해당 내용은 Coursera의 딥러닝 특화과정(Deep Learning Specialization)의 네 번째 강의 Convolutional Neural Networks를 듣고 정리한 내용입니다. (Week 1)
Learning Objectives
- Explain the convolution operation
- Apply two different types of pooling operation
- Identify the components used in a convolutional neural network (padding, stride, filter, ...) and their purpose
- Build and train a ConvNet in TensorFlow for a classification problem
- Convolutional Neural Networks
[Computer Vision]
딥러닝 덕분에 Computer Vision는 매우 빠르게 발전되고 있는 분야 중 하나이다. 컴퓨터 비전 딥러닝은 자율주행 자동차들이 주변의 다른 자동차나 보행자들을 찾아서 피할 수 있게 해주거나, 얼굴 인식을 훨씬 더 잘 동작하도록 해준다. 심지어 새로운 유형의 예술을 탄생시키는 것도 가능하게 해줄 수 있다.
아래는 몇 가지 컴퓨터 비전으로 가능한 것들이다.

이미지를 분류하거나, 또는 자율주행에서 자동차나 보행자 등 다른 물체를 감지할 수 있다. 또는 사진과 미술작품을 합쳐서 새로운 작품을 탄생시킬 수도 있다. 이번 강의에서는 어떻게 이것들이 가능하고 어떻게 하는지 배우게 될 것이다.
컴퓨터 비전의 문제 중의 하나는 매우 큰 input을 가질 수 있다는 것인데, 만약 3채널(RGB)의 64 x 64 크기의 이미지로 작업을 한다고 했을 때에는 입력의 크기가 64 x 64 x 3 = 12288가 된다. 이정도는 그리 나쁜 것은 아니지만, 만약 1000 x 1000 크기의 매우 고화질의 이미지를 입력으로 사용한다면, 300만의 input size를 가지게 된다. 즉 입력은 300만 차원이 되는 것이고, 다음 hidden layer의 unit size가 1000이라면, (1000, 3m) 차원의 파라미터를 가지게 되는 것이다.
그렇다면 고화질 이미지에 대한 파라미터의 개수는 30억개가 되며, 이렇게 많은 파라미터를 가진 NN이 overfitting(과대적합)을 피할만큼 충분한 데이터를 얻는 것이 어렵고, 컴퓨터 사양이나 메모리 사용량을 고려한다면 실행이 불가능하다.
하지만, 컴퓨터 비전 app을 학습할 때, 작은 이미지에 한정되어서 사용하기는 원하지 않기 때문에, 이러한 문제점을 해결하기 위한 방법들을 배워보도록 할 것이다.
Convolution operation은 CNN의 기본적으로 구성되는 block들 중의 하나이다. Edge Detection 예시를 통해서 convolution operation이 어떻게 동작하는지 살펴보도록 하자.
[Edge Detection Example]
왼쪽 이미지가 있을 때, 오른쪽처럼 어떻게 수직 모서리나 수평 모서리를 감지할 수 있을까?
6x6 grayscale(1 channel)의 이미지가 있을 때, vertical edge를 탐지하기 위해서 우리는 3x3 Matrix를 사용할 것인데, 이 행렬은 filter라고 부른다(kernel이라고 부르기도함). 그리고 위와 같이 filter에 숫자를 채워보도록하자.
그리고 가운데 '*'는 convolution 연산을 의미한다. python에서 *는 곱셈 혹은 행렬 요소간의 곱셉을 나타내기 위해 사용되지만, 여기서는 convolve 연산을 의미하며 *로 계속 표시하도록 한다.
그래서 연산을 하게 되면 output은 4x4 matrix가 되는데, output의 요소들이 어떻게 연산되는지 살펴보자.
output의 첫번째 element를 계산하는 방법은, 원본 input 이미지에 3x3 filter를 영역 위에 두고, 요소간 곱셉을 수행해서 모두 더해주면 된다.
