References
- Fluent Python
Contents
- Vector: User-Defined Sequence Type
- Protocols and Duck Typing
- Special Methods for Sequences
이번 포스팅에서는 위의 포스팅에서 구현한 2차원 벡터 클래스를 개선하여 다차원 벡터를 표현하는 클래스를 구현해볼 것입니다. 이렇게 작성된 벡터는 표준 파이썬의 immutable flat 시퀀스와 비슷하게 동작하며, 실수(float)를 요소로 가지고 다음과 같은 기능을 지원합니다.
- 기본 시퀀스 프로토콜: __len__, __getitem__
- 여러 항목들을 가진 인스턴스를 안전하게 표현
- 슬라이싱을 지원하여 새로운 벡터 인스턴스 생성
- 포함된 요소의 값들을 모두 고려한 Hashing
- 커스터마이즈된 formatting language 확장
그리고, 시퀀스 타입에 일반적으로 사용되는 기법은 아니지만, Vector2d의 읽기 전용 프로퍼티를 대체하기 위한 __getattr__() 메소드로 dynamic attribute access를 구현합니다.
Vector: User-Defined Sequence Type
벡터를 구현하는데 사용할 전략은 상속(inheritance)가 아닌 구성(composition)을 이용하는 것입니다. 요소들을 실수형 배열에 저장하고, 벡터가 불변이면서 균일한 시퀀스처럼 동작하기 위해 필요한 메소드들을 구현합니다.
시퀀스 메소드를 구현하기 전에, 먼저 이전 포스팅에서 구현한 Vector2d 클래스와 호환성이 높은 기본 Vector 클래스를 구현해보도록 하겠습니다. 이전에 구현한 Vector2d 클래스는 다음과 같습니다.
from array import array
import math
class Vector2d:
typecode = 'd'
def __init__(self, x=0, y=0):
# 2개의 언더바(__)로 시작하도록 하여 속성을 비공개로 만든다
self.__x = float(x)
self.__y = float(y)
# @property 데코레이터는 프로퍼티의 getter 메소드를 나타낸다
@property
def x(self): # 노출시키고자 하는 public 프로퍼티 이름을 따라 메소드의 이름 지정
return self.__x # 단순히 self.__x를 반환
@property
def y(self): # y 프로퍼티도 x와 동일하게 정의
return self.__y
def __iter__(self):
# x와 y를 읽기만 하는 다른 메소드들은 self.x, self.y를 통해 읽으므로
# __x, __y로 변경하지 않아도 됨
return (i for i in (self.x, self.y))
def __repr__(self):
# __repr__는 {!r}을 각 요소에 repr()을 호출해서 반환된 문자열을 치환해 문자열을 생성
# Vector2d가 iterable하므로, *self는 format()에 x와 y 속성을 제공함
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
def __str__(self):
# iterable Vector2d에서 튜플을 만들어 순서쌍으로 출력하도록 함
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) + # bytes를 생성하기 위해 typecode를 bytes로 변환
bytes(array(self.typecode, self))) # 객체를 반복해서 배열을 생성
def __eq__(self, other):
# 모든 속성을 비교하기 위해 피연산자로부터 튜플을 생성.
# 다만 문제가 있는데, 동일한 숫자값을 가진 어떠한 iterable 객체도 Vector2d와 비교하면
# True를 반환(ex, Vector2d(3, 4) == [3, 4])
return tuple(self) == tuple(other)
def __hash__(self):
return hash(self.x) ^ hash(self.y)
def __abs__(self):
# 벡터의 크기는 sqrt(x*x + y*y). 이를 계산하고 반환
return math.hypot(self.x, self.y)
def __bool__(self):
# __bool__은 abs(self)를 사용해서 벡터의 크기를 계산하고 boolean 타입으로 변환
# 0.0은 False, 그 외의 값은 True
return bool(abs(self))
def angle(self):
return math.atan2(self.y, self.x)
def __format__(self, fmt_spec=''):
if fmt_spec.endswith('p'): # format specifier가 'p'로 끝나면 극좌표를 사용
fmt_spec = fmt_spec[:-1] # 마지막에 있는 'p'를 떼어냄
coords = (abs(self), self.angle())
outer_fmt = '<{}, {}>'
else:
coords = self # 'p'가 없다면 self의 x,y로 직교좌표를 만든다
outer_fmt = '({}, {})'
components = (format(c, fmt_spec) for c in coords)
return outer_fmt.format(*components)
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(*memv)
Vector Version #1: Vector2d Compatible
구현할 Vector는 앞서 구현한 Vector2d 클래스와 가능한 한 호환성이 높아야 합니다.
그러나 Vector 생성자는 Vector2d의 생성자와 호환되지 않습니다. __init__() 메소드에서 임의의 인수 *args를 받아서 Vector(3, 4)나 Vector(3, 4, 5) 형태로 동작하도록 만들 수 있지만, 모든 내장 시퀀스 타입처럼 iterable 타입을 인수로 받게 만드는 것이 가장 좋습니다.
