References
- An Introduction to Parallel Programming
Contents
- for 디렉티브
- parallel for 디렉티브와 for 디렉티브 비교
이전 MPI 프로그래밍에 관한 포스팅에서 버블 정렬과 odd-even 정렬에 대해서 살펴봤는데, 이번에는 OpenMP에서의 버블 정렬과 odd-even 정렬에 대해서 알아보겠습니다.
2021.11.13 - [프로그래밍/병렬프로그래밍] - [MPI] Odd-even transposition sort (MPI Safety)
[MPI] Odd-even transposition sort (MPI Safety)
References An Introduction to Parallel Programming Contents Odd-even transposition sort MPI Safety, MPI_Ssend MPI_Sendrecv 성능 측정 및 비교 분산 메모리 환경에서 병렬 정렬 알고리즘은 무엇을 의미할까..
junstar92.tistory.com
시리얼 코드로 버블 정렬은 다음과 같이 작성할 수 있습니다.
for (int list_length = n; list_length >= 2; list_length--) {
for (int i = 0; i < list_length - 1; i++) {
if (a[i] > a[i+1]) {
tmp = a[i];
a[i] = a[i+1];
a[i+1] = tmp;
}
}
}배열 a는 n개의 정수형 값을 저장하고, 우리는 버블 정렬을 통해서 n개의 값들을 오름차 순으로 정렬할 수 있습니다. 버블 정렬 코드는 외부 루프 안에서 매 루프마다 리스트에서 가장 큰 수를 찾고 그 수를 배열의 마지막에 저장합니다. 예를 들어, 처음에 발견한 가장 큰 수는 a[n-1]에, 그 다음 큰 수는 a[n-2]에 저장합니다.
내부 루프에서는 현재의 리스트에서 연속된 두 항목의 값을 비교합니다. 만약 a[i] > a[i+1]이면 두 수를 서로 바꾸어줍니다. 이 과정을 통해서 가장 큰 수를 리스트의 가장 마지막 위치로 이동시키게 됩니다.
이 코드를 살펴보면, 외부 루프에 루프에 의한 의존성이 있다는 것이 명백합니다. 외부 루프의 반복에서 현재 리스트의 요소들은 외부 루프의 이전 반복에 의존적이기 때문입니다. 예를 들어, 알고리즘이 a = 3, 4, 1, 2 에서 시작했다면, 외부 루프의 두 번째 반복에서 a는 3, 1, 2가 됩니다. 이는 외부 루프의 첫 번째 반복에서 4가 리스트의 가장 마지막 위치로 이동했기 때문입니다. 만약 두 개의 반복이 동시에 시작되면 두 번째 반복에서의 리스트에 4가 존재할 수도 있습니다.
안쪽 루프에서도 루프에 의한 의존성이 존재합니다. i번째 반복에서 비교하게될 i번째 항목은 i-1번째 반복의 결과에 의존적입니다. i-1번째 반복에서 a[i-1]과 a[i]가 서로 바뀌지 않았다면 i번째 반복에서 a[i]과 a[i+1]을 비교했겠지만, 만약 a[i-1]과 a[i]가 서로 바뀌었다면, 다음 반복에서 a[i-1]과 a[i+1]을 비교해야하기 때문입니다. a = 3, 1, 2라면 3과1 그리고 1과2를 동시에 비교하는 상황이 생길 수 있다는 것입니다.
이처럼 버블 정렬에서 코드를 수정하여 두 개의 루프의 의존성을 완벽하게 제거할 수 있을지는 확실하지 않습니다. 여기서 말하고자 하는 것은 항상 루프에 의한 의존성이 있는지 찾아봐야한다는 것이고, 찾게 되더라도 그 의존성을 제거하기가 어렵거나 어떤 경우에는 불가능할 수도 있습니다. parallel for 디렉티브는 항상 for루프를 병렬화할 수 있는 완벽한 해결책은 아닙니다.
