References
- CUDA Toolkit Documentation - CUDA Runtime API (link)
Contents
- Legacy Default Stream
- Per-thread Default Stream
[프로그래밍/CUDA] - API Synchronization Behavior
API Synchronization Behavior
References CUDA Toolkit Documentation - CUDA Runtime API (link) Contents Difference between the driver and runtime APIs API Synchronization Behavior 이번 포스팅에서는 CUDA의 API에 대한 동기/비동기..
junstar92.tistory.com
지난 포스팅에서 CUDA Runtime/Device API의 동기/비동기 동작을 살펴봤습니다.
이번 포스팅에서는 CUDA Stream의 동기/비동기 동작에 대해서 살펴보도록 하겠습니다.
Default Stream
잘 아시다시피 default stream은 API의 인자 중 cudaStream_t에 0을 전달하거나, 암시적으로 스트림을 사용하는 API에 의해서 사용됩니다. 아마 여기까지는 잘 아실 것이라고 생각됩니다.
지금부터 알아볼 내용은 아마도 공식 문서에서 봤지만 그냥 지나쳤을 가능성이 높거나, 제대로 파악하지 못하고 있을 가능성이 높을 것 같습니다.
default stream의 동작은 legacy와 per-thread, 두 가지 동작 중 하나로 설정하여 동기화 동작을 configuration할 수 있습니다. 아래에서 두 동작에 대해서 자세히 살펴볼 텐데, 이러한 동작은 nvcc로 컴파일 할 때, --default-stream 옵션을 통해서 설정할 수 있습니다. 또는, 컴파일 옵션을 사용하지 않고 처음 어떤 CUDA Header를 include하기 전에 CUDA_API_PER_THREAD_DEFAULT_STREAM 매크로를 정의하여 per-thread로 동작하도록 설정할 수도 있습니다.
어떤 방법이든지, per-thread 동기화 동작을 사용하게 된다면 CUDA_API_PER_THREAD_DEFAULT_STREAM 매크로는 컴파일 단계에서 정의됩니다.

그렇다면 이제 legacy와 per-thread 동작이 어떻게 다른지 살펴보도록 하겠습니다.
Legacy Default Stream
legacy default stream은 동일한 CUcontext에서 non-blocking streams을 제외한 다른 모든 스트림과 동기화하는 implicit stream입니다. 우리가 일반적으로 알고 있는 default stream과 동일합니다.
예를 들어, 아래의 코드를 살펴보도록 하겠습니다.
__global__
void kernel(float* x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = tid; i < n; i += stride) {
x[i] = sqrt(pow(3.14159, i));
}
}
int main()
{
const int N = 1 << 22;
float* data1, *data2, *data3;
cudaMalloc(&data1, sizeof(float) * N);
cudaMalloc(&data2, sizeof(float) * N);
cudaMalloc(&data3, sizeof(float) * N);
cudaStream_t s;
cudaStreamCreate(&s);
kernel<<<1, 64, 0, s>>>(data1, N);
kernel<<<1, 64>>>(data2, N);
kernel<<<1, 64, 0, s>>>(data3, N);
cudaDeviceSynchronize();
cudaFree(data1);
cudaFree(data2);
cudaFree(data3);
cudaDeviceReset();
}여기서 24~26 lines의 커널 호출 부분을 살펴봅시다. 첫 번째와 세 번째 커널은 스트림 s에서 실행되고, 두 번째 커널은 명시적으로 스트림이 지정되지 않았으므로 default stream에서 실행됩니다.
default stream은 다른 모든 스트림을 blocking하기 때문에 첫 번째 커널 실행은 두 번째 커널 실행을 blocking하고, 두 번째 커널 실행 또한 세 번째 커널 실행을 blocking하게 됩니다.
위 코드를 nvcc로 컴파일 한 뒤, Nsight System으로 커널이 어떻게 실행되는지 살펴보겠습니다. nvcc로 컴파일 할 때, 특별한 옵션을 지정할 필요는 없습니다. 저는 아래의 커맨드로 컴파일하였습니다.
nvcc -o legacy-default-stream legacy-default-stream.cu

예상한 대로 blocking 때문에 각각의 커널이 순차적으로 실행된 것을 확인할 수 있습니다.
