- 참조 문헌 및 사이트(Reference)
Data Structure : A Pseudocode Approach with C
Data Structure and Algorithm in C++
리스트 List
리스트는 자료구조(Data Structure)에서 기본이 되는 추상자료형(Abstract Data Type:ADT)으로, sequential한 data의 집합입니다. 즉, 선형적으로 순서가 있는(ordered) 값들의 집합이라고 보면 되겠습니다.
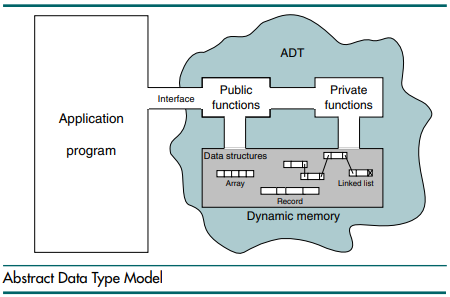
여기서 ADT란 간단하게 data의 정의와 그 data에 대한 연산이 정의된 가상의 자료구조를 의미하며, 그 연산에는 data의 삽입/삭제/탐색 등이 있습니다.
리스트는 배열(Array)이나 연결리스트(Linked List)로 구현이 가능합니다.
배열은 프로그래밍을 공부한다면 알고 있을 것이라고 생각하고 넘어가도록 하겠습니다..
연결리스트 Linked List
연결리스트는 각 요소(element)들이 다음 요소의 주소를 포함하고 있는 순서가 있는 데이터의 모임입니다.
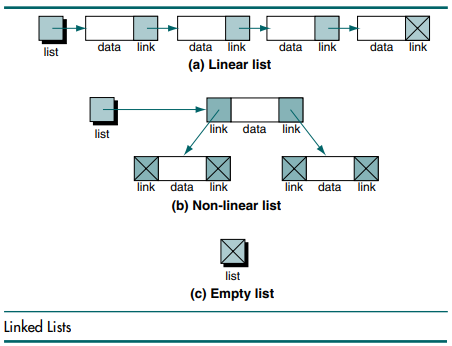
연결리스트에서 각 요소에는 데이터 값과 하나 혹은 하나 이상의 Links로 구성되어 있습니다. 데이터 값은 말 그대로 연결리스트 내에서 처리되는 자료이고 Link는 그 데이터들을 연결시켜주는 역할을 하게 됩니다. 아래 그림과 같이 각 요소에 link가 다른 요소의 주소를 가리키고 있습니다.
Linear list는 단순히 하나의 link가 있어서 다음 요소를 가리키고 있으며 마지막 요소는 아무것도 가리키고 있지 않습니다. Non-linear list는 한 개 이상의 link가 있으며, link가 하나인 연결리스트를 단일 연결리스트(singly linked list)라고 하며, link가 두개인 연결리스트를 이중 연결리스트(doubly linked list)라고 합니다.
연결리스트는 배열과 비교했을때, 요소의 삽입과 삭제 시에 추가 공간 또는 빈 공간을 위해서 Shift하지 않아도 되기 때문에 삽입과 삭제가 더 쉽습니다. 반면에 물리적인 시퀀스가 아니여서, 배열보다 탐색속도는 떨어지게 됩니다.
Nodes 노드
연결리스트 구현에서 리스트의 각 요소는 노드(node)라고 불립니다. 노드는 데이터와 하나 혹은 하나 이상의 link가 존재합니다. 아래 그림은 두 종류의 노드를 보여주고 있으며, 하나는 linear list의 노드이고 다른 하나는 non-linear list의 노드입니다.

노드에서 data는 하나뿐만 아니라 여러개가 될 수 있으며, 구조체 또한 가능합니다.
그리고 연결리스트는 무조건 head 포인터를 가져야합니다. 또한, 어떻게 리스트를 사용하느냐에 따라서 다른 포인터를 추가할 수도 있습니다. 많은 자료구조에서 효율을 높이기 위해서 마지막 노드를 가리키는 포인터를 추가적으로 사용하기도 합니다.
