References
- Professional CUDA C Programming
Contents
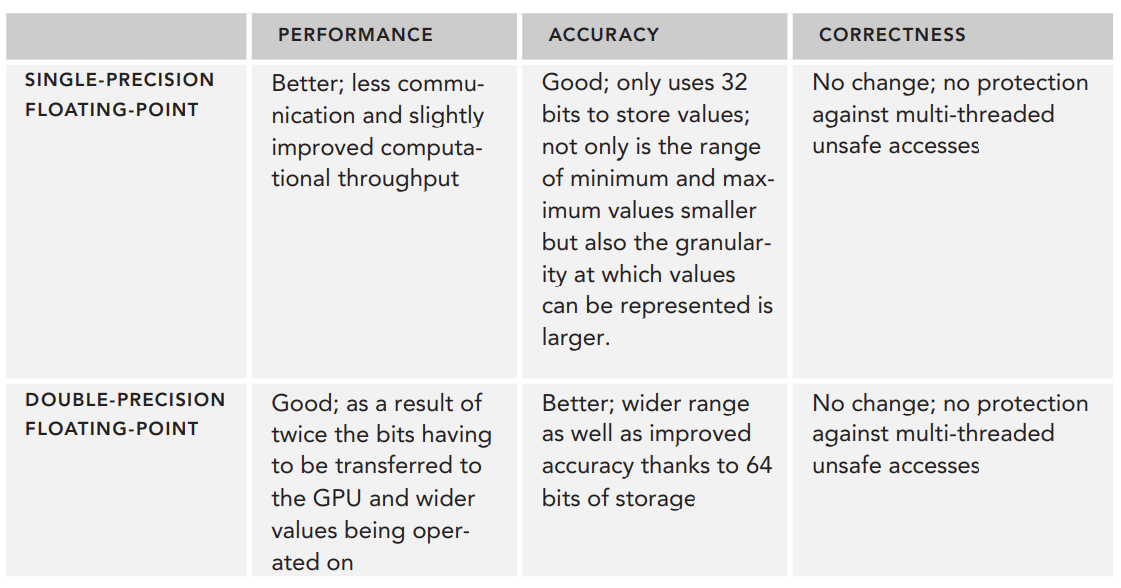
- Single-Precision vs. Double-Precision
- Standard vs. Intrinsic Functions
- Understanding Atomic Instructions
지난 포스팅을 통해서 CUDA의 Instruction들을 살펴보고, 그 특징들을 알아봤습니다.
이 Instruction들을 통해, CUDA 프로그램에서 명령어들을 최적화할 때 많은 선택 사항들이 있다는 것을 알 수 있습니다.
- Single-Precision or Double-Precision
- Standard or Intrinsic Functions
- Atomic function or Unsafe accesses
일반적으로 이들 간의 선택은 성능과 정밀도, 정확성들 간의 tradeoff 입니다. 모든 프로그램에서 최선인 단 하나의 선택은 없습니다. 이 선택은 어플리케이션의 요구사항에 따라 다릅니다.
이번 포스팅에서는 예제 코드들을 통해 이러한 instruction들의 장점과 단점들을 비교해보도록 하겠습니다.
Single-Precision vs. Double-Precision
지난 포스팅에서 봤듯이, 단정밀도(single-precision)와 배정밀도(double-precision)은 값을 저장하는데 사용되는 비트의 개수가 다릅니다. 결과적으로 배정밀도인 변수는 단정밀도보다 더 넓은 범위의 정확하고 세밀한 값을 표현할 수 있습니다.
먼저 다음의 예제 코드를 살펴보겠습니다. 이 코드는 12.1을 host와 device에서 float와 double 타입에 각각 저장하고, 실제 저장된 값을 소수점 20자리까지 출력합니다.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
위 코드를 컴파일 후 실행하면 다음의 출력을 확인할 수 있습니다.

host와 device에서 12.1을 동일한 근사치로 표현하지만, 둘 다 정확한 값을 저장하지는 못합니다. 이 예제 코드에서 배정밀도의 값이 단정밀도보다 12.1에 조금 더 가깝습니다.
배정밀도의 정확성은 공간과 성능의 비용과 함께 고려되어야 합니다.
다음의 예제 코드를 살펴보겠습니다.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
위 예제 코드는 float와 double 타입의 input 배열을 생성하고, GPU로 복사한 후 반복적으로 산술 연산이 포함된 커널을 수행하고 다시 그 결과값을 Host로 복사합니다.
/* The computational kernel for single-precision floating-point */ __global__ void lots_of_float_compute(float* in, int N, size_t nIters, float* out) { size_t tid = blockDim.x * blockIdx.x + threadIdx.x; size_t nThreads = gridDim.x * blockDim.x; for (; tid < N; tid += nThreads) { float val = in[tid]; for (size_t i = 0; i < nIters; i++) { val = (val + 5.0f) - 101.0f; val = (val / 3.0f) + 102.0f; val = (val + 1.07f) - 103.0f; val = (val / 1.037f) + 104.0f; val = (val + 3.00f) - 105.0f; val = (val / 0.22f) + 106.0f; } out[tid] = val; } } /* The computational kernel for double-precision floating-point */ __global__ void lots_of_double_compute(double* in, int N, size_t nIters, double* out) { size_t tid = blockDim.x * blockIdx.x + threadIdx.x; size_t nThreads = gridDim.x * blockDim.x; for (; tid < N; tid += nThreads) { double val = in[tid]; for (size_t i = 0; i < nIters; i++) { val = (val + 5.0f) - 101.0f; val = (val / 3.0f) + 102.0f; val = (val + 1.07f) - 103.0f; val = (val / 1.037f) + 104.0f; val = (val + 3.00f) - 105.0f; val = (val / 0.22f) + 106.0f; } out[tid] = val; } }
lots_of_float_compute와 lots_of_double_compute 커널은 동일한 연산을 float 타입과 double 타입에서 각각 수행하면서, HostToDevice Copy, Kernel, DeviceToHost Copy의 시간을 측정하고 비교합니다.