다음 두번째 element(빨간색 박스)는 filter를 한칸 오른쪽으로 옮겨서 구할 수 있다. 그리고 동일하게 요소간 곱을 구하고 다 더해서 output 두번째 element값을 구하게 된다.
모든 연산을 수행하게 되면 아래와 같은 output matrix를 얻을 수 있다.
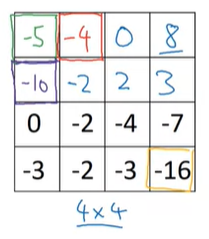
이 과정을 실제 코드에서는 python의 경우에 Conv_forward와 같은 함수나, tensorflow에서는 tf.nn.conv2d, 케라스에서 Conv2D라는 함수로 수행이 가능하다.
그렇다면, 위의 3x3 filter로 convolution 연산을 진행한 것이 어떻게 vertical edge detection을 수행하게 되는 것일까?
조금 더 단순한 이미지를 가지고 convolution 연산한 결과를 살펴보도록 하자.
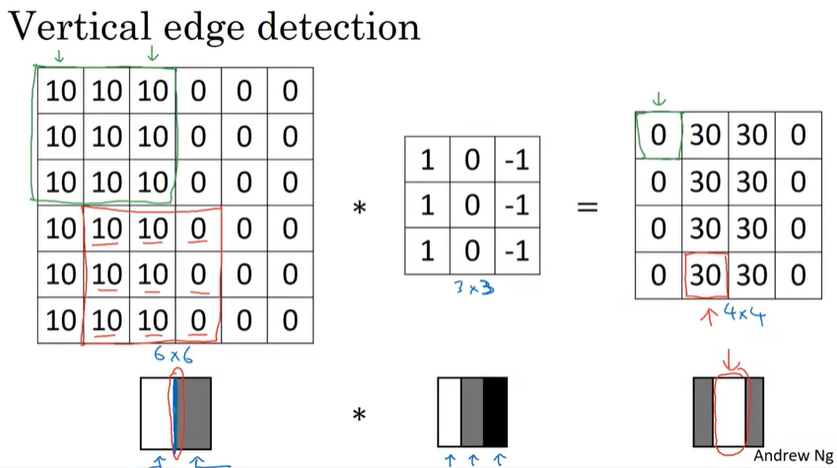
이미지의 각 element의 숫자가 높을수록 밝고, 낮을수록 어둡다고 할 때, 각 이미지, filter, output은 위와 같이 연산된다.
input 이미지를 봤을 때, 중앙에 edge가 있으며 우리는 이것을 검출하면되는데, 3x3 vertical edge detection filter를 사용해서 연산을 하게 되면 오른쪽 4x4 output을 얻을 수 있다. 중앙에 아주 밟은 하얀색 부분이 존재하게 되는데, 이 부분에 의해서 vertical edge를 감지할 수 있다.
우리가 input 이미지를 꽤 작은 것으로 사용했기 때문에, 흰색 부분이 꽤 두꺼워 보일 수 있는데, 만약 1000x1000과 같은 고해상도의 이미지를 사용한다면, 이미지의 vertical edge가 더 잘 감지될 것이다.
[More Edge Detection]
이번에는 positive edge와 negative edge의 차이점과 다른 유형의 edge detector를 살펴보도록 하자.
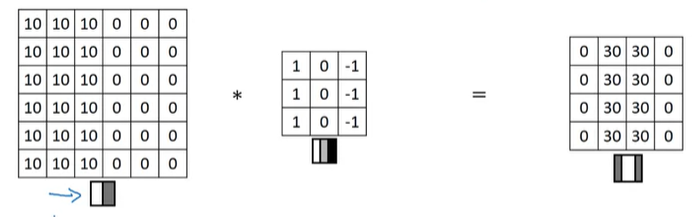
방금 전 위에서 봤던 예시인데, input 이미지가 왼쪽은 밝고 오른쪽은 어두운 이미지이다. 이러한 Edge를 positive edge라고 한다. 그리고 3x3 filter를 conv 연산을 통해서 이미지 가운데에 vertical edge를 감지하도록 했다.
