References
- Programming Massively Parallel Processors
Contents
- 부동소수점(Floating-Point) 표현, 표기법
- 특별한 비트 패턴과 정밀도(in IEEE Format)
- 산술 정확도와 자리맞춤(Rounding)
- 부동소수점 주의사항
Floating-point Data Representation (부동소수점 표현)
IEEE-754 부동소수점 표준은 컴퓨터 제조업에서 부동소수점데이터를 공통되게 표현하고 산술 연산하기 위한 노력으로 만들어졌습니다. 거의 대부분의 컴퓨터 제조업체에서 이 표준을 수용하고 사용하고 있습니다. 따라서 개발자들은 이 표준의 개념과 현실적인 고려사항들을 이해하는 것이 중요합니다.
부동소수점 수 체계는 어떤 수를 비트 패턴으로 표현하는 것부터 시작합니다. IEEE 부동소수점 표준에서 어떤 수는 3개의 비트 그룹으로 표현됩니다: 부호(S, sign), 지수(E, exponent), 가수(M, mantissa). 각 S, E, M 패턴은 다음의 형식에 따라서 수를 표현합니다.
\[\text{Value } = (-1)^S \times 1.M \times \{2^{E-\text{bias}}\} \tag{1}\]
S의 의미는 간단합니다. S=0은 양수를 의미하고, S=1은 음수를 의미합니다. M과 E비트 해석은 S보다는 복잡한데, 간단하게 설명하기 위해서 각 부동소수점 수가 1비트의 S, 3비트의 E, 2비트의 M으로 구성되어 있다고 가정하고, 총 가상의 6비트의 부동소수점 수로 살펴보겠습니다.
그리고 어떤 수에 대해 이야기할 때, 십진수나 이진수로 표현할 필요가 있는데 십진수는 아래첨자 D로 표기하고, 이진수는 아래첨자 B로 표기하도록 하겠습니다. 예를 들어, 0.5\(_D\)(== 5 x 10\(^{-1}\))는 0.1\(_B\)(== 1 x 2\(^{-1}\))와 같은 수입니다.
M의 정규 표현
위 식(1)에서 가수(M)을 1.M으로 처리하여 모든 값을 얻는데, 이는 각 부동소수점 숫자에 대한 가수 비트 패턴을 고유하게 만들어줍니다. 예를 들어, 아래 0.5\(_D\)에 허용되는 유일한 가수 비트 패턴은 M = 0인 패턴입니다.
\[0.5_D = 1.0_B \times 2^{-1}\]
\(0.1_B \times 2^0\)이나 \(10.0_B \times 2^{-2}\)로 표현할 수도 있겠지만, 이는 1.M 이라는 형식에 맞지 않습니다. 이러한 제한을 만족하는 수를 정규화된 수(normalized number)라고 합니다.
정규화된 표현을 만족하는 가수는 1.XX 형태이기 때문에 부동소수점을 표현할 때 '1'을 생략할 수 있습니다. 그러므로, 2비트의 M에서 0.5의 가수는 1.00이고 1을 생략하면 00이 됩니다. 결과적으로 2비트 가수를 3비트 가수로 표현할 수 있게 하며, 일반적으로 IEEE 형식에서 m-비트 가수는 (m+1)-비트 가수를 표현합니다.
Excess Encoding of E (초과표기법)
E를 표현하는데 사용되는 비트의 수는 표현할 수 있는 수의 범위를 결정합니다. 큰 양수의 E는 매우 큰 부동소수점 절대값을 나타냅니다. 예를 들어, E의 값이 64라면 부동소수점 수는 \(2^{64} (>10^{18})\)에서 \(2^{65}\) 사이의 수를 표현할 수 있습니다. 큰 음수의 E는 매우 작은 부동소수점 수를 표현할 수 있는데, E의 값이 -64라면 표현할 수 있는 수의 범위는 \(2^{-64} (< 10^{-18})\) 에서 \(2^{-63}\) 사이입니다. 이는 매우 작은 수입니다. 부동소수점 수의 표현에서 E 필드는 정수 표현보다 더 넓은 범위의 수를 표현할 수 있습니다.
