력의 분포도가 약간 변경될 수는 있지만, 변경되는 정도를 줄여주고 결과적으로 다음 layer에서 학습해야되는 양을 줄여주어서 더 안정적으로 학습할 수 있게 한다.
이것은 결과적으로 전체 네트워크의 학습 속도를 증가시켜주는 효과를 주게 된다.
정리를 하자면 batch normalization은 이전 layer의 이동폭이 크지 않도록 똑같은 평균값과 분산을 가지게 해서 다음 layer의 학습을 더 수월하게 해준다.
추가적으로 Batch Normalization은 Regularization의 효과가 있다.

각 mini-batch에서는 해당되는 mini-batch의 데이터로만 mean/variance를 계산했기 때문에 전체 샘플로 했을 구했을 때보다 더 noisy하고, 결과적으로 또한 noisy해 질 것이다. 그 결과, dropout과 유사하게 hidden layer activation에 noisy를 더하게 되는 것이고, 이로 인해서 regularization의 효과가 발생하는 것이다. 그러나 noisy의 정도는 작기 때문에, 큰 효과는 없다(dropout을 같이 사용할 수 있다).
만약 mini-batch의 size가 크다면(64->256), regularization의 효과를 감소시키는 것이다(noisy가 감소하기 때문).
Batch Norm을 Regularization을 위해 사용하는 것은 권장하지 않는다.
[Batch Norm at test time]
Batch Norm의 공식을 다시 정리하면 다음과 같고, 각 mini-batch에서 진행하게 된다.
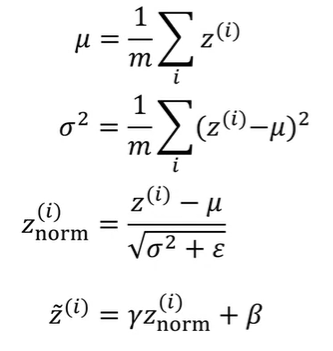
하지만 test time에서는 mini-batch size만큼(64, 128, 256)의 example들을 한번에 처리할 수 있는 mini-batch가 없을 수 있다. 그래서 평균과 분산을 구하기 위해서는 다른 방법이 필요할 것이다. 만약 테스트에서 1개의 example밖에 없는 경우에는, 1개의 값을 가지고 평균과 분산을 구하는 것은 적절하지 않기 때문이다.
그래서 test time에서 적용하기 위해서는 별도의 평균과 표준편차의 예측값을 구해야한다. 일반적인 Batch Normalization의 경우에는 Exponetially Weighted Average를 사용하고, 그 예측값은 mini-batch에서의 평균값들으로 구한다.
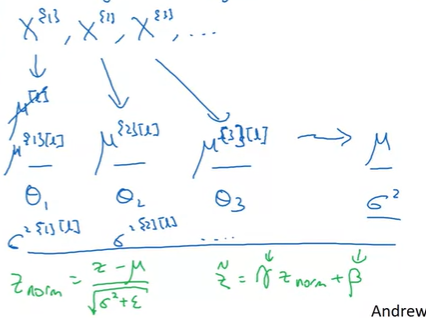
즉, 특정 layer에서 각 mini-batch에서의 을 로 사용해서 test에서 사용할 을 구해서, Batch Normalization을 적용하는 것이다.
위 방법이 아니더라도, 전체 sample을 사용해서 평균과 분산의 예측값을 구해서 사용해도 되지만, 보통 EWA를 사용한다. EWA는 학습에 사용되는 값들을 사용해서 예측값을 구하기 때문에 running average라도 불리기도하며, 꽤 정확하고 stable한 편이다.
'Coursera 강의 > Deep Learning' 카테고리의 다른 글
| ML Strategy 1(orthogonalization, evaluation metric, human-level performance) (0) | 2020.10.25 |
|---|---|
| Multi-class classification(Softmax regression) (0) | 2020.10.11 |
| [실습] Optimization Methods(Mini-batch, Momentum, Adam Algorithm) (0) | 2020.10.02 |
| Optimization(최적화 알고리즘) : Mini-batch/Momentum/RMSprop/Adam (0) | 2020.10.02 |
| [실습] Gradient Checking (0) | 2020.09.26 |




댓글