References
- Learning Regular Expressions
Contents
- 역참조 (Backreferences)
- 치환 작업 (Replace Operations)
- C++, Python 예제
[REGEX] 하위 표현식 (Subexpression)
이전 포스팅에서 하위표현식을 사용해 문자들을 집합으로 묶는 방법을 살펴봤습니다. 이렇게 묶는 이유는 주로 반복되는 패턴 검색 작업을 통제하기 위함입니다. 이번 포스팅에서는 하위표현식에서 중요한 사용법인 역참조(backreferences)에 대해서 살펴보겠습니다.
역참조 이해하기
역참조가 언제 필요한지 이해하기 위해서 예제를 통해 살펴보겠습니다.
HTML 개발자는 웹페이지에서 헤더 텍스트를 정의하고 만들고자, 헤더 태그를 사용합니다. 헤더 태그는 <h1>부터 <h6>까지 있으며, 이에 대응하는 종료 태그를 함께 사용합니다. 단계에 상관없이 헤더를 모두 찾아야 한다고 생각하면서, 다음 예문을 살펴보겠습니다.
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
</body>
이 예문에서 '<[hH]1>.*<\/[hH]1>'로 검색하면 다음의 결과를 확인할 수 있습니다.

사용한 패턴은 첫 번째 헤더와 일치하고, HTML은 대소문자를 구분하지 않으므로 <H1>과도 일치할 것 입니다. 하지만 다른 단계의 헤더를 모두 사용했을지도 모르는데, 여기서 사용된 헤더를 모두 찾으려면 어떤 패턴을 사용해야 할까요?
직접 1을 패턴에 사용하는 대신 다음과 같이 간단히 범위를 적용하는 방법도 있습니다.
'<[hH][1-6]>.*?<\/[hH][1-6]>'

'<[hH][1-6]>'은 모든 헤더의 시작 태그(예제에서는 <h1>와 <h2>)와 일치하고, '<\/[hH][1-6]>'은 모든 헤더의 종료 태그와 일치하여 제대로 동작하는 것처럼 보입니다.
여기서 '.*' (greedy quantifier)이 아닌 '.*?' (lazy quantifier)을 사용했음에 유의합니다. 여기서 만약 '.*'를 사용하여 '<[hH][1-6]>.*<\/[hH][1-6]>' 패턴은 두 번째 줄에 있는 <h1>에서 시작해 여섯 번째 줄에 있는 </h2> 사이의 모든 글자와 일치할 수도 있습니다. 이러한 문제는 '.*?'를 사용해서 해결합니다.
여기서 '일치한다'가 아닌 '일치할 수도 있다'라고 한 이유는 지금과 같은 특정한 예제에서는 대게 greedy quantifier로도 원하는 결과를 얻을 수 있기 때문입니다. 메타 문자 마침표는 줄바꿈 문자와는 일치하지 않는데, 이 예제에는 각 헤더마다 줄이 따로 있습니다. 하지만 lazy quantifier를 사용하는 것이 더 나쁠 것이 없는 데다가 더 안전하기도 합니다.
이 패턴으로 성공적으로 일치하는 헤더들을 모두 찾을 수 있을까요?
정답은 '아니다' 입니다. 같은 패턴을 다음 예문에 적용해보겠습니다.
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
결과는 다음과 같습니다.

여기서 헤더 태그가 <h2>로 시작해 </h3>으로 끝나 올바른 형식이 아니지만, 패턴과 일치하고 있습니다.
문제는 두 번째 태그(종료 태그)가 일치할 때 첫 번째 태그(시작 태그)가 어떤 텍스트인지 알 수 있는 정보가 없다는 점입니다. 이러한 경우에 역참조가 매우 유용합니다.
역참조로 찾기
헤더 문제는 잠시 후에 살펴보고, 조금 더 간단하지만 역참조를 사용하지 않고는 절대로 해결할 수 없는 예제를 먼저 살펴보겠습니다.
한 문장이 있고, 이 문장 안에 반복해 나오는 문자, 바로 실수로 같은 단어를 두 번 입력한 오자를 모두 찾고 싶다고 가정해봅시다. 두 단어가 일치하는지 알려면 먼저 나온 단어가 무엇인지 반드시 알고 있어야 합니다. 역참조는 정규표현식 패턴으로, 앞서 일치한 부분을 다시 가리킵니다(이 경우에는 먼저 일치한 단어를 말합니다).
다음 예문에서는 반복해 나오는 단어가 세 가지 존재하는데, 이 세 단어를 모두 찾도록 해보겠습니다.
This is a block of of text,
several words here are are
repeated, and and they
should not be.
위 예문에서 '[ ]+(\w+)[ ]+\1' 패턴을 사용한 결과는 다음과 같습니다.