다음 예제 코드는 구현할 Vector 클래스의 인스턴스를 생성하는 방법을 보여줍니다.

생성자 시그니처(파라미터)가 달라진 점 외에 요소 2개를 가진 Vector 클래스는 Vector2d로 수행했던 모든 테스트와 동일한 결과가 나오도록 구현되었습니다. 예를 들어, Vector([3, 4])는 Vector2d(3, 4)와 동일한 결과를 생성합니다.
위의 출력 결과 중, Vector의 요소가 6개 이상 있을 때 repr()이 생성한 문자열은 생략 기호(...)로 축약됩니다. repr()이 디버깅에 사용되므로 많은 항목을 가진 컬렉션 타입에서 이러한 동작은 중요하며, 생략하지 않으면 객체 하나가 콘솔이나 로그에서 수천 줄을 차지하게 됩니다. 위에서 출력된 결과처럼 제한된 길이로 표현하려면 reprlib 모듈을 사용하는 것을 추천합니다.
아래 코드는 최초로 구현한 첫 번째 버전의 Vector 클래스를 구현합니다.
from array import array
import reprlib
import math
class Vector:
typecode = 'd'
def __init__(self, components):
# 'protected' 객체 속성 self._components는 벡터 요소를 배열로 저장
self._components = array(self.typecode, components)
def __iter__(self):
# 반복할 수 있도록 self._components의 반복자를 반환
return iter(self._components)
def __repr__(self):
# self._components를 제한된 길이로 표현하기 위해 reprlib.repr()를 사용
# array('d', [0.0, 1.0, ...]) 형태로 출력
components = reprlib.repr(self._components)
# 문자열을 Vector 생성자에 전달할 수 있도록 문자열 "array('d',"와
# 마지막 괄호를 제거
components = components[components.find('['):-1]
return f'Vector({components})'
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components)) # self._components에서 바로 bytes 객체 생성
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
# 파이썬 3.8부터 math.hypot은 n차원 포인트를 받을 수 있음, 파이썬 3.8 이전이라면
# math.sqrt(sum(x * x for x in self)) 로 작성
return math.hypot(*self)
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv) # *를 이용해서 언패킹할 필요없음
reprlib.repr()을 사용한 방법에 대해서 조금 더 살펴보겠습니다. 이 함수는 생략 기호를 이용해서 생성한 문자열의 길이를 제한하므로 아주 큰 구조체나 재귀적인 구조체도 안전하게 표현합니다. 또한, repr()이 Vector 객체를 "Vector(array('d', [3.0, 4.0, 5.0]))"이 아닌 "Vector([3.0, 4.0, 5.0])"으로 출력하도록 하여, Vector 내부에 배열을 사용한다는 구현 내용을 외부에 노출시키지 않도록 했습니다. 또한 이렇게 생성된 문자열로 동일한 Vector 객체를 생성할 수 있습니다.
__repr__()을 구현할 때, reprlib.repr(list(self._components)) 문장으로 components를 간략히 출력할 수도 있습니다. 하지만 단순히 list.repr()을 사용하기 위해 self._components의 모든 항목을 list에 복사하는 것은 낭비입니다. 대신 reprlib.repr()을 self._components 배열에 직접 적용하고 나서 []바깥쪽에 있는 글자들을 잘라냈습니다.
__str__(), __eq__(), __bool__() 메소드는 Vector2d에 구현된 것과 완전히 동일하며, frombytes() 메소드에는 마지막 리턴문에서 '*'만 제거 되었습니다.
여기서 Vector 클래스가 Vector2d 클래스를 상속받도록 만들 수도 있었지만, 다음과 같은 두 가지 이유 때문에 그렇게 구현하지 않았습니다. 첫째, 생성자가 호환되지 않으므로 상속받는 것은 좋지 않습니다. __init__()에서 매개변수를 처리하도록 만들면 이 문제를 해결할 수 있지만 두 번째 이유가 더 중요한데, Vector 클래스가 시퀀스 프로토콜을 구현하는 독자적인 예제가 되길 원했기 때문입니다.
아래에서 프로토콜이라는 용어에 대해서 살펴보도록 하겠습니다.
Protocols and Duck Typing
파이썬에서 시퀀스 타입을 만들기 위해소 어떤 특별한 클래스를 상속할 필요가 없습니다. 단지 시퀀스 프로토콜을 따르는 메소드를 구현하면 됩니다. 그런데 여기서 말하는 프로토콜은 어떤 프로토콜일까요?
객체지향 프로그래밍의 문맥에서 프로토콜은 문서에만 정의되어 있고 실제 코드에서는 정의되지 않는 비공식 인터페이스입니다. 예를 들어 파이썬의 시퀀스 프로토콜은 __len__()과 __getitem__() 메소드를 동반할 뿐입니다. 표준 시그니처와 의미에 따라 이 메소드들을 구현하는 어떠한 클래스도 시퀀스가 필요한 곳에서 사용될 수 있습니다. 그 클래스의 슈퍼클래스가 무엇인지는 중요하지 않고, 단지 필요한 메소드만 제공하면 됩니다.
