References
- Fundamentals of Accelerated Computing with CUDA C/C++ (NVIDIA Online Training)
- Managing Accelerated Application Memory with CUDA Unified Memory and nsys
Contents
- Nsight System
- Understanding Streaming Multiprocessors
- Querying the Device
- Unified Memory Details
CUDA C/C++ 기초 - (1)
References Fundamentals of Accelerated Computing with CUDA C/C++ (NVIDIA Online Training) Contents Writing Application Code for the GPU(CUDA C/C++) CUDA Thread Hierarchy Allocating Memory to be acce..
junstar92.tistory.com
지난 포스팅에 이어서 CUDA C/C++에 대한 기본적인 내용에 대해서 알아보도록 하겠습니다.
NVIDIA Command Line Profiler
CUDA 프로그램을 최적화하기 위해서는 프로그램의 성능에 대한 정량적인 프로파일링이 필요합니다. NVIDIA에서는 Nsight Systems(nsys)이라는 프로그램을 제공하는데, 이는 CUDA Toolkit과 함께 제공되며 CUDA 어플리케이션을 프로파일링하기 위한 도구입니다.
리눅스에서는 nsys 커맨드로 실행할 수 있으며, 윈도우에서는 nsys-ui.exe를 실행하여 UI 환경에서 프로파일링이 가능합니다. 포스팅에서는 리눅스를 기반으로 설명하도록 하겠습니다.
nsys는 사용하기 쉬운데, 가장 기본적인 사용 방법은 단순히 nvcc로 컴파일된 실행 파일의 경로를 전달하면 됩니다. nsys는 실행 파일을 실행하면서 GPU activities와 CUDA API calls, Unified Memory acitivity와 관련된 정보들을 요약하여 출력합니다.
아래 예제 코드는 벡터 덧셈 연산을 구현한 코드입니다. 이 코드에서 스레드의 수를 바꿔가며 컴파일한 후 프로파일링을 직접 해보도록 하겠습니다.
// 09_vector-add.cu #include <stdio.h> #include <assert.h> inline cudaError_t checkCuda(cudaError_t result) { if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result)); assert(result == cudaSuccess); } return result; } void initWith(float num, float* a, const int N) { for (int i = 0; i < N; i++) { a[i] = num; } } __global__ void addVectorsInto(float* result, float* a, float* b, const int N) { int idx = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; for (int i = idx; i < N; i += stride) { result[i] = a[i] + b[i]; } } void checkElementsAre(float target, float* array, const int N) { for (int i = 0; i < N; i++) { if (array[i] != target) { printf("FAIL: array[%d] - %0.0f does not equal %0.0f\n", i, array[i], target); exit(1); } } printf("SUCCESS! All values added correctly.\n"); } int main() { const int N = 2 << 20; size_t size = N * sizeof(float); float *a, *b, *c; checkCuda(cudaMallocManaged(&a, size)); checkCuda(cudaMallocManaged(&b, size)); checkCuda(cudaMallocManaged(&c, size)); initWith(3, a, N); initWith(4, b, N); initWith(0, c, N); size_t threadsPerBlock = 1; size_t numberOfBlocks = 1; addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N); checkCuda(cudaGetLastError()); checkCuda(cudaDeviceSynchronize()); checkElementsAre(7, c, N); checkCuda(cudaFree(a)); checkCuda(cudaFree(b)); checkCuda(cudaFree(c)); }
먼저 위 코드를 컴파일하여 실행 파일을 생성합니다.
nvcc -o single-thread-vector-add 09_vector-add.cu그리고 아래의 커맨드를 통해 프로파일링을 수행합니다.
nsys profile --stats=true ./single-thread-vector-add'nsys profile'은 다양한 방법으로 사용될 수 있는 qdrep 리포트 파일을 생성합니다. 여기서 '--stats=true' 플래그를 사용했는데, 이 플래그는 터미널에 프로파일링 결과를 요약하여 출력하도록 합니다. 출력되는 결과는 아래 내용들을 포함합니다.
- Profile configuration details
- Report file(s) generation details
- CUDA API Statistics
- CUDA Kernel Statistics
- CUDA Memory Operation Statistics (time and size)
- OS Runtime API Statistics
여기서 우리가 주목해야할 정보는 bold체로 표시한 3가지 항목입니다.
위의 커맨드로 컴파일된 실행 파일 single-thread-vector-add를 프로파일링하면 아래의 출력을 확인할 수 있습니다.

CUDA Kernel Statistics에서 벡터 덧셈을 수행하는 커널인 addVectorsInto가 수행되는데 걸리는 시간이 약 2,285ms라는 것을 알 수 있습니다.
이번에는 코드에서 스레드의 갯수를 1,024개로 변경하여 컴파일 후, 프로파일링해보도록 하겠습니다. 컴파일된 실행 파일 이름은 multi-thread-vector-add으로 지정하였습니다.
nsys profile --stats=true ./multi-thread-vector-addaddVectorsInfo 커널의 실행 시간이 144ms로 향상된 것을 확인할 수 있습니다.
Streaming Multiprocessors and Querying the Device
SMs and Warps
CUDA 프로그램이 실행되는 GPU에는 Streaming Multiprocessors(SMs)라는 처리 장치가 있습니다.
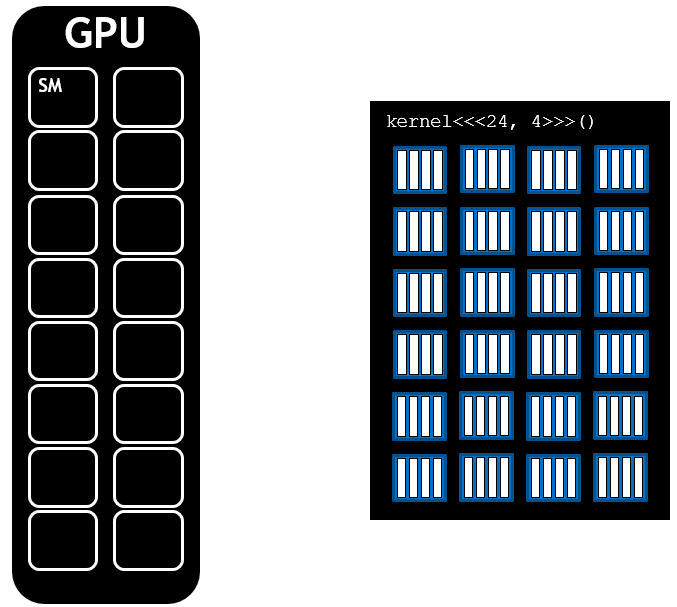
커널이 실행되는 동안, 실행하기 위해서 스레드 블록이 SMs에 제공됩니다.