최대한 정확하게 측정하여 비교하기 위해서 5번 반복 수행하여 합산된 시간의 평균을 구합니다.
for (int i = 0; i < nRuns; i++) { double toDeviceTime, kernelTime, fromDeviceTime; run_float_test(N, nKernelIters, blocksPerGrid, threadsPerBlock, &toDeviceTime, &kernelTime, &fromDeviceTime, floatSample, sampleLength); meanFloatToDeviceTime += toDeviceTime; meanFloatKernelTime += kernelTime; meanFloatFromDeviceTime += fromDeviceTime; run_double_test(N, nKernelIters, blocksPerGrid, threadsPerBlock, &toDeviceTime, &kernelTime, &fromDeviceTime, doubleSample, sampleLength); meanDoubleToDeviceTime += toDeviceTime; meanDoubleKernelTime += kernelTime; meanDoubleFromDeviceTime += fromDeviceTime; if (i == 0) { printf("\nInput\tDiff Between Single- and Double-Precision\n"); printf("------\t------\n"); for (int j = 0; j < sampleLength; j++) { printf("%d\t%.20e\n", j, fabs(doubleSample[j] - static_cast<double>(floatSample[j]))); } printf("\n"); } }
위 코드를 컴파일하고 실행하면 다음의 출력을 확인하실 수 있습니다.
결과를 살펴보면, 단정밀도와 배정밀도 간의 성능 차이는 무시할 수 없는 정도입니다. 특히 배정밀도의 값이 단정밀도 값 크기의 2배이기 때문에 GPU와 데이터를 주고 받는 시간이 약 2배 증가한 것을 확인할 수 있습니다. 또한 Global Memory I/O의 양과 각 명령어에 의해 조작되는 비트 수가 증가함에 따라 디바이스의 계산 시간도 증가했습니다.
위 결과에서 한 번의 반복에서 발생한 오차가 다음 반복의 입력으로 그대로 사용되면서 각 반복에서의 오차가 갈수록 누적되어 단정밀도와 배정밀도의 결과 차이가 점점 벌어지는 것을 볼 수 있습니다. 따라서 반복적으로 수해외는 연산의 경우 정확도를 위해서 배정밀도 변수를 사용하는 것이 더 좋을 수 있습니다.
또한, 배정밀도의 값은 단정밀도의 값이 차지하는 공간의 2배를 차지하므로, 레지스터에 double 타입을 저장할 때 스레드 블록에서 공유되는 레지스터는 float 타입을 사용할 때보다 줄어듭니다.
그리고 float 타입의 값을 선언할 때에는 특히 주의해야 합니다. 예를 들어, pi = 3.14159f로 선언하지 않고 f를 생략하면 자동으로 nvcc는 이 값을 배정밀도로 승격시켜 사용합니다.
Standard vs. Intrinsic Functions
Standard와 intrinsic 함수는 수치적 정확성과 성능 면에서 모두 다릅니다. Standard 함수는 광범위한 산술 연산을 지원합니다. intrinsic 함수는 동일한 기능을 구현하지만, 명령의 수는 적고, 성능은 향상되면서 정확도는 떨어집니다.
Visualizing Standard and Intrinsic Functions
standard와 intrinsic 함수 간의 차이점을 시각적으로 확인하는 방법은 각 함수에 대해 CUDA 컴파일러가 생성한 명령어를 확인하는 것입니다. nvcc에 --ptx 플래그를 사용하면 컴파일러가 프로그램의 중간 생성물을 만들도록 하며, 이는 최종 실행 파일이 아닌 PTX(parallel thread execution) ISA(instruction set architecture) 입니다. PTX는 x86 프로그래밍의 어셈블리와 유사하며, 작성한 커널코드와 GPU에 의해서 실행되는 명령어 사이의 중간 명령어를 보여줍니다.
예시로, 다음 두 개의 CUDA 함수를 시각적으로 비교하기 위해 PTX를 생성해보도록 하겠습니다.
foo.cu라는 이름의 파일을 만들어서 아래의 코드를 작성합니다.
__global__ void intrinsic(float* ptr) { *ptr = __powf(*ptr, 2.0f); } __global__ void standard(float* ptr) { *ptr = powf(*ptr, 2.0f); }
그리고 다음의 nvcc 커맨드를 입력하여 PTX 출력물을 생성합니다.
nvcc --ptx -o foo.ptx foo.cu
생성된 foo.ptx의 내용을 text editer로 보면, 익숙하지 않은 명령어들이 나열되어 있습니다. '.entry' 명령어는 함수 정의의 시작지점을 의미합니다. 저의 경우 CUDA 11.5에서 생성하였으며, 아래는 ptx 결과의 일부분입니다. 맹글링된 함수 이름은 컴파일러 버전마다 아마 다를 것입니다.
