References
- Fluent Python
Contents
- Dynamic Attributes (__getattr__)
- __new__
- read-only properties (@property, @cache, @cached_property)
- read/write properties
- Property Factory
- Handling Attribute Deletion
- Attributes and Functions for Handling Attributes
파이썬에서는 데이터 속성과 메소드를 통틀어 속성(attributes)라고 합니다. 메소드는 단지 호출할 수 있는(callable) 속성일 뿐입니다. 데이터 속성과 메소드 외에도 프로퍼티를 정의할 수 있습니다. 프로퍼티를 사용하면 클래스 인터페이스를 변경하지 않고도 공개 데이터 속성을 접근자 메소드(accessor methods), 즉, getter와 setter로 대체할 수 있습니다.
프로퍼티 외에도 파이썬은 속성에 대한 접근을 제어하고 동적 속성을 구현할 수 있는 풍부한 API를 제공합니다. 파이썬 인터프리터는 obj.attr과 같은 점 표기법으로 표현된 속성에 대한 접근을 __getattr__()과 __setattr__() 등 스페셜 메소드를 호출해서 평가합니다. __getattr__() 메소드를 구현하는 사용자 정의 클래스는 obj.no_such_attribute처럼 실제로 존재하지 않는 속성을 실행 도중에 계산함으로써 'virtual attributes'를 구현할 수 있습니다.
동적 속성을 구현하는 것은 프레임워크 개발자들이 하는 메타프로그래밍의 한 종류입니다. 그러나 파이썬에서는 기본적인 기법이 간단하므로 누구나 사용할 수 있고, 심지어 일상적으로 수행하는 데이터 랭글링(data wrangling) 작업에도 사용할 수 있습니다.
Data Wrangling with Dynamic Attributes
이번 포스팅에서 살펴볼 몇 가지 예제에서는 OSCON 2014 컨퍼런스에서 O'Relly가 공개한 JSON 데이터셋을 가지고 동적 속성을 이용할 예정입니다. 아래 JSON 데이터는 이 데이터셋에서 가져온 레코드 4개입니다.
{ "Schedule":
{ "conferences": [{"serial": 115 }],
"events": [
{ "serial": 34505,
"name": "Why Schools Don´t Use Open Source to Teach Programming",
"event_type": "40-minute conference session",
"time_start": "2014-07-23 11:30:00",
"time_stop": "2014-07-23 12:10:00",
"venue_serial": 1462,
"description": "Aside from the fact that high school programming...",
"website_url":
"http://oscon.com/oscon2014/public/schedule/detail/34505",
"speakers": [157509],
"categories": ["Education"] }
],
"speakers": [
{ "serial": 157509,
"name": "Robert Lefkowitz",
"photo": null,
"url": "http://sharewave.com/",
"position": "CTO",
"affiliation": "Sharewave",
"twitter": "sharewaveteam",
"bio": "Robert ´r0ml´ Lefkowitz is the CTO at Sharewave, a startup..." }
],
"venues": [
{ "serial": 1462,
"name": "F151",
"category": "Conference Venues" }
]
}
}위 JSON 데이터는 895개 레코드 중 4개를 보여줍니다. 여기에서 보는 것처럼 전체 데이터셋이 "Schedule"이라는 키를 가진 하나의 JSON 객체이며, 이 값은 "conferences", "events", "speakers", "venues" 등 4개의 키로 매핑되어 있으며, 이 네 개의 키는 각각 레코드 리스트와 짝지어져 있습니다. 여기에서는 각 리스트에 레코드가 하나만 있지만, 전체 데이터셋에는 이 리스트에 수십 혹은 수백 개의 레코드가 들어 있다. 단, "conferences"에는 레코드가 하나만 들어 있습니다. 이 4개의 리스트에 들어 있는 모든 항목은 "serial" 필드를 가지고 있는데, 이 필드는 리스트 안에서 고유한 식별자로 사용됩니다.
파이썬 콘솔에서 다음과 같이 이 데이터셋을 확인해볼 수 있습니다. JSON 데이터 셋은 link에서 받으실 수 있습니다.

