Contents
- OpenBLAS (cblas) 라이브러리를 사용한 행렬 곱 연산
- intel-mkl을 사용한 행렬 곱 연산
- cuBLAS 라이브러리를 사용한 행렬 곱 연산
행렬 곱 연산 비교 (Pthreads, OpenMP, OpenCV, CUDA)
행렬 곱 연산 비교 (Pthreads, OpenMP, OpenCV, CUDA)
Contents Pthread, OpenMP에서의 행렬 곱 연산 + 전치 행렬(transpose matrix) 사용 OpenCV library mat을 사용한 행렬 곱 연산 CUDA libarary로 구현한 행렬 곱 연산 Matrix Multiplication 이번 포스팅에서는 행..
junstar92.tistory.com
이전 게시글에서 여러 병렬 프로그래밍을 위한 라이브러리를 사용하여 행렬 곱 연산을 구현하고, 연산에 걸리는 시간을 측정해봤습니다. 그리고, 추가적으로 다른 선형대수를 위한 수학 라이브러리에서는 행렬 곱 연산 성능이 어떤지 궁금하여 OpenBLAS, mkl, cuBLAS에서 제공되는 행렬 곱 연산의 수행 시간을 측정해보았습니다.
OpenBLAS
https://github.com/junstar92/parallel_programming_study/blob/master/cblas_mat_mul.c
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
먼저 OpenBLAS 입니다. apt를 사용하여 OpenBLAS를 install 했고, 기본적으로 제공되는 c언어 인터페이스를 사용하여 행렬 곱 연산을 수행했습니다.
다음은 cblas의 행렬 곱 연산 수행을 위한 main 함수입니다. 전체 코드는 위 링크를 참조해주세요.
#include <stdio.h> #include <stdlib.h> #include <cblas.h> int main(int argc, char* argv[]) { int m, n, k; Get_args(argc, argv, &m, &n, &k); double *A, *B, *C; A = (double*)malloc(m * n * sizeof(double)); B = (double*)malloc(n * k * sizeof(double)); C = (double*)malloc(m * k * sizeof(double)); Generate_matrix(A, m, n); Generate_matrix(B, n, k); #ifdef DEBUG Print_matrix(A, m, n, "A"); Print_matrix(B, n, k, "B"); #endif double start, finish, avg_elapsed = 0.0; for (int count = 0; count < NCOUNT; count++) { GET_TIME(start); cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, m, k, n, 1.0, A, n, B, k, 0, C, k); GET_TIME(finish); printf("[%3d] Elapsed time = %.6f seconds\n", count+1, finish-start); avg_elapsed += (finish - start) / NCOUNT; } #ifdef DEBUG Print_matrix(C, m, k, "The product is"); #endif printf("Average elapsed time = %.6f seconds\n", avg_elapsed); free(A); free(B); free(C); return 0; }
이전 게시글에서 보던 코드와 크게 다른 점은 없습니다. 차이점은 line 25에서 cblas에서 제공되는 level-3 BLAS 연산 함수를 사용했습니다. level-3은 matrix-matrix 간의 연산이며, 참고로 level-1은 vector-vector 연산, level-2는 vector-matrix 연산입니다. 이 함수의 첫 번째 매개변수는 연산에서 row-major와 column-major 방법 중에 선택하도록 합니다. row-major가 우리가 일반적으로 계산할 때와 같다고 보시면 됩니다. 따라서 첫 번째 매개변수에 row-major를 사용하도록 합니다. 두 번째와 세 번째 매개변수는 곱셈할 행렬 A, B를 곱셈 전에 전치를 할 것인가의 여부를 결정합니다. row-major로 우리가 일반적으로 계산하는 방식으로 설정했기 때문에 전치는 하지 않아도 됩니다. 만약 column-major라면 전치가 필요합니다.
함수의 파라미터 설명은 아래 MKL에서 제공하는 API 문서를 참조바랍니다 !
컴파일은 다음의 커맨드로 할 수 있습니다.