우선 패턴이 제대로 동작하는 것 같습니다. 하지만 어떻게 이렇게 동작하는 것 일까요?
'[ ]+'는 공백이 하나 이상 연속되는 경우와 일치하고, '\w+'는 영숫자 문자가 하나 이상 연속되는 경우와 일치하며, '[ ]+'는 그 뒤에 공백이 있을 때 일치합니다. 여기서 '\w+'를 괄호로 감싸 하위표현식으로 만들었음에 주목합니다. 반복하기 위해서 하위표현식을 사용한 것이 아니며, 반복해서 일치하는 부분도 없습니다. 여기서는 나중에 일치한 부분을 사용할 수 있도록 표시하여 구별하고자 하위표현식을 사용했습니다. 이 패턴의 마지막 부분인 '\1'은 앞서 일치한 하위표현식을 참조한다는 것을 의미하고, 따라서 '(\w+)'와 일치하는 문자는 '\1'과도 일치합니다.
역참조(backreferences)라는 용어는 이런 항목들이 앞에 나온 표현을 역으로 가리킨다는 것을 나타냅니다.
'\1'은 정확히 무엇을 뜻할까요? '\1'은 패턴에서 처음 사용한 하위표현식과 일치한다는 뜻입니다. '\2'는 두 번째, 그리고, '\3'은 세 번째 사용한 하위표현식과 일치하는 식입니다. 따라서 '[ ]+(\w+)[ ]+\1'은 앞서 나온 예제서 보듯이 어떤 단어가 일치하고, 그 다음에는 같은 단어가 반복해 나와야만 일치합니다.
안타깝게도 역참조 문법은 정규표현식 구현에 따라 크게 다릅니다. 자바스크립트는 역참조를 표현할 때 역슬래시를 사용하는데, 이는 vi 에디터에서도 사용합니다. 펄은 달러 기호($)를 사용하므로 '\1' 대신 '$1'로 표시합니다. 닷넷 정규표현식은 일치한 정보를 포함하도록 이름이 Groups인 속성을 담은 객체를 반환하도록 합니다. 따라서 match.Groups[1]은 C#에서 가장 먼저 일치하는 부분을 참조합니다. PHP는 이런 정보를 $matches라는 이름을 지닌 배열로 반환합니다. 따라서 $matches[1]은 가장 먼저 일치하는 부분을 참조합니다(정규표현식 함수에 전달된 플래그에 따라 다르게 동작할 수도 있음). 자바와 파이썬은 group이라는 이름의 배열이 포함된 결과 객체(match object)를 반환합니다.
- 역참조를 변수와 비슷하게 생각해도 됩니다.
역참조를 어떻게 사용하는지 살펴봤으니, 이제 다시 HTML 헤더 예제를 다시 살펴보겠습니다.
역참조를 사용해서 짝이 맞지 않는 헤더 태그는 무시하고 시작 태그와 일치하는 종료 태그를 일치시키는 패턴을 다음과 같이 만들어 사용할 수 있습니다.
'<[hH]([1-6])>.*?<\/[hH]\1>'
이를 사용한 결과는 다음과 같습니다.