Exploring JSON-Like Data with Dynamic Attributes
위의 파이썬 콘솔의 코드는 간단하지만 feed['Schedule']['speakers'][40]['name']과 같은 문법은 조금 번거롭습니다. 자바스크립트에서는 feed.Schedule.events[40].name과 같은 구문으로 동일한 값을 가져올 수 있습니다. 파이썬에서는 이와 비슷하게 동작하는 사용자 정의 dict 클래스를 쉽게 구현할 수 있으며, 구현된 클래스는 웹에서도 많이 볼 수 있습니다. 여기서는 FrozenJSON을 직접 구현하는데, 읽기 연산만 지원하므로 다른 코드들보다 간단합니다. 지금은 데이터 조회만 하므로 이정도면 충분합니다. 하지만, FrozenJSON은 재귀적으로 호출되므로 중첩된 매핑과 리스트를 자동으로 처리합니다.
FrozenJSON의 구현은 다음과 같습니다.
from collections import abc
class FrozenJSON:
"""A read-only façade for navigating a JSON-like object
using attribute notation
"""
def __init__(self, mapping):
self.__data = dict(mapping) # mapping으로부터 딕셔너리 생성
# 원본을 변경하지 않으면서 딕셔너리 메소드를 사용할 수 있음
# name 속성이 없을 때만 __getattr__이 호출된다
def __getattr__(self, name):
if hasattr(self.__data, name):
# __data에 들어 있는 객체가 name 속성을 가지고 있으면 그 속성을 반환
# 이는 keys() 메소드가 처리하는 방식과 동일하다
return getattr(self.__data, name)
else:
# 그렇지 않으면 self.__data에 name을 키로 사용해서 항목을 가져오고,
# 가져온 항목에 FrozenJSON.build()를 호출한 결과를 반환한다.
return FrozenJSON.build(self.__data[name])
# 추가 생성자로서, 일반적으로 @classmethod 데코레이터가 사용됨
@classmethod
def build(cls, obj):
if isinstance(obj, abc.Mapping): # obj가 Mapping 타입이면
return cls(obj) # 이 객체로부터 FrozenJSON 객체 생성
elif isinstance(obj, abc.MutableSequence): # obj가 MutableSequence 타입이면
return [cls.build(item) for item in obj]# obj안에 있는 모든 항목에 build() 메소드를 적용해
else: # 생성된 객체들의 리스트를 반환
return obj # 둘 다 아니라면 항목을 그대로 반환다음은 위에서 정의한 FrozenJSON의 사용 방법을 보여줍니다.
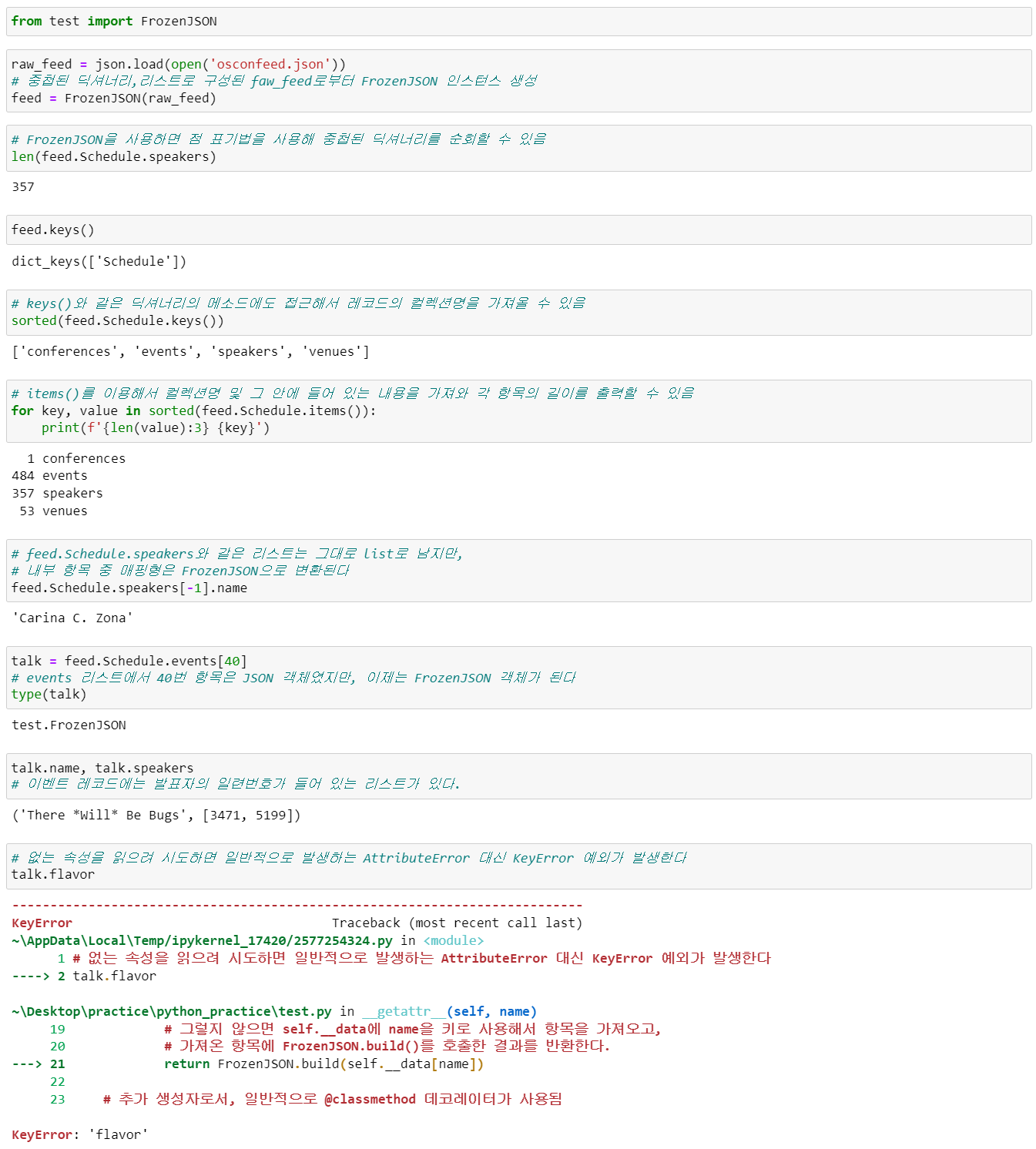
FrozenJSON 클래스의 핵심은 __getattr__() 메소드입니다. __getattr__() 스페셜 메소드는 속성을 가져오기 위한 일반적인 과정이 실패할 때만 인터프리터에서 호출한다는 점에 유의해야 합니다. 즉, 지명한 속성을 객체, 클래스, 슈퍼클래스에서 찾을 수 없을 때만 호출된다는 의미입니다.
위 예제 코드의 마지막은 FrozenJSON 구현의 작은 문제를 보여줍니다. 이상적으로는 없는 속성을 읽을 때 AttributeError 예외가 발생해야 합니다. 위에서 구현한 FrozenJSON에서는 예외 처리 코드는 포함되지 않았기 때문입니다.
구현한 FrozenJSON 클래스에는 __init__(), __getattr__() 메소드와 __data 객체 속성만 있으므로, 다른 이름으로 속성을 접근할 때는 __getattr__() 메소드가 호출됩니다. __getattr__()은 먼저 self.__data 딕셔너리에 그 이름의 속성(키가 아님!)이 있는지 살펴봅니다. 이때 FrozenJSON 객체는 self.__data.items() 등에 위임해서 items() 등의 딕셔너리 메소드를 처리할 수 있게 해줍니다. self.__data에 해당 이름의 속성이 없으면, __getattr__()은 해당 이름을 키로 사용하여 self.__data에서 항목을 가져와서 FrozenJSON.build()에 전달합니다. 각각의 중첩된 데이터 구조체를 build() 클래스 메소드를 이용해서 중첩된 FrozenJSON 객체로 변환하면서 JSON 데이터의 중첩된 구조체를 순회할 수 있습니다.
원본 데이터셋을 보관하거나 변환하지 않는다는 점에 주의해야 합니다. 데이터셋을 순회하면서 중첩된 데이터 구조체는 계속해서 FronzenJSON으로 변환됩니다. 이 정도의 데이터셋 크기에서 데이터를 순회만 하는 코드에서는 이 변환 작업이 큰 문제가 되지는 않습니다.
The Invalid Attributes Name Problem
임의의 데이터 소스에서 동적 속성명을 생성하는 프로그램에서는 원래 데이터에 들어 있는 키를 속성명으로 사용할 수 없는 경우에 대해 처리를 해주어야 합니다.
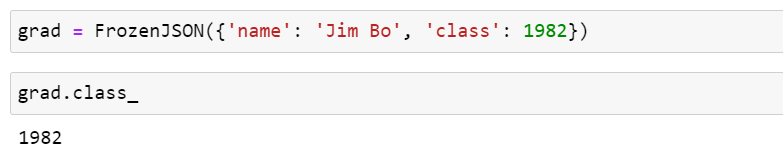
위에서 구현한 FrozenJSON 클래스는 한계가 있습니다. 파이썬 키워드가 속성명으로 사용된 경우를 처리하지 못합니다. 예를 들어 다음과 같은 객체를 만드는 경우를 생각해보겠습니다.
grad = FrozenJSON({'name': 'Jim Bo', 'class': 1982})class는 파이썬에서 예약된 키워드이므로, grad.class 속성을 읽을 수 없습니다.

그렇지만 다음의 방법으로는 읽을 수 있습니다.

그러나 FrozenJSON은 데이터에 편리하게 접근하기 위해 만든 것이므로 FrozenJSON.__init__()에 전달된 매핑 안에 키가 파이썬 키워드인지 검사하고, 파이썬 키워드인 경우에는 뒤에 _를 붙여 속성을 다음과 같은 방법으로 읽을 수 있게 만드는 것이 좋습니다.
이렇게 동작하도록 하려면, 다음과 같이 __init__() 메소드를 수정해주면 됩니다. keyword 모듈을 임포트해주어야 합니다.
def __init__(self, mapping):
self.__data = {}
for key, value in mapping.items():
if keyword.iskeyword(key): # keyword 모듈을 사용하여 키워드가 같은 속성명인지 체크
key += '_'
self.__data[key] = value
다음 실행 예시처럼 JSON에서 사용된 키가 올바른 파이썬 식별자가 아닐 때도 비슷한 문제가 발생합니다.

