References
- Fluent Python
Contents
- Attribute Descriptors
- Overriding Descriptor
- Non-Overriding Descriptor
이번 포스팅은 지난 포스팅에 이어서 설명되는 부분들이 꽤 있습니다. 이점 유의 바랍니다.. !
디스크립터(descriptor)를 사용하면 여러 속성에 대한 동일한 접근 로직을 재사용할 수 있습니다. 예를 들어, 장고와 SQL Alchemy의 ORM(object-relational mapping)에 있는 필드는 디스크립터로 구현되어 있어서, 데이터베이스 레코드의 필드에 들어 있는 데이터를 파이썬 객체 속성으로 상호 변환할 수 있게 해줍니다.
디스크립터는 __get__(), __set__(), __delete__() 메소드로 구현된 프로토콜을 구현하는 클래스입니다. property 클래스는 디스크립터 프로토콜을 완벽히 구현합니다. 프로토콜과 마찬가지로 일부만 구현해도 됩니다. 사실 우리가 보는 대부분의 디스크립터는 __get__()과 __set__() 메소드만 구현하며, 이 메소드들 중 하나만 구현하는 디스크립터도 많습니다.
디스크립터는 파이썬의 독특한 특징으로서, 어플리케이션 수준뿐만 아니라 언어의 기반 구조에도 적용되어 있습니다. 프로퍼티 외에도 메소드 및 @classmethod와 @staticmethod 데코레이터가 디스크립터를 활용하는 파이썬 기능입니다.
Descriptor Example: Attribute Validation
지난 포스팅에서 언급한 것처럼, 프로퍼티 팩토리를 사용하면 함수형 프로그래밍 패턴을 적용함으로써 똑같은 getter와 setter를 반복해서 구현할 필요가 없습니다. 프로퍼티 함수는 고차 함수(higher-function)로서 일련의 접근자 함수를 매개변수화하고 storage_name과 같은 환경 변수를 클로저에 담아서 사용자 정의 프로퍼티 객체를 생성합니다. 이와 동일한 문제를 객체지향 방식으로 해결한 것이 디스크립터 클래스입니다.
이번 포스팅에서는 지난 포스팅의 LineItem 예제를 이용해서 quantity() 프로퍼티 팩토리를 Quantity 디스크립터 클래스로 리팩토링합니다.
LineItem #3: A Simple Descriptor
__get__(), __set__(), __delete__() 메소드를 구현하는 클래스가 디스크립터입니다. 디스크립터는 클래스의 객체를 다른 클래스의 클래스 속성으로 정의해서 사용합니다.
여기서 우리는 Quantity 디스크립터 클래스를 생성하고, LineItem 클래스는 두 개의 Quantity 객체를 사용합니다. 하나는 weight 속성을, 다른 하나는 price 속성을 관리하기 위해 사용합니다. 다음 그림을 보면 조금 더 이해하기 쉬울 것입니다.

위 그림에서 weight라는 단어가 두 번 나오는 것에 주의합니다. 실제로 weight라는 이름의 두 개의 속성이 따로 존재합니다. 하나는 LineItem의 클래스 속성이며, 다른 하나는 각각의 LineItem 객체(인스턴스)에 존재하는 객체 속성입니다. 이는 price에도 동일하게 적용됩니다.
먼저 다음의 용어부터 정리하고 이어서 설명하도록 하겠습니다.
- Descriptor Class :
디스크립터 프로토콜을 구현하는 클래스. 뒤에서 살펴볼 Quantity 클래스가 디스크립터 클래스입니다. - Managed Class (관리대상 클래스) :
디스크립터 객체를 클래스 속성으로 선언하는 클래스. LineItem 클래스가 관리대상 클래스가 됩니다. - Descriptor Instance :
관리 대상 클래스의 클래스 속성으로 선언된, 디스크립터 클래스의 객체(인스턴스). 위 그림에서 각각의 디스크립터 객체는 밑줄 친 이름을 가진 composition arrow로 표현됩니다(UML에서 밑줄 친 속성은 클래스 속성을 나타냄). 디스크립터 객체를 가진 LineItem 클래스 쪽에 검은 마름모가 붙습니다. - Managed Instance :
관리 대상 클래스의 객체(인스턴스). 이 예제에서는 LineItem 클래스의 객체들이 관리 대상 객체가 됩니다. - Storage Attribute (저장소 속성) :
관리 대상 객체 안의 관리 대상 속성값을 담을 속성. 위 그림에서 LineItem 객체의 weight와 price 속성이 저장소 속성입니다. 이들은 디스크립터 객체와는 별개의 속성으로, 항상 클래스 속성입니다. - Managed Attribute (관리대상 속성) :
디스크립터 객체에 의해 관리되는 관리 대상 클래스 안의 public 속성으로, 이 속성의 값은 저장소 속성에 저장됩니다. 즉, 디스크립터 객체와 저장소 속성이 관리 대상 속성에 대한 기반을 제공합니다.