반면, non-blocking 스트림은 legacy default stream과 동기화하지 않습니다. cudaStreamCreateWithFlags() API를 통해서 스트림을 생성할 때, cudaStreamNonBlocking 플래그를 지정할 수 있는데, 이렇게 생성된 스트림은 default stream에 대해 non-blocking입니다.
int main()
{
const int N = 1 << 22;
float* data1, *data2, *data3;
cudaMalloc(&data1, sizeof(float) * N);
cudaMalloc(&data2, sizeof(float) * N);
cudaMalloc(&data3, sizeof(float) * N);
cudaStream_t s;
cudaStreamCreateWithFlags(&s, cudaStreamNonBlocking);
kernel<<<1, 64, 0, s>>>(data1, N);
kernel<<<1, 64>>>(data2, N);
kernel<<<1, 64, 0, s>>>(data3, N);
cudaDeviceSynchronize();
cudaFree(data1);
cudaFree(data2);
cudaFree(data3);
cudaDeviceReset();
}main 함수를 위와 같이 수정하고, 다시 컴파일하여 결과를 확인해보도록 하겠습니다.
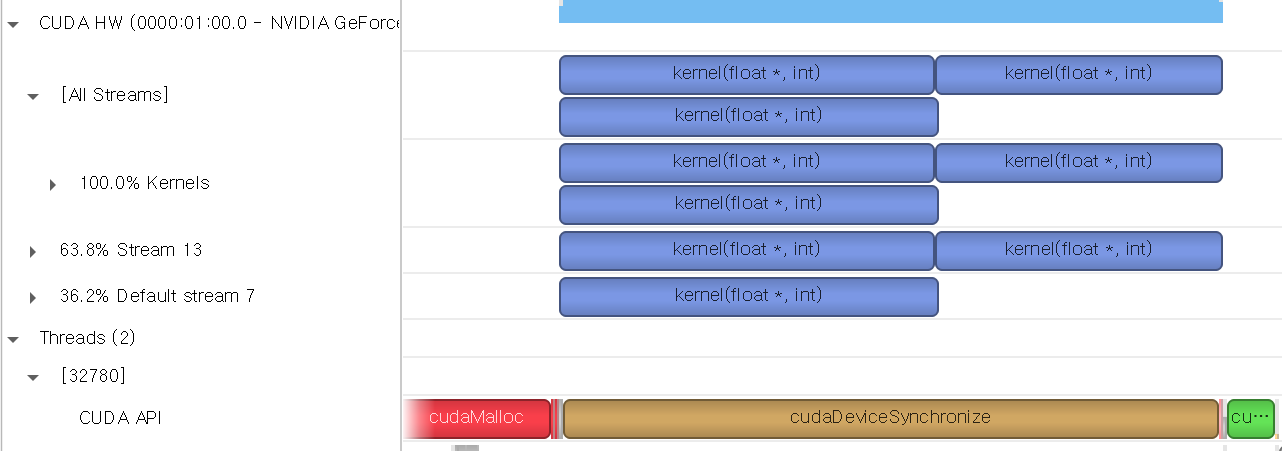
이제 생성된 스트림이 non-blocking으로 생성되어, 두 커널 사이에 default stream에서 실행되는 커널이 있더라도 blocking되지 않고 동시에 실행된 것을 확인할 수 있습니다.
Per-thread Deafult Stream
Per-thread Default Stream은 CUcontext나 thread 모두에서 암시적으로 local인 스트림입니다. 따라서, 명시적으로 생성된 스트림과 같이 다른 스트림과 동기화하지 않으며, 비동기적으로 동작합니다.
따라서, per-thread 동작으로 설정되면, default stream이 명시적으로 생성된 스트림처럼 동작하게 됩니다. legacy로 설정되었을 때는 default stream은 다른 스트림들을 blocking하는 성질이 있었지만, per-thread로 설정하면 명시적으로 생성된 스트림과 같이 다른 스트림들을 blocking하지 않는다는 것을 의미합니다.
코드를 통해서 조금 더 자세히 살펴보도록 하겠습니다.
