References
- Scaling Workloads Across Mutliple GPUs with CUDA C++
Contents
- Concurrency Strategies
- Multiple GPUs
- Use non-default Streams with Multiple GPUs
이번 포스팅에서는 NVIDIA Online Training 중 다중 GPU를 사용하는 방법에 대한 강의, Scaling Workloads Across Multiple GPUs with CUDA C++에 대한 내용을 정리하였습니다.
Concurrency Strategies
일반적으로 GPU Programming은 다음의 3 Steps로 구성됩니다.
- Transfer data to GPU device(s)
- Perform computation on GPU device(s)
- Transfer data back to the host

보통 전체 실행 시간은 각 단계에서 걸린 시간을 모두 더한 것과 같습니다.
만약 메모리 전송(memory transfer)과 연산(compute)를 오버랩할 수 있다면, 전체 실행 시간은 이전보다 짧아질 수 있습니다. 이 경우에는 CUDA Streams을 사용한 것이라고 볼 수 있습니다.

그리고, 여러 개의 GPU 디바이스를 사용하면 다음과 같이 연산(compute)를 오버랩할 수 있습니다.

이 경우에도 총 실행 시간은 이전보다 약간 줄어든 것을 확인할 수 있습니다.
위의 두 방법을 조합하면, 다음과 같이 데이터를 디바이스의 수로 분할하고 각 카피와 연산을 오버랩시킬 수 있습니다.

따라서, 이번 강의의 목적은 single-node CUDA C/C++ 어플리케이션의 성능을 아래의 두 가지 전략을 통해서 증가시키는 방법을 알아보는 것입니다.
- 메모리 전송(memory transfer)과 연산(compute) 오버랩
- 각 연산을 하나 이상의 GPU에서 동시에 수행
Application Overview
우선 사용할 베이스 코드를 간단하게 살펴보겠습니다. 전체 코드는 포스팅 마지막 부분에 있으니 참조바랍니다.
int main()
{
const uint64_t num_entries = 1UL << 26;
const uint64_t num_iters = 1UL << 10;
const bool openmp = true;
Timer timer, overall;
uint64_t *data_cpu, *data_gpu;
timer.start();
cudaMallocHost(&data_cpu, sizeof(uint64_t) * num_entries);
cudaMalloc(&data_gpu, sizeof(uint64_t) * num_entries);
timer.stop("allcate memory");
timer.start();
// encrypt data
encrypt_cpu(data_cpu, num_entries, num_iters, openmp);
timer.stop("encrypt data on CPU");
overall.start();
timer.start();
// Data copy from CPU to GPU
cudaMemcpy(data_gpu, data_cpu, sizeof(uint64_t) * num_entries, cudaMemcpyHostToDevice);
timer.stop("copy data from CPU to GPU");
timer.start();
// Decrypt data on GPU(s).
decrypt_gpu<<<80 * 32, 64>>>(data_gpu, num_entries, num_iters);
timer.stop("decrypt data on GPU");
timer.start();
// Copy data from GPU to CPU
cudaMemcpy(data_cpu, data_gpu, sizeof(uint64_t) * num_entries, cudaMemcpyDeviceToHost);
timer.stop("copy data from GPU to CPU");
// Stop timer for total time on GPU(s).
overall.stop("total time on GPU");
timer.start();
// Check results on CPU.
const bool success = check_result_cpu(data_cpu, num_entries, openmp);
std::cout << "STATUS: test " << (success ? "passed" : "failed") << std::endl;
timer.stop("checking result on CPU");
timer.start();
// Free memory
cudaFreeHost(data_cpu);
cudaFree(data_gpu);
timer.stop("free memory");
}위 코드는 파이스텔 암호(Peistel Cipher)를 암호화하고 복호화하는 코드를 사용하는데, 여기서 암호화/복호화 과정을 자세히 알고 있을 필요는 없습니다. 필요한 것은 암호화된 코드를 복호화하는 함수가 device function이며, 우리는 이 복호화에 걸리는 시간을 다중 GPU를 사용하여 줄이는 것이 목적이라는 것입니다.
(전체 코드는 github을 참조바랍니다)
현재 위 코드는 하나의 GPU 디바이스만을 사용하는데, 컴파일하고 nsys profile을 통해서 성능을 측정해보도록 하겠습니다. 컴파일 커맨드는 다음과 같습니다.
nvcc -arch=sm_70 -O3 -Xcompiler="-march=native -fopenmp" -o baseline-report ./FeistelCipher.cu위 커맨드는 NVIDIA 온라인 트레이닝에서 제공되는 환경 기준으로 동작합니다.