$ g++ -Wall -o cblas_mat_mul cblas_mat_mul.c -lopenblas # or g++ -Wall -o cblas_mat_mul cblas_mat_mul.c $(pkg-config openblas --libs --cflags)
행렬 A (4096x4096)과 행렬 B(4096x4096)을 연산한 결과입니다.

CUDA를 사용했을 때보다는 조금 느리지만, 그래도 이전 게시글에서의 pthread, OpenMP, OpenCV보다는 훨씬 빠르게 수행됩니다. GPU를 사용하지 않았지만, GPU만큼의 속도가 나와서 개인적으로 깜짝 놀랐습니다. 기회가 된다면 어떻게 이렇게 빠른 연산이 가능한지 원리나 구현 방식을 찾아볼 필요는 있을 것 같습니다.
Intel MKL (Math Kerenl Library)
https://github.com/junstar92/parallel_programming_study/blob/master/mkl_mat_mul.c
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
다음은 Intel-MKL 입니다. 인텔에서 제공되는 math 라이브러리입니다. 인텔 프로세서에 최적화되어 있지만, 다른 프로세서에서도 사용은 가능하지만, 최신 최적화는 lock이 되어있다고 합니다. 구글링을 통해서 확인해보니, 다음의 시스템 환경 변수(MKL_DEBUG_CPU_TYPE)의 값을 5로 설정하면, 그 lock이 해제된다고 합니다.
$ export MKL_DEBUG_CPU_TYPE=5실제로 위 환경 변수를 설정하기 전, 후의 성능이 차이가 있었습니다.
MKL 라이브러리를 사용하여 구현한 행렬 곱 main함수입니다.
#include <stdio.h> #include <stdlib.h> #include <mkl/mkl.h> int main(int argc, char* argv[]) { int m, n, k; Get_args(argc, argv, &m, &n, &k); double *A, *B, *C; A = (double*)mkl_malloc(m * n * sizeof(double), 64); B = (double*)mkl_malloc(n * k * sizeof(double), 64); C = (double*)mkl_malloc(m * k * sizeof(double), 64); Generate_matrix(A, m, n); Generate_matrix(B, n, k); #ifdef DEBUG Print_matrix(A, m, n, "A"); Print_matrix(B, n, k, "B"); #endif double start, finish, avg_elapsed = 0.0; for (int count = 0; count < NCOUNT; count++) { GET_TIME(start); cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, m, k, n, 1.0, A, n, B, k, 0, C, k); GET_TIME(finish); printf("[%3d] Elapsed time = %.6f seconds\n", count+1, finish-start); avg_elapsed += (finish - start) / NCOUNT; } #ifdef DEBUG Print_matrix(C, m, k, "The product is"); #endif printf("Average elapsed time = %.6f seconds\n", avg_elapsed); mkl_free(A); mkl_free(B); mkl_free(C); return 0; }
코드 자체는 OpenBLAS와 유사합니다. 특히 행렬 곱 연산을 수행해주는 API(line 26)는 cblas.h에서 제공되는 것과 동일합니다. 매개변수에 대한 설명은 링크된 API 문서를 참조바랍니다 !
그리고, malloc과 free는 MKL에서 제공되는 mkl_malloc과 mkl_free를 사용했습니다.
MKL 라이브러리는 sequence로 실행하는 것과 OpenMP로 실행하는 것이 있습니다. 이외에도 ILP와 LP로 나누어지는데, ILP는 64-bit의 integer type을 사용하고, LP는 32-bit의 integer type을 사용한다고 합니다. 배열 인덱스의 크기가 보다 클 때, ILP를 사용해야 한다고 하네요.
현재 코드 상에서는 ILP와 LP가 크게 중요하지 않다고 생각되기 때문에, OpenMP와 LP를 사용하도록 컴파일 옵션을 주었습니다. 컴파일은 다음의 커맨드로 할 수 있습니다.
$ gcc -Wall -o mkl_mat_mul mkl_mat_mul.c $(pkg-config mkl-static-lp64-iomp --libs --cflags)
연산 수행 결과입니다.