GPU에 있는 SMs의 수와 블록의 요구사항에 따라서 하나 이상의 블록이 SM에 스케쥴링될 수 있습니다.
그리고 아래 그림과 같이 그리드에 남은 블록들이 처리되는데, GPU에서 한 번에 처리할 수 있는 블록보다 더 적은 블록들이 스케쥴링되는 것을 볼 수 있습니다.
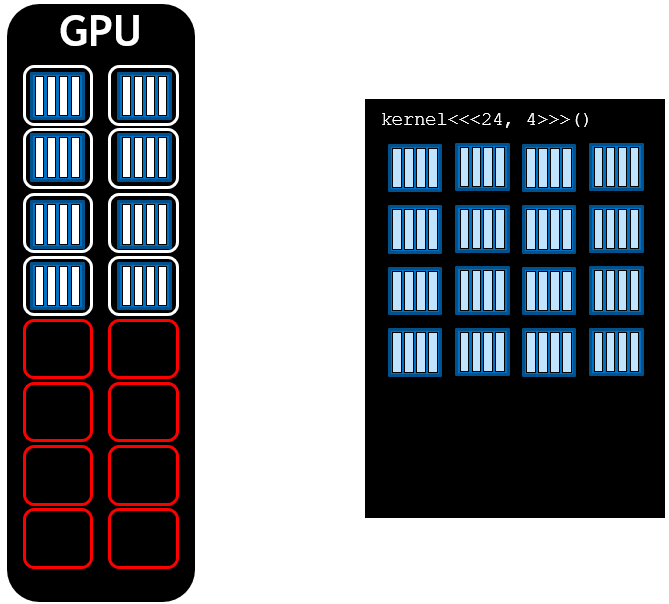
이와 같이 비어있는 SMs들이 있다면, 더 많은 병렬 수행을 동시에 할 수 있음에도 사용하지 않는 것과 같습니다. 따라서, SMs의 수로 나누어 떨어지도록 그리드의 차원을 설정하면 SM의 utilization을 최대한 활용할 수 있습니다.
따라서, 가능한 한 많은 병렬 작업을 수행하기 위해 그리드의 블록 수를 GPU의 SM 갯수의 배수로 설정하는 것이 좋습니다.
또한, SM은 워프(warp)라는 블록 내에서 32개의 스레드 그룹을 생성, 관리, 스케쥴링 및 실행합니다. 자세한 내용은 트레이닝 과정의 범위를 벗어나긴 하는데, 이와 관련한 포스팅이 있으니 필요하시다면 참조바랍니다!
WARP Execution
References Professional CUDA C Programming https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/issueefficiency.htm Contents Warps 이해하기 Wa..
junstar92.tistory.com
한 가지 중요한 사실은 블록의 크기, 즉, 스레드의 수를 32의 배수로 설정하면 성능을 향상시킬 수 있다는 것입니다.
Querying GPU Device Properties Programmatically
사용되는 GPU에 따라 SM의 수가 다를 수 있습니다. 따라서, 이식성을 위해서 SM의 수를 하드 코딩하면 안됩니다. 이러한 정보는 프로그래밍을 통해서 얻을 수 있는데, 그 방법은 다음과 같습니다.
int deviceId; cudaGetDevice(&deviceId); // `deviceId` now points to the id of the currently active GPU. cudaDeviceProp props; cudaGetDeviceProperties(&props, deviceId); // `props` now has many useful properties about // the active GPU device.
위 코드는 CUDA C/C++에서 현재 실행 중인 GPU 디바이스에 대한 많은 속성들을 포함하고 있는 C 구조체를 얻는 방법을 보여줍니다. 이 구조체에는 SMs의 갯수 등을 포함하고 있습니다.
아래 예제 코드는 GPU 디바이스의 정보를 쿼리하고 몇 가지 정보를 출력합니다.
// 11_get-device-properties #include <stdio.h> int main() { /* * Device ID is required first to query the device. */ int deviceId; cudaGetDevice(&deviceId); cudaDeviceProp props; cudaGetDeviceProperties(&props, deviceId); /* * `props` now contains several properties about the current device. */ int computeCapabilityMajor = props.major; int computeCapabilityMinor = props.minor; int multiProcessorCount = props.multiProcessorCount; int warpSize = props.warpSize; printf("Device ID: %d\nNumber of SMs: %d\nCompute Capability Major: %d\nCompute Capability Minor: %d\nWarp Size: %d\n", deviceId, multiProcessorCount, computeCapabilityMajor, computeCapabilityMinor, warpSize); }

GPU 디바이스 쿼리에 대한 조금 더 자세한 내용은 아래 포스팅에서 다룬 적이 있습니다. 필요하시다면 참조바랍니다 !
리소스 동적 분할 및 제한 사항 (+ device query)
리소스 동적 분할 및 제한 사항 (+ device query)
References Programming Massively Parallel Processors Contents SM 리소스의 동적 분할 (Dynamic Partitioning) 리소스 간의 제한사항 (limitations) CUDA Device Query SM(Streaming multiprocessor)의 실행 리..
junstar92.tistory.com
그럼 포스팅 처음에 살펴봤던 벡터 덧셈 프로그램에서 GPU의 SMs 갯수를 쿼리하여, 성능을 조금 더 향상시켜 보도록 하겠습니다. 간단하게, 블록 당 스레드 수는 GPU 디바이스에서 블록에서 지정할 수 있는 최대 스레드 수로 지정하고, 그리드의 블록 수는 GPU 디바이스의 SMs 수로 지정하였습니다.