파이썬 3의 str 클래스에서는 s가 유효한 파이썬 식별자인지 판단하는 s.isidentifier() 메소드를 제공하므로, 이러한 문제를 발생시키는 키를 쉽게 탐지할 수 있습니다. 그렇지만 유효한 식별자가 아닌 문자열을 유효한 속성명으로 바꾸는 것은 간단하지 않습니다. 예외를 발생시키는 방법이나 유효하지 않은 키를 attr_0, attr_1 등의 일반적인 이름으로 바꾸는 두 가지 방법을 생각해볼 수 있지만, 여기서 예제 코드를 단순하게 만들기 위해서 이러한 문제에 대해서는 신경 쓰지 않았습니다.
지금까지 동적 속성명에 대해 알아보았고, 이제 FrozenJSON의 또 다른 중요한 특징인 접근하는 속성값에 따라 다양항 타입의 객체를 FrozenJSON 객체 혹은 FrozenJSON 객체의 리스트로 변환해서 반환하기 위해 __getattr__() 메소드가 사용하는 build() 클래스 메소드의 로직에 대해 살펴보겠습니다.
여기서 클래스 메소드 대신, 아래서 살펴볼 __new__() 스페셜 메소드를 이용해서 동일한 로직을 구현할 수 있습니다.
Flexible Object Creation with __new__
흔히 __init__() 메소드를 생성자 메소드라고 부르지만, 생성자라는 말은 다른 언어에서 빌려온 용어일 뿐입니다. 실제로 객체를 생성하는 스페셜 메소드는 __new__()입니다. 이 메소드는 클래스 메소드로서(하지만, @classmethod 데코레이터는 사용하지 않음) 반드시 객체를 반환합니다. 그리고 나서 그 객체가 __init__() 메소드의 첫 번째 인수 self로 전달됩니다. __init__()은 호출될 때 객체를 받으며 아무것도 반환할 수 없으므로, 실제로 __init__()은 '초기화 메소드'일 뿐입니다. 실제 생성자인 __new__() 메소드는 object 클래스에서 상속받은 메소드로도 충분하므로 직접 구현할 일은 거의 없습니다.
필요하다면 __new__() 메소드는 다른 클래스의 객체로 반환할 수 있는데, 이 경우에는 파이썬 인터프리터가 __init__()을 호출하지 않습니다. 이 로직을 파이썬 의사코드로 표현하면 다음과 같이 표현할 수 있습니다.
# pseudo-code for object construction
def make(the_class, some_arg):
new_object = the_class.__new__(some_arg)
if isinstance(new_object, the_class):
the_class.__init__(new_object, some_arg)
return new_object
# the following statements are roughly equivalent
x = Foo('bar')
x = make(Foo, 'bar')
다음 예제 코드는 이전에 작성한 build() 메소드에서 처리하던 로직을 __new__() 메소드로 옮긴 새로운 버전의 FrozenJSON 클래스를 보여줍니다.
from collections import abc
import keyword
class FrozenJSON:
"""A read-only façade for navigating a JSON-like object
using attribute notation
"""
# 클래스 메소드로서 __new__()가 첫 번째로 받는 인수는 클래스 자신이다
# 그리고 나머지 인수는 __init__()이 받는 인수와 동일하다
def __new__(cls, arg):
if isinstance(arg, abc.Mapping):
# 기본적으로 슈퍼클래스의 __new__() 메소드에 위임한다
# 이 경우 FrozenJSON을 유일한 인수로 전달해서 object 클래스의 __new__() 메소드를 호출
return super().__new__(cls)
elif isinstance(arg, abc.MutableSequence): # 나머지 로직은 build()와 동일
return [cls(item) for item in arg]
else:
return arg
def __init__(self, mapping):
self.__data = {}
for key, value in mapping.items():
if keyword.iskeyword(key):
key += '_'
self.__data[key] = value
def __getattr__(self, name):
if hasattr(self.__data, name):
return getattr(self.__data, name)
else:
# 기존에는 FrozenJSON.build()를 호출했지만, 이제는 단지 FrozenJSON() 생성자를 호출
return FrozenJSON(self.__data[name])
__new__() 메소드는 일반적으로 해당 클래스의 객체를 생성하므로 클래스를 첫 번째 인수로 받습니다. 따라서 FrozenJSON.__new__() 안에서 super().__new__(cls)는 object.__new__(FrozenJSON)을 호출하는 셈이 되어 object 클래스가 실제로는 FrozenJSON 객체를 생성합니다. 즉, 실제로는 파이썬 인터프리터 내부에서 C 언어로 구현된 object.__new__()가 객체를 생성하지만, 생성된 객체의 __class__ 속성은 FrozenJSON을 가리키게 됩니다.
Computed Properties
OSCON JSON 데이터셋은 구조적으로 명백한 단점들이 있습니다. 'There *Will* be Bugs'라는 제목이 붙은 인덱스 40번에 있는 이벤트는 3471과 5199, 두 명의 speakers가 있지만 이 발표자들을 찾아내기가 쉽지 않습니다. 이 숫자들은 일련번호지만, Schedule.speakers 리스트가 일련번호로 인덱싱되어 있지 않기 때문입니다. 모든 event 레코드에 존재하는 venue 필드 역시 일련번호를 가지고 있지만, 해당 venue 레코드를 찾으려면 Schedule.venues 리스트를 순차적으로 검색해야 합니다. 이번에는 연결된 레코드에 대해 자동 검색을 지원하기 위해서 데이터를 다시 구조화해보도록 하겠습니다.
OSCON JSON 데이터에서 'events' 리스트 안의 데이터는 'speakers' 및 'venues' 리스트의 레코드를 가리키는 정수의 일련 번호를 포함합니다.

이번에는 venue와 speakers 속성을 가진 Event 클래스를 구현해서 연결된 데이터를 자동으로 리턴하도록 하겠습니다. 즉, 일련 번호를 역참조하는 것입니다. Event 인스턴스는 다음과 같이 동작하도록 구현됩니다.

Event를 구현하기 전에 Record 클래스와 JSON 데이터를 읽고 Record 인스턴스로 딕셔너리를 반환하는 함수를 구현하는 것부터 한 단계씩 진행해보도록 하겠습니다.
Step 1: Data-driven Attribute Creation
구현할 Record와 load 함수는 다음과 같이 동작합니다.

아래 코드는 Record 클래스와 JSON 데이터를 읽고 Record 인스턴스를 딕셔너리로 반환하는 load 함수를 구현합니다.
import json
JSON_PATH = 'osconfeed.json'
class Record:
def __init__(self, **kwargs):
# 키워드 인수로 생성되는 속성을 가진 인스턴스를 구축하는 일반적인 shortcut
self.__dict__.update(kwargs)
def __repr__(self):
cls_name = self.__class__.__name__
# 커스텀 Record representation을 구축하기 위해 serial 필드를 사용
return f'<{cls_name} serial={self.serial!r}>'
def load(path=JSON_PATH):
records = {} # load()는 궁극적으로 Record 인스턴스의 딕셔너리를 반환
with open(path) as fp:
# JSON을 파싱하고, 네이티브 파이썬 객체를 반환(lists, dicts, strings, numbers etc)
raw_data = json.load(fp)
# 4개의 top-level 리스트('conferences', 'events', 'speakers', 'venues')를 반복
for collection, raw_records in raw_data['Schedule'].items():
record_type = collection[:-1] # 마지막 문자를 제외(speakers -> speaker)
for raw_record in raw_records:
# key를 'speaker.3471'의 포캣으로 구축
key = f'{record_type}.{raw_record["serial"]}'
# Record 인스턴스를 생성하고, records의 key에 저장
records[key] = Record(**raw_record)
return records
Record.__init__() 메소드는 널리 사용되는 파이썬의 꼼수를 보여줍니다. __slots__ 속성이 클래스에 선언되어 있지 않다면 객체의 __dict__에 속성들이 들어 있습니다. 따라서 __dict__를 직접 매핑형으로 설정하면, 그 객체의 속성 묶음(bunch)을 빠르게 정의할 수 있습니다.
위에서 정의한 Record의 정의는 매우 간단합니다. 그렇다면 이전에 왜 더 복잡한 FrozenJSON 클래스 대신 이렇게 간단한 방법을 사용하지 않았을까 하는 의문이 들수도 있습니다. 여기에는 두 가지 이유가 있습니다. 첫째, FrozenJSON은 중첩된 매핑과 리스트를 재귀적으로 변환하면서 동작합니다. 우리가 변환한 데이터셋에서는 매핑이나 리스트 안에 매핑이 중첩되어 들어가지 않으므로 Record는 이런 기능이 필요 없습니다. 레코드에는 문자열, 정수, 문자열의 리스트, 정수의 리스트만 들어 있습니다. 둘째, FrozenJSON은 keys()와 같은 메소드를 호출하기 위해 사용했던 __data 딕셔너리 속성에 접근할 수 있게 해주지만, 지금은 이러한 기능이 필요하지 않습니다.
Step 1에서 schedule 데이터셋의 구조를 변경하는 작업을 완료했으니, 이제 event 레코드에서 참조하는 venue와 speaker 레코드를 자동으로 가져오도록 Record 클래스를 확장해보도록 하겠습니다.
Step 2: Property to Retrieve a Linked Record
이번 단계의 목적은 가져온 event 레코드에서 venue나 speakers 속성을 읽을 때 Record를 반환하는 것입니다. 이는 Django ORM이 ForeignKey 필드에 접근할 때 하는 것과 유사합니다.
먼저 venue 속성부터 시작해보도록 하겠습니다. 원하는 동작은 다음고 같습니다.

