References
- An Introduction to Parallel Programming
Contents
- 데이터 분산(distribution)
- MPI_Scatter, MPI_Gather
이번에는 MPI에서 벡터의 합을 어떻게 구하는지 살펴보도록 하겠습니다.
아래처럼 벡터의 합을 계산하는 함수를 작성한다고 가정해봅시다.
더블형 타입을 사용하여 벡터를 표현하면, 시리얼 벡터의 합은 다음과 같이 구현할 수 있습니다.
void vector_sum(double x[], double y[], double z[], int n) { for (int i = 0; i < n; i++) { z[i] = x[i] + y[i]; } }
MPI에서는 어떻게 구현할까요?
벡터의 합은 벡터의 각 요소들끼리 더하는 것이기 때문에 태스크는 단순히 대응되는 요소들끼리의 덧셈 연산이라고 할 수 있습니다. 그렇기 때문에 태스크들 간의 통신이 없고, 따라서 벡터 합의 병렬화 문제는 태스크들을 집계하고 그 결과를 코어에 할당하는 것이 됩니다.
만약 벡터의 크기가 n이고 우리가 comm_sz개의 코어(프로세스)를 가지고 있다면, (n은 comm_sz으로 나누어 떨어진다고 가정하고) local_n을 n/comm_sz로 정의할 수 있습니다. 그러면 우리는 간단하게 각 프로세스에 local_n개의 연속된 요소들로 이루어진 블록을 할당할 수 있습니다. n = 12, comm_sz = 3이라면 각 프로세스는 (0,1,2,3), (4,5,6,7), (8,9,10,11)의 블록들로 할당받을 수 있습니다. 이는 벡터의 block partition이라고 부릅니다.
block partition의 대안으로는 cyclic partition이 있습니다. cyclic partition에서는 각 요소들을 라운드-로빈 방식으로 할당할 수 있습니다. 똑같이 n = 12, comm_sz = 3이라면, (0,3,6,9), (1,4,7,10), (2,5,8,11)로 할당될 수 있습니다.
세 번째 대안은 block-cycle partition입니다. 이 아이디어는 각 요소를 cyclic하게 분배하는 대신 블록된 요소들을 cyclic하게 분배합니다. 따라서 이 방법에서는 블록의 사이즈를 결정해야하는데, n = 12, comm_sz = 3, 그리고 block size = 2라면, (0,1,6,7), (2,3,8,9), (4,5,10,11)로 각 프로세스에 할당할 수 있습니다.

벡터를 어떻게 파티셔닝할 지 결정하고 나면, 병렬 벡터 덧셈 함수를 작성하는 것은 어렵지 않습니다. 각 프로세스는 간단하게 주어진 요소들을 더하면 됩니다. 각 프로세스는 파티션과 상관없이 local_n개의 요소를 갖게 되고, 공간을 절약하기 위해서 각 프로세스는 이 값을 local_n개의 항목을 갖는 배열에 저장합니다. 이 병렬 벡터 덧셈 함수는 다음과 같이 작성될 수 있습니다.
void Parallel_vector_sum( double local_x[] /* in */, double local_y[] /* in */, double local_z[] /* out */, int local_n /* in */) { for (int local_i = 0; local_i < local_n; local_i++) local_z[local_i] = local_x[local_i] + local_y[local_i]; }
함수 이름은 변경되었지만, 이 함수는 위의 시리얼 함수와 동일합니다.
MPI_Scatter
Parallel_vector_sum 함수를 사용하기 전에 입력으로 사용할 벡터의 크기와 벡터 x,y를 먼저 각 프로세스에 할당해주어야 합니다. 이전 게시글을 포함하여 알고 있는 방법은 프로세스 0에서 사용자로부터 입력을 받고 값을 읽어 오고, 그리고 나서 그 값을 다른 프로세스에게 broadcast하는 것입니다.
하지만 이러한 작업은 낭비가 너무 심합니다. 만약 10개의 프로세스가 있고 벡터의 크기가 10,000이라면, 각 프로세스는 전부 크기가 10,000인 벡터를 위한 공간을 할당해야 합니다. 하지만 작업할 태스크는 각 프로세스에서 크기가 1,000인 서브 벡터를 더하기 때문에 이는 낭비입니다.
따라서, broadcast가 아닌 block distribution을 사용하여 프로세스 0에서는 1000에서 1999까지의 요소를 프로세스 1에게 전달하고, 2000부터 2999까지의 요소는 프로세스 2에게 전송하도록 하는 것이 훨씬 낫습니다. 이 방법을 사용하면 프로세스 1에서 9까지는 실제 사용하는 서브벡터의 크기만큼의 공간만 할당하면 됩니다.