이제 제대로 일치하는 부분을 모두 찾았습니다. 바로 <h1> 한 쌍과 <h2> 두 쌍입니다. '<[hH]([1-6])>' 패턴이 모든 헤더 시작 태그와 일치한다는 점은 이전과 동일하고, 대신 [1-6]을 하위표현식으로 만들었습니다. 이렇게 하면 헤더의 종료 태그 패턴인 '<\/[hH]\1>' 안에서 '\1'로 하위표현식을 참조할 수 있습니다. '([1-6])'은 하위표현식이며, 숫자 1부터 6까지 일치합니다. '\1'은 오직 하위표현식에서 일치한 숫자와 일치하므로 여덟 번째 줄의 잘못된 헤더 태그는 일치하지 않습니다.
역참조는 참조하는 표현식이 하위표현식일 때(그리고 하위표현식으로 괄호로 감싸고 있을 때)만 동작합니다.
일치하는 부분을 참조하는 숫자는 주로 1로 시작하며, 대부분 구현에서 0번째 참조는 표현식 전체를 가리킵니다.
지금까지 살펴봤듯이, 하위표현식은 '\1'은 첫 번째, '\5'는 다섯 번째로 표현하는 식으로 상대적 위치로 참조됩니다. 이것이 일반적인 방식이지만, 이 문법에는 심각한 제약 사항이 있습니다. 바로 하위표현식을 수정하거나 옮겨서 하위표현식 순서가 바뀌면 패턴이 깨질 수 있고, 하위표현식을 추가하거나 삭제하면 문제를 해결하기가 훨씬 더 힘들어진다는 점입니다.
이러한 결점을 해결하고자 몇몇 새로운 정규표현식 구현들은 이름을 붙여 저장하는 기능을 지원하는데, 이 기능은 각 하위표현식에 고유한 이름을 주어 상대적인 위치가 아니라 지정된 이름으로 하위표현식을 참조하도록 합니다. 이 기능은 유용하지만, 지원하는 구현마다 문법이 서로 다르기 때문에 자세하게 다루지는 않을 예정입니다.
참고로 파이썬의 re 모듈에서는 이 기능을 제공하며 '(?P<name>...)' 패턴을 사용하면 <name>으로 참조할 수 있습니다.
자세한 내용은 link의 (?P<name>...) 부분을 참조하시길 바랍니다.
치환 작업
이전 포스팅부터 지금까지 다룬 정규표현식들은 모두 텍스트가 많을 때 원하는 텍스트를 검색하는 용도로 사용하는 것이었습니다. 실제로 대부분의 경우에는 텍스트를 검색하는 패턴인 경우가 많습니다. 하지만 정규표현식으로 검색만 할 수 있는 것은 아닙니다. 정규표현식으로 강력한 치환 작업도 수행할 수 있습니다.
단순한 텍스트를 치환하는 데 정규표현식은 필요 없습니다. 예를 들어 CA라는 요소를 모두 California로 치환하거나, MI를 Michigan으로 치환하는 작업은 단연코 정규표현식을 사용할 정도로 대단한 일이 아닙니다. 물론 그런 간단한 정규표현식 작업이 가능하긴 하지만, 정규표현식을 사용할 가치가 없는 데다가 사실 우리가 사용할 수 있는 일반적인 문자열 처리 기능(에디터에서 제공하는 기능)을 사용하는 것이 더 간단합니다.
정규표현식을 사용해 치환하는 작업은 역참조와 함께 사용했을 때 진가를 발휘합니다.
다음의 예문을 살펴봅시다.
Hello, ben@forta.com is my email address.
여기서 '\w+[\w\.]*@[\w\.]+\.\w+' 패턴을 사용하면 메일 주소를 검색할 수 있습니다.

이 패턴은 텍스트 구역 안에서 이메일 주소를 분별합니다.
하지만, 만약 텍스트에 포함된 이메일 주소에 링크를 걸고 싶다면 어떻게 해야 할까요?
HTML에서는 <a href="mailto:user@address.com">user@address.com</a>를 사용해 클릭할 수 있는 이메일 주소를 만듭니다. 정규표현식의 역참조를 사용하면 매우 간단하게 이와 같은 이메일 주소를 클릭이 가능한 주소 형식으로 바꿀 수 있습니다.
제가 정규표현식 테스트를 위해 사용하는 사이트(link)에서 Substitution 기능을 제공하는데, 사용한 결과는 다음과 같습니다.

