References
- An Introduction to Parallel Programming
Contents
- MPI (Message-Passing Interface)
- MPI 프로그램(MPI_Init, MPI_Finalize, Communicator, MPI_Comm_size, MPI_Comm_rank)
- SPMD 프로그램
- communication(MPI_Send, MPI_Recv, 메세지 매칭)
MPI (Message-Passing Interface)
MPI(메세지 인터페이스)는 분산 및 병렬 처리에서 정보의 교환에 대해 기술하는 표준입니다.
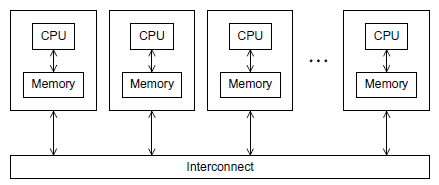
MPI는 분산 메모리 시스템에서 사용할 수 있도록 프로그래밍할 수 있도록 기본적인 기능들과 문법, 프로그래밍 API에 대해 기술하고 있습니다.
메세지 패싱(message-passing) 프로그램에서 코어-메모리에서 실행되는 프로그램을 보통 프로세스(process)라고 하고, 두 개의 프로세스는 송신(send) 함수라고 하는 프로세스와 수신(receive) 함수라고 하는 프로세스를 사용하여 통신합니다. 일반적으로 메세지 패싱에 대한 구현을 MPI(Message-Passing Interface)라고 합니다. MPI는 새로운 프로그래밍 언어를 의미하는 것이 아니라, C, C++, 그리고 포트란에서 사용되어 왔던 함수들의 라이브러리로 정의됩니다.
Hello, MPI
프로그래밍을 처음 배울 때, "Hello, world" 프로그램을 작성해보았을텐데, 이번 게시글에서는 MPI를 사용하여 이 프로그램과 비슷한 프로그램을 작성해보겠습니다. 이 프로그램은 각 프로세스가 메세지를 출력하는 대신에 하나의 프로세스가 출력을 맡고 다른 프로세스는 메세지를 전송하도록 설계할 것입니다.
병렬 프로그램에서는 음수가 아닌 정수형 rank(등급)을 사용하여 프로세스를 식별하는 것이 일반적입니다. p개의 프로세스들이 있다면 그 프로세스들은 0, 1, 2, ..., p-1의 rank를 갖고 있습니다. 병렬로 "hello, world"를 출력하도록 만들기 위해서 프로세스 0이 메세지를 출력하고 다른 프로세스는 메세지를 전송하도록 설계할텐데, 바로 아래의 코드를 살펴보겠습니다 !
#include <stdio.h>
#include <string.h>
#include <mpi.h>
const int MAX_STRING = 100;
int main(void)
{
char greeting[MAX_STRING];
int comm_sz;
int my_rank;
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
if (my_rank != 0) {
sprintf(greeting, "Greetings from process %d of %d!", my_rank, comm_sz);
MPI_Send(greeting, strlen(greeting) + 1, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
}
else {
printf("Greetings from process %d of %d!\n", my_rank, comm_sz);
for (int q = 1; q < comm_sz; q++) {
MPI_Recv(greeting, MAX_STRING, MPI_CHAR, q, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("%s\n", greeting);
}
}
MPI_Finalize();
return 0;
}코드를 살펴보기 전에 우선 컴파일하고 실행을 해보도록 하겠습니다.
컴파일과 실행
위 코드를 컴파일하고 실행하는 것은 시스템에 따라 다를텐데, 많은 시스템에서 컴파일을 위해 사용하는 명령어는 mpicc입니다.
$ mpicc -g -Wall -o mpi_hello mpi_hello.c일반적으로 mpicc는 C 컴파일러를 위한 래퍼 스크립터(wrapper script)입니다. 래퍼 스크립트는 주로 어떤 프로그램을 실행하기 위한 목적의 스크립트이며, mpicc에 해당하는 명령어는 'mpicc -showme'를 통해서 확인할 수 있습니다.
저의 경우에는 아래처럼 출력됩니다.

그리고, mpiexec를 사용하여 프로그램을 실행할 수 있습니다.
$ mpiexec -n <number of processes> ./mpi_hello만약 하나의 프로세스를 사용하여 프로그램을 실행하려면,
$ mpiexec -n 1 ./mpi_hello4개의 프로세스로 프로그램을 시작하면 다음과 같이 입력합니다.
$ mpiexec -n 4 ./mpi_hello
위 명령어의 출력은 다음과 같습니다.