MPI에서는 이를 위해서 MPI_Scatter 함수를 제공하는데, 이 함수를 사용하면 프로세스 0에서 전체 벡터를 읽어오는 함수를 작성하고 필요한 컴포넌트만큼만 다른 프로세스에게 전송할 수 있습니다.
int MPI_Scatter( void* send_buf_p /* in */, int send_count /* in */, MPI_Datatype send_type /* in */, void* recv_buf_p /* out */, int recv_count /* in */, MPI_Datatype recv_type /* in */, int source_proc /* in */, MPI_comm comm /* in */);
커뮤니케이터 comm에 comm_sz개의 프로세스를 포함하고 있다면, MPI_Scatter는 send_buf_p가 참조하는 데이터를 comm_sz만큼으로 분할합니다. 첫 번째 분할된 조각은 프로세스 0이 처리하고, 두 번째 조각은 프로세스 1, 세 번째는 프로세스 2가 처리하도록 합니다.
예를 들어, block distribution을 사용하고 프로세스 0이 n개의 요소를 가진 벡터를 send_buf_p로 읽어왔다고 가정해봅시다. 프로세스 0은 첫 번째 local_n = n/comm_sz개의 요소를 갖게 되고, 프로세스 1은 다음 local_n개의 요소를 갖게 됩니다. 각 프로세스는 로컬 벡터를 recv_buf_p 인수로 전달해야 하고, recv_count 인수는 local_n이 됩니다. send_type과 recv_type은 MPI_DOUBLE이 되고, source_proc 인수는 0이 되어야 합니다. send_count는 각 프로세스로 보낼(전달될) 요소의 크기인 local_n이 되어야 합니다.
이렇게 block distribution과 MPI_Scatter를 사용하면 아래의 Get_vector 함수를 사용하여 각 프로세스에 서브벡터들을 전달할 수 있습니다. 사용자 입력으로 입력받아도 되지만, 편의를 위해서 100보다 작은 랜덤한 수로 값을 읽습니다.
void Get_vector( double local_vec[] /* out */, int local_n /* in */, int n /* in */, char vec_name[] /* in */, int my_rank /* in */, MPI_Comm comm /* in */) { double* tmp_vec = NULL; int local_ok = 1; char* fname = "Get_vector"; if (my_rank == 0) { tmp_vec = (double*)malloc(n * sizeof(double)); if (tmp_vec == NULL) local_ok = 0; Check_for_error(local_ok, fname, "Can't allocate temporary vector", comm); for (int i = 0; i < n; i++) { tmp_vec[i] = rand() % RMAX; } MPI_Scatter(tmp_vec, local_n, MPI_DOUBLE, local_vec, local_n, MPI_DOUBLE, 0, comm); free(tmp_vec); } else { Check_for_error(local_ok, fname, "Can't allocate temporary vector", comm); MPI_Scatter(tmp_vec, local_n, MPI_DOUBLE, local_vec, local_n, MPI_DOUBLE, 0, comm); } }
여기서 포인트는 MPI_Scatter는 프로세스 0에게 첫 번째 블록(send_count개의 서브벡터)은 프로세스 0에게 전달하고, 다음 블록은 프로세스 1에게 전달한다는 점입니다. 따라서 이렇게 입력된 벡터를 읽어서 분산하는 방법은 (n이 comm_sz로 나누어떨어진다면) 꽤 유용하게 사용될 수 있습니다.
MPI_Gather
벡터 덧셈의 결과를 확인할 수 없으면 프로그램은 쓸모가 없습니다. 따라서 분산되어 덧셈을 수행한 결과를 하나로 출력하는 함수가 필요합니다. 이 함수는 프로세스 0에서 다른 프로세스의 서브벡터들을 모으고, 모든 서브벡터들을 출력합니다. 이 함수의 통신은 MPI_Gather에 의해 수행됩니다.
int MPI_Gather( void* send_buf_p /* in */, int send_count /* in */, MPI_Datatype send_type /* in */, void* recv_buf_p /* out */, int recv_count /* in */, MPI_Datatype recv_type /* in */, int dest_proc /* in */, MPI_comm comm /* in */);
프로세스 0에서 send_buf_p가 참조하는 메모리에 저장된 데이터는 recv_buf_p의 첫 번째 블록에 저장됩니다. 그리고 프로세스 1에서 send_buf_p가 참조하는 메모리에 저장된 데이터는 recv_buf_p의 두 번째 블록에 저장됩니다. 나머지 블록도 나머지 프로세스들에서 동일한 방법으로 저장됩니다. 그래서 만약 block distribution을 사용한다면, 다음의 함수로 분산된 벡터들을 출력할 수 있습니다. 주의할 점은 recv_count는 각 프로세스로부터 받은 데이터의 수이며 수신받은 전체 데이터의 수가 아닙니다.
