References
- Learning Regular Expressions
Contents
- 전방탐색 (Looking Ahead)
- 후방탐색 (Looking Behind)
- 부정형 전후방탐색 (Nagative Lookaround)
이전 포스팅들에서 사용한 표현식들은 모두 일치하는 텍스트를 가지고 있었지만, 종종 텍스트 자체를 찾기보다는 어디서 텍스트를 찾을지를 표시하는데 표현식을 사용하고 싶을 때도 있습니다. 그러려면 전후방탐색(lookaround)를 사용해야 하는데, 이번 포스팅에서는 이에 관해 살펴보도록 하겠습니다.
전후방탐색
먼저 예제로 시작해보도록 하겠습니다. 아래 예문은 HTML 포맷의 텍스트이며, 웹페이지에서 제목을 추출해야 한다고 가정합니다.
<head>
<title>Ben Forta's Homepage</title>
</head>
HTML 페이지 제목은 HTML 코드에서 <head> 구역 내의 <title>과 </title> 태그 사이에 있습니다. 따라서 다음 정규표현식 패턴으로 제목에 일치시킬 수 있습니다.
'<[tT][iI][tT][lL][eE]>.*<\/[tT][iI][tT][lL][eE]>'

사실 필요한 건 제목의 텍스트뿐이었지만, 실제로는 시작 태그인 <title>과 종료 태그 </title>도 들어 있습니다. 여기서 제목의 텍스트만 얻을 수는 없을까요?
한 방법으로는 이전 포스팅([REGEX] 하위 표현식 (Subexpression))에서 다루었던 하위표현식을 사용할 수 있습니다. 이 방법을 사용해서 패턴을 시작 태그, 텍스트, 종료 태그, 이렇게 세 부분으로 나누어 결과를 얻을 수 있습니다. 이 방식을 사용하면 일치하는 텍스트를 여러 조각으로 나누어 원하는 부분을 쉽게 얻을 수 있습니다.
하지만, 이 방법을 사용하면, 원하지 않는 결과까지 얻게 되고, 이 부분은 수동으로 없애야 한다는 점이 걸립니다. 반환하지 않는 일치를 포함하는 패턴을 구성하는 것, 즉, 정확한 일치 지점을 찾는 데는 사용되지만 실제 일치하는 부분의 일부로는 사용되지 않는 '어떤 것'이 필요합니다. 다시 말해, 전후방탐색(lookaround)가 필요합니다.
전방탐색
전방탐색(lookahead) 패턴은 일치 영역을 발견해도 그 값을 반환하지 않는 패턴을 말합니다. 전방탐색은 실제로는 하위표현식이며, 하위표현식과 같은 형식으로 작성합니다. 전방탐색 패턴의 구문은 '?='로 시작하고 '=' 다음에 일치할 텍스트가 오는 하위표현식입니다.
일부 정규표현식 문서에서는 일치하는 영역을 반환하는 동작을 표현할 때 '소비한다(consume)'라는 용어를 사용합니다. 이런 경우에 전방탐색은 '소비하지 않는다(not consume)'라고 말합니다.
다음 예제를 살펴보겠습니다. 예문에는 URL 목록이 있고, 우리는 각 URL에서 프로토콜의 위치를 추출해야 한다고 가정하겠습니다.
http://www.forta.com/
https://mail.forta.com/
ftp://ftp.forta.com/
'.+(?=:)' 패턴을 사용한 결과는 다음과 같습니다.

여기에 나열한 URL들에서 프로토콜은 콜론(:)을 기준으로 호스트 이름과 분리되어 있습니다. '.+' 패턴은 모든 텍스트와 일치하고, 하위표현식 '(?=:)'는 ':'과 일치합니다. 그런데 결과를 살펴보면 ':'은 일치하지 않는 것으로 나타납니다. '?='는 정규표현식 엔진에서 ':'을 찾되 ':' 앞에 있는 문자를 탐색하라고 지시(':'을 '소비'하지 말고)합니다.
'?='가 어떻게 동작하는지 이해하기 위해서 동일한 예문에서 전방탐색 메타 문자를 제외한 패턴('.+(:)')을 적용해보았습니다.