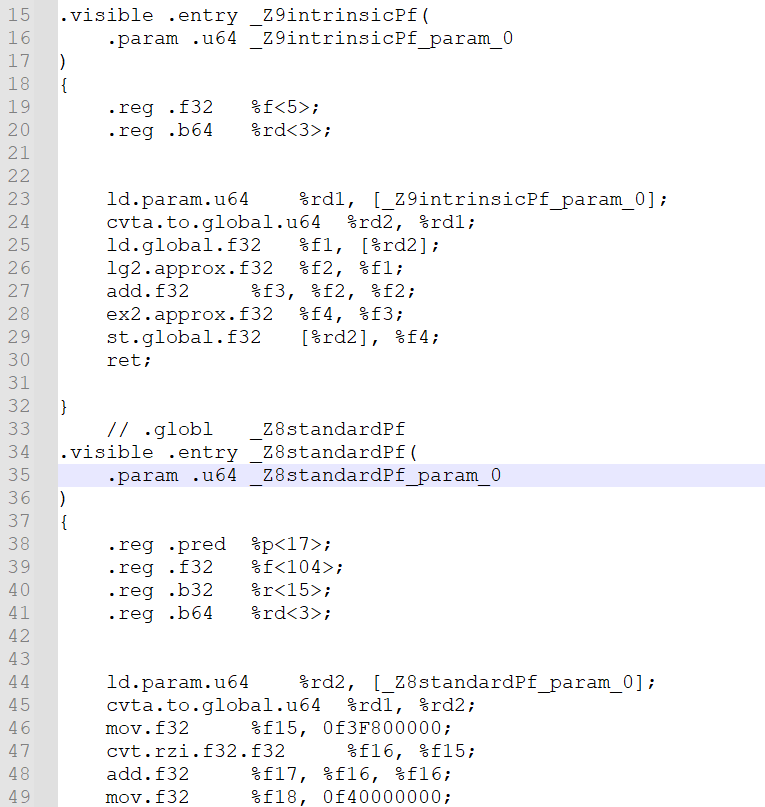
여기서 intrinsic 커널을 찾으면 다음과 같습니다.
.visible .entry _Z9intrinsicPf( .param .u64 _Z9intrinsicPf_param_0 ) { .reg .f32 %f<5>; .reg .b64 %rd<3>; ld.param.u64 %rd1, [_Z9intrinsicPf_param_0]; cvta.to.global.u64 %rd2, %rd1; ld.global.f32 %f1, [%rd2]; lg2.approx.f32 %f2, %f1; add.f32 %f3, %f2, %f2; ex2.approx.f32 %f4, %f3; st.global.f32 [%rd2], %f4; ret; }
intrinsic 함수인 __powf 함수를 구현하는데 총 18줄이 필요하고, floating-point exponentiation을 수행하는데 7개의 명령어만이 필요합니다. 그러나 standar 함수인 powf 함수를 살펴보면, 저의 경우에는 206줄로 되어 있습니다. line 수가 직접적으로 사이클당 명령어로 변환되는 것은 아니지만, 성능에서 큰 차이가 있을 것으로 추측할 수 있습니다.
standard와 intrinsic 함수는 성능뿐만 아니라 정밀도 측면에서도 서로 다릅니다. 이를 테스트하기 위해 다음의 예제 코드를 살펴보도록 하겠습니다.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
이 예제 코드에서 커널은 입력 값의 제곱을 반복적으로 수행하는데, 먼저 standard function인 powf에 대해 수행하고 intrinsic function인 __powf에 대해 수행합니다. 또한 C에서 제공하는 표준 math 라이브러리를 사용하여 동일한 계산을 수행하고 이 결과를 기준으로 결과를 비교합니다.
위 코드를 컴파일하고, 실행한 결과는 다음과 같습니다.
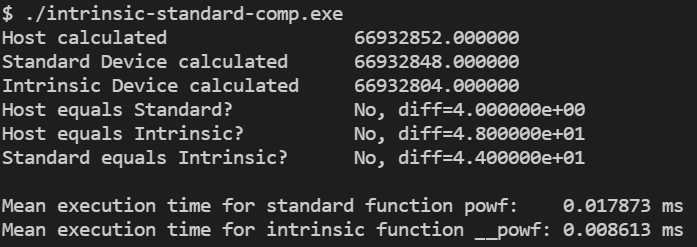
intrinsic 함수와 standard 함수에는 약 2배의 속도 차이가 발생하는 것을 확인할 수 있습니다. 계산 결과는 더 흥미롭습니다. CUDA standard 함수와 intrinsic 함수의 결과는 다를 뿐만 아니라 host의 표준 math 라이브러리에서 계산한 결과와도 다릅니다.
PORTING FROM CPU TO GPU
과학 시뮬레이션이나 financial 알고리즘 및 높은 수준의 정확성을 요구하는 다른 어플리케이션에 CUDA를 사용하려면 일반적으로 두 가지 단계가 필요합니다. CPU 전용 프레임워크에서 CUDA로 레거시 어플리케이션을 포팅한 다음 레거시 구현과 CUDA 버전의 결과를 비교하여 수치적 정확도를 검증합니다.
수치적으로 안정적인 CUDA 함수를 사용하더라도 GPU 장치로부터의 연산 결과는 여전히 기존의 CPU 전용 어플리케이션과 다를 수 있습니다. Host와 Device에서 부동소수점 연산의 본질적인 부정확성 때문입니다. 따라서 포팅 플랜은 수차적 차이를 명시적으로 준비하고 필요하다면 허용할만한 오차를 설정해야 합니다.