다음으로 실제로 어떻게 코드로 나타내는지 알아봅시다. 여기서 Generic Code라는 새로운 용어가 나오는데, Generic Code란 우리가 어떤 데이터 타입에도 적용할 수 있도록 코드를 구현하는 것을 의미합니다. 예를 들어, int형 자료형에만 국한되는 것이 아니라, 추가적인 구현없이도 다른 어떤 자료형에서도 사용될 수 있는 코드를 말하는 것입니다. C언어에서는 void pointer를 사용해서 구현할 수 있고, C++에서는 templete를 사용해서 구현할 수 있습니다.
물론 C++에서는 STL에 <list> 헤더파일에 다 구현되어 있으므로 이것을 바로 사용하면 되는데, 직접 한번 구현해보도록 하죠.
Singly Linked List 단일 연결 리스트
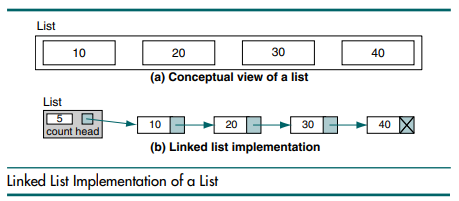
단일 연결리스트는 위 그림의 (b)와 같이 구현됩니다. List의 head 포인터가 연결리스트의 첫 번째 노드를 가리키게 되며, 각 노드의 link는 다음 노드를 가리키게 됩니다. 여기서 자료구조의 크기는 4이며, [ 10 20 30 40 ]의 값을 순차적으로 저장하고 있고, 마지막 노드의 link는 null 포인터로 아무것도 가리키고 있지않습니다.
기본적인 동작에는 삽입, 삭제가 있습니다.
1. 삽입 Insertion
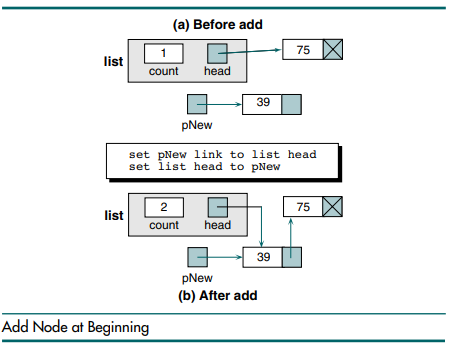
연결리스트의 첫번째 위치에 삽입하는 경우는 살펴봅시다. head 포인터를 새로운 노드(39)에 연결하고, 새로운 노드가 head가 가리키고 있던 노드를 가리키도록 하면 됩니다.

새로운 값을 연결리스트의 중간에 삽입하는 경우를 알아봅시다. 우리는 삽입하고자 하는 위치의 이전 노드(39)의 연결을 끊고, 새로운 노드(52)로 연결해주고 새로운 노드는 이전 노드(39)의 다음 노드(75)로 연결시켜줍니다. 연결리스트의 마지막에 삽입하는 것과 동일합니다.
2. 삭제 Deletion

첫 번째 노드를 삭제하는 경우를 살펴보면, 1)pLoc 포인터로 삭제할 노드를 저장하고 2)head 포인터를 첫번째 노드가 가리키고 있던 노드로 변경합니다. 그리고 pLoc가 가리키고 있는 노드를 삭제(메모리 해제)하면 됩니다.
1)을 먼저 하지 않으면, 우리는 삭제할 노드를 참조하지 못하고 노드를 잃어버리게 되어서 삭제가 불가능해집니다...(메모리가 누수된다)

일반적으로 중간에 위치한 노드의 삭제는 위와 같습니다. 1)삭제할 노드를 우선 pLoc에 저장하고, 2)삭제할 노드의 이전 노드(39)가 삭제할 노드(75)의 다음 노드(134)를 가리키게 합니다. 그리고 pLoc에 저장된 노드를 삭제하면 됩니다.