Quantity 객체는 LineItem의 클래스 속성이라는 점을 명심해야 하며 다음 그림은 이를 시각적으로 표현해줍니다.
이제 코드를 살펴보도록 하겠습니다. 아래의 코드들은 Quantity 클래스 및 두 개의 Quantity 객체를 사용하는 LineItem 클래스를 보여줍니다.
# 디스크립터는 프로토콜에 기반한 기능. 구현하기 위해 상속할 필요가 없음 class Quantity: def __init__(self, storage_name): # 관리대상 객체에서 값을 보관할 속성의 이름을 받음 self.storage_name = storage_name # 관리대상 속성에 값을 할당할 때 __set__()이 호출됨 # 여기서 self는 디스크립터 객체, instance는 관리대상 객체(LineItem 객체), value는 할당할 값 def __set__(self, instance, value): if value > 0: # 관리대상 객체의 __dict__을 직접 처리해야 함 # setattr() 함수를 사용하면 또 다시 __set__() 메소드가 호출되어, 무한재귀가 됨 instance.__dict__[self.storage_name] = value else: raise ValueError('value must be > 0') # 관리대상 속성의 이름이 storage_name과 다를 수 있으므로 __get__을 구현할 필요가 있음 def __get__(self, instance, owner): return instance.__dict__[self.storage_name]
__get__() 의 구현은 유저가 다음과 같이 작성할 수도 있기 때문에 필요합니다.
class House: rooms = Quantity('number_of_rooms')
House 클래스에서 관리대상 속성은 rooms 이지만, 저장소 속성은 number_of_rooms 입니다.
__get__() 메소드는 self, instance, owner라는 3개의 인수를 받습니다. owner 인수는 관리대상 클래스(여기서는 LineItem)의 참조이며, 만약 디스크립터가 클래스 속성을 탐색하는 것을 지원하길 원한다면 유용하게 사용할 수 있습니다.
만약 LineItem.weight와 같이 클래스를 통해 weight와 같은 관리대상 속성을 가져올 때는, 디스크립터의 __get__() 메소드는 instance 인수에 None을 받습니다.
만약 사용자가 내부 조사(introspection)나 다른 메타프로그래밍 기법을 사용할 수 있도록 지원하려면, 클래스를 통해 관리대상 속성에 접근할 때 __get__() 메소드가 디스크립터 객체를 반환하게 하는 것이 좋습니다. 이를 위해서 __get__을 다음과 같이 구현할 수 있습니다.
def __get__(self, instance, owner): if instance is None: return self else: return instance.__dict__[self.storage_name]
다음은 LineItem 클래스입니다.
class LineItem: # 디스크립터 객체를 각 속성에 바인딩 weight = Quantity('weight') price = Quantity('price') def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price
이렇게 구현한 클래스는 다음과 같이 의도한 대로 동작하며, 0이나 음수의 달러에 파는 것을 방지합니다.
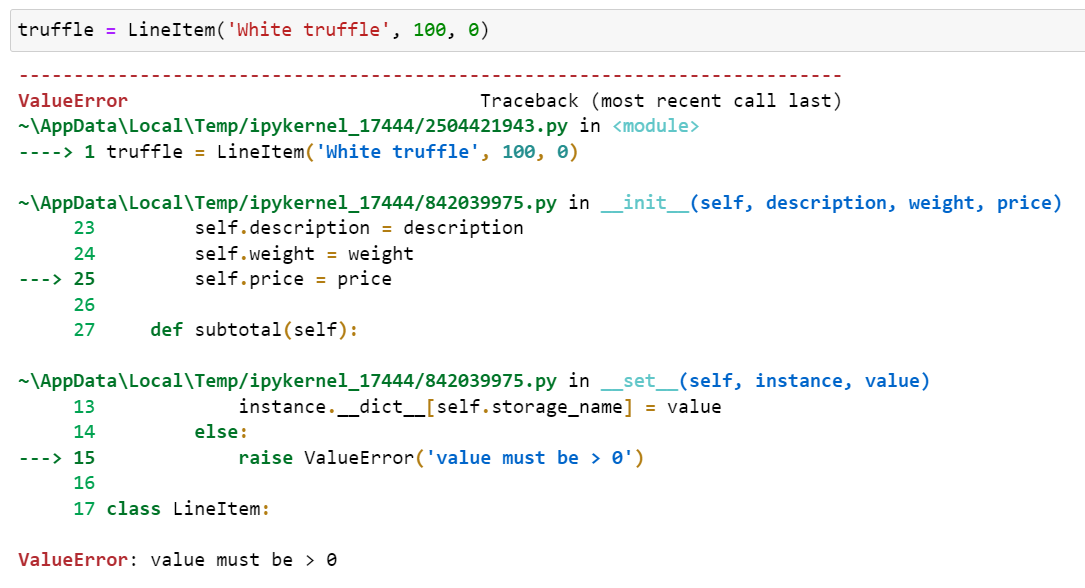
각각의 관리대상 속성을 디스크립터 객체 자체에 저장하고 싶은 생각이 들 수 있지만, 이는 잘못된 방법입니다.
