References
- https://docs.nvidia.com/cuda/profiler-users-guide/index.html#nvtx
- https://nvidia.github.io/NVTX/doxygen/index.html
Contents
- NVTX API
- Nsight System with NVTX for profiling
NVTX
NVIDIA Tools Extension(NVTX) 라이브러리는 어플리케이션에서 event, code range, resources 등에 어노테이션하기 위한 C-based API를 제공합니다. 이렇게 제공되는 API를 통해서 어플리케이션의 추가적인 정보를 얻을 수 있습니다.
NVTX가 통합된 어플리케이션은 Nsight System 또는 Visual Profiler에서 events나 ranges를 시각적으로 보여줄 수 있는데, NVTX에서 제공하는 핵심 기능은 다음과 같습니다.
- Tracing of CPU events and time ranges
- Naming of OS and CUDA resources
이러한 기능들은 어플리케이션의 성능을 향상시키기 위해 프로파일링할 때 유용하게 사용될 수 있습니다.
간단하게 NVTX를 다음과 같이 어플리케이션 코드에 추가하여 빌드한 뒤,
#include <nvtx3/nvToolsExt.h> void wait(int waitMilliseconds) { nvtxNameOsThread(GetCurrentThreadId(), "MAIN"); nvtxRangePush(__FUNCTION__); nvtxMark("Waiting..."); Sleep(waitMilliseconds); nvtxRangePop(); } int main() { nvtxNameOsThread(GetCurrentThreadId(), "MAIN"); nvtxRangePush(__FUNCTION__); wait(10); nvtxRangePop(); }
생성된 실행 파일을 통해 Nsight System으로 프로파일링하면, 아래와 같이 시각적으로 추가 정보들을 확인할 수 있습니다.

NVTX API
위에서 살펴본 코드에서 알 수 있듯이 NVTX를 사용하려면 nvToolsExt.h 헤더 파일을 include하고, 소스 코드에 NVTX API를 호출하면 됩니다. 이 헤더 파일은 CUDA가 설치된 경로 아래 include/nvtx3 내에 위치합니다.
모든 NVTX API 함수들의 이름은 nvtx로 시작하며, 끝에는 A, W, Ex 중 하나로 끝나게 됩니다. 예를 들면, nvtxRangePushA, nvtxRangePushW, nvtxRangePushEx라는 API가 각각 존재합니다. 이들은 서로 다른 매개변수를 받을 뿐, 핵심 기능은 동일합니다. NVTX 라이브러리 버전에 따라 사용할 수 있는 것들이 다르며, 사용 가능한 인코딩에는 ASCII(A), Unicode(W), Event Structure(Ex)가 있습니다.
(NVTX의 CUDA 구현에서 unicode는 지원하지 않으며, 호출해도 아무런 효과가 없습니다)
몇몇의 NVTX 함수들은 반환 값(return value)이 존재합니다. 예를 들어, nvtxRangeStart() 함수는 range 식별자를 반환하고, nvtxRangePush() 함수는 현재 stack level을 반환합니다. 일반적으로 어플리케이션에서 이러한 반환 값들을 조건문에 사용하지 않는 것이 좋습니다. 반환되는 값은 NVTX 라이브러리의 구현에 따라 다를 수 있으므로, 반환 값에 대한 종속성이 존재하면 프로그램의 일관성이 보장되지 않습니다.
NVTX의 API를 종류에 따라서 간단하게 살펴보도록 하겠습니다.
Markers
마커(marker)는 보통 event가 일어나는 순간을 표시할 때 사용됩니다. 텍스트 메세지를 포함시킬 수도 있고, event attributes 구조체를 사용하여 추가 정보도 포함시킬 수도 있습니다. 위에서 언급했듯이, nvtxMarkA()를 사용하면 ASCII 메세지가 포함된 마커를 생성할 수 있습니다. nvtxMarkEx()를 사용하면 event attributes를 포함하는 마커를 생성할 수 있습니다.
다음은 마커를 사용하는 예제 코드입니다.
nvtxMarkA("My mark"); nvtxEventAttributes_t eventAttrib = {0}; eventAttrib.version = NVTX_VERSION; eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE; eventAttrib.colorType = NVTX_COLOR_ARGB; eventAttrib.color = COLOR_RED; eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII; eventAttrib.message.ascii = "my mark with attributes"; nvtxMarkEx(&eventAttrib);
Range Start/Stop
Start/Stop range는 (잠재적으로)중첩되지 않은 time span을 나타내는데 사용됩니다. range의 시작은 범위의 끝과 다른 스레드에서 일어날 수 있습니다. 즉, 프로세스의 range에 대한 time span을 나타냅니다.