기본적인 실행 시간은 다음과 같습니다. 그리고 프로파일링한 결과는 다음과 같습니다.


아래에서는 위의 어플리케이션을 다중 GPU를 사용하도록 코드를 수정하여 성능을 향상시켜보도록 하겠습니다.
Multiple GPUs
이번에는 다중 GPU를 사용하는 방법에 대해서 순차적으로 살펴보도록 하겠습니다.
먼저, 시스템에서 사용 가능한 GPU의 수는 다음의 코드를 통해서 얻을 수 있습니다.
int num_gpus;
cudaGetDeviceCount(&num_gpus);그리고, 현재 활성화된 GPU는 cudaGetDevice() API를 통해서 얻을 수 있습니다.
int device;
cudaGetDevice(&device); // 'device' is now a 0-based index of the current GPU.
각 host thread에서는 한 번에 하나의 GPU 디바이스만 활성화됩니다. 그리고, 특정 GPU를 활성화시키려면 cudaSetDevice() API를 사용하면 됩니다. cudaSetDevice()의 파라미터로 0-based 인덱스를 전달합니다.
cudaSetDevice(0);
일반적으로 다중 GPU를 사용하는 패턴은 바로 loop입니다. 먼저, 현재 시스템에서 사용 가능한 GPU의 갯수를 쿼리하고, 해당 갯수만큼 for loop를 반복하면서 각 반복마다 각각의 GPU를 활성화시키는 것입니다.
int num_gpus;
cudaGetDeviceCount(&num_gpus);
for (int gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
// Perform operations for this GPU.
}
non-default인 스트림을 사용하여 copy/compute를 오버랩하여 수행하는 것처럼, 각각의 GPU에서 또한 data chunk를 처리합니다. 아래 코드는 각 GPU의 데이터 포인터를 갖는 포인터 배열을 생성하고 활용합니다.
const int num_gpus;
cudaGetDeviceCount(&num_gpus);
const uint64_t num_entries = 1UL << 26;
const uint64_t chunk_size = sdiv(num_entries, num_gpus);
uint64_t *data_gpu[num_gpus]; // One pointer for each GPU.
for (int gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
const uint64_t lower = chunk_size * size;
const uint64_t upper = min(lower + chunk_size, num_entries);
const uint64_t width = upper - lower;
// Allocate chunk of data for current GPU.
cudaMalloc(&data_gpu[gpu], sizeof(uint64_t) * width);
}
그리고, 위와 동일한 방법을 통해서 GPU로, 또는 GPU로부터 데이터를 전달할 수 있습니다.
// Assume data has been allocated on host and for each GPU
for (int gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
const uint64_t lower = chunk_size * gpu;
const uint64_t upper = min(lower + chunk_size, num_entries;
const uint64_t width = upper - lower;
// Note use of 'cudaMemcpy' and not 'cudaMemcpyAsync' since we are not
// presently using non-default streams.
cudaMemcpy(data_gpu[gpu], data_cpu + lower, sizeof(uint64_t) * width,
cudaMemcpyHostToDevice); // .. or cudaMemcpyDeviceToHost
}
다중 GPU에서 커널을 실행하는 방법 또한, 위와 동일한 기법을 사용합니다.
// Assume data has been allocated on host and for each GPU
for (int gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
const uint64_t lower = chunk_size * gpu;
const uint64_t upper = min(lower + chunk_size, num_entries;
const uint64_t width = upper - lower;
// Pass chunk of data for current GPU to work on.
kernel<<<grid, block>>>(data_gpu[gpu], width);
}
Use Multiple GPUs
NVIDIA에서 제공되는 환경은 4개의 GPU가 장착되어 있습니다.
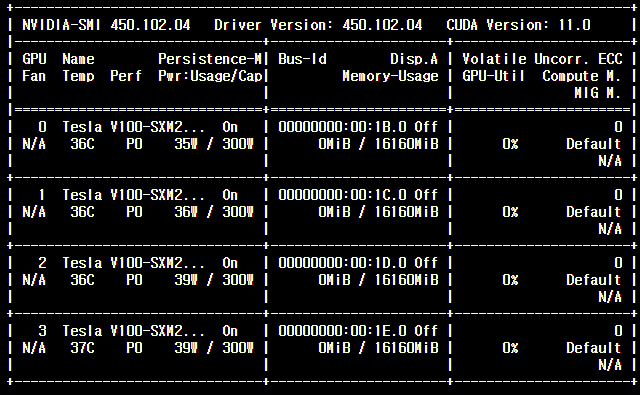
그럼 이제 위에서 설명한 기법들을 적용하도록 위에서 처음 베이스로 작성한 코드를 다음과 같이 수정합니다.
int main()
{
