References
- PyTorch Official Tutorial (link)
Tensors는 파이토치에서 중심이 되는 data abstraction 입니다. 이번 포스팅에서는 튜토리얼에서 설명하고 있는 torch.Tensor에 대해서 조금 더 자세히 살펴보도록 하겠습니다.
import torch import math
시작하기에 앞서, 위의 두 패키지를 import 해줍니다.
Creating Tensors
Tensor를 생성하는 가장 간단한 방법은 torch.empty() 를 호출하는 것입니다.
x = torch.empty(3, 4) print(type(x)) print(x)

여기서 우리는 torch 모듈에 있는 수 많은 factory methods 중 하나를 사용해서 텐서를 생성했으며, 여기서 생성한 텐서는 3개의 행과 4개의 열을 갖는 2차원 텐서입니다.
위에서 생성한 텐서의 타입을 출력하면 torch.Tensor가 출력되며, 이는 torch.FloatTensor의 alias 입니다. 기본적으로 파이토치의 텐서는 32비트 부동소수점 숫자로 채워집니다.
그리고, 위에서 생성한 텐서를 출력했을 때 랜덤한 값이 출력되고 있다는 것을 볼 수 있습니다. torch.empty()를 호출하여 생성한 텐서에는 메모리가 할당되지만 초기화가 수행되지 않습니다. 따라서, 할당 당시에 메모리에 있던 값이 표시됩니다.
만약 텐서를 어떤 값으로 초기화하고 싶다면, 즉, 0 또는 1로 채우거나 임의의 값으로 채우고 싶을 때에는 아래의 factory 메소드를 사용하면 됩니다.
zeros = torch.zeros(2, 3) print(zeros) ones = torch.ones(2, 3) print(ones) torch.manual_seed(1729) random = torch.rand(2, 3) print(random)
torch.rand()는 텐서를 생성하고, 0~1 사이의 값으로 초기화해줍니다.
Random Tensors and Seeding
위에서 랜덤한 값으로 초기화하며 텐서를 생성하는 torch.rand() 함수 호출 바로 전에 torch.manual_seed()를 호출하고 있습니다. 모델의 weight와 같은 텐서를 임의의 값으로 초기화하는 것이 일반적이지만, 특별한 경우에는 결과를 재현하는 것이 필요할 수 있습니다. 이러한 경우에 random seed를 메뉴얼로 설정하면 결과를 재현할 수 있습니다.
torch.manual_seed(1729) random1 = torch.rand(2, 3) print(random1) random2 = torch.rand(2, 3) print(random2) torch.manual_seed(1729) random3 = torch.rand(2, 3) print(random3) random4 = torch.rand(2, 3) print(random4)
random1과 random3은 동일한 값으로 초기화되었습니다. 또한, random2와 random4도 동일한 값으로 초기화된 것을 볼 수 있습니다. Random Number Generator(RNG)의 seed를 수동으로 설정하면, 난수가 재설정되어 동일한 결과를 볼 수 있습니다.
Tensor Shapes
일반적으로 둘 이상의 텐서에서 연산을 수행할 때는 그 텐서들의 shape가 동일해야 합니다. 이를 위해서 파이토치에서는 torch.*_like() 메소드를 지원합니다.
x = torch.empty(2, 2, 3) print(x.shape) print(x) empty_like_x = torch.empty_like(x) print(empty_like_x.shape) print(empty_like_x) zeros_like_x = torch.zeros_like(x) print(zeros_like_x.shape) print(zeros_like_x) ones_like_x = torch.ones_like(x) print(ones_like_x.shape) print(ones_like_x) rand_like_x = torch.rand_like(x) print(rand_like_x.shape) print(rand_like_x)
위 코드에서 가장 먼저 나오는 텐서의 .shape 프로퍼티는 해당 텐서의 각 차원 값을 리스트로 가지고 있습니다. 위의 경우 x는 3차원의 2x2x3 텐서입니다.
아래에서 .empty_like(), .zeros_like(), .ones_like(), .rand_like() 메소드가 사용되고 있습니다. 이 메소드를 사용해서 생성된 텐서의 shape를 확인하면 x와 동일한 차원이라는 것을 알 수 있습니다.
텐서를 생성하는 또 다른 방법은 파이토치 collection으로부터 데이터를 직접 지정하는 것입니다.
some_constants = torch.tensor([[3.1415926, 2.71828], [1.61803, 0.0072897]]) print(some_constants) some_integers = torch.tensor((2, 3, 5, 7, 11, 13, 17, 19)) print(some_integers) more_integers = torch.tensor(((2, 4, 6), [3, 6, 9])) print(more_integers)
파이썬의 튜플이나 리스트 타입의 데이터가 있다면, torch.tensor()를 사용하여 간단히 텐서를 생성할 수 있습니다. 위와 같이 collection을 중첩시키면, 다차원의 텐서가 생성됩니다.
Tensor Data Types
텐서의 데이터 타입을 설정하는 방법은 아래와 같이 몇 가지가 있습니다.
a = torch.ones((2, 3), dtype=torch.int16) print(a) b = torch.rand((2, 3), dtype=torch.float64) * 20. print(b) c = b.to(torch.int32) print(c)

