References
- Fluent Python
Contents
- threading, multiprocessing, asyncio

Concurrency(동시성)은 한 번에 많은 것을 처리하는 것이고, Parallelism(병렬성)은 한 번에 많은 작업을 수행하는 것입니다. 둘은 같지 않지만, 관련은 있습니다. 동시성는 구조(structure)에 관한 것이고, 병렬성은 실행(execution)에 관한 것입니다. 동시성은 병렬화할 수 있는(반드시 그런 것은 아니지만) 문제를 해결하기 위해 솔루션을 구성하는 방법을 제공합니다.
이번 포스팅에서는 파이썬이 어떻게 한 번에 많은 것들을 처리하는지 알아볼 예정입니다. 여기에는 concurrent(동시) 프로그래밍 또는 parallel(병렬) 프로그래밍이 포함될 수 있습니다.
병렬성(Parallelism)은 동시성(Concurrency)의 특별 케이스라고 할 수 있습니다. 모든 병렬 시스템은 동시성이지만, 모든 동시성 시스템이 병렬인 것은 아닙니다.
먼저 간단한 개념들을 살펴보고, 동시성 프로그래밍을 위한 파이썬의 코어 패키지인 threading, multiprocessing, asyncio에 대해서 살펴보도록 하겠습니다.
A Bit of Jargon
- Concurrency :
다중 pending tasks를 처리하는 기능으로, 한 번에 하나씩 또는 병렬로 처리합니다. 싱글 코어 CPU에서는 pending task의 실행을 인터리브(interleave)하는 OS 스케쥴러를 실행하는 경우 동시성이 가능합니다. 멀티태스팅(multitasking)이라고도 알려져 있습니다. - Parallelism :
동시에 여러 연산을 수행하는 기능. 이는 다중 코어 CPU나 GPU, 또는 클러스터에서는 여러 컴퓨터가 필요합니다. - Process :
실행되는 동안 메모리와 CPU 시간의 일부를 사용하는 컴퓨터 프로그램의 인스턴스. 현대 OS는 다중 프로세스를 동시에 관리할 수 있으며 각 프로세스는 자신만의 private 메모리 공간에 고립되어 있습니다. 프로세스들은 파이프, 소켓 또는 메모리 매핑 파일들을 통해 통신하며, 이들은 Python Objects가 아닌 raw bytes로만 전달될 수 있습니다. 프로세스는 각각 자식 프로세스(child process)라고 부르는 하위 프로세스를 생성할 수 있습니다. 이들 또한 서로 고립되어 있습니다. - Thread :
싱글 프로세스에서의 실행 경로(execution path). 프로세스가 실행될 때, 이 프로세스는 싱글(메인) 스레드를 사용합니다. OS API를 사용해서 프로세스는 OS 스케쥴러 덕분에 동시에 수행하는 여러 스레드를 생성할 수 있습니다. 스레드들은 프로세스의 메모리 공간을 공유하며, 이 메모리는 live Python objects를 붙잡고 있습니다. 이것은 스레드 간 통신을 쉽게 해주지만, 하나 이상의 스레드가 동시에 같은 객체를 업데이트할 때 데이터 충돌이 발생할 수 있습니다. - Contention :
제한된 리소스에 대한 경쟁. 리소스 경쟁(resource contention)은 다중 프로세스 또는 스레드가 공유 리소스(lock or storage)에 액세스하려고 할 때 발생합니다. - Lock :
스레드가 작업을 조정 및 동기화하고, 데이터 손상을 방지하는 데 사용할 수 있는 객체. 공유하는 데이터 구조를 업데이트하는 동안 스레드는 연관된 락(lock)을 홀드해야 합니다. 이는 다른 스레드가 동일한 데이터 구조에 액세스하기 전에 연관된 락이 해제될 때까지 기다리도록 합니다. 락의 가장 간단한 타입은 뮤텍스(mutex)라고도 합니다.
위에서 살펴본 개념들은 파이썬 프로그래밍에 다음과 같이 적용됩니다.
- 파이썬 인터프리터의 각 인스턴스는 프로세스입니다. multiprocessing 또는 concurrent.futures 라이브러리를 사용하면 파이썬 프로세스를 추가할 수 있습니다. 파이썬의 하위 프로세스 라이브러리는 외부(external) 프로그램을 작성하는 데 사용되는 언어에 관계없이 프로세스를 시작하여 외부 프로그램을 실행하도록 설계되었습니다.
- 파이썬 인터프리터는 단일 스레드를 사용하여 사용자 프로그램과 메모리 가비지 콜렉터를 실행합니다. threading 또는 concurrent.futures 라이브러리를 사용하여 파이썬 스레드를 추가할 수 있습니다.
- 참조 카운트(reference counts) 및 기타 내부 인터프리터의 상태에 대한 액세스는 GIL(Global Interpreter Lock)에 의해 제어됩니다. 오직 한 번에 하나의 파이썬 스레드만 GIL을 홀드할 수 있습니다. 이는 CPU 코어 수에 관계없이 언제든지 하나의 파이썬 스레드만 실행할 수 있음을 의미합니다.