따라서, 위의 벡터 덧셈 프로그램 코드에서 main 함수의 내부만 다음과 같이 변경하면 됩니다.
int main() { const int N = 2 << 20; size_t size = N * sizeof(float); int deviceId; checkCuda(cudaGetDevice(&deviceId)); cudaDeviceProp props; checkCuda(cudaGetDeviceProperties(&props, deviceId)); float *a, *b, *c; checkCuda(cudaMallocManaged(&a, size)); checkCuda(cudaMallocManaged(&b, size)); checkCuda(cudaMallocManaged(&c, size)); initWith(3, a, N); initWith(4, b, N); initWith(0, c, N); size_t threadsPerBlock = props.maxThreadsPerBlock; size_t numberOfBlocks = props.multiProcessorCount; addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N); checkCuda(cudaGetLastError()); checkCuda(cudaDeviceSynchronize()); checkElementsAre(7, c, N); checkCuda(cudaFree(a)); checkCuda(cudaFree(b)); checkCuda(cudaFree(c)); }
다시 컴파일 후, 실행 파일(sm-optimized-vector-add)를 프로파일링하면,
nsys profile --stats=true ./sm-optimized-vector-add아래와 같은 출력 결과를 얻을 수 있습니다.
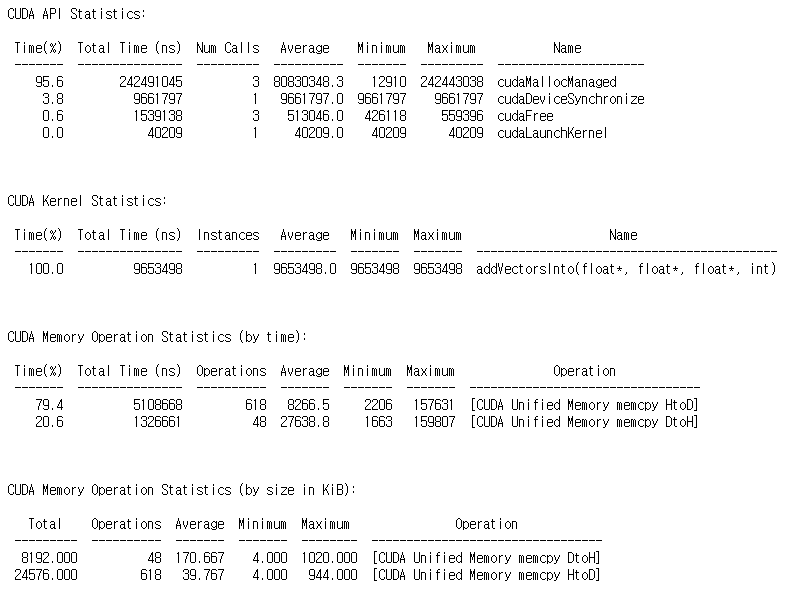
저의 경우, 커널의 수행 시간이 약 9.65ms으로 측정되었습니다. 단일 블록과 각 블록 당 1024개의 스레드로 설정했을 때의 결과인 144ms보다 훨씬 더 빨라진 것을 확인할 수 있습니다.
Unified Memory Details
이전 포스팅에서 host와 device 코드에서 모두 사용하기 위해 cudaMallocManaged() API를 사용하여 메모리를 할당하였습니다. 이를 통해서, 자동으로 이루어지는 CPU<->GPU간의 마이그레이션(migration)과 편의성을 얻었지만, Unified Memory(UM)의 할당 방법에 대한 자세한 내용을 살펴보진 못했습니다.
'nsys profile'은 UM 관리에 대한 세부적인 정보를 제공하며, 이러한 정보와 UM의 동작 방식을 잘 알고 있으면 프로그램을 더 최적화할 수 있는 기회가 있을 수 있습니다.
우선 UM이 기본적으로 어떻게 동작하는지 살펴보겠습니다.
먼저, UM이 할당될 때, 처음에는 CPU나 GPU에 상주하지 않을 수 있습니다.
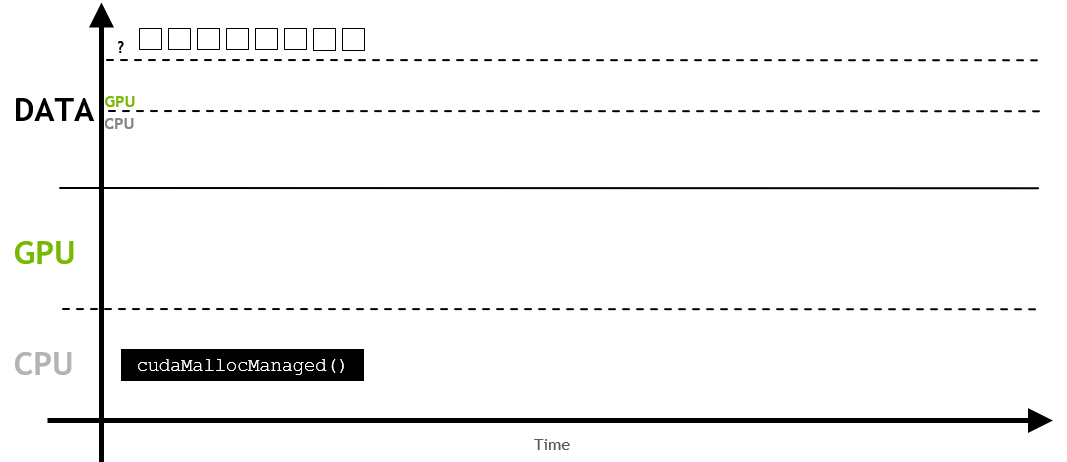
이후에 어떤 작업(이 경우, init())이 처음 메모리를 요청하면, 페이지 폴트(page fault)가 발생합니다.
즉, host나 device에서 메모리를 액세스하려고 하면 페이지 폴드가 발생하게 됩니다.