만약 input 이미지의 색상이 뒤집어져서, 왼쪽이 어둡고 오른쪽이 밝게 된다면 어떻게 될까? 즉, negative edge인 이미지를 의미한다.
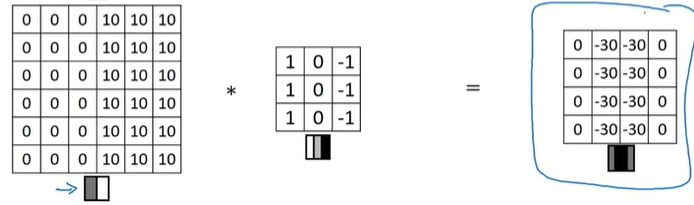
전환되는 명암이 반대가 되기 때문에, 위와 같이 conv 연산 결과값이 -30으로 나타나게 된다. 이것은 edge가 어두운 색에서 밝은 색으로 변환한 것을 감지했다는 의미이고, 만약 positive나 negative를 신경쓰지 않는다면, output matrix에 절대값을 얻어서 사용하면 된다.
지금까지 vertical edge detection을 살펴보았는데, horizontal edge detection은 아래의 filter를 사용해서 감지할 수 있다.
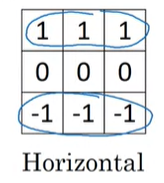

그래서 위와 같은 6x6 이미지가 조금 복잡한 예시이긴 하지만, 이 input 이미지를 horizontal edge filter와 conv연산을 하게 되면, 오른쪽 4x4 output matrix를 얻을 수 있다. 초록색 박스의 경우에는 10 -> 0으로 변화하는 positive edge의 결과이며, 보라색 박스의 경우는 0 -> 10으로 변화하는 negative edge의 결과이다. 여기서 노란색 박스의 10을 살펴보면, 왼쪽은 positive edge를 감지하고 있고, 오른쪽은 negative edge를 감지하고 있는 것을 볼 수 있다. 따라서 두 edge 감지가 섞여서 중간값을 나타내고 있는것이다. 6x6 이미지는 매우 작기 때문에 체감이 되지 않겠지만, 1000x1000 정도의 이미지라고 한다면, 10이나 -10과 같은 전환영역은 보이지 않게 된다.
지금까지 vertical, horizontal edge detection filter를 살펴봤는데, 이는 우리가 선택할 수 있는 filter들 중에 일부이다.

이렇게 우리가 9개의 숫자를 선택할 수 있는데, 딥러닝에서는 직접 선택할 필요가 없으며, 학습을 통해서 이 값들을 얻게 된다. 즉, 3x3 filter의 경우에는 9개의 학습할 parameter를 갖게 되는 것이다.
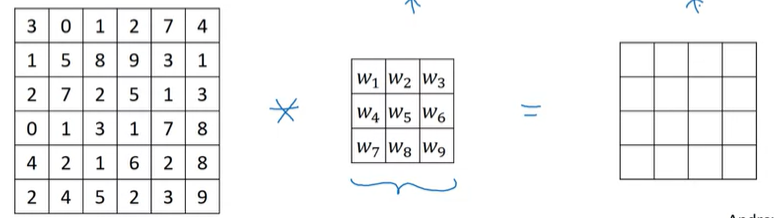
그렇기 때문에, 어느 방향의 edge detection이든지 데이터로부터 학습할 수 있다. (이것은 low-level의 feature가 된다)
따라서, CNN에서의 장점은 어떤 특정한 filter를 선택하는 것이 아니라, 학습을 통해서 최적의 filter(일종의 weight)를 얻게 되는 것이다.