텐서의 기본 데이터 타입을 설정하는 가장 간단한 방법은 텐서를 생성할 때, optional argument인 dtype을 설정해주는 것입니다. 위의 코드에서 텐서 a는 생성할 때, 'dtype=torch.int16'을 전달했습니다. 해당 텐서를 출력해보면 '1.' 이 아닌 '1'이라는 정수로 출력되는 것을 볼 수 있으며, 이 텐서가 부동소수점이 아닌 정수라는 것을 보여줍니다.
또한, dtype을 지정하지 않았을 때와 달리, 텐서를 출력했을 때 dtype도 같이 출력되는 것을 볼 수 있습니다.
데이터 타입을 설정하는 또 다른 방법은 .to() 메소드를 사용하는 것입니다. 위의 코드에서 일반적인 방법을 사용해서 임의의 부동소수점 텐서 b를 생성했고, 그런 다음 .to() 메소드를 사용하여 텐서 b를 32비트 정수로 변환하여 텐서 c를 생성합니다.
사용 가능한 데이터 타입은 다음과 같습니다.
- torch.bool
- torch.int8
- torch.uint8
- torch.int16
- torch.int32
- torch.int64
- torch.half
- torch.float
- torch.double
- torch.bfloat
Math & Logic with PyTorch Tensors
텐서를 가지고 할 수 있는 것들을 살펴보도록 하겠습니다.
먼저 텐서와 스칼라의 연산이 어떻게 상호작용하는지 살펴봅니다.
ones = torch.zeros(2, 2) + 1 twos = torch.ones(2, 2) * 2 threes = (torch.ones(2, 2) * 7 - 1) / 2 fours = twos ** 2 sqrt2s = twos ** 0.5 print(ones) print(twos) print(threes) print(fours) print(sqrt2s)

위의 결과에서 볼 수 있듯이, 텐서와 스칼라에 대한 더하기/빼기/곱하기/나누기/거듭제곱과 같은 연산은 텐서의 모든 요소들에게 적용됩니다. 이러한 연산의 결과는 텐서이므로, three라는 텐서를 생성하는 코드와 같이 일반적인 연산자 우선 순위 규칙과 연결시킬 수 있습니다.
두 텐서 간의 기본적인 연산도 위와 같이 동작합니다.
powers2 = twos ** torch.tensor([[1, 2], [3, 4]]) print(powers2) fives = ones + fours print(fives) dozens = threes * fours print(dozens)

위에서 본 텐서들의 연산에서 가장 중요한 것은 두 텐서의 shape가 동일해야 한다는 것입니다. 만약 두 텐서의 차원이 다르다면, 아래와 같이 런타임 에러가 발생합니다.
a = torch.rand(2, 3) b = torch.rand(3, 2) print(a * b)

Tensor Broadcasting
파이토치에는 numpy의 ndarrays에 적용되는 broadcasting semantics가 동일하게 적용됩니다.
위에서 연산에서 두 텐서는 동일한 차원이어야 한다고 했는데, 한 가지 예외가 있습니다. 이 예외가 바로 tensor broadcasting 입니다. 다음의 예제 코드를 살펴봅시다.
rand = torch.rand(2, 4) doubled = rand * (torch.ones(1, 4) * 2) print(rand) print(doubled)