- 파이썬 스레드가 GIL을 무한히 홀드하는 것을 방지하기 위해 파이썬의 바이트코드(bytecode) 인터프리터는 기본적으로 현재 파이썬 스레드를 5ms마다 일지 중지하고 GIL을 해제합니다. 그런 다음 스레드는 GIL을 다시 얻기 위해 시도할 수 있지만, 다른 대기 중인 스레드가 있는 경우 OS 스케쥴러는 그 중 하나를 선택하여 계속 진행할 수 있습니다.
- 파이썬 코드를 작성할 때, GIL을 제어할 수 없습니다. 그러나 내장 함수 또는 C로 작성된 익스텐션 또는 Python/C API 레벨에서 상호작용하는 모든 언어는 time-consuming tasks를 수행하는 동안 GIL을 해제할 수 있습니다.
- syscall을 하는 모든 파이썬 표준 라이브러리는 GIL를 해제합니다. 여기에는 disk I/O, network I/O, time.sleep()을 수행하는 모든 함수가 포함됩니다. Numpy/SciPy 라이브러리에서 CPU 집약적인 많은 함수들과 zlib과 bz2 모듈에서 압축/압축해제 함수 또한 GIL을 해제합니다.
- Python/C 레벨에서 통합되는 익스텐션은 GIL의 영향을 받지 않는 다른 non-Python 스레드를 시작할 수 있습니다. 이러한 GIL-free 스레드는 일반적으로 Python 객체를 변경할 수는 없지만 buffer protocol을 지원하는 array.array나 Numpy 배열에서 읽고 쓸 수 있습니다.
- 파이썬 스레드를 사용한 네트워크 프로그래밍에 대한 GIL의 영향은 비교적으로 작습니다. I/O 기능이 GIL을 해제하고 네트워크에 대한 읽기 및 쓰기에 비해 항상 높은 지연시간(latency)를 가지고 있기 때문입니다. 결과적으로 각각의 스레드는 대기하는 데 많은 시간을 소비하므로 전체 처리량에 큰 영향을 주지 않고 실행을 인터리브할 수 있습니다.
- GIL의 경쟁은 컴퓨팅 집약적인 파이썬 스레드의 속도를 느리게 합니다. 이러한 작업에는 순차(sequential), 단일 스레드 코드가 더 간단하고 빠릅니다.
- CPU-Intensive 파이썬 코드를 멀티 코어에서 실행하려면 여러 파이썬 프로세스를 사용해야 합니다.
threading 모듈의 문서에는 다음과 같이 잘 요약해주고 있습니다.

GIL은 파이썬의 언어 정의의 일부가 아니기 때문에 threading 모듈은 'CPython implementation detail'로 시작합니다. Jython 구현에는 GIL이 없지만, 불행히도 아직 파이썬 2.7에 머물러있습니다. 높은 성능을 가지는 PyPy 인터프리터 또한 GIL을 가집니다(2.7 and 3.7 versions).
교재를 해석한 것에 불과해서 부족한 부분이 많을 것 같습니다. 특히 GIL의 경우에는 잘 모르는 개념이기 때문에 따로 살펴 볼 필요는 있을 것 같습니다.. !
A Concurrent Hellow World
스레드와 GIL을 피하는 방법에 대한 토론 중에, Python의 컨트리뷰터인 Michele Simionato는 동시성을 보여주는 Hello World와 같은 예제를 포스트(link)했습니다.
이 프로그램은 multiprocessing을 사용했지만, 아래에서 살펴볼 예제 코드는 이 프로그램의 동작과는 동일하지만 threading와 asyncio을 적용하여 구현합니다.
Spinner with threading
이 프로그램는 3초간 블락하는 함수를 시작하고, 그 3초 동안 "\|/-" 문자열의 한 문자씩 터미널에 출력합니다. 이는 프로그램이 중단되지 않았고, "thinking" 중이라는 것을 알려줍니다. 프로그램의 연산이 종료되면, 출력되던 것들은 제거되고 "Answer: 42"가 출력됩니다.
아래 코드를 실행하면 다음과 같이 출력이 됩니다.

이제 이를 출력하는 예제 코드를 살펴보겠습니다.
# spinner_thread.py
import itertools
import time
from threading import Thread, Event
# 이 함수는 분리된 스레드에서 수행됩니다. done 인수는 threading.Event의 인스턴스이며
# 스레드를 동기화하는 간단한 방법입니다.
def spin(msg: str, done: Event) -> None:
# itertools.cycle은 한 번에 한 문자씩 생산하며, 사이클을 돌며 무한히 반복합니다.
for char in itertools.cycle(r'\|/-'):
# 텍스트 애니메이션을 위한 트릭. '\r'을 사용해 커서를 line의 처음으로 위치시킴
status = f'\r{char} {msg}'
print(status, end='', flush=True)
# Event.wait(timeout=None) 메소드는 이벤트가 다른 스레드에 의해 set되면 True를 리턴
# 만약 timeout이 경과하면, False를 반환. 여기서 .1 timeout은 애니메이션의 프레임 속도를
# 10FPS로 설정합니다. 더 빨리 회전하도록 하려면 더 작은 값으로 설정하면 됨
if done.wait(.1):
break # 무한 루프를 빠져나옴
blanks = ' ' * len(status)
# 공백으로 덮어써서 출력된 것들을 지우고 커서를 라인의 첫 위치로 이동
print(f'\r{blanks}\r', end='')
def slow() -> int:
# 메인 함수로부터 호출되는 함수
# sleep의 호출은 메인 스레드를 블락시키며, GIL가 해제되어 spinner thread가 진행된다
time.sleep(3)
return 42
def supervisor() -> int:
# threading.Event 인스턴스는 메인 스레드와 spinner 스레드의 활동을 조정하는 핵심
done = Event()
# 새로운 Thread를 생성할 때,
# target 키워드에 함수를 전달하고, 전달한 함수의 위치 인수를 튜플로 전달
spinner = Thread(target=spin, args=('thinking!', done))
# spinner 객체를 출력. <Thread(Thread-1), initial)>를 출력하며,
# initial은 스레드의 상태이다. 이는 아직 시작하지 않았음을 의미함
print(f'spinner object: {spinner}')
# spinner 스레드를 시작
spinner.start()
# slow()를 호출하고, 이 함수는 메인 스레드를 블락시킨다.
# 메인 스레드가 블락되는 동안 두 번째 스레드가 spinner 애니메이션을 실행하고 있다.
result = slow()
# Event 플래스를 True로 설정한다. 이는 spin 함수 내의 for 루프를 종료시킨다
done.set()
spinner.join() # spinner 스레드가 종료할 때까지 대기한다
return result # return the result of slow()
def main() -> None:
# supervisor() 함수를 실행한다.
result = supervisor()
print(f'Answer: {result}')
if __name__ == '__main__':
main()위 예제 코드는 time.sleep() 호출이 호출한 스레드를 블락시키고, GIL을 해제한다는 것을 보여줍니다. 따라서 다른 파이썬 스레드가 실행되도록 합니다.
spin()과 slow() 함수는 동시에 실행될 것입니다. 메인 스레드(프로그램이 시작할 때 존재하는 유일한 스레드)는 spin()을 실행하기 위한 새로운 스레드를 시작하고, 그 후에 slow()를 호출합니다. 의도적으로 파이썬에는 스레드를 종료하기 위한 API가 없습니다. 반드시 종료(shut down)를 위한 메세지를 보내주어야 합니다.
threading.Event 클래스는 스레드를 조정하기 위한 파이썬의 가장 간단한 시그널 메커니즘입니다. Event 인스턴스는 False로 시작하는 내부 boolean 플래그를 가지고 있습니다. Event.set()을 호출하면 이 플래그는 True가 됩니다. 플래그가 false인 동안 한 스레드가 Event.wat()를 호출하면, 이 스레드는 다른 스레드가 Event.set()을 호출하여 Event.wat()가 True를 반환할 때까지 블락됩니다. 만약 Event.wait(s)에 타임아웃 시간(unit: seconds)이 주어지면, 타임아웃 시간이 경과하면 False를 반환하거나, 다른 스레드에서 Event.set()을 호출하자마자 True를 반환합니다.
Event는 supervisor() 함수에서 spin 함수를 종료시키기 위해 사용됩니다.
메인 스레드에서 done 이벤트를 설정할 때, spinner 스레드는 이를 전달받고 결국 종료하게 됩니다.
Spinner with multiprocessing
multiprocessing 패키지는 스레드 대신 분리된 파이썬 프로세스로 동시 태스크를 수행하도록 지원합니다. multiprocessing.Process 인스턴스를 생성할 때 백그라운드에서의 자식 프로세스처럼 완전히 새로운 파이썬 인터프리터가 실행됩니다. 각 파이썬 프로세스는 저마다의 GIL을 가지고 있기 때문에 이는 프로그램이 사용가능한 CPU 코어를 모두 사용할 수 있도록 해줍니다.
이 섹션의 요점은 multiprocessing을 소개하고, 이 API가 threading API와 유사하다는 것입니다. 따라서 스레드에서 프로세스를 사용하도록 코드를 변환하는 것이 쉽습니다.
# spinner_proc.py
import itertools
import time
from multiprocessing import Process, Event
# multiprocessing.Event는 synchronize.Event 인스턴스를 반환하는 함수이다.
# 따라서, multiprocessing.synchronize를 import 해야 한다.
from multiprocessing import synchronize
# done의 타입 힌트만 변경되고 나머지는 threading을 사용한 예제와 동일
def spin(msg: str, done: synchronize.Event) -> None:
for char in itertools.cycle(r'\|/-'):
status = f'\r{char} {msg}'
print(status, end='', flush=True)
if done.wait(.1):
break
blanks = ' ' * len(status)
print(f'\r{blanks}\r', end='')
def slow() -> int:
time.sleep(3)
return 42
def supervisor() -> int:
done = Event()
# Process의 사용법은 Thread와 유사하다
spinner = Process(target=spin, args=('thinking!', done))