Record.fetch()는 static 메소드로 데이터셋으로부터 Record 또는 Event 객체를 얻습니다. 여기서 event는 Event 클래스의 인스턴스가 됩니다. event.venue에 접근하면 Record 인스턴스가 반환됩니다. 이제 event.venue의 이름을 쉽게 name 속성으로 찾을 수 있으며, Event 인스턴스는 venue_serial 속성 또한 가지고 있습니다.
Event는 Record의 서브클래스이며, 연결된 레코드를 검색하기 위한 venue와 __repr__ 메소드가 추가됩니다. 코드 전체를 한 번에 보기는 힘들기 때문에 먼저 Record 클래스부터 살펴보겠습니다.
import inspect # load에서 사용할 예정
import json
JSON_PATH = 'osconfeed.json'
class Record:
# __index private 클래스 속성은 load로부터 반환되는 딕셔너리의 참조에 바인딩됨
__index = None
def __init__(self, **kwargs):
self.__dict__.update(kwargs)
def __repr__(self):
cls_name = self.__class__.__name__
return f'<{cls_name} serial={self.serial!r}>'
# staticmethod로 지정하여 어떻게 호출되던 간에 명시적으로 효과가 항상 정확히 동일하도록 함
@staticmethod
def fetch(key):
if Record.__index is None:
Record.__index = load()
return Record.__index[key]
다음은 Event 클래스입니다.
class Event(Record): # Event는 Record를 확장함
def __repr__(self):
# 만약 인스턴스가 name 속성을 가지고 있다면, 커스텀 representation을 생성
# 그렇지 않다면 Record의 __repr__()에 위임한다
if hasattr(self, 'name'):
cls_name = self.__class__.__name__
return f'<{cls_name} {self.name!r}>'
else:
return super().__repr__()
@property
def venue(self):
key = f'venue.{self.veneu_serial}'
# venue 속성은 venue_serial 속성으로부터 key를 구축하고,
# fetch 클래스 메소드(Record로부터 상속받은)로 전달한다.
return self.__class__.fetch(key)venue 메소드는 self.__class__.fetch(key)를 반환합니다. 이것을 간단히 self.fetch(key)로 사용하지 않는 이유는 무엇일까요? OSCON 데이터셋의 경우에는 'fetch'라는 키를 가진 이벤트 레코드가 없으므로, 간단히 self.fetch(key)로 쓸 수 있습니다. 하지만 'fetch'라는 키를 가진 이벤트 레코드가 하나라도 있으면 그 Event 객체에서 self.fetch의 참조는 Record로부터 상속한 fetch 클래스 메소드가 아니라 그 필드의 값을 가져오게 됩니다. 이는 사소한 버그이며, 데이터셋에 의해 달라지므로 운 좋게 테스트를 통과할 수 있습니다.
Record 클래스가 매핑(mapping)과 비슷하게 동작한다면 __getattr__() 대신 __getitem__()을 구현해서 속성을 가리거나 덮어쓸 버그 위험을 피할 수 있습니다. 사용자 정의 매핑이 Record를 구현하는 파이썬스러운 방법일 수도 있지만, 그 방법을 택했다면 동적 속성 프로그래밍 기법을 살펴볼 기회는 없었을 것입니다.
이 예제의 마지막 부분은 수정된 load() 함수입니다.
def load(path=JSON_PATH):
records = {}
with open(path) as fp:
raw_data = json.load(fp)
for collection, raw_records in raw_data['Schedule'].items():
record_type = collection[:-1]
# record_type으로부터 클래스 이름을 얻음. 'event' -> 'Event'
cls_name = record_type.capitalize()
# 모듈의 global scope에서 cls_name으로 객체를 얻음
# 어떠한 객체도 없다면 Record를 얻는다
cls = globals().get(cls_name, Record)
if inspect.isclass(cls) and issubclass(cls, Record):
# 찾은 객체가 클래스이고, Record의 서브클래스라면
# 이 이름을 factory에 바인딩
factory = cls
else:
# 그렇지 않다면 factory에 Record를 바인딩
factory = Record
for raw_record in raw_records:
key = f'{record_type}.{raw_record["serial"]}'
# 이전과 동일하지만, 위에서 바인딩한 factory로 객체를 생성
records[key] = factory(**raw_record)
return records커스텀 클래스를 가지는 record_type은 현재 Event지만, Speaker나 Venue라는 클래스를 구현했다면, load() 함수는 레코드를 만들어서 저장할 때 Record 클래스 대신 구현된 클래스를 자동으로 사용합니다.
이제 Event 클래스에 speakers 속성을 추가해보겠습니다.
Step 3: Property Overriding an Existing Attributes
venue 속성의 이름은 Event 레코드에서 필드 이름과 매칭되는 것이 없습니다. 이 데이터는 venue_serial 속성으로부터 옵니다. 이와 대조적으로 각 Event 인스턴스는 speakers라는 속성을 일련번호와 함께 가지고 있습니다. 그리고 우리는 해당 정보를 Record 인스턴스의 리스트를 반환하는 speakers 속성으로 노출시키고자 합니다. 여기서 이름이 충돌하는 부분에 특별히 주의를 기울여야 합니다.
아래 코드는 Event 클래스에서 speakers 속성을 구현하며, 이러한 이름 충돌을 해결하는 방법을 보여줍니다.
class Event(Record): # Event는 Record를 확장함
def __repr__(self):
if hasattr(self, 'name'):
cls_name = self.__class__.__name__
return f'<{cls_name} {self.name!r}>'
else:
return super().__repr__()
@property
def venue(self):
key = f'venue.{self.venue_serial}'
return self.__class__.fetch(key)
@property
def speakers(self):
# speakers 속성을 재귀호출하는 것을 방지하기 위해 인스턴스 __dict__로부터 직접 찾는다
spkr_serials = self.__dict__['speakers']
fetch = self.__class__.fetch
# fetch()를 이용해서 speaker 레코드들의 리스트를 반환
return [fetch(f'speaker.{key}') for key in spkr_serials]speakers 메소드 안에서, self.speakers를 읽는 시도는 속성 그 자체를 호출하며 RecursionError 예외를 일으킵니다. 그러나 만약 동일한 데이터를 self.__dict__['speakers']를 통해 읽는다면, 속성 검색을 위한 파이썬의 일반적인 알고리즘들이 우회되고 속성이 호출되지 않으며 무한 재귀호출을 피할 수 있습니다. 이러한 이유 때문에, 객체의 __dict__를 직접 읽고 쓰는 것은 일반적인 파이썬 메타프로그래밍의 기법입니다.
위에서 구현한 speakers 속성에서 리스트 컴프리헨션의 사용은 cost가 크다고 생각될 수 있습니다. 하지만 OSCON 데이터셋의 이벤트 레코드에는 speakers가 많지 않기 때문에 최적화 코드는 아직 불필요합니다. 하지만 속성을 캐싱하는 것은 일반적으로 필요합니다. 아래에서는 이 방법에 대해 알아보도록 하겠습니다.
Step 4: Bespoke Property Cache
속성을 캐싱하는 것 event.venue와 같은 표현식의 cost가 크지 않아야 하기 때문에 일반적으로 필요합니다. Event 속성 뒤에 있는 Record.fetch 메소드가 데이터베이스 또는 Web API를 쿼리하는 데 필요한 경우 캐싱이 필요할 수 있습니다.
커스텀 캐싱 로직을 speakers 속성에 적용하면 다음과 같습니다.
@property
def speakers(self):
# 인스턴스가 __speakers_objs 속성을 가지고 있지 않다면, speaker 객체를 fetch하고 해당 속성에 저장한다
if not hasattr(self, '__speaker_objs'):
spkr_serials = self.__dict__['speakers']
fetch = self.__class__.fetch
self.__speaker_objs = [fetch(f'speaker.{key}') for key in spkr_serials]
return self.__speaker_objs # self.__speaker_objs를 반환한다이렇게 수작업한 캐싱은 간단하지만 인스턴스가 초기화된 후 속성을 생성하면 PEP 412(key-sharing dictionary)의 최적화를 무력화합니다. 데이터셋의 크기에 따라서, 메모리 사용량의 차이는 중요할 수 있습니다.
key-sharing 최적화와 잘 동작하는 유사한 솔루션을 사용하려면 Event 클래스에 대해 __init__()을 작성하여 None으로 초기화된 __speaker_objs를 만든 다음 speakers 메소드에서 이를 확인하면 됩니다. 즉, 다음 코드처럼 작성합니다.
class Event(Record):
def __init__(self, **kwargs):
self.__speaker_objs = None
super().__init__(**kwargs)
# ... 생략
@property
def speakers(self):
if self.__speaker_objs is None:
spkr_serials = self.__dict__['speakers']
fetch = self.__class__.fetch
self.__speaker_objs = [fetch(f'speaker.{key}') for key in spkr_serials]
return self.__speaker_objs
위에서 살펴본 2가지 방법의 캐싱은 레거시 Python 코드에서 일반적으로 사용되는 캐싱 기법을 보여줍니다. 그러나 다중 스레드 프로그램에서 이와 같이 수작업으로 구현된 캐시는 데이터 충돌을 일으킬 수 있는 race condition을 발생시킵니다. 두 스레드가 이전에 캐시되지 않은 속성을 읽는 경우 첫 번째 스레드는 캐시 속성(예제에서 __speaker_objs)에 대한 데이터를 계산해야 하고, 두 번째 스레드는 아직 완료되지 않은 캐시된 값을 읽을 수 있습니다.
다행히 파이썬 3.8에는 스레드로부터 안전한 @functools.cached_property 데코레이터가 도입되었습니다. 다만, 아래에서 설명하겠지만 여기에는 몇 가지 주의 사항이 있습니다.
Step 5: Caching Properties with functools
functools 모듈은 캐싱을 위한 3가지 데코레이터를 제공합니다. @cache와 @lru_cache는 아래 포스팅에서 살펴봤습니다.
[Python] 데코레이터와 클로저
References Fluent Python Contents Decorators Basic Registration Decorators Variable Scope Rules Closures nonlocal Decorators in the Standard Library : cache, lru_cache, singledispatch Parameterized..
junstar92.tistory.com
functools.cached_property 데코레이터는 동일한 이름의 인스턴스 속성에 메소드의 결과를 캐싱합니다. 예를 들어, 아래처럼 작성된 venue 메소드는 venue 메소드에 의해 연산된 값을 self의 venue 속성에 저장합니다. 이후에, 클라이언트 코드가 venue를 읽으려고 시도하면, 새롭게 생성된 venue 인스턴스 속성이 메소드 대신 사용됩니다.
@cached_property
def venue(self):
key = f'venue.{self.venue_serial}'
return self.__class__.fetch(key)
Step 3에서 프로퍼티는 같은 이름의 인스턴스 속성을 가려준다는 것을 봤습니다. 이것이 사실이라면, @cached_property는 어떻게 동작할 수 있을까요? 만약 프로퍼티가 인스턴스 속성을 오버라이드한다면, venue 속성은 무시되고 venue 메소드가 항상 호출되며 매번 key를 계산하고 fetch를 실행할 것입니다.
사실 cached_property는 잘못 지어진 이름입니다. @cached_property는 완전한 자질을 갖춘 프로퍼티를 생성하지 않습니다. @property는 overriding descriptor를 생성하지만, @cached_property는 non-overriding descriptor를 생성합니다. Descriptor는 다음 포스팅에서 살펴보도록 하겠습니다.
지금은 사용자 관점에서 cached_property와 property의 차이점에 대해 집중하도록 하겠습니다. 파이썬 문서(link)에서는 이 둘의 차이점에 대해서 설명해주고 있습니다.