void Print_vector( double local_vec[] /* in */, int local_n /* in */, int n /* in */, char title[] /* in */, int my_rank /* in */, MPI_Comm comm /* in */) { double* tmp_vec; int local_ok = 1; char* fname = "Print_vector"; if (my_rank == 0) { tmp_vec = (double*)malloc(n * sizeof(double)); if (tmp_vec == NULL) local_ok = 0; Check_for_error(local_ok, fname, "Can't allocate temporary vector", comm); MPI_Gather(local_vec, local_n, MPI_DOUBLE, tmp_vec, local_n, MPI_DOUBLE, 0, comm); printf("%s\n", title); for (int i = 0 ; i < n; i++) { printf("%f ", tmp_vec[i]); } printf("\n"); free(tmp_vec); } else { Check_for_error(local_ok, fname, "Can't allocate temporary vector", comm); MPI_Gather(local_vec, local_n, MPI_DOUBLE, tmp_vec, local_n, MPI_DOUBLE, 0, comm); } }
다음은 병렬 벡터 합을 구하기 위한 메인 함수입니다.
int main(void) { int n, local_n, comm_sz, my_rank; double *local_x, *local_y, *local_z; MPI_Comm comm; srand(0); MPI_Init(NULL, NULL); comm = MPI_COMM_WORLD; MPI_Comm_size(comm, &comm_sz); MPI_Comm_rank(comm, &my_rank); Read_n(&n, &local_n, my_rank, comm_sz, comm); Allocate_vectors(&local_x, &local_y, &local_z, local_n, comm); Get_vector(local_x, local_n, n, "x", my_rank, comm); Print_vector(local_x, local_n, n, "x is", my_rank, comm); Get_vector(local_y, local_n, n, "y", my_rank, comm); Print_vector(local_y, local_n, n, "y is", my_rank, comm); Parallel_vector_sum(local_x, local_y, local_z, local_n); Print_vector(local_z, local_n, n, "The sum is", my_rank, comm); free(local_x); free(local_y); free(local_z); MPI_Finalize(); return 0; }
위에서 알아봤던, Read_n, Get_vector, Print_vector, Parallel_vector_sum 함수를 사용하고 있고, 추가로 로컬 벡터의 공간을 할당하기 위해서 Allocate_vectors 함수를 사용하고 있습니다. 물론 내부적으로 사용되는 함수들이 몇 가지 더 있는데, 이는 전체 코드를 참조하시기 바랍니다 !
전체 코드는 아래 링크에서 확인 가능합니다.
https://github.com/junstar92/parallel_programming_study/blob/master/mpi/07_mpi_vec_add.c
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
코드를 컴파일하고, 실행하면
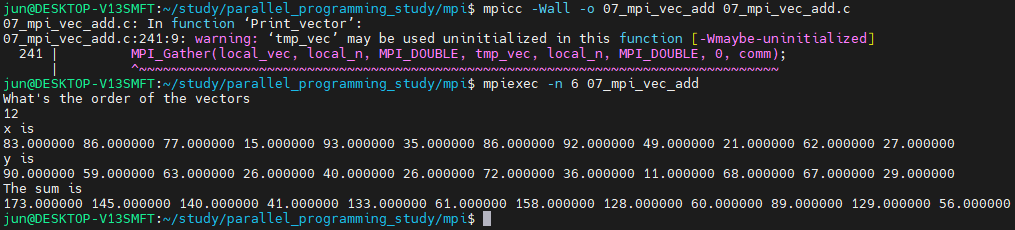
위의 결과를 얻을 수 있습니다. 저의 경우에는 6개의 프로세스를 사용했고, 벡터의 크기를 12로 지정했습니다.
하지만 벡터의 크기가 사용할 프로세스의 크기로 나누어 떨어지지 않는다면 에러가 발생하도록 하였고, 크기를 잘못 지정하면, 다음의 에러 문구를 출력하게 됩니다.

'프로그래밍 > 병렬프로그래밍' 카테고리의 다른 글
| [MPI] MPI Derived Datatypes (파생 데이터타입) (0) | 2021.11.13 |
|---|---|
| [MPI] 행렬 - 벡터 곱 연산 + 성능 평가 (0) | 2021.11.12 |
| [MPI] 사다리꼴 공식 (trapezoidal rule) 병렬화 - 2 (0) | 2021.11.10 |
| [MPI] 사다리꼴 공식 (trapezoidal rule) 병렬화 - 1 (0) | 2021.11.09 |
| [MPI] Hello, MPI (0) | 2021.11.08 |




댓글