Manipulating Instruction Generation
대부분의 경우, 프로그래머가 작성한 커널 코드에서 GPU 명령어 셋으로의 변환은 CUDA 컴파일러에 의해서 다루어지는 부분입니다. 수작업으로 생성되는 명령어들을 수정하거나 살펴보는 것은 거의 드물다고 할 수 있습니다. 하지만, 컴파일러가 성능, 정확도, 또는 둘 사이의 밸런스를 맞추도록 쉽게 지시할 수 없다는 것은 아닙니다. 컴파일러 플래그와 intrinsic or standard 함수의 호출은 CUDA 컴파일러가 수행할 수 있는 Instruction-level 최적화의 타입을 제어할 수 있도록 합니다.
예를 들어, __fdividef intrinsic 함수는 '/' 연산자에 비해 빠르지만 수치적으로 덜 정밀한 floating-point division을 구현합니다.
다음의 커널 함수 foo가 있다고 가정해봅시다.
__global__ void foo(...) { float a = ...; float b = ...; float c = a / b; }
우리는 간단히 '/' 연산자를 기능적으로 동등한 __fdividef로 변경하고 성능을 측정할 수 있습니다.
__global__ void foo(...) { float a = ...; float b = ...; float c = __fdividef(a, b); }
그러나 수작업으로 커널의 operation by operation으로 조정하는 것은 많은 시간이 걸리는 작업입니다.
컴파일 플래그를 사용하면 컴파일러 명령어 생성을 더 자동화하고 전역적으로 조작할 수 있습니다.
예를 들어, CUDA 컴파일러에 의해서 float-point MAD (FMAD) 명령어의 생성을 제어하고 싶다고 가정해봅시다. MAD는 곱셈과 덧셈을 하나의 명령어로 혼합하는 간단한 컴파일러 최적화이며, 두 개의 명령어를 수행하는 것에 비해 시간이 절반으로 줄어듭니다. 그러나 이러한 최적화에는 약간의 정확도가 희생됩니다. 따라서 일부 어플리케이션에서는 FMAD 명령어의 사용을 명시적으로 제한할 수 있습니다.
nvcc에 --fmad 옵션을 추가하면 전역적으로 FMAD 최적화를 컴파일러 유닛에서 활성화하거나 비활성화할 수 있습니다. 기본적으로 nvcc는 --fmad=true를 사용하여 성능 최적화를 위해 FMAD 명령어 생성을 활성화합니다. --fmad=false를 사용하면 컴파일러가 곱셈과 덧셈을 혼합하지 않도록 하여, 성능 향상보다는 정확한 결과를 얻도록 해줍니다.
예를 들어, 다음의 간단한 커널을 살펴봅시다.
__global__ void foo(float *ptr) { *ptr = (*ptr) * (*ptr) + (*ptr); }
위 코드를 --fmad=true를 추가하여 PTX를 생성하면 커널 바디에는 하나의 산술 명령어(line 12)만 있습니다.
.visible .entry _Z3fooPf( .param .u64 _Z3fooPf_param_0 ) { .reg .f32 %f<3>; .reg .b64 %rd<3>; ld.param.u64 %rd1, [_Z3fooPf_param_0]; cvta.to.global.u64 %rd2, %rd1; ld.global.f32 %f1, [%rd2]; fma.rn.f32 %f2, %f1, %f1, %f1; st.global.f32 [%rd2], %f2; ret; }
--fmad=false를 사용하여 PTX를 생성하면, 하나의 명령어가 곱셈과 덧셈(line 12,13)으로 나누어진 것을 확인할 수 있습니다.
.visible .entry _Z3fooPf( .param .u64 _Z3fooPf_param_0 ) { .reg .f32 %f<4>; .reg .b64 %rd<3>; ld.param.u64 %rd1, [_Z3fooPf_param_0]; cvta.to.global.u64 %rd2, %rd1; ld.global.f32 %f1, [%rd2]; mul.rn.f32 %f2, %f1, %f1; add.rn.f32 %f3, %f1, %f2; st.global.f32 [%rd2], %f3; ret; }
더 많은 컴파일러 플래그는 아래 nvcc 공식 문서에서 확인하실 수 있습니다.
https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
NVCC :: CUDA Toolkit Documentation
The compilation trajectory involves several splitting, compilation, preprocessing, and merging steps for each CUDA source file. It is the purpose of nvcc, the CUDA compiler driver, to hide the intricate details of CUDA compilation from developers. It accep
docs.nvidia.com
다음의 표는 책에서 설명하고 있는 명령어 생성과 관련된 몇 가지 컴파일러 플래그입니다.