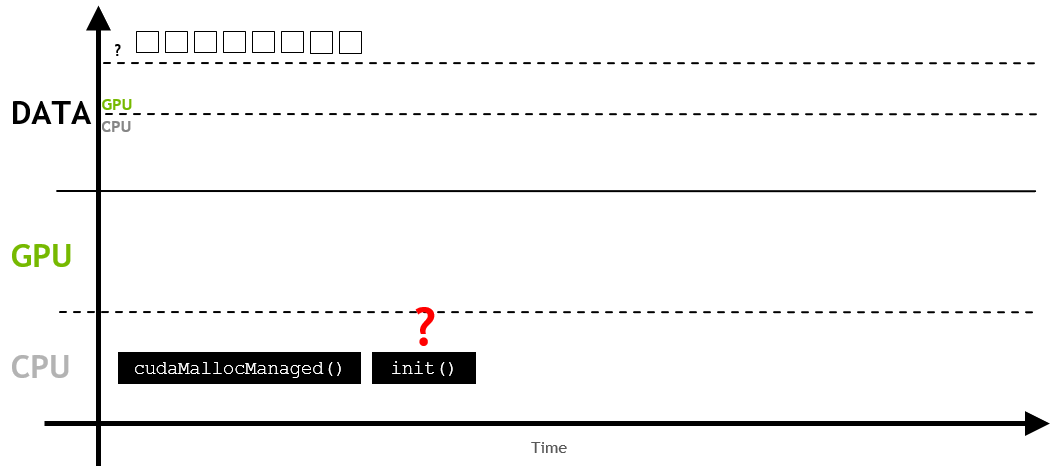
페이지 폴트가 발생하게 되면, 이 시점에서 host나 device는 요청된 메모리를 일괄적으로 migration합니다. 이 경우 CPU로 migration하게 되며, host code에서 메모리를 사용합니다.
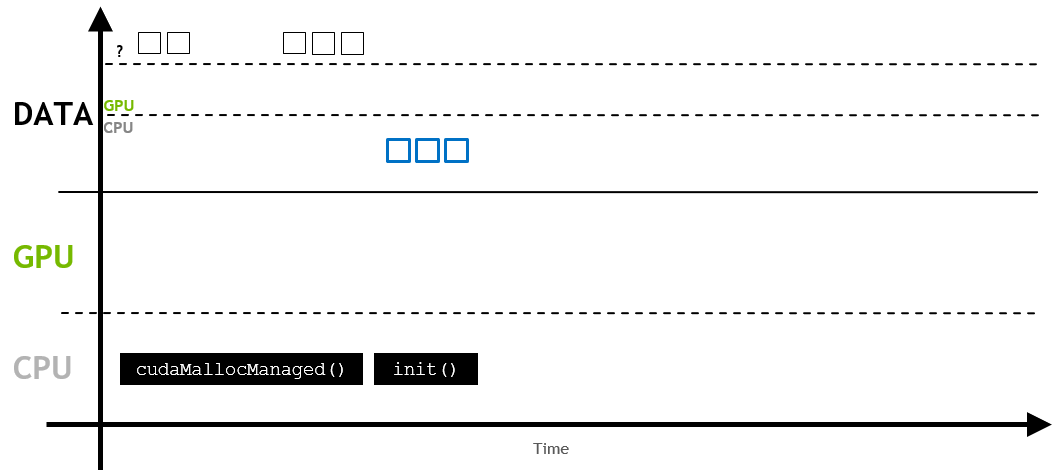
이 과정은 메모리가 상주하지 않는 시스템에서 메모리를 요청할 때마다 반복됩니다.
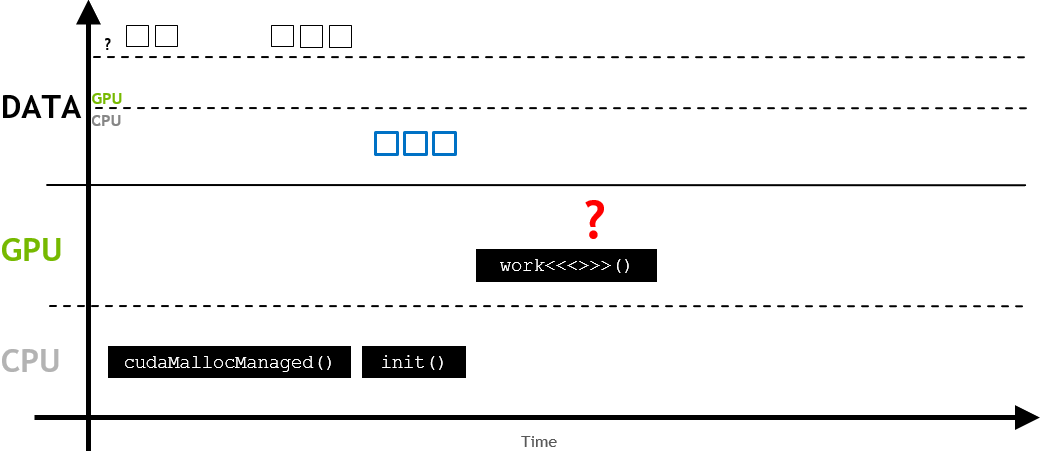
따라서, init()이 수행된 이후에 work 커널이 호출되고, 이 커널에서 메모리 요청이 발생하면, 다음과 같이 GPU로 migration이 트리거 됩니다.

만약 메모리가 상주하고 있지 않는 곳에서 액세스될 것이라는 사실을 알고 있다면, 비동기 prefetching이 사용될 수 있습니다.
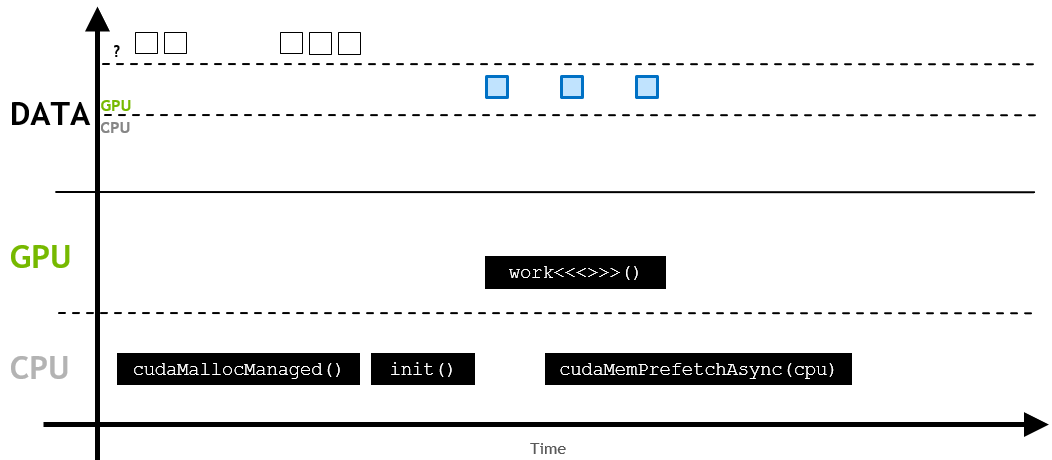
이는 메모리를 더 큰 batch로 이동시키고, 페이지 폴트를 방지합니다.