odd-even trasposition sort
odd-even 정렬은 위의 버블 정렬과 유사한 정렬 알고리즘입니다. 다만, 버블 정렬보다 병렬화하기가 훨씬 더 수월합니다. 이전 포스팅에서 작성한 시리얼 코드 버전의 odd-even 정렬 알고리즘을 살펴봅시다.
void Odd_even_sort(
int list[] /* in/out */,
int n /* in */)
{
int tmp;
for (int phase = 0; phase < n; phase++) {
if (phase % 2 == 0) {
/* even phase */
for (int i = 1; i < n; i += 2) {
if (list[i-1] > list[i]) {
tmp = list[i];
list[i] = list[i-1];
list[i-1] = tmp;
}
}
}
else {
/* odd phase */
for (int i = 1; i < n-1; i += 2) {
if (list[i] > list[i+1]) {
tmp = list[i];
list[i] = list[i+1];
list[i+1] = tmp;
}
}
}
}
}위 알고리즘의 자세한 설명은 이전 포스팅을 참조해주시기 바랍니다 !
이 알고리즘은 만약 a = {9, 7, 8, 6} 일 때, 각 phase에서 아래의 표처럼 정렬됩니다.
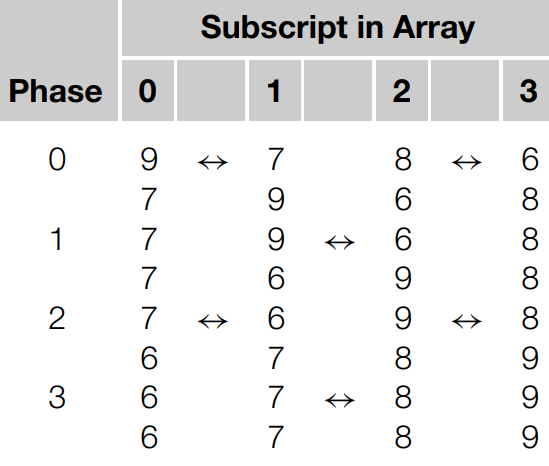
위 경우에 마지막 phase 3 단계가 필요하지는 않습니다. 위 알고리즘에서는 이처럼 각 phase에서 요소들이 정렬되기 전에 이미 리스트가 정렬되었는지 체크하는 것을 신경쓰지 않는다는 것을 확인할 수 있습니다. 즉, 알고리즘의 외부 루프가 루프에 의한 의존성이 없다는 뜻입니다. 내부 루프도 마찬가지 입니다.
(요소들을 비교하는 것과 교환하는 과정이 병렬적으로 수행될 수 있기 때문입니다.)
다만 병렬화하기 전에 체크하야할 몇 가지 문제점은 존재합니다.
첫 번째로 각 phase에서 이전 phase의 결과에 의존성이 없다고 하더라도, 현재 phase를 시작하기 전에 이전 phase가 끝나야 한다는 것을 보장해야합니다.
다행히 parallel 디렉티브와 같이 parallel for 디렉티브로 루프의 끝에 묵시적인 배리어를 갖고 있으며, 모든 스레드가 현재 phase를 완료할 때까지 어떠한 스레드도 그 다음 phase로 넘어갈 수 없습니다.
두 번째 문제는 스레드를 fork하고 join하는 것과 관련된 overhead(오버헤드)입니다.
우선 parallel for 디렉티브를 사용하여 odd-even 정렬을 구현한 코드를 보겠습니다. 전체 코드는 아래 링크를 참조하시기 바랍니다.