즉, __set__() 메소드 내에서, 다음의 코드를
instance.__dict__[self.storage_name] = value다음과 같이 바꾸려고 시도할 수 있습니다.
self.__dict__[self.storage_name] = value그러나 이 코드는 잘못되었습니다. 그 이유를 이해하려면 __set__()에 전달되는 앞의 두 인수 self와 instance의 의미에 대해서 생각해보면 됩니다. 여기서 self는 디스크립터 객체로서, 관리대상 클래스의 클래스 속성입니다. 메모리에 수천 개의 LineItem 객체가 있더라도 디스크립터 객체는 LineItem.weight와 LineItem.price, 단 두 개밖에 없습니다. 디스크립터 객체에 저장하는 모든 것은 LineItem 클래스 속성이 되어, 모든 LineItem 객체가 공유합니다.
위에서 정의한 클래스들의 단점은 관리대상 클래스 본체에 디스크립터 객체를 생성할 때 속성명을 반복해야 한다는 것입니다. LineItem 클래스 속성을 다음과 같이 선언할 수 있다면 훨씬 더 좋을 것입니다.
class LineItem: weight = Quantity() price = Qunatity() # .. 나머지 코드 생략
문제는 변수가 존재하기도 전에 할당문의 오른쪽이 실행된다는 것입니다. 디스크립터 객체를 생성하기 위해 Quantity() 표현식이 평가되는데, 이때 Quantity 클래스 안에 있는 코드에서는 디스크립터 객체를 어떤 이름의 변수(예를 들면 weight나 price)에 바인딩해야 할지 알 수 없다는 것입니다.
위의 구현으로는 각각의 Quantity 객체에 속성명을 명시적으로 지정할 수 밖에 없습니다. 이는 불편할 뿐만 아니라 위험하기도 합니다. 프로그래머가 코드를 복사해서 붙여 넣고 변수명을 바꾸지 않아서, price = Quantity('weight')와 같이 되어 있다고 가정해봅시다. 이 프로그램은 엉뚱하게도 price의 값을 설정할 때마다 weight의 값을 변경하게 됩니다.
다행히, 디스크립터 프로토콜은 이제 __set_name__() 스페셜 메소드를 지원합니다. 이에 대해서 알아보도록 하겠습니다.
LineItem #4: Automatic Storage Attribute Names
디스크립터를 선언할 때 속성명을 반복해서 입력하지 않기 위해 __set_name__()을 구현하여 각 Quantity 인스턴스에 storage_name을 생성해보도록 하겠습니다. __set_name__() 스페셜 메소드는 파이썬 3.6에서 디스크립터 프로토콜에 추가되었습니다. 인터프리터는 디스크립터가 이 메소드를 구현했다면, 클래스 바디에서 찾은 각 디스크립터에 대해 __set_name__()을 호출합니다.
아래 코드를 보면 이제 디스크립터 클래스는 __init__()이 더 이상 필요하지 않습니다. 대신 __set_name__()이 저장소 속성의 이름을 저장합니다.
class Quantity: # self는 디스크립터 인스턴스, owner는 관리대상 클래스 # name은 owner의 클래스 body에서 이 디스크립터 인스턴스가 할당된 owner의 속성 이름 def __set_name__(self, owner, name): self.storage_name = name # self.storage_name에 저장소 이름을 저장 def __set__(self, instance, value): # __set__은 이전과 동일 if value > 0: instance.__dict__[self.storage_name] = value else: msg = f'{self.storage_name} must be > 0' raise ValueError(msg) # 이제 저장소 속성의 이름이 관리대상 속성의 이름과 같으므로 __get__을 구현할 필요가 없음 # product.price 표현식은 LineItem 인스턴스로부터 직접 price 속성을 얻음 class LineItem: # 이제 관리대상 속성의 이름을 인수로 전달할 필요가 없음 weight = Quantity() price = Quantity() def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price
위의 코드를 보면 몇 가지 속성을 관리하기 위한 코드가 많다고 생각할 수 있지만, 디스크립터 로직이 이제 별도의 코드 단위인 Quantity 클래스로 추상화된다는 것을 알 수 있습니다. 일반적으로 디스크립터는 디스크립터가 사용되는 동일한 모듈에 정의되지 않고 어플리케이션 전체에서 사용하도록 분리된 유틸리티 모듈에 정의됩니다.
이를 염두에 두고, 다음과 같이 사용하는 것이 일반적인 디스크립터의 사용 방법입니다.
from model_v4c as model class LineItem: weight = model.Quantity() price = model.Quantity() def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price
만약에 장고에 익숙하시다면 위의 코드가 모델 정의와 매우 흡사하다는 것을 알 수 있습니다. 우연이 아니고, 장고 모델 필드는 디스크립터입니다.
디스크립터는 클래스로 구현되기 때문에 상속을 활용하여 새로운 디스크립터에 대해 가지고 있는 코드 일부를 재사용할 수 있습니다. 이에 대해 알아보도록 하겠습니다.