비록 최적화가 전혀 고려되지 않았지만, GPU를 사용한 CUDA 버전보다 빠를 줄은 몰랐습니다. 꽤 놀라운 결과였고.. 무조건 GPU가 가장 빠르다고 생각했는데, 꼭 그렇지만은 않다라는 사실을 깨닫게 해주었습니다. 특히 pthread나 openmp를 사용했을 때는 CPU 사용량이 100%를 찍었지만, MKL에서는 60~70%의 CPU 사용량을 보여주고 있다는 사실에도 놀랐습니다. (최적화가 얼마나 잘 되어 있길래...)
이 부분도 어떻게 이러한 성능이 가능한지 알고 싶네요 ㅠ.ㅠ
cuBLAS
MKL의 성능이 CUDA를 사용했을 때보다 더 빠른 수행 시간을 보여주어서.. 그렇다면 NVIDIA에서 제공되는 BLAS 라이브러리는 어떨까 궁금하여, cuBLAS 라이브러리를 사용해보기로 했습니다.
https://github.com/junstar92/parallel_programming_study/blob/master/cublas_mat_mul.cu
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
CUDA와 코드는 유사합니다.
#include <stdio.h> #include <stdlib.h> #include <cublas.h> int main(int argc, char* argv[]) { int m, n, k; Get_args(argc, argv, &m, &n, &k); double *A, *B, *C; A = (double*)malloc(m * n * sizeof(double)); B = (double*)malloc(n * k * sizeof(double)); C = (double*)malloc(m * k * sizeof(double)); Generate_matrix(A, m, n); Generate_matrix(B, n, k); #ifdef DEBUG Print_matrix(A, m, n, "A"); Print_matrix(B, n, k, "B"); #endif // Allocate the device input matrixs for A, B, C; double* d_A, *d_B, *d_C; CUBLAS_CHECK(cublasAlloc(m*n, sizeof(double), (void**)&d_A)); CUBLAS_CHECK(cublasAlloc(n*k, sizeof(double), (void**)&d_B)); CUBLAS_CHECK(cublasAlloc(m*k, sizeof(double), (void**)&d_C)); double start, finish, avg_elapsed = 0.0; // Launch the Matrix Multiplication CUDA Kernel CUBLAS_CHECK(cublasInit()); for (int count = 0; count < NCOUNT; count++) { GET_TIME(start); // Copy the host matrixs A and B in host memory to the device matrixs in device memory CUBLAS_CHECK(cublasSetVector(m * n, sizeof(double), A, 1, d_A, 1)); CUBLAS_CHECK(cublasSetVector(n * k, sizeof(double), B, 1, d_B, 1)); cublasDgemm('T', 'T', m, k, n, 1.0, d_A, n, d_B, k, 0, d_C, m); CUBLAS_CHECK(cublasGetError()); // Copy the device result matrix in device memory to the host result matrix in host memory CUBLAS_CHECK(cublasGetVector(m * k, sizeof(double), d_C, 1, C, 1)); GET_TIME(finish); printf("[%3d] Elapsed time = %.6f seconds\n", count+1, finish-start); avg_elapsed += (finish - start) / NCOUNT; } #ifdef DEBUG Print_matrix(C, m, k, "The product is"); #endif printf("Average elapsed time = %.6f seconds\n", avg_elapsed); // Free device global memory CUBLAS_CHECK(cublasFree(d_A)); CUBLAS_CHECK(cublasFree(d_B)); CUBLAS_CHECK(cublasFree(d_C)); free(A); free(B); free(C); return 0; }
cuBLAS에서 제공되는 double형의 행렬 곱셈 연산 API는 cublasDgemm 입니다. 그리고, cuBLAS에서는 column-major를 사용합니다. cblas나 MKL과는 다르게 row-major는 제공되지 않고, 오직 column-major 방법만 사용되는데 정확한 계산을 위해서 곱해지는 행렬을 전치해주어야 합니다. 전치해주기 위해서 cublasDgemm 함수의 첫 번째와 두 번째 매개변수에 'T'를 입력해주는데, 이게 바로 곱셈에 사용되는 행렬 A와 B를 전치해준다는 것을 의미합니다. 'N'을 값으로 전달하면 전치되지 않고 행렬 A, B를 그대로 사용합니다.