우리가 구현한 Event 클래스로 돌아와서, @cached_property의 구체적인 동작은 speakers를 데코레이트하기에 부적절합니다. 이는 이 메소드가 speakers라는 이름의 속성이 존재하느냐에 따라 달라지기 때문입니다.

이러한 제약에도 불구하고 @cached_property는 일반적인 요구사항을 간단한 방법으로 해결하며, thread-safe합니다.
@cached_property 문서는 대안의 방법을 권장하며 이는 speakers에 사용할 수 있으며, 단지 @property와 @cache 데코레이터를 쌓아서 작성하면 됩니다.
# 순서는 중요하다. @property가 가장 위에 와야함
@property
@cache
def speakers(self):
if self.__speaker_objs is None:
spkr_serials = self.__dict__['speakers']
fetch = self.__class__.fetch
self.__speaker_objs = [fetch(f'speaker.{key}') for key in spkr_serials]
return self.__speaker_objs # self.__speaker_objs를 반환한다이렇게 쌓여진 데코레이터는 다음과 같이 동작합니다.
speakers = property(cache(speakers))
최종 구현된 클래스들은 다음과 같습니다.
import inspect
import json
from functools import cache, cached_property
JSON_PATH = 'osconfeed.json'
class Record:
__index = None
def __init__(self, **kwargs):
self.__dict__.update(kwargs)
def __repr__(self):
cls_name = self.__class__.__name__
return f'<{cls_name} serial={self.serial!r}>'
@staticmethod
def fetch(key):
if Record.__index is None:
Record.__index = load()
return Record.__index[key]
class Event(Record):
def __init__(self, **kwargs):
self.__speaker_objs = None
super().__init__(**kwargs)
def __repr__(self):
if hasattr(self, 'name'):
cls_name = self.__class__.__name__
return f'<{cls_name} {self.name!r}>'
else:
return super().__repr__()
@cached_property
def venue(self):
key = f'venue.{self.venue_serial}'
return self.__class__.fetch(key)
@property
@cache
def speakers(self):
if self.__speaker_objs is None:
spkr_serials = self.__dict__['speakers']
fetch = self.__class__.fetch
self.__speaker_objs = [fetch(f'speaker.{key}') for key in spkr_serials]
return self.__speaker_objs
def load(path=JSON_PATH):
records = {}
with open(path) as fp:
raw_data = json.load(fp)
for collection, raw_records in raw_data['Schedule'].items():
record_type = collection[:-1]
cls_name = record_type.capitalize()
cls = globals().get(cls_name, Record)
if inspect.isclass(cls) and issubclass(cls, Record):
factory = cls
else:
factory = Record
for raw_record in raw_records:
key = f'{record_type}.{raw_record["serial"]}'
records[key] = factory(**raw_record)
return records
Using a Property for Attribute Validation
지금까지는 read-only 프로퍼티와 캐싱 데코레이터에 대해서 살펴봤습니다. 이번에는 read/write 프로퍼티를 살펴보도록 하겠습니다.
속성 값을 연산하는 것뿐만 아니라, 프로퍼티는 public 속성을 클라이언트 코드에 영향을 끼치지 않으면서 getter와 setter로 관리하는 속성으로 변경함으로써 비즈니스 로직을 강제하기 위해 사용되기도 합니다. 조금 더 확장된 예제를 통해서 이를 살펴보도록 하겠습니다.
LineItem #1: Class for an Item in an Order
유기농 음식을 판매하는 상점을 위한 앱을 상상해보겠습니다. 이 상점에서 고객은 땅콩, 견과류, 시리얼을 무게로 주문할 수 있습니다. 이 시스템에서 각각의 주문에는 일련의 품목명(line item)이 들어가며, 각 품목명은 아래의 클래스로 표현됩니다.
class LineItem:
def __init__(self, description, weight, price):
self.description = description
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price너무 심플한 것 같은데, 이 클래스는 다음과 같이 동작합니다.