연결리스트의 순회(iteration)은 삽입/삭제와 마찬가지로 반복문을 통해서 각 노드에 접근할 수 있습니다.
다른 용도로 별도의 포인터가 존재하지 않는 이상 head 포인터로만 연산을 한다면 첫번째 노드부터 다음 노드로 순차적으로 접근하기 때문에 연결리스트의 크기가 N일 때, O(N)의 시간이 걸리게 됩니다. 다만, K번째 자리에 추가한다면 O(K)의 시간이 걸리고, 만약 삽입과 삭제를 첫번째 노드에서만 수행한다면 O(1)의 시간이 걸립니다.
처음에 언급했지만, 배열과 비교하자면 배열은 랜덤 Access가 가능해서(인덱스로 접근하기 때문에) 어느 원소에 접근하든지 O(1)의 시간이 걸리지만, 삽입과 삭제는 배열을 쉬프트해주는 추가적인 연산이 필요하기 때문에 평균 O(N)의 시간이 걸리게 됩니다.
따라서 연결리스트는 삽입과 삭제 연산이 많은 자료구조에 유용하고, 배열은 자료에 탐색이 많은 경우에 유용합니다.
이제 직접 구현해봅시다. 언어는 C++을 사용했습니다.
우선 node는 다음과 같이 구현할 수 있습니다.
template<typename T>
class SNode {
public:
SNode(const T data, SNode<T>* next) : data(data), next(next) {}
T data;
SNode<T>* next;
};다음 node를 가리키는 하나의 node 포인터를 가지며, 다양한 타입의 자료형을 처리하기 위해서 template를 사용해주어서 node 자료형을 위와 같이 구현하였습니다. line 4는 생성자로 사용되며, 초기에 노드의 변수들을 설정해줍니다.
단일 연결리스트 구조는 첫 번째 노드를 가르켜야하는 head 포인터와 현재 노드의 개수를 저장하는 count 변수, 그리고 노드의 삽입, 삭제, 탐색을 위한 내부 함수가 필요할 것입니다. 우선 구현되는 코드는 아래와 같습니다.
template<typename T>
class SLinkedList {
public:
SLinkedList() : count(0), head(nullptr), tail(nullptr) {}
~SLinkedList();
/* insert(const T& data, int k) : insert node at the k-th */
void insert(const T data, int k);
/* erase(int k) : erase node at the k-th */
void erase(int k);
/* search(const T data) : find index of data at first. Or return -1 if fail to find data */
int search(const T data);
/* isEmpty() : If SLinkedList is empty, return true. Or false */
bool isEmpty() const;
/* front() : Return the data of first node */
T front() const;
SNode<T>* head;
SNode<T>* tail;
int count;
};우선 정의되는 변수부터 살펴보면 단일 연결리스트의 첫 번째 노드를 가리키는 head 포인터와 연결리스트의 개수를 저장하는 count가 있습니다. 그리고 추가적으로 마지막 노드를 가리키는 tail 포인터도 추가를 해주었습니다.
기본 동작으로는 삽입을 위한 insert(const T data, int k), 삭제를 위한 erase(int k)를 구현했습니다. 이는 k번째 요소에 노드를 추가 및 삭제한다는 의미입니다. 그리고 추가적으로 특정 값이 존재하는지 확인하는 search(const T data), 연결리스트가 비었는지 확인하는 isEmpty()와 head 노드의 데이터를 반환하는 front() 함수까지 구현을 해보았습니다.
전체 소스코드는 아래와 같습니다. template을 사용하면서 선언과 구현을 나누기 위해서 선언은 .h파일에 구현은 .hpp파일에 구현을 하였습니다.
