References
- Fluent Python
Contents
- Object Identity, Value, Aliasing
- == and is 연산자
- Shallow Copy and Deep Copy
- Function Parameters as References
- del and Garbage Collection
- Weak References
Variables Are Not Boxes
일반적으로 변수를 값을 담고 있는 상자라고 표현합니다. 하지만 '상자로서의 변수' 개념이 실제로는 객체지향 언어에서 참조 변수(reference variable)을 이해하는데 방해가 됩니다. 파이썬 변수는 자바에서의 참조 변수와 같으므로 변수는 객체에 붙은 레이블이라고 생각하는 것이 좋습니다.
다음 코드는 '상자로서의 변수'라는 개념이 설명할 수 없는 간단한 코드입니다.

아래 그림을 살펴보면, 파이썬에서 상자 비유는 잘못되었고, 포스트잇이 변수가 어떻게 동작하는지 이해하는데 도움이 됩니다.
할당에 대해서도 잘못된 비유가 있습니다. 예를 들어 시소 객체가 있다고 할 때, '변수 s가 시소에 할당되었다'라고 설명하지 '시소가 변수 s에 할당되었다'라고 하지 않습니다. 참조 변수의 경우 변수가 객체에 할당되었다는 표현이 객체를 변수에 할당했다는 표현보다 더 타당합니다. 결국 객체는 변수가 할당되기 전에 생성됩니다.
다음 코드는 할당문의 오른쪽이 먼저 실행된다는 것을 입증합니다.
위 출력을 살펴보면, Gizmo: id ... 출력은 Gizmo 객체를 생성할 때 부수적으로 생성됩니다. 여기서 Gizmo() 객체에 숫자를 곱하면 예외가 발생하는데, 곱셈을 시도하기 전에 두 번째 Gizmo 객체가 실제로 생성되었는 것을 확인할 수 있습니다. 그러나 할당문의 우항이 실행되는 동안 예외가 발생했기 때문에 변수 y는 생성되지 않았습니다.
변수는 단지 레이블일 뿐이므로 객체에 여러 레이블을 붙이지 못할 이유가 없습니다. 여러 레이블을 붙이는 것을 앨리어싱(aliasing, 별명) 이라고 합니다.
Identity, Equality, and Aliases
Lewis Carroll은 Charles Lutwidge Dodgson 교수의 필명입니다. 그렇다면 Carroll은 Dodgson 교수와 같을 뿐만 아니라, 단 한 명의 동일인입니다. 아래 코드는 이러한 개념을 파이썬으로 표현하고 있습니다.
여기서 is 연산자와 id() 함수로 이러한 사실을 확인합니다.
그런데, 예를 들어 Alexander Pedchenko 박사가 자신이 1832년에 태어난 Charles L. Dodgon이라고 사칭하고 있다고 가정해봅시다. 그의 자격 증명이 동일할 수는 있어도 동일인일 수는 없습니다. 아래 그림은 이 시나리오를 보여줍니다.
다음 예제 코드는 위 그림에서 나온 alex 객체를 구현하고 테스트합니다.
charles와 lewis는 앨리어싱의 한 예입니다. 코드 안에서 lewis와 charles는 별명이며, 두 변수가 동일 객체에 바인딩되어 있습니다. 한편 alex는 charles에 대한 별명이 아닙니다. 이 두 변수는 서로 다른 객체에 바인딩되어 있습니다. alex에 바인딩된 객체와 charles에 바인딩된 객체가 동일한 값(value)을 가지고 있으므로 == 연산자(동치;equality 연산자)에 의해 동일하다고 판단되지만, 정체성(identity)은 다릅니다.
파이썬 언어의 레퍼런스 문서의 '3.1 Objects, values and types'(link)에는 다음과 같이 설명하고 있습니다.
- 모든 객체는 정체성, 타입, 값을 가지고 있다. 객체의 정체성은 일단 생성한 후에는 결코 변하지 않는다. 정체성은 메모리 내의 객체 주소라고 생각할 수 있다. is 연산자는 두 객체의 정체성을 비교한다. id() 함수는 정체성을 나타내는 정수를 반환한다.
객체 ID의 실제 의미는 구현에 따라 다릅니다. CPython의 경우 id()는 객체의 메모리 주소를 반환하지만, 다른 파이썬 인터프리터는 메모리 주소 이외의 다른 값을 반환할 수도 있습니다. 다만 ID는 객체마다 고유한 레이블이라는 것을 보장하며 객체가 소멸될 때까지 결코 변하지 않습니다.
실제 프로그래밍할 때는 id() 함수를 거의 사용하지 않습니다. 정체성 검사는 주로 is 연산자를 이용해서 수행하며 ID를 직접 비교하지 않습니다.