마찬가지로 텍스트 메세지나 event attributes 구조체를 전달할 수 있습니다.
사용 예는 다음과 같습니다.
// non-overlapping range nvtxRangeId_t id1 = nvtxRangeStartA("My range"); nvtxRangeEnd(id1); nvtxEventAttributes_t eventAttrib = {0}; eventAttrib.version = NVTX_VERSION; eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE; eventAttrib.colorType = NVTX_COLOR_ARGB; eventAttrib.color = 0xFF0000FF; //COLOR_BLUE eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII; eventAttrib.message.ascii = "my start/stop range"; nvtxRangeId_t id2 = nvtxRangeStartEx(&eventAttrib); nvtxRangeEnd(id2); // overlapping ranges nvtxRangeId_t r1 = nvtxRangeStartA("My range 0"); nvtxRangeId_t r2 = nvtxRangeStartA("My range 1"); nvtxRangeEnd(r1); nvtxRangeEnd(r2);
NVTX Range Push/Pop
Push/Pop range는 중첩되는 time span을 나타내는데 사용됩니다. range의 시작과 끝은 반드시 동일한 스레드이어야 합니다. 다른 API와 마찬가지로 텍스트 메세지나 event attributes 구조체를 사용하여 추가 정보를 입력할 수 있습니다.
각 push 함수는 0부터 시작하는 depth를 반환하며, nvtxRangePop() 함수는 API가 호출된 스레드에서 가장 최근에 push된 range를 종료합니다. 만약 pop에 일치하는 push가 없다면 에러를 나타내는 음수가 반환됩니다.
사용 예시는 다음과 같습니다.
nvtxRangePushA("outer"); nvtxRangePushA("inner"); nvtxRangePop(); // end "inner" range nvtxRangePop(); // end "outer" range nvtxEventAttributes_t eventAttrib = {0}; eventAttrib.version = NVTX_VERSION; eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE; eventAttrib.colorType = NVTX_COLOR_ARGB; eventAttrib.color = 0xFF00FF00; eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII; eventAttrib.message.ascii = "my push/pop range"; nvtxRangePushEx(&eventAttrib); nvtxRangePop();
Synchronization Markers
NVTX synchronization module은 어플리케이션에서 동기화에 관한 세부 사항을 추적하기 위한 함수들을 제공합니다. OS synchronization primitives에 이름을 지정하면 API에 의해서 수집된 데이터들을 더 잘 이해할 수 있습니다.
참고로, 윈도우에서는 해당 기능이 지원되지 않으며 이번 포스팅에서 해당 내용은 다루지 않도록 하겠습니다 !
Event Attributes Structure
nvtxEventAttributes_t는 event의 속성들을 설정하기 위해 사용됩니다. 이 구조체의 레이아웃은 NVTX 버전마다 조금씩 다릅니다.
Markers와 ranges는 event에 대해 추가적인 정보를 제공하기 위해 attributes를 사용할 수 있습니다. 각각의 속성들은 optional이며, 지정되지 않으면 기본값으로 대체됩니다.
- Message: message 필드는 문자열을 지정합니다. 반드시 messageType과 message 필드를 모두 설정해야 하며, 기본값은 NVTX_MESSAGE_UNKNOWN 입니다. NVTX의 CUDA 구현에서는 오직 ASCII 타입의 메세지만 지원합니다.
- Category: category 속성은 event를 묶어주는데 사용되는 user-controlled ID 입니다. 이러한 ID는 tool에서 필터링하거나, 묶을 때 사용될 수 있습니다. 기본값은 0입니다.
- Color: color 속성은 tool에서 시각적으로 식별할 수 있도록 도와줍니다. 반드시 colorType과 color 필드가 모두 설정되어야 합니다.
- Payload: payload 속성은 markers와 ranges에 추가적인 데이터를 전달할 때 사용될 수 있습니다. Range event는 오직 range의 시작에서 값을 지정할 수 있습니다. 반드시 payloadType과 payload 필드가 설정되어야 하며 유효한 값을 지정해야 합니다.
attributes structure를 사용할 때는 아래의 3가지를 따르는 것이 좋습니다.
- Zero the structure
- Set the version field
- Set the size field
아래는 위의 3가지를 따르면서 attributes를 사용하는 예시입니다.
nvtxEventAttributes_t eventAttrib = {0}; eventAttrib.version = NVTX_VERSION; eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE; eventAttrib.colorType = NVTX_COLOR_ARGB; eventAttrib.color = ::COLOR_YELLOW; eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII; eventAttrib.message.ascii = "My event"; nvtxMarkEx(&eventAttrib);
NVTX Domains
Domains을 사용하면 어노테이션의 범위를 지정할 수 있습니다. 기본적으로 모든 events와 annotations는 default domain에 있습니다. 추가 domain을 등록할 수 있는데, 이를 통해 markers와 ranges의 범위를 지정하여 충돌을 피할 수 있습니다.