아주 간단한 예제이지만, 생각만큼 나이스하게 작동하지는 않습니다.
이 문제는 어떻게 고쳐야 할까요? LineItem의 인터페이스를 변경해서 weight 속성에 getter와 setter를 사용할 수 있습니다. 하지만 이는 자바와 같은 언어의 방식이며 잘못된 것은 아닙니다.
하지만 상품의 무게에 직접 값을 할당해서 설정하는 것이 자연스럽습니다. 그리고 이 시스템의 다른 부분에서 이미 item.weight 속성에 접근하고 있을지도 모릅니다. 이럴 때는 데이터 속성을 프로퍼티로 변경하는 게 파이썬스러운 방법입니다.
LineItem #2: A Validating Property
프로퍼티를 구현하면 getter/setter 메소드를 사용할 수 있지만, LineItem의 인터페이스는 바뀌지 않습니다. 즉, 프로퍼티를 구현해도 LineItem의 weight 속성을 설정하기 위해 여전히 raisins.weight = 12와 같이 사용할 수 있습니다.
다음은 read/write가 가능한 weight 프로퍼티 코드를 보여줍니다.
class LineItem:
def __init__(self, description, weight, price):
self.description = description
# 프로퍼티의 setter가 이미 사용되도록해서,
# 음수의 weight를 가진 인스턴스가 생성되지 않도록 한다
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
@property # @property로 getter 메소드를 데코레이트 한다
def weight(self): # 프로퍼티를 구현하는 메소드는 모두 public 속성명
return self.__weight # 실제 값은 private 속성인 __weight에 저장
# 데코레이트된 getter는 .setter 속성을 가지고 있으며, 이 또한 데코레이터임
# 이를 통해 getter와 setter를 연결함
@weight.setter
def weight(self, value):
if value > 0:
# 값이 0보다 크면 __weight를 그 값으로 설정
self.__weight = value
else:
# 그렇지 않으면 ValueError를 발생시킴
raise ValueError('value must be > 0')이제 LineItem 객체를 생성할 때 무게를 잘못 입력하면 다음과 같이 ValueError가 발생합니다.

이제 사용자가 잘못된 무게를 지정하지 못하도록 보호 장치를 마련했습니다. 그런데 일반적으로 구매자가 항목의 단가(price)를 설정할 수 없지만, 실수 또는 버그로 인해서 LineItem의 단가가 음수가 될 수도 있습니다. 이 문제를 방지하기 위해 price도 프로퍼티로 만들 수 있지만, 그러면 비슷한 코드를 반복하게 됩니다.
Paul Graham은 '프로그램 안에 패턴이 보이면, 이것을 문제의 징조라고 생각한다'라고 했습니다. 반복을 해결하는 방법은 추상화입니다. 프로퍼티 정의를 추상화하려면 프로퍼티 팩토리나 디스크립터 클래스(descriptor class)를 사용합니다. 특히 디스크립터 클래스는 flexible하며, 이는 다음 포스팅에서 다루어보도록 할 예정입니다. 사실 프로퍼티 자체도 디스크립터 클래스로 구현됩니다. 이번 포스팅에서는 프로퍼티 팩토리를 함수로 구현함으로써 프로퍼티 사용법에 대해서 계속 알아보도록 하겠습니다.
하지만, 프로퍼티 팩토리를 구현하기 전에 프로퍼티에 대해서 좀 더 깊게 이해하는 시간을 가져보도록 하겠습니다.
A Proper Look at Properties
내장된 property()는 비록 데코레이터로 사용되는 경우가 많지만, 사실상 클래스입니다. 파이썬에서 함수와 클래스는 서로 교환할 수 있는 경우가 많습니다. 함수와 클래스 모두 콜러블이고 객체를 생성하기 위한 new 연산자가 없으므로, 생성자를 호출하는 것은 팩토리 함수를 호출하는 것과 차이가 없습니다. 그리고 데코레이트된 함수를 적절히 대체할 수 있는 콜러블(callable)을 생성한다면 둘 다 데코레이터로 사용할 수 있습니다.
property() 생성자의 전체 시그니처(signature)는 다음과 같습니다.
property(fget=None, fset=None, fdel=None, doc=None)모든 인수는 옵셔널이며, 인수에 함수를 제공하지 않으면 생성된 프로퍼티 객체가 해당 연산을 지원하지 않습니다.
property 타입은 파이썬 2.2에서 추가되었지만, @기호를 사용한 데코레이터 구문은 파이썬 2.4에서 도입되었습니다. 따라서 수년간 접근자 함수를 앞의 두 인수로 전달함으로써 프로퍼티를 정의했습니다.
다음 코드는 데코레이터를 사용하지 않고 프로퍼티를 정의하는 클래식한 문법을 보여줍니다.
class LineItem:
def __init__(self, description, weight, price):
self.description = description
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
# getter
def get_weight(self):
return self.__weight
# setter
def set_weight(self, value):
if value > 0:
self.__weight = value
else:
raise ValueError('value must be > 0')
# property 객체를 생성하고 클래스의 public 속성에 할당
weight = property(get_weight, set_weight)경우에 따라서는 이 클래식한 구문이 데코레이터 구문보다 나을 때도 있는데, 곧 이어 설명할 데코레이터 구문이 바로 그 사례입니다. 한편 메소드가 많이 있는 클래스 바디 안에서 프로퍼티는 메소드명 앞에 get과 set을 사용하는 관례에 의존하지 않고도 어느 것이 getter고, 어느 것이 setter인지 명확히 보여줍니다.
클래스 안에 프로퍼티가 존재하면 그 클래스의 안에 있는 속성을 찾는 방식에 영향을 미칩니다. 아래에서 살펴보도록 하겠습니다.
Properties Override Instance Attributes
프로퍼티는 언제나 클래스속성이지만, 실제로는 클래스의 인스턴스에 들어 있는 속성에 대한 접근을 관리합니다.
만약 인스턴스와 클래스가 모두 동일한 이름의 속성을 가지고 있으면, 인스턴스를 통해 속성에 접근할 때 인스턴스 속성이 클래스 속성을 가립니다. 다음 예제 코드는 이러한 현상을 잘 보여줍니다.

이제 obj 객체의 prop 속성을 덮어써보도록 하겠습니다. 위의 콘솔 세션에 이어서 다음의 예제 코드들을 실행합니다.

마지막으로 Class에 새로운 프로퍼티를 추가하고, 이 프로퍼티가 인스턴스 속성을 가리는 것을 확인합니다.