Choosing Between == and is
== 연산자가 객체의 값을 비교하는 반면, is 연산자는 객체의 정체성(identity)를 비교합니다. 정체성보다 값을 비교하는 경우가 많으므로, 파이썬 코드에서는 == 연산자를 is 연산자보다 자주 볼 수 있습니다.
그렇지만 변수를 싱글턴(singleton)과 비교할 때는 is 연산자를 사용해야 합니다. is 연산자를 사용할 때는 변수를 None과 비교하는 경우가 일반적이며, 다음과 같이 사용합니다.
x is None그리고 이 표현식의 반대는 다음과 같이 작성합니다.
x is not None
is 연산자는 오버로딩할 수 없으므로 파이썬이 이 값을 평가하기 위해 스페셜 메소드를 호출할 필요가 없고, 두 정수를 비교하는 정도로 연산이 간단하므로 is 연산자가 == 연산자보다 빠릅니다. 반면 a == b는 a.__eq__(b)의 축약 문법입니다. object 객체에서 상속받은 __eq__() 메소드는 객체의 ID를 비교하므로 is 연산자와 동일한 결과를 산출합니다. 그러나 대부분의 내장 타입은 __eq__() 메소드를 오버라이드해서 객체의 값을 비교합니다. 매우 큰 컬렉션이나 깊게 중첩된 구조체를 비교하는 경우 equlity는 상당한 처리를 필요로 합니다.
The Relative Immutability of Tuples
Identity와 Equality에 대한 이야기를 마치기 전에 튜플의 불변성에 대해서 살펴보겠습니다.
리스트, 딕셔너리, 집합 등 대부분의 파이썬 컬렉션과 마찬가지로 튜플도 객체에 대한 참조를 담습니다. 참조된 항목이 가변형이면 튜플 자체는 불변형이지만 참조된 항목은 변할 수 있습니다. 즉, 튜플의 불변성은 tuple 데이터 구조체의 물리적인 내용(즉, 참조 자체)만을 말하는 것이며, 참조된 객체까지 불변성을 가지는 것은 아닙니다.
다음 예제 코드는 튜플이 참조한 가변 객체의 변경에 의해 튜플의 값이 변경되는 상황을 보여줍니다. 튜플 안에서 절대로 변하지 않는 것은 튜플이 담고 있는 항목들의 identity입니다.
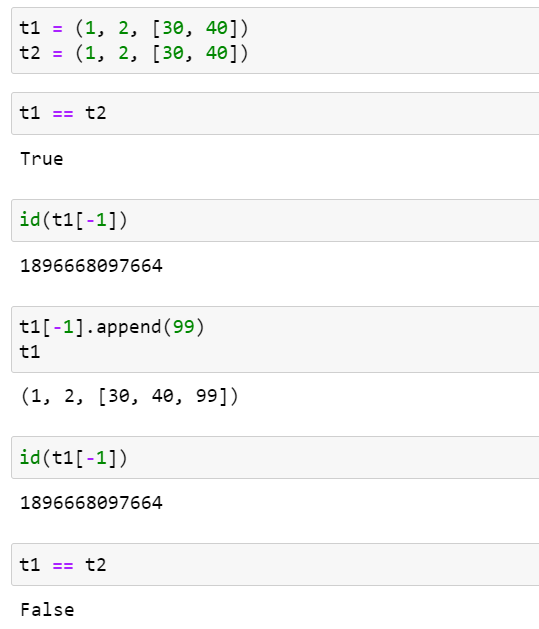
이러한 튜플의 상대적 불변성 때문에 일부 튜플이 해시 불가능하기도 합니다.
Equality와 Identity 간의 차이는 객체를 복사할 때 더 큰 영향을 미칩니다. 사본은 ID가 다른 동일한 객체입니다. 그러나 객체가 다른 객체를 담고 있을 때 복사하면 내부 객체도 복사해야 할까요? 아니면 내부 객체는 공유해도 될까요 ?
이에 대한 정답은 없습니다.
Copies Are Shallow by Default
리스트와 같은 대부분의 내장된 컬렉션 타입을 복사하는 가장 손쉬운 방법은 그 타입 자체의 내장 생성자를 사용하는 것입니다.

위에서 list(l1)은 l1의 사본을 생성하며, l1과 l2는 동일합니다. 하지만 l1과 l2는 서로 다른 두 객체를 참조합니다.
리스트 및 가변형 시퀀스의 경우 l2 = l1[:]로 작성해도 사본을 생성합니다.
그러나 생성자나 [:]를 사용하면 얕은 복사(shallow copy)로 생성하게 됩니다. 즉, 최상위 컨테이너는 복사하지만 사본은 원래 컨테이너에 들어 있던 동일 객체에 대한 참조로 채워집니다. 모든 항목이 불변형이면 이 방식은 메모리르 ㄹ절약하며 아무런 문제를 일이키지 않습니다. 그러나 가변 항목이 들어 있다면 문제를 야기할 수 있습니다.