만약 -n 옵션을 입력하지 않는다면,

최대 CPU 코어만큼 자동으로 할당하여 프로그램을 시작합니다. 제가 사용하는 노트북의 CPU가 6개의 코어를 가지고 있기 때문에 6줄의 출력을 확인할 수 있었습니다.
+) C++로 컴파일하고 실행하고 싶다면, 다음의 커맨드로 컴파일할 수 있습니다.
$ mpic++ -Wall -o mpi_hell mpi_hello.c
MPI 프로그램
그럼 이제 프로그램을 조금 더 자세히 살펴보도록 하겠습니다. 먼저 이 코드는 C언어로 이루어져있기 때문에 표준 C 헤더 파일인 stdio.h와 string.h 파일을 include합니다. 또한 메인 함수는 다른 C 프로그램과 동일합니다. 그리고 MPI를 사용하여 병렬 프로그래밍을 하기 위해서 line 3에서 mpi.h 헤더 파일을 include합니다. 이 헤더 파일은 MPI 함수들의 프로토타입, 매크로의 정의, 타입 정의 등을 포함합니다.
MPI에 의해 정의된 모든 식별자들은 'MPI_'로 시작합니다. MPI_ 다음으로 오는 것은 MPI에서 정의된 타입을 가리킵니다. 그리고 MPI의 define 매크로나 상수는 모든 문자들이 대문자로 되어 있습니다.
MPI_Init과 MPI_Finalize
line 13에서 MPI_Init의 호출은 MPI 시스템이 필요한 모든 셋업을 하도록 하는 부분입니다. 예를 들어, 메세지 버퍼를 위한 저장 공간을 확보하거나 어떤 프로세스가 어떤 rank를 가질지 결정하는 부분입니다. 다른 MPI 함수를 사용하기 전에 MPI_Init에 대한 호출이 가장 먼저 실행되어야 합니다.
MPI_Init의 문법은 다음과 같습니다.
int MPI_Init(
int* argc_p /* in/out */,
char*** argv_p /* in/out */);인수인 argc_p와 argv_p는 main의 argc와 argv 인수에 대한 포인터입니다. mpi_hello 프로그램에서는 이 인수를 사용하지 않기 때문에 이 코드에서는 NULL로 넘겨줍니다. 대부분의 MPI 함수는 에러 코드를 리턴하는데, MPI_Init 또한 에러 코드를 리턴합니다만, 대부분의 경우 이 에러 코드는 무시하는 편입니다.
line 29에 있는 MPI_Finalize 호출은 MPI에서 사용한 리소스들을 해제하도록 하는 부분입니다. 문법은 다음과 같습니다.
int MPI_Finalize(void);일반적으로 MPI_Finalize가 호출된 후에는 어떤 MPI 함수도 호출되어서는 안됩니다.
따라서, 일반적인 MPI 프로그램은 다음과 같은 구조를 따릅니다.

argc와 argv에 대한 포인터를 MPI_Init에 넘기지 않아도 되며, MPI_Init과 MPI_Finalize는 꼭 main 함수에서 호출하지 않아도 됩니다.
Communicator, MPI_Comm_size와 MPI_Comm_rank
MPI Communicator(커뮤니케이터)는 서로 메세지를 전송하는 프로세스들의 컬렉션(collection)입니다. MPI_Init을 하는 목적 중의 하나는 프로그램을 시작할 때 사용자에 의해 시작되는 프로세스들을 구성하는 커뮤니케이터를 정의하는 것입니다. 이 커뮤니케이터는 MPI_COMM_WORLD라고 합니다.
line 14, 15에 있는 함수의 호출은 MPI_COMM_WORLD에서 정보를 얻어 옵니다. 문법은 다음과 같습니다.
int MPI_Comm_size(
MPI_Comm comm /* in */,
int* size /* out */);
int MPI_Comm_rank(
MPI_Comm comm /* in */,
int* rank /* out */);위 두 함수에서 첫 번째 인수는 커뮤니케이터이고 MPI 커뮤니케이터에 의해 정의되는 특별한 타입인 MPI_Comm을 갖습니다. MPI_Comm_size는 커뮤니케이터에 있는 프로세스의 수를 두 번째 인수(size)로 리턴합니다. MPI_Comm_rank는 커뮤니케이터에서 호출하는 프로세스의 rank를 두 번째 인수(rank)로 리턴합니다. 예제 코드의 comm_sz는 MPI_COMM_WORLD에서의 프로세스 수를 나타내는 변수이며 프로세스의 rank는 my_rank라는 변수를 사용합니다.