[Padding]
우리는 6x6 이미지에 3x3 filter로 conv연산을 했을 때, output matrix가 4x4의 크기를 갖는 것을 보았다. 4x4 matrix가 되는 이유는 3x3 filter가 input 이미지에 놓일 수 있는 공간이 4x4이기 때문이다.
따라서, (n x n) image * (f x f) filter를 연산하면 (n - f + 1) x (n - f + 1)의 output을 얻을 수 있다.
이 부분에서 2가지 단점이 존재한다.
1. convolution 연산을 수행할 때마다 이미지가 작아진다. 계속해서 작아진다면, 몇 번의 conv연산 밖에 할 수 없게 된다.
2. 코너나 모서리에 존재하는 픽셀은 많이 사용되지 않는다. -> 코너나 모서리에 존재하는 픽셀의 정보를 버리는 것과 같다.
이렇게 이미지가 conv연산을 할 때마다 줄어든다면, 만약 100개의 deep layer를 가진 network가 있을 때 100 layer 이후에는 너무나 작은 이미지만 남게 되고, 또한 가장자리의 정보들을 버리게 된다.
이 문제점을 해결하기 위해서 우리는 경계에 이미지를 채워서(padding을 추가해서), conv연산을 이미지 전체에 적용하면 된다.
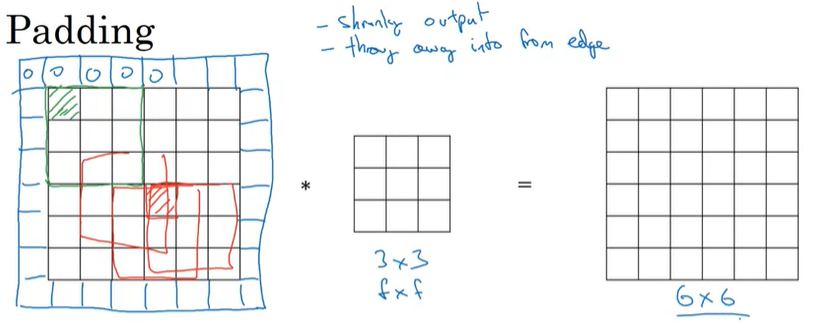
위와 같이, 원래 6x6 이미지에 padding을 추가해서 8x8이미지로 만들고 3x3 filter를 통해서 conv연산을 수행하면, output matrix는 입력 이미지와 동일한 6x6 크기의 matrix를 얻을 수 있게 되며, 원본 이미지의 크기를 보존하게 된다.
padding의 정도를 p라고 한다면, (기본 p = 0; no padding) 아래와 같은 공식으로 크기가 결정된다.
(n + 2p, n + 2p) image * (f, f) filter = (n + 2p - f + 1, n + 2p - f + 1) output
물론 p=2, 2개의 pixel을 추가해도 된다.
padding의 존재에 따라서 두 가지 옵션의 convolution이 있는데, 각각 Valid Convolution, Same Convolution이라고 부른다.
Valid Convolution은 기본적으로 padding없이 conv연산하는 것을 의미한다.
Same Convolution은 padding을 추가해서 input size가 output size와 동일하도록 conv연산하는 것을 의미한다.

Same Convolution에 대해서 조금 더 살펴보면, input image가 (n, n), filter가 (f, f), 그리고 padding을 p만큼 적용한다면, output matrix는 (n+2p-f+1, n+2p-f+1)이 된다. 우리는 이 size가 input과 동일하도록 만들기 위해서 방정식으로 정리하면, 결국 로 나타낼 수 있다.
전형적으로 f는 거의 홀수이며, 만약 짝수라면, 비대칭 padding을 해야한다.(f를 홀수로 지정해서 중앙 포지션을 갖도록 하는 것이 computer vision에서 좋은 편이다) f가 홀수인 것이 항상 좋다는 이유는 될 수 없지만, 많은 논문에서 3x3 filter가 흔하며, 5x5, 7x7, 1x1의 filter도 존재하며, 만약 f가 짝수더라도 좋은 성능을 낼 수도 있다.