위 예제에서 설명하고자 하는 요점은 obj.data 같은 표현식이 obj에서 data을 검색하는 것이 아니라는 것입니다. 일반적으로 검색은 obj.__class__에서 시작하고, 클래스 안에 data이라는 이름의 프로퍼티가 없을 때만 파이썬이 obj 객체(인스턴스)를 살펴봅니다. 이 규칙은 overriding descriptors에도 적용됩니다. 사실 프로퍼티는 overriding descriptor의 한 예입니다.
Property Documentation
이번에는 문서를 프로퍼티에 연결하는 방법에 대해 알아보겠습니다.
콘솔의 help() 함수나 IDE 같은 도구가 프로퍼티에 대한 문서를 보여주어야 할 때 프로퍼티의 __doc__ 속성에서 정보를 가져옵니다.
클래식한 호출 구문을 사용하는 경우에는 property()가 doc 인수로 전달된 문자열을 받습니다.
weight = property(get_weight, set_weight, doc='weight in kilograms')
프로퍼티를 데코레이터로 사용하는 경우에는 @property로 데코레이트된 getter 메소드의 docstring이 프로퍼티 전체의 문서로 사용됩니다.
다음은 클래스 정의 코드와 이를 사용한 help 화면입니다.
class Foo:
@property
def bar(self):
'''The bar attribute'''
return self.__dict__['bar']
@bar.setter
def bar(self, value):
self.__dict__['bar'] = value
프로퍼티에 대한 설명은 이것으로 마무리하고, 이제 다시 LineItem 클래스로 돌아가서 동일한 getter/setter를 직접 구현하지 않고도 LineItem의 weight와 price 속성이 0보다 큰 값만 받을 수 있도록 보호하는 방법에 대해서 살펴보도록 하겠습니다.
Coding a Property Factory
여기서 quantity()라는 프로퍼티 팩토리를 만들도록 하겠습니다. 이 팩토리가 관리하는 속성은 0보다 큰 값만 가져야 한다는 의미에서 quantity라는 이름을 붙였습니다. 아래 코드는 두 개의 quantity 프로퍼티 객체를 이용해서 정의한 깔끔한 LineItem 클래스를 보여줍니다. 프로퍼티 객체 하나는 weight 속성을, 다른 하나는 price 속성을 관리합니다.
class LineItem:
# 팩토리를 이용해서 weight/price를 클래스 속성으로 정의
weight = quantity('weight')
price = quantity('price')
def __init__(self, description, weight, price):
self.description = description
# 프로퍼티가 활성화되어 있으므로 0이나 음수가 되지 않도록 보장함
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
프로퍼티는 클래스 속성이라는 점에 주의합니다. quantity() 프로퍼티를 생성할 때 해당 프로퍼티에 의해 관리된 LineItem 속성의 이름을 전달해야 합니다.
weight = property('weight')weight라는 단어를 두 번이나 입력하는 것이 좋아보이지는 않지만, 프로퍼티가 어느 클래스 속성명에 바인딩해야 할지 알 수 있는 방법이 없으므로, 이렇게 반복하지 않으면 복잡해집니다. 할당문의 오른쪽이 먼저 평가되므로 quantity()가 호출될 때 weight 클래스 속성은 존재하지 않음에 주의합니다.
이처럼 속성명을 두 번 입력하지 않도록 개선하려면 아주 복잡한 메타프로그래밍 기법을 사용해야 합니다
다음 코드는 quantity() 프로퍼티 팩토리를 구현합니다.
def quantity(storage_name): # storage_name 인수는 각 프로퍼티를 어디에 저장할 지 결정
def qty_getter(instance):
# 이 함수는 storage_name를 참조하므로, storage_name은 이 함수의 클로저에 보관됨
# 프로퍼티를 사용하면 무한히 재귀호출되므로, 프로퍼티를 우회하기 위해 __dict__에서 직접 속성을 가져옴
return instance.__dict__[storage_name]
def qty_setter(instance, value):
if value > 0:
instance.__dict__[storage_name] = value
else:
raise ValueError('value must be > 0')
return property(qty_getter, qty_setter) # 커스텀 프로퍼티 객체를 생성해서 반환위의 코드에서 storage_name 변수 주변의 코드를 주의 깊게 살펴보겠습니다. 프로퍼티를 전통적인 방식으로 구현하는 경우에는 값을 저장할 속성명이 getter와 setter 안에 하드코딩됩니다. 그러나 여기서 qty_getter()와 qty_setter()는 범용 함수로서, 객체의 __dict__ 안에 있는 어느 속성에서 값을 가져오고 어느 속성에 값을 저장할지 판단하기 위해 storage_name에 의존합니다. quantity() 팩토리 함수가 호출될 때마다 프로퍼티를 생성하므로, storage_name은 고유한 값으로 설정되어야 합니다.
qty_getter()와 qty_setter() 함수는 팩토리 함수의 마지막 행에서 생성된 property 객체에 의해 래핑됩니다. 나중에 호출될 때 이 함수들은 자신의 클로저에서 storage_name을 가져와서 어느 속성을 읽고, 어느 속성에 저장할지 결정합니다.
다음 예제 코드는 이렇게 구현된 LineItem 객체를 생성하고 조사해서 값을 저장하는 속성을 보여줍니다.

팩토리가 만든 프로퍼티가 위에서 설명한 인스턴스 속성을 가리는 특징을 잘 보여줍니다. weight 프로퍼티는 weight 인스턴스 속성을 가리므로 self.weight나 nutmeg.weight로 참조하는 것은 모두 프로퍼티 함수에 의해 처리되며, 객체의 __dict__에 접근하는 방법을 이용해야 이 로직을 우회할 수 있습니다.
이렇게 정의한 quantity()는 약간 까다롭지만, 길이로만 본다면 weight 프로퍼티의 getter와 setter 메소드와 같습니다. 하지만 quantity()를 사용한 LineItem 정의는 getter와 setter로 어지럽혀져 있지 않으므로 훨씬 더 보기 좋습니다.
실제 시스템에서는 이런 형태의 검증을 여러 필드에서 볼 수 있으며, quantity() 프로퍼티 팩토리는 유틸리티 모듈에 넣어 계속 사용할 수 있습니다. 결국 이 간단한 팩토리는 리팩토링을 통해 확장성이 향상된 디스크립터 클래스가 되며, 특화된 서브클래스는 여러 가지 다른 형태의 검증을 수행할 수 있습니다. 이에 대한 예제들은 다음 포스팅에서 살펴보도록 하겠습니다.
Handling Attribute Deletion
이제 속성을 제거하는 문제에 대한 내용을 알아보도록 하겠습니다.
del 문을 이용하면 객체의 속성을 제거할 수 있습니다.
del my_object.an_attribute사실 속성을 제거하는 연산은 파이썬에서 항상 수행하는 연산은 아니며, 프로퍼티로 처리해야 하는 경우는 더더욱 드뭅니다. 그러나 프로퍼티로 속성을 제거하는 연산이 지원되며, 다음과 같이 이상한 예제를 볼 수 있습니다.
프로퍼티 정의에서 @my_property.deleter 데코레이터는 이 프로퍼티에 의해 관리되는 속성을 제거하는 역할을 담당합니다. 아래 예제 코드는 프로퍼티 deleter를 구현하는 방법을 보여주는 바보같은 예제입니다.
class BlackKnight:
def __init__(self):
self.phrases = [
('an arm', "'Tis but a scratch."),
('another arm', "It's just a flesh wound."),
('a leg', "I'm invincible!"),
('another leg', "All right, we'll call it a draw.")
]
@property
def member(self):
print('next member is:')
return self.phrases[0][0]
@member.deleter
def member(self):
member, text = self.phrases.pop(0)
print(f'BLACK KNIGHT (loses {member}) -- {text}')
이 예제 코드는 다음과 같이 동작합니다.