SPMD 프로그램
위에서 컴파일할 때, 우리는 각각의 프로세스별로 프로그램을 컴파일한 것이 아니라, 하나의 프로그램을 컴파일했습니다. 그리고 프로세스 0은 기본적으로 다른 프로세스들과 다르다는 것을 발견할 수 있습니다. 프로세스 0은 메세지들을 수신하고 출력합니다. 반면에 다른 프로세스들은 메세지를 생성하고 전송합니다. 이는 병렬 프로그래밍에서 매우 일반적이고, 대부분의 MPI 프로그램은 이러한 방식으로 작성됩니다. 즉, 하나의 프로그램으로 작성되어 다른 프로세스들은 다른 액션을 수행하고, 각 프로세스의 rank에 따라서 할 일이 나누어집니다. 병렬 프로그래밍에서 이러한 접근 방법을 싱글 프로그램, 다중 데이터(single program, multiple data), 즉, SPMD라고 합니다. line 17부터 line 27까지의 if-else 문장이 이 프로그램을 SPMD가 되도록 해줍니다.
또한, 프로그램이 여러 개의 프로세스를 사용하여 실행된다는 사실에 주목합시다. 위에서 하나의 프로세스 혹은 4개의 프로세스, 6개의 프로세스를 사용했었습니다. 그러나 우리가 사용한 시스템에 충분한 리소스가 존재한다면 1000개 또는 100,000개의 프로세스를 사용할 수도 있습니다. 물론, MPI가 이렇게 많은 리소스를 요구하는 것은 아니지만 프로그램을 작성할 때 몇 개의 프로세스에서라도 동작할 수 있도록 작성해야합니다.
Communication 통신
line 18에서 0이 아닌 각 프로세스는 메세지를 생성하고, line 19에서 프로세스 0에게 메세지를 전송합니다. 프로세스 0은 printf를 사용하여 간단하게 메세지를 출력하고 루프를 사용하여 메세지를 수신하고, 프로세스 1, 2, ..., comm_sz-1까지의 프로세스에게서 받은 메세지를 출력합니다. line 24는 프로세스 q에게서 메세지를 받습니다. 여기서 q는 1, 2, ..., comm_sz-1 입니다.
MPI_Send
프로세스 1, 2, ..., comm_sz-1에 의해 실행되는 메세지 전송은 조금 복잡합니다. 각각의 전송은 MPI_Send를 호출해서 이루어지는데, 이에 대한 문법은 다음과 같습니다.
int MPI_Send(
void* msg_buf_p /* in */,
int msg_size /* in */,
MPI_Datatype msg_type /* in */,
int dest /* in */,
int tag /* in */,
MPI_Comm communicator /* in */)첫 번째 3개의 인수인 msg_buf_p, msg_size와 msg_type은 메세지의 콘텐츠를 결정합니다. 나머지 인수인 dest, tag, 그리고 communicator는 메세지의 목적지를 결정합니다.
첫 번째 인수인 msg_buf_p는 메세지의 내용, 즉, 콘텐츠를 갖고 있는 메모리 블록의 포인터입니다. 예제에서는 메세지를 포함하고 있는 문자열이 됩니다.
두 번째 인수와 세 번째 인수는 msg_size와 msg_type이며, 전송할 데이터의 사이즈와 타입을 결정합니다. mpi_hello 프로그램에서 msg_size는 메세지에 포함되어 있는 문자의 수와 C언어에서 문자열의 종료를 뜻하는 '\0' 문자 하나를 더한 숫자입니다. msg_type은 MPI_CHAR 입니다. C 타입(int, char 등)은 함수의 인자로 전달될 수 없기 때문에 MPI에서는 특별한 타입인 MPI_Datatype을 정의합니다. 이 타입은 msg_type 인수에서 사용됩니다. 사용할 수 있는 MPI 타입의 예는 다음과 같습니다. (이외에도 많은 데이터타입이 존재합니다.)

네 번째 인수 dest는 메세지를 수신하는 프로세스의 rank를 설정합니다.