[Strided Convolution]
Strided Convolution은 CNN에서 사용되는 기본적인 building block 중의 하나이다. 7x7 이미지를 3x3 filter와 conv연산을 수행하는데, stride = 2로 설정한다고 하면 다음과 같은 연산된다.
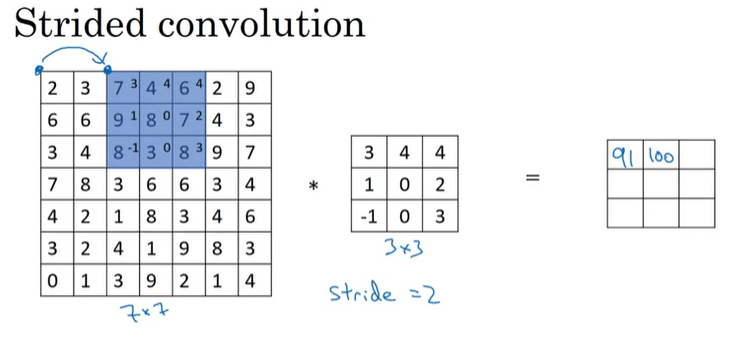
첫 번째 element는 이전과 동일하게 진행하지만, 2번째 element는 원본 이미지에서 2칸 이동해서 element-wise 곱을 수행하게 된다.

그 결과, 우리는 7x7 image와 3x3 filter를 conv연산을 통해서 3x3 output matrix를 얻게 된다. input과 output 크기는 다음 공식에 따라서 결정된다. (padding p, stride s가 있을 때)
를 의미하며, 만약 정수가 아니라면 소수점은 버리게 된다. 즉, 위에서 파란색 박스가 이미지 내에 완전히 포함될 경우에만 유효하다는 것을 의미한다.
여기서는 p = 0이고, s = 2 이기 때문에, 공식을 적용하면,
이 된다.

추가적으로, 수학적인 의미의 convolution과 CNN에서의 convolution은 사실 방법이 조금 다르다.
수학적인 의미에서 convolution은 요소간의 곱을 진행하기 전에 수행하야되는 단계가 하나 더 있으며, 이 단계는 filter를 상하좌우 반전을 시켜주는 것이다. 따라서 CNN에서 수행하는 conv연산은 실제적으로는 cross_correlation에 해당하지만, 딥러닝에서는 그냥 convolution이라고 부른다.
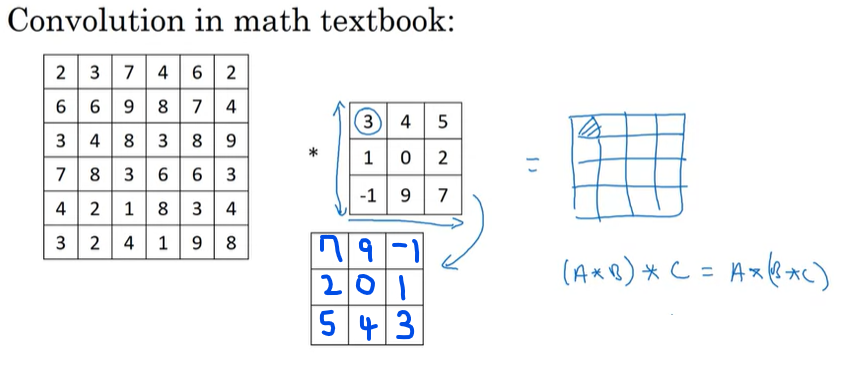
위와 같이 filter를 반전시켜주는 단계가 필요하지만, 이 부분은 신호처리에는 적합하지만 딥러닝과 크게 상관없기 때문에 반전을 시키는 단계(mirroring operation)은 생략한다.
[Convolutions Over Volume]
지금까지 2-dim에서의 convolution 연산을 살펴보았고, 이제는 3-dim 이상의 volume에서 어떻게 conv연산을 수행하는지 살펴보자.
