References
- An Introduction to Parallel Programming
Contents
- schedule clause
- static type
- dynamic type / guided type
- runtime type
- auto type
parallel for 디렉티브를 사용할 때, 루프 반복을 정확히 각 스레드에 할당하는 것은 시스템마다 다릅니다. 그러나 대부분의 OpenMP 구현에서는 block partitioning(블록 파티셔닝)을 사용합니다. 만약 시리얼 루프에 n개의 반복이 있다면 병렬 루프에서는 처음 n/thread_count가 스레드 0에 할당되고 다음 n/thread_count가 스레드 1에 할당됩니다. 하지만, 이렇게 스레드에 할당하는 것이 최적화된 것은 아닙니다.
예를 들어, 다음의 루프를 병렬화하려고 한다고 가정해봅시다.
sum = 0.0;
for (int i = 0; i <= n; i++)
sum += f(i);그리고, f를 호출하는데 필요한 시간이 인수 i의 크기에 비례한다고 가정해봅시다.
그렇다면 블록 파티셔닝으로 할당하면 0번 스레드보다 thread_count-1번 스레드에게 더 많은 작업을 할당하게 됩니다.
이 상황에서는 스레드에 작업을 할당할 때, cyclic partitioning(사이클릭 파티셔닝)으로 분할하는 것이 더 좋습니다. 사이클릭 파티셔닝은 라운드-로빈(round-robin) 형태로 각 작업을 할당하며, thread_count가 t일 때 다음과 같이 할당합니다.

이 방법을 사용할 때 성능에 얼마나 영향을 미치는지 한 번 확인해보겠습니다.
우선 다음의 함수 f를 작성합니다.
double f(long i)
{
long start = i*(i+1) / 2;
long finish = start + i;
double return_val = 0.0;
for (long j = start; j <= finish; j++) {
return_val += sin(j);
}
return return_val;
}\(f(i)\)의 호출은 sin() 함수를 i번 호출하게 됩니다. 따라서, \(f(2i)\)를 호출하여 실행하는데 걸리는 시간은 \(f(i)\)를 실행하는데 걸리는 시간의 약 두 배가 될 것입니다.
그리고 다음과 같이 f함수의 합을 구하는 함수 Sum을 작성하고, main 함수를 실행시켜 걸리는 시간을 측정해보겠습니다. 전체 코드는 다음의 링크를 참조하시면 되는데, Sum 함수는 아래처럼 수정해야 합니다. (omp 디렉티브가 다릅니다.)
https://github.com/junstar92/parallel_programming_study/blob/master/OpenMP/10_omp_sin_sum.c
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
double Sum(long n, int thread_count)
{
double approx = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+: approx)
for (int i = 0; i <= n; i++) {
approx += f(i);
#ifdef DEBUG
iterations[i] = omp_get_thread_num();
#endif
}
return approx;
}
int main(int argc, char* argv[])
{
if (argc != 3)
Usage(argv[0]);
int thread_count = strtol(argv[1], NULL, 10);
long n = strtol(argv[2], NULL, 10);
#ifdef DEBUG
iterations = (int*)malloc((n+1)*sizeof(int));
#endif
double start, finish, global_result;
start = omp_get_wtime();
global_result = Sum(n, thread_count);
finish = omp_get_wtime();
double error, check;
check = Check_sum(n, thread_count);
error = fabs(global_result - check);
printf("Result = %.14f\n", global_result);
printf("Check = %.14f\n", check);
printf("With n = %ld terms, the error is %.14f\n", n, error);
printf("Elapsed time = %f seconds\n", finish - start);
#ifdef DEBUG
Print_iters(iterations, n);
free(iterations);
#endif
}n = 10,000이고 스레드를 1개와 2개로 각각 설정하여 프로그램을 실행하면,

다음의 결과를 얻을 수 있습니다. 1개의 스레드로 실행했을 때 약 1.01초가 걸렸고, 2개의 스레드에서는 0.77초가 걸렸습니다. 약 0.24초의 성능 향상이 있습니다.
schedule clause
위 코드에서 사이클릭 파티셔닝을 사용하기 위해서는 parallel for 디렉티브에 schedule clause를 추가하면 됩니다.
우선 다음과 같이 추가해보도록 하겠습니다.
double Sum(long n, int thread_count)
{
double approx = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+: approx) schedule(static, 1)
for (int i = 0; i <= n; i++) {
approx += f(i);
#ifdef DEBUG
iterations[i] = omp_get_thread_num();
#endif
}
return approx;
}일반적으로 schedule clause는 다음과 같은 형태를 갖습니다.
schedule(<type>, [, <chunksize>])type은 다음 중의 하나가 됩니다.
- static : 루프가 실행되기 전에 반복이 할당
- dynamic or guided : 루프가 실행되는 스레드 할당. 스레드가 현재 반복을 완료한 후에 런타임 시스템에 그 다음 반복을 할당해줄 것을 요청함
- auto : 컴파일러 혹은 런타임 시스템이 스케쥴을 결정
- runtime : 스케쥴이 런타임에 결정됨
chunksize는 0보다 큰 정수입니다. OpenMP에서 chunk는 시리얼 루프에서 연속해서 실행될 수 있는 반복의 블록을 의미합니다. static, dynamic, guided 타입만 chunksize를 가질 수 있습니다.
static type
static type은 시스템이 라운드-로빈 방식으로 각 스레드에 chunksize만큼의 반복을 각 스레드에 할당합니다. 예를 들어 12번의 반복이 존재하고 3개의 스레드가 있다면, shedule(static, 1)이 parallel for이나 for 디렉티브에서 사용되면 할당은 다음과 같이 이루어집니다.