다섯 번째 인수 tag는 음수가 아닌 int형인데, 이는 메세지를 식별하는데 사용됩니다. 예를 들어, 프로세스 1이 프로세스 0에 실수형(float)를 전송하고, 몇몇 실수형은 출력하는데 사용하고, 나머지는 연산을 위해 사용된다고 가정해봅시다. 그렇다면 MPI_Send이 제공하는 처음 4개의 인수로는 어떤 실수형이 출력되고, 어떤 실수형이 연산에 사용될지에 대한 정보를 알려줄 수가 없습니다. 따라서 프로세스 1에 tag를 0으로 설정하여 메세지를 출력하라고 알려주거나, tag를 1로 설정하여 연산에 사용하도록 알려줄 수 있습니다.
마지막 인수는 커뮤니케이터입니다.
커뮤니케이션을 포함하는 모든 MPI 함수들은 커뮤니케이터 인수를 갖고 있습니다. 커뮤니케이터의 가장 중요한 목적 중의 하나는 통신 기능을 설정하는 것입니다. 커뮤니케이터는 서로 간의 메세지를 전송하는 프로세스들의 컬렉션인데, 반대로 하나의 커뮤니케이터를 사용하는 프로세스에 의해 전송되는 메세지는 다른 커뮤니케이터를 사용하는 프로세스에는 수신될 수 없습니다. MPI는 새로운 커뮤니케이터를 생성하는 기능을 제공하기 때문에 이 기능은 메세지들이 우연히 수신됬다라는 상황이 발생하지 않도록 하기 위해 복잡한 프로그램에서도 사용이 가능합니다.
즉, 독립적인 2개의 모델에서 서로 통신하지 않는다는 환경에서 각각의 커뮤티케이터를 사용하여 각각의 모델에만 데이터를 전달할 수 있도록 할 수 있습니다.
MPI_Recv
MPI_Recv의 문법은 다음과 같습니다.
int MPI_Recv(
void* msg_buf_p /* out */,
int buf_size /* in */,
MPI_Datatype but_type /* in */,
int source /* in */,
int tag /* in */,
MPI_Comm communicator /* in */,
MPI_Status* status_p /* out */,MPI_Recv의 처음 6개의 인수들은 MPI_Send의 처음 6개의 인수와 대응됩니다. 따라서 처음 3개의 인수는 수신 메세지를 위해 사용 가능한 메모리를 설정하는데, msg_buf_p는 메세지 블록을 가리키고, buf_size는 블록에 저장되는 object의 수를 결정합니다. buf_type은 object의 타입을 가리킵니다. 다음 3개의 인수를 메세지를 식별하는데 사용되는데, source는 메세지가 어떤 프로세스로부터 전송되었는지에 대해 설정합니다. tag 인수는 전송한 메세지의 tag 인수와 매칭되어야 하고, communicator는 전송 프로세스에서 사용된 커뮤니케이터와 매칭되어야 합니다.
status_p는 object의 status의 결과가 담기는데, 여기서는 사용하지 않습니다. 사용하지 않도록 설정하려면 MPI 상수인 MPI_STATUS_IGNORE를 인수로 넘겨주면 됩니다.
메세지 매칭
프로세스 q가 다음과 같이 MPI_Send를 호출하다고 가정해봅시다.
MPI_Send(send_buf_p, send_buf_sz, send_type, dest, send_tag, send_comm);또한, 프로세스 r이 다음과 같이 MPI_Recv를 호출한다고 가정해봅시다.
MPI_Recv(recv_buf_p, recv_buf_sz, recv_type, src, recv_tag, recv_comm, &status);
MPI_Send를 호출해서 q에 의해 전송된 메세지가 r에서 MPI_Recv로 전송되려면, 다음의 조건들을 만족해야합니다.
- recv_comm = send_comm
- recv_tag = send_tag
- dest = r
- src = q
그러나, 이러한 조건들은 메세지가 성공적으로 수신되었다는 것을 보장하기에는 충분하지 않습니다. 처음 3개의 인수들인 send_buf_p/recv_buf_p, send_buf_sz/recv_buf_sz, send_type/recv_type들은 반드시 호환가능한 버퍼를 설정해야 합니다. (자세한 규칙은 MPI_Spec의 Ch 3.1.1 Type Matching Rules를 참조바랍니다 !)
대부분의 경우에는 다음의 규칙만으로도 충분합니다.
- recv_type = send_type과 recv_buf_sz >= send_buf_sz라면, q에서 전송한 메세지는 성공적으로 r에 의해 수신된다.