사용된 패턴의 하위표현식 '(:)'은 정확하게 ':'과 일치했지만, 일치한 텍스트를 소비(consume)한 것을 확인할 수 있습니다.
위의 두 예제에서 처음 패턴은 ':'을 찾고자 '(?=:)'을 사용했고, 두 번째 패턴은 '(:)'을 사용했다는 차이가 있습니다. 두 패턴 모두 프로토콜 다음에 나오는 콜론을 찾지만, 일치한 콜론을 검색 결과에 포함시키는지 아닌지가 다릅니다. 전방탐색을 사용하면 정규표현식은 콜론과 일치하는 지점 앞쪽을 파싱하지만, '.+(:)' 패턴은 콜론까지 포함해 텍스트를 찾습니다. '.+(?=:)' 패턴도 콜론까지 찾긴 하지만, 콜론을 결과에 포함시키지 않습니다.
전방탐색(or 후방탐색) 일치는 실제로 결과를 반환하지만, 반환된 문자의 길이가 항상 0입니다. 따라서 전방탐색을 흔히 'zero-width'라고 부르기도 합니다.
모든 하위표현식 앞쪽에 '?='를 붙이기만 하면 전방탐색 표현으로 바꿀 수 있습니다. 하나의 검색 패턴 속에서 여러 개의 전방탐색 표현식을 사용할 수 있고, 또한 그 표현식은 패턴 안에서 어느 위치에서든 사용할 수 있습니다.
후방탐색
앞서 본 것처럼, '?='는 앞으로 탐색합니다. 일치하는 텍스트 다음에 무엇이 오는지 찾고, 발견한 텍스트 자체는 소비하지 않습니다. 따라서 '?='는 전방탐색 연산자(lookahead operator)라고 부릅니다. 많은 정규표현식 구현에서는 전방탐색과 더불어 후방탐색(lookbehind) 기능도 지원합니다. 후방탐색 연산자는 '?<=' 입니다.
'?<='의 사용법은 '?='와 같습니다. 즉, 하위표현식 안에서 사용하고, 일치할 텍스트 앞에 옵니다. 다음 예제를 통해 살펴보도록 하겠습니다. 아래 예문은 데이터베이스의 제품 목록이며, 여기서 가격만 일치시켜야 한다고 가정하겠습니다.
ABC01: $23.45
HGG42: $5.31
CFMX1: $899.00
XTC99: $69.96
Total items found: 4
'\$[0-9.]+' 패턴을 사용한 결과는 다음과 같습니다.
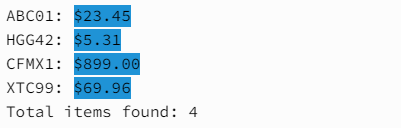
사용한 패턴에서 '\$'는 달러 기호($)와 일치하고, '[0-9.]+'는 가격과 일치합니다.
잘 동작합니다. 하지만 '$' 기호가 필요없다면 어떻게 해야 할까요?
단순히 패턴에서 '\$'를 제외하면 된다고 생각할 수도 있는데, 이는 잘못된 결과를 반환합니다.

이에 대한 해결책이 바로 후방탐색입니다.
다음의 패턴을 사용하면 원하는 가격만 일치시킬 수 있습니다.
'(?<=\$)[0-9.]+'

'(?<=\$)'는 '$' 기호와 일치하지만 소비하지는 않고, 단지 앞에 $ 기호가 없는 가격만 반환합니다.
예제에서 사용한 첫 번째 패턴과 마지막 패턴을 비교해봅시다. '\$[0-9.]+'는 $ 기호와 이어 나오는 금액이 함께 일치합니다. '(?<=\$)[0-9.]+' 역시 $ 기호와 금액이 함께 일치합니다. 단지, 검색을 수행하는 동안 어디에 위치하는가가 다른 게 아니라 결과 속에 무엇을 포함하는지가 다릅니다. 첫 번째 패턴은 $ 기호를 찾아서 결과에 포함시키지만, 마지막 패턴은 $ 기호를 찾아 정확하게 금액을 얻고, 결과에는 $ 기호를 포함시키지 않습니다.
전방탐색 패턴은 마침표(.)와 더하기(+)를 포함하여 텍스트의 길이를 다양하게 일치시킬 수 있으며, 매우 동적입니다. 반면 후방탐색 패턴은 보통 일치시킬 텍스트의 길이를 고정해야 합니다. 거의 모든 정규표현식 구현에는 이러한 제약이 있습니다.
전방탐색과 후방탐색 함께 사용하기
포스팅 처음에 HTML 제목을 일치시키는 문제에서는 다음과 같이 전방탐색과 후방탐색 연산자를 함께 사용할 수 있습니다.
'(?<=<[tT][iI][tT][lL][eE]>).*(?=<\/[tT][iI][tT][lL][eE]>)'