LineItem #5: New Descriptor Type
실수로 LineItem 객체 하나가 빈 description 속성으로 생성되어 주문을 완료할 수 없게 되었다고 가정해봅시다. 이 문제를 방지하기 위해 새로운 디스크립터 NonBlack를 생성하려고 합니다. NonBlack를 설계하다보니 검증 로직을 제외하고는 Quantity 디스크립터와 아주 비슷하다는 것을 알게 됩니다.
따라서 리팩토링을 통해 __set__() 메소드를 재정의하는 추상 클래스인 Validated를 생성하고, __set__() 메소드는 서브클래스에서 구현해야 하는 validate() 메소드를 호출합니다.
그런 다음 Validated를 상속하고 validate 메소드를 코딩하여 Quantity를 다시 작성하고 NonBlank를 구현합니다.
Validated, Quantity, NonBlank 간의 관계는 'Design Patterns'에 설명한 Template Method 방법을 응용한 것입니다.
다음 코드에서 Validated.__set__()은 템플릿 메소드이고 self.validate는 abstract operation입니다.
import abc class Validated(abc.ABC): def __set_name__(self, owner, name): self.storage_name = name def __set__(self, instance, value): value = self.validate(self.storage_name, value) # validate 메소드에 검증을 위임 instance.__dict__[self.storage_name] = value # 반환된 value로 값을 업데이트 @abc.abstractclassmethod def validate(self, name, value): # 추상 메소드. 이는 템플릿 메소드이다 """return validated value or raise ValueError"""
구체적인 Validated의 서브클래스, Quantity와 NonBlack의 구현은 다음과 같습니다.
class Quantity(Validated): """a number greated than zero""" def validate(self, name, value): if value <= 0: raise ValueError(f'{name} must be > 0') return value class NonBlank(Validated): """a string with at least one non-space character""" def validate(self, name, value): value = value.strip() if len(value) == 0: raise ValueError(f'{name} cannot be blank') return value
이 클래스의 사용자는 이러한 내부 처리 과정을 알 필요가 없습니다. 중요한 것은 Quantity와 NonBlank 디스크립터 클래스를 사용해서 객체 속성을 자동으로 검증할 수 있다는 것입니다. 이 디스크립터들을 사용한 LineItem 클래스의 구현은 다음과 같습니다. 디스크립터는 model.py에 구현되어 있다고 가정합니다.
import model class LineItem: description = model.NonBlank() weight = model.Quantity() price = model.Quantity() def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price
지금까지 살펴본 LineItem 예제는 데이터 속성을 관리하는 디스크립터의 전형적인 사용방법을 보여줍니다. 이러한 디스크립터는 오버라이딩 디스크립터(overriding descriptor)라고도 합니다. 디스크립터의 __set__() 메소드가 관리대상 객체 안에 있는 동일한 이름의 속성 설정을 오버라이드하기 때문입니다. 그러나 오버라이드하지 않는 논-오버라이딩(non-overriding) 디스크립터도 있습니다.
Overriding Versus Non-Overriding Descriptors
파이썬이 속성을 처리하는 방식에는 커다란 비대칭성이 있음에 주의해야 합니다. 일반적으로 객체(인스턴스)를 통해 속성을 읽으면 객체에 정의된 속성을 반환하지만, 객체에 그 속성이 없으면 클래스 속성을 읽습니다. 반면에, 일반적으로 객체의 속성에 값을 할당하면 객체 안에 그 속성을 만들고 클래스에는 전혀 영향을 미치지 않습니다.
이런 비대칭성은 디스크립터에도 영향을 미쳐, __set__() 메소드의 정의 여부에 따라 두 가지 범주의 디스크립터를 생성합니다. __set__() 메소드가 존재한다면 클래스는 오버라이딩 디스크립터이며, 그렇지 않다면 논-오버라이딩 디스크립터입니다.
서로 다른 동작 방식을 관찰하려면 몇 가지 클래스가 필요하므로, 다음의 예제 코드를 testbed로 사용하여 디스크립터의 동작을 살펴보겠습니다.
### auxiliary function for display only ### def cls_name(obj_or_cls): cls = type(obj_or_cls) if cls is type: cls = obj_or_cls return cls.__name__.split('.')[-1] def display(obj): cls = type(obj) if cls is type: return '<class {}>'.format(obj.__name__) elif cls in [type(None), int]: return repr(obj) else: return '<{} object>'.format(cls_name(obj)) def print_args(name, *args): pseudo_args = ', '.join(display(x) for x in args) print('-> {}.__{}__({})'.format(cls_name(args[0]), name, pseudo_args)) ### essential classes for this example ### class Overriding: """a.k.a. data descriptor or enforced descriptor""" def __get__(self, instance, owner): print_args('get', self, instance, owner) def __set__(self, instance, value): print_args('set', self, instance, value) class OverridingNoGet: """an overriding descriptor without ``__get__``""" def __set__(self, instance, value): print_args('set', self, instance, value) class NonOverriding: """a.k.a. non-data or shadowable descriptor""" def __get__(self, instance, owner): print_args('get', self, instance, owner) class Managed: over = Overriding() over_no_get = OverridingNoGet() non_over = NonOverriding() def spam(self): print('-> Managed.spam({})'.format(display(self)))
아래에서 Managed 클래스와 관련된 속성을 읽고 쓰는 과정을 살펴보면서, 각기 다른 디스크립터에 대해 자세히 알아보겠습니다.
