References
- Fluent Python
Contents
- Characters and Bytes
- bytes, bytearray, memoryview
- Codecs for full Unicode and lecacy character sets (Encoders/Decoders)
- Unicode Normalization
- Sorting Unicode
- Unicode Database
- Dual-Mode str and bytes APIs
파이썬 3부터는 인간이 사용하는 텍스트 문자열과 원시 바이트 시퀀스를 엄격히 구분하기 시작했습니다. 암묵적으로 바이트 시퀀스를 유니코드 텍스트로 변환하는 것은 과거의 것이 되었습니다. 이번 포스팅에서는 유니코드 문자열, 바이너리 시퀀스, 그리고 이 둘 간의 변환에 사용되는 인코딩에 대해서 알아보겠습니다.
파이썬 프로그래밍 환경에 따라 유니코드를 깊게 이해하는 것이 중요할 수도 있고 아닐 수도 있는데, 여기서 언급하는 문제는 아스키 텍스트만 사용한다면 아무런 영향을 미치지 않습니다. 하지만, 아스키 텍스트만 사용하는 경우에도 문자열과 바이트는 구분해야 합니다.
Character Issues
문자열(string)이라는 개념은 아주 간단합니다. 문자열은 문자의 열(sequence of characters) 입니다. 하지만 문제는 '문자'의 정의에 있습니다.
현재 '문자'를 가장 잘 정의한 것은 유니코드 문자입니다. 이에 따라 파이썬3의 str에서 가져오는 항목도 유니코드 문자입니다. 파이썬 2의 unicode 객체에서 가져오는 항목들은 유니코드지만, 파이썬 2의 str에서 가져오는 low-level 바이트는 유니코드가 아닙니다.
유니코드 표준은 문자의 단위 원소와 특정 바이트 표현을 명확히 구분합니다.
- 문자의 identity(= code point)는 0에서 1,114,111까지의 숫자이며, 유니코드 표준에서는 'U+' 접두사를 붙여 4자리에서 6자리 사이의 16진수로 표현합니다. 예를 들어 A라는 문자는 코드 포인터 U+0041, 유료화 기호는 U+20AC에 할당되어 있습니다.
- 문자를 표현하는 실제 바이트는 사용하는 인코딩에 따라 달라집니다. 인코딩은 코드 포인트를 바이트 시퀀스로 변환하는 알고리즘입니다. 문자 A(U+0041)에 대한 코드 포인트는 UTF-8 인코딩에서는 1바이트 \x41로, UTF-16LE 인코딩에서는 2바이트 \x41\x00으로 인코딩됩니다.
여기서 코드 포인트에서 바이트로 변환하는 것을 인코딩(encoding), 바이트를 코드 포인트로 변환하는 것을 디코딩(decoding)이라고 합니다.

s = 'café'
위의 예제 코드는 s에 4개의 유니코드 문자로 문자열을 저장하고, UTF-8 인코딩을 이용해 str을 bytes로 인코딩하고 디코딩하는 것을 보여주고 있습니다.
Byte Essentials
이렇게 새로 도입된 바이너리 시퀀스 타입은 파이썬 2의 str과 여러모로 다릅니다. 우선 바이너리 시퀀스를 위해 사용되는 내장 자료형은 bytes와 bytearray, 두 가지가 있습니다. bytes 타입은 파이썬 3에서 소개된 불변형이고, bytearray는 파이썬 2.6에서 추가된 가변형입니다. (파이썬 2.6에서도 bytes 타입을 소개했었지만, 이때는 str 타입의 앨리어스일 뿐, 파이썬 3의 bytes 타입과는 동작 방식이 다릅니다.)
bytes와 bytearray에 들어 있는 각 항목은 0에서 255사이의 정수로, 파이썬 2의 str에 들어있는 문자 하나로 구성된 문자열과는 다릅니다. 그러나 바이너리 시퀀스를 슬라이싱하면 언제나 동일한 타입의 바이너리 시퀀스가 만들어지며, 슬라이스 길이가 1일 때도 마찬가지 입니다.
다음의 코드를 살펴보겠습니다.

위에서 보듯이 bytes는 str에 인코딩을 지정해서 만들 수 있습니다. bytes의 각 항목은 range(256)에 속하는 정수이며, bytes는 슬라이싱해도 bytes인데, 이는 슬라이스가 한 바이트일 때도 마찬가지입니다.
bytesarray에 대한 리터럴 구문은 없고, bytes 리터럴을 인수로 사용해서 bytearray()로 표현합니다.
cafe[0]은 int 타입을 반환하지만, cafe[:1]은 길이가 1인 bytes 객체를 반환합니다. s[0] == s[:1]이 되는 시퀀스 타입은 str이 유일합니다. 실용적이긴 하지만 str의 이런 동작 방식은 예외적인 것입니다. 그 외 모든 시퀀스의 경우, s[i]는 항목 하나를, s[i:i+1]은 내부에 s[i] 항목을 가진 동일한 타입을 가진 시퀀스를 반환합니다.
바이너리 시퀀스가 실제로 정수 타입의 시퀀스이기는 하지만, 리터럴 표기법을 보면 실제로는 아스키 텍스트가 들어가는 경우가 많다는 것을 알 수 있습니다. 따라서 각 바이트 값에 따라 다음과 같이 세 가지 형태로 출력이 가능합니다.
- 화면에 출력 가능한 아스키 문자
- 탭, 개행 문자, 캐리지 리턴(carriage return), 백슬래시(\)는 이스케이프 시퀀스(\t, \n, \r, \\)로 출력
- 그 외의 값을 널 바이트를 나타내는 \x00처럼 16진수 이스케이프 시퀀스로 출력
그렇기 때문에, 위 코드의 첫 번째 줄에서 b'caf\xc3\xa9'로 출력합니다. 처음 3바이트 b'caf'는 출력 가능한 아스키 범위에 있지만, 나머지 2바이트는 범위에 속하지 않기 때문입니다.
bytes와 bytearray는 포매팅하는 format(), format_map() 메소드를 제외하고는 str이 제공하는 메소드를 모두 지원하며, casefold(), isdecimal(), isidentifier(), isnumeric(), isprintable(), encode() 등 유니코드 데이터에 관련된 메소드를 지원합니다. 따라서, endswith(), replace(), strip(), translate(), upper() 등의 메소드를 str이 아닌 bytes에도 적용할 수 있습니다. 게다가 str 대신 바이너리 시퀀스로 정규표현식을 컴파일하면 re모듈에서 제공하는 정규표현식 함수를 바이너리 시퀀스에도 적용할 수 있습니다. 파이썬 3.0부터 3.4까지는 바이너리 시퀀스에 퍼센트(%) 연산자를 사용할 수 없지만, PEP 461에 따라 파이썬 3.5에서는 퍼센터 연산자도 지원합니다.
바이너리 시퀀스는 fromhex()라는 str에 없는 클래스 메소드도 제공하는데, 이 메소드를 이용하면 공백으로 구분된 16진수 쌍을 파싱해서 바이너리 시퀀스를 만들 수 있습니다.