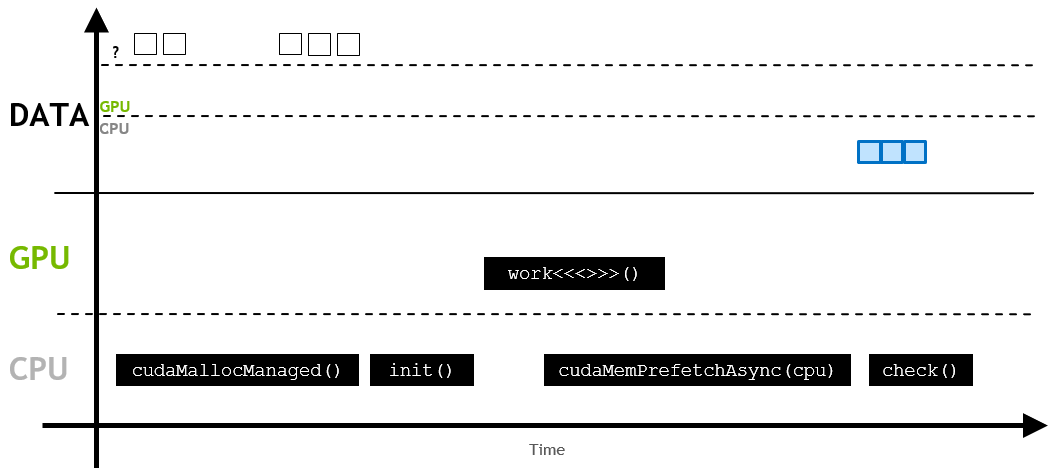
위에서 언급한 것처럼 UM이 처음 할당될 때 메모리는 host나 device에 아직 상주하고 있지 않는 상태입니다. host나 device가 메모리에 엑세스하려고 할 때, 페이지 폴트가 발생합니다. 그리고 이 시점에서 host 또는 device는 필요한 데이터를 일괄적으로 마이그레이션합니다.
UM의 사용은 CUDA 어플리케이션의 개발을 좀 더 쉽게 만들어줍니다. 또한, 어플리케이션이 실제로 실행될 때까지 어떤 데이터를 작업해야 하는지 알 수 없는 경우나 데이터가 다중 GPU를 사용하는 시스템에서 여러 GPU 장치에서 데이터를 액세스하는 경우에서 이러한 on-demand memory migration이 매우 유용합니다.
반면, 런타임 전에 데이터가 어디에서 사용될 지 알고 있고 크고 연속적인 메모리 블록이 필요한 경우에는 페이지 폴트와 데이터 마이그레이션의 오버헤드 때문에 성능이 하락할 수 있으므로 사용하지 않는 것이 좋습니다.
간단한 함수(host)와 커널(device)를 통해 UM과 관련된 실험을 몇 가지 진행해보도록 하겠습니다. 사용될 커널과 함수는 다음과 같습니다.
__global__ void deviceKernel(int *a, const int N) { int idx = blockIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; for (int i = idx; i < N; i += stride) { a[i] = i; } } void hostFunction(int *a, const int N) { for (int i = 0; i < N; i++) { a[i] = i; } }
그리고, 아래의 4가지 경우에 대해 Nsight System으로 프로파일링을 진행합니다.
- Unified Memory가 GPU에 의해서만 액세스되는 경우
- Unified Memory가 CPU에 의해서만 액세스되는 경우
- Unified Memory가 GPU에 의해 액세스된 후, CPU에 의해서 액세스되는 경우
- Unified Memory가 CPU에 의해 액세스된 후, GPU에 의해서 액세스되는 경우
테스트할 메인 함수는 다음과 같으며, 각 경우에 해당하는 코드는 주석으로 작성되어 있습니다.
int main() { int N = 2 << 24; size_t size = N * sizeof(int); int *a; cudaMallocManaged(&a, size); /* * Conduct experiments to learn more about the behavior of * `cudaMallocManaged`. * * What happens when unified memory is accessed only by the GPU? * deviceKernel(a, N); * cudaDeviceSynchronize(); * What happens when unified memory is accessed only by the CPU? * hostFunction<<<256, 256>>>(a, N); * cudaDeviceSynchronize(); * What happens when unified memory is accessed first by the GPU then the CPU? * deviceKernel<<<256, 256>>>(a, N) * cudaDeviceSynchronize(); * hostFunction(a, N); * What happens when unified memory is accessed first by the CPU then the GPU? * hostFunction(a, N); * deviceKernel<<<256, 256>>>(a, N); * cudaDeviceSynchronize(); * * Hypothesize about UM behavior, page faulting specificially, before each * experiment, and then verify by running `nsys`. */ cudaFree(a); }
4가지 경우에 대해 컴파일한 뒤, 실행 파일을 프로파일링한 결과를 살펴봅시다.
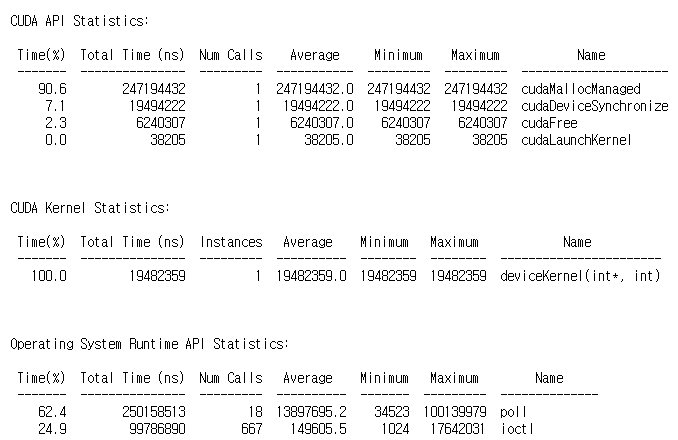
먼저 1번과 2번의 경우, CUDA Memory Operation 관련 분석 결과는 출력되지 않았습니다.