다음 예제 코드를 살펴보겠습니다.
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]위 예제 코드의 FrenchDeck 클래스는 시퀀스 프로토콜을 구현하므로 파이썬에서 제공하는 여러 기능들을 활용할 수 있습니다. 코드 어디에서도 시퀀스 프로토콜을 따른다고 정의한 곳은 없습니다. 이 클래스가 object를 상속하고 있지만, 파이썬을 잘 아는 프로그래머들은 이 코드를 보고 시퀀스라는 것을 알 수 있습니다. 이 클래스가 시퀀스처럼 동작하기 때문에 시퀀스인 것이고, 바로 이 점이 중요합니다.
이러한 메커니즘을 덕 타이핑(Duck Typing)이라고 합니다.
프로토콜이 비공식적이며 강제로 적용되는 사항이 아니므로 클래스가 사용되는 특정 환경에 따라 프로토콜의 일부만 구현할 수도 있습니다. 예를 들어 반복을 지원하려면 __getitem__() 메소드만 구현하면 되며, __len__() 메소드를 구현할 필요는 없습니다.
이제 아래에서 Vector 클래스 안에 시퀀스 프로토콜을 구현해보도록 하겠습니다.
Vector Version #2: A Sliceable Sequence
위에서 살펴본 FrenchDeck 예제처럼 객체 안에 있는 시퀀스 속성에 위임하면 시퀀스 프로토콜을 구현하기 위한 __len__()과 __getitem__() 메소드를 self._components 배열을 사용하여 다음과 같이 구현할 수 있습니다.
class Vector:
# ... 나머지 메소드 생략
def __len__(self):
return len(self._components)
def __getitem__(self, index):
return self._components[index]이 두 메소드가 추가되면, 다음과 같은 연산을 수행할 수 있습니다.

여기서 볼 수 있듯이 제대로는 아니지만 슬라이싱도 지원됩니다. Vector의 슬라이스도 배열이 아니라 Vector 객체가 되면 더 좋을 것입니다. 위에서 본 FrenchDeck 클래스도 이와 동일한 문제가 있는데, FrenchDeck을 슬라이싱하면 리스트가 생성됩니다. 이처럼 Vector를 슬라이싱해서 생성된 평범한 배열은 Vector의 기능을 상실하게 됩니다.
내장된 시퀀스 타입은 슬라이싱했을 때 다른 자료형이 아니라 자신과 동일한 자료형의 객체를 생성합니다.
Vector를 슬라이싱해서 Vector 객체를 생성하려면, 슬라이싱 연산을 배열에 위임하면 안되며, __getitem__() 메소드가 받은 인수를 분석하여 제대로 처리해주어야 합니다.
우선 my_seq[1:3]과 같은 구문에서 1:3을 my_seq.__getitem__() 메소드의 인자로 어떻게 변환하는지 살펴보겠습니다.
How Slicing Words
예제 코드를 바로 살펴보겠습니다.

이제 slice에 대해서 알아보도록 하겠습니다.

dir(slice)를 호출하면 indices라는 메소드가 보이는데, 여기에 대해서는 현재 알고 있는 것이 별로 없습니다. help(slice.indices) 명령을 실행해보면 다음의 도움말을 볼 수 있습니다.

내용을 살펴보면, 길이가 len인 시퀀스 S가 나타내는 확장된 슬라이스의 start와 stop 인덱스 및 stride를 계산하며, 경계를 벗어난 인덱스는 일반적인 슬라이스를 처리하는 방법과 동일하게 잘라냅니다.
즉, indices는 missing or nagative 인덱스, 그리고 원본 시퀀스보다 더 긴 시퀀스를 처리하기 위해서 내장된 시퀀스에 구현된 복잡한 로직을 보여줍니다. 이 메소드는 주어진 길이의 시퀀스 경계 안에 들어가도록 음수가 아닌 start, stop, stride의 정규화(normalized)된 튜플을 생성합니다.
'ABCDE'처럼 길이가 5인 시퀀스에 적용한 슬라이스의 예제는 다음과 같습니다.

구현할 Vector 코드에서 slice 인수를 전달 받을 때, 이를 _components 배열에 처리를 위임할 것이므로 slice.indicies() 메소드를 구현할 필요는 없습니다. 하지만, 기반이 되는 시퀀스가 제공하는 서비스에 의존할 수 없을 때는 이 메소드가 큰 도움이 됩니다.
이제 Vector.__getitem__() 메소드가 어떻게 구현되어야 하는지 살펴보겠습니다.