그리고, 생성자에 다음과 같은 인수를 사용해서 bytes나 bytearray 객체를 생성할 수 있습니다.
- str과 encoding 키워드 인수
- 0에서 255 사이의 값을 제공하는 iterable
- bytes, bytearray, memoryview, array.array 등 버퍼 프로토콜을 구현하는 객체. 이 메소드를 사용하면 원본 객체의 바이트를 복사해서 바이트 시퀀스를 새로 생성함
버퍼 등의 객체로부터 바이너리 시퀀스를 생성하는 방법은 low-level 연산으로서, 형변환이 필요할 수도 있습니다. 다음 예제 코드를 살펴보겠습니다.
import array
numbers = array.array('h', [-2, -1, 0, 1, 2])
octets = bytes(numbers)
octets
여기서 'h' 타입코드는 short int(16비트) 타입의 배열을 생성합니다. octets은 numbers를 구성하는 바이트들의 사본을 가지고 있으며 octets은 다섯 개의 short int 타입을 나타내는 10바이트입니다.
버퍼와 같은 객체로부터 bytes나 bytearray 객체를 생성하면 언제나 바이트를 복사합니다. 이와 반대로 memoryview는 바이너리 데이터 구조체 간에 메모리를 공유할 수 있도록 해줍니다. 바이너리 시퀀스에서 구조화된 정보를 추출하려면 struct 모듈을 사용하는데, 아래에서 사용법을 살펴보겠습니다.
Basic Encoders/Decoders
텍스트를 바이트 혹은 바이트를 텍스트로 변환하기 위해 파이썬에는 100여 개의 코덱(인코더/디코더)이 포함되어 있습니다. 각 코덱은 utf_8과 같은 이름을 갖고 있는데, utf8, utf-8, U8 등으로 불리기도 합니다. 코덱은 open(), str.encode(), bytes,decode() 등의 함수를 호출할 때 encoding 인수에 전달해서 사용할 수 있습니다. 다음 코드는 하나의 텍스트를 세 개의 서로 다른 바이트 시퀀스로 인코딩한 결과를 보여줍니다.
for codec in ['latin_1', 'utf_8', 'utf_16']:
print(codec, 'El Niño'.encode(codec), sep='\t')
아래 그림은 7개의 코덱을 이용해서 A 문자부터 높은음자리표까지 여러 문자의 바이트 배열을 생성한 결과를 보여줍니다. 마지막 3개의 인코딩은 가변 길이, 다중바이트(multibyte) 인코딩입니다.

위 그림에서 별표는 ASCII나 GB2312 같은 multibytes 인코딩도 유니코드 문자를 모두 표현할 수 없다는 것을 보여줍니다. 그러나 UTF 인코딩은 모든 유니코드 코드 포인터를 처리할 수 있도록 만들어졌습니다.
위 그림에서 보여준 인코딩은 대표적인 인코딩 방식이며, 간단하게 설명하면 다음과 같습니다.
- latin1(iso8859_1)
cp1252와 같은 다른 인코딩 방식과 유니코드 자체의 기반이 되는 중요한 인코딩 방식입니다. (latin1 바이트 값은 cp1252 및 코드 포인트에도 그대로 나타납니다) - cp1252
마이크로소프트에서 둥근 따옴표 및 유로화 기호(€) 등을 추가해서 latin1을 확장한 것입니다. ANSI라고 부르는 윈도우 어플리케이션도 있지만, 실제 ANSI 표준은 아닙니다. - cp437
상자를 그리기 위한 문자를 포함해서 원래 IBM PC에서 사용하는 문자셋입니다. 나중에 등장한 latin1과 호환되지 않습니다. - gb2312
중국 본토에서 사용하는 간체를 인코딩하기 위한 레거시 표준입니다. - utf-8
웹에서 8비트 인코딩을 하기 위해 가장 널리 사용되는 인코딩 방식으로, 아스키 코드와 하위 호환 됩니다. - utf-16le
16비트 인코딩 체계인 UTF-16의 한 형태입니다. 모든 UTF-16 인코딩은 surrogate paris라 불리는 이스케이프 시퀀스를 통해 U+FFFF 이후의 코드 포인트도 지원합니다.
Understading Encode/Decode Problems
UnicodeError라는 범용 예외가 있지만, 거의 항상 UnicodeEncodeError(str을 바이너리 시퀀스로 변환할 때)나 UnicodeDecodeError(바이너리 시퀀스를 str로 읽어 들일 때) 같은 구체적인 예외가 발생합니다. 파이썬 모듈을 로딩할 때 소스 코드가 예기치 않은 방식으로 인코딩되어 있으면 Syntax Error가 발생하기도 합니다. 이러한 에러들을 처리하는 방법에 대해서 살펴보겠습니다.
UnicodeEncodeError
대부분의 non-UTF 코덱은 유니코드 문자의 일부만 처리할 수 있습니다. 텍스트를 바이트로 변환할 때 문자가 대상 인코딩에 정의되어 있지 않으면, 인코딩 메소드나 함수의 errors 인수에 별도의 처리기를 지정하지 않는 한 UnicodeEncodeError가 발생합니다. 에러 처리기를 사용하는 방법은 다음과 같습니다.
city = 'São Paulo'

UnicodeDecodeError
모든 바이트가 유효한 아스키 문자가 될 수 없으며, 모든 바이트 시퀀스가 유효한 UTF-8이나 UTF-16 문자가 되는 것은 아닙니다. 따라서 바이너리 시퀀스를 텍스트로 변환할 때 유효한 문자로 변환할 수 없으면 UnicodeDecodeError가 발생합니다.
하지만, 'cp1252', 'iso8859_1', 'koi8_4' 등 많인 레거시 8비트 코덱은 무작위 비트 배열에 대해서도 에러를 발생시키지 않고 바이트 스트림으로 디코딩할 수 있습니다. 따라서 프로그램이 잘못된 8비트 코덱을 사용하면 쓰레기 문자를 디코딩하게 됩니다.
다음 예제 코드는 잘못된 코덱을 사용해서 문자가 깨지거나 UnicodeDecodeError가 발생하는 예를 보여줍니다.