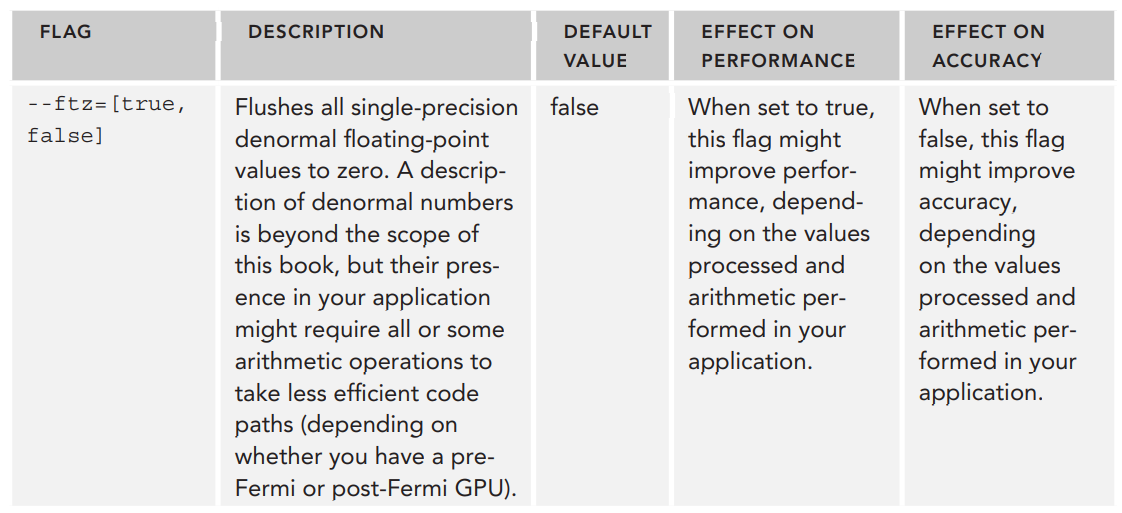
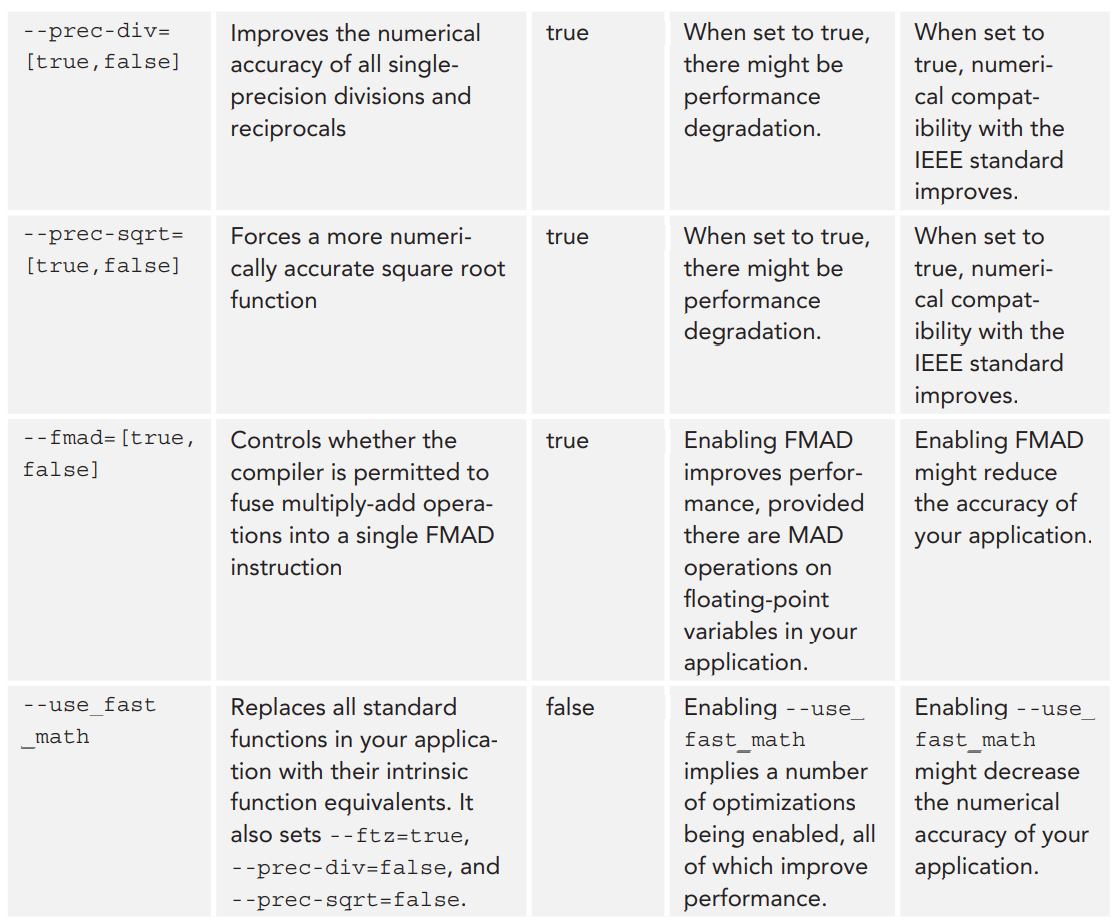
--fmad 옵션외에도 CUDA는 FMAD 명령어 생성을 제어할 수 있는데 사용할 수 있는 __fmul와 __dmul이라는 intrinsic 함수를 제공합니다. 이 함수는 float와 double 타입에서의 부동소수점 곱셈을 구현합니다. 이 함수들은 곱셈 연산의 성능에 영향을 미치지는 않지만, * 연산자 대신 이 함수들을 호출하면 nvcc가 곱셈을 MAD 최적화의 일부로 사용하는 것을 방지할 수 있습니다. 예를 들어, 위에서 살펴본 예제 커널 foo에서는 --fmad=false를 사용하여 FMAD 명령어 생성을 못하도록 했지만, __fmul 함수를 사용하면 컴파일러 옵션을 설정하지 않아도 동일한 효과를 얻을 수 있습니다.