Timer timer, overall;
const uint64_t num_entries = 1UL << 26;
const uint64_t num_iters = 1UL << 10;
const bool openmp = true;
// Set number of avaiable GPUs.
int num_gpus;
cudaGetDeviceCount(&num_gpus);
// Get chunk size using round up division.
const uint64_t chunk_size = sdiv(num_entries, num_gpus);
// Use array of pointers for multiple GPU memory.
uint64_t *data_cpu, *data_gpu[num_gpus];
cudaMallocHost(&data_cpu, sizeof(uint64_t) * num_entries);
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
// set GPU as active
cudaSetDevice(gpu);
// get width of this GPUs data chunk
const uint64_t lower = chunk_size * gpu;
const uint64_t upper = min(lower + chunk_size, num_entries);
const uint64_t width = upper - lower;
// allocate data for this GPU.
cudaMalloc(&data_gpu[gpu], sizeof(uint64_t) * width);
}
// encrypt data
encrypt_cpu(data_cpu, num_entries, num_iters, openmp);
overall.start();
timer.start();
// Data copy from CPU to GPU
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
const uint64_t lower = chunk_size * gpu;
const uint64_t upper = min(lower + chunk_size, num_entries);
const uint64_t width = upper - lower;
// copy correct chunk of data to active GPU.
cudaMemcpy(data_gpu[gpu], data_cpu + lower, sizeof(uint64_t) * width,
cudaMemcpyHostToDevice);
}
timer.stop("copy data from CPU to GPU");
timer.start();
// Decrypt data on GPU(s).
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
const uint64_t lower = chunk_size * gpu;
const uint64_t upper = min(lower + chunk_size, num_entries);
const uint64_t width = upper - lower;
// decrypt its chunk of data
decrypt_gpu<<<80 * 32, 64>>>(data_gpu[gpu], width, num_iters);
}
timer.stop("total kernel execution on GPU");
timer.start();
// Copy data from GPU to CPU
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
const uint64_t lower = chunk_size * gpu;
const uint64_t upper = min(lower + chunk_size, num_entries);
const uint64_t width = upper - lower;
// copy its chunk of data back to the host.
cudaMemcpy(data_cpu + lower, data_gpu[gpu], sizeof(uint64_t) * width,
cudaMemcpyDeviceToHost);
}
timer.stop("copy data from GPU to CPU");
// Stop timer for total time on GPU(s).
overall.stop("total time on GPU");
timer.start();
// Check results on CPU.
const bool success = check_result_cpu(data_cpu, num_entries, openmp);
std::cout << "STATUS: test " << (success ? "passed" : "failed") << std::endl;
timer.stop("checking result on CPU");
timer.start();
// Free memory
cudaFreeHost(data_cpu);
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
cudaFree(data_gpu[gpu]);
}
timer.stop("free memory");
}위 코드를 컴파일 후, 실행하면 다음과 같이 출력합니다.

