References
- https://docs.opencv.org/
- OpenCV 4로 배우는 컴퓨터 비전과 머신러닝
- https://leimao.github.io/blog/Save-Load-Inference-From-TF2-Frozen-Graph/
Contents
- OpenCV의 DNN 모듈
- tensorflow로 학습한 모델을 OpenCV에서 사용하기
dnn 모듈
OpenCV 3.1 버전부터는 딥러닝을 활용할 수 있는 DNN(deep neural network) 모듈을 제공합니다.
dnn 모듈은 이미 만들어진 네트워크에서 추론을 위한 용도로 설계되어 있습니다. 즉, 학습은 다른 프레임워크(tensorflow, pytorch 등)에서 진행하고, 학습된 모델을 불러와서 실행할 때에는 dnn 모듈을 사용하는 방식입니다. 기존의 네트워크에 레이어를 추가하거나 수정하는 기능도 제공하지만, 포스팅에서 다루지는 않을 예정입니다.
OpenCV dnn 모듈은 caffe, tensorflow, torch 등의 프레임워크에서 학습된 모델과 ONNX(Open Neural Network Exchange) 파일 형식으로 저장된 모델을 불러와 실행할 수 있습니다.
dnn 모듈은 이미 널리 사용되고 있는 딥러닝 네트워크를 지원하고, 새롭게 개발되는 네트워크도 지속적으로 추가 지원하고 있습니다. 영상 인식과 관련된 AlexNet, GoogLeNet, VGG, ResNet, MobileNet 등의 네트워크가 OpenCV에서 동작됩니다. 객체 검출과 관련해서는 VGG-SSD, MobileNet-SSD, Faster-RCNN, R-FCN, Mask-RCNN, EAST, YOLOv2, tiny YOLO, YOLOv3 등의 모델을 사용할 수 있습니다. 이외에도 사람의 포즈를 인식하는 OpenPose, 흑백 영상에 자동으로 색상을 입히는 Colorization, 사람 얼굴 인식을 위한 OpenFace 등의 모델도 사용할 수 있습니다.
dnn 모듈에서 딥러닝 네트워크는 cv::dnn::Net 클래스를 이용하여 표현합니다. Net 클래스는 다양한 레이어로 구성된 네트워크 구조를 표현하고, 네트워크에서 특정 입력에 대한 forward propagation을 지원합니다.
기본적인 사용법
Net 클래스 객체를 생성하여 네트워크를 구성하고, 생성된 네트워크에서 특정 입력에 대한 출력을 얻기 위해 어떻게 해야하는지 살펴보도록 하겠습니다.
Net 클래스 객체는 보통 사용자가 직접 생성하지 않고, readNet() 등의 함수를 사용합니다. readNet() 함수는 미리 학습된 딥러닝 모델과 네트워크 구성 파일을 이용하여 Net 객체를 생성합니다.
Net cv::dnn::readNet(const String& model, const String& config="", const String& framework="");
이 함수는 훈련된 네트워크의 가중치가 저장된 model 파일과 네트워크 구조를 표현하는 config 파일을 이용하여 Net 객체를 생성하는데, 만약 model 파일에 네트워크 훈련 가중치와 네트워크 구조가 함께 저장되어 있다면 config를 생략할 수 있습니다. framework에는 모델 파일 생성 시 사용된 딥러닝 프레임워크 이름을 지정합니다. 만약 model 또는 config 파일 이름 확장자를 통해 프레임워크 구분이 가능하다면 framework 또한 생략할 수 있습니다. 지정할 수 있는 파라미터는 아래와 같습니다.

readNet() 함수의 구현은 다음과 같습니다.