이렇듯 치환 작업을 할 때는 정규표현식이 두 개 필요합니다. 하나는 원하는 부분을 일치시키는 패턴이고 다른 하나는 일치한 부분을 치환하는 데 사용할 패턴입니다. 역참조는 서로 다른 패턴에서도 사용할 수 있으므로, 첫 패턴에서 일치한 하위표현식을 두 번째 패턴에서도 사용했습니다. '(\w+[\w\.]*@[\w\.]+\.\w+)'은 앞서 본 예제와 같은 패턴인데, 이번에는 하위표현식으로 만들었습니다. 이렇게 하면 일치한 텍스트를 치환 패턴에 사용할 수 있습니다. '<a href="mailto:$1">$1</a>'에서 일치하는 하위표현식을 두 번 사용했는데, 한 번은 href 속성 값인 mailto:를 정의할 때, 다른 한 번은 클릭할 수 있는 텍스트를 넣을 때 사용했습니다.
앞서 언급했듯이, 정규표현식은 구현에 따라 역참조를 표시하는 방법을 바꿔야합니다. 자바스크립트에서는 역슬래시(\) 대신 '$'를 사용하여 역참조할 수 있습니다.
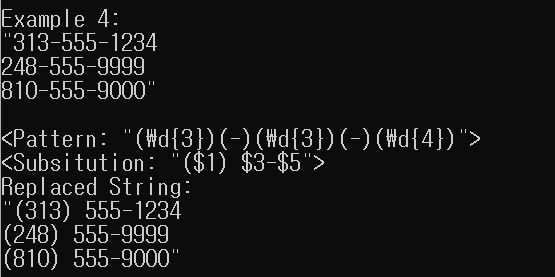
예제를 하나 더 살펴보겠습니다. 이번에는 사용자 정보를 저장하는 데이터베이스에 전화번호가 313-555-1234와 같은 형식으로 저장되어 있으며, 이 전화번호를 (313) 555-1234와 같은 형식으로 변환해야 한다고 가정해봅시다.
313-555-1234
248-555-9999
810-555-9000
아래처럼 정규표현식 패턴을 사용하면 원하는 형식으로 변환할 수 있습니다.

여기서 다시 정규표현식 패턴을 두 개 사용했습니다. 첫 번째 표현식은 '(\d{3})(-)(\d{3})(-)(\d{4})'인데, 이 패턴은 전화번호와 일치합니다. 각 부분을 독립적으로 만들고자 전화번호를 다섯 부분으로 나누었습니다. '(\d{3})'은 첫 하위표현식으로 처음 세 자리 숫자와 일치하고, '(-)'는 두 번째 하위표현식으로 -와 일치하는 식입니다. 결과적으로 전화번호를 다섯 부분으로 나누었고, 각 부분은 하위표현식이라는 것인데, 이 하위표현식들은 지역번호, 하이픈, 처음 세 자리 숫자, 다시 하이픈, 마지막 네 자리 숫자를 가리킵니다. 다섯 부분은 필요에 따라 개별적으로 사용할 수 있으므로, '($1) $3-$5' 패턴은 하위표현식을 필요한 세 개만 사용하고 두 개는 무시하여 간단하게 숫자 형식을 바꿉니다.
대소문자 변환
몇몇 정규표현식 구현에서는 다음의 표에 나열된 메타 문자를 써서 텍스트를 변환하도록 지원합니다.

\l과 \u는 바꾸고 싶은 글자 앞에 두어 각각 그 글자를 소문자와 대문자로 변환합니다. \L과 \U는 \E를 만날 때까지 모든 문자를 각각 소문자와 대문자로 변환합니다.
위에서 살펴본 HTML 예문을 통해서 살펴보겠습니다.
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
위 예문에서 <h1> 태그로 감싸인 텍스트를 대문자로 변환하려면 다음과 같이 패턴을 사용합니다.