커널의 실행 시간이 기존에 약 71ms로 측정되었는데, 다중 GPU를 사용하는 코드에서는 약 18ms로 측정되었습니다. 줄어든 커널의 실행 시간만큼 GPU에서의 total time도 약 110ms로 줄어든 것을 확인할 수 있습니다.

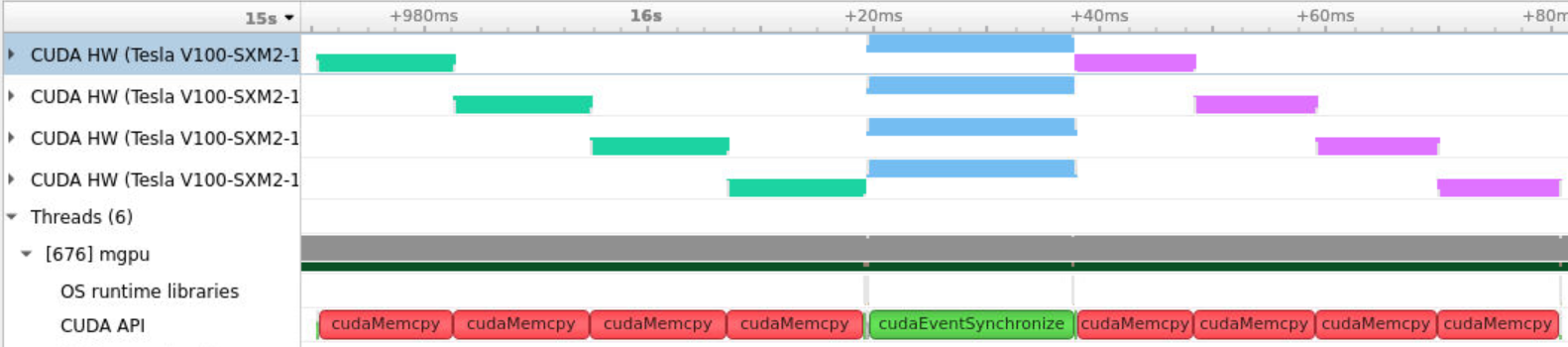
UI로 살펴보면, 4개의 CUDA HW를 확인할 수 있습니다.
여기서 메모리 전송은 중첩되지 않는 것을 확인할 수 있는데, 이는 모든 GPU에서 default 스트림을 사용하고 있기 때문입니다. 이처럼 default 스트림의 blocking하는 특징은 다중 GPU에서도 적용된다는 것을 알 수 있습니다.
대신, 각 GPU에서 커널은 중첩되어서 실행되고 있는 것을 확인할 수 있습니다.
Copy Compute Overlap with Multiple GPUs
각 GPU는 자기만의 default 스트림을 가지고 있습니다. 그리고 non-default 스트림을 현재 활성화된 GPU에서 생성하고 사용할 수 있는데, 이때, 다른 GPU에서 생성된 스트림을 현재 활성화된 GPU에서 사용하지 않도록 주의해야 합니다.
non-default stream을에 대한 기본적인 내용은 아래 포스팅을 참조하시길 바랍니다.
CUDA C/C++ 기초 - (3)
References Fundamentals of Accelerated Computing with CUDA C/C++ (NVIDIA Online Training) Asynchronous Streaming, and Visual Profiling for Accelerated Applications with CUDA C/C++ Contents Concurren..
junstar92.tistory.com
다중 GPU 환경에서 여러 non-default 스트림을 사용할 때는 일반적으로 2차원 배열을 사용합니다.
// 2D array containing number of streams for each GPU.
cudaStream_t streams[num_gpus][num_streams];
// for each available GPU
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
// set as active device
cudaSetDevice(gpu);
for (uint64_t stream = 0; stream < num_streams; stream++) {
// create and store its number of stream.
cudaStreamCreate(&streams[gpu][stream]);
}
}
이렇게 다중 GPU에서 생성된 스트림에서 사용될 data chunk 크기는 다음과 같이 계산할 수 있습니다.
// Each stream needs num_entries/num_gpus/num_streams data. We use round up division
// for reasons previously discussed.
const uint64_t stream_chunk_size = sdiv(sdiv(num_entries, num_gpus), num_streams);
// It will be helpful to also to have handy the chunk size for an entire GPU.
const uint64_t gpu_chunk_size = stream_chunk_size * num_streams;
각 GPU 디바이스에서 사용되는 데이터는 동일하므로, 스트림을 사용하지 않을 때와 메모리를 할당하는 코드는 동일합니다.
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
// use a GPU chunk's worth of data to calculate indices and width
const uint64_t lower = gpu_chunk_size * gpu;
const uint64_t upper = min(lower + gpu_chunk_size, num_entires);
const uint64_t width = upper - lower;
// allocate data
cudaMalloc(&data_gpu[gpu], sizeof(uint64_t) * width);
}
이제 각 GPU 디바이스에서 non-default 스트림들을 사용하도록, 다음과 같이 작성하여 커널을 실행합니다.
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
// For each stream (on each GPU)...
for (uint64_t stream = 0; stream < num_streams; stream++) {
// Calculate index offset for this stream's chunk of data within the GPU's chunk of data...
const uint64_t stream_offset = stream_chunk_size * stream;
// ...get the lower index within all data, and width of this stream's data chunk...
const uint64_t lower = gpu_chunk_size * gpu + stream_offset;
const uint64_t upper = min(lower + stream_chunk_size, num_entries);
const uint64_t width = upper - lower;
// ...perform async HtoD memory copy...
cudaMemcpyAsync(data_gpu[gpu] + stream_offset, // This stream's data within this GPU's data.
data_cpu + lower, // This stream's data within all CPU data.
sizeof(uint64_t) * width, // This stream's chunk size worth of data.
cudaMemcpyHostToDevice,
streams[gpu][stream]); // Using this stream for this GPU.
kernel<<<grid, block, 0, streams[gpu][stream]>>> // Using this stream for this GPU.
(data_gpu[gpu] + stream_offset, // This stream's data within this GPU's data.
width); // This stream's chunk size worth of data.
cudaMemcpyAsync(data_cpu + lower, // This stream's data within all CPU data.
data_gpu[gpu] + stream_offset, // This stream's data within this GPU's data.
sizeof(uint64_t) * width,
cudaMemcpyDeviceToHost,
streams[gpu][stream]); // Using this stream for this GPU.
}
}
Use streams with multiple GPUs
non-default 스트림을 사용하도록 이전 코드를 수정하면 다음과 같습니다.
int main()
{
Timer timer, overall;