Net readNet(const String& _model, const String& _config, const String& _framework) { String framework = toLowerCase(_framework); String model = _model; String config = _config; const std::string modelExt = model.substr(model.rfind('.') + 1); const std::string configExt = config.substr(config.rfind('.') + 1); if (framework == "caffe" || modelExt == "caffemodel" || configExt == "caffemodel" || modelExt == "prototxt" || configExt == "prototxt") { if (modelExt == "prototxt" || configExt == "caffemodel") std::swap(model, config); return readNetFromCaffe(config, model); } if (framework == "tensorflow" || modelExt == "pb" || configExt == "pb" || modelExt == "pbtxt" || configExt == "pbtxt") { if (modelExt == "pbtxt" || configExt == "pb") std::swap(model, config); return readNetFromTensorflow(model, config); } if (framework == "torch" || modelExt == "t7" || modelExt == "net" || configExt == "t7" || configExt == "net") { return readNetFromTorch(model.empty() ? config : model); } if (framework == "darknet" || modelExt == "weights" || configExt == "weights" || modelExt == "cfg" || configExt == "cfg") { if (modelExt == "cfg" || configExt == "weights") std::swap(model, config); return readNetFromDarknet(config, model); } if (framework == "dldt" || modelExt == "bin" || configExt == "bin" || modelExt == "xml" || configExt == "xml") { if (modelExt == "xml" || configExt == "bin") std::swap(model, config); return readNetFromModelOptimizer(config, model); } if (framework == "onnx" || modelExt == "onnx") { return readNetFromONNX(model); } CV_Error(Error::StsError, "Cannot determine an origin framework of files: " + model + (config.empty() ? "" : ", " + config)); }
내부 구현에서 전달된 framework 문자열, 또는 model과 config 파일 이름 확장자를 분석하여 해당 프레임워크에 맞는 readNetFromXXX() 형태의 함수를 다시 호출합니다. readNetFromXXX() 형태의 함수를 사용자가 직접 호출하여 사용할 수도 있지만, readNet()을 사용하는 것이 좋습니다.
readNet() 함수를 이용하여 Net 객체를 생성한 후에는 Net::empty() 함수를 사용하여 Net 객체가 정상적으로 생성되었는지 확인하는 것이 좋습니다.
일단 Net 객체가 정상적으로 생성되었다면, 생성된 네트워크에 새로운 데이터를 입력하여 그 결과를 확인할 수 있습니다. 이때 Net 객체로 표현되는 네트워크 입력은 Mat 타입의 2차원 영상을 그대로 입력하는 것이 아닌 블롭(blob) 형식으로 변경해야 합니다. 블롭은 영상 등의 데이터를 포함할 수 있는 다차원 데이터 표현 방식이며, OpenCV에서 블롭은 Mat 타입의 4차원 행렬로 표현됩니다. 이때 각 차원은 NCHW 정보를 표현합니다(N: 데이터 개수, C: 채널 수, H,W: 영상의 세로와 가로 크기). OpenCV에서는 blobFromImage() 함수를 이용하여 Mat 영상으로부터 블롭을 생성합니다.
이 함수는 입력 image로부터 4차원 블롭 객체를 생성하여 반환합니다. 이때, 딥러닝 네트워크마다 고유의 입력 블롭 크기와 행렬 원소 값 구성 방법을 가지고 있으므로, 이러한 구성에 맞게 블롭 크기 또는 원소 값을 제대로 설정해주어야 합니다. 예를 들어, 사용할 네트워크에서 224x244 크기의 입력을 사용한다면 blobFromImage() 함수의 size에 cv::Size(224, 244)를 지정해주어야 합니다. 만약 입력 픽셀 값 범위를 0에서 1 사이의 실수로 정규화하여 훈련된 딥러닝 모델을 사용한다면 scalefactor에 1/255.f를 지정해야 합니다.
mean에는 입력 영상의 모든 픽셀에서 추가로 뺄 값을 지정하며, 없다면 cv::Scalar()를 지정합니다. 또한, 프레임워크에서 영상의 컬러 영상 채널 순서를 RGB로 사용했다면, swapRB에 true를 지정해야 합니다.
blobFromImage() 함수로 생성한 블롭 객체는 Net::setInput() 함수를 이용하여 네트워크 입력으로 설정합니다.
이 함수에는 blobFromImage() 함수에 있는 scalefactor와 mean 파라미터가 있어서, 추가적인 픽셀 값을 조정할 수 있습니다. 따라서, 최종 네트워크에 입력되는 블롭은 다음과 같은 형태로 설정됩니다.
네트워크 입력을 설정한 후에는 네트워크를 순방향으로 실행(추론, inference)하여 결과를 예측할 수 있는데, 이때 Net::forward() 함수를 사용합니다.