/* SLinkedList.h */
#ifndef SLinkedList_H
#define SLinkedList_H
#include <stdlib.h>
template<typename T>
class SNode {
public:
SNode(const T data, SNode<T>* next) : data(data), next(next) {}
T data;
SNode<T>* next;
};
template<typename T>
class SLinkedList {
public:
SLinkedList() : count(0), head(nullptr), tail(nullptr) {}
~SLinkedList();
/* insert(const T& data, int k) : insert node at the k-th */
void insert(const T data, int k);
/* erase(int k) : erase node at the k-th */
void erase(int k);
/* search(const T data) : find index of data at first. Or return -1 if fail to find data */
int search(const T data);
/* isEmpty() : If SLinkedList is empty, return true. Or false */
bool isEmpty() const;
/* front() : Return the data of first node */
T front() const;
SNode<T>* head;
SNode<T>* tail;
int count;
};
#include "SLinkedList.hpp"
#endif/* SLinkedList.hpp */
/* Destructor */
template<typename T>
SLinkedList<T>::~SLinkedList()
{
while (!isEmpty())
erase(0);
}
template<typename T>
void SLinkedList<T>::insert(const T data, int k)
{
if (k > count || k < 0)
return;
if (k == 0)
{
head = new SNode<T>(data, head);
tail = head;
}
else
{
SNode<T>* preNode = head;
for (int i = 0; i < k - 1; i++)
preNode = preNode->next;
preNode->next = new SNode<T>(data, preNode->next);
if (k == count)
tail = preNode->next;
}
count++;
}
template<typename T>
void SLinkedList<T>::erase(int k)
{
if (k >= count || k < 0)
return;
SNode<T>* preNode = head;
if (k == 0)
{
head = head->next;
delete preNode;
}
else
{
SNode<T>* delNode;
for (int i = 0; i < k - 1; i++)
preNode = preNode->next;
delNode = preNode->next;
preNode->next = preNode->next->next;
delete delNode;
if (k == count - 1)
tail = preNode;
}
count--;
}
template<typename T>
int SLinkedList<T>::search(const T data)
{
SNode<T>* curNode = head;
for (int i = 0; i < count; i++)
{
if (curNode->data == data)
return i;
curNode = curNode->next;
}
return -1;
}
template<typename T>
bool SLinkedList<T>::isEmpty() const
{
return (count == 0);
}
template<typename T>
T SLinkedList<T>::front() const
{
if (isEmpty())
exit(1); //wrong access
return head->data;
}
//for printing SLinkedList
template<typename T>
ostream& operator<<(ostream& o, const SLinkedList<T>& SList)
{
SNode<T>* walkNode = SList.head;
o << "[ ";
for (int i = 0; i < SList.count; i++)
{
o << walkNode->data;
walkNode = walkNode->next;
if (i < SList.count - 1)
o << " -> ";
}
o << " ]\n";
return o;
}
삽입을 위한 코드는 다음과 같습니다.
template<typename T>
void SLinkedList<T>::insert(const T data, int k)
{
if (k > count || k < 0)
return;
if (k == 0)
{
head = new SNode<T>(data, head);
tail = head;
}
else
{
SNode<T>* preNode = head;
for (int i = 0; i < k - 1; i++)
preNode = preNode->next;
preNode->next = new SNode<T>(data, preNode->next);
if (k == count)
tail = preNode->next;
}
count++;
}data를 k번째에 삽입을 하는 코드로, 만약 k가 연결리스트의 크기보다 크거나 음수면 바로 함수를 종료합니다. 그리고 k가 0일 때에만 따로 처리를 해주는데, 이는 연결리스트에 head 포인터 값을 수정해야하기 때문입니다. 이외의 경우에는 반복문으로 k-1번째 노드를 찾고, k-1번째 노드의 next 포인터에 새로운 노드를 연결하고, 새로운 노드의 next는 k번째 노드를 가리키게하면 됩니다. 그리고 마지막 위치에 삽입되면 tail 포인터를 새로운 노드로 변경해줍니다.