물론 하나의 프로세스가 여러 프로세스에게서 메세지를 받을 수 있고, 수신하는 프로세스가 다른 프로세스가 송신한 메세지의 순서를 알 수는 없습니다. 예를 들어, 프로세스 0이 프로세스 1, 2, ..., comm_sz-1의 프로세스와 통신을 하고, 작업이 끝났을 때 프로세스의 결과를 프로세스 0에게 송신한다고 가정해봅시다. 각 프로세스에게 할당된 작업이 어느 정도 걸릴지 예측 불가능하다면 프로세스 0은 어떤 프로세스가 어떤 순서로대로 끝냈는지 알 수 없습니다. 프로세스 0은 프로세스 rank 순서에서 결과를 수신한다면, 먼저 프로세스 1로부터 결과를 받고 그 다음은 프로세스 2와 같은 순서대로 결과를 수신할 수 있습니다. 프로세스 comm_sz-1이 먼저 일을 끝냈다면 프로세스 comm_sz-1은 다른 프로세스가 일을 끝낼 때까지 대기해야 합니다. 이러한 문제를 피하기 위해서 MPI는 특별한 상수 MPI_ANY_SOURCE를 제공하며 이 상수는 MPI_Recv의 source에 전달됩니다.
프로세스 0에서 다음의 코드를 실행하면 일이 끝나는 순서대로 수신할 수 있습니다.
for (int i = 1; i < comm_sz; i++) {
MPI_Recv(result, result_sz, result_type, MPI_ANY_SOURCE,
result_tag, comm, MPI_STATUS_IGNORE);
}
비슷하게 하나의 프로세스가 다른 프로세스로부터 다른 태그를 갖는 여러 메세지를 수신할 수도 있습니다. 수신하는 프로세스는 메세지들이 어떤 순서로 전송되는지 알 수 없습니다. 이러한 환경에서 MPI는 특별한 상수 MPI_ANYTHING tag를 제공하며 이 태그는 MPI_Recv의 tag 인수에 전달됩니다.
이러한 와일드카드 인수들은 몇 가지 주의사항이 있습니다.
- 오직 수신하는 쪽만 와일드카드 인수를 사용할 수 있다. 송신하는 쪽은 프로세스 rank와 음수가 아닌 태그를 명시해야 한다. 그러므로 MPI는 "pull" 메커니즘보다 "push" 통신 메커니즘을 사용한다.
- 커뮤니케이터 인수에는 와일드카드 인수를 사용할 수 없다. 송신하는 쪽과 수신하는 쪽 모두 커뮤니케이터를 명시해야한다.
status_p 인수
위의 통신 규칙들을 살펴보면, 수신하는 쪽은 아래의 정보없이 메세지를 수신한다는 것을 발견할 수 있습니다.
- 메세지에 있는 data amount
- 메세지의 sender
- 메세지의 tag
어떻게 수신하는 쪽은 이 정보를 알 수 있을까요?
MPI_Recv의 마지막 인수는 MPI_Status* 타입입니다. MPI_Status 타입은 MPI_SOURCE, MPI_TAG, MPI_ERROR를 멤버로 가지는 구조체입니다.
프로그램에 다음과 같이 정의하면,
MPI_Status status;&status를 MPI_Recv의 마지막 인수로 전달하여 아래의 두 멤버 변수를 조사해서 sender와 tag를 결정할 수 있습니다.
status.MPI_SOURCE
status.MPI_TAG수신되는 data의 size는 프로그램에서 직접 액세스할 수 있는 필드에 저장되지는 않습니다. 그러나 MPI_Get_count를 호출해서 그 정보를 추출할 수는 있습니다. 예를 들어, recv_type과 &status를 인수로 전달하여 MPI_Recv를 호출했다고 가정해봅시다. 그리고 MPI_Get_count를 다음과 같이 호출했다고 합시다.
MPI_Get_count(&status, recv_type, &count);위는 count 인수에 수신된 object의 사이즈(integer)를 리턴합니다. 일반적으로 MPI_Get_count의 문법은 다음과 같습니다.
int MPI_Get_count(
MPI_Status* status_p /* in */,
MPI_Datatype type /* in */,
int* count_p /* out */);
MPI_Send와 MPI_Recv의 의미
하나의 프로세스에서 다른 프로세스로 메세지를 전송할 때 정확하게 어떤 일이 일어날까요? 이에 대한 자세한 정보는 시스템에 따라서 다르지만, 몇 가지 일반적인 사항은 있습니다.