위의 연산을 살펴보면, 2x4 텐서와 1x4 텐서를 곱하고 있습니다.
브로드캐스팅은 서로 비슷한 모양을 갖는 텐서들 간의 연산을 수행하는 방법입니다. 위의 예제에서는 1-row, 4-column 텐서가 2-row, 4-column 텐서의 두 행에 각각 곱해집니다.
이와 같은 연산은 딥러닝에서 매우 중요합니다. 예를 들면, weight 텐서를 input 텐서의 배치와 곱하는 것이 있습니다. 이러한 경우, 각 개별 배치의 인스턴스에 동일한 연산이 적용되며 동일한 모양의 텐서를 반환합니다. 위에서는 (2,4) * (1,4) 연산은 (2,4) 모양의 텐서를 반환했습니다.
브로드캐스팅 규칙은 다음과 같습니다.
- 각 텐서는 적어도 하나의 차원을 가지고 있어야 한다 (no empty tensors)
- 두 텐서의 차원을 비교할 때, 마지막 차원부터 첫 번째까지 비교하며, 다음을 만족
- 각 차원이 동일하거나
- 차원 중 하나의 크기가 1이거나
- 텐서들 중 하나의 차원이 존재하지 않거나
당연히 동일한 shape의 텐서는 자명하게 broadcastable 합니다.
아래 코드는 위의 규칙을 따르는 브로드캐스킹의 몇 가지 예시입니다.
a = torch.ones(4, 3, 2) b = a * torch.rand( 3, 2) # 3rd & 2nd dims identical to a, dim 1 absent print(b) c = a * torch.rand( 3, 1) # 3rd dim = 1, 2nd dim identical to a print(c) d = a * torch.rand( 1, 2) # 3rd dim identical to a, 2nd dim = 1 print(d)
위의 브로드캐스팅 연산을 자세히 살펴보면 다음과 같습니다.
- 텐서 b를 생성하는 곱셈 연산은 a의 모든 'layer'에 대해 브로드캐스팅됨
- 텐서 c를 생성하는 연산에서는 a의 모든 'layer'와 'row'에 대해 브로드캐스팅됨. 그 결과 각 열의 3개의 값들이 서로 같은 것을 볼 수 있음
- 텐서 d를 생성하는 연산에서는 a의 모든 'layer'와 'column'에 대해 브로드캐스팅됨. 각 행의 결과가 모두 같은 것을 볼 수 있음
아래의 연산은 모두 런타임 에러를 발생시킵니다.
a = torch.ones(4, 3, 2) b = a * torch.rand(4, 3) # dimensions must match last-to-first c = a * torch.rand( 2, 3) # both 3rd & 2nd dims different d = a * torch.rand((0, )) # can't broadcast with an empty tensor
More Math with Tensors
파이토치 텐서는 300개 이상의 연산을 지원합니다. 아래의 예제에서는 연산들의 몇 가지 주요 카테고리를 보여줍니다.
# common functions a = torch.rand(2, 4) * 2 - 1 print('Common functions:') print(torch.abs(a)) print(torch.ceil(a)) print(torch.floor(a)) print(torch.clamp(a, -0.5, 0.5))

# trigonometric functions and their inverses angles = torch.tensor([0, math.pi / 4, math.pi / 2, 3 * math.pi / 4]) sines = torch.sin(angles) inverses = torch.asin(sines) print('\nSine and arcsine:') print(angles) print(sines) print(inverses)

# bitwise operations print('\nBitwise XOR:') b = torch.tensor([1, 5, 11]) c = torch.tensor([2, 7, 10]) print(torch.bitwise_xor(b, c)) # comparisons: print('\nBroadcasted, element-wise equality comparison:') d = torch.tensor([[1., 2.], [3., 4.]]) e = torch.ones(1, 2) # many comparison ops support broadcasting! print(torch.eq(d, e)) # returns a tensor of type bool

# reductions: print('\nReduction ops:') print(torch.max(d)) # returns a single-element tensor print(torch.max(d).item()) # extracts the value from the returned tensor print(torch.mean(d)) # average print(torch.std(d)) # standard deviation print(torch.prod(d)) # product of all numbers print(torch.unique(torch.tensor([1, 2, 1, 2, 1, 2]))) # filter unique elements

# vector and linear algebra operations v1 = torch.tensor([1., 0., 0.]) # x unit vector v2 = torch.tensor([0., 1., 0.]) # y unit vector m1 = torch.rand(2, 2) # random matrix m2 = torch.tensor([[3., 0.], [0., 3.]]) # three times identity matrix print('\nVectors & Matrices:') print(torch.cross(v2, v1)) # negative of z unit vector (v1 x v2 == -v2 x v1) print(m1) m3 = torch.matmul(m1, m2) print(m3) # 3 times m1 print(torch.svd(m3)) # singular value decomposition