다음 예제 코드는 다른 리스트와 튜플을 담고 있는 리스트의 얕은 복사로 사본을 생성한 후 변경하면 참조된 객체에 어떠한 영향을 미치는지 보여줍니다.

아래 그림은 위의 코드에서 l2 = list(l1) 할당문을 실행한 직후의 상태입니다.
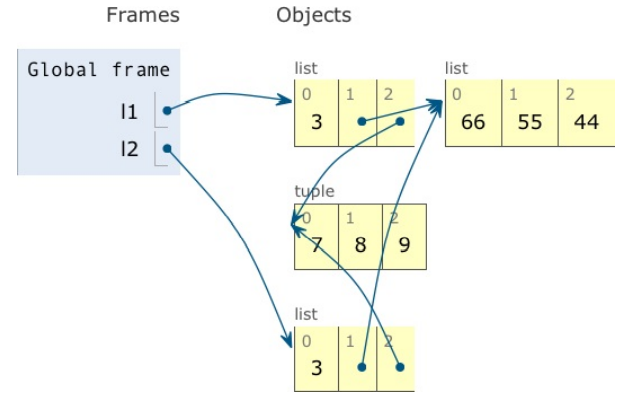
그리고 l1과 l2의 최종 상태는 다음과 같습니다.
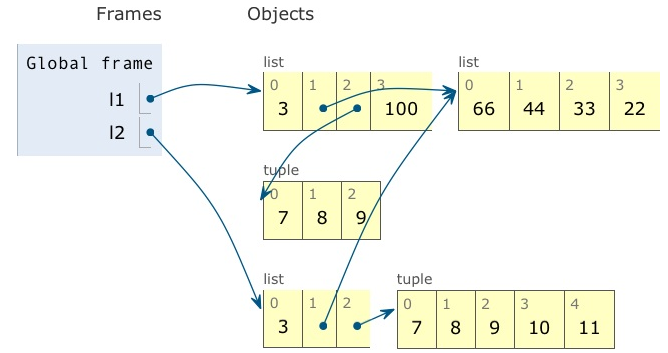
Deep and Shallow Copies of Arbitary Objects
얕은 복사에서 늘 문제가 발생하는 것은 아니지만, 내포된 객체의 참조를 공유하지 않도록 깊은 복사(deep copy)가 필요한 경우가 종종 있습니다. copy 모듈이 제공하는 deepcopy() 함수는 깊은 복사를, copy() 함수는 얕은 복사를 지원합니다.
copy()와 deepcopy()의 사용방법을 살펴보기 위해서 아래 코드는 노선을 따라가면서 승객을 태우거나 내리는 버스를 표현하는 Bus 클래스를 정의합니다.
class Bus: def __init__(self, passengers=None): if passengers is None: self.passengers = [] else: self.passengers = list(passengers) def pick(self, name): self.passengers.append(name) def drop(self, name): self.passengers.remove(name)
위 클래스를 가지고 bus1 객체와 두 개의 사본(bus2는 얕은 복사, bus3은 깊은 복사를 통한 사본)을 만들어 bus1에서 승객이 내릴 때 어떤 일이 발생하는지 살펴보겠습니다.
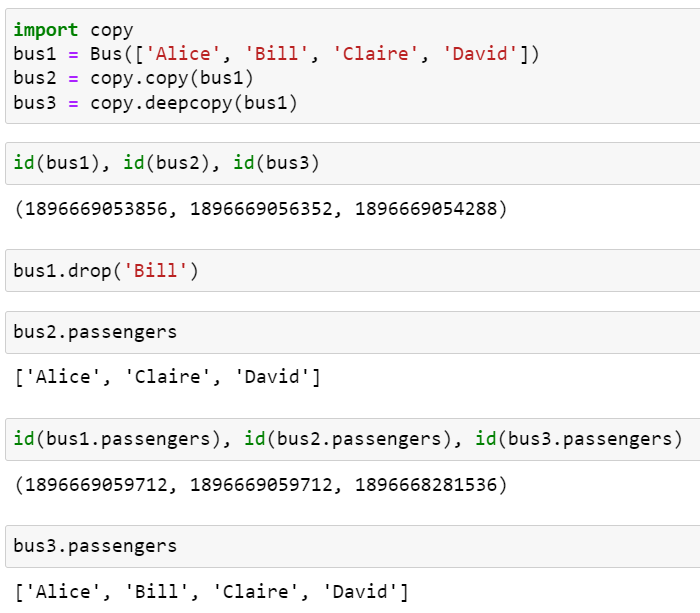
결과를 살펴보면 bus1의 passengers와 bus2의 passengers가 동일한 리스트라는 것을 알 수 있습니다.