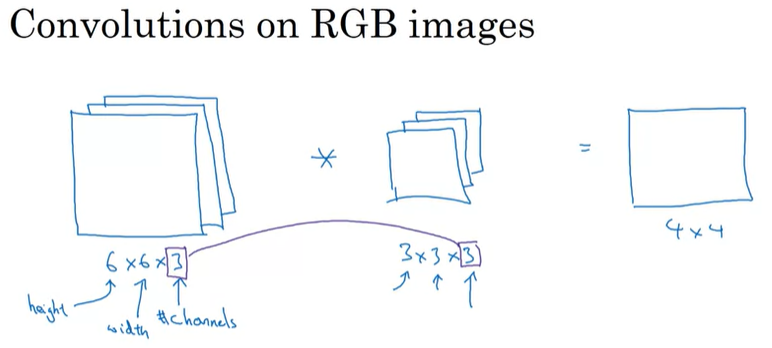
우선 RGB channel을 가지고 있는 이미지를 convolution 연산을 수행한다면, 연산에 사용되는 filter의 channel은 input 이미지의 channel과 동일해야 한다. 이렇게 연산을 하게 되면, ouput은 4x4가 되는데, 이것은 4x4x1이라는 것을 명심해야한다. 어떻게 연산되는지 자세하게 살펴보자.
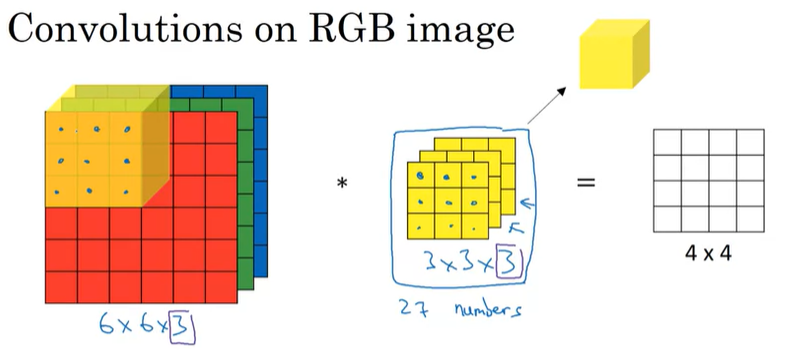
일반적인 conv연산과 거의 동일하며, 차이점은 input과 filter를 각각의 채널에서 요소간의 곱을 수행한다. 그러면 각 채널마다 9개의 결과값이 나오고, 총 27개의 결과값이 나오게 된다. 그리고 이 결과값들을 모두 더해주면, 최종 output이 되는 것이다. 나머지 element들도 기존과 동일한 방법으로 구하고, 채널끼리 conv 연산을 수행해서 모두 더해주면 된다.
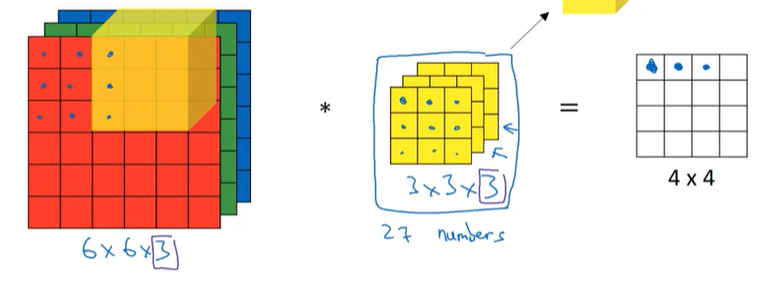
그리고, 만약 R Channel에서만 Edge를 감지하고 싶다면, R channel만 채워고, 나머지 channel은 전부 0으로 채우면 된다.