Domain 생성은 nvtxDomainCreateA() 또는 nvtxDomainCreateW() 함수를 사용합니다.
이렇게 생성된 각 도메인은 자체 카테고리(categories), 스레드 range stack, 등록된 문자열을 관리합니다.
nvtxDomainDestroy() 함수는 domain의 끝을 마킹합니다. Domain을 삭제하면 등록된 문자열, 리소스 객체, 명명된 카테고리 등 domain과 관련된 모든 객체가 unregister/destroy 됩니다.
아쉽게 윈도우에서 해당 기능은 지원되지 않습니다.
예제 코드는 다음과 같습니다.
nvtxDomainHandle_t domain = nvtxDomainCreateA("Domain_A"); nvtxMarkA("Mark_A"); nvtxEventAttributes_t attrib = {0}; attrib.version = NVTX_VERSION; attrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE; attrib.message.ascii = "Mark A Message"; nvtxDomainMarkEx(NULL, &attrib); nvtxDomainDestroy(domain);
NVTX Resource Naming
NVTX resource naming을 통해 host OS thread, context, device 및 스트림과 같은 CUDA 리소스에 커스텀 이름을 지정할 수 있습니다. 이렇게 NVTX를 사용하여 할당된 이름은 Nsight System이나 Visual Profiler에서 표시됩니다.
OS Thread
nvtxNameOsThreadA() 함수를 통해 host OS thread의 이름을 지정할 수 있습니다. nvtxNameOsThreadW() 함수는 NVTX의 CUDA 구현에서 지원되지 않으면 호출해도 아무런 효과가 없습니다.
// Windows nvtxNameOsThread(GetCurrentThreadId(), "MAIN_THREAD"); // Linux/Mac nvtxNameOsThread(pthread_self(), "MAIN_THREAD");

CUDA Runtime Resources
nvtxNameCudaDeviceA()와 nvtxNameCudaStreamA()는 각각 CUDA device와 stream 객체의 이름을 지정할 수 있습니다. 마찬가지로 W로 끝나는 함수들을 NVTX의 CUDA 구현에서 지원되지 않습니다. nvtxNameCudaEventA()와 nvtxNameCudaEventW() 또한 지원되지 않습니다.
nvtxNameCudaDeviceA(0, "my cuda device 0"); cudaStream_t cudastream; cudaStreamCreate(&cudastream); nvtxNameCudaStreamA(cudastream, "my cuda stream");
여기서 사용되는 API는 nvtx3/nvToolsExtCudaRt.h에 정의되어 있으므로 해당 헤더 파일을 include 해주어야 합니다.
CUDA Device Resources
nvtxNameCuDeviceA(), nvtxNameCuContextA(), nvtxNameCuStreamA() 함수는 CUDA driver device, context, stream 객체의 이름을 지정합니다. 마찬가지로 W로 끝나는 함수들은 NVTX의 CUDA 구현에서 지원되지 않습니다. 또한, nvtxNameCuEventA(), nvtxNameCuEventW() 함수 또한 지원되지 않습니다.
CUdevice device; cuDeviceGet(&device, 0); nvtxNameCuDeviceA(device, "my device 0"); CUcontext context; cuCtxCreate(&context, 0, device); nvtxNameCuContextA(context, "my context"); cuStream stream; cuStreamCreate(&stream, 0); nvtxNameCuStreamA(stream, "my stream");
몇 가지 테스트를 윈도우에서 진행해봤는데... 저는 적용이 되지 않았습니다.. ㅠ
Examples
이번에는 예제를 통해서 NVTX가 어떻게 사용될 수 있는지 살펴보겠습니다. 실질적으로 Range Push/Pop을 많이 사용하며, 이번 예제에서도 Range Push/Pop만 사용합니다.
예제 코드는 다음과 같습니다. 간단하게 설명하면, 아래 코드는 host 메모리와 device 메모리에 할당된 데이터를 초기화하고 ax + y 연산을 수행하여 y에 저장하고 그 결과를 검증합니다.
