(tensorflow v2.4.0)
IMDB dataset을 사용해서 감성분류를 해보도록 하겠습니다. IMDB dataset은 영화 리뷰 데이터이며, 구현해볼 것은 해당 리뷰가 긍정적인 리뷰인지 부정적인 리뷰인지 분류하는 것입니다.
이번 글에서는 RNN layer가 아닌 Dense layer로만 구성된 모델과 Word Embedding layer를 사용한 Dense layer 모델로 학습해보도록 하겠습니다.
1. Dense layer로만 이루어진 Model 학습
우선 데이터를 준비합니다. num_words=10000으로 설정해서, 가장 빈도수가 높은 10000개의 단어만 사용하도록 합니다.
import tensorflow as tf
import numpy as np
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words=10000)
print(train_data.shape)
print(train_labels.shape)
print(test_data.shape)
print(test_labels.shape)
학습 데이터 25000개, 테스트 데이터 25000개로 이루어져 있습니다.
train_data[0]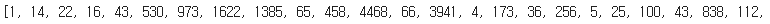
각 데이터는 이미 토큰화된 정수 index로 이루어져 있습니다.
max([max(sequence) for sequence in train_data])
그리고 10000개의 단어만 사용하기 때문에 사용되는 단어의 인덱스의 최대값은 9999입니다.
index to word dictionary를 받아와서 data가 실제로 어떻게 이루어져 있는지 살펴보면 다음과 같습니다.
word_to_idx = tf.keras.datasets.imdb.get_word_index()
idx_to_word = dict([(value, key) for (key, value) in word_to_idx.items()])
decoded_review = ' '.join([idx_to_word.get(i) for i in train_data[0]])
print(decoded_review)
그리고 각 training sample 시퀀스의 길이가 다르기 때문에 one-hot encoding을 통해서 포함되는 단어만 1로 표시하도록 변환해줍니다.
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
print(x_train.shape)
print(x_test.shape)
각 시퀀스 데이터는 10000차원의 one-hot vector입니다.
y_train = np.array(train_labels).astype('float32')
y_test = np.array(test_labels).astype('float32')labels도 numpy array로 변환해주고, data type은 'float32'로 설정합니다.
model = tf.keras.models.Sequential(
[tf.keras.layers.Dense(16, activation='relu', input_shape=(10000,)),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
]
)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics='acc')
model.summary()
Dense layer로만 구성된 모델입니다.
학습을 진행해보도록 하겠습니다.
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_split=0.2)
train data의 정확도는 거의 100%인 반면에, valid data의 정확도는 약 87%로 전형적인 과적합의 모습을 보여주고 있는 것 같습니다.
정확도와 Loss를 그래프를 통해서 살펴보겠습니다.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], 'b-', label='train loss')
plt.plot(history.history['val_loss'], 'b--', label='valid loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.figure()
plt.plot(history.history['acc'], 'b-', label='train acc')
plt.plot(history.history['val_acc'], 'b--', label='valid acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()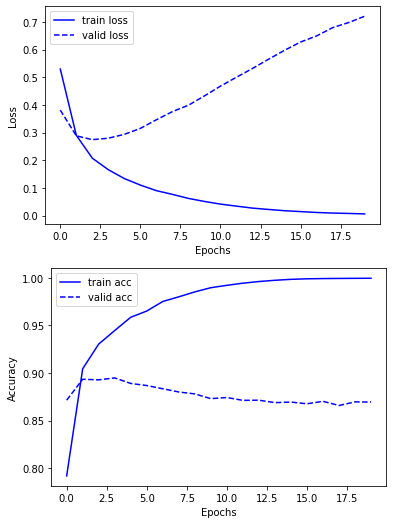
valid loss가 감소하다가 증가하는 모습을 보여주고 있으며, valid acc는 학습이 진행되면서 감소하는 모습을 보여주고 있습니다.
다음은 test data에 대한 평가입니다.
model.evaluate(x_test, y_test)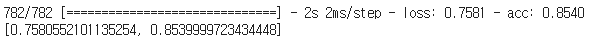
약 85%의 정확도를 보여주고 있습니다.
2. Word Embedding layer를 사용한 Dense model
Word Embedding은 단어를 벡터화하는 또 다른 방법입니다.
2020/12/24 - [ML & DL/tensorflow] - one-hot encoding과 Tokenizer를 통한 Word Representation
one-hot encoding으로 만들어진 벡터는 sparse하기 때문에(대부분 0으로 채워짐) 고차원입니다. 따라서 메모리 낭비가 심합니다.