일반적으로 깊은 복사를 통해 사본을 만드는 일은 간단하지 않습니다. 객체 안에 순환 참조가 있으면 단순한 알고리즘은 무한 루프에 빠질 수 있습니다. deepcopy() 함수는 순환 참조를 제대로 처리하기 위해 이미 복사한 객체에 대한 참조를 기억하고 있습니다. 순환 참조를 깊은 복사로 복사하는 예는 다음과 같습니다.
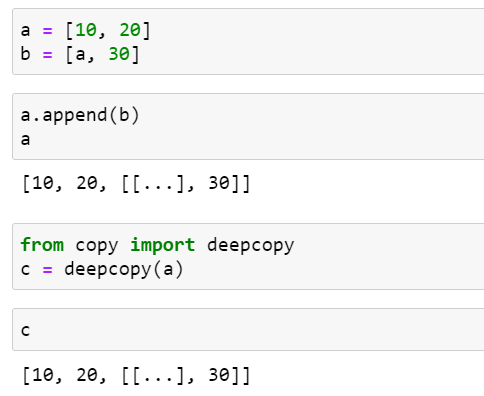
게다가 깊은 복사가 너무 깊게 복사하는 경우도 있습니다. 예를 들어 복사하면 안되는 외부 리소스나 싱글턴을 객체가 참조하는 경우가 있습니다. copy 모듈 문서(link)에 설명된 대로 __copy__()와 __deepcopy__() 스페셜 메소드를 구현해서 copy()와 deepcopy()의 동작을 제어할 수 있습니다.
Function Parameters as References
파이썬은 call by sharing하는 매개변수 전달 방식만 지원합니다. 이 방식은 루비, 스몰토크, 자바(참조 타입일 때만 동일) 등 대부분의 객체지향 언어에서 사용하는 방식과 동일합니다. 공유로 호출한다는 말은 함수의 각 매개변수가 인수로 전달받은 각 참조의 사본을 받는다는 의미입니다. 달리 말하면, 함수 안의 매개변수는 실제 인수의 별명이 됩니다.
이러한 체계의 결과로, 함수는 인수로 전달받은 모든 가변 객체를 변경할 수 있지만, 객체의 identity 자체는 변경할 수 없습니다. 즉, 어떤 객체를 다른 객체로 바꿀 수 없습니다. 아래 예제 코드는 매개변수 중 하나에 += 연산자를 사용하는 간단한 함수를 보여줍니다. 함수에 숫자, 리스트, 튜플을 전달하면, 전달받은 인수는 서로 다른 영향을 받습니다.

결과를 살펴보면, 숫자 x는 변경되지 않았고, 리스트 a는 변경되었고, 튜플 t는 변경되지 않았습니다.
함수 매개변수와 관련된 또 다른 문제는 가변형 기본값을 사용하는 것과 관련이 있는데, 아래에서 살펴보겠습니다.
Mutable Types as Parameter Defaults: Bad Idea
기본값을 가진 선택적 인수는 파이썬 함수 정의에서 아주 좋은 기능으로, 하위 호환성을 유지하며 API를 개선할 수 있게 해줍니다. 그러나 매개변수 기본값으로 가변 객체를 사용하는 것은 피해야 합니다.
예를 들어, 위에서 살펴본 Bus 클래스에서 __init__() 메소드를 변경하여 HauntedBus 클래스를 정의합니다. 여기서 약간의 트릭으로 passengers의 기본값을 None 대신 []을 사용하여 이전 __init__() 메소드에서 if문으로 검사하던 부분을 생략했습니다.
class HauntedBus: def __init__(self, passengers=[]): self.passengers = passengers def pick(self, name): self.passengers.append(name) def drop(self, name): self.passengers.remove(name)
이 클래스에서 passengers 인수를 전달하지 않는 경우 이 매개변수는 기본값인 빈 리스트에 바인딩됩니다. __init__() 메소드 내에서 할당문은 self.passengers를 passengers에 대한 별명으로 만들기 때문에 passengers 인수를 전달하지 않는 경우 self.passengers를 기본값인 빈 리스트에 대한 별명으로 설정합니다.
다음 코드는 HauntedBus의 이상한 동작들을 보여줍니다.