SyntaxError When Loading Modules with Unexpected Encoding
파이썬 2.5부터는 아스키를, 파이썬 3부터는 UTF-8을 소스 코드 기본 인코딩 방식으로 사용했습니다. 파이썬3에서 인코딩 선언없이 non-UTF-8로 인코딩된 .py 모듈을 로딩하면 다음과 같은 에러 메세지가 발생합니다.

GNU/리눅스 및 OS X 시스템에서는 UTF-8이 널리 사용되고 있으므로, 위에서 에러를 발생시킨 모듈은 cp1252를 사용하는 윈도우 시스템에서 작성되었을 지도 모릅니다. 파이썬 3은 기본적으로 모든 플랫폼에서 UTF-8 인코딩을 사용하므로, 윈도우용 파이썬에서도 실행해도 이 에러는 발생합니다.
이 문제는 다음과 같이 파일의 top 위치에 encoding 주석을 달아서 해결할 수 있습니다.
# coding: cp1252
print('Olá, Mundo!')파이썬 3의 소스 코드는 더 이상 아스키 문자에 구애받지 않고 UTF-8 인코딩을 기본적으로 사용하고 있으므로, cp1252와 같은 레거시 코덱으로 인코딩된 소스 코드는 UTF-8로 변환하는 것이 좋으며 굳이 coding 주석을 사용할 필요가 없습니다.
How to Discover the Encoding of a Byte Sequence
바이트 시퀀스의 인코딩 방식을 알아낼 수 있을까요 ? 간단히 말하면, 불가능하며 반드시 별도로 인코딩 정보를 가져와야 합니다.
HTTP나 XML과 같은 통신 프로토콜이나 파일 포맷은 내용이 어떻게 인코딩되어 있는지 명시하는 헤더를 가지고 있습니다. 바이트 스트림에 127이 넘는 값이 들어 있다면 아스키로 인코딩되어 있지 않음을 확신할 수 있고, UTF-8과 UTF-16 인코딩에서도 생성할 수 있는 바이트 시퀀스가 한정되어 있습니다. 그럼에도, 특정 비트 패턴이 나타나지 않는다고 해서 바이너리 파일이 아시크로 인코딩되어 있는지 아니면 UTF-8로 인코딩되어 있는지 100% 확신할 수는 없습니다.
그렇지만 일단 바이트 스트림이 자연어(human language)라고 간주되면, 자연어에도 어떠한 규칙과 제한이 있다는 점을 고려하면 경험과 통계를 이용해서 인코딩 방식을 추정할 수 있습니다. 예를 들어, b'\x00' 바이트가 많이 나타난다면, 이 파일은 8비트가 아니라 16이나 32비트로 인코딩되어 있을 가능성이 큽니다. 일반적으로 자연어 중간에는 널 문자가 들어가지 않기 때문입니다. 그리고 b'\x20\x00' 바이트 시퀀스가 자주 나타난다면, 이 문자는 잘 사용되지 않는 U+2000(ENQUAD 문자)이라기 보다는 UTF-16LE 인코딩에서의 공백문자(U+0020)일 가능성이 큽니다.
다양한 문자 인코딩을 탐지하는 Chardet 패키지는 이러한 방법을 이용해서 30가지 인코딩 방식을 알아냅니다. Chardet은 프로그램에서 사용할 수 있는 파이썬 라이브러리일 뿐만 아니라 chardetect라는 명령행 유틸리리도 포함하고 있습니다.
BOM: A Useful Gremlin
u16 = 'El Niño'.encode('utf_16')UTF-16으로 인코딩된 'El Niño'의 텍스트 앞에 여분의 바이트가 있다는 것을 확인할 수 있습니다.

출력된 텍스트를 보면 b'\xff\xfe' 문자가 앞에 나온 것을 볼 수 있습니다. 이 문자가 바로 바이트 순서 표시(BOM)로, 인코딩한 인텔 CPU의 '리틀엔디언(little endian') 바이트 순서를 나타냅니다.
리틀엔디언 컴퓨터에서는 코드 포인트의 최하위 바이트가 먼저 나옵니다. 코드 포인트가 U+0045(69D)인 'E' 문자는 다음과 같이 바이트 오프셋 2와 3에 69와 0으로 인코딩되었습니다.

빅엔디언 컴퓨터에서는 인코딩 순서가 반대로 되어 'E' 문자는 0과 69로 인코딩됩니다.
바이트 순서로 인한 혼란을 방지하기 위해 UTF-16 인코딩은 ZERO WIDTH NO-BREAK SPACE(U+FEFF)라는 특수 문자를 인코딩된 텍스트 앞에 붙이는데, 이 문자는 화면에 출력되지 않습니다. 리틀엔디언 컴퓨터에서 이 문자는 b'\ff\xfe'로 인코딩됩니다. UTF-16에 U+FFFE에 해당하는 문자는 없으므로 바이트 시퀀스 b'\xff\xfe'는 리틀엔디언으로 인코딩된 ZERO WIDTH NO-BREAK SPACE 문자를 나타내며, 코덱은 어떤 바이트 순서를 사용해야 할지 알 수 있습니다.
UTF-16에는 리틀엔디언을 명시하는 UTF-16LE와 빅엔디언을 명시하는 UTF-16BE 변형이 있습니다. 다음 예제 코드에서 볼 수 있는 것처럼 이들, 변형 인코딩을 사용하면 BOM을 생성하지 않습니다.

BOM이 존재하는 경우 UTF-16 코덱에 의해 걸러지므로, 텍스트로 변환한 후에는 앞에 추가된 ZERO WIDTH NO-BREAK SPACE 문자 없이 파일의 실제 내용만을 가져옵니다. 표준에 의하면 UTF-16 파일에 BOM이 없다면 이 파일은 UTF-16BE(빅엔디언)로 인코딩되어 있다고 가정해야 합니다. 그렇지만 인텔 x86 아키텍처가 리틀엔디언이므로, 실제로는 BOM이 없지만 UTF-16LE로 인코딩된 파일도 많습니다.
엔디언 문제는 한 바이트 이상을 word로 사용하는 UTF-16과 UTF-32에만 영향을 미칩니다. UTF-8은 컴퓨터의 엔디언 특성에 상관없이 동일한 바이트 시퀀스를 생성하므로 BOM이 필요없다는 장점이 있습니다. 그렇지만 윈도우 어플리케이션(특히 노트패드)은 UTF-8로 인코딩하면서 파일에 BOM을 붙입니다.
Handling Text Files
텍스트를 처리하는 최고의 방법은 '유니코드 샌드위치' 입니다.