데코레이터 대신 고전적인 구문을 사용할 때는 fdel 인수를 사용해서 deleter 함수를 설정합니다. 예를 들어, 위의 BlackKnight 클래스의 바디에서는 다음과 같이 member 프로퍼티를 구현할 수 있습니다.
member = property(member_getter, fdel=member_deleter)
프로퍼티를 사용하지 않을 때는 low-level의 __delattr__() 스페셜 메소드를 구현해서 속성을 제거할 수 있습니다.
프로퍼티는 강력한 기능이지만, 더 간단하거나 low-level의 다른 방법이 좋을 때도 있습니다. 마지막으로 동적 속성 프로그래밍을 위해 파이썬이 제공하는 핵심 API 몇 가지를 살펴보고 포스팅을 마무리 하도록 하겠습니다.
Essential Attributes and Functions for Attribute Handling
지금까지 동적 속성을 처리하기 위해 파이썬이 제공하는 몇 가지 내장 함수와 스페셜 메소드를 사용했습니다. 이번에는 이 속성과 메소드를 한 곳에 모아서 간략히 정리합니다.
Special Attributes that Affect Attribute Handling
뒤에서 설명할 함수와 스페셜 메소드의 동작은 다음의 3가지 스페셜 속성에 의존합니다.
- __class__ :
객체의 클래스에 대한 참조(즉, obj.__class__는 type(obj)와 동일). 파이썬은 __getattr__()과 같은 스페셜 메소드를 객체(인스턴스) 자체가 아닌 객체의 클래스에서만 검색합니다. - __dict__ :
객체나 클래스의 쓰기가능 속성을 저장하는 매핑. __dict__를 가진 객체는 임의의 새로운 속성을 언제든지 설정할 수 있습니다. 클래스에 __slots__ 속성이 있으면, 이 클래스의 객체에는 __dict__가 없을 수도 있습니다. - __slots__ :
자신의 객체가 가질 수 있는 속성을 제한하려고 클래스에 정의하는 속성. __slots__은 허용된 속성명을 담은 일종의 튜플입니다. __dict__가 __slots__에 들어 있지 않으면, 이 클래스의 객체는 자체적인 __dict__를 가질 수 없고, __slots__에 나열된 속성만 만들 수 있습니다.
Build-In Functions for Attributes Handling
아래의 다섯 함수는 읽기/쓰기/내부 조사(intorspection)를 할 수 있습니다.
- dir([object]) :
대부분의 객체 속성을 나열합니다. 공식 문서(link)에 따르면 dir()은 대화형 세션에서 사용하기 위한 것으로 전체 속성의 리스트를 제공하지는 않지만 "흥미로운" 속성명들을 나열합니다. 객체에 __dict__가 있뜬 없든 dir()는 객체 내부를 조사할 수 있습니다. __dict__ 자체는 dir()이 나열하지 않지만, __dict__에 들어 있는 키들은 나열합니다. __mco__(), __bases__(), __name__() 등의 스페셜 메소드도 dir()이 나열하지 않습니다. dir()의 object는 선택적 인수로서, 이 인수를 지정하지 않으면 현재 스코프에 있는 이름들을 나열합니다. - getattr(object, name[, default]) :
object에서 name 문자열로 식별된 속성을 가져옵니다. 객체의 클래스나 슈퍼클래스에서 속성을 가져올 수 있습니다. 이러한 속성이 존재하지 않으면 getattr()은 AttributeError를 발생시키거나 default 값을 반환합니다. - hasattr(object, name) :
해당 이름의 속성이 object에 있거나 상속 등의 메커니즘으로 가져올 수 있으면 True를 반환합니다. 공식 문서(link)에 따르면 이 메소드는 getattr(object, name)을 호출하고 AttributeError 예외가 발생하는지 아닌지 확인하도록 구현되어 있습니다. - setattr(object, name, value) :
object가 허용하면 name 속성에 value를 할당합니다. 이 메소드에 의해 새로운 속성이 생성되거나 기존 속성의 값이 변경됩니다. - vars([object]) :
object의 __dict__를 반환합니다. dir() 메소드와 달리 __slots__은 있고 __dict__는 없는 클래스의 객체는 처리할 수 없습니다. 인수를 전달하지 않으면 현재 스코프의 __dict__를 가져오므로 locals()와 동일하게 동작합니다.
Special methods for Attribute Handling
다음의 스페셜 메소드를 커스텀 클래스에 구현하면, 이 스페셜 메소드들은 속성을 가져오고, 설정하고, 삭제하고 나열합니다.
점 표기법이나 getattr(), hasattr(), setattr() 내장 함수를 이용해서 속성에 접근하면, 실제로 여기에 나열된 스페셜 메소드를 호출합니다. __dict__에 직접 속성을 쓰거나 읽으면 스페셜 메소드를 호출하지 않는데, 이는 스페셜 메소드를 우회하기 위해 일반적으로 사용하는 방법입니다.
파이썬 공식 문서 "Special method lookup"(link)에서는 다음과 같은 주의를 줍니다.
커스텀 클래스의 경우 객체의 __dict__가 아니라 객체의 클래스에 정의되어야 암묵적으로 호출하는 스페셜 메소드가 제대로 동작한다.
즉, 동작의 타겟이 인스턴스인 경우에도 스페셜 메소드를 클래스 자체에서 가져온다고 가정합니다. 그렇기 때문에 스페셜 메소드는 동일한 이름의 속성이 객체에 있더라도 가려지지 않습니다.
아래에서 설명할 스페셜 메소드에는 Class라는 이름의 클래스, Class의 객체 obj, obj의 속성 attr이 있다고 가정하고 설명합니다.
여기에 나열된 스페셜 메소드들은 위에서 설명한 내장 함수를 사용하든, 점 표기법을 사용하든, 속성에 접근하면 호출됩니다. 예를 들어 abj.attr과 getattr(obj, 'attr', 42)는 모두 Class.__getattribute__(obj, 'attr')을 호출합니다.
- __delattr__(self, name) :
del문을 이용해서 속성을 제거하려 할 때 호출됩니다. 즉, del obj.attr은 Class.__delattr__(obj, 'attr')을 호출합니다. - __dir__(self) :
속성을 나열하기 위해 객체에 dir()을 호출할 때 호출됩니다. dir(obj)는 Class.__dir__(obj)를 호출합니다. - __getattr__(self, name) :
obj, Class, Class의 슈퍼클래스를 검색해서 명명된 속성을 가져오려는 시도하다 실패할 때 호출됩니다. 예를 들어, obj, Class, Class의 슈퍼클래스에서 no_such_attr이라는 속성을 찾을 수 없을 때 obj.no_such_attr, getattr(obj, 'no_such_attr'), hasattr(obj, 'no_such_attr')은 Class.__getattr__(obj, 'no_such_attr')을 호출합니다. - __getattribute__(self, name) :
스페셜 속성이나 메소드가 아닌 속성을 가져올 때 언제나 호출됩니다. 점 표기법 및 getattr()과 hasattr() 함수가 이 메소드를 호출합니다. __getattr__()은 __getattribute__()가 AttributeError를 발생시킨 후에만 호출됩니다. obj의 속성을 가져올 때 무한히 재귀적으로 호출되는 것을 방지하기 위해 __getattribute__()는 super().__getattribute__(obj, name)을 이용해야 합니다. - __setattr__(self, name, value) :
지명된 속성에 값을 설정할 때 언제나 호출됩니다. 점 표기법과 setattr() 함수가 이 메소드를 호출합니다. obj.attr = 42와 settattr(obj, 'attr', 42)는 모두 Class.__setattr__(obj, 'attr', 42)를 호출합니다.
실제로 __getattribute__()와 __setattr__() 스페셜 메소드는 무조건 호출되며 거의 모든 속성 접근에 영향을 미치므로, 존재하지 않는 속성만 처리하는 __getattr__()보다 제대로 구현하기 어렵습니다. 이런 스페셜 메소드를 정의하는 것보다 프로퍼티나 디스크립터를 이용하는 것이 에러를 줄이는 데 도움이 됩니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] Class Metaprogramming (0) | 2022.04.01 |
|---|---|
| [Python] Attribute Descriptor (0) | 2022.03.31 |
| [Python] Futures (0) | 2022.03.30 |
| [Python] Concurrency Models (0) | 2022.03.29 |
| [Python] 코루틴(Coroutines), yield from (0) | 2022.03.27 |




댓글