IEEE 표준은 excess or biased 인코딩 규칙을 채택했습니다. 만약 지수 E를 표현하기 위해 e 비트가 사용되었다면, (\(2^{e-1}-1\))이 그 지수에 대한 2의 보수값에 더해져서 excess representation(초과 표현)을 나타냅니다.
3비트 지수에서는 지수 E에 3개의 비트가 있습니다(e = 3). 따라서, \(2^{3-1}-1 = 011\)이 지수 값에 대한 2의 보수값에 더해집니다.
Excess Representation의 장점은 부호가 없는 비교기(unsigned comparator)를 통해 부호가 있는 숫자를 비교할 수 있다는 것입니다. 아래 표는 3비트 지수 표현에서 정렬된 excess-3 비트 패턴을 볼 때, -3에서 3으로 증가하는 것을 보여줍니다.

각각의 비트 패턴에 해당되는 값을 코드라고 칭합니다. 예를 들어, -3의 코드는 000이고, 3의 코드는 110입니다. 따라서 부호가 없는 숫자 비교기를 사용하여 임의의 숫자의 excess-3 코드를 비교한다면, 비교기는 어떤 숫자가 크고 작은지 정확한 비교 결과를 알려줍니다.
다른 예시로, 만약 excess-3 코드 001과 100을 비교한다면, 001은 100보다 작다고 결과를 알려주고 두 값이 나타내는 값이 -2와 1이기 때문에 올바른 결과가 됩니다.
Unsigned Comparator는 Signed Comparator보다 작고 빠르기 때문에 하드웨어 구현 측면에서도 바람직합니다.
위 표에서 모든 비트가 1인 excess representation 패턴은 reserved 패턴입니다. IEEE 표준이 이 특별한 비트 패턴을 특별한 방법으로 사용하는데 뒤에서 다시 알아보겠습니다.
이제 6비트 형식의 부동소수점으로 \(0.5_D\)를 표현하면 다음과 같이 표현할 수 있습니다.
\[\begin{matrix} 0.5_D = 001000 && \text{where S=0, E=010, and M=(1.)00} \end{matrix}\]
즉 \(0.5_D\)의 6비트 표현은 001000 입니다.
일반적으로 정규화된 가수와 escess-coded 지수를 사용하여 n-비트 지수를 가지는 수의 값은 다음과 같습니다.
\[(-1)S \times 1.M \times 2^{(E-(2^{(n-1)}-1))}\]
표현 가능한 수
어떤 수 형식에서 표현 가능한 수들이란 그 형식으로 정확히 표현될 수 있는 수들을 의미합니다. 예를 들어, 3비트의 부호없는 정수 형식으로 표현 가능한 수는 다음과 같습니다.


여기서 -1이나 9는 이 형식으로는 표현할 수 없습니다.
비슷한 방식으로 부동소수점 형식에서 표현 가능한 수를 시각화할 수 있습니다. 아래 표에서 위에서 설명한 부동소수점 표기 형식(no-zero)과 두 개의 변형된 형식에 대해 표현 가능한 모든 수를 보여주고 있습니다. 표의 크기를 고려해서 5비트 형식을 사용했는데, 이 형식은 1비트 S, 2비트 E(excess-2 code), 그리고 2비트 M('1.'이 생략됨)으로 구성됩니다.

no-zero 형식으로 나타낼 수 있는 수는 다음과 같습니다. 표현 가능한 양수만 나타나있는데, 음수는 0을 기준으로 대칭되어 존재합니다. (0은 표현할 수 없습니다.)

위 그림으로 다섯 가지를 관찰할 수 있습니다.
첫번째, 지수 비트가 표현 가능한 수들의 주요 간격(major interval)을 정의합니다. 여기서 지수가 두 개의 비트로 구성되기 때문에 0일 기준으로 3개의 주요 간격들이 존재합니다. 그 간격들은 2의 승수 사이가 됩니다. 두 개의 지수 비트를 사용하면 3개의 2의 승수(\(2^{-1}=0.5_D, 2^0=1.0_D, 2^1=2.0_D\)가 존재하고, 각각은 표현 가능한 수에서 간격의 시작점이 됩니다.