이는 처음 cudaMallocManaged()으로 메모리를 할당했을 때, 메모리가 특정 위치에 상주하고 있지 않기 때문인 것으로 보입니다. 그리고 처음 메모리가 요청되는 곳에서 바로 위치하기 때문에 Host와 Device간의 데이터 마이그레이션 오버헤드가 발생하지 않은 것 같습니다.
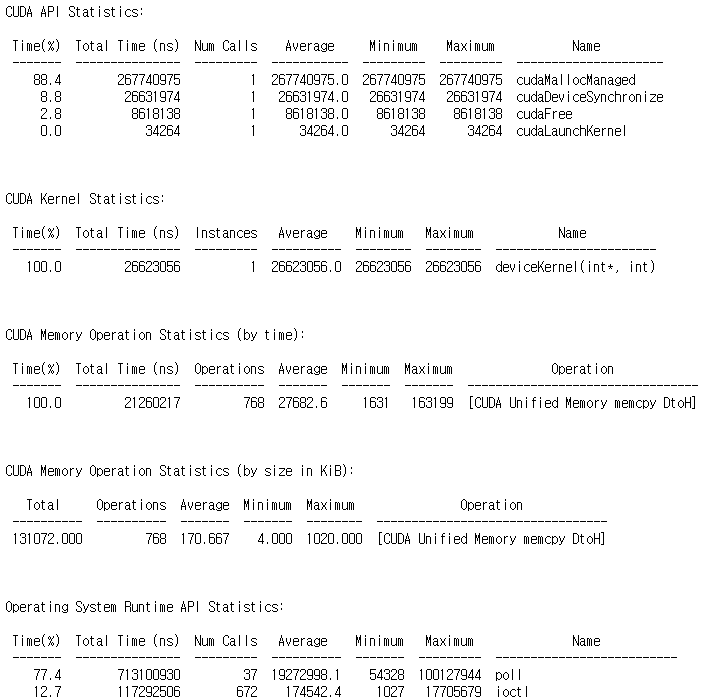
3번(GPU 커널 호출 후, Host 함수 호출)의 경우, Device -> Host(DtoH)의 메모리 복사가 발생했습니다. 처음 메모리가 할당한 뒤에 Device(GPU)에서 처음 메모리가 요청되었기 때문에 할당된 메모리의 첫 위치는 Device가 됩니다. 이후, Host 함수에서 동일한 메모리(현재 device에 상주)를 호출했기 때문에 device에 상주하는 메모리의 데이터를 host 측으로 마이그레이션하는 작업이 수행되었습니다. 따라서, 프로파일링 결과에서 CUDA Memory Operation 항목이 출력된 것을 확인할 수 있습니다.

4번의 경우(Host 함수 호출 뒤, GPU 커널 호출), Host -> Device로의 메모리 마이그레이션이 발생합니다. 처음 할당된 메모리는 처음 메모리가 요청되는 Host 위치에서 사용되었고, 그 이후에 Device 커널에서 요청되면서 Host(CPU)에 상주하는 메모리의 데이터 마이그레이션이 발생합니다. 따라서 프로파일링 출력 결과에서 HtoD 방향으로의 memcpy가 발생한 것을 확인할 수 있습니다.
Vector Add Example
위에서 작성한 Vector Add 커널은 약 9.65ms의 성능을 보여주었습니다. 이 코드에서 UM을 할당하고, 초기화를 host function에서 수행한 뒤, 커널 함수에서 벡터의 덧셈 작업을 수행합니다. 따라서, 메모리를 할당한 뒤, 처음 메모리가 요청되는 곳이 host function이기 때문에 처음에는 할당된 메모리가 host 위치(CPU)에 상주하게 됩니다. 이후에 커널 함수에서 메모리가 요청되면서 페이지 폴드가 발생하고 HtoD 방향으로 데이터 마이그레이션이 발생하여 오버헤드가 발생합니다. 이 오버헤드를 제거해주면 성능이 더 좋아질 것이기 때문에, initWith 함수(host측)를 device에서 초기화하도록 수정하면 조금 더 성능이 좋아질 것입니다.
수정된 코드는 다음과 같습니다. initWith 함수가 host 함수가 아닌 device 커널로 수정되었습니다.
// 09_vector-add.cu #include <stdio.h> #include <assert.h> inline cudaError_t checkCuda(cudaError_t result) { if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result)); assert(result == cudaSuccess); } return result; } __global__ void initWith(float num, float *a, int N) { int idx = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; for (int i = idx; i < N; i += stride) { a[i] = num; } } __global__ void addVectorsInto(float* result, float* a, float* b, const int N) { int idx = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; for (int i = idx; i < N; i += stride) { result[i] = a[i] + b[i]; } } void checkElementsAre(float target, float* array, const int N) { for (int i = 0; i < N; i++) { if (array[i] != target) { printf("FAIL: array[%d] - %0.0f does not equal %0.0f\n", i, array[i], target); exit(1); } } printf("SUCCESS! All values added correctly.\n"); } int main() { const int N = 2 << 20; size_t size = N * sizeof(float); int deviceId; checkCuda(cudaGetDevice(&deviceId)); cudaDeviceProp props; checkCuda(cudaGetDeviceProperties(&props, deviceId)); float *a, *b, *c; checkCuda(cudaMallocManaged(&a, size)); checkCuda(cudaMallocManaged(&b, size)); checkCuda(cudaMallocManaged(&c, size)); size_t threadsPerBlock = props.maxThreadsPerBlock; size_t numberOfBlocks = props.multiProcessorCount; initWith<<<numberOfBlocks, threadsPerBlock>>>(3, a, N); initWith<<<numberOfBlocks, threadsPerBlock>>>(4, b, N); initWith<<<numberOfBlocks, threadsPerBlock>>>(0, c, N); addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N); checkCuda(cudaGetLastError()); checkCuda(cudaDeviceSynchronize()); checkElementsAre(7, c, N); checkCuda(cudaFree(a)); checkCuda(cudaFree(b)); checkCuda(cudaFree(c)); }
프로파일링 결과는 다음과 같습니다.