제대로 검색은 되나 '$1\U$2\E$3' 패턴으로 제대로 치환은 되지 않는 것 같습니다. 자바스크립트에서는 해당 메타 문자들이 지원되지 않는 것으로 추측됩니다. (파이썬에서도 지원하지 않는 것 같습니다.. !
C++ 예제 코드
#include <iostream>
#include <string>
#include <regex>
void pattern_find(const std::string& str, const std::string& pattern, bool ignore_case = false)
{
std::regex::flag_type flags{};
if (ignore_case)
flags |= std::regex::icase;
std::regex re{ pattern, flags };
std::cout << "\n<Pattern: \"" << pattern << "\">\n";
if (std::regex_search(str, re)) {
std::cout << "- Found\n";
}
else {
std::cout << "- Not Found\n";
}
}
void pattern_find_all(const std::string& str, const std::string& pattern)
{
std::regex re{ pattern };
std::smatch match;
std::string tmp{ str };
bool found{ false };
std::cout << "\n<Pattern: \"" << pattern << "\">\n";
while (std::regex_search(tmp, match, re)) {
std::cout << "- \"" << match.str() << "\" Found\n";
tmp = match.suffix();
found = true;
}
if (!found) {
std::cout << "- Not Found\n";
}
}
void pattern_replace(const std::string& str, const std::string& pattern, const std::string& repl_pattern)
{
std::regex pt{ pattern };
std::cout << "\n<Pattern: \"" << pattern << "\">";
std::cout << "\n<Subsitution: \"" << repl_pattern << "\">\n";
auto result_str = std::regex_replace(str, pt, repl_pattern);
std::cout << "Replaced String: \n\"" << result_str << "\"\n";
}
int main(void)
{
std::string ex1 = R"(This is a block of of text,
several words here are are
repeated, and and they
should not be.)";
std::cout << "Example 1: \n\"" << ex1 << "\"\n";
pattern_find_all(ex1, R"([ ]+(\w+)[ ]+\1)");
std::cout << "\n----------------------------------------------------------\n\n";
std::string ex2 = R"(<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>)";
std::cout << "Example 2: \n\"" << ex2 << "\"\n";
pattern_find_all(ex2, R"(<[hH]([1-6])>.*?<\/[hH]\1>)");
std::cout << "\n----------------------------------------------------------\n\n";
std::string ex3 = R"(Hello, ben@forta.com is my email address.)";
std::cout << "Example 3: \n\"" << ex3 << "\"\n";
pattern_replace(ex3,
R"((\w+[\w\.]*@[\w\.]+\.\w+))",
R"(<a href="mailto:$1">$1</a>)"); // regex_replace에서 역참조는 '\'대신 '$'를 사용 !
std::cout << "\n----------------------------------------------------------\n\n";
std::string ex4 = R"(313-555-1234
248-555-9999
810-555-9000)";
std::cout << "Example 4: \n\"" << ex4 << "\"\n";
pattern_replace(ex4,
R"((\d{3})(-)(\d{3})(-)(\d{4}))",
R"(($1) $3-$5)");
}


Python 예제 코드
import re
def pattern_find(STR, PATTERN, ignore_case = False):
flags = re.I if ignore_case else 0
pattern = re.compile(PATTERN, flags=flags)
print(f"<Pattern: \"{PATTERN}\">")
match = pattern.search(STR)
if match:
print("- Found")
print(f"match: {match}")
else:
print("- Not Found")
def pattern_find_all(STR, PATTERN):
pattern = re.compile(PATTERN)
found = False
print(f"<Pattern: \"{PATTERN}\">")
match = pattern.finditer(STR)
for m in match:
print(f'- "{m[0]}" Found')
found = True
if not found:
print("- Not Found")
return match
def pattern_replace(STR, PATTERN, REPL_PATTERN):
pattern = re.compile(PATTERN)
print(f"<Pattern: {PATTERN}>")
print(f"<Subsitution: {REPL_PATTERN}>")
result_str = pattern.sub(REPL_PATTERN, STR)
print(f"\nReplace String:\n{result_str}")
if __name__ == '__main__':
EX1 = """This is a block of of text,
several words here are are
repeated, and and they
should not be."""
print(f'Example 1: \n"{EX1}"')
pattern_find_all(EX1, R"[ ]+(\w+)[ ]+\1")
print('\n' + '-' * 60 + '\n')
EX2 = """<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>"""
print(f'Example 2: \n"{EX2}"')
pattern_find_all(EX2, R"<[hH]([1-6])>.*?<\/[hH]\1>")
print('\n' + '-' * 60 + '\n')
EX3 = """Hello, ben@forta.com is my email address."""
print(f'Example 3: \n"{EX3}"')
pattern_replace(EX3,
R"(\w+[\w\.]*@[\w\.]+\.\w+)",
R'<a href="mailto:\1">\1</a>')
print('\n' + '-' * 60 + '\n')
EX4 = """313-555-1234
248-555-9999
810-555-9000"""
print(f'Example 4: \n"{EX4}"')
pattern_replace(EX4,
R"(?P<first>\d{3})(-)(?P<second>\d{3})(-)(?P<third>\d{4})",
R"(\1) \3-\5")

포스팅 내용 중 파이썬에서는 이름을 지정하여 역참조가 가능하다고 했는데, 이는 다음과 같이 사용할 수 있습니다.

'프로그래밍 > 정규표현식' 카테고리의 다른 글
| [REGEX] 조건 달기 (0) | 2022.04.10 |
|---|---|
| [REGEX] 전방탐색과 후방탐색 (1) | 2022.04.10 |
| [REGEX] 하위 표현식 (Subexpression) (0) | 2022.04.08 |
| [REGEX] 위치 찾기 (Position Matching) (0) | 2022.04.07 |
| [REGEX] 반복 찾기 (0) | 2022.04.06 |




댓글