지원되는 연산은 link에서 찾아보실 수 있습니다.
Altering Tensors in Place
텐서에 대한 대부분의 binary 연산은 세 번째 새로운 텐서를 반환합니다. c = a * b라면, 새롭게 생성되는 텐서 c는 다른 텐서들과 서로 다른 메모리 영역에 있습니다. 그러나, 중간 과정의 값을 유지할 필요가 없는 연산을 수행할 때는 텐서에 대해 in-place 연산을 수행할 수 있습니다. 즉, 새로 메모리를 할당하지 않고 기존 메모리에서 값만 변경하는 것입니다. 이러한 in-place 연산을 위해 math function들에는 underscore(_)가 추가된 버전의 함수들이 있습니다.
a = torch.tensor([0, math.pi / 4, math.pi / 2, 3 * math.pi / 4]) print('a:') print(a) print(torch.sin(a)) # this operation creates a new tensor in memory print(a) # a has not changed b = torch.tensor([0, math.pi / 4, math.pi / 2, 3 * math.pi / 4]) print('\nb:') print(b) print(torch.sin_(b)) # note the underscore print(b) # b has changed

a에 torch.sin() 함수를 적용하면 새로운 텐서를 새로운 메모리에 할당하여 반환하기 때문에 a는 변경되지 않습니다. 하지만 b의 경우 in-place 연산을 수행하는 torch.sin_()을 사용했기 때문에 in-place 연산이 수행되어 b의 값이 변경되게 됩니다.
산술 연산도 위와 유사하게 동작합니다.
a = torch.ones(2, 2) b = torch.rand(2, 2) print('Before:') print(a) print(b) print('\nAfter adding:') print(a.add_(b)) print(a) print(b) print('\nAfter multiplying') print(b.mul_(b)) print(b)

위와 같은 in-place 산술연산 함수들ㄹ은 torch.Tensor 객체의 메소드이며 torch.sin()과 같은 다른 함수들과 같이 torch 모듈에 있는 것이 아닙니다. 위에서 보듯, a.add_(b)는 메소드를 호출한 텐서에 대해 in-place 연산을 수행합니다.
존재하는 텐서에 연산의 결과를 저장하는 또 다른 방법이 있습니다. 바로 out argument를 사용하는 것인데, 대 부분의 메소드와 함수들에 이 argument가 있습니다. out argument를 사용하여 output을 저장할 텐서를 지정할 수 있습니다. 만약 out 텐서가 올바른 shape, dtype라면 새로운 메모리 할당없이 연산이 수행됩니다.
a = torch.rand(2, 2) b = torch.rand(2, 2) c = torch.zeros(2, 2) old_id = id(c) print(c) d = torch.matmul(a, b, out=c) print(c) # contents of c have changed assert c is d # test c & d are same object, not just containing equal values assert id(c), old_id # make sure that our new c is the same object as the old one torch.rand(2, 2, out=c) # works for creation too! print(c) # c has changed again assert id(c), old_id # still the same object!
위 코드는 a와 b의 행렬곱 연산의 결과를 c에 저장합니다. 이때, 반환되는 텐서를 d에 저장하는데, c와 d를 비교해보면 같은 객체라는 것을 알 수 있습니다. 또한 c의 id를 비교해보면 기존과 동일한 것도 확인할 수 있습니다.
Copy Tensors
파이썬의 모든 객체와 마찬가지로 변수에 텐서를 할당하면 변수는 텐서의 label이 되며 복사하지 않습니다.
a = torch.ones(2, 2) b = a a[0][1] = 561 # we change a... print(b) # ...and b is also altered
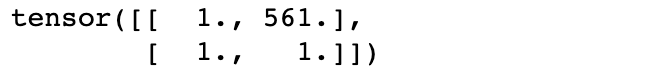
위에서 변수 b에 a를 할당했고, a의 값을 변경하고 b를 출력해도 해당 값이 변경된 것을 볼 수 있습니다.
만약 복사본이 필요하다면, clone() 메소드를 사용하면 됩니다.
a = torch.ones(2, 2) b = a.clone() assert b is not a # different objects in memory... print(torch.eq(a, b)) # ...but still with the same contents! a[0][1] = 561 # a changes... print(b) # ...but b is still all ones