# spinner 객체는 <Process name='Process-1' parrent=29272 initial>과 같이 출력됨
# 29272는 spinner.proc.py를 실생하는 파이썬 인스턴스의 프로세스 id이다.
print(f'spinner object: {spinner}')
spinner.start()
result = slow()
done.set()
spinner.join()
return result
def main() -> None:
result = supervisor()
print(f'Answer: {result}')
if __name__ == '__main__':
main()
threading과 multiprocessing의 기본 API는 비슷하지만, 이들의 구현은 매우 다르며, multiprocessing에는 멀티 프로세스 프로그램의 복잡성을 처리하기 위한 더 많은 API가 있습니다. 예를 들어, 스레드에서 프로세스로 변환할 때 한 가지 문제는 서로 고립된 프로세스 간의 통신을 어떻게 할 것인가이며, 파이썬 객체들은 공유할 수 없습니다. 즉, 프로세스 경계를 넘나드는 객체는 serialized/deserialized되어야 하므로, 오버헤드가 발생합니다. 위의 예제 코드에서 프로세스 경계를 넘는 유일한 데이터는 Event 상태이며, 이는 multiprocessing 모듈의 기반이 되는 C 코드에서 low-level OS 세마포(semaphore)로 구현됩니다.
다음으로는 스레드나 프로세스가 아닌 코루틴으로 동일한 동작을 어떻게 구현하는지 살펴보겠습니다.
Spinner with asyncio
스레드나 프로세스를 구동하기 위해서 CPU Time을 할당하는 것은 OS 스케쥴러의 일입니다. 이와 대조적으로 코루틴은 어플리케이션 수준(application-level)의 이벤트 루프에 의해 구동되는데, 이것은 보류 중인 코루틴의 대기열(queue)를 관리하고, 하나씩 구동하고, 코루틴에 의해 시작된 I/O 작업에 의해 트리거된 이벤트들을 모니터링하고, 각 이벤트가 발생할 때 해당 코루틴에 제어를 다시 전달합니다. 이벤트 루프와 라이브러리 코루틴과 유저 코루틴은 모두 단일 스레드로 실행됩니다.
위에서 살펴본 spinner 프로그램의 코루틴 버전 코드는 다음과 같습니다.
# spinner_async.py
import asyncio
import itertools
# 이전 예제와 달리 Event 인수(done)가 필요없음
async def spin(msg: str) -> None:
for char in itertools.cycle(r'\|/-'):
status = f'\r{char} {msg}'
print(status, end='', flush=True)
try:
# 다른 코루틴을 블락하지 않고 중지하기 위해
# time.sleep(.1) 대신 await asyncio.sleep(.1)을 사용
await asyncio.sleep(.1)
except asyncio.CancelledError:
# 이 예외는 코루틴을 제어하는 Task의 cancel() 메소드가 호출될 때 발생
break
blanks = ' ' * len(status)
print(f'\r{blanks}\r', end='')
async def slow() -> int:
# slow() 코루틴 또한 time.sleep 대신 await asyncio.sleep을 사용
await asyncio.sleep(3)
return 42
def main() -> None:
result = asyncio.run(supervisor())
print(f'Answer: {result}')
# Native 코루틴은 async def로 정의됨
async def supervisor() -> int:
# asyncio.create_task는 spin을 실행을 스케쥴링하고, 즉시 asyncio.Task 인스턴스를 반환함
spinner = asyncio.create_task(spin('thinking!'))
# spinner 객체의 repr은
# <Task pending name='Task-2' coro=<spin() running at /path/to/spinner_async.py:4>>와 같음
print(f'spinner object: {spinner}')
# await 키워드는 slow()를 호출하고 slow()가 리턴할 때까지 superviosr()를 블락함
# 반환된 값을 result에 할당됨
result = await slow()
# Task.cancel() 메소드는 spin 코루틴 안에서 CancelledError 예외를 발생시킴
spinner.cancel()
return result
if __name__ == '__main__':
main()
위 코드에서는 코루틴을 실행하기 위한 3가지 방법을 보여줍니다.
- asyncio.run(coro())
- asyncio.create_task(coro()) :
현재 코루틴을 중지시키지 않고, Task 인스턴스를 리턴한다. 이 객체는 코루틴 객체를 래핑하며 제어와 상태를 쿼리하기 위한 메소드들을 제공한다. - await coro() :
coro()가 리턴될 때까지 현재 코루틴을 중지시킨다.
Experiment: Break the Spinner for an Insight
spinner_async.py의 동작을 조금 더 이해하기 위해, time 모듈을 import하고 slow() 코루틴의 await asyncio.sleep(3)을 time.sleep(3)으로 바꿔서 실행해보겠습니다.
async def slow() -> int:
# slow() 코루틴 또한 time.sleep 대신 await asyncio.sleep을 사용
time.sleep(3) #await asyncio.sleep(3)
return 42이렇게 바꾼 후 실행한 결과는 다음과 같습니다.

spinner 객체가 출력되지만, spinner 애니메이션을 발생하지 않고 프로그램은 3초간 멈춥니다. 그 후 "Answer: 42"가 출력되며 프로그램이 종료됩니다.
어떤 일이 발생했는지 이해하기 위해서, asyncio를 사용하는 파이썬 코드는 오직 하나의 실행 흐름을 가지고 있다는 것을 떠올리면 됩니다. 위 예제 코드에서 우리는 명시적으로 추가 스레드나 프로세스를 시작하지 않았습니다. 이는 어느 지점에서든지 한 번에 하나의 코루틴의 실행만이 존재한다는 것을 의미합니다. 여기서 동시성은 한 코루틴에서 다른 코루틴으로 제어를 전달함으로서 달성됩니다.