송신 프로세스는 메세지들을 조합합니다. 예를 들어, 전송할 실제 데이터(도착 프로세스 rank, 전송하는 프로세스 rank, tag, communicator, message size 등)들을 "envelop" 정보에 추가합니다. 메세지가 이렇게 취합되면, 송신 프로세스는 메세지를 buffer 하거나 block할 수 있습니다. 메세지를 buffer하면, MPI 시스템은 메세지를 자신의 내부 저장 공간에 두고 MPI_Send에 대한 호출을 리턴합니다. 반대로 시스템이 block되면 메세지를 전송하게 될 때까지 대기하고 MPI_Send로 즉시 리턴하지 않습니다. 따라서 MPI_Send를 사용하면 함수가 리턴할 때, 실제 메세지를 전송했는 지를 알 수 없습니다. 단시 메세지를 위해 사용한 저장 공간은 알 수 있습니다. 그 저장 공간은 송신 버퍼이며 프로그램에서 재사용이 가능합니다. 만약 메세지가 전송되었는지 알아야 하거나, MPI_Send 호출을 즉시 리턴해야 한다면(메세지가 전송되었는지 여부와 상관없이) MPI는 송신을 위한 다른 함수를 제공합니다. (추후에 알아보도록 하겠습니다.)
MPI_Send의 정확한 동작은 MPI의 구현에 따라서 결정됩니다. 그러나 일반적인 구현은 기본적으로 메세지의 크기를 'cutoff'하는 것입니다. 메세지의 크기가 cutoff보다 작으면 메세지는 버퍼링이 됩니다. 만약 메세지의 크기가 cutoff보다 크다면 MPI_Send는 block됩니다.
MPI_Send와는 달리, MPI_Recv는 매칭되는 메세지가 송신될 때까지 항상 block됩니다.
따라서 MPI_Recv의 호출이 리턴될 때 (에러가 발생하지 않았다면) 수신 버퍼에 메세지가 저장되었는지를 알 수 있습니다. 메세지를 수신하는 다른 방법도 있는데, 바로 시스템에서 매칭되는 메세지가 사용 가능하고 리턴 가능한지를 체크하는 것입니다. 이는 메세지가 존재하거나 존재하지 않더라도 상관없습니다(non-blocking communication).
MPI는 메세지가 nonovertaking되는 것을 요구합니다. 이는 프로세스 q가 프로세스 r에게 두 개의 메세지를 전송한다면, q에서 전송한 첫 번째 메세지가 두 번째 메세지보다 먼저 r에게 전송된다는 것을 의미합니다. 그러나 다른 프로세스들이 전송하는 메세지들 간에는 제약이 없습니다. q와 t가 r에 메세지를 전송한다면 t가 메세지를 전송하기 전에 q가 메세지를 전송했다고 하더라도 q의 메세지가 t의 메세지보다 먼저 r에게 전송해야할 필요는 없습니다. 이는 MPI가 네트워크 성능에 대해서는 고려하지 않기 때문입니다. 예를 들어, q가 화성에 있는 기계에서 동작하고 있고, r과 t는 샌프란시스코에 있는 동일한 기계에서 동작하고 있다고 가정해봅시다. q가 t가 메세지를 전송하기 몇 나노세컨트 전에 메세지를 전송한다면 q의 메세지가 t의 메세지보다 먼저 도착해야 한다는 것은 말이 안 되는 상황이기 때문입니다.
따라서, MPI_Recv 때문에 MPI 프로그래밍을 하다 보면 약간 심각한 문제가 발생합니다. 만약 프로세스가 메세지를 수신하려고 하는데, 전송한 메세지와 매칭되는 것이 없다면 프로세스는 영원히 block됩니다. 이러한 현상을 프로세스가 행(hang)되었다고 합니다. 따라서 프로그램을 설계할 때, 모든 수신은 반드시 매칭되는 송신이 있다는 것을 보장해야합니다. MPI_Send와 MPI_Recv를 호출할 때 우연히라도 이러한 실수가 없도록 주의해야 합니다.
'프로그래밍 > 병렬프로그래밍' 카테고리의 다른 글
| [MPI] 행렬 - 벡터 곱 연산 + 성능 평가 (0) | 2021.11.12 |
|---|---|
| [MPI] 데이터 분산 (벡터합 병렬화) (0) | 2021.11.11 |
| [MPI] 사다리꼴 공식 (trapezoidal rule) 병렬화 - 2 (0) | 2021.11.10 |
| [MPI] 사다리꼴 공식 (trapezoidal rule) 병렬화 - 1 (0) | 2021.11.09 |
| 병렬 프로그래밍 (0) | 2021.11.07 |




댓글