'clone()'을 사용할 때 주의할 점이 있는데, source 텐서의 autograd가 활성화되어 있으면 복사된 텐서도 마찬가지로 활성화됩니다. 이에 대해서는 다음 포스팅에서 조금 더 자세히 다룰 예정입니다.
대부분의 경우, 이러한 동작을 원합니다. 예를 들어, 모델의 forward() 메소드에서 여러 computation path가 있고, 원본 텐서와 복사된 텐서가 모두 모델의 출력에 관여하는 경우, 모델을 학습하려면 두 텐서 모두에 대해 autograd가 활성화되어 있어야 합니다. 따라서, 원본 텐서의 autograd가 활성화되어 있다면 원하는 결과를 얻을 수 있습니다.
반면, 원본이나 복사본이 gradient를 추적할 필요가 없는 연산을 수행하는 경우, 원본 텐서의 autograd를 비활성화시키면 됩니다.
또 다른 경우가 있는데, 모델의 forward() 함수에서 연산을 수행하지만, 일부 메트릭을 생성하기 위해서 중간의 일부 값들을 추출하려고하는 경우입니다. 이러한 경우 원본 텐서를 복사한 복사본이 gradient를 추적하지 않아도 되고, autograd의 history tracking을 끄면 성능이 향상됩니다. 이 경우에는 원본 텐서에서 .detach() 메소드를 사용하면 됩니다.
a = torch.rand(2, 2, requires_grad=True) # turn on autograd print(a) b = a.clone() print(b) c = a.detach().clone() print(c) print(a)
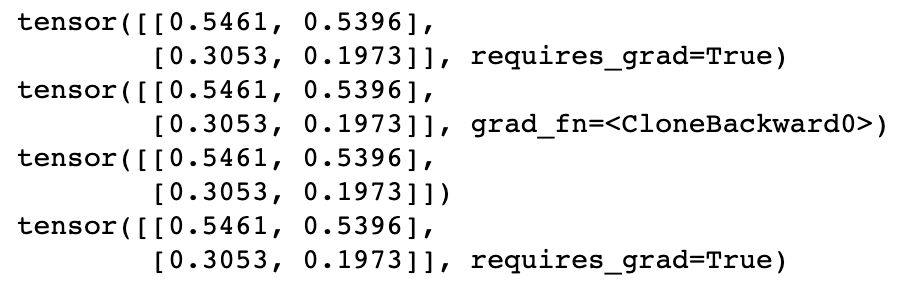
여기서 따로 언급하고 있지는 않은데, 위의 a 텐서와 a.detach()에 의해 반환되는 텐서의 id가 서로 다른 것을 확인했습니다.
공식 문서의 torch.Tensor.detach() 의 설명을 살펴보면, 현재 그래프로부터 detach된 새로운 텐서를 반환한다고 언급하고 있습니다.
단, 반환된 텐서는 원본 텐서와 동일한 메모리 공간을 공유하며, 둘 중 하나에 대한 변경은 다른 텐서에도 반영됩니다.
아래 코드에서 a 텐서에서 detach한 텐서를 a_detach 변수에 저장하고, a_detach의 값을 변경하면 a의 값에도 해당 변경이 반영된 것을 볼 수 있습니다.
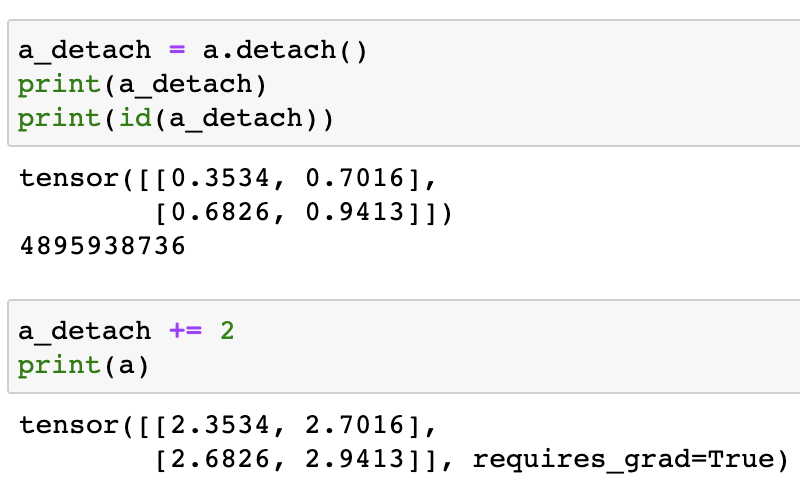
Moving to GPU
파이토치에서는 CUDA-compatible NVIDIA GPUs를 사용하여 가속할 수 있습니다.
이를 위해서는 먼저 is_available() 메소드를 사용하여 GPU를 사용할 수 있는지 확인해야 합니다.
if torch.cuda.is_available(): print('We have a GPU!') else: print('Sorry, CPU only.')
데이터를 GPU 디바이스로 가져오는 방법에는 여러 가지가 있는데, 먼저 텐서를 생성할 때 다음과 같이 명시적으로 디바이스를 지정할 수 있습니다.
if torch.cuda.is_available(): gpu_rand = torch.rand(2, 2, device='cuda') print(gpu_rand) else: print('Sorry, CPU only.')