이 실험에서 supervisor()와 slow() 에서는 어떤 일이 발생하는지 살펴보겠습니다.
async def slow() -> int:
# slow() 코루틴 또한 time.sleep 대신 await asyncio.sleep을 사용
time.sleep(3) #await asyncio.sleep(3)
return 42
async def supervisor() -> int:
# asyncio.create_task는 spin을 실행을 스케쥴링하고, 즉시 asyncio.Task 인스턴스를 반환함
spinner = asyncio.create_task(spin('thinking!'))
# spinner 객체의 repr은
# <Task pending name='Task-2' coro=<spin() running at /path/to/spinner_async.py:4>>와 같음
print(f'spinner object: {spinner}')
# await 키워드는 slow()를 호출하고 slow()가 리턴할 때까지 superviosr()를 블락함
# 반환된 값을 result에 할당됨
result = await slow()
# Task.cancel() 메소드는 spin 코루틴 안에서 CancelledError 예외를 발생시킴
spinner.cancel()
return result실행 순서는 다음과 같습니다.
- line 8: spinner 태스크가 생성되어, 나중에 spin의 실행을 구동합니다.
- line 11: 여기서 출력되는 spinner 태스크의 상태는 "pending"입니다.
- line 14: await 표현식은 제어를 slow() 코루틴으로 전달합니다.
- line 3: 3초간 블락합니다. 프로그램에서는 아무것도 일어나지 않는데, 이는 프로그램의 유일한 스레드인 메인 스레드가 블락되었기 때문입니다. 3초 후, sleep은 언블락되고 slow()는 리턴됩니다.
- line 16: slow()가 리턴되는 즉시, spinner 태스크는 cancel됩니다. 이후 제어 흐름은 절대 spin 코루틴의 바디에 도달할 수 없습니다.
Supervisors Side-by-side
Thread를 사용한 버전과 asyncio를 사용한 버전의 코드는 거의 유사합니다. 위 예제 프로그램에서는 superviosr 함수가 핵심입니다. 이번 섹션에서는 spinner_thread.py와 spinner_async.py의 supervisor 함수를 서로 비교해보도록 하겠습니다. 아래 코드는 각 코드에서의 supervisor() 함수입니다.
# spinner_thread.py
def supervisor() -> int:
done = Event()
spinner = Thread(target=spin, args=('thinking!', done))
print(f'spinner object: {spinner}')
spinner.start()
result = slow()
done.set()
spinner.join()
return resultasync def supervisor() -> int:
spinner = asyncio.create_task(spin('thinking!'))
print(f'spinner object: {spinner}')
result = await slow()
spinner.cancel()
return result
두 supervisor()의 구현의 차이점과 공통점을 정리하면 다음과 같습니다.
- asyncio.Task는 threading.Thread와 거의 동일하다고 볼 수 있습니다.
- Task는 코루틴 객체를 가동(drive)하고, Thread는 callable을 실행(invokde)합니다.
- Task 객체는 스스로 인스턴스화할 수 없으며, asyncio.create_task(...)에 코루틴을 전달하여 인스턴스를 얻을 수 있습니다.
- asyncio.create_task(...)가 Task 객체를 반환할 때, 이 객체는 이미 실행하기 위한 스케쥴링을 마친 상태입니다. 하지만 Thread 인스턴스는 명시적으로 start() 메소드를 호출하여 실행합니다.
- supervisor 스레드에서 slow()는 plain function이며 메인 스레드로부터 직접 호출됩니다. 반면, 비동기 superviosr()에서 slow는 await에 의해 가동되는 코루틴입니다.
- 바깥에서 스레드를 종료하는 API는 없습니다. 대신 done Event 객체를 설정하는 것처럼 신호를 보낼 수 있습니다. 반면 Task 객체에는 Task.cancel()이라는 인스턴스 메소드가 있습니다. 이 메소드는 코루틴 본문의 현재 정지된 곳의 await 표현식에서 CancelledError 예외를 발생시킵니다.
- supervisor 코루틴은 반드시 메인 함수의 asyncio.run으로 시작됩니다.
만약 Threading 모듈에 조금 더 익숙하다면, 위와 같은 비교를 통해 asyncio가 어떻게 현재 작업을 조율하는지 좀 더 이해할 수 있습니다.
스레드와 코루틴에 대해 마지막으로 살펴볼 포인트가 있습니다. 스레드를 사용하여 프로그래밍을 해봤다면, 스케쥴러가 언제든지 스레드에 끼어들 수 있기 때문에 프로그램의 상태에 대해 추론하는 것이 상당히 어렵다는 것을 알고 있습니다. 스레드에 인터럽트가 걸리면서 데이터를 유효하지 않은 상태로 남겨둘 수 있기 때문에, 프로그램의 크리티컬 섹션을 보호하기 위해서 락을 유지해야 합니다.