이는 입력할 때(파일을 읽기 위해 열 때) 가능하면 빨리 bytes를 str로 변환해야 한다는 것을 의미합니다. 샌드위치에 들어가는 패티는 프로그램의 비즈니스 로직에 해당하는 부분이며, 여기서는 텍스트를 오직 str 객체로 다룹니다. 즉, 다른 처리를 하는 도중에 인코딩이나 디코딩을 하면 안됩니다. 출력할 때는 가능한 늦게 str을 bytes로 인코딩합니다. 대부분의 웹 프레임워크도 이렇게 작동하며, 처리하는 동안 bytes를 다루는 일은 거의 없습니다. Django의 경우 뷰는 유니코드 str만 출력하고, Django 자체가 응답을 bytes(기본적으로 UTF-8 인코딩)로 인코딩하는 일을 담당합니다.
파이썬 3은 유니코드 샌드위치 모델을 따르기 쉽게 해줍니다. 내장된 open() 함수는 파일을 텍스트 모드로 읽고 쓸 때 필요한 모든 인코딩과 디코딩 작업을 수행해주므로 my_file.read()에서 str 객체를 가져와서 처리하고 my_file.write()에 전달하면 됩니다.
따라서 텍스트 파일을 사용하는 일은 간단합니다. 그렇지만 기본 인코딩에 의존하다보면 뜻하지 않은 문제들을 마주할 수 있습니다.
아래의 콘솔 세션을 살펴보겠습니다. 여기서 실행하는 컴퓨터에 따라 문제가 발생할 수도 있고 아닐 수도 있습니다.

버그는 인코딩 지정 때문에 발생했습니다. 파일에 쓸 때는 UTF-8로 지정했지만, 파일을 읽을 때는 지정하지 않았습니다. 따라서 파이썬은 시스템 기본 인코딩을 이용해서 파일을 읽게 되고, 마지막 문자를 이상하게 디코딩한 것입니다.
위의 코드를 윈도우에서 실행했을 때 이와 같은 문제가 발생했습니다. 기본 인코딩으로 UTF-8을 사용하는 GNU/리눅스나 MAC OS X에서 이 코드를 실행하면 아무런 문제없이 작동하므로, 코드에 문제가 없다고 생각하기 쉽습니다. 파일을 쓸 때 encoding 인수를 생략하면 기본 지역 설정에 따른 인코딩 방식을 사용하며, 파일을 읽을 때도 동일한 인코딩 방식을 사용합니다. 하지만 플랫폼에 따라, 혹은 플랫폼이 동일해도 지역 설정에 따라 다른 바이트를 담은 파일을 생성하게 되어 호환성 문제를 일으킵니다.
다음 예제를 통해 위에서 살펴본 문제를 확장하여 조금 더 살펴보겠습니다.
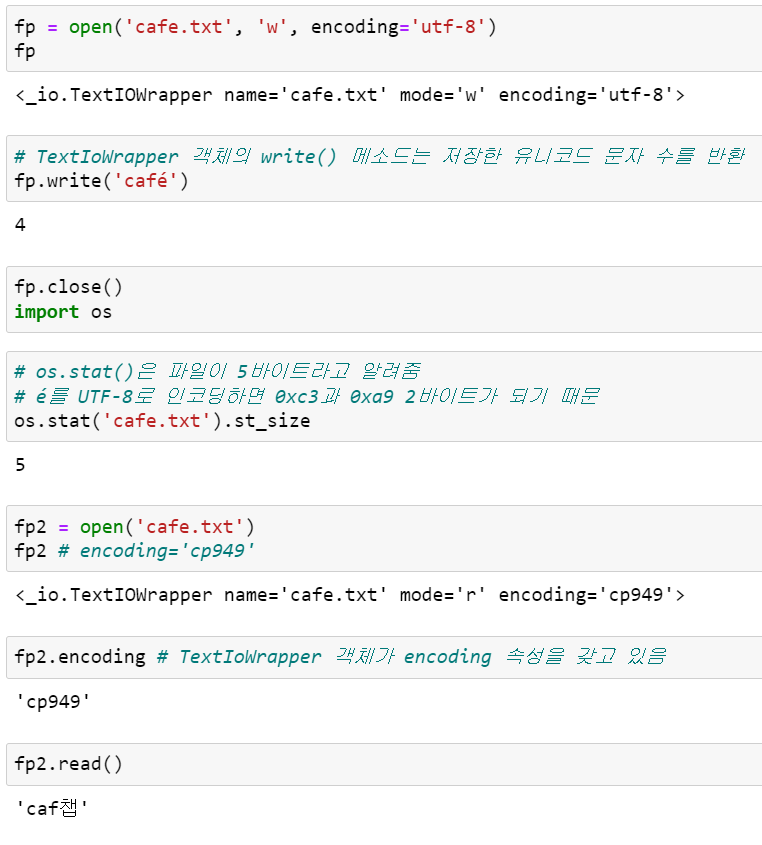
기본 인코딩이 cp949이기 때문에 encoding을 지정하지 않으면 cp949 인코딩으로 파일을 읽습니다. 따라서 'caf챕'으로 출력하는 것을 볼 수 있습니다.
이 파일을 UTF-8 인코딩으로 읽으면 예상한 대로 동일한 4개의 유니코드 문자가 나오게 됩니다.

fp4는 'rb' 플래그를 지정해주었는데, 이는 파일을 바이너리 모드로 읽도록 합니다. 이때 반환되는 객체는 TextIOWrapper가 아니라 BufferedReader 객체 입니다. 이 객체를 읽으면 bytes가 반환됩니다.
Encoding Defaults: A Madhouse
파이썬에서 입출력할 때 기본 인코딩 방식은 여러 설정에 의해 영향을 받습니다.
다음 코드를 살펴보겠습니다.
import locale
import sys
expressions = """
locale.getpreferredencoding()
type(my_file)
my_file.encoding
sys.stdout.isatty()
sys.stdout.encoding
sys.stdin.isatty()
sys.stdin.encoding
sys.stderr.isatty()
sys.stderr.encoding
sys.getdefaultencoding()
sys.getfilesystemencoding()
"""
my_file = open('dummy', 'w')
for expression in expressions.split():
value = eval(expression)
print(f'{expression:>30} -> {value!r}')제 PC에서 위 코드를 콘솔에서 실행하면 다음의 출력이 확인됩니다.