기본적으로 새로운 텐서는 CPU에 생성됩니다. 따라서, 만약 GPU에 텐서를 생성하고 싶다면 device argument(optional)을 지정해주어야 합니다.
사용할 수 있는 GPU의 갯수는 torch.cuda.device_count()를 통해 쿼리할 수 있습니다. 만약 하나 이상의 GPU를 사용할 수 있다면, 해당 GPU는 인덱스를 이용하여, device='cuda:0', device='cuda:1'과 같이 지정할 수 있습니다.
일반적으로 모든 곳에서 문자열 상수로 디바이스를 지정하는 것은 권장하지 않습니다. 문자열 대신 텐서에 전달할 수 있는 device handle을 생성하여 디바이스를 지정해야 합니다.
if torch.cuda.is_available(): my_device = torch.device('cuda') else: my_device = torch.device('cpu') print('Device: {}'.format(my_device)) x = torch.rand(2, 2, device=my_device) print(x)

만약 이미 어떤 디바이스에 존재하는 텐서가 있다면, to() 메소드를 사용하여 다른 디바이스로 이동시킬 수 있습니다. 다음 코드는 CPU에 생성된 텐서를 GPU 디바이스로 이동시킵니다.
y = torch.rand(2, 2) y = y.to(my_device)
둘 이상의 텐서가 포함된 연산을 수행하려면 모든 텐서가 동일한 디바이스에 위치해야 합니다. 다음 코드는 GPU를 사용할 수 있더라도, 연산되는 두 텐서가 서로 다른 디바이스에 위치하기 때문에 예외가 발생합니다.
x = torch.rand(2, 2) y = torch.rand(2, 2, device='gpu') z = x + y # exception will be thrown

Manipulating Tensor Shapes
종종 텐서의 shape를 변경할 필요가 있습니다. 여기서는 몇 가지 일반적인 케이스와 이를 어떻게 다루는지에 대해 살펴보겠습니다.
Changing the Number of Dimensions
차원의 수를 변경해야 하는 한 가지 경우는 a single instance of input을 모델에 전달하는 경우입니다. 파이토치 모델은 일반적으로 input의 배치를 기대합니다.
예를 들어, 3 x 226 x 226 이미지에 대해 동작하는 모델이 있다고 가정해봅시다. 이미지를 로드하고 transform하게 되면 (3, 226, 266) shape의 텐서를 얻게 됩니다. 하지만 모델은 (N, 3, 226, 266) shape의 입력을 기대하며, 여기서 N은 배치의 수 입니다. 여기서 하나의 배치를 만드려면 다음과 같이 해주면 됩니다.
a = torch.rand(3, 226, 226) b = a.unsqueeze(0) print(a.shape) print(b.shape)

unsqueeze() 메소드는 하나의 차원을 확장하여 추가합니다. unsqueeze(0)은 새로운 차원을 0번째 차원에 추가합니다.
(unsqueeze와 squeeze는 차원을 추가하거나 제거하는 것이 요소의 갯수를 변경하지 않는다는 사실을 활용합니다)
이번에는 모델의 출력이 각 입력에 대해 20-element vector라고 가정해봅시다. 그렇다면 output의 shape는 (N, 20) 이라고 기대하며, N은 input batch에서 instance의 갯수입니다. 이는 하나의 싱글 배치에 대해서는 (1, 20) shape의 output을 얻는다는 것을 의미합니다.
만약 단지 a 20-element vector를 기대하여, non-batched computation을 수행하려면 어떻게 될까요?
a = torch.rand(1, 20) print(a.shape) print(a) b = a.squeeze(0) print(b.shape) print(b) c = torch.rand(2, 2) print(c.shape) d = c.squeeze(0) print(d.shape)