__global__ void foo(float *ptr) { *ptr = _fmul_rn(*ptr, *ptr) + *ptr; }
__fmul과 __dmul은 사용하면 --fmad=true나 --fmad=false 중 어떤 것을 사용하든지 MAD 명령어를 생성하지 않습니다. 그 결과 __fmul 또는 __dmul을 선택적으로 호출하여 특정 계산의 수치적 견고성을 향상시키면서 전역적으로는 MAD 컴파일러 최적화를 가능하게 할 수 있습니다.
위 foo 커널에서는 실제로 __fmul_rn이 호출되고 있습니다. 많은 부동소수점 함수(__fadd, __fsub, __fmul 등)에서는 명시적으로 floating-point rounding mode를 함수 이름 뒤에 sufix(2-character)를 붙여서 지정할 수 있습니다.

부동소수점 변수는 이산적인 값들만 나타낼 수 있기 때문에 표현 불가능한 값은 표현 가능한 값으로 반올림해야한다고 이전 포스팅에서 언급했었습니다. 위 suffix들에 의해서 결정되는 rounding mode는 표현 불가능한 값에서 표현 가능한 값으로 변환되는 방법을 결정합니다.
다음 예제 코드를 통해서 FMAD 최적화를 활성화하고 비활성화함에 따라 instruction-level의 변화가 어떻게 일어나는지 살펴보도록 하겠습니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/Instruction/fmad.cu
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
위의 예제 코드는 하나의 단일 MAD 명령어를 host와 device에서 실행합니다. 여기서 --fmad 플래그를 다르게 설정하여 그 결과가 어떻게 변화되는지 살펴보겠습니다.
__global__ void fmad_kernel(double x, double y, double *out) { int tid = blockDim.x * blockIdx.x + threadIdx.x; if (tid == 0) { *out = x * x + y; } } double host_fmad_kernel(double x, double y) { return x * x + y; } int main(int argc, char** argv) { double *d_out, h_out; double x = 2.891903; double y = -3.980364; double host_value = host_fmad_kernel(x, y); CUDA_CHECK(cudaMalloc((void**)&d_out, sizeof(double))); fmad_kernel<<<1, 32>>>(x, y, d_out); CUDA_CHECK(cudaMemcpy(&h_out, d_out, sizeof(double), cudaMemcpyDeviceToHost)); if (host_value == h_out) { printf("The device output the same value as the host.\n"); } else { printf("The device output a different value than the host, diff=%e.\n", fabs(host_value - h_out)); } return 0; }
먼저 --fmad=true로 컴파일하고 실행한 결과입니다.

예상한대로, MAD 최적화를 사용하면 device에서 약간의 오차가 발생합니다.
이제 --fmad=false로 컴파일하고 실행해보도록 하겠습니다.

MAD를 비활성화하면 host와 device에서의 결과가 일치합니다. 그러나 device 커널은 이제 이 연산을 수행하기 위해 더 많은 명령어를 필요로 할 것입니다.
Understanding Atomic Instructions
이번에는 atomic operation을 사용하는 방법과 높은 concurrent 환경에서 공유 데이터에 대해 올바른 연산을 구현하는 방법에 대해 알아보도록 하겠습니다.
atomicCAS
CUDA에서 제공되는 모든 atomic function은 single atomic function을 사용하여 재구현될 수 있습니다. 이를 atomic compare-and-swap(CAS) operator라고 합니다. Atomic CAS는 CUDA에서 자신만의 atomic 함수를 정의할 수 있게 해줄뿐만 아니라 atomic operation에 대해 깊게 이해할 수 있도록 도와줍니다.
CAS는 3개의 input을 파라미터로 입력받습니다. 메모리 주소(memory location), 이 메모리 주소에서의 expected value, 그리고 앞의 메모리 주소에 저장할 값입니다. 그런 다음 다음의 단계를 수행합니다.
- target location을 읽고, 여기에 저장된 값과 expected value를 비교한다
- 만약 저장된 값이 expected value와 같다면, target memory location은 원하는 값으로 채워짐
- 만약 저장된 값이 expected value와 같지 않다면, target location에는 변화가 없음
- 두 경우 모두, CAS operation은 항상 target location에 저장된 값을 반환합니다. 이 반환된 값을 사용하여 성공적으로 swap이 이루어졌는지 확인할 수 있습니다. 만약 반환된 값이 전달된 expected value와 같다면, CAS operation은 성공한 것입니다.
atomic operation을 좀 더 이해하기 위해 CUDA의 atomicCAS를 사용하여 직접 atomic fucntion을 구현해보도록 하겠습니다. 예제로는 atomic 32bit integer addition을 구현하도록 하겠습니다.
먼저 사용할 atomicCAS는 다음과 같습니다.
int atomicCAS(int *address, int compare, int val);address는 target location이며, compare는 해당 값에 대한 expected value이고, val은 이 메모리 위치에 write하고자하는 값입니다.
그럼 어떻게 atomicCAS를 사용하여 atomic addition을 구현할 수 있을까요?
먼저 더하고자 하는 메모리 위치와 더할 값을 받는 함수로부터 시작해보겠습니다.
__device__ int myAtomicAdd(int* address, int incr) { ... }
그리고 target location의 값을 간단히 읽어서 target의 expected value를 계산할 수 있습니다. 그리고 메모리에 write하고자하는 값은 읽은 값에 myAtomicAdd로 전달된 incr 값을 더한 값으로 정의할 수 있습니다.
이렇게 구한 값들을 사용하여 atomicCAS를 호출할 수 있습니다.