코루틴을 사용하면 기본적으로 코드가 중단되지 않도록 보호됩니다. 우리는 나머지 프로그램이 실행될 때까지 명시적으로 기다리야 합니다. 여러 스레드의 작업을 동기화하기 위해서 락을 유지하는 대신, 코루틴은 정의에 따라서 동기화됩니다. 코루틴 중의 오직 하나만 언제든지 실행됩니다. 만약 제어를 포기하길 원한다면, await를 사용하여 스케쥴러에 제어를 되돌려줍니다. 이러한 이유로 코루틴을 안전하게 취소할 수 있습니다. 정의에 의해서, 코루틴은 await 표현식에서 중단된 경우에만 취소할 수 있습니다. 따라서 CancelledError 예외를 처리하여 제어를 돌려줄 수 있습니다.
The Real Impact of the GIL
sleep.time(3)은 호출한 스레드를 블락시키지만, 아무것도 수행하지 않습니다. 이번에는 CPU 집약적인(CPU를 많이 소모하는) 호출을 이용한 실험을 통해서 GIL에 대해 조금 더 살펴보겠습니다. 또한, CPU 집약적인 함수가 비동기 코드에서 미치는 영향도 살펴보도록 합니다.
위에서 살펴 본 spinner 예제 코드의 slow() 함수에서 time.sleep(3)의 호출은 HTTP 클라이언트 요청과 같은 것으로 바꿀 수 있으며, 요청이 처리되는 동안 spinner는 계속 돌아갈 것입니다. 이러한 방식으로 잘 디자인된 네트워크 라이브러리는 네트워크의 응답을 기다리는 동안 GIL을 해제합니다.
slow() 코루틴 asyncio.sleep(3) 표현식 또한 다른 것으로 교체되어 잘 설계된 비동기 네트워크 라이브러리로부터 응답을 기다릴 수도 있습니다. 이러한 라이브러리는 네트워크를 기다리는 동안 이벤트 루프에 제어권을 되돌려주는 코루틴을 제공하기 때문입니다.
CPU 집약적인 코드에서는 이야기가 조금 다릅니다. 아래의 is_prime() 함수를 살펴보겠습니다. 이 함수는 인수가 소수라면 True를 반환하고, 그렇지 않으면 False를 리턴합니다.
import math
def is_prime(n: int) -> bool:
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
root = math.isqrt(n)
for i in range(3, root + 1, 2):
if n % i == 0:
return False
return Trueis_prime(5_000_111_000_222_021) 호출은 제 PC에서 대략 3초정도 소요됩니다.
만약 위의 spinner 예제에서 n = 5_000_111_000_222_021로 설정하고, 다음과 같이 변경하면 무슨 일이 발생할까요?
- spinner_proc.py(multiprocessing)에서 time.sleep(3)을 is_prime(n)으로 변경
- spinner_thread.py(multithreading)에서 time.sleep(3)을 is_prime(n)으로 변경
- spinner_async.py(코루틴)에서 await asyncio.sleep(3)을 is_prime(n)으로 변경
순서대로 정답을 알아보도록 하겠습니다.
1. Answer for multiprocessing
spinner는 자식 프로세스에 의해 제어됩니다. 따라서, 부모 프로세스에 의해 소수 판별이 연산되는 동안 계속해서 spinner는 돌아가게 됩니다.
2. Answer for threading
spinner는 두 번째 스레드에 의해서 제어됩니다. 따라서 마찬가지로 메인 스레드에서 소수 판별이 연산되는 동안 계속해서 spinner는 돌아가게 됩니다.
이 예제에서 spinner는 계속해서 회전하는데, 파이썬은 실행 중인 스레드를 5ms(default)마다 중지시켜, 다른 중지된 스레드가 GIL을 점유하도록 하기 때문입니다. 그러므로 is_prime을 실행 중인 메인 스레드는 매 5ms마다 인터럽트되어, done Event의 wait 메소드가 호출될 때까지 두 번째 스레드가 깨어나 for 루프를 통해 한 번 반복하고 GIL을 해제합니다. 그러면 메인 스레드는 다시 GIL을 점유하고, is_prime 계산이 5ms 동안 다시 진행됩니다.
is_prime(n)으로 변경해도 예제의 실행 시간에 가시적인 영향은 미치지 않습니다. 이는 spin 함수가 한 번 빠르게 반복하고 done 이벤트를 기다리는 동안 GIL을 해제하므로, GIL에 대한 경합이 많이 발생하지 않기 때문입니다. is_prime을 실행하는 메인 스레드가 GIL을 대부분 점유하고 있습니다.
이 간단한 실험에서는 스레드가 두 개뿐이기 때문에 스레딩을 사용하여 계산 집약적인 태스크를 수행하지 못했습니다. 한 스레드는 CPU를 사용하지만, 다른 스레드는 spinner를 업데이트하기 위해 초당 10번만 깨어나기 때문입니다. 하지만 많이 CPU Time을 놓고 경쟁하는 두 개 이상의 스레드가 있는 경우 프로그램은 순차 프로그램보다 느릴 것입니다.
3. Answer for asyncio
slow() 코루틴에서 asyncio.sleep(3)을 is_prime(n)으로 변경하여 호출하면, spinner는 절대 나타나지 않습니다. 이는 위에서 asyncio.sleep(3)을 time.sleep(3)으로 변경했을 때와 동일합니다. 제어 흐름은 supervisor에서 slow르 전달되고, 그리고 is_prime으로 전달됩니다. is_prime이 반환되면, slow 또한 반환되며, supervisor가 재게됩니다. 하지만 supervisor는 실행되기 전에 spinner 태스크를 cancel시킵니다. 따라서 프로그램은 약 3초간 정지되어 있다가, answer를 출력하게 됩니다.