schedule(static, 2)가 사용되면, 다음과 같고,

schedule(static, 4)라면, 다음과 같이 할당됩니다.

schedule(static, total_iterations/thread_count)는 대부분의 OpenMP에서의 기본 스케쥴링과 동일합니다. chunksize는 생략될 수 있는데, 만약 생략되었다면 chunksize는 거의 total_iterations/thread_count로 설정됩니다.
방금 코드에서 schedule(static, 1)을 parallel for 디렉티브에 사용하여 똑같이 실행하면 다음의 수행 시간을 확인할 수 있습니다.

schedule clause를 사용하지 않았을 때 0.77초가 걸렸지만, schedule clause를 추가하면 수행 시간은 훨씬 더 빠른 0.53초로 감소하였습니다.
dynamic / guided type
dynamic type에서의 반복은 연속된 반복을 chunksize만큼으로 나눕니다. 각 스레드는 할당받은 크기만큼 실행하고 작업을 완료하면 런타임 시스템에 동일한 크기만큼의 다른 작업을 요청합니다. 이러한 동작은 반복이 모두 완료할 때가지 계속됩니다. chunksize는 생략될 수 있는데, 생략되면 1로 설정됩니다.
double Sum(long n, int thread_count)
{
double approx = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+: approx) schedule(dynamic, 1000)
for (int i = 0; i <= n; i++) {
approx += f(i);
#ifdef DEBUG
iterations[i] = omp_get_thread_num();
#endif
}
return approx;
}위 처럼 schedule의 타입과 chunksize를 변경하고, -DDEBUG옵션을 추가하여 코드를 실행해봅시다.

각 스레드에 chunksize만큼 각 스레드에 할당된 것을 확인할 수 있습니다.
guided type에서는 dynamic type과 유사합니다. 할당 크기를 chunk만큼 나누고, 각 스레드는 chunk만큼의 작업을 수행한 후에 다음 chunk만큼의 작업이 더 이상 없을때까지 시스템에게 다른 작업을 요청합니다. dynamic type과 다른 점은 바로 chunk의 크기인데, chunk의 크기는 남은 반복 횟수를 스레드 수로 나눈 값에 비례합니다. 따라서 스레드에 작업이 할당될 수록 할당되는 chunk의 크기는 감소합니다.
직접 눈으로 확인해보도록 하겠습니다. schedule(guided, 1)을 parallel for에 추가하여 컴파일 후 실행해보겠습니다.
double Sum(long n, int thread_count)
{
double approx = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+: approx) schedule(guided, 1)
for (int i = 0; i <= n; i++) {
approx += f(i);
#ifdef DEBUG
iterations[i] = omp_get_thread_num();
#endif
}
return approx;
}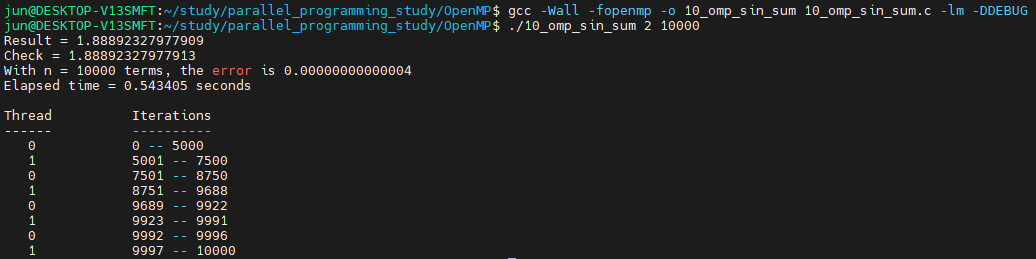
첫 스레드의 할당은 n/thread_count, 즉 10000/2로 5000개의 반복이 할당되었습니다. 다음 스레드에는 남은 반복 횟수인 5000을 스레드 개수로 나눈 수, 즉, 2500개의 반복이 스레드 1에 할당되었습니다. 그 다음은 1250, 또 그 다음 스레드에는 625, 그 다음은 312개의 반복이 할당됩니다. 중간에 스레드 1에서 8751-9688이 할당된 것으로 나오는데 이는 1250개를 할당받은 스레드 0이 끝나기 전에 스레드 1에서 625번의 반복이 끝나 다시 스레드 1에 312개의 반복이 할당된 결과입니다.
chunk의 최소 사이즈는 chunksize로 설정되는데, schedule clause에서 이를 설정하면 됩니다. 단 마지막 반복은 설정한 chunksize보다 작을 수 있습니다. chunksize를 6으로 설정하고 실행해보았습니다.