반면에 단어 임베딩은 저차원의 수치형 벡터입니다.(one-hot vector와 반대로 밀집 벡터입니다.)
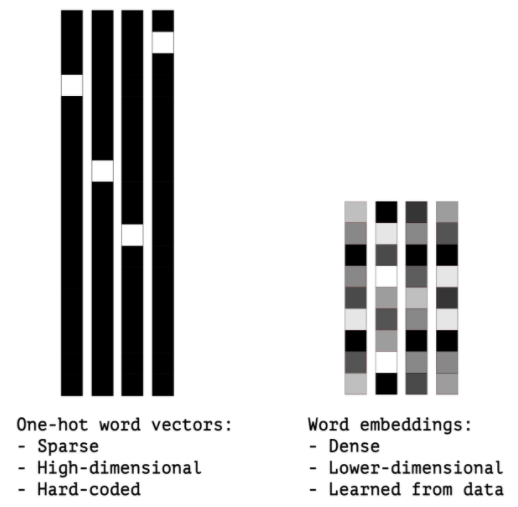
one-hot encoding과 다르게 단어 임베딩은 데이터로부터 학습되며, 더 적은 정보를 더 적은 차원에 저장합니다.
단어 임베딩은 학습하려는 문제와 함께 단어 임베딩을 학습하는 방법과 사전 학습된 단어 임베딩을 사용하는 방법이 있습니다. 두 가지 모두 진행해보도록 하겠습니다.
먼저 단어 임베딩을 학습하는 모델입니다.
새롭게 data를 불러와서 수행해보도록 하겠습니다.
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
import tensorflow.keras.models as models
max_features = 10000 # 가장 빈번하게 사용된 10000개의 단어만 사용
maxlen = 500 # 각 시퀀스의 최대 길이
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=max_features)
# 시퀀스의 길이를 maxlen으로 변경해줌(maxlen보다 짧았으면, 0으로 채워준다)
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen, padding='post')
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen, padding='post')
model = models.Sequential(
[layers.Embedding(10000, 32, input_length=maxlen),
layers.Flatten(),
layers.Dense(1, activation='sigmoid')])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics='acc')
model.summary()
각 batch data 시퀀스의 길이가 다르기 때문에 pad_sequences를 통해서 길이를 통일시켜주고 있습니다. 최대 maxlen=500의 길이를 가지며, 만약 더 짧았다면 뒷 부분을 모두 0으로 채워줍니다.(padding='pre'로 설정하면 앞 부분을 0으로 채웁니다.)
그리고 모델은 Embedding layer와 Dense layer로 구성되어 있습니다.

Embedding layer의 input_dim은 사용되는 voca의 차원이며, output_dim은 embedding feature의 개수입니다. 그리고 input_length를 통해서 입력받는 시퀀스의 길이를 설정합니다.
따라서 Embedding layer의 output dimension은 (batch_size, 500, 32)가 됩니다.
학습을 진행해보도록 하겠습니다.
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
학습 정확도는 거의 100%이며, valid data의 정확도는 약 88%입니다.
plt.figure(figsize=(12, 4))
plt.subplot(121)
plt.plot(history.history['loss'], 'b-', label='train loss')
plt.plot(history.history['val_loss'], 'b--', label='valid loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(122)
plt.plot(history.history['acc'], 'b-', label='train acc')
plt.plot(history.history['val_acc'], 'b--', label='valid acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()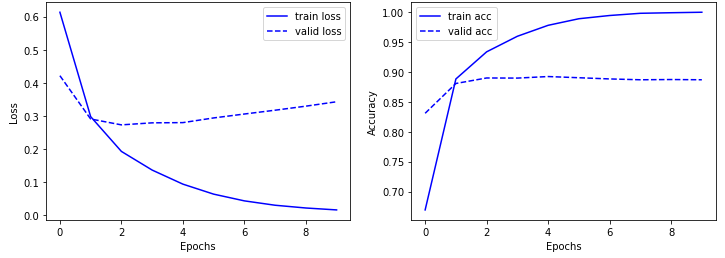
학습이 진행되면서 validation data의 loss가 증가하고 acc가 조금 감소하는것으로 보아 과적합이 진행되는 것 같습니다.
다음으로 미리 학습된 GloVe 단어 임베딩을 사용해서 학습해보도록 하겠습니다.
(local에서 진행했기 때문에 tensorflow의 버전이 2.3.1 입니다.)