A Homegrown Process Pool
이번 섹션에서 20개의 정수에 대해 소수 판별을 수행하는 프로그램을 작성합니다. 이 정수는 2에서 9,999,999,999,999,999(\(10^{16}-1\)) 까지의 범위를 갖고 있습니다.
일단 소수를 판별하는 함수가 정의된 코드는 다음과 같습니다.
# primes.py
import math
PRIME_FIXTURE = [
(2, True),
(142702110479723, True),
(299593572317531, True),
(3333333333333301, True),
(3333333333333333, False),
(3333335652092209, False),
(4444444444444423, True),
(4444444444444444, False),
(4444444488888889, False),
(5555553133149889, False),
(5555555555555503, True),
(5555555555555555, False),
(6666666666666666, False),
(6666666666666719, True),
(6666667141414921, False),
(7777777536340681, False),
(7777777777777753, True),
(7777777777777777, False),
(9999999999999917, True),
(9999999999999999, False),
]
NUMBERS = [n for n, _ in PRIME_FIXTURE]
def is_prime(n: int) -> bool:
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
root = math.isqrt(n)
for i in range(3, root + 1, 2):
if n % i == 0:
return False
return True
if __name__ == '__main__':
for n, prime in PRIME_FIXTURE:
prime_res = is_prime(n)
assert prime_res == prime
print(n, prime)
먼저 싱글 스레드(프로세스)로 20개의 정수의 소수 여부를 판별하는 순차 코드는 다음과 같습니다.
# sequential.py
from time import perf_counter
from typing import NamedTuple
from primes import is_prime, NUMBERS
class Result(NamedTuple):
prime: bool
elapsed: float
def check(n: int) -> Result:
t0 = perf_counter()
prime = is_prime(n)
return Result(prime, perf_counter() - t0)
def main() -> None:
print(f'Checking {len(NUMBERS)} numbers sequentially:')
t0 = perf_counter()
for n in NUMBERS:
prime, elapsed = check(n)
label = 'P' if prime else ' '
print(f'{n:16} {label} {elapsed:9.6f}s')
elapsed = perf_counter() - t0
print(f'Total time: {elapsed:.2f}s')
if __name__ == '__main__':
main()이 코드를 실행한 결과는 다음과 같으며, 아래서 살펴볼 다른 코드의 결과와 비교할 베이스라인입니다.

결과의 첫 번째 열은 검사를 수행한 정수, 두 번째는 소수 여부(P or 빈칸), 세 번째는 소수를 판별하는데 걸린 시간입니다.
Process-based Solution
아래 코드는 동일한 소수 판별 연산을 다중 CPU 코어에 분산하여 수행하도록 합니다. 코드에 관한 설명은 따로 하지 않고, 기회가 될 때 multiprocessing 패키지에 관해서 알아보도록 하겠습니다.
# procs.py
import sys
from time import perf_counter
from typing import NamedTuple
from multiprocessing import Process, SimpleQueue, cpu_count
from multiprocessing import queues
from primes import is_prime, NUMBERS
class PrimeResult(NamedTuple):
n: int
prime: bool
elapsed: float
JobQueue = queues.SimpleQueue
ResultQueue = queues.SimpleQueue
def check(n: int) -> PrimeResult:
t0 = perf_counter()
res = is_prime(n)
return PrimeResult(n, res, perf_counter() - t0)
def worker(jobs: JobQueue, results: ResultQueue) -> None:
while n := jobs.get():
results.put(check(n))
results.put(PrimeResult(0, False, 0.0))
def start_jobs(
procs: int, jobs: JobQueue, results: ResultQueue
) -> None:
for n in NUMBERS:
jobs.put(n)
for _ in range(procs):
proc = Process(target=worker, args=(jobs, results))
proc.start()
jobs.put(0)
def main() -> None:
if len(sys.argv) < 2:
procs = cpu_count()
else:
procs = int(sys.argv[1])
print(f'Checking {len(NUMBERS)} numbers with {procs} processes:')
t0 = perf_counter()
jobs: JobQueue = SimpleQueue()
results: ResultQueue = SimpleQueue()
start_jobs(procs, jobs, results)
checked = report(procs, results)
elapsed = perf_counter() - t0
print(f'{checked} checks in {elapsed:.2f}s')
def report(procs: int, results: ResultQueue) -> int:
checked = 0
procs_done = 0
while procs_done < procs:
n, prime, elapsed = results.get()
if n == 0:
procs_done += 1
else:
checked += 1
label = 'P' if prime else ' '
print(f'{n:16} {label} {elapsed:9.6f}s')
return checked
if __name__ == '__main__':
main()
실행 결과는 다음과 같습니다.