여기서 locale.getpreferredencoding()이 가장 중요한 설정인데, 텍스트 파일은 기본적으로 locale.getpreferredencoding()을 사용합니다. 그리고 stdout.encoding은 utf-8로 설정되어 있는 것을 확인할 수 있습니다.
이 파일을 파일로 redirection하도록 실행하면 결과가 달라지는데, 파일에는 다음의 내용이 저장되어 있습니다.
'$ python test.py > encodings.log'

sys.stdout.isatty()는 False가 되고, sys.stdout.encoding은 locale.getpreferredencoding()에 의해 'cp949'로 설정되었습니다.
이 예제에서는 4가지 인코딩을 볼 수 있습니다.
- 파일을 열 때 encoding 인수를 생략하면 locale.getpreferredencoding()에 의해 기본 인코딩 방식이 설정됩니다.
- PYTHONIOENCODING 환경 변수가 설정되어 있다면, 이 변수에 의해 sys의 stdout/stdin/stderr가 설정됩니다. 그렇지 않으면 콘솔의 설정을 가져오거나, 입출력을 파일에서 또는 파일로 리다이렉션하는 경우 locale.getpreferredencoding()에 의해 정의됩니다.
- 바이너리 데이터와 str 간의 변환을 위해 파이썬은 내부적으로 sys.getdefaultencoding() 함수를 사용합니다. 파이썬 3에서는 드물게 사용되지만, 여전히 사용되며 이 설정을 변경하는 것은 지원되지 않습니다.
- sysgetfilesystemencoding() 함수는 파일 내용이 아니라 파일명을 인코딩 및 디코딩하기 위해 사용됩니다. 이 함수는 open()이 str 타입의 파일명을 인수로 받을 때 사용됩니다. 파일명이 bytes 인수로 전달되면 인수를 변경하지 않고 그대로 OS의 API로 전달합니다.
요약하자면, 가장 중요한 인코딩 설정은 locale.getpreferredencoding() 함수가 반환하는 설정입니다. 이 함수는 텍스트 파일을 열 때 기본적으로 사용되며, 표준 입출력(sys.stdout/stdin/stderr)을 리다이렉션할 때도 사용됩니다. 그렇지만 파이썬 공식 문서에서는 다음과 같이 설명하고 있습니다.
locale.getpreferredencoding(do_setlocale=True)
사용자 환경 설정에 따라 텍스트 데이터에 사용되는 인코딩을 반환한다. 사용자 환경 설정은 시스템마다 다르게 표현되며, 프로그램 코드를 통해 구할 수 없는 시스템도 있고 이 함수가 반환하는 값은 추정치일 뿐이다.
따라서 기본 인코딩에 의존하지 않는 것이 가장 좋습니다.
Normalizing Unicode for Saner Comparisons
유니코드에는 결합 문자가 있기 때문에 문자열 비교가 간단하지 않습니다. 앞 문자에 연결되는 발음 구별 기호(diacritical mark)는 출력할 때 앞 문자와 하나로 결합되어 출력됩니다.
예를 들어, café라는 단어는 4개나 5개의 코드 포인트를 이용해서 두 가지 방식으로 표현할 수 있지만, 결과는 동일합니다.

코드 포인트 U+0301은 COMBINING ACUTE ACCENT입니다. 'e' 다음에 이 문자가 오면 'é'를 만듭니다. 유니코드 표준에서는 'é'와 'e\u0301', 이 두 개의 시퀀스를 규범적으로 동일하다(canonical equivalents)라고 하며, 어플리케이션은 이 두 시퀀스를 동일하게 처리해야 합니다. 그렇지만 파이썬은 서로 다른 두 개의 코드 포인트 시퀀스를 보고, 이 둘이 서로 동일하지 않다고 판단합니다.
이 문제를 해결하려면 unicodedata.normalize() 함수가 제공하는 유니코드 정규화를 이용해야 합니다. 이 함수의 첫 번째 인수는 'NFC', 'NFD', 'NFKC', 'NFKD' 중 하나이어야 하는데, 먼저 NFC와 NFD를 알아보겠습니다.
Normalization Form C (NFC)는 코드 포인트를 조합해서 가장 짧은 동일 문자열을 생성하는 반면, NFD는 조합된 문자를 기본 문자와 별도의 결합 문자로 분리합니다. 이 두 방식 모두 문자열을 제대로 비교할 수 있도록 해줍니다.

키보드는 일반적으로 결합된 문자를 입력할 수 있으므로, 사용자가 입력하는 텍스트는 기본적으로 NFC 형태입니다. 그러나 안전을 보장하기 위해 파일에 저장하기 전에 normalize('NFC', user_text) 코드로 문자열을 정리해주는 것이 좋습니다.
NFC에 의해 다른 문자 하나로 정규화되는 문자도 있습니다. 전지 저항을 나타내는 옴(Ω) 기호는 그리스어 대문자 오메가로 정규화됩니다. 겉모습은 똑같지만 다르다고 판단되므로 정규화해서 뜻하지 않은 문제를 예방해야 합니다.

나머지 두 가지 정규화 방식 NFKC와 NFKD에서 K는 호환성(compatibility)을 나타냅니다. 이것은 정규화의 더 강력한 형태로서, 소위 말하는 '호환성 문자'에 영향을 미칩니다. 하나의 문자에 대해 하나의 '규범적인' 코드를 가지는 게 유니코드의 목표 중 하나였지만, 기존 표준과의 호환성을 위해 두 번 이상 나타나는 문자도 있습니다. 예를 들어, 마이크로 기호 'µ' (U+00B5)는 코드 포인트 U+03BC (GREEK SMALL LETTER MU)와 같은 문자지만, latin1과의 상호 변환을 지원하기 위해 유니코드에 추가되었습니다. 따라서 마이크로 기호를 '호환성 문자(compatibility character)'라고 할 수 있습니다.
NFKC와 NFKD 방식에서 각 호환성 문자는 포맷팅 손실(formatting loss)가 발생하더라도 '선호하는' 형태의 하나 이상의 문자로 구성된 '호환성 분할(compatibility decomposition)'로 치환됩니다. 이상적으로 포맷팅은 외부 표시의 책임이며, 유니코드의 책임은 아닙니다. 예르 들어, 절반을 나타내는 '½' (U+00BD) 문자의 호환성 분할은 3개의 문자의 시퀀스인 '1/2'로, 마이크로 기호 'µ' (U+00B5)의 호환성 분할은 소문자 뮤인 'μ' (U+03BC)로 치환됩니다.
NFKC를 사용하는 예는 다음과 같습니다.