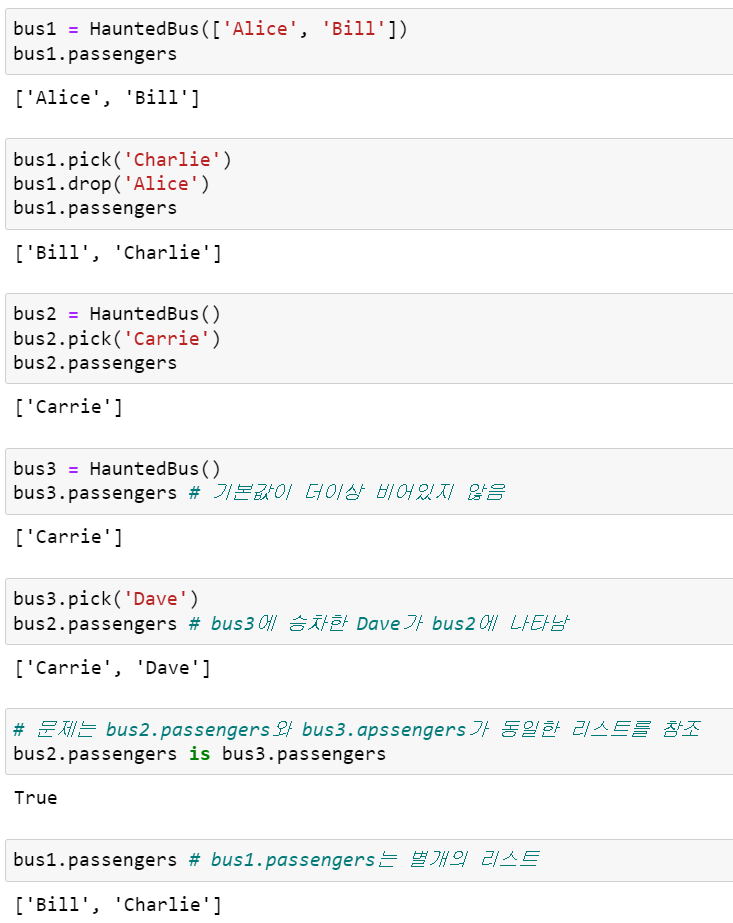
결국 명시적으로 승객 리스트를 초기화하지 않은 Bus 객체들이 승객 리스트를 공유하게 되는 문제가 발생합니다.
이런 버그를 찾아내기는 쉽지 않습니다. 앞서 본 예제 코드처럼 HauntedBus 객체를 passengers로 초기화하면 원하는 대로 동작합니다. HauntedBus 객체가 빈 리스트로 시작할 때만 문제가 발생합니다. 문제는 각 기본값이 함수가 정의될 때(즉, 일반적으로 모듈이 로딩될 때) 평가되고 기본값은 함수 객체의 속성이 된다는 것입니다. 따라서 기본값이 가변 객체고, 이 객체를 변경하면 변경 내용이 향후에 이 함수의 호출에 영향을 미칩니다.
위의 코드를 실행한 후, HauntedBus.__init__ 객체를 조사하면 다음과 같이 __default__ 속성 안에 승객이 들어 있는 것을 볼 수 있습니다.

마지막으로 다음 문장을 실행하면 bus2.passengers가 HauntedBus.__init__.__defaults__ 속성의 첫 번째 항목에 바인딩된 별명임을 확인할 수 있습니다.

가변 기본값에 대한 이러한 문제 때문에, 가변값을 받는 매개변수의 기본값으로 None을 주로 사용합니다. 처음 구현한 Bus 클래스는 passengers 인수가 None인지 확인하고 새로 만든 빈 리스트를 self.passengers에 할당합니다.
Defensive Programming with Mutable Parameters
가변 매개변수를 받는 함수를 구현할 때는 전달된 인수가 변경될 것이라는 사실을 호출자가 예상할 수 있는지 없는지 신중하게 고려해야 합니다.
예를 들어 우리가 구현하는 함수를 dict 객체를 받아서 처리하는 동안 그 dict 객체를 변경한다면, 함수가 반환된 후에도 변경 내용이 남아 있어야 할까요? 판단은 상황에 따라 다릅니다. 정말 중요한 것은 함수 구현자와 함수 호출자가 예상하는 것을 일치시키는 것입니다. 뒤에서 구현해 볼 버스 예제인 TwilightBus 클래스는 승객 리스트를 코드 호출자와 공유함으로써 어떻게 호출자가 예상하지 못한 일이 발생하는지 살펴볼 예정입니다. 클래스 구현에 앞서 클래스 사용자의 입장에서 TwilightBus 클래스가 어떻게 작동해야 하는지 살펴보겠습니다.

TwilightBus 클래스는 인터페이스 디자인에서 가장 중요한 'Principle of least astonishment'을 어깁니다. 학생이 버스에서 내린다고 해서 그 학생이 농구팀 출전 명단에서 빠진다는 것은 굉장히 놀라운 일입니다.