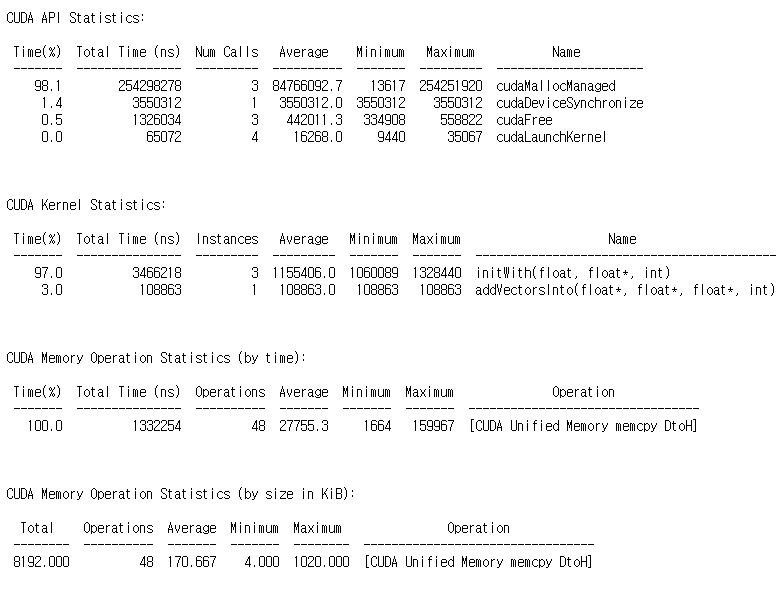
이전 결과와 비교했을 때, HtoD 방향의 memcpy가 없어진 것을 볼 수 있습니다. 그리고 커널의 런타임 또한 9.65ms에서 0.11ms로 더욱 빨라진 것을 확인할 수 있습니다.
Asynchronous Memory Prefetching
UM을 사용할 때, 페이지 폴트와 on-demand 메모리 마이그레이션에 의해 발생하는 오버헤드를 줄이는 강력한 테크닉이 있습니다. 이를 asynchronous memory prefetching이라고 합니다. 이 테크닉을 사용하면, 프로그래머는 어플리케이션 코드에서 해당 메모리를 사용하기 전에 백그라운드에서 비동기적으로 UM을 CPU 또는 GPU로 마이그레이션할 수 있습니다.
또한, prefetch하는 작업은 on-demand보다 더 큰 chunk로 데이터를 마이그레이션하는 경향이 있기 때문에 이동 횟수가 더 적습니다. 따라서, 실행 전에 해당 데이터가 어디에서 액세스될 지 알고 있고 데이터 액세스 패턴이 희소하지 않는 경우에 적합합니다.
CUDA는 cudaMemcpyPrefetchAsync API를 사용하여 메모리를 비동기로 prefetch합니다. 아래 예제 코드는 사용 중인 GPU 장치로 데이터를 prefetch한 다음, CPU로 prefetch하는 방법을 보여줍니다.
int deviceId; cudaGetDevice(&deviceId); cudaMemPrefetchAsync(pointerToSomeUMData, size, deviceId); // Prefetch to GPU device. cudaMemPrefetchAsync(pointerToSomeUMData, size, cudaCpuDeviceId); // Prefetch to host. // 'cudaCpuDeviceId' is a build-in CUDA variable.
방금 전에 initWith를 수정하여 성능을 개선했던 코드에서 cudaMemcpyPrefetchAsync API를 추가하면, 성능의 변화가 어떤지 살펴보겠습니다. cudaMemcpyPrefetchAsync 함수를 추가한 코드는 다음과 같습니다.
// 09_vector-add.cu #include <stdio.h> #include <assert.h> inline cudaError_t checkCuda(cudaError_t result) { if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result)); assert(result == cudaSuccess); } return result; } __global__ void initWith(float num, float *a, int N) { int idx = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; for (int i = idx; i < N; i += stride) { a[i] = num; } } __global__ void addVectorsInto(float* result, float* a, float* b, const int N) { int idx = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; for (int i = idx; i < N; i += stride) { result[i] = a[i] + b[i]; } } void checkElementsAre(float target, float* array, const int N) { for (int i = 0; i < N; i++) { if (array[i] != target) { printf("FAIL: array[%d] - %0.0f does not equal %0.0f\n", i, array[i], target); exit(1); } } printf("SUCCESS! All values added correctly.\n"); } int main() { const int N = 2 << 20; size_t size = N * sizeof(float); int deviceId; checkCuda(cudaGetDevice(&deviceId)); cudaDeviceProp props; checkCuda(cudaGetDeviceProperties(&props, deviceId)); float *a, *b, *c; checkCuda(cudaMallocManaged(&a, size)); checkCuda(cudaMallocManaged(&b, size)); checkCuda(cudaMallocManaged(&c, size)); checkCuda(cudaMemPrefetchAsync(a, size, deviceId)); checkCuda(cudaMemPrefetchAsync(b, size, deviceId)); checkCuda(cudaMemPrefetchAsync(c, size, deviceId)); size_t threadsPerBlock = props.maxThreadsPerBlock; size_t numberOfBlocks = props.multiProcessorCount; initWith<<<numberOfBlocks, threadsPerBlock>>>(3, a, N); initWith<<<numberOfBlocks, threadsPerBlock>>>(4, b, N); initWith<<<numberOfBlocks, threadsPerBlock>>>(0, c, N); addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N); checkCuda(cudaGetLastError()); checkCuda(cudaDeviceSynchronize()); checkElementsAre(7, c, N); checkCuda(cudaFree(a)); checkCuda(cudaFree(b)); checkCuda(cudaFree(c)); }
위 코드를 컴파일하고, nsys profile로 프로파일링한 결과는 다음과 같습니다.