두번째, 가수 비트가 각 간격의 표현 가능한 수의 개수를 정의합니다. 가수 비트가 2개이면 각 간격에는 4개의 표현 가능한 수가 존재합니다. 일반적으로 N개의 가수 비트가 있다면 각 간격에는 \(2^N\)의 표현 가능한 수가 존재합니다. 만약 표현해야하는 수의 값이 이 간격들 중 하나에 해당한다면, 이 표현 가능한 수들 중 하나로 자리 맞춤됩니다. 각 간격에 표현 가능한 수가 많으면 많을수록 그 범위에 존재하는 수를 보다 정밀하게 표현할 수 있을 것 입니다.
따라서, 가수 비트의 개수가 표현의 정밀도(precision)을 결정합니다.
세번째, 이 포맷으로는 0을 표현할 수 없다는 것입니다. 위의 표의 no-zero열에 보면 표현 가능한 수에 0이 없습니다. 0은 수에서 가장 중요한 숫자중 하나이기 때문에 수 표현 체계에서 0을 표현할 수 없다는 점은 심각한 결함입니다. 이 결함에 대해서는 뒤에서 다시 다루도록 하겠습니다.
네번째, 숫자가 0에 가까워질수록 표현 가능한 수들은 서로 더 가까워진다는 점입니다. 각 간격의 크기는 0에 가까이 갈수록 이전 간격 크기의 절반입니다. 2~4까지 간격의 크기는 2, 1~2까지 간격 크기는 1, 0.5~1까지 간격 크기는 0.5입니다. 위 그림에서 음수쪽은 표시가 안되어 있는데, 가장 왼쪽의 간격의 크기는 2, 그 다음은 1, 그리고 그 다음 간격은 0.5입니다. 모든 간격이 동일한 개수의 표현 가능한 수를 가지기 때문에 0에 가까이 갈수록 표현 가능한 수들은 서로 더 가까워지는 것입니다. 다시 말하면, 절대값이 크기가 작으면 작을수록 더 가까워집니다. 이는 절대값의 크기가 작을수록 그 수들을 보다 정확하게 표현하는 것이 더 중요하기 때문에 바람직한 경향입니다.
다섯번째, 네번째에서 이야기한 0에 가까워질수록 정확도가 증가하는 것은 0의 바로 근처에서는 적용되지 않습니다. 0의 부근에서는 표현 가능한 수에 공백이 있는데, 이는 정규화된 가수의 범위에 0이 포함되지 않기 때문입니다. 이는 또 다른 심각한 결함입니다. 이 표현은 0.5와 1.0사이 간격의 수들에 대한 오차를 비교했을 때, 0과 0.5 사이 간격에서 상당히 더 큰 오차(x4)를 발생시킵니다. 일반적으로 m비트 가수를 사용할 때, 이 방식의 표현은 0과 가장 가까운 간격이 그 다음 간격에 비해서 \(2^M\)배 더 큰 오차를 발생시킵니다.
매우 작은 데이터 값에 근거하여 수렴조건을 정확히 판별해야 하는 수치계산법의 경우, 이러한 결함은 수행시간과 결과의 정확성에 있어서 불안정할 수 있습니다. 더 나아가, 어떤 알고리즘들은 작은 수들을 생성하여 그 수들을 분모로 사용하기도 합니다. 이 작은 수들을 표현할 때 발생하는 오차는 나누기 과정에서 크게 확대되어 계산의 불안정을 초래합니다.
Abrupt Underflow
정규화된 부동소수점 수 체계에 0을 포함할 수 있는 방법 중 하나가 위 표의 두 번째 열에 있는 abrupt underflow 규칙입니다. E가 0일 때, 그 수는 0으로 해석됩니다. 표에서 사용된 5-비트 형식에서 이 방법은 0 부근(-1.0~+1.0)의 8개의 표현 가능한 수(4개의 양수와 4개의 음수)를 없애버리고 그 수들을 모두 0으로 만들어버립니다. 단순함 때문에, 1980년대 미니 컴퓨터에서는 abrupt underflow를 사용했습니다.