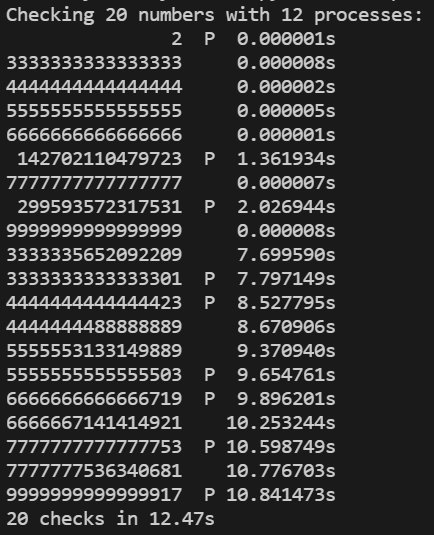
총 걸린 시간이 순차 코드보다 약 3.5배 정도 빨라진 것을 확인할 수 있습니다.
스레드나 프로세스에 연산을 위임할 때 코드는 worker 함수를 직접 호출하지 않으므로 간단히 반환 값을 얻을 수 없습니다. 대신 worker는 스레드 또는 프로세스 라이브러리에 의해 구동되며 결국 어딘가에 저장해야 하는 결과를 생성합니다. 동시 프로그램에서 worker를 조정하고 결과를 수집하는 것은 일반적으로 queue를 사용합니다.
큐는 아시다시피 FIFO 순서를 적용하는 데이터 구조입니다. 파이썬 표준 라이브러리의 queue 패키지는 스레드를 지원하는 queue 클래스를 지원하는 반면, multiprocessing과 asyncio 패키지는 자체 queue 클래스를 구현합니다. queue 및 asyncio 패키지는 FIFO가 아닌 LifoQueue와 PriorityQueue도 포함합니다.
위의 코드에서 커맨드 인수로 사용할 프로세스의 개수를 설정할 수 있습니다. 예를 들어, 다음과 같이 실행합니다.

인수로 2를 설정하면, 2개의 프로세스를 사용해서 20개의 정수에 대한 소수 판별 연산을 수행합니다. 결과는 순차 코드에 비해 약 2배 정도 빨라졌다고 볼 수 있습니다.
교재에서는 프로세스의 개수를 1부터 20까지 설정하여 테스트한 결과가 있는데, 그 결과는 다음과 같습니다.

Threaded-based Non-solution
multiprocessing 대신 threading을 사용한 버전의 코드는 다음과 같습니다.
# threads.py
import os
import sys
from queue import SimpleQueue
from time import perf_counter
from typing import NamedTuple
from threading import Thread
from primes import is_prime, NUMBERS
class PrimeResult(NamedTuple):
n: int
prime: bool
elapsed: float
def check(n: int) -> PrimeResult:
t0 = perf_counter()
res = is_prime(n)
return PrimeResult(n, res, perf_counter() - t0)
def worker(jobs: SimpleQueue, results: SimpleQueue) -> None:
while n := jobs.get():
results.put(check(n))
results.put(PrimeResult(0, False, 0.0))
def start_jobs(workers: int, jobs: SimpleQueue, results: SimpleQueue) -> None:
for n in NUMBERS:
jobs.put(n)
for _ in range(workers):
proc = Thread(target=worker, args=(jobs, results))
proc.start()
jobs.put(0)
def report(workers: int, results: SimpleQueue) -> int:
checked = 0
workers_done = 0
while workers_done < workers:
n, prime, elapsed = results.get()
if n == 0:
workers_done += 1
else:
checked += 1
label = 'P' if prime else ' '
print(f'{n:16} {label} {elapsed:9.6f}s')
return checked
def main() -> None:
if len(sys.argv) < 2:
workers = os.cpu_count()
else:
workers = int(sys.argv[1])
print(f'Checking {len(NUMBERS)} numbers with {workers} threads:')
t0 = perf_counter()
jobs = SimpleQueue()
results = SimpleQueue()
start_jobs(workers, jobs, results)
checked = report(workers, results)
elapsed = perf_counter() - t0
print(f'{checked} checks in {elapsed:.2f}s')
if __name__ == '__main__':
main()코드는 procs.py 버전과 유사하지만, 결과는 그렇지 않습니다.

GIL과 is_prime의 계산 집약적인 특성 때문에 스레드 버전은 순차 코드만큼 느리고, CPU 경합과 컨텐스트 스위칭 때문에 스레드 수가 증가할수록 느려집니다. 새 스레드로 스위칭하려면 OS가 CPU 레지스터를 저장하고 프로그램 카운터와 스택 포인터를 업데이트해야 하므로 cost가 큰 부작용이 발생합니다.
이번 포스팅을 통해서 파이썬에서의 동시성 모델들에 대해 간단하게 살펴봤습니다. 다음 두 포스팅을 통해서 high-level concurrent.futures 라이브러리를 사용하여 스레드와 프로세스를 관리하는 것과 asyncio를 사용하여 비동기 프로그래을 작성하는 방법에 대해서 알아보도록 하겠습니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] 동적 속성과 프로퍼티 (0) | 2022.03.30 |
|---|---|
| [Python] Futures (0) | 2022.03.30 |
| [Python] 코루틴(Coroutines), yield from (0) | 2022.03.27 |
| [Python] Context Mangers and else Blocks (0) | 2022.03.26 |
| [Python] Iterables, Iterators, and Generators (0) | 2022.03.25 |




댓글