데이터는 nlp.stanford.edu/data/glove.6b.zip 에서 다운받을 수 있습니다.
# GloVe 임베딩 사용
glove_dir = 'glove.6B.100d.txt'
def read_glove_vecs(glove_file):
with open(glove_file, 'r', encoding='utf-8') as f:
words = set()
word_to_vec_map = {}
for line in f:
line = line.strip().split()
curr_word = line[0]
words.add(curr_word)
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
i = 1
words_to_index = {}
index_to_words = {}
for w in sorted(words):
words_to_index[w] = i
index_to_words[i] = w
i += 1
return words_to_index, index_to_words, word_to_vec_map
words_to_index, index_to_words, word_to_vec_map = read_glove_vecs(glove_dir)words_to_index는 word-index 딕셔너리, index_to_words는 index-word 딕셔너리, word_to_vec_map은 word-embedding word vector 딕셔너리입니다.
사용하는 사전훈련된 단어 임베딩의 차원이 100이기 때문에, (100 x 10000)의 빈 embedding matrix를 만들고, 사용되는 단어의 임베딩 벡터의 값을 넣어주도록 하겠습니다.
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
if i < max_words and word in word_to_vec_map.keys():
embedding_matrix[i] = word_to_vec_map[word]
모델을 구성하고, 학습하도록 하겠습니다.
model = models.Sequential([
layers.Embedding(max_words, embedding_dim, input_length=maxlen),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.summary()
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics='acc')
학습 진행하고 acc와 loss의 경과를 살펴보도록 하겠습니다.
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
plt.figure(figsize=(12, 4))
plt.subplot(121)
plt.plot(history.history['loss'], 'b-', label='train loss')
plt.plot(history.history['val_loss'], 'b--', label='valid loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(122)
plt.plot(history.history['acc'], 'b-', label='train acc')
plt.plot(history.history['val_acc'], 'b--', label='valid acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()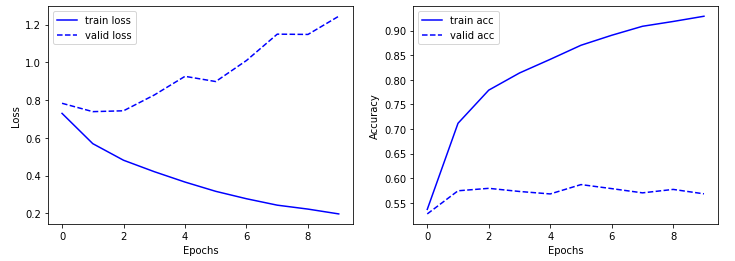
valid loss가 학습이 진행될수록 증가하고, valid acc가 감소하고 있는 것으로 보아 과적합 문제가 발생하고 있는 것으로 보입니다.
model.evaluate(x_test, y_test)
test data의 정확도는 약 57%로 valid acc와 유사하게 나왔습니다.
마지막으로 Embedding layer를 랜덤 초기화를 통해 학습하면 결과가 어떻게 되는지 살펴보겠습니다.
model = models.Sequential([
layers.Embedding(max_words, embedding_dim, input_length=maxlen),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics='acc')
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
model.evaluate(x_test, y_test)
validation data의 정확도가 83%, test data의 정확도가 83%가 나왔습니다. 이 경우에는 해당 작업(리뷰 분석)에 특화된 입력 토큰의 임베딩을 학습했기 때문에 사전 훈련된 단어 임베딩보다 성능이 좋은 것으로 추측됩니다.
결론
위 모델들은 Dense layer로만 구성되므로, 입력 시퀀스에 있는 단어를 독립적으로 다루고 있습니다. 즉, 단어 사이의 관계나 문장 구조를 고려하지 않고, 예측하게 됩니다.
이러한 문제를 해결하기 위해서 다음 글에서 RNN layer를 사용해서 학습해보도록 하겠습니다.
'ML & DL > tensorflow' 카테고리의 다른 글
| [tensorflow] naver 영화 리뷰 감성 분석 (1) | 2020.12.24 |
|---|---|
| 감성분류 on IMDB datasets (2) (0) | 2020.12.24 |
| one-hot encoding과 Tokenizer를 통한 Word Representation (0) | 2020.12.24 |
| [tensorflow] RNN에 사용되는 layer (0) | 2020.12.22 |
| [Tensorflow] Neural Style Transfer 튜토리얼 (0) | 2020.12.15 |




댓글