오늘날에도 빨리 동작해야하는 일부 산술연산 유닛은 abrupt underflow 규칙을 사용합니다. 이 방법은 0을 표현 가능한 숫자로 만들지만, 위 그림과 같이 0 근처의 표현 가능한 숫자 사이에 훨씬 더 큰 간격을 만듭니다. no-zero 형식에서 0.5~1.0 사이의 간격의 2배(0~1.0)가 되었습니다. 앞서 언급했듯이, 이는 0에 가까운 작은 숫자의 정확한 표현에 의존하는 많은 수치 알고리즘에는 문제가 될 수 있습니다.
Denormalization
IEEE 표준에서 실제 채택한 방법은 denormalization 규칙입니다. 이 방법은 0과 매우 가까운 수들에 대해서 정규화 요구사항(normalization requirement)를 완화합니다. E = 0일 때, 가수는 더 이상 1.XX의 형태가 아니고, 0.XX로 간주합니다. 이때, 지수의 값은 이전 간격과 동일하다고 가정합니다.
예를 들어, 위의 표에서의 denoramlization 표현 00000에서 지수의 값은 00, 가수의 값은 01 입니다. 가수는 0.01\(_B\)로 간주되고, 지수의 값은 이전 간격(interval)의 지수 값인 0이 됩니다. 즉, 00001이 표현하는 값은 \(0.01_B \times 2^0 = 2^{-1}\) 입니다. 아래 표는 denormalized format에서의 표현 가능한 수를 보여줍니다.

0의 근처에서 표현 가능한 수들은 이제 균등하게 분포되어 있습니다.

직관적으로 표현하면, no-zero의 마지막 간격(0.5~1.0)의 4개의 수를 공백 영역에 골고루 흩어놓았다고 볼 수 있습니다.
이 방법으로 이전 두 표현 방식이 가지고 있던 바람직하지 않은 공백이 사라졌습니다.
일반적으로 n-비트의 지수가 0이라면, 값은 다음과 같습니다.
\[0.M \times 2^{-2^{(n-1)} + 2}\]
보다시피 denormalization 공식은 조금 복잡합니다. 하드웨어 또한 숫자가 denormalization 간격에 속하는지의 여부를 감지하고 해당 숫자에 대한 적절할 표현을 선택할 수 있어야 합니다. 빠른 속도로 denormalization을 구현하는 데 필요한 하드웨어 리소스는 상당합니다. 적당한 양의 하드웨어 리소스에서 denormalized number를 생성하거나 사용할 때마다 수천 사이클의 클럭이 지연됩니다. 초기 CUDA 디바이스에서는 이러한 이유로 denormalization을 지원하지 않았는데, 최근에는 공정에 사용 가능한 트랜지스터 수가 증가함에따라 거의 모든 최신 CUDA 디바이스에서는 지원합니다.
구체적으로 Compute Capability 1.3 이상의 모든 CUDA 디바이스에서는 denormalized double-precision 피연산자를 지원하고, Compute Capability 2.0 이상의 디바이스에서는 denormalized single-precision 피연산자를 지원합니다.
요약하면, 부동소수점 표현의 정밀도는 어떤 부동소수점 수를 표현 가능한 부동소수점 수 중 하나로 표현할 때 발생하는 최대 오차로 측정될 수 있습니다. 오차가 작을수록 정밀도는 높아집니다. 가수에 더 많은 비트를 할당하여 부동소수점 표현의 정밀도를 높일 수 있습니다. 만약 가수에 1비트를 추가하면 최대 오차가 절반으로 줄어들어 정밀도가 향상됩니다. 따라서, 수 체계에서 가수에 더 많은 비트를 사용할 때 더 높은 정밀도를 가집니다.
이는 IEEE 표준의 double precision versus single precision numbers에 반영되어 있습니다.
특별한 비트 패턴과 정밀도
IEEE 형식은 특별한 비트 패턴을 하나 더 가지고 있습니다. 지수의 모든 비트가 1일 때 가수가 0이라면, 표현되는 수는 무한대입니다. 그리고 가수가 0이 아니라면 그 수는 Not a Number(NaN)입니다. 위에서 0을 표현할 때 봤던 표를 다시 가져왔습니다. 아래 표는 IEEE 부동 소수점 형식에 대한 모든 특별한 비트 패턴을 보여줍니다.