Case Folding
본질적으로 케이스 폴딩(Case Folding)은 모든 텍스트를 소문자로 변환하는 연산이며, 약간의 변환을 동반합니다. 케이스 폴딩은 파이썬 3.3에 추가된 str.casefold() 메소드를 이용해서 수행합니다.
latin1 문자만 담고 있는 문자열 s의 경우 s.casefold()와 s.lower()를 실행한 결과가 동일합니다. 다만 마이크로 기호 'µ'는 그리스어 소문자 뮤(대부분 폰트에서 동일하게 보임)로 변환하고, 영어에서 'sharp s'(ß)라고 부르는 독일어 에스체트는 'ss'로 변환합니다.

str.casefold()와 str.lower()이 서로 다른 문자를 반환하는 코드 포인트는 거의 300개가 넘습니다.
유니코드와 관련된 대부분의 문제와 마찬가지로 케이스 폴딩은 수많은 언어학적 특별 케이스를 다루는 복잡한 문제지만, 파이썬 코어 팀은 대부분의 사용자가 만족할 만한 해결책을 제시하기 위해 노력하고 있습니다.
Utility Functions for Normalized Text Matching
지금까지 살펴본 것처럼 NFC와 NFD는 안전하며 유니코드 문자열을 적절히 비교할 수 있게 해줍니다. NFC는 대부분의 어플리케이션에서 사용할 수 있는 최고의 정규화된 형태이며, str.casefold()는 대소문자 구분없이 문자를 비교할 때 가장 좋은 방법입니다.
다양한 언어로 구성된 텍스트를 사용하는 경우, 아래처럼 구현하는 nfc_equal()과 fold_equal() 메소드를 사용하는 것이 좋습니다.
from unicodedata import normalize
def nfc_equal(str1, str2):
return normalize('NFC', str1) == normalize('NFC', str2)
def fold_equal(str1, str2):
return (normalize('NFC', str1).casefold() ==
normalize('NFC', str2).casefold())위 함수들은 다음과 같이 사용될 수 있습니다.

Extream "Normalization": Taking Out Diacritics
구글 검색에서는 많은 기법이 사용되지만, 그중 문맥에 따라 악센트나 갈고리형 기호 등의 발음 구별 기호를 무시하는 방법도 있습니다. 발음 구별 기호를 제거하는 방법은 단어의 뜻을 변경하기도 하며 검색시 오탐이 발생할 수 있으므로 적절한 정규화 방식은 아닙니다. 그렇지만 발ㅇ므 구별 기호를 무시하거나 정확히 사용하지 못하는 경우가 종종 있으며 철자법 규칙이 시대에 따라 변하기도 하므로, 실제 사용되는 언어에서 악센트 용법은 생겼다가 사라지기도 합니다. 따라서 악센트에 너무 연연할 필요는 없습니다.
검색하는 경우 외에도 발음 구별 기호를 제거하면, 특히 라틴어의 경우 URL이 읽기 좋아집니다.
다음의 위키피디아 문서의 URL을 살펴보겠습니다.
http://en.wikipedia.org/wiki/S%C3%A3o_Paulo
%C3%A3 부분은 URL 이스케이프 처리한 부분으로, 물결표가 있는 'a'인 'ã'를 UTF-8로 표현한 것입니다. 다음은 철자가 올바르지는 않지만 훨씬 더 읽기 좋습니다.
http://en.wikipedia.org/wiki/Sao_Paulo
어떤 문자열에서 발음 구별 기호를 모두 제거하려면 아래와 같은 함수를 구현해서 사용하면 됩니다.
import unicodedata
import string
def shave_marks(txt):
"""Remove all diacritic marks"""
# 모든 문자를 기본 문자와 결합 표시로 분해
norm_txt = unicodedata.normalize('NFD', txt)
# 결합 표시를 모두 걸러냄
shaved = ''.join(c for c in norm_txt
if not unicodedata.combining(c))
# 모든 문자를 재결합시켜 반환
return unicodedata.normalize('NFC', shaved)
다음은 shave_marks() 함수를 사용하는 방법을 보여줍니다.

위 코드에서 shave_marks() 함수는 제대로 동작하긴 합니다. 다만 흔히 발음 구별 기호를 제거하는 것은 라틴 텍스트를 순수한 아스키코드로 변환하기 위한 것인데, shave_marks() 함수는 단지 악센트만을 제거해서 아스키 문자로 만들 수 없는 그리수 문자도 변경합니다. 따라서 아래와 같이 모든 기반 문자를 분석해서 기반 문자가 라틴 알파벳인 경우에만 연결된 발음 구별 기호를 제거하는 방법이 더 좋습니다.
def shave_marks_latin(txt):
"""Remove all diacritic marks from Latin base characters"""
# 모든 문자를 기본 문자와 결합 표시로 분해
norm_txt = unicodedata.normalize('NFD', txt)
latin_base = False
keepers = []
for c in norm_txt:
# 라틴 문자인 경우 결합 표시 기호를 건너뜀
if unicodedata.combining(c) and latin_base:
continue
keepers.append(c)
# 결합 문자가 아니면, 이 문자를 새로운 기반 문자로 간주
if not unicodedata.combining(c):
latin_base = c in string.ascii_letters
shaved = ''.join(keepers)
return unicodedata.normalize('NFC', shaved)
원형 따옴표, em dashes, 작은 점 등 서양 텍스트에서 널리 사용되는 기호들을 아스키에 해당하는 문자로 바꾸는 훨씬 더 극단적인 방법도 있습니다. 아래의 asciize() 함수는 이와 같이 극단적으로 텍스트를 변환합니다.
single_map = str.maketrans("""‚ƒ„†ˆ‹‘’“”•–—˜›""",
"""'f"*^<''""---~>""")
multi_map = str.maketrans({
'€': '<euro>',
'…': '...',
'Œ': 'OE',
'™': '(TM)',
'œ': 'oe',
'‰': '<per mille>',
'‡': '**',
})
multi_map.update(single_map)
def dewinize(txt):
"""Replace Win1252 symbols with ASCII chars or sequences"""
return txt.translate(multi_map)
def asciize(txt):
no_marks = shave_marks_latin(dewinize(txt))
no_marks = no_marks.replace('ß', 'ss')
return unicodedata.normalize('NFKC', no_marks)다음 코드는 asciize()를 사용하는 방법을 보여줍니다.