Overriding Descriptors
__set__() 메소드를 구현하는 디스크립터를 오버라이딩 디스크립터라고 합니다. 비록 클래스 속성이기는 하지만, __set__() 메소드를 구현하는 디스크립터는 객체 속성에 할당하려는 시도를 가로채기 때문입니다. 프로퍼티도 오버라이딩 디스크립터라고 할 수 있습니다. setter 함수를 제공하지 않더라도, property 클래스에서 기본적으로 제공하는 __set__() 메소드가 읽기 전용 속성임을 알려주기 위해 AttributeError를 발생시킵니다. 위의 코드를 이용해서 오버라이딩 디스크립터를 실험한 결과는 다음과 같습니다.

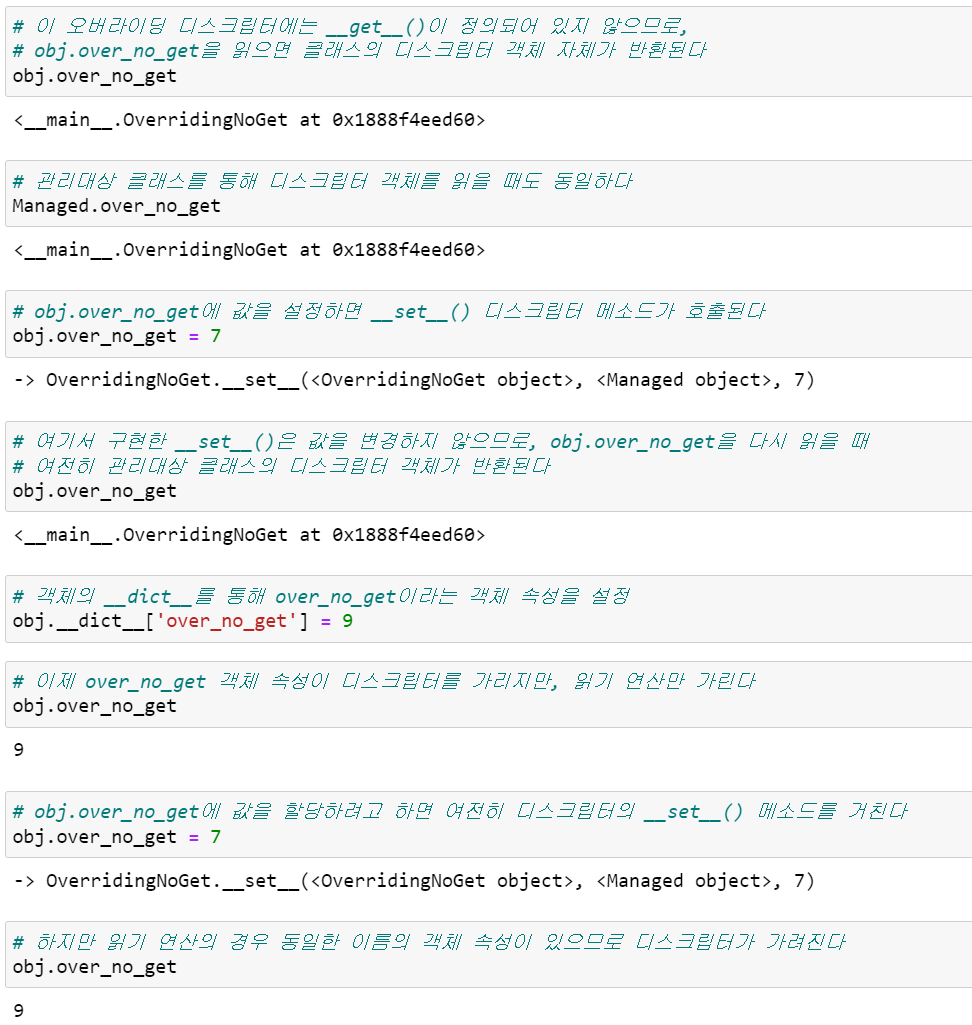
Overriding Descriptor Without __get__()
일반적으로 오버라이딩 디스크립터는 __set__()과 __get__() 메소드를 모두 구현하지만, __set__() 메소드만 오버라이드할 수 있습니다. 이때 저장 연산만 디스크립터가 처리합니다. 객체를 통해 디스크립터를 확인해보면 읽기 접근을 처리하는 __get__() 메소드가 없으므로 디스크립터 객체 자체가 반환됩니다. 객체의 __dict__에 직접 접근해서 새로운 값을 가진 동일한 이름의 객체 속성을 생성하더라도, 이후의 쓰기 접근은 __set__() 메소드가 가로채지만, 그 속성을 읽을 때는 디스크립터 객체가 아니라 새로운 값을 그대로 반환합니다.