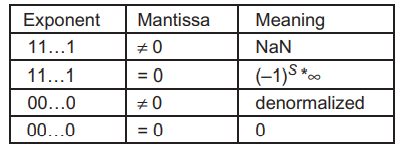
위 표에 없는 모든 다른 수들은 정규화된(normalized) 부동소수점 수입니다.
단정밀도(Single precision) 수들은 1비트의 S, 8비트의 E, 23비트의 M으로 구성되어 있습니다.
배정밀도(Double precision) 수들은 1비트의 S, 11비트의 E, 52비트의 M으로 구성됩니다.
배정밀도는 단정밀도에 비해서 29개의 가수 비트가 더 있습니다. 따라서 배정밀도로 수를 표현할 때의 최대 오차는 단정밀도 형식에 비해서 1/2\(^{29}\)로 감소합니다. 지수 비트는 3개 더 많은데, 이 때문에 배정밀도 형식은 표현 가능한 수의 간격의 개수를 더 확장합니다. 이 때문에 매우 작은 수들에서 뿐만아니라 매우 큰 수에서도 표현 가능한 수의 범위를 확장합니다.
모든 표현 가능한 수는 \(-\infty \sim +\infty\) 사이에 존재합니다. 양의 무한대는 오버플로우(overflow)에 의해서 생길 수 있는데, 예를 들면, 큰 수를 매우 작은 숫자로 나누는 경우가 있습니다. 그리고 어떤 표현 가능한 수를 \(+\infty\)나 \(-\infty\)로 나누면 그 결과는 0이 됩니다.
NaN은 입력이 말이 되지 않는 경우에 대한 연산이 수행될 때 발생합니다. 예를 들어, 0/0, 0 x \(\infty\), \(\infty / \infty\), \(\infty - \infty\)와 같은 연산입니다. 또한 NaN은 어떤 프로그램에서 데이터가 적절히 초기화되지 않고 사용될 때 사용됩니다.
IEEE 표준에는 두 종류의 NaN이 있는데, 하나는 Signaling NaN(SNaN)이고 다른 하나는 Quiet NaN 입니다. Signaling NaN은 가수 비트 중 최상위 비트를 0으로 설정하여 표현하고, Quiet NaN은 가수 비트의 최상위 비트를 1로 설정하여 표현합니다.
Signaling NaN은 SNaN이 산술연산의 입력으로 사용되었을 때 예외를 발생시킵니다. 예를 들어, (1.0 + signaling NaN)은 예외를 발생시킵니다. Signaling NaN은 프로그래머가 부동소수점 계산에서 어떤 NaN이 발생하든지 그때마다 프로그램 수행이 인터럽트를 확실하게 받기를 원할 때 사용합니다. 이러한 상황은 보통 수행에 있어서 뭔가 문제가 있다는 것을 의미합니다. 현재 CUDA 하드웨어는 signaling NaN을 지원하지 않습니다. 이는 대규모 병렬 수행 중에 정확한 signaling을 지원하는 것이 어렵기 때문입니다.
Quiet NaN이 산술연산의 입력으로 사용되면 Quiet NaN이 발생합니다. Quiet NaN은 일반적으로 유저가 출력결과를 보고 타당한 결과인지 판단하는 상황에서 사용됩니다. 결과가 출력될 때 Quiet NaN은 유저가 출력 파일에서 쉽게 발견할 수 있도록 "NaN"으로 출력됩니다.
산술 정확도(Accuracy)와 자리맞춤(Rounding)
지금까지 IEEE 부동소수점 포맷에 대해서 알아봤고, 이제 산술 정확도의 개념에 대해서 알아보겠습니다.