squeeze() 메소드를 통해 2차원 텐서가 1차원이 되는 것을 볼 수 있습니다. 이때, 텐서 a를 출력해보면 여분의 대괄호 []가 있음을 볼 수 있습니다. 즉, extent 1의 차원만 squeeze할 수 있습니다.
아래에서 텐서 c에 대해 squeeze하는 연산을 적용해도 차원이 압축되지 않는다는 것을 볼 수 있습니다. 이처럼 squeeze()와 unsqueeze()는 extent 1 차원에서만 동작할 수 있으며, 1이 아니라면 텐서의 요소 수가 변경되기 때문입니다.
unsqueeze()를 사용하면 브로드캐스트를 쉽게 적용할 수 있습니다.
a = torch.ones(4, 3, 2) c = a * torch.rand( 3, 1) # 3rd dim = 1, 2nd dim identical to a print(c)
위의 코드에서의 브로드캐스트는 0, 2 차원에 대한 연산을 브로드캐스팅하여 임의의 3x1 텐서가 a의 모든 3-element column에 element-wise 곱셈이 적용됩니다.
만약 (3, 1) 텐서 대신 3-element vector가 주어지면 어떻게 될까요?
최종 차원이 브로드캐스트 규칙을 만족하지 않기 때문에 브로드캐스팅을 할 수 없습니다. 이때, unsqueeze()를 사용하면 브로드캐스트가 가능하도록 할 수 있습니다.
a = torch.ones(4, 3, 2) b = torch.rand( 3) # trying to multiply a * b will give a runtime error c = b.unsqueeze(1) # change to a 2-dimensional tensor, adding new dim at the end print(c.shape) print(a * c) # broadcasting works again!

3-element vector를 (3,1) 행렬로 변경시키고 있습니다.
squeeze()와 unsqueeze() 메소드 또한 in-place 버전, squeeze_(), unsqueeze_()가 있습니다.
batch_me = torch.rand(3, 226, 226) print(batch_me.shape) batch_me.unsqueeze_(0) print(batch_me.shape)

네트워크 모델의 convolution layer와 linear layer 사이의 연산인 경우, 요소의 갯수와 그 값들을 유지하면서 텐서의 shape를 변경해야 합니다. 이러한 케이스는 이미지 분류 모델에서는 일반적입니다. convolution kernel은 features x width x height shape로 출력 텐서를 생성하지만, linear layer는 1차원 input을 기대합니다. 이때 reshape() 메소드를 사용하면 입력 텐서와 동일한 수의 요소를 갖는 차원으로 변경할 수 있습니다.
output3d = torch.rand(6, 20, 20) print(output3d.shape) input1d = output3d.reshape(6 * 20 * 20) print(input1d.shape) # can also call it as a method on the torch module: print(torch.reshape(output3d, (6 * 20 * 20,)).shape)

reshape가 성공적으로 수행된다면, reshape()는 변경할 텐서의 view를 반환합니다. 즉, 동일한 메모리 영역을 사용하는 별도의 텐서 객체를 반환합니다. 따라서, 원본 텐서에 대한 모든 변경은 clone()하지 않는 이상, 반환된 텐서의 view에 반영됩니다.
Numpy Bridge
파이토치의 텐서와 넘파이의 배열을 서로 메모리를 공유할 수 있으며, 한 쪽에 데이터를 수정하면 다른 쪽에도 반영됩니다.
아래 포스팅에서도 다룬 내용이므로 이 포스팅에서 예제는 생략하도록 하겠습니다. 필요하시다면 아래 포스팅을 참조바랍니다.
[pytorch] Tutorial - Tensors
References Official PyTorch Tutorials (link) PyTorch Documentations (link) Tensor Vies (link) 텐서는 배열이나 행렬과 매우 유사한 데이터 구조체입니다. 파이토치에서 텐서는 모델의 input/output 그리고, 모델의 파라미
junstar92.tistory.com
'ML & DL > pytorch' 카테고리의 다른 글
| [pytorch] 커스텀 연산 with autograd (0) | 2022.12.26 |
|---|---|
| [pytorch] autograd (0) | 2022.12.05 |
| [pytorch] Tutorial - Optimizing Model Parameters (0) | 2022.11.30 |
| [pytorch] Tutorial - Automatic Differentiation (autograd) (0) | 2022.11.29 |
| [pytorch] Tutorial - Build the Neural Network (0) | 2022.11.29 |




댓글