__device__ int myAtomicAdd(int* address, int incr) { // Create an initial guess for the value stored at *address int guess = *address; int oldValue = atomicCAS(address, guess, guess + incr); ... }
위의 myAtomicAdd 함수는 이미 atomic addition을 수행할 수 있습니다. 하지만, atomicCAS가 수행될 때 expected 값이 주소에 저장된 값과 일치하는 경우에만 이 작업이 성공합니다. target location은 여러 스레드에 의해 공유되기 때문에, 다른 스레드가 address의 값을 수정할 수 있습니다. 이러한 경우에는 현재 값과 expected value가 다르기 때문에 atomicCAS는 실패합니다.
이러한 실패는 atomicAdd가 리턴하는 값이 expected value와 다르다는 것을 체크하여 확인할 수 있습니다. 이 정보를 사용하여 myAtomicAdd는 성공했는지 체크하고, atomicCAS가 성공할 때까지 compare-and-swap을 루프에서 계속해서 시도하도록 합니다.
__device__ int myAtomicAdd(int* address, int incr) { // Create an initial guess for the value stored at *address int guess = *address; int oldValue = atomicCAS(address, guess, guess + incr); // Loop while the quess is incorrect while (oldValue != guess) { guess = oldValue; oldValue = atomicCAS(address, guess, guess + incr); } return oldValue; }
전체 코드는 아래 링크에서 확인하실 수 있습니다.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
위 커널을 128개의 스레드를 갖는 4개의 블록으로 configuration하여 실행하면 다음의 결과를 얻을 수 있습니다. 512개의 스레드에 의해서 결과값은 512가 됩니다.

Build-In CUDA Atomic Functions
CUDA는 여러 atomic 함수들을 지원합니다. 지원되는 atomic 함수들은 compute capability에 따라서 조금씩 다릅니다.
atomic function는 compute capability 1.1부터 지원되었고, 여기에서는 global memory의 32-bit 값을 조작하는 함수들에 액세스할 수 있습니다. shared memory에서 32-bit의 값을 조작하는 것과 global memory에서 64-bit의 값을 조작하는 것은 compute capability 1.2부터 지원됩니다. shared memory에서 64-bit값에 대한 조작은 compute capability 2.0부터 지원됩니다.
다음은 CUDA에서 지원하는 atomic 함수들입니다.

The Cost of Atomic Operations
atomic 함수는 매우 유용하고 몇몇 어플리케이션에서 필수적이나, 여기에는 상당한 성능에 대한 cost를 수반할 수 있습니다. 성능에 영향을 미치는 몇 가지 요인들은 다음과 같습니다.
- global memory나 shared memory에서 atomic operation을 수행할 때, 한 가지 보장되는 것은 atomic operation에 의한 변화가 모든 스레드에 즉시 visible하다는 것입니다. 그러므로 최소한의 atomic instruction은 저장된 현재 값을 읽기 위해서 캐시를 사용하지 않고 global memory나 shared memory로 이동합니다. 만약 atomic operation이 성공하면 원하는 값은 global 이나 shared memory에 write되어야 합니다.
- 공유된 위치에 대한 atomic access가 충돌하는 것은 myAtomicAdd 커널의 루프를 두 번 이상 반복하는 것과 동일하게 conflicting thread에 의해서 또 다시 시도된다는 것을 의미합니다. 내장된 atomic function이 어떻게 구현되는지에 대한 정보는 제한적이지만, 위에서 구현한 커스텀 atomic operation에서는 확실합니다. 만약 I/O 오버헤드가 발생하는 동안 어플리케이션이 반복적으로 루프되면 성능이 저하됩니다.
- 동일한 warp에서 스레드들이 다른 명령어를 수행할 때, warp execution은 serialization됩니다. 만약 한 warp에서 여러 스레드들이 동일한 메모리 위치에 atomic operation을 실행하면 서로 충돌하는 것과 같은 유사한 현상이 발생합니다. 오직 하나의 스레드의 atomic operation만이 성공하기 때문에 다른 명령들은 재시도됩니다.
간단한 예제로 실험해보도록 하겠습니다. 전체 코드는 아래 링크를 참조해주세요.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
위 코드를 통해서 atomic operation과 unsafe accesses간의 동작과 성능을 비교해보도록 하겠습니다. 사용되는 커널은 다음과 같습니다.
__global__ void atomics(int* shared_var, int* values_read, int N, int iters) { int tid = blockDim.x * blockIdx.x + threadIdx.x; if (tid > N) return; values_read[tid] = atomicAdd(shared_var, 1); for (int i = 0; i < iters; i++) atomicAdd(shared_var, 1); } __global__ void unsafe(int* shared_var, int* values_read, int N, int iters) { int tid = blockDim.x * blockIdx.x + threadIdx.x; if (tid > N) return; int old = *shared_var; *shared_var = old + 1; values_read[tid] = old; for (int i = 0; i < iters; i++) { int old = *shared_var; *shared_var = old + 1; } }
각 커널에서 각 스레드는 먼저 입력 배열에 저장된 이전 값을 저장하고, shared_var가 가리키는 메모리의 값을 1 증가시킵니다. 그리고 정해진 반복 횟수만큼 shared_var 위치에 저장된 값을 1씩 증가시킵니다.
그리고, 커널이 다 수행되고 나면 old값이 저장된 배열의 값들과 수행 시간을 비교합니다.