const uint64_t num_entries = 1UL << 26;
const uint64_t num_iters = 1UL << 10;
const bool openmp = true;
// Set number of avaiable GPUs and number of streams.
const uint64_t num_gpus = 4;
const uint64_t num_streams = 32;
// Get chunk size using round up division.
const uint64_t stream_chunk_size = sdiv(sdiv(num_entries, num_gpus), num_streams);
// It will be helpful to also to have handy the chunk size for an entire GPU.
const uint64_t gpu_chunk_size = stream_chunk_size * num_streams;
// 2D array containing number of streams for each GPU.
cudaStream_t streams[num_gpus][num_streams];
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
// set as active device
cudaSetDevice(gpu);
for (uint64_t stream = 0; stream < num_streams; stream++) {
// create and store its number of streams
cudaStreamCreate(&streams[gpu][stream]);
}
}
// Store GPU data pointers in an array.
uint64_t *data_cpu, *data_gpu[num_gpus];
cudaMallocHost(&data_cpu, sizeof(uint64_t) * num_entries);
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
// set GPU as active
cudaSetDevice(gpu);
// get width of this GPUs data chunk
const uint64_t lower = gpu_chunk_size * gpu;
const uint64_t upper = min(lower + gpu_chunk_size, num_entries);
const uint64_t width = upper - lower;
// allocate data for this GPU.
cudaMalloc(&data_gpu[gpu], sizeof(uint64_t) * width);
}
// encrypt data
encrypt_cpu(data_cpu, num_entries, num_iters, openmp);
overall.start();
// For each gpu...
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
// For each stream (on each GPU)...
for (uint64_t stream = 0; stream < num_streams; stream++) {
// Calculate index offset for this stream's chunk of data within the GPU's chunk of data...
const uint64_t stream_offset = stream_chunk_size * stream;
// ...get the lower index within all data, and width of this stream's data chunk...
const uint64_t lower = gpu_chunk_size * gpu + stream_offset;
const uint64_t upper = min(lower + stream_chunk_size, num_entries);
const uint64_t width = upper - lower;
// ...perform async HtoD memory copy...
cudaMemcpyAsync(data_gpu[gpu] + stream_offset, // This stream's data within this GPU's data.
data_cpu + lower, // This stream's data within all CPU data.
sizeof(uint64_t) * width, // This stream's chunk size worth of data.
cudaMemcpyHostToDevice,
streams[gpu][stream]); // Using this stream for this GPU.
decrypt_gpu<<<80*32, 64, 0, streams[gpu][stream]>>> // Using this stream for this GPU.
(data_gpu[gpu]+stream_offset, // This stream's data within this GPU's data.
width, // This stream's chunk size worth of data.
num_iters);
cudaMemcpyAsync(data_cpu + lower, // This stream's data within all CPU data.
data_gpu[gpu] + stream_offset, // This stream's data within this GPU's data.
sizeof(uint64_t) * width,
cudaMemcpyDeviceToHost,
streams[gpu][stream]); // Using this stream for this GPU.
}
}
// Synchronize streams to block on memory transfer before checking on host.
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
for (uint64_t stream = 0; stream < num_streams; stream++) {
cudaStreamSynchronize(streams[gpu][stream]);
}
}
// Stop timer for total time on GPU(s).
overall.stop("total time on GPU");
// Check results on CPU.
const bool success = check_result_cpu(data_cpu, num_entries, openmp);
std::cout << "STATUS: test " << (success ? "passed" : "failed") << std::endl;
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
for (uint64_t stream = 0; stream < num_streams; stream++) {
cudaStreamDestroy(streams[gpu][stream]);
}
}
// Free memory
cudaFreeHost(data_cpu);
for (uint64_t gpu = 0; gpu < num_gpus; gpu++) {
cudaSetDevice(gpu);
cudaFree(data_gpu[gpu]);
}
}위 코드를 컴파일 후, 실행하면 아래의 출력을 확인할 수 있습니다.