A Slice-Aware __getitem__
아래 코드는 Vector가 시퀀스로 동작하기 위해 필요한 __len__()과 __getitem__() 메소드를 보여줍니다. 이렇게 구현하면 __getitem__()이 슬라이싱도 제대로 처리하게 됩니다.
def __len__(self):
return len(self._components)
def __getitem__(self, key):
if isinstance(index, slice): # if index's type is slice
# 객체의 클래스(Vector)를 가져옴
cls = type(self)
# _components 배열의 슬라이스로부터 Vector 객체 생성
return cls(self._components[key])
# if index's type is Integral
index = operator.index(key)
# _components에서 해당 항목을 가져와서 반환
return self._components[index]
여기서 operator.index() 함수는 __index__ 스페셜 메소드를 호출합니다. 이 함수와 스페셜 메소드는 PEP 357에 정의되어 있습니다. 이는 Numpy에서 정수형의 어떠한 숫자 타입도 인덱스와 slice 인수로 사용될 수 있도록 해줍니다. operator.index()와 int()의 가장 큰 차이점은 operator.index()는 특별한 목적을 가지고 있다는 것입니다. 예를 들어, int(3.14)는 3을 반환하지만, operator.index(3.14)는 float는 인덱스가 될 수 없기 때문에 TypeError를 발생시킵니다.
이렇게 구현된 Vector는 이제 다음과 같이 적절하게 슬라이싱 동작을 수행합니다.
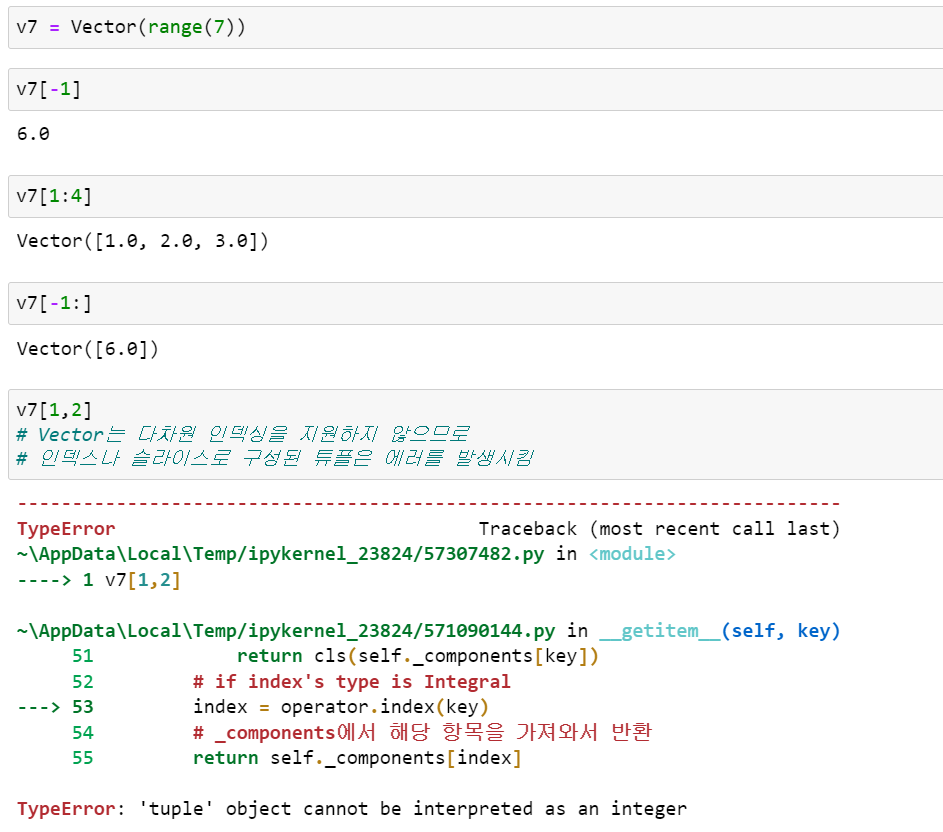
Vector Version #3: Dynamic Attribute Access
Vector2d에서 Vector로 변경되면서, v.x, v.y처럼 벡터 요소를 이름으로 접근하는 기능을 잃어버렸습니다. 이제는 아주 많은 요소를 가진 벡터를 다루고 있습니다. 그렇지만 앞에 있는 요소 몇 개는 v[0], v[1], v[2] 대신 x, y, z로 접근할 수 있으면 편리할 것입니다.
따라서, 벡터의 처음 네 요소를 읽는 또 다른 구문은 다음과 같습니다

Vector2d에서는 @property 데코레이터를 이용해서 x와 y에 읽기 전용 접근을 제공했습니다. Vector에 4개의 프로퍼티를 작성할 수도 있지만, 코드가 지저분해집니다. 대신 __getattr__() 스페셜 메소드를 이용하면 더욱 깔끔하게 구현할 수 있습니다.
속성을 찾지 못할 때, 인터프리터는 __getattr__() 메소드를 호출합니다. 간단히 말해, my_obj.x 표현식이 주어졌을 때, 파이썬은 my_obj 객체에 x라는 속성이 있는지 검사합니다. 속성이 없으면 이 객체의 클래스(my_obj.__class__)에서 더 검색합니다. 그리고 나서 상속 그래프(inheritance graph)를 따라 계속 올라갑니다. 그래도 x 속성을 찾지 못하면 self와 속성명을 문자열(ex, 'x')로 전달해서 my_obj의 클래스에 정의된 __getattr__() 메소드를 호출합니다.