위 코드를 컴파일 후 실행하면 다음의 출력을 확인하실 수 있습니다.

성능면의 차이는 명백하게 드러납니다. atomic 커널은 unsafe 커널보다 약 10배정도 느립니다. 하지만 마지막 결과를 보면 덧셈 수행이 unsafe에서 완전히 수행되지 않은 것을 볼 수 있습니다. 이는 unsafe 커널은 global memory에서 동작하여 값을 덮어쓰기 때문입니다.
Limiting the Performance Cost of Atomic Operations
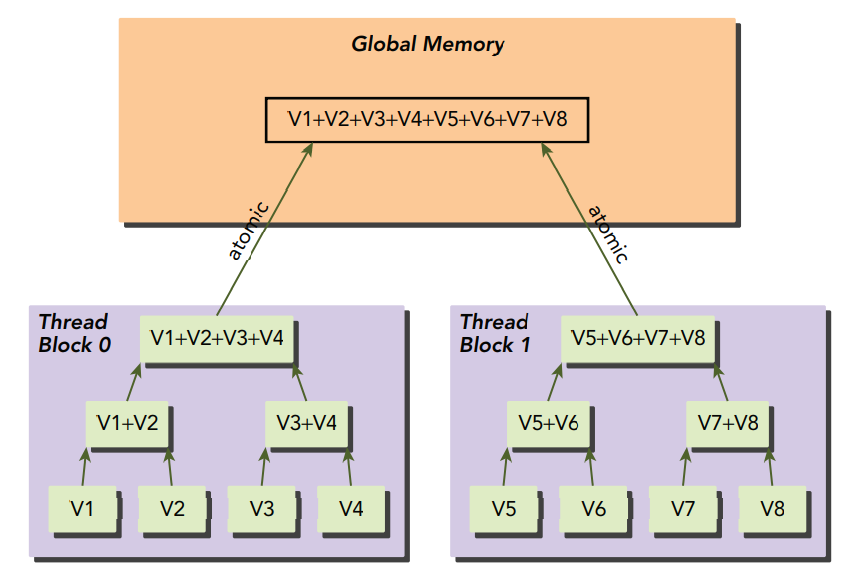
다행히, atomic operations가 필요할 때 성능 하락 폭을 감소시킬 수 있는 기법이 있습니다. 바로 global atomic operations를 local step으로 나누어 각 스텝에서 동일한 스레드 블록에서의 스레드로부터 중간 결과값을 생성하도록 하는 것입니다. 이는 local이며, lower-latency 리소스를 사용하여 각 스레드 블록으로부터의 부분 결과를 생성하도록 합니다. 그리고 마지막에 atomic operations를 사용하여 부분 결과들을 마지막 결과에 합해줍니다.
Atomic Floating-Point Support
atomic function은 거의 대부분이 int 타입(int, unsigned int, unsigned long long int)에 대해서만 선언되어 있습니다. 모든 atomic function 중에서 오직 atomicExch와 atomicAdd만이 single-precision floating-point(단정밀도 부동소수점) 값을 지원합니다. 배정밀도를 지원하는 atomic function은 없습니다. 다행히, 만약 스레드들이 공유하는 부동소수점 변수 액세스를 관리해야한다면 커스텀 floating-point atomic operation을 구현할 수 있는 방법이 있습니다.
이 방법은 부동소수점 값의 raw bit를 지원되는 타입의 변수에 저장하고, 해당 타입을 사용하여 atomic CAS operation을 실행하는 것입니다.
예를 들어, 다음의 커널 함수를 살펴보겠습니다. 아래의 myAtomicAdd는 단정밀도 부동소수점 수에 대해 atomicAdd를 수행합니다.
__device__ float myAtomicAdd(float *address, float incr) { // Convert address to point to a supported type of the same size unsigned int* typedAddress = (unsigned int*)address; // Stored the expected and desired float values as an unsigned int float currentVal = *address; unsigned int expected = __float2uint_rn(currentVal); unsigned int desired = __float2uint_rn(currentVal + incr); int oldIntValue = atomicCAS(typedAddress, expected, desired); while (oldIntValue != expected) { expected = oldIntValue; /* Convert the value read from typedAddress to a float, increment, * and then convert back to an unsigned int */ desired = __float2uint_rn(__uint2float_rn(oldIntValue) + incr); oldIntValue = atomicCAS(typedAddress, expected, desired); } return __uint2float_rn(oldIntValue); }
이 커널은 위에서 살펴본 int버전의 myAtomicAdd와 유사합니다. 큰 차이점은 atomicCAS에 전달되는 값과 atomicCAS로부터 반환되는 값의 변환이 이루어진다는 것이며, 이 변환은 CUDA에서 제공되는 유틸리티 함수를 사용하여 변환됩니다.
__float2uint_rn은 float 타입의 값을 동일한 비트를 포함하는 unsigned int로 변환하고, __uint2float_rn은 unsigned int의 값을 다시 float로 변환합니다.
Summary
'NVIDIA > CUDA' 카테고리의 다른 글
| CUDA C/C++ 기초 - (2) (0) | 2022.06.13 |
|---|---|
| CUDA C/C++ 기초 - (1) (2) | 2022.06.10 |
| CUDA Instructions (1) (0) | 2022.01.26 |
| Streams and Events (3) - Kernel and Data Transfer, Stream Callback (0) | 2022.01.25 |
| Streams and Events (2) - Concurrent Kernels (0) | 2022.01.24 |




댓글