정밀도(Precision)는 부동소수점 형식에서 사용된 가수 비트의 개수에 의해서 결정되는 반면, 정확도(Accuracy)는 부동소수점 수에 사용된 연산들에 의해서 결정됩니다. 부동소수점 산술 연산의 정확도는 그 연산에 의해 발생한 최대 오차로 측정될 수 있습니다. 당연히 오차가 적을수록 정확도는 높습니다. 부동소수점 연산에서 가장 흔한 오차의 원인은 연산의 결과가 정확히 표현될 수 없는 수이기 때문에 자리맞춤(Rounding)을 할 때입니다. 자리맞춤은 결과를 정확하게 표현하기 위해서는 너무 많은 가수 비트가 필요할 때 발생합니다.
예를 들어, 곱셈 연산은 두 입력 값의 비트 수의 두 배로 표현되는 곱셈 값을 생성합니다. 또 다른 예로, 부동소수점 덧셈이나 뺄셈의 두 피연산자들이 서로 다른 지수를 가지고 있을 때 더 작은 지수를 가진 부동소수점 수의 가수는 통상 지수들이 서로 같아질 때까지 오른쪽으로 자리옮김 됩니다. 결과적으로 최종 결과는 표현 형식이 수용할 수 있는 비트보다 많은 수의 비트를 가지게 됩니다.
이와 같은 예시들은 위에서 살펴본 5-비트 표현 형식을 사용한 간단한 예제를 통해서 확인할 수 있습니다.
\(1.00_B \times 2^{-2}\)(0,00,01)과 \(1.00_B \times 2^1\)(0,10,00)을 더하는 연산을 살펴봅시다.
이 연산은 즉, \(1.00_B \times 2^1 + 1.00_B \times 2^{-2}\)를 수행해야 합니다. 지수 값이 다르기 때문에, 두 번째 수의 가수가 첫 번째 수에 더해지기 전 오른쪽으로 shift해야 됩니다. 즉, \(1.00_B \times 2^1 + 0.001_B \times 2^1\)이 됩니다. 이 덧셈의 결과는 \(1.001_B \times 2^1\) 입니다. 하지만, 이 수는 가수에 3개의 비트가 필요하므로, 우리의 5-비트 표현에서 표현 가능한 수가 아닙니다. 그러므로 차선책은 이 수에 가장 가까운 표현 가능한 수로 만드는 것인데, 이 수는 \(1.01_B \times 2^1\) 또는 \(1.00_B \times 2^1\) 입니다. 이렇게 할 때, 오차 \(0.001_B \times 2^1\)이 발생하는데, 이는 최하위 자리수의 값의 반입니다. 이를 0.5\(_D\) ULP(Units in the Last Place)라고 부릅니다.
만약 하드웨어가 완벽하게 산술연산과 자리맞춤을 수행하도록 설계되었다면, 최대 오차는 0.5\(_D\) ULP를 초과하지 않아야 합니다. 이는 오늘날 모든 CUDA 디바이스의 덧셈, 뺄셈 연산에서 달성할 수 있는 정확도입니다.
현실적으로, 나눗셈이나 초월함수와 같은 더 복잡한 산술 하드웨어 유닛들은 대개 polinomial approximation(다항 근사) 알고리즘을 통해 구현됩니다. 만약 하드웨어가 근사를 위해 충분한 수의 항을 사용하지 않는다면 결과는 0.5\(_D\) ULP보다 큰 에러를 가질 수 있습니다. 예를 들어, inversion 연산의 이상적인 결과가 \(1.00_B \times 2^1\)이지만 근사 알고리즘으로 하드웨어에서 \(1.10_B \times 2^1\)을 생성하는 경우 에러는 \(1.10_B - 1.00_B = 0.10_B\)이고, 이 에러 값은 마지막 자리 수 \(0.01_B\)의 두 배 크기이므로 에러는 2\(_D\) ULP가 됩니다.
실제 일부 초기 디바이스의 하드웨어 inversion 연산은 기수의 최하위 위치값의 2배인 에러를 발생시킵니다만, 최근 CUDA 디바이스에서는 충분한 트랜지스터 덕분에 훨씬 더 정확해졌습니다.
부동소수점 주의사항
수치 알고리즘에서 보통 매우 큰 값들을 합산해야 하는 경우가 있습니다. 예를 들어, 행렬곱셈에서 내적연산은 입력 행렬 원소쌍들을 곱해서 이들을 모두 더해야 합니다. 이상적으로 덧셈은 결합법칙이 성립하기 때문에 이 값들을 어떤 순서로 더하든지 간에 최종 값에는 영향을 받지 않습니다.