__global__
void kernel(float* x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = tid; i < n; i += stride) {
x[i] = sqrt(pow(3.14159, i));
}
}
int main()
{
const int N = 1 << 22;
const int num_streams = 8;
cudaStream_t streams[num_streams];
float* data[num_streams];
for (int stream = 0; stream < num_streams; stream++) {
cudaStreamCreate(&streams[stream]);
cudaMalloc(&data[stream], sizeof(float) * N);
// launch one worker kernel per stream
kernel<<<1, 64, 0, streams[stream]>>>(data[stream], N);
// launch a dummy kernel on the default stream
kernel<<<1, 1>>>(0, 0);
}
for (int stream = 0; stream < num_streams; stream++) {
cudaFree(data[stream]);
}
cudaDeviceReset();
}위 코드에서는 8개의 스트림을 생성하고, for-loop를 통해서 각 반복마다 스트림에서 커널을 실행시킨 후 바로 default stream에서 커널을 실행시킵니다. legacy 동작으로 설정하여 컴파일한 뒤, Nsight System으로 살펴본 결과는 다음과 같습니다.

각 스트림에서의 커널 실행 사이마다 default stream에서의 커널 실행이 포함되어 있기 때문에 위와 같이 모든 커널들이 순차적으로 수행된다는 것을 확인할 수 있습니다. 이와 같은 legacy 동작이 우리가 잘 알고 있는 default stream의 동작일 것입니다.
이번에는 동일한 코드를 컴파일 할 때, '--default-stream per-thread' 옵션을 추가하여 컴파일 한 뒤 그 결과를 살펴보겠습니다.
nvcc --default-stream per-thread -o multi-stream-per-thread multi-stream.cu
그 결과는 다음과 같습니다.
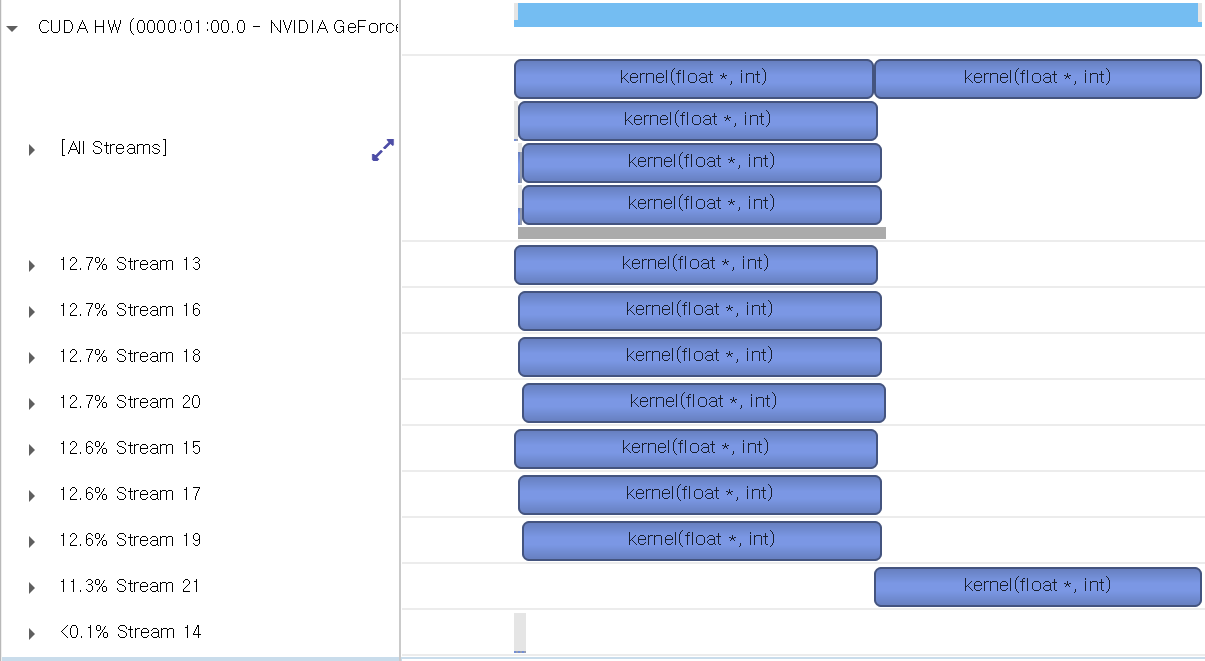
아마 GPU가 좋으면 8개의 스트림이 동시에 수행되는 결과를 얻을 수 있을 것입니다. 저의 경우에는 리소스가 부족하거나 다른 이유로 인해서 7개까지만 동시에 수행되고 나머지 하나는 리소스가 부족해서 이후에 수행된 것으로 보입니다. 이처럼 동일한 코드였지만, 스트림의 동작을 per-thread로 설정하게 되면 default stream의 동작이 달라진다는 것을 확인할 수 있습니다. 즉, per-thread로 설정하게 되면, default stream이 명시적으로 생성된 다른 스트림과 동일한 성질을 갖게 됩니다.