template<typename T>
void SLinkedList<T>::erase(int k)
{
if (k >= count || k < 0)
return;
SNode<T>* preNode = head;
if (k == 0)
{
head = head->next;
delete preNode;
}
else
{
SNode<T>* delNode;
for (int i = 0; i < k - 1; i++)
preNode = preNode->next;
delNode = preNode->next;
preNode->next = preNode->next->next;
delete delNode;
if (k == count - 1)
tail = preNode;
}
count--;
}삭제함수입니다. 삽입과 유사하게 k번째 노드를 삭제하는 함수이며, 이것또한 k가 0일 때에는 head 포인터를 삭제해야하기 때문에 예외로 처리합니다. 이외의 경우에는 반복문으로 k-1번째 노드를 찾고, 삭제할 k번째 노드를 delNode에 저장합니다. 그리고 k-1번째와 k+1번째 노드를 연결해주고, k번째 노드를 가리키는 delNode를 삭제하면 됩니다. delNode없이 삭제를 하면 k+1번째 참조할 수 있는 연결고리가 사라지기 때문에 delNode가 필요합니다. 마찬가지로 삭제되는 노드가 마지막 노드라면, tail 포인터를 이전 노드로 변경해주면 됩니다.
template<typename T>
int SLinkedList<T>::search(const T data)
{
SNode<T>* curNode = head;
for (int i = 0; i < count; i++)
{
if (curNode->data == data)
return i;
curNode = curNode->next;
}
return -1;
}데이터 탐색을 위한 함수입니다. 현재 가리키는 curNode를 head부터 시작해서 반복문을 통해서 탐색을 진행합니다. 첫번째로 같은 값이 등장하면 해당 노드의 위치(인덱스)를 반환하며, 찾지 못하면 -1을 리턴하게 됩니다.
isEmpty()나 front() 함수는 간단하게 구현되어 있어서 설명을 생략하도록 하겠습니다.
그리고 마지막에 ostream& operator<<(ostream& o, const SLinkedList<T>& SList) 함수를 출력연산자를 오버로딩을 통해서 구현했고, 연결리스트의 값을 간단하게 출력할 수 있도록 했습니다.
using namespace std;
#include <iostream>
#include "SLinkedList.h"
int main()
{
SLinkedList<int> SList;
SList.insert(10, 0), cout << SList;
SList.insert(5, 1), cout << SList;
SList.insert(3, 2), cout << SList;
SList.insert(2, 3), cout << SList;
SList.insert(1, 0), cout << SList;
SList.insert(20, 5), cout << SList;
SList.insert(6, 4), cout << SList;
SList.insert(8, 5), cout << SList;
SList.insert(7, 8), cout << SList;
SList.erase(2), cout << SList;
SList.erase(0), cout << SList;
SList.erase(5), cout << SList;
SList.insert(12, 4), cout << SList;
SList.erase(1), cout << SList;
return 0;
}그래서 위와 같은 코드를 실행해보면 아래와 같은 결과를 얻을 수 있습니다.
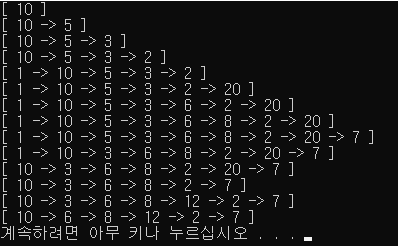
C언어로 구현한 것은 github를 참조하기 바랍니다.
https://github.com/junstar92/DataStructure_Algorithm/tree/master/Data_Structure/SinglyLinkedList
junstar92/DataStructure_Algorithm
Contribute to junstar92/DataStructure_Algorithm development by creating an account on GitHub.
github.com
'Data Structure & Algorithm > 자료구조' 카테고리의 다른 글
| [자료구조] Binary Search Tree(BST) (0) | 2020.09.09 |
|---|---|
| [자료구조] 우선순위큐(priority queue), 힙(heap) (0) | 2020.09.04 |
| [자료구조] 트리(Tree) (0) | 2020.09.03 |
| [자료구조] Queue(큐), Deque(덱) (0) | 2020.09.01 |
| [자료구조] Stack(스택) (0) | 2020.08.31 |




댓글