#include <stdio.h> #include <nvtx3/nvToolsExt.h> __global__ void init_data_gpu(double* x, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < n) { x[idx] = n - idx; } } __global__ void daxpy_gpu(double a, double *x, double *y, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < n) { y[idx] = a * x[idx] + y[idx]; } } __global__ void check_results_gpu(double correctValue, double *x, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < n) { if (x[idx] != correctValue) { printf("ERROR at index = %d, expected = %f, actual: %f\n", idx, correctValue, x[idx]); } } } void init_host_data(double *x, int n) { nvtxRangePush("init_host_data"); for (int i = 0; i < n; i++) { x[i] = i; } nvtxRangePop(); } void init_data(double *x, double *x_d, double *y_d, int n) { nvtxRangePush("init_data"); cudaStream_t copy_stream; cudaStream_t compute_stream; cudaStreamCreate(©_stream); cudaStreamCreate(&compute_stream); cudaMemcpyAsync(x_d, x, sizeof(double) * n, cudaMemcpyDefault, copy_stream); init_data_gpu<<<ceil(n/256), 256, 0, compute_stream>>>(y_d, n); cudaStreamSynchronize(copy_stream); cudaStreamSynchronize(compute_stream); cudaStreamDestroy(copy_stream); cudaStreamDestroy(compute_stream); nvtxRangePop(); } void daxpy(double a, double *x_d, double *y_d, int n) { nvtxRangePush("daxpy"); daxpy_gpu<<<ceil(n / 256), 256>>>(a, x_d, y_d, n); cudaDeviceSynchronize(); nvtxRangePop(); } void check_results(double correctValue, double *x_d, int n) { nvtxRangePush("check_results"); check_results_gpu<<<ceil(n / 256), 256>>>(correctValue, x_d, n); nvtxRangePop(); } int main() { int n = 1 << 22; nvtxRangePush("run_test"); // allocate memory double *x, *x_d, *y_d; cudaMallocHost(&x, sizeof(double) * n); cudaMalloc(&x_d, sizeof(double) * n); cudaMalloc(&y_d, sizeof(double) * n); init_host_data(x, n); init_data(x, x_d, y_d, n); daxpy(1.0, x_d, y_d, n); check_results(n, y_d, n); // free memory cudaFreeHost(x); cudaFree(x_d); cudaFree(y_d); cudaDeviceSynchronize(); nvtxRangePop(); }
그리고 관심있는 부분에 Range Push/Pop을 추가하였습니다. 이를 통해서 우리는 관심있는 영역의 time span을 시각적으로 살펴볼 수 있습니다.
위 코드를 컴파일 한 뒤, Nsight System으로 프로파일링한 결과는 다음과 같습니다.
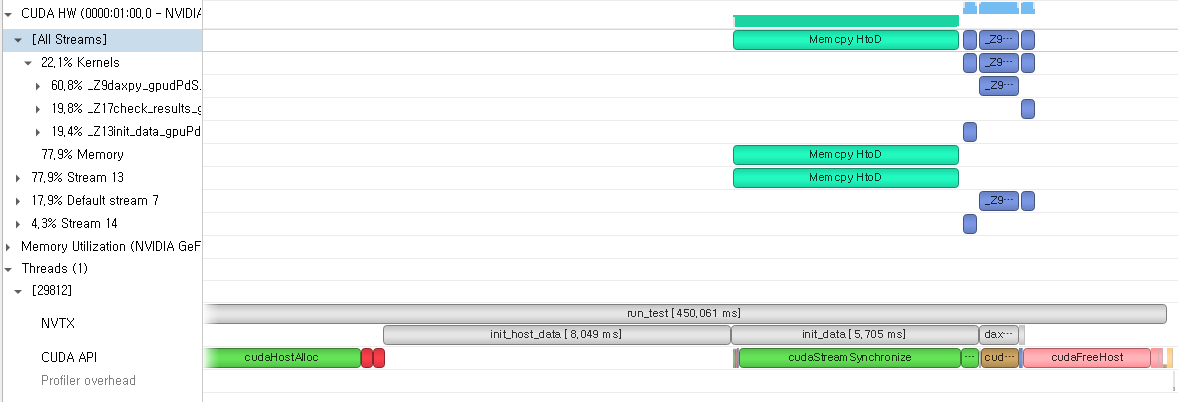
NVTX를 사용함으로써, 각 구간의 CPU에서의 실행 시간을 아주 간단하게 측정할 수 있습니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| Stream Synchronization Behavior (0) | 2022.06.19 |
|---|---|
| API Synchronization Behavior (0) | 2022.06.18 |
| Multiple GPUs with CUDA C++ (0) | 2022.06.16 |
| CUDA C/C++ 기초 - (3) (0) | 2022.06.14 |
| CUDA C/C++ 기초 - (2) (0) | 2022.06.13 |




댓글