Sorting Unicode Text
파이썬은 각 시퀀스 안에 들어 있는 항목들을 하나하나 비교함으로써 어떠한 자료형의 시퀀스도 정렬할 수 있습니다. 문자열의 경우에는 각 단어의 코드 포인트를 비교합니다. 하지만 이런 방식은 non-ASCII 문자를 사용하는 경우 부적절한 결과가 발생할 수 있습니다.
아래는 브라질 과일 목록을 정렬하는 예제 코드입니다.
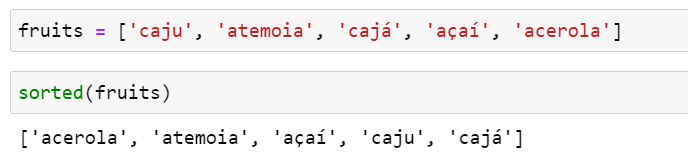
정렬 규칙은 현지 언어에 따라 달라집니다. 그렇지만 포르투갈어 등 라틴 알파벳을 사용하는 언어에서는 정렬할 때 악센트와 갈고리형 기호가 거의 영향을 미치지 않습니다. 따라서 'cajá'는 'caja'로 처리해서 'caju'보다 먼저 나와야 합니다.
정렬된 fruits 리스트는 다음과 같아야 합니다.
['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
파이썬에서 non-ASCII 텍스트는 locale.strxfrm() 함수를 이용해서 변환하는 것이 표준입니다. locale 모듈 문서에 따르면 strxfrm() 함수는 문자열을 locale-aware comparison에 사용할 수 있는 문자열로 변환합니다.
locale.strxfrm() 함수를 활성화하려면 먼저 어플리케이션에 대해 적절히 현지어를 설정하고, OS가 이 설정을 지원하도록 기도(?)해야 합니다.. 위의 과일 목록을 정렬하기 위해서 locale.setxfrm() 함수를 사용한 예는 다음과 같습니다.

위와 같이 정렬할 때 locale.strxfrm() 함수를 키로 사용하기 전에 setlocale(LC_COLLATE, <지역 언어>)를 호출해야 합니다.
이때 다음의 내용들에 주의해야 합니다.
- 지역 설정은 시스템 전역에 영향을 미치므로 라이브러리의 setlocale()을 호출하는 것은 권장하지 않습니다. 어플리케이션이나 프레임워크는 프로세스를 시작할 때 지역을 설정하고, 그 후에는 변경하면 안됩니다.
- locale 모듈이 OS에 설치되어 있어야 합니다. 그렇지 않으면 setlocale() 함수를 호출할 때 예외가 발생합니다.
- 지역명의 철자를 알고 있어야 합니다. 유닉스 계열에서는 <language_code.encoding> 형태로 표준화가 잘 되어 있지만, 윈도우의 경우에는 조금 더 복잡한데, <language name>-<language variant_region name>.<codepage> 형태를 갖고 있습니다. 윈도우가 인식하는 지역명은 MSDN에서 확인하실 수 있습니다.
- OS에서 locale이 올바르게 구현되어 있어야 합니다.
따라서 국제화된 정렬 문제에 대해 파이썬 표준 라이브러리가 잘 동작하지만, GNU/리눅스 혹은 윈도우 에서만 잘 지원됩니다. 그렇더라도 지역 설정에 따라 달라지므로, 복잡한 배포 문제가 남아 있긴 합니다.
다행히, PyPI로 제공되는 PyUCA 라이브러리라는 간단한 해결책이 있습니다.
Sorting with the Unicode Collation Algorithm
Django의 contributor인 James Tauber도 이 문제를 겪고 유니코드 대조 알고리즘(Unicode Collation Algorithm; UCA)를 순수 파이썬으로 구현한 PyUCA를 만들었습니다. 이를 사용하는 방법은 다음과 같이 아주 간단합니다.