만약 첫 번째와 두 번째 매개변수에 'N'을 값으로 전달하여 계산하면, 아래처럼 잘못된 결과가 나옵니다.
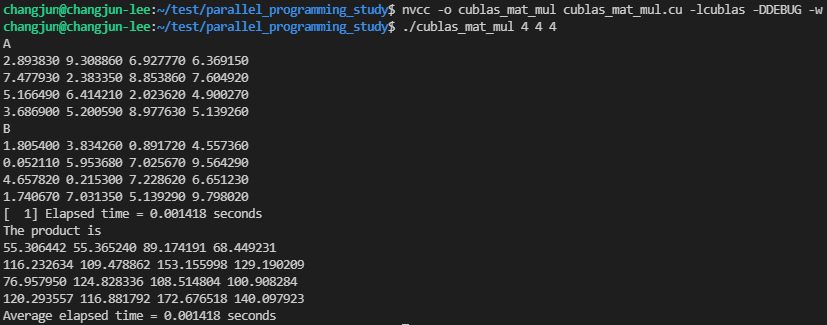
두 행렬의 정확한 연산 결과는 다음과 같습니다.

API에 대한 자세한 설명은 링크를 참조해주세요.
컴파일은 다음의 커맨드로 가능합니다.
$ nvcc -o cublas_mat_mul cublas_mat_mul.cu -lcublas # or nvcc -o cublas_mat_mul cublas_mat_mul.cu $(pkg-config cublas-11 --libs -cflags)
실행 결과입니다.

GPU를 사용해서인지 그래도 MKL 보다는 좋은 성능을 보여주고 있습니다. 성능이 더 안좋았더라면, 이때까지 GPU 최고라는 믿음이 깨지는 불상사가 발생할 뻔 했는데.. 다행입니다..
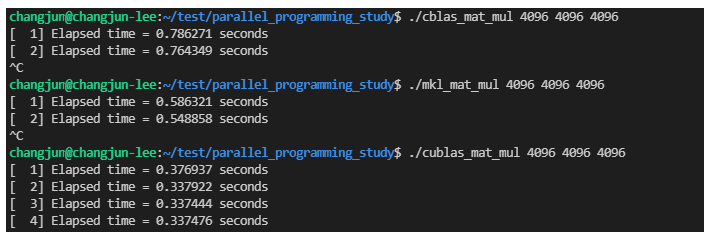
이전 게시글에 이어서 다른 라이브러리를 사용한 행렬 곱 연산의 수행 시간을 측정해봤습니다. 이전 글에서도 언급했지만 정확히 동일한 환경도 아니고 실험으로 각 라이브러리에서 행렬 곱을 간단하게 수행했을 때 얼마나 걸리는지 측정하고 싶어서 해본 실험이므로, 지표로 사용할 정도는 아닙니다.
각 라이브러리에서 어느 정도의 성능이 나온다는 것을 알아 봤는데, OpenBLAS나 MKL이 제 예상보다 너무 좋은 성능을 보여주어서 깜짝 놀랐습니다.
위에서도 언급했지만, 기회가 된다면 해당 라이브러리들이 어떻게 최적화가 되어있는지 알아보면 좋을 것 같습니다.
(부족한 머리로 이해가 가능할지는 모르겠지만 ㅠㅠ)
부족한 글 봐주셔서 감사합니다.
'프로그래밍 > 병렬프로그래밍' 카테고리의 다른 글
| 행렬 곱 연산 비교 (Pthreads, OpenMP, OpenCV, CUDA) (0) | 2021.11.26 |
|---|---|
| [OpenMP] 행렬-벡터 곱 연산 (0) | 2021.11.25 |
| [OpenMP] Critical Section (0) | 2021.11.25 |
| [OpenMP] schedule clause (0) | 2021.11.24 |
| [OpenMP] for 디렉티브 (0) | 2021.11.23 |



댓글