즉, 읽기 연산의 경우에만 객체 속성이 디스크립터를 가립니다. 아래 실험을 살펴보겠습니다.
Non-overriding Descriptor
디스크립터가 __set__() 메소드를 구현하지 않으면 논-오버라이딩 디스크립터가 됩니다. 동일한 이름의 객체 속성을 설정하면 디스크립터를 가리므로, 그 객체에는 디스크립터가 작동하지 않습니다. 메소드와 @functools.cached_property는 논-오버라이딩 디스크립터로 구현됩니다.
아래 실험은 논-오버라이딩 디스크립터의 동작을 보여줍니다.

앞서 나온 예제에서, 디스크립터와 동일한 이름을 가진 객체 속성에 값을 할당하는 여러 연산이 디스크립터의 __set__() 메소드 존재 여부에 따라 결과가 달라짐을 알 수 있습니다.
클래스 안에 속성을 설정하는 것은 이 클래스에 연결된 디스크립터가 통제할 수 없습니다. 특히 아래에서 설명하는 것처럼 클래스 속성에 값을 할당함으로써 디스크립터 객체 자신이 무용지물이 될 수 있습니다.
Overwriting a Descriptor in the Class
오버라이딩 디스크립터든 논-오버라이딩 디스크립터든 클래스의 속성에 값을 할당하면 덮어써집니다. 이런 기법을 멍키 패칭이라고 부르지만, 아래 예제 코드에서는 디스크립터가 정수로 바뀌므로, 제대로 동작하기 위해 디스크립터에 의존하는 모든 클래스를 사실상 무용지물로 만듭니다.
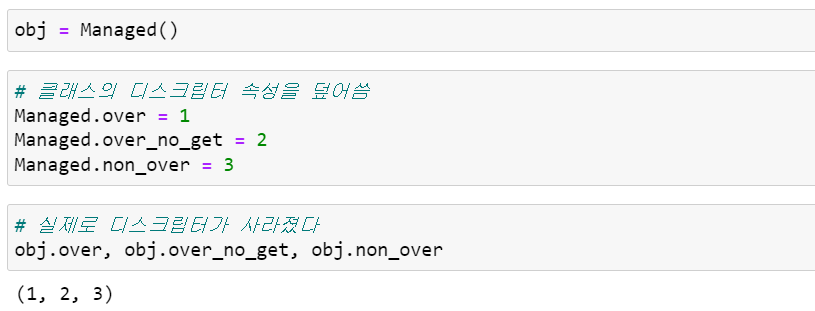
위 예제 코드는 속성의 읽기와 쓰기에 관련된 또 다른 비대칭성을 보여줍니다. 클래스 속성을 읽는 것은 관리대상 클래스에 연결된 디스크립터의 __get__() 메소드에 의해 통제되지만, 클래스 속성에 쓰는 연산은 관리대상 클래스에 연결된 디스크립터의 __set__() 메소드가 통제할 수 없습니다.
클래스 속성에 저장하는 연산을 통제하려면 클래스의 클래스, 즉, 메타클래스에 디스크립터를 연결해야 합니다. 기본적으로 사용자 정의 클래스의 메타클래스는 type이며, type에는 속성을 추가할 수 없습니다.
Methods Are Descriptors
모든 사용자 정의 함수는 __get__() 메소드를 가지고 있어서, 클래스에 연결된 함수는 디스크립터로 동작하기 때문에 클래스 안의 함수는 클래스에 바인딩된 메소드가 됩니다. 아래 예제 코드는 위에서 정의한 Managed 클래스의 spam() 메소드를 읽는 예를 보여줍니다.
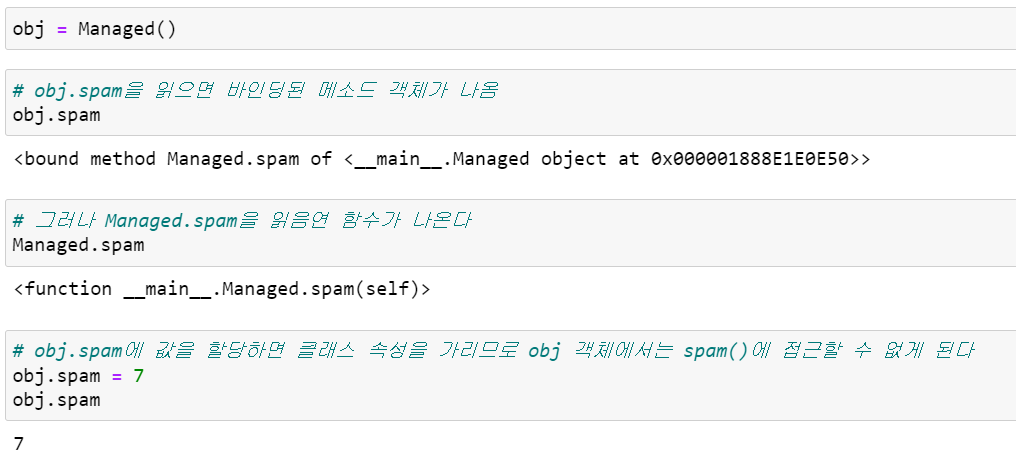
함수는 __set__() 메소드를 구현하지 않으므로, 위 예제의 마지막 행에서 보는 것처럼 함수는 논-오버라이딩 디스크립터입니다.