https://github.com/junstar92/parallel_programming_study/blob/master/OpenMP/08_omp_odd_even1.c
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
void Odd_even(int a[], int n)
{
int tmp;
for (int phase = 0; phase < n; phase++) {
if (phase % 2 == 0) {
#pragma omp parallel for num_threads(thread_count) \
default(none) shared(a, n) private(tmp)
for (int i = 1; i < n; i += 2) {
if (a[i-1] > a[i]) {
tmp = a[i-1];
a[i-1] = a[i];
a[i] = tmp;
}
}
}
else {
#pragma omp parallel for num_threads(thread_count) \
default(none) shared(a, n) private(tmp)
for (int i = 1; i < n-1; i += 2) {
if (a[i] > a[i+1]) {
tmp = a[i+1];
a[i+1] = a[i];
a[i] = tmp;
}
}
}
}
}위 코드에서 외부 루프 내부에서 thread_count개의 스레드를 fork하고 수행이 끝난 후 join 됩니다. 스레드 개수를 1개부터 4개까지 설정하고 사용되는 배열이 20,000개의 요소를 가질 때의 정렬 결과는 다음과 같습니다.
| thread_count | 1 | 2 | 3 | 4 |
| elapsed time (sec) | 0.73 | 0.45 | 0.33 | 0.28 |
아주 느린 것은 아니지만 성능을 더 향상시킬 수는 있습니다. 만약 우리가 내부 루프의 반복을 수행할 때마다 동일한 수의 스레드를 사용할 때, 매번 fork하고 join하는 것보다 같은 team의 스레드를 재사용하는 것이 더 빠를 것입니다. OpenMP에서는 이와 같은 기능을 사용할 수 있는 디렉티브를 제공합니다. 바로 parallel 디렉티브를 사용하여 외부 루프에 진입하기 전에 thread_count개의 스레드를 fork합니다. 그리고 내부 루프에는 for 디렉티브를 사용해줍니다. 이렇게 하면 내부 루프를 수행할 때 스레드를 새로 fork하는 것이 아닌 기존의 스레드 팀을 재사용하여 for 루프를 병렬화합니다. for 디렉티브를 사용한 코드는 다음과 같습니다.
void Odd_even(int a[], int n)
{
int phase, tmp;
#pragma omp parallel num_threads(thread_count) \
default(none) shared(a, n) private(tmp, phase)
for (phase = 0; phase < n; phase++) {
if (phase % 2 == 0) {
#pragma omp for
for (int i = 1; i < n; i += 2) {
if (a[i-1] > a[i]) {
tmp = a[i-1];
a[i-1] = a[i];
a[i] = tmp;
}
}
}
else {
#pragma omp for
for (int i = 1; i < n-1; i += 2) {
if (a[i] > a[i+1]) {
tmp = a[i+1];
a[i+1] = a[i];
a[i] = tmp;
}
}
}
}
}전체 코드는 아래 링크를 참조바랍니다.
https://github.com/junstar92/parallel_programming_study/blob/master/OpenMP/09_omp_odd_even2.c
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
동일하게 스레드를 1~4개로 설정하고, 20,000개의 요소를 갖는 배열로 정렬 시간을 측정해보면,
| thread_count | 1 | 2 | 3 | 4 |
| elapsed time (sec) | 0.72 | 0.39 | 0.31 | 0.25 |
위와 같습니다.
parallel for 디렉티브만을 사용한 결과(아래 표)를 비교해보면,
| thread_count | 1 | 2 | 3 | 4 |
| elapsed time (sec) | 0.73 | 0.45 | 0.33 | 0.28 |
확실히 외부 루프에 parallel 디렉티브를 사용하고, 내부 루프에서 for 디렉티브를 사용한 코드가 약간 더 빠르다는 것을 확인할 수 있습니다.
이처럼 for 디렉티브는 parallel for 디렉티브와 달리 어떤 스레드도 포크하지 않습니다. 대신 병렬 블록에 이미 포크되어 있는 스레드를 그대로 사용합니다.
'프로그래밍 > 병렬프로그래밍' 카테고리의 다른 글
| [OpenMP] Critical Section (0) | 2021.11.25 |
|---|---|
| [OpenMP] schedule clause (0) | 2021.11.24 |
| [OpenMP] for 루프 병렬화 (+ default, private, shared clause) (0) | 2021.11.22 |
| [OpenMP] 사다리꼴 공식 (trapezoidal rule) (0) | 2021.11.21 |
| [OpenMP] Hello, OpenMP (0) | 2021.11.20 |




댓글