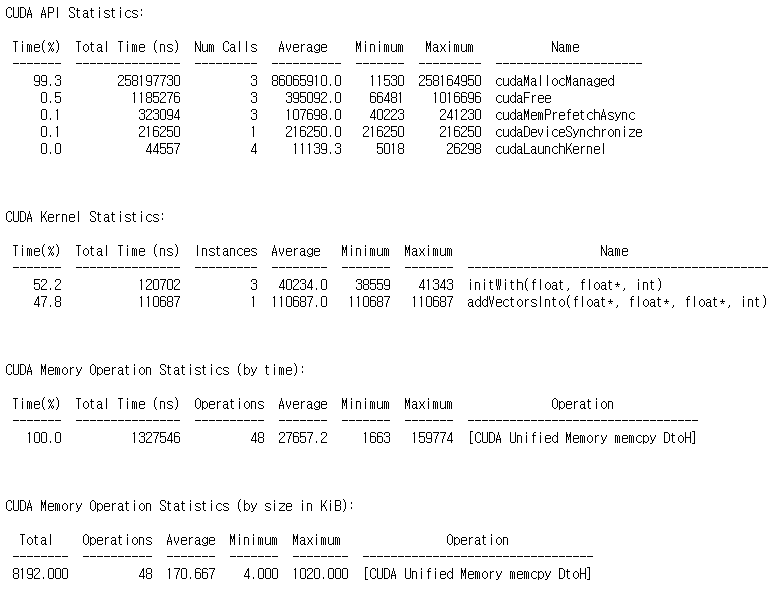
이전 결과에서 처음 메모리를 요청하는 initWith 커널의 런타임은 약 3.47ms로 측정되었습니다. 하지만, 비동기로 메모리를 prefetch한 코드에서 initWith 커널의 런타임은 0.12ms로 더욱 빨라진 것을 확인할 수 있습니다. 참고로 실제 CPU Memory Operation(memcpy DtoH)의 런타임은 동일한 것을 확인할 수 있습니다.
main 함수 마지막 부분에 검증을 하기 위해 checkElementsAre 함수를 호출하여 UM을 요청하고 있습니다. 따라서, 여기서 페이지 폴트가 발생합니다. 이 경우, 우리는 해당 함수가 host에서 호출되고, host 측에서 UM을 요청하는 것을 알고 있기 때문에 checkElementsAre을 호출하기 전에 prefetch를 통해 성능을 더 향상시킬 수 있다는 것을 짐작할 수 있습니다.
int main() { const int N = 2 << 20; size_t size = N * sizeof(float); int deviceId; checkCuda(cudaGetDevice(&deviceId)); cudaDeviceProp props; checkCuda(cudaGetDeviceProperties(&props, deviceId)); float *a, *b, *c; checkCuda(cudaMallocManaged(&a, size)); checkCuda(cudaMallocManaged(&b, size)); checkCuda(cudaMallocManaged(&c, size)); checkCuda(cudaMemPrefetchAsync(a, size, deviceId)); checkCuda(cudaMemPrefetchAsync(b, size, deviceId)); checkCuda(cudaMemPrefetchAsync(c, size, deviceId)); size_t threadsPerBlock = props.maxThreadsPerBlock; size_t numberOfBlocks = props.multiProcessorCount; initWith<<<numberOfBlocks, threadsPerBlock>>>(3, a, N); initWith<<<numberOfBlocks, threadsPerBlock>>>(4, b, N); initWith<<<numberOfBlocks, threadsPerBlock>>>(0, c, N); addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N); checkCuda(cudaGetLastError()); checkCuda(cudaDeviceSynchronize()); checkCuda(cudaMemPrefetchAsync(c, size, cudaCpuDeviceId)); checkElementsAre(7, c, N); checkCuda(cudaFree(a)); checkCuda(cudaFree(b)); checkCuda(cudaFree(c)); }
main 함수를 위와 같이 변경하고 컴파일 한 뒤, 프로파일링한 결과는 다음과 같습니다.
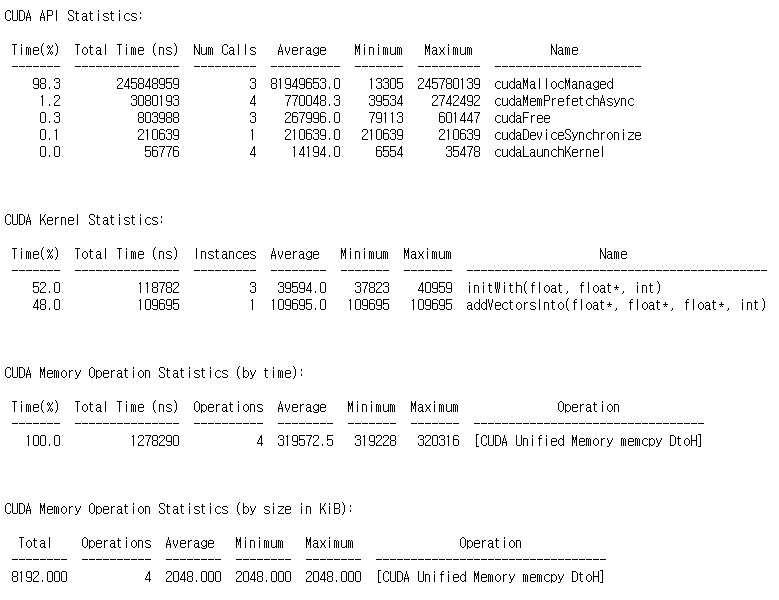
이번에는 CUDA Memory Operation Statistics (by size in KiB)에 주목하시길 바랍니다.
checkElementsAre 함수를 호출하기 전에 prefetch를 수행하지 않은 경우,

총, 8192KB의 데이터를 48번의 op를 통해 마이그레이션한다는 것을 볼 수 있습니다.
반면, prefetch를 수행하는 경우에는,

4번의 op만으로 8192KB의 데이터를 마이그레이션합니다.
다만, Memory Operation의 런타임은 눈에 띌 정도로 빨라지지는 않았습니다(1.33ms -> 1.28ms).
위에서 사용된 일부 예제 코드는 아래 github에서 확인하실 수 있습니다.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
'NVIDIA > CUDA' 카테고리의 다른 글
| Multiple GPUs with CUDA C++ (0) | 2022.06.16 |
|---|---|
| CUDA C/C++ 기초 - (3) (0) | 2022.06.14 |
| CUDA C/C++ 기초 - (1) (2) | 2022.06.10 |
| CUDA Instructions (2) - Instruction 최적화 (0) | 2022.01.28 |
| CUDA Instructions (1) (0) | 2022.01.26 |




댓글