예제에서 obj.spam과 Managed.Spam이 서로 다른 객체를 반환하는 것에 주의하시길 바랍니다. 디스크립터가 그러하듯이 관리대상 클래스를 통해 접근할 때 함수의 __get__() 메소드는 자기 자신을 반환합니다. 그러나 객체를 통해 함수에 접근할 때는 함수의 __get__() 함수가 바인딩된 메소드 객체를 반환합니다. 메소드는 functools.partial() 함수처럼 관리대상 객체(obj)를 함수의 첫 번째 인수(self)에 바인딩하는 콜러블 객체입니다.
이 메커니즘을 자세히 알아보기 위해 다음의 코드를 살펴보겠습니다.
import collections class Text(collections.UserString): def __repr__(self): return 'Text({!r})'.format(self.data) def reverse(self): return self[::-1]
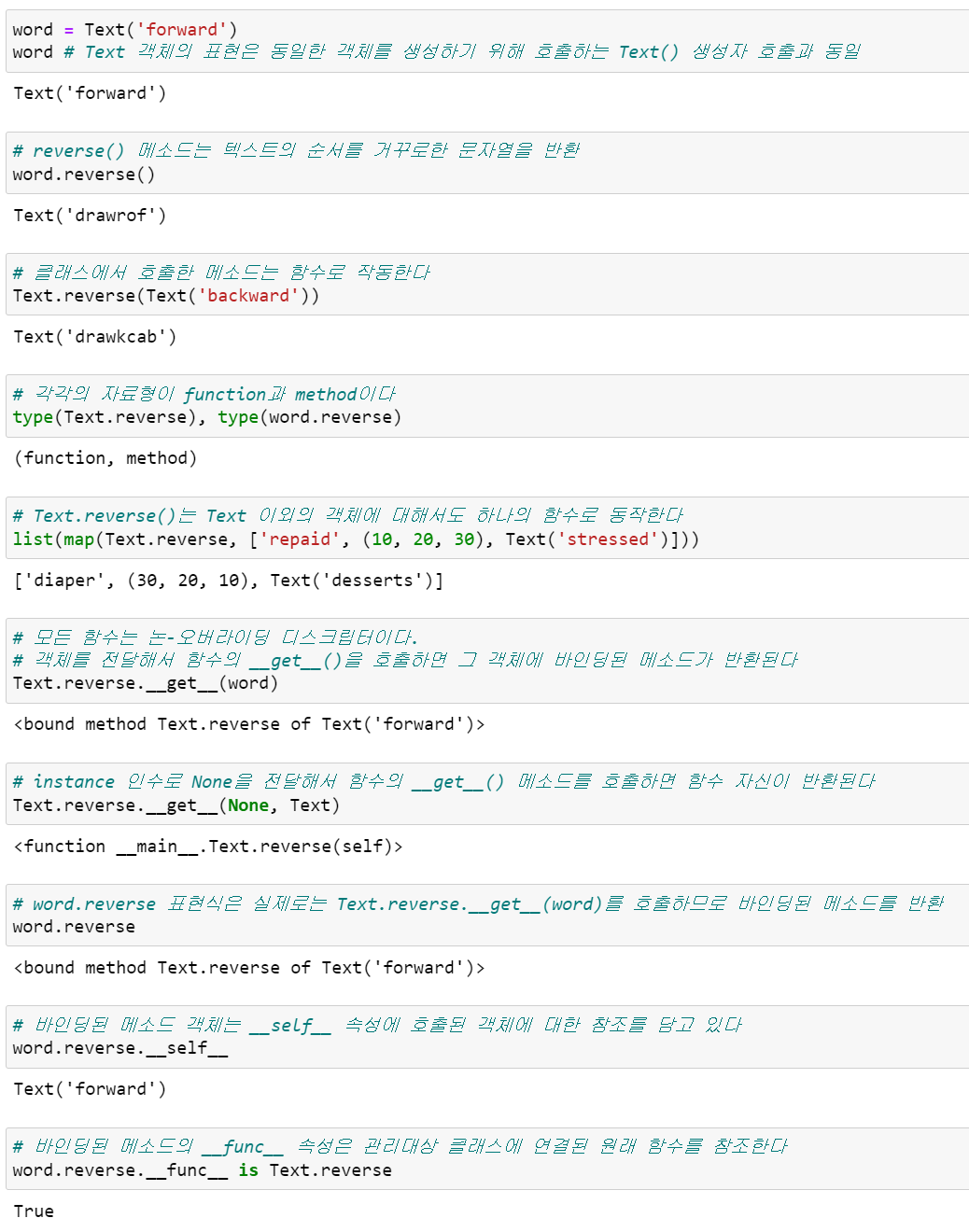
바인딩된 메소드 객체는 호출을 실제로 처리하는 __call__() 메소드도 가지고 있습니다. __call__() 메소드의 __self__ 속성을 첫 번째 인수로 전달해서 __func__ 속성이 ㅊ마조하는 원래 함수를 호출합니다. 전형적인 self 인자는 이런 방식으로 바인딩됩니다.