아래 코드는 위의 동작을 지원하는 __getattr__() 메소드의 구현을 보여줍니다. 이 메소드는 찾고 있는 속성이 x, y, z, t 문자 중 하나인지 검사하고, 이중 하나인 경우에는 해당 벡터 요소를 반환합니다.
# __getattr__에 의해 지원되는 dynamic attributes의 매칭 패턴
__match_args__ = ('x', 'y', 'z', 't')
def __getattr__(self, name):
# Vector 클래스를 가져옴
cls = type(self)
try:
# __match_args__에서 name의 위치를 가져옴
pos = cls.__match_args__.index(name)
# name을 찾지 못했을 때 .index(name)는 ValueError를 발생시킴
except ValueError:
# name을 찾지 못하면 pos를 -1로 설정
pos = -1
# pos가 유효한 인덱스라면 해당 항목 반환
if 0 <= pos < len(self._components):
return self._components[pos]
# 여기까지 도달하면 문제가 발생했다는 것이고, AttributeError를 발생시킴
msg = f'{cls.__name__!r} object has no attirbute {name!r}'
raise AttributeError(msg)
__getattr__() 메소드를 구현하는 것이 어렵지는 않지만, 이걸로 충분하지는 않습니다. 다음과 같은 부적절하게 사용하는 경우를 살펴보겠습니다.

여기서 v.x에 10을 할당했고, v.x를 읽으면 10을 반환합니다. 하지만 벡터 요소 배열을 살펴보면 10이 들어 있지 않습니다.
위의 불일치 문제는 __getattr__() 메소드가 동작하는 방식 때문에 발생합니다. 파이썬은 해당 이름의 속성을 찾지 못할 때 최후 수단으로 __getattr__() 메소드를 호출합니다. 그러나 v.x = 10 문장으로 x 속성에 값을 할당할 때, v 객체에 x 속성이 추가되므로, 더 이상 v.x 값을 가져오기 위해 __getattr__()을 호출하지 않습니다. 인터프리터는 단지 v.x에 바인딩된 값 10을 반환합니다.
이와 같은 불일치 문제를 해결하려면 Vector 클래스에서 속성값을 설정하는 부분의 로직을 수정해야 합니다. Vector2d에서 .x나 .y 인스턴스 속성에 값을 할당하려고 하면 AttributeError가 발생했습니다. Vector에서도 이런 문제를 피하기 위해 소문자 하나로 된 속성명에 값을 할당할 때 동일한 예외를 발생시켜주어야 합니다. 그렇게 하려면 다음과 같이 __setattr__() 메소드를 구현해야 합니다.
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1: # 단일 문자 속성에 대한 특별한 처리
if name in cls.__match_args__: # name이 __match_args__ 중 하나에 속할 때, 에러 발생
error = 'readonly attribute {attr_name!r}'
elif name.islower(): # name이 소문자일 때 모든 단일 문자에 대해 에러 발생
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
# 나머지의 경우 빈 에러 메세지로 설정
error = ''
if error:
# 빈 에러 메세지가 아니라면, AttributeError 발생
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg)
# 에러가 발생하지 않을 때는 표준 동작을 위해 슈퍼클래스의 __setattr__() 메소드 호출
super().__setattr__(name, value)
여기서 주의할 점은, 모든 속성의 설정을 막는 것이 아니라 지원되는 읽기 전용 속성 x, y, z, t와의 혼동을 피하기 위해서 단일 소문자로 되어 있는 속성의 설정만 막고 있다는 것입니다.
클래스 수준에서 __slots__을 정의하면 새로운 객체 속성을 생성할 수 없다는 것을 알고 있으므로, 여기서 구현한 __setattr__() 대신 __slots__ 속성을 사용하고 싶을 수도 있습니다. 그러나 단지 객체 속성의 생성을 막기 위해 __slots__을 사용하는 것은 권장하지 않습니다. __slots__은 정말로 문제가 있을 때만 메모리를 절약하기 위해서 사용해야 합니다.
Vector 요소에 저장하는 기능을 지원하지는 않지만, 이 예제에서는 객체 동작의 불일치를 피하려면 __getattr__()을 구현할 때 __setattr__()도 함께 구현해야 한다는 것을 알려줍니다.
벡터 요소의 변경을 허용하고 싶은 경우, __setitem__() 메소드를 구현하면 v[0] = 1.1의 형태로, __setattr__() 메소드를 구현하면 v.x = 1.1의 형태로 작성할 수 있습니다. 다만, 아래에서 Vector를 해시 가능하도록 만들기 위해서, 일단 Vector를 불변형으로 유지하도록 하겠습니다.