처음에 해결하지 못했던 문제를 전방탐색과 후방탐색을 사용하여, 제목 태그를 제외하고 필요한 제목의 텍스트만을 일치시킬 수 있습니다. 패턴에서 '(?<=<[tT][iI][tT][lL][eE]>)'는 후방탐색 작업으로 <title>과 일치하며, 소비하지는 않습니다. '(?=<\/[tT][iI][tT][lL][eE]>)'도 같은 방식으로 </title>과 일치하며, 역시 소비하지 않습니다.
여기서 사용한 패턴에서 혼란을 방지하고자 첫 번째로 찾을 문자인 <를 이스케이프하는 편이 바람직할 수 있습니다. 즉, '(?<=<' 대신 '(?<=\<'를 사용해도 됩니다.
부정형 전후방탐색
지금까지 살펴본 전방탐색과 후방탐색은 반환할 텍스트의 위치, 즉 찾고하 하는 부분의 앞뒤를 특별히 지정하고 싶을 때 주로 사용합니다. 이런 방법을 긍정형 전방탐색(positive lookahead)과 긍정형 후방탐색(positive lookbehind)이라고 합니다. positive라는 말을 쓰는 이유는 실제로 일치하는 텍스트를 찾기 때문입니다.
전후방탐색 중에서 부정형(nagative) 전후방탐색은 비교적 덜 쓰이는 방법입니다. 부정형 전방탐색(nagative lookahead)은 앞쪽에서 지정한 패턴과 일치하지 않는 텍스트를 찾고, 부정형 후방탐색(nagative lookbehind)도 이와 비슷하게, 뒤쪽에서 지정한 패턴과 일치하지 않는 텍스트를 찾습니다.
혹시, 제외를 의미하는 '^'를 사용한다고 기대했다면 틀렸습니다. 문법이 약간 다른데, 전후방탐색 명령에서 부정형을 나타낼 때는 등호(=) 대신 느낌표(!)를 사용합니다. 아래 표는 모든 전후방탐색의 문법을 보여줍니다.

전방탐색을 지원하는 정규표현식 구현에서는 대부분 positive와 nagative 전방탐색을 모두 지원합니다. 후방탐색도 마찬가지 입니다.
다음 예제를 통해 긍정형 후방탐색과 부정형 후방탐색 간에 어떠한 차이점이 있는지 살펴보겠습니다. 아래 예문은 가격과 수량을 나타내는 숫자들이 있으며, 우선 간단하게 가격만 얻도록 합니다.
I paid $30 for 100 apples,
50 oranges, and 60 pears.
I saved $5 on this order.
'(?<=\$)\d+' 패턴을 사용하면 $ 기호 뒤의 가격만 일치시킬 수 있습니다.

이 패턴은 앞서 본 예제에서의 패턴과 매우 비슷합니다. '\d+'는 하나 이상 연속된 숫자와 일치하고, '(?<=\$)'는 후방탐색이며 '\$'로 이스케이프한 $ 기호를 찾지만 소비하지는 않습니다. 따라서 수량을 제외한 가격 두 개가 일치했습니다.
이번에는 아래의 패턴을 사용해 가격이 아니라 수량을 찾아보겠습니다.
'\b(?<!\$)\d+\b'

첫 번째 패턴과 같이, '\d+'는 숫자와 일치하지만 이번에는 가격이 아닌 수량만 일치했습니다. '(?<!\$)'는 부정형 후방탐색으로, 앞에 $ 기호가 없는 숫자와만 일치합니다.
두 번째 사용한 패턴에서 '\b'를 사용하여 왜 단어 경계를 지정했는지 궁금할 수 있는데, 동일한 예제에서 경계를 빼면 다음과 같은 결과를 얻습니다.

이처럼 단어 경계가 빠지면 $30에 있는 0과도 일치합니다. 이는 숫자 0 앞에 $ 기호가 없기 때문입니다. 따라서 여기서는 전체 패턴을 단어 경계로 감싸 이러한 문제를 해결했습니다.
'프로그래밍 > 정규표현식' 카테고리의 다른 글
| [REGEX] 조건 달기 (0) | 2022.04.10 |
|---|---|
| [REGEX] 역참조와 치환 작업 (0) | 2022.04.09 |
| [REGEX] 하위 표현식 (Subexpression) (0) | 2022.04.08 |
| [REGEX] 위치 찾기 (Position Matching) (0) | 2022.04.07 |
| [REGEX] 반복 찾기 (0) | 2022.04.06 |




댓글