다음은 TwilightBus 클래스의 구현 코드이며, 문제의 원인을 알려줍니다.
class TwilightBus: def __init__(self, passengers=None): if passengers is None: self.passengers = [] else: self.passengers = passengers def pick(self, name): self.passengers.append(name) def drop(self, name): self.passengers.remove(name)
여기서 문제는 bus가 생성자에 전달된 리스트의 별명이라는 점입니다. 여기서는 TwilightBus 객체 고유의 리스트를 유지해야 합니다. 해결하는 방법은 __init__() 메소드가 passengers 인수를 받을 때 인수의 사본으로 self.passengers를 초기화하면 됩니다.
def __init__(self, passengers=None): if passengers is None: self.passengers = [] else: self.passengers = list(passengers)
이제 TwilightBus 객체 안에서 passengers 리스트를 변경해도 TwilightBus 객체를 초기화하기 위해 전달된 인수에는 아무런 영향을 미치지 않습니다. 게다가 더 flexible 해집니다. list() 생성자가 모든 iterable 객체를 받으므로, 튜플은 물론 집합이나 데이터베이스 결과 등의 iterable한 객체는 모두 passengers 매개변수에 사용될 수 있습니다. 관리할 리스트를 자체적으로 생성하므로 pick()과 drop() 메소드 안에서 사용하는 remove()와 append() 메소드 지원을 보장할 수 있습니다.
del and Garbage Collection
del 명령은 이름을 제거하는 것이지, 객체를 제거하는 것이 아닙니다. del 명령의 결과로 객체가 가비지 컬렉트도리 수 있지만, 제거된 변수가 객체를 참조하는 최소의 변수거나 객체에 접근할 수 없을 때만 가비지 컬렉트됩니다. 변수를 다시 바인딩해도 객체에 대한 참조 카운트를 0으로 만들어 객체가 제거될 수 있습니다.
__del__() 이라는 스페셜 메소드가 있긴 하지만, 객체가 제거되도록 만들지 않으며 사용자 코드에서 직접 호출하면 안됩니다. __del__()은 객체가 제거되기 직전에 외부 리소스를 해제할 기회를 주기 위해 파이썬 인터프리터가 호출합니다. 사용자 코드에서 __del__()을 구현해야 하는 경우는 거의 없습니다. __del__()은 제대로 사용하기 다소 어려습니다. 자세한 내용은 파이썬의 공식 문서 link를 참조하시기 바랍니다.
CPython의 경우 가비지 컬렉션은 주로 참조 카운트(reference count)에 기반합니다. 본질적으로 각 객체는 얼마나 많은 참조가 자신을 가리키는지 개수(refcount)를 세고 있습니다. refcount가 0이 되자마자 CPython이 객체의 __del__() 메소드를 호출하고(정의되어 있는 경우) 객체에 할당되어 있는 메모리를 해제함으로써 객체가 제거됩니다. CPython 2.0에는 순환 참조에 관련된 객체 그룹을 탐지하기 위해 'generational garbage collection algorithm'을 추가했습니다. 다른 파이썬 구현에서는 참조 카운트에 기반하지 않는 더 정교한 가비지 컬렉터를 사용하므로, 객체에 대한 참조가 모두 사라진 경우에도 __del__() 메소드가 바로 호출되지 않을 수 있습니다. __del__() 메소드의 적절한 사용과 적절하지 못한 사용에 대해서는 다음 링크를 참조하시길 바랍니다.
PyPy, Garbage Collection, And A Deadlock (emptysqua.re)
PyPy, Garbage Collection, And A Deadlock
I fixed a deadlock in PyMongo 3 and PyPy which, rarely, could happen in PyMongo 2 as well. Diagnosing the deadlock was educational and teaches us a rule about writing __del__ methods—yet another tip about what to expect when you're expiring. A Toy Exampl
emptysqua.re
객체가 소멸될 때를 보여주기 위해 다음 코드에서는 weakref.finalize()를 사용해서 객체가 소멸될 때 호출되는 콜백 함수를 등록합니다.
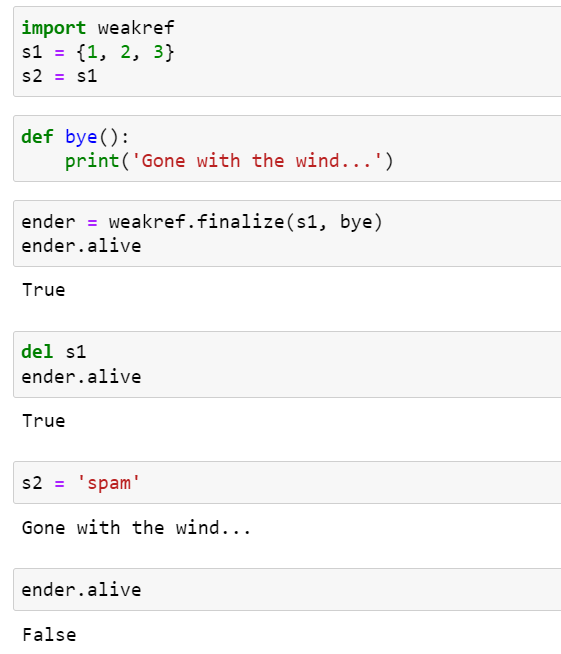
여기서 s1과 s2는 동일한 집합 {1, 2, 3}을 가리키는 별명입니다. 여기서 정의한 bye() 함수는 제거될 객체의 메소드에 바인딩되거나 제거될 객체를 참조하면 안되며, 이 함수는 s1이 가리키는 객체에 대해 콜백으로 등록합니다. finalize 객체가 호출되기 전의 alive 속성은 True 입니다.