Vector Version #4: Hashing and a Faster ==
__hash__() 메소드를 구현해보도록 하겠습니다. 기존의 __eq__() 메소드와 함께 __hash__() 메소드를 구현하면 Vector 객체는 해시할 수 있게 됩니다.
Vector2d의 __hash__()는 hash(self.x) ^ hash(self.y)를 이용해서 해시값을 계산했습니다. Vector에서는 hash(v[0]) ^ hash(v[1]) ^ hash(v[2]) ...의 형태로 각 요소의 해시를 계산하고, 그 결과에 ^(XOR) 연산자를 적용하려고 합니다. 이런 연산을 위해서 functools.reduce() 함수가 있습니다. reduce() 함수가 그리 자주 사용되는 것은 아니지만, 모든 벡터 요소의 해시를 계산하는 연산은 reduce()에 딱 맞습니다.
functools.reduce()를 자세히 살펴보겠습니다. 이 함수의 핵심은 일련의 값들을 하나의 값으로 줄이는 것입니다. reduce()가 받는 첫 번째 인수는 두 개의 인수를 받는 함수이고, 두 번째 인수는 반복형입니다. 인수 두 개를 받는 함수 fn과 리스트 lst가 있다고 가정해봅시다. reduce(fn, lst)를 호출하면 첫 번째 요소 쌍에 fn을 적용해서(즉, fn(lst[0], lst[1])) 첫 번째 결과 r1을 생성합니다. 그리고 나서 r1과 다음 요소에 fn을 적용해서(즉, fn(r1, lst[2])) 두 번째 결과 r2를 생성합니다. 이 과정을 마지막 요소까지 반복하면 결국 rN이 반환됩니다.
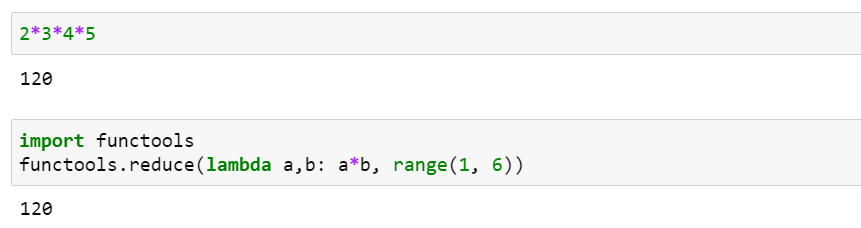
다음은 reduce()를 이용해서 5!를 계산하는 코드입니다.
이제 다시 해시 문제로 돌아가보겠습니다. 아래 예제 코드는 0에서 5까지의 숫자에 XOR을 누적 계산하는 3가지 방법을 보여줍니다. 첫 번째는 for루프, 두 번째와 세 번째는 reduce() 함수를 사용합니다.

3가지 방법 중에 선호하는 것을 사용하면 됩니다.
여기서 operator 모듈은 모든 파이썬 중위 연산자를 함수 형태로 제공해서 람다를 사용할 필요성을 줄여줍니다.
Vector.__hash__()를 마지막 스타일로 구현하려면 functools와 operator 모듈을 import해주어야 합니다. (operator는 이미 __getitem__() 에서 사용하고 있긴 합니다.)
그리고 구현한 __hash__는 다음과 같습니다.
def __eq__(self, other):
return tuple(self) == tuple(other)
def __hash__(self):
# 각 요소의 해시를 계산하기 위한 제너레이터 표현식을 생성
hashes = (hash(x) for x in self._components)
# xor 함수와 hashes를 전달하여 reduce() 함수 호출, 세 번째 인수 0은 초기값
return functools.reduce(operator.xor, hashes, 0)
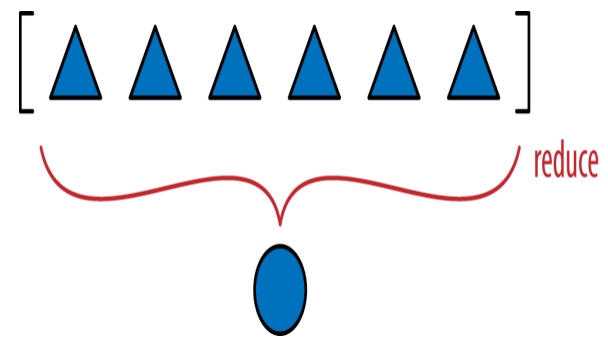
__hash__ 메소드는 아래 그림의 맵-리듀스 연산에 딱 맞는 예제입니다.

map 단계에소 각 요소에 대한 해시를 계산하고, reduce 단계에서 모든 해시에 xor 연산자를 적용합니다. 제너레이터 표현식 대신 맵을 사용하면 그 단계가 더 잘 드러납니다.
def __hash__(self):
hashes = map(hash, self._components)
return functools.reduce(operator.xor, hashes)map() 함수가 결과값을 가진 리스트를 새로 생성하는 파이썬 2에서는 map()을 이용한 방법은 효율이 떨어집니다. 하지만 파이썬 3에서의 map()은 필요할 때 결과를 내보내는 제너레이터로 생성합니다. 따라서 map을 사용한 __hash__ 또한 제너레이터 표현식과 마찬가지로 메모리를 절약해줍니다.
지금까지 reduce 함수에 대해서 살펴봤지만, __eq__() 메소드를 간단히 살펴보겠습니다.