여러 종류의 forward() 함수가 있지만, 대표적인 하나를 살펴보겠습니다.
Mat cv::dnn:Net::forward(const String& outputName = String());위 함수는 Net::setInput() 함수로 설정한 입력 블롭을 이용하여 네트워크를 실행하고, outputName에 해당하는 레이어에서의 결과를 Mat 객체로 반환합니다. 만약 outputName을 지정하지 않으면 전체 네트쿼으 실행 결과를 반환합니다. Net::forward() 함수가 반환하는 Mat 객체의 형태는 사용하는 네트워크 구조에 따라 다르며, 따라서 반환하는 Mat 행렬을 제대로 이용하려면 네트워크 구조와 동작 방식에 대해 충분히 이해하고 있어야 합니다.
필기체 숫자 인식
위 포스트에서 OpenCV에서 제공되는 digits.png 파일을 이용하여 5000개의 필기체 숫자 이미지를 가지고 k-NN 알고리즘을 통해 분류를 해봤습니다. 이번에는 tensorflow와 OpenCV의 dnn 모듈을 이용하여 필기체 숫자 이미지 분류를 구현해보도록 하겠습니다.
저의 경우에는 구글의 colab을 이용하였습니다. 사용된 tensorflow 버전은 2.8.0 입니다.
import tensorflow as tf (x_train_orig, y_train_orig), (x_test_orig, y_test_orig) = tf.keras.datasets.mnist.load_data() x_train, x_test = x_train_orig / 255., x_test_orig / 255. x_train = x_train[..., tf.newaxis] y_train = tf.one_hot(y_train_orig, 10).numpy() x_test = x_test[..., tf.newaxis] y_test = tf.one_hot(y_test_orig, 10).numpy() print(f"x_train's shape : {x_train.shape}") print(f"y_train's shape : {y_train.shape}") print(f"x_test's shape : {x_test.shape}") print(f"y_test's shape : {y_test.shape}") model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), padding="same", activation="relu", input_shape=(28, 28, 1)), tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding="same"), tf.keras.layers.Conv2D(filters=16, kernel_size=(2, 2), padding="same", activation="relu"), tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding="same"), tf.keras.layers.Flatten(), tf.keras.layers.Dense(10, activation="softmax") ]) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc']) learning_rate = 0.001 training_epochs = 20 batch_size = 100 model.summary() model_hist = model.fit(x_train, y_train, batch_size=batch_size, epochs=training_epochs, validation_data=(x_test, y_test)) model.save('saved_model') from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2 full_model = tf.function(lambda x: model(x)) full_model = full_model.get_concrete_function(tf.TensorSpec(model.inputs[0].shape, model.inputs[0].dtype)) frozen_func = convert_variables_to_constants_v2(full_model) frozen_func.graph.as_graph_def() tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir="./frozen_models", name="frozen_graph.pb", as_text=False)
위 파이썬 코드는 tensorflow를 사용하여 MNIST 데이터를 이용해 학습을 수행합니다. 학습이 완료된 후에는 모델을 저장합니다. OpenCV에서 사용하기 위한 파일은 pb 확장자로 끝나는 'saved_model.pb' 입니다. 하지만, 이 파일을 그대로 사용하면 OpenCV에서는 아래와 같은 에러가 발생합니다.
String field 'opencv_tensorflow.FunctionDef.Node.ret' contains invalid UTF-8 data when parsing a protocol buffer. Use the 'bytes' type if you intend to send raw bytes.
정확한 원인은 파악하지는 못했으나, 바이너리가 아닌 포맷으로 된 pb 파일이 필요한데 tensorflow의 케라스 모델의 멤버 함수 save를 호출하여 저장된 saved_model.pb 파일은 바이너리 포맷으로 저장되는 것으로 보입니다. 그리고 가중치 또한 다른 곳에 저장되어 있는 것 같습니다. 아래는 모델을 save하여 생성된 파일들인데, 아마도 variables 폴더 내의 파일에 가중치와 같은 정보들이 저장되어 있는 것으로 보입니다.