Nsight System에서도 Default stream 7로 표시되던 것이 Stream 14로 표시되고 있습니다.
이번에는 multi-thread 환경에서의 동작을 살펴보겠습니다. per-thread로 설정하면, 각각의 thread에서 각자의 default stream을 가지게 되므로 모든 커널이 동시에 수행될 것이라고 예상할 수 있습니다.
먼저 테스트 코드를 legacy로 컴파일하여 그 결과를 살펴보고, 그 다음 per-thread로 컴파일하여 결과를 비교해보도록 하겠습니다.
#include <thread>
__global__
void kernel(float* x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = tid; i < n; i += stride) {
x[i] = sqrt(pow(3.14159, i));
}
}
void launch_kernel(float* data, int n)
{
cudaMalloc(&data, sizeof(float) * n);
kernel<<<1, 64>>>(data, n);
cudaStreamSynchronize(0);
}
int main()
{
const int N = 1 << 22;
const int num_threads = 8;
float* data[num_threads];
std::thread threads[num_threads];
for (int i = 0; i < num_threads; i++) {
threads[i] = std::thread(launch_kernel, data[i], N);
}
for (int i = 0; i < num_threads; i++) {
if (threads[i].joinable()) {
threads[i].join();
}
cudaFree(data[i]);
}
cudaDeviceReset();
}코드는 위와 같습니다. 총 8개의 스레드를 생성하고, 각 스레드에서 커널을 실행시킵니다.
legacy로 컴파일 한 뒤, 프로파일링한 결과는 다음과 같습니다.
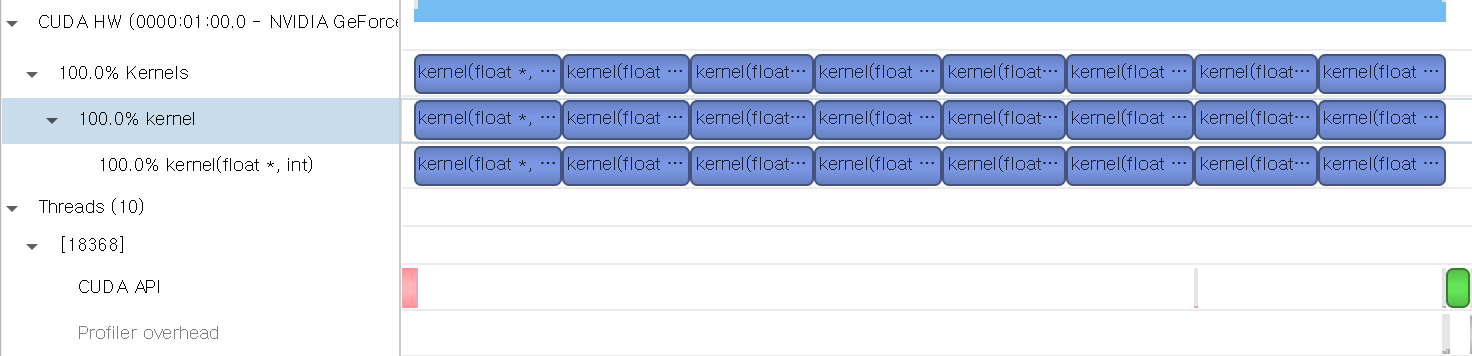
각 스레드에서 모든 커널이 동일한 default stream에서 동작하므로, 모든 커널이 순차적으로 수행됩니다. 따라서 Nsight System에서 스트림에 대한 정보는 따로 표시되지 않는 것을 확인할 수 있습니다.
이번에는 동일한 코드를 per-thread로 컴파일 한 결과입니다.

각 스레드에서 수행되는 커널들이 자신만의 default stream에서 수행된다는 것을 확인할 수 있습니다.
그리고 각 스레드에서 사용된 default stream이 Nsight System에서 Stream 13 등으로 표시되고 있습니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| NVIDIA 라이브러리 스터디 repo (0) | 2023.07.30 |
|---|---|
| TensorRT CMake 스크립트 (FindTENSORRT.cmake) (2) | 2023.07.24 |
| API Synchronization Behavior (0) | 2022.06.18 |
| NVIDIA Tools Extension (NVTX) (0) | 2022.06.17 |
| Multiple GPUs with CUDA C++ (0) | 2022.06.16 |


댓글