__eq__() 메소드도 간단한 수정을 통해서 커다란 벡터를 더 빠르고 메모리를 적게 사용하도록 할 수 있습니다. 현재 __eq__는 다음과 같이 구현되어 있습니다.
def __eq__(self, other):
return tuple(self) == tuple(other)이 코드는 Vector2d와 Vector 클래스 모두에 동작합니다. 심지어 Vector([1, 2])와 (1, 2)가 같다고 판단합니다. 이는 문제가 될 수는 있는데, 지금은 무시하도록 하겠습니다.
하지만, 수천 개의 요소를 가질 수 있는 Vector 인스턴스의 경우에, 이 코드는 상당히 비효율적입니다. 단지 튜플형의 __eq__() 메소드를 적용하기 위해서 피연산자 전체를 복사해서 튜플 2개를 생성합니다. 요소가 두 개 밖에 없는 Vector2d의 경우에는 나쁘지 않지만, 아주 큰 다차원 벡터의 경우에는 이야기가 다릅니다. Vector 객체를 다른 Vector 객체나 반복형과 비교할 때는 다음과 같이 구현하는 것이 좋습니다.
def __eq__(self, other):
if len(self) != len(other): # 두 객체의 길이가 다르면, 다른 객체
return False
for a, b in zip(self, other):
# zip은 반복형 인수의 항목으로 구성된 튜플의 제너레이터를 생성
if a != b:
# 두 요소가 다르다는 것이 발견되면 바로 False를 반환
return False
# 여기까지 도달하면 객체가 동일한 것으로 판단
return True위 코드는 효율이 높지만, all() 함수를 사용하면 for 루프와 동일한 계산을 단 한 줄에 할 수 있습니다. 해당 요소 간의 비교가 모두 True면, 결과도 True입니다. 비교하는 도중에 다른 요소가 발견되면, 즉 비교가 False면 all()은 바로 False를 반환합니다. all() 함수를 이용해서 구현한 __eq__() 메소드는 다음과 같습니다.
def __eq__(self, other):
return len(self) == len(other) and all(a == b for a, b in zip(self, other))zip()은 가장 짧은 피연산자에 맞춰서 중단되기 때문에, 먼저 피연산자의 길이를 검사해야 하는 것에 주의합니다.
Vector Version #5: Formatting
Vector의 __format__() 메소드는 Vector2d의 __format__()과 비슷하지만, 극좌표 대신 구면좌표(spherical coordinate)를 사용합니다. 구면좌표는 초구면좌표(hyperspherical coordinate)라고도 하는데, 4차원 이상에서의 구를 초구(phyersphere)라고 하기 때문입니다. 이에 따라 뒤에 붙는 포맷 코드를 'p'에서 'h'로 변경합니다.
예를 들어, 4차원 공간(len(v) == 4)에 있는 Vector 객체에 대해 'h' 코드는 <r, \(\phi_1\), \(\phi_2\), \(\phi_3\)>을 출력합니다. 이때 r의 크기는 (abs(v))로 나타내고, 나머지 숫자는 각좌표 \(\phi_1\), \(\phi_2\), \(\phi_3\)를 나타냅니다.
4차원 구면 좌표로 출력하도록 만들면, 다음과 같이 출력 되어야 합니다.

우선 __format__() 메소드를 수정하기 전에 몇 가지 헬퍼 메소드를 구현해야 합니다. angle(n)은 특정 좌표의 각좌표를 계산하고(ex, \(\phi_1\)), angles()는 모든 각좌표의 반복형을 반환합니다. 여기서 구체적인 수학 공식에 대한 내용은 생략하도록 하겠습니다. Vector 요소 배열에 들어 있는 직교좌표에서 구면좌표를 구하는 자세한 방법은 wiki를 참조하시길 바랍니다.
헬퍼 메소드와 __format__() 메소드의 구현은 다음과 같습니다.
import itertools
# ...
# 특정 좌표에 대한 각좌표를 계산
def angle(self, n):
r = math.hypot(*self[n:])
a = math.atan2(r, self[n-1])
if (n == len(self) - 1) and (self[-1] < 0):
return math.pi * 2 - a
else:
return a
# 모든 각좌표를 계산하는 제너레이터 표현식을 생성
def angles(self):
return (self.angle(n) for n in range(1, len(self)))
def __format__(self, fmt_spec=''):
if fmt_spec.endwidth('h'):
fmt_spec = fmt_spec[:-1]
# itertools.chain() 함수를 이용해서 크기와 각좌표를 차례로 반복하는
# 제너레이터 표현식 생성
coords = itertools.chain([abs(self)],
self.angles())
outer_fmt = '<{}>' # 구면좌표는 꺽쇠괄호를 이용하여 출력
else:
coords = self
outer_fmt = '({})' # 직교좌표는 괄호를 이용하여 출력
# 좌표의 각 항목을 요구사항에 따라 포맷하는 제너레이터 표현식 생성
components = (format(c, fmt_spec) for c in coords)
# 포맷된 요소들을 콤마로 분리하여 반환
return outer_fmt.format(', '.join(components))
이번 포스팅에서는 다차원 벡터를 표현하는 클래스 Vector를 여기까지 구현해보도록 하겠습니다. 스페셜 메소드들을 이용하여 다른 시퀀스형과 같은 동작을 수행할 수 있는 것에 초점을 맞추었습니다 !