데이터 전달과 연산이 하나의 GPU에서 한 번에 수행되기 때문에 전체 GPU 수행 시간만 출력하도록 하였습니다. 이전에 다중 GPU만 사용했을 때의 총 실행 시간은 약 110ms였지만, non-default 스트림을 같이 사용했을 때에는 약 32ms로 더 빨라진 것을 확인할 수 있습니다.

반면 nsys profile에서 측정된 커널의 총 실행 시간은 약 73ms에서 약 81ms로 증가한 것을 볼 수 있습니다. 하지만 전체 실행 시간은 줄어들었는데, 그 이유는 nsys UI를 통해서 확인할 수 있습니다.

전체를 살펴보면, 조금 알아보기 힘드니 조금 더 확대하여 살펴보면 다음과 같습니다.

이처럼 모든 GPU에서 메모리 전달과 연산이 중첩되어서 수행되고 있는 것을 확인할 수 있습니다. 따라서 커널이 각 스트림마다 분할되어서 생기는 오버헤드 때문에 실제 커널의 전체 실행 시간은 증가하였지만, 메모리 전달과 커널 수행이 중첩되어 수행되기 때문에 전체 실행 시간은 감소하였습니다.
전체 코드
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
'NVIDIA > CUDA' 카테고리의 다른 글
| API Synchronization Behavior (0) | 2022.06.18 |
|---|---|
| NVIDIA Tools Extension (NVTX) (0) | 2022.06.17 |
| CUDA C/C++ 기초 - (3) (0) | 2022.06.14 |
| CUDA C/C++ 기초 - (2) (0) | 2022.06.13 |
| CUDA C/C++ 기초 - (1) (2) | 2022.06.10 |




댓글