이제 del s1을 실행하면, 앞서 설명한 대로 객체가 아닌 객체에 대한 참조를 제거합니다. 마지막 참조인 s2를 다른 객체에 바인딩하면 {1, 2, 3} 튜플에 더 이상 접근할 수 없게 됩니다. 그러면 튜플이 제거되고, bye() 콜백이 호출되고, ender.alive는 False가 됩니다.
이처럼 위 예제 코드는 del이 객체를 제거하는 것이 아니고, del을 실행한 후 객체가 도달할 수 없게 된 결과로 객체가 제거됨을 명확히 보여줍니다.
위 코드에서 {1, 2, 3} 튜플 객체가 제거된 이유가 궁금할 수 있는데, 어쨋든 s1 참조가 finalize() 함수에 전달되었고, finalize() 함수는 객체를 감시하고 콜백을 호출하기 위해 객체에 대한 참조를 갖고 있는 것이 아닐까하는 의심을 가질 수 있습니다. 이 코드가 동작하는 것은 finalize()가 {1, 2, 3} 튜플 객체에 대한 약한 참조(weak reference)를 가지고 있기 때문입니다.
Weak References
객체가 메모리에 유지되거나 유지되지 않도록 만드는 것은 참조의 존재 여부입니다. 객체 참조 카운트가 0이 되면 가비지 콜렉터는 해당 객체를 제거합니다. 그러나 불필요하게 객체를 유지시키지 않으면서 객체를 참조할 수 있으면 도움이 되는 경우가 종종 있는데, 캐시가 대표적인 예입니다.
약한 참조는 참조 카운트를 증가시키지 않고 객체를 참조합니다. 참조의 대상인 객체를 참조 대상(referent)이라고 합니다. 따라서 약한 참조는 참조 대상이 가비지 컬렉트되는 것을 방지하지 않는다고 할 수 있습니다.
약한 참조는 캐시 어플리케이션에서 유용하게 사용됩니다. 캐시가 참조하고 있다고 해서 캐시된 객체가 계속 남아 있는 것을 원치 않기 때문입니다.
아래 예제 코드는 weakref.ref 객체를 호출해서 참조 대상에 접근하는 방법을 보여줍니다. 객체가 살아 있으면 약한 참조 호출은 참조된 객체를 반환하고, 그렇지 않으면 None을 반환합니다.
import weakref a_set = {0, 1} wref = weakref.ref(a_set) print(wref) print(wref()) a_set = {2, 3, 4} print(wref()) print(wref() is None)

처음에 약한 참조 객체 wref를 생성하고 set을 할당합니다. line 5에서 wref()를 호출하면 참조된 객체 {0, 1}을 반환합니다. 그리고 line 7에서 더 이상 {0, 1} 집합을 참조하지 않으므로 참조 카운트가 줄어듭니다. 따라서 그 다음에 wref()를 호출하면 None이 반환됩니다.
weakref 모듈 문서(link)에서는 weakref 클래스는 고급 사용자를 위한 low-level 인터페이스이며, 일반적인 경우에는 weakref 컬렉션과 finalize()를 사용하느 것이 좋다고 설명합니다. 위 예제에서는 weakref.ref 객체 하나가 동작하는 방식을 보면서 약한 참조에 대한 개념을 익히기 위해서 weakref.ref 객체를 직접 만들었지만, 실제로 대부분의 파이썬 프로그램은 weakref 컬렉션을 사용합니다. 아래에서 weakref 컬렉션에 대해 간단히 살펴보겠습니다.
The WeakValueDictionary
WeakValueDictionary 클래스는 객체에 대한 약한 참조를 값으로 가지는 가변 매핑을 구현합니다. 참조된 객체가 프로그램 다른 곳에서 가비지 컬렉트되면 해당 키도 WeakValueDictionary에서 자동으로 제거됩니다. 이 클래스는 일반적으로 캐시를 구현하기 위해 사용됩니다.