pyUCA는 지역 정보를 고려하지 않습니다. 정렬 방식을 커스터마이즈하려면 Collator() 생성자에 직접 만든 대조 테이블에 대한 경로를 제공하면 됩니다. 기본적으로는 프로젝트와 함께 제공되는 allkeys.txt를 사용합니다. 이 키 파일은 유니코드 6.3.0에서 제공하는 기본 유니코드 대조 요소 테이블의 사본일 뿐입니다.
The Unicode Database
유니코드 표준은 수많은 구조화된 텍스트 파일의 형태로 하나의 완전한 데이터베이스를 제공합니다. 이 데이터베이스에는 코드 포인트를 문자명으로 매핑하는 테이블뿐만 아니라 각 문자에 대한 메타데이터 및 각 문자의 연관 방법을 담고 있습니다. 예를 들어 유니코드 데이터베이스는 문자를 출력할 수 있는지, 문자인지, 10진수인지, 혹은 다른 수치형 기호인지 기록합니다. str의 isidentifier(), isprintable(), isdecimal(), isnumeric() 메소드는 이 데이터베이스를 사용합니다. str.casefold() 메소드도 유니코드 테이블의 정보를 사용합니다.
unicodedata 모듈에는 문자 메타데이터를 반환하는 함수들이 있습니다. 예를 들어 표준에 정의된 공식 명칭, 결합 문자인지 여부, 사람이 인식하는 기호의 숫자값 등을 반환합니다. 아래 코드는 unicodedata.name()과 unicodedata.numeric()을 str의 isdecimal(), isnumeric() 메소드와 함께 사용하는 방법을 보여줍니다.
import unicodedata
import re
re_digit = re.compile(r'\d')
sample = '1\xbc\xb2\u0969\u136b\u216b\u2466\u2480\u3285'
for char in sample:
print('U+%04x' % ord(char), # code point in U+0000 format
char.center(6), # Character centralized in a str of length 6
're_dig' if re_digit.match(char) else '-', # show re_dig if char matches the r'\d' regex
'isdig' if char.isdigit() else '-', # show isdig if char.isdigit() is True
'isnum' if char.isnumeric() else '-', # show isnum if char.isnumeric() is True
format(unicodedata.numeric(char), '5.2f'), # Numeric value
unicodedata.name(char), # Unicode character name
sep='\t')이를 실행한 결과는 다음과 같습니다.
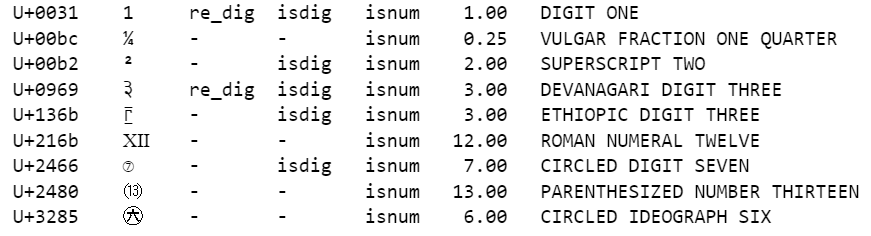
출력된 결과에서 6번째 열은 문자에 unicodedata.numeric(char) 메소드를 호출한 결과로, 숫자를 나타내는 기호의 숫자값을 보여줍니다.
출력 결과에서 정규표현식 '\d'가 숫자 '1'(첫 번째 줄)과 Devanagari 숫자 3(다섯 번째 줄)에 일치하지만, isdigit() 함수가 숫자로 인식하는 문자 중 일부를 숫자가 아니라고 판단합니다. re 모듈을 유니코드를 잘 인식하지 못합니다. PyPI를 통해 새로 제공되는 regex 모듈은 re 모듈을 대체하기 위해 만들어졌으며 유니코드를 더 잘 지원합니다.
unicodedata 모듈이 제공하는 여러 함수를 살펴봤는데, 이 모듈에는 더 많은 함수가 있습니다. 이에 대한 내용은 표준 라이브러리 문서(link)를 참조하시길 바랍니다.
Dual-Mode str and bytes APIs
표준 라이브러리에는 str이나 bytes 인수를 모두 받으며, 인수의 타입에 따라 다르게 작동하는 함수들이 있습니다. re와 os 모듈이 대표적이 예입니다.
str vs. bytes in Regular Expressions
bytes로 정규표현식을 만들면 \d와 \w 같은 패턴은 아스키 문자만 매칭되지만, str로 이 패턴을 만들면 아스키 문자 이외에 유니코드 숫자나 문자로 매칭됩니다. 아래 코드는 문자, 아스키 문자, 위첨자, 타밀 숫자가 str과 bytes 패턴에 어떻게 매칭되는지 비교합니다.
import re
re_numbers_str = re.compile(r'\d+')
re_words_str = re.compile(r'\w+')
re_numbers_bytes = re.compile(rb'\d+')
re_words_bytes = re.compile(rb'\w+')
text_str = ("Ramanujan saw \u0be7\u0bed\u0be8\u0bef"
" as 1729 = 1³ + 12³ = 9³ + 10³.")
text_bytes = text_str.encode('utf_8')
print('Text', repr(text_str), sep='\n ')
print('Numbers')
print(' str :', re_numbers_str.findall(text_str))
print(' bytes:', re_numbers_bytes.findall(text_bytes))
print('Words')
print(' str :', re_words_str.findall(text_str))
print(' bytes:', re_words_bytes.findall(text_bytes))출력 결과는 다음과 같습니다.

위 코드에서 str패턴 r'\d+'는 타밀과 아스키 숫자에 매칭되고, bytes 패턴 rb'\d+'는 아스키 숫자에만 매칭됩니다. 다음 str 패턴 r'\w+'는 문자, 위첨자, 타밀, 아스키 숫자에 매칭되며, bytes 패턴 rb'\w+'는 문자와 숫자에 대한 아스키 바이트에만 매칭됩니다.
위 예제는 str과 bytes의 차이를 보여주는 사소한 예제입니다. 정규표현식을 str과 bytes에 사용할 수 있지만, bytes에 정규표현식을 사용하면 아스키 범위를 벗어나는 문자들은 숫자나 단어로 처리하지 않습니다.
str 정규표현식의 경우 \w, \W, \b, \B, \d, \D, \s, \S가 아스키 문자에만 매칭하게 만드는 re.ASCII 플래그가 있습니다. 자세한 내용은 re 모듈 문서(link)를 참조바랍니다 !
str vs. bytes in os Functions
GNU/리눅스 커널은 유니코드를 알지 못합니다. 따라서 실제 OS의 파일명은 어떠한 인코딩 체계에서도 올바르지 않은 바이트 시퀀스로 구성되어 있으며 str로 디코딩할 수 없습니다. 특히 다양한 OS를 클라이언트로 가지는 파일 서버는 이런 문제가 발생하기 쉽습니다.
이 문제를 해결하기 위해서 파일명이나 경로명을 받는 모든 os 모듈 함수는 str이나 bytes 타입의 인수를 받습니다. 이런 함수를 str 인수로 호출하면 인수는 sys.getfilesystemencoding() 함수에 의해 지정된 코덱을 이용해서 자동으로 변환되고, OS의 응답은 동일 코덱을 이용해서 디코딩됩니다. 대부분의 경우 이 방법은 이 유니코드 샌드위치 모델에 따라 우리가 원하는 대로 동작합니다.
하지만 이렇게 처리할 수 없는 파일명을 다루거나 수정해야 할 때는 bytes 인수를 os 함수에 전달해서 bytes 반환값을 가져올 수 있습니다. 파일명이나 경로명에 얼마나 많은 깨진 문자가 있는지에 상관없이 이 방식을 사용할 수 있습니다.
다음 예제 코드를 살펴보겠습니다.

파일이나 경로명인 str 혹은 bytes 시퀀스를 수작업으로 처리하는 것을 도와주기 위해 os 모듈은 다음과 같이 특별한 인코딩/디코딩 함수 fsencode(name_or_path)와 fsdecode(name_or_path)를 제공합니다. 두 함수 모두 str, bytes를 인수로 받고, 파이썬 3.6부터는 os.PathLike 인터페이스가 구현된 객체를 인수로 받습니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] 일급 함수 (Functions as First-Class Objects) (0) | 2022.03.17 |
|---|---|
| [Python] 객체 참조, 가변성, 재활용 (0) | 2022.03.16 |
| [Python] 딕셔너리와 집합 (0) | 2022.03.13 |
| [Python] 시퀀스 (Sequences) - (2) (0) | 2022.03.12 |
| [Python] 시퀀스 (Sequences) - (1) (0) | 2022.03.12 |




댓글