여기까지 구현된 Vector 클래스의 전체 구현은 다음과 같습니다 !
from array import array
import reprlib
import math
import operator
import functools
import itertools
class Vector:
typecode = 'd'
def __init__(self, components):
# 'protected' 객체 속성 self._components는 벡터 요소를 배열로 저장
self._components = array(self.typecode, components)
def __iter__(self):
# 반복할 수 있도록 self._components의 반복자를 반환
return iter(self._components)
def __repr__(self):
# self._components를 제한된 길이로 표현하기 위해 reprlib.repr()를 사용
# array('d', [0.0, 1.0, ...]) 형태로 출력
components = reprlib.repr(self._components)
# 문자열을 Vector 생성자에 전달할 수 있도록 문자열 "array('d',"와
# 마지막 괄호를 제거
components = components[components.find('['):-1]
return f'Vector({components})'
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components)) # self._components에서 바로 bytes 객체 생성
def __eq__(self, other):
return len(self) == len(other) and all(a == b for a, b in zip(self, other))
def __hash__(self):
# 각 요소의 해시를 계산하기 위한 제너레이터 표현식을 생성
hashes = (hash(x) for x in self._components)
# xor 함수와 hashes를 전달하여 reduce() 함수 호출, 세 번째 인수 0은 초기값
return functools.reduce(operator.xor, hashes, 0)
def __abs__(self):
# 파이썬 3.8부터 math.hypot은 n차원 포인트를 받을 수 있음, 파이썬 3.8 이전이라면
# math.sqrt(sum(x * x for x in self)) 로 작성
return math.hypot(*self)
def __bool__(self):
return bool(abs(self))
def __len__(self):
return len(self._components)
def __getitem__(self, key):
if isinstance(key, slice): # if index's type is slice
# 객체의 클래스(Vector)를 가져옴
cls = type(self)
# _components 배열의 슬라이스로부터 Vector 객체 생성
return cls(self._components[key])
# if index's type is Integral
index = operator.index(key)
# _components에서 해당 항목을 가져와서 반환
return self._components[index]
# __getattr__에 의해 지원되는 dynamic attributes의 매칭 패턴
__match_args__ = ('x', 'y', 'z', 't')
def __getattr__(self, name):
# Vector 클래스를 가져옴
cls = type(self)
try:
# __match_args__에서 name의 위치를 가져옴
pos = cls.__match_args__.index(name)
# name을 찾지 못했을 때 .index(name)는 ValueError를 발생시킴
except ValueError:
# name을 찾지 못하면 pos를 -1로 설정
pos = -1
# pos가 유효한 인덱스라면 해당 항목 반환
if 0 <= pos < len(self._components):
return self._components[pos]
# 여기까지 도달하면 문제가 발생했다는 것이고, AttributeError를 발생시킴
msg = f'{cls.__name__!r} object has no attirbute {name!r}'
raise AttributeError(msg)
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1:
if name in cls.__match_args__:
error = 'readonly attribute {attr_name!r}'
elif name.islower():
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
error = ''
if error:
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg)
super().__setattr__(name, value)
# 특정 좌표에 대한 각좌표를 계산
def angle(self, n):
r = math.hypot(*self[n:])
a = math.atan2(r, self[n-1])
if (n == len(self) - 1) and (self[-1] < 0):
return math.pi * 2 - a
else:
return a
# 모든 각좌표를 계산하는 제너레이터 표현식을 생성
def angles(self):
return (self.angle(n) for n in range(1, len(self)))
def __format__(self, fmt_spec=''):
if fmt_spec.endwidth('h'):
fmt_spec = fmt_spec[:-1]
# itertools.chain() 함수를 이용해서 크기와 각좌표를 차례로 반복하는
# 제너레이터 표현식 생성
coords = itertools.chain([abs(self)],
self.angles())
outer_fmt = '<{}>' # 구면좌표는 꺽쇠괄호를 이용하여 출력
else:
coords = self
outer_fmt = '({})' # 직교좌표는 괄호를 이용하여 출력
# 좌표의 각 항목을 요구사항에 따라 포맷하는 제너레이터 표현식 생성
components = (format(c, fmt_spec) for c in coords)
# 포맷된 요소들을 콤마로 분리하여 반환
return outer_fmt.format(', '.join(components))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv) # *를 이용해서 언패킹할 필요없음
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] 연산자 오버로딩 (0) | 2022.03.24 |
|---|---|
| [Python] Interfaces, Protocols, and ABCs (2) | 2022.03.23 |
| [Python] Data Class Builders (0) | 2022.03.20 |
| [Python] A Pythonic Object (0) | 2022.03.19 |
| [Python] 데코레이터와 클로저 (0) | 2022.03.18 |




댓글