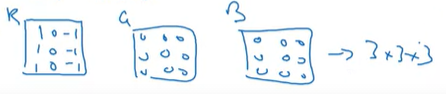
이렇게 하면, R Channel에서만 Vertical Edge 감지하는 filter가 된다.
또는, vertical edge의 색상을 신경쓰지 않는다면, 3가지 channel에 모두 동일하게 vertical edge detector로 만들 수 있으며, 이렇게 만든다면 어느 색상의 모서리도 감지할 수 있는 filter가 된다.

이렇게 파라미터를 다르게 선택함으로써, 3x3x3 filter로부터 다른 feature detector를 얻을 수 있다.
위 예시는 6x6x3 input image를 3x3x3 filter로 conv연산을 수행하면 4x4, 즉, 하나의 필터를 사용해서 결과는 2-dim으로 나타나는 것을 보여주고 있다. 만약 우리가 동시에 여러 filter를 사용하고 싶다면 어떻게 해야 할까?
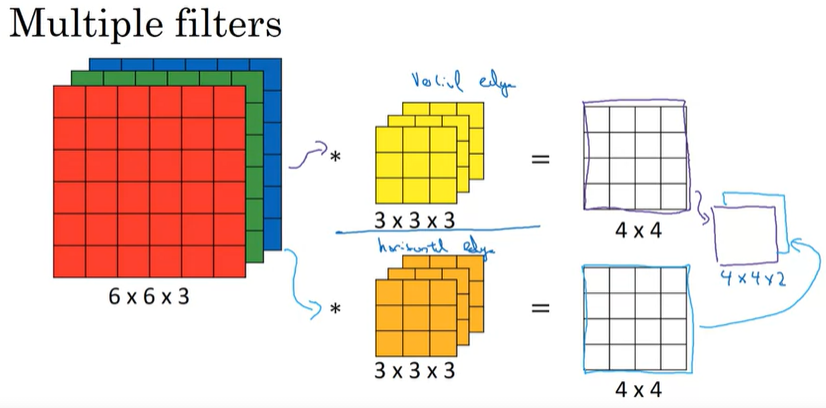
만약 동시에 2가지 filter를 사용하기 원한다면, 위와 같이 각각의 filter(여기서는 vertical edge와 horizontal edge detector)에 대해서 conv연산을 수행하고, 결과 matrix를 쌓으면 된다. 따라서, 결과는 4x4x2의 matrix가 된다.
요약하자면, 다음과 같이 나타낼 수 있다.
여기서 는 input 이미지의 channel을 의미하고, 는 filter의 수를 의미한다.
이렇게 filter의 수를 추가함으로써 다른 feature들을 동시에 감지할 수 있도록 해준다.
여기서 input의 마지막 dimension을 channel의 수라고 언급했는데, 종종 다른 문헌에서는 volume의 'depth'라고 부르기도 한다. channel과 depth, 모두 문헌들에서 흔하게 사용되는 표현이지만, Neural network의 depth를 말할 때도 동일하게 depth를 사용하므로 혼동이 될 수도 있어서, 강의에서는 세 번째 dimension을 channel이라는 용어로 지칭한다.
[One Layer of a Convolutional Network]
이제 CNN에서 하나의 layer를 어떻게 구성하는지 살펴보도록 하자.