함수가 바인딩된 메소드로 변환되는 과정은 파이썬 언어의 밑바닥에 디스크립터가 사용되는 방식을 잘 보여줍니다.
Descriptor Usage Tips
지금까지 설명한 디스크립터의 특징과 사용할 때 고려해야할 사항은 다음과 같습니다.
- 코드를 간결하게 작성하기 위해 프로퍼티를 사용하라
property() 내장 함수는 setter 메소드를 정의하지 않는 경우에도 __set__()과 __get__() 메소드를 모두 구현하는 오버라이딩 디스크립터를 생성합니다. 프로퍼티의 기본 __set__() 메소드는 AttributeError 예외를 발생시키므로, 프로퍼티는 읽기 전용 속성을 만들기 위한 가장 간단한 방법입니다. - 읽기 전용 디스크립터는 __set__()을 구현해야 한다
디스크립터 클래스를 이용해서 읽기 전용 속성을 구현하려면 __get__()과 __set__() 메소드를 모두 구현해야 합니다. 그렇지 않으면 객체가 동일한 이름의 속성을 가질 때 디스크립터가 가려집니다. 읽기 전용 속성의 __set__() 메소드는 적절한 메소드를 담아서 AttributeError를 발생시켜야 합니다. - 검증 디스크립터는 __set__()만 사용할 수 있다
검증하기 위해 만들어진 디스크립터에서는 __set__() 메소드만 이용해서 값의 정당성을 검증하고, 값이 정당한 경우 디스크립터 객체명과 동일한 이름의 속성을 __dict__에 직접 설정해야 합니다. 이렇게 하면 디스크립터 객체명과 동일한 이름의 속성을 읽을 때 __get__()을 거치지 않으므로 객체의 속성을 더 빨리 읽을 수 있습니다. - 캐시는 __get__() 에서만 효율적으로 구현할 수 있다
__get__() 메소드만 구현하면 논-오버라이딩 디스크립터가 됩니다. 논-오버라이딩 디스크립터는 값비싼 연산을 수행하고 객체에 있는 동일한 이름이 속성에 결과를 저장해서 캐시할 때 유용하게 사용할 수 있습니다. 동일한 이름의 객체 속성이 디스크립터를 가리므로, 이후에 이 속성을 읽을 때는 디스크립터의 __get__() 메소드를 더 이상 사용하지 않고 __dict__에서 바로 가져옵니다. - 스페셜 메소드 이외의 메소드는 객체 속성에 의해 가려질 수 있다
함수와 메소드는 __get__()만 구현하므로 동일한 이름의 객체 속성에 저장하는 연산은 간섭하지 않습니다. 따라서 my_obj.the_method = 7과 같이 할당하면, 클래스와 다른 객체에는 영향을 미치지 않고 이후에 my_object의 the_method를 읽을 때 7을 반환합니다. 그러나 이런 방식이 스페셜 메소드에 대해서는 동작하지 않습니다. 파이썬 인터프리터는 클래스 자체에 있는 스페셜 메소드를 먼저 검색 합니다. 예를 들어, repr(x)는 x.__class__.__repr__(x)를 호출하므로 x에 정의된 __repr__ 속성은 repr(x)에 영향을 미치지 않습니다. 이와 같은 이유로 객체에 __getattr__이라는 이름의 속성이 존재하더라도 속성에 접근하는 알고리즘에 전혀 영향을 끼치지 못합니다.
스페셜 메소드 이외의 메소드가 객체에 의해 쉽게 오버라이드될 수 있다는 사실 때문에 불안정하고 에러가 발생하기 쉬울 것 같지만 보통 이러한 문제를 겪는 경우는 없습니다. 오히려 직접 통제하지 않는 데이터를 가져와서 속성명으로 사용하면서 동적 속성을 많이 생성하는 경우, 이런 문제를 예상하고 코드에 문제를 야기할 수 있는 동적 속성명을 걸러 내거나 피해가는 방법을 구현해야 합니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] Class Metaprogramming (0) | 2022.04.01 |
|---|---|
| [Python] 동적 속성과 프로퍼티 (0) | 2022.03.30 |
| [Python] Futures (0) | 2022.03.30 |
| [Python] Concurrency Models (0) | 2022.03.29 |
| [Python] 코루틴(Coroutines), yield from (0) | 2022.03.27 |




댓글