그러나, 유한한 정밀도를 가지고 있기 때문에 이 값들을 더하는 순서는 최종 결과의 정확도에 영향을 미칠 수 있습니다.
예를 들어, 5-비트 표현에서 다음 4개의 수를 더할 때 결과가 어떻게 달라지는지 살펴보겠습니다.
\[(1.00_B \times 2^0) + (1.00_B \times 2^0) + (1.00_B \times 2^{-2}) + (1.00_B \times 2^{-2})\]
이 숫자들을 순차적으로 더한다면 다음의 순서로 계산될 것입니다.
\[\begin{align*} 1.00_B \times 2^0 &+ 1.00_B \times 2^0 + 1.00_B \times 2^{-2} + 1.00_B \times 2^{-2} \tag{1} \\ &= 1.00_B \times 2^1 + 1.00_B \times 2^{-2} + 1.00_B \times 2^{-2} \tag{2} \\ &= 1.00_B \times 2^1 + 1.00_B \times 2^{-2} \tag{3} \\ &= 1.00_B \times 2^1 \end{align*}\]
(2)와 (3) 단계에서 더 작은 피연산자는 더 큰 피연산자에 비해서 너무 작기 때문에 그냥 사라진다는 점에 유의해야합니다.
이제, 앞쪽의 두 수에 대한 덧셈과 뒤쪽의 두 수의 대한 덧셈이 병렬적으로 수행되는 병렬 알고리즘을 고려해보도록 합시다. 최종적으로 알고리즘은 각 부분합을 더하게 됩니다.
\[\begin{align*} (1.00_B \times 2^0 &+ 1.00_B \times 2^0) + (1.00_B \times 2^{-2} + 1.00_B \times 2^{-2}) \tag{1} \\ &= (1.00_B \times 2^1) + (1.00_B \times 2^{-1}) \tag{2} \\ &= 1.01_B \times 2^1 \end{align*}\]
두 결과가 서로 다릅니다. 이는 병렬 알고리즘에서 세번째와 네번째 값의 합이 덧셈 결과에 영향을 줄 수 있을만큼 충분히 커졌기 때문입니다. 부동소수점 정밀도와 정확도에 대해 익숙하지 않다면 이러한 결과에 의문을 품을 수 있겠죠.
부동소수점 산술 정확도를 최대화하는 일반적인 방법은 위의 덧셈과 같은 Reduction 연산을 수행하기 전에 데이터를 미리 정렬하는 것입니다. 위 4개의 숫자를 오름차순으로 데이터를 미리 정렬하고 수행하면 다음과 같습니다.
\[ 1.00_B \times 2^{-2} + 1.00_B \times 2^{-2} + 1.00_B \times 2^0 + 1.00_B \times 2^0 \]
병렬 알고리즘에서 수들을 몇 개의 그룹으로 나누면 서로 가까운 값을 가지는 수들이 같은 그룹에 속하는 것이 보장됩니다. 따라서 이 그룹들로 덧셈을 수행하면 정확한 결과를 얻을 확률이 높아집니다.
이처럼 오름차순으로 정렬된 수들로 순차적인 덧셈을 하면 더 높은 정확도를 얻을 수 있습니다. 이러한 이유로 거대한 병렬 수치 알고리즘에서 정렬이 자주 사용됩니다.
(관심이 있다면, 부동소수점 값의 정확한 합을 구하기 위한 compensated summation algorithm과 같은 고급 기술을 공부하면 좋을 것 같습니다.. !)
'NVIDIA > CUDA' 카테고리의 다른 글
| Tiled 2D Convolution (0) | 2021.12.14 |
|---|---|
| 1D Convolution (CUDA Constant Memory) (1) | 2021.12.13 |
| 리소스 동적 분할 및 제한 사항 (+ device query) (2) | 2021.12.10 |
| Divergent Wraps (예제 : Sum Reduction) (0) | 2021.12.09 |
| Global Memory 대역폭(bandwidth) 활용 (2) | 2021.12.08 |




댓글