따라서, 모델을 프리징(freezing)하는 과정이 필요하다고 합니다. 이는 그래프 정의와 가중치 등의 정보들이 저장된 변수들의 값을 모두 받아와서 하나의 파일로 저장하는 역할을 합니다. 위의 파이썬 코드에서 line 37부터가 이에 대한 코드에 해당합니다. 이를 통해 생성된 frozen_graph.pb 파일을 OpenCV에서 사용합니다.
필기체 숫자 이미지를 인식하기 위한 OpenCV의 dnn 모듈을 사용한 코드는 다음과 같습니다.
#include <iostream> #include "opencv2/opencv.hpp" using namespace cv; void on_mouse(int event, int x, int y, int flags, void* userdata) { static Point ptPrev(-1, -1); Mat img = *(Mat*)userdata; if (event == EVENT_LBUTTONDOWN) { ptPrev = Point(x, y); } else if (event == EVENT_LBUTTONUP) { ptPrev = Point(-1, -1); } else if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON)) { line(img, ptPrev, Point(x, y), Scalar::all(255), 40, LINE_AA, 0); ptPrev = Point(x, y); imshow("img", img); } } int main(int argc, char* argv[]) { dnn::Net net = dnn::readNet("frozen_graph.pb"); if (net.empty()) { std::cout << "Network load failed!\n"; return -1; } Mat img = Mat::zeros(400, 400, CV_8UC1); imshow("img", img); setMouseCallback("img", on_mouse, (void*)&img); while (true) { int c = waitKey(); if (c == 27) { // ESC key break; } else if (c == ' ') { // space key Mat inputBlob = dnn::blobFromImage(img, 1 / 255.f, Size(28, 28)); net.setInput(inputBlob); Mat prob = net.forward(); double maxVal; Point maxLoc; minMaxLoc(prob, NULL, &maxVal, NULL, &maxLoc); int digit = maxLoc.x; std::cout << digit << " (" << maxVal * 100 << "%)\n"; waitKey(); img.setTo(0); imshow("img", img); } } }
tensorflow로 학습시킨 모델 정보가 저장된 frozen_graph.pb 파일을 통해 Net 객체를 생성하고, 마우스로 그린 숫자를 판별합니다.
위 코드를 실행시킨 결과는 다음과 같습니다.
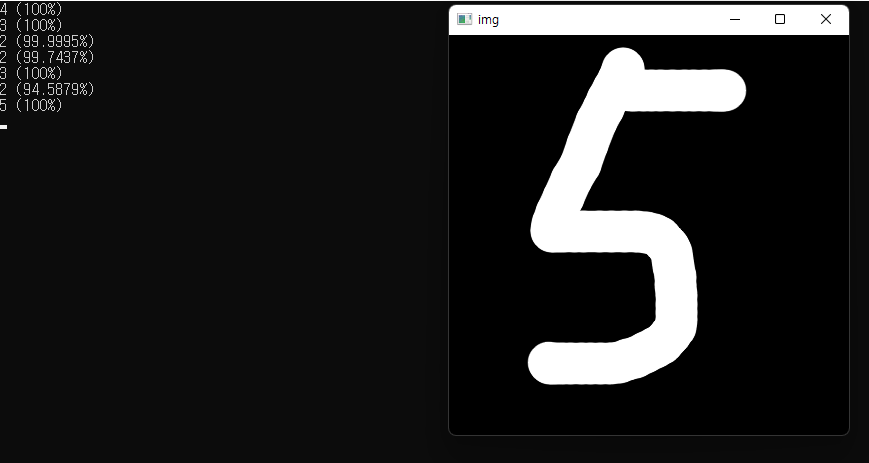
7을 2로 판단하거나, 1을 2로 판단하는 등 잘못 분류하는 경우도 꽤 발생했습니다.
'프로그래밍 > OpenCV' 카테고리의 다른 글
| [OpenCV] 서포트 벡터 머신 (SVM) (0) | 2022.05.11 |
|---|---|
| [OpenCV] 머신러닝과 KNearest 클래스 (0) | 2022.05.10 |
| [OpenCV] 컬러 이미지 처리 (0) | 2022.05.09 |
| [OpenCV] 에지 검출 (0) | 2022.05.08 |
| [OpenCV] 어파인 변환 / 투시 변환 (0) | 2022.05.07 |




댓글