runtime type
runtime type으로 설정되면 OpenMP는 내부 제어 변수인 run-sched-var에 의해서 스케쥴링이 결정됩니다. 이 변수는 OMP_SCHDULE을 원하는 스케쥴링 유형의 값으로 변경하여 적용할 수 있습니다.
Sum 함수에 parallel for 디렉티브에 schedule(runtime)을 추가하고,
double Sum(long n, int thread_count)
{
double approx = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+: approx) schedule(runtime)
for (int i = 0; i <= n; i++) {
approx += f(i);
#ifdef DEBUG
iterations[i] = omp_get_thread_num();
#endif
}
return approx;
}컴파일 후 다음과 같이 실행해보세요.

환경변수 OMP_SCHEDULE의 값을 "guided, 1"로 설정했더니, 스케쥴링이 schedule(guided, 1)로 설정한 것과 동일한 결과가 나왔습니다. 만약 OMP_SCHEDULE의 값을 "dynamic, 1000"로 설정하게 되면,

위와 같은 결과를 얻을 수 있습니다.
즉, runtime type을 사용하면 OMP_SCHEDULE 값을 사용하여 스케쥴링을 schdule(OMP_SCHEDULE)으로 설정한 것과 같이 동작하도록 할 수 있습니다.
+) omp_set_schedule(schedule-type) 함수를 통해서 코드 내에서도 runtime type을 설정할 수 있습니다.
double Sum(long n, int thread_count)
{
double approx = 0.0;
omp_set_schedule(omp_sched_dynamic, 1000);
#pragma omp parallel for num_threads(thread_count) \
reduction(+: approx) schedule(runtime)
for (int i = 0; i <= n; i++) {
approx += f(i);
#ifdef DEBUG
iterations[i] = omp_get_thread_num();
#endif
}
return approx;
}위와 같이 코드를 작성하면 되는데, omp_set_schedule의 첫 번째 인수는 omp_sched_t 타입으로 omp.h에 정의되어 있는 enum이며, 두 번째 인수는 chunksize입니다. static, dynamic, guided 일때만 chunksize를 입력하면 됩니다.

위 코드를 컴파일 후 실행하면,
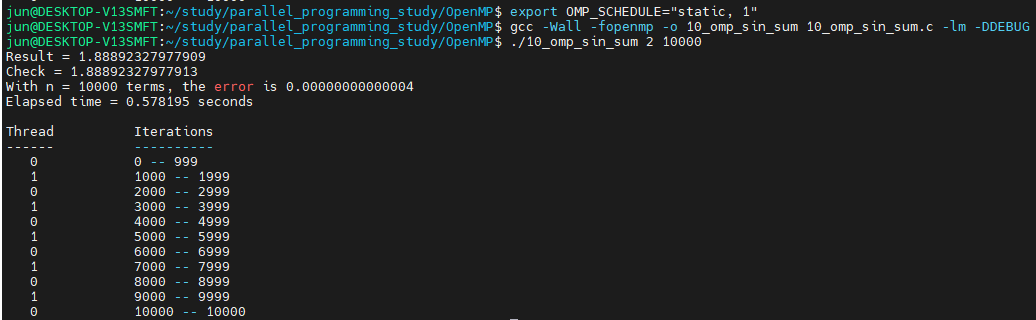
schedule(dynamic, 1000)과 동일한 결과를 확인할 수 있습니다.
Auto type
auto type은 컴파일이나 시스템에 의해서 결정됩니다.
double Sum(long n, int thread_count)
{
double approx = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+: approx) schedule(auto)
for (int i = 0; i <= n; i++) {
approx += f(i);
#ifdef DEBUG
iterations[i] = omp_get_thread_num();
#endif
}
return approx;
}저의 경우, 위 코드로 컴파일 후, 실행했더니 아래와 같이 할당되어 프로그램이 수행되었습니다.

위에서 사용된 코드는
https://github.com/junstar92/parallel_programming_study/blob/master/OpenMP/10_omp_sin_sum.c
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
여기서 확인하실 수 있습니다. Sum 함수에는 schedule(auto)로 되어있으므로 원하시는 걸로 변경하여 사용하시면 됩니다.
'프로그래밍 > 병렬프로그래밍' 카테고리의 다른 글
| [OpenMP] 행렬-벡터 곱 연산 (0) | 2021.11.25 |
|---|---|
| [OpenMP] Critical Section (0) | 2021.11.25 |
| [OpenMP] for 디렉티브 (0) | 2021.11.23 |
| [OpenMP] for 루프 병렬화 (+ default, private, shared clause) (0) | 2021.11.22 |
| [OpenMP] 사다리꼴 공식 (trapezoidal rule) (0) | 2021.11.21 |



댓글