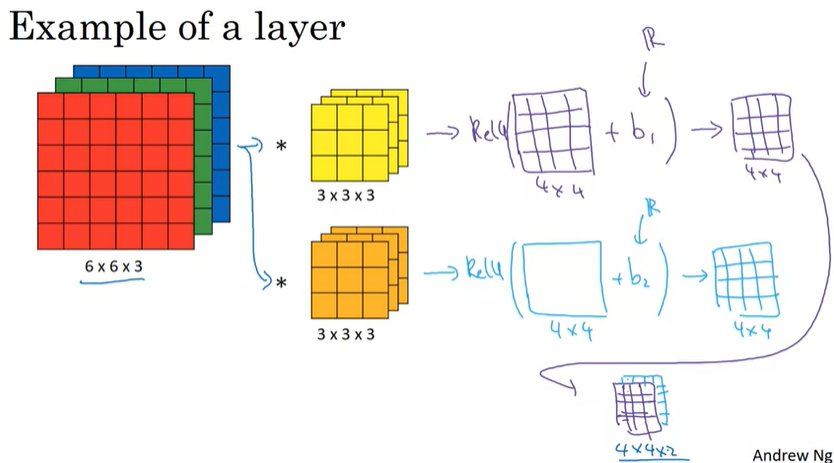
이전 강의까지 우리는 input 이미지를 filter를 통해 conv연산을 수행했는데, 연산을 수행하고 bias를 추가한 후에 non-linear(ReLU)를 적용한다. 이 과정이 하나의 CNN layer가 된다.
우리가 잘 아는 공식으로 나타낸다면, 다음과 같이 나타낼 수 있을 것이다.
은 input x이고, filter들이 와 같은 역할을 하게 된다.
이 예제에서는 2개의 filter를 사용했기 때문에, output이 4x4x2로 나타나고, 만약 10개의 filter를 사용했다면, 4x4x10의 결과를 얻을 수 있다.
예제를 같이 풀어보면서 한 layer에서 파라미터의 개수가 어떻게 되는지 한번 살펴보도록 하자.

만약 CNN Layer에서 3x3x3의 filter 10개를 사용한다면, 이 layer에서 파라미터의 개수는 어떻게 될까?
하나의 filter를 먼저 살펴보면, 각 filter는 3x3x3=27 parameters와 1개의 bias가 존재하며, 따라서 하나의 filter에는 28개의 parameter가 존재한다.
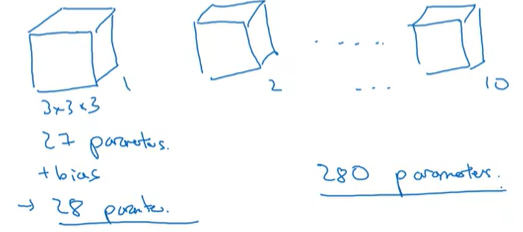
따라서, 총 280개의 파라미터가 존재하게 된다.
여기서 CNN의 장점이 나타나는데, input 이미지의 크기가 아무리 크다고 하더라도 파라미터의 수는 280개로 항상 고정되어 있다. 따라서, 매우 큰 이미지가 있더라도 overfitting하지 않도록 할 수 있게 된다.
Notation 정리
- if layer l is a convolution layer
- = filter size
- = padding(same or valid 선택 가능)
- = stride
- = number of filters
기본적인 notation은 위와 같고, 이제 input/output, filter의 크기가 어떻게 표시되는지 살펴보자.
- Input :
- Output :
- Each filter : , : 이전 layer output의 와 동일
- Activations :
m개의 example이 있다면, activation, weight, bias는 다음과 같이 나타낼 수 있다.
- weights : , 개의 filter 존재
- bias : , 실수이므로 차원으로 표현하, 가 된다.
이런 notation에서 보편적인 표준규칙은 존재하지 않는다. 다른 논문에서는 채널의 수가 가장 먼저 표기되기도 하는데, 강의에서는 가장 뒤쪽에 위치하도록 표기한다.
'Coursera 강의 > Deep Learning' 카테고리의 다른 글
| Object Detection(YOLO algorithm) (0) | 2020.11.22 |
|---|---|
| CNN (LeNet-5, AlexNet, VGG-16, ResNets, Inception Network) (0) | 2020.11.18 |
| ML Strategy 2-2 (Transfer learning, Multi-task learning, End-to-end learning) (0) | 2020.10.30 |
| ML Strategy 2-1 (Error Analysis, Data mismatched) (0) | 2020.10.28 |
| ML Strategy 1(orthogonalization, evaluation metric, human-level performance) (0) | 2020.10.25 |




댓글