아래에서 설명하는 WeakValueDictionary의 사용 예제는 몬티 파이튼의 치즈 가게(Cheese shop)에서 영감을 받은 것입니다. '치즈 가게'에서는 체다, 모차렐라 등 40여 종의 치즈를 고객이 주문하지만, 그중 어느 것도 재고가 없습니다.
아래 코드는 치즈의 종류를 나타내는 간단한 클래스를 구현합니다.
class Cheese: def __init__(self, kind): self.kind = kind def __repr__(self): return 'Cheese(%r)' % self.kind
아래 예제 코드는 catalog에 들어 있는 각종 치즈가 WeakValueDictionary로 구현되어 있는 stock 배열에 로딩됩니다. 그런데 catalog를 제거하자마자 stock에 있는 치즈가 하나만 빼고 모두 사라집니다.
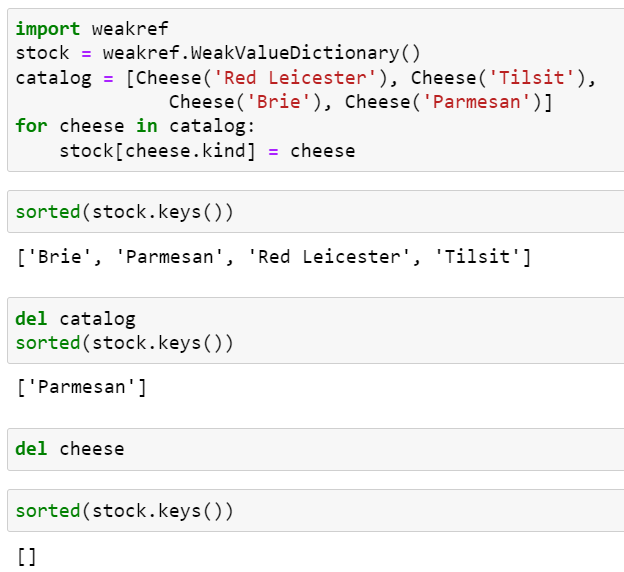
여기서 catalog를 제거한 후, 예상대로 WeakValueDictionary 객체인 stock에서 대부분의 치즈가 사라졌습니다. 그런데 Parmesan만 남아 있는 것을 확인할 수 있습니다.
이는 임시 변수가 객체를 참조함으로써 예상보다 객체의 수명이 늘어날 수 있기 때문입니다. 지역 변수는 함수가 반환되면서 사라지므로 일반적으로 문제가 되지 않습니다. 그러나 위의 예제 코드의 경우에는 for 루프 변수인 cheese는 전역 변수이므로, 명시적으로 제거하기 전에는 사라지지 않습니다.
WeakValueDictionary의 짝궁 격인 WeakKeyDictionary 클래스는 키가 약한 참조입니다.
weakref 모듈은 WeakSet 클래스도 제공합니다. 자신의 객체를 모두 알고 있는 클래스를 만들어야 한다면, 각 객체에 대한 참조를 모두 WeakSet 타입의 클래스 속성에 저장하는 것이 좋습니다. 그렇게 하지 않고 일반 집합을 사용하면 이 클래스로 생성한 모든 객체는 가비티 컬렉트되지 않을 것입니다. 클래스 자체가 객체를 강하게 참조하므로 명시적으로 제거하지 않는 한 파이썬 프로세스가 종료될 때까지 객체가 제거되지 않기 때문입니다.
Limitaions of Weak References
모든 파이썬 객체가 약한 참조의 대상이 될 수 있는 것은 아닙니다. 기본적인 list와 dict 객체는 참조 대상이 될 수 없지만, 이 클래스들의 서브클래스는 이 문제는 다음 코드처럼 쉽게 해결할 수 있습니다.
class MyList(list): """list subclass whose instances may be weakly referenced""" a_list = MyList(range(10)) # a_list can be the target of a weak reference wref_to_a_list = weakref.ref(a_list)
set 객체도 참조 대상이 될 수 있으며, 사용자 타입도 아무런 문제없이 참조 대상이 될 수 있습니다. 그러나 int 및 tuple 객체는 클래스를 상속해도 약한 참조의 대상이 될 수 없습니다.
이러한 제약사항 대부분은 CPython 구현 방식에 따른 것이므로, 다른 파이썬 구현에서는 적용되지 않을 수 있습니다. 이들은 내부 구현 최적화에 의해 발생하는 문제입니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] 데코레이터와 클로저 (0) | 2022.03.18 |
|---|---|
| [Python] 일급 함수 (Functions as First-Class Objects) (0) | 2022.03.17 |
| [Python] 텍스트와 바이트 (0) | 2022.03.15 |
| [Python] 딕셔너리와 집합 (0) | 2022.03.13 |
| [Python] 시퀀스 (Sequences) - (2) (0) | 2022.03.12 |




댓글