References
- Professional C++
- https://en.cppreference.com/w/
Contents
- Mutual Exclusion
- Condition Variable
- Futures (std::promise, std::future)
- 멀티스레드 Logger 클래스 예제
지난 포스팅에 이어서 계속해서 C++에서의 멀티스레딩 프로그래밍에 대해 알아보겠습니다. 이전 포스팅과 마찬가지로 C++에서 제공하는 기능들에 대해 살펴보고, 이후에 사용하는 예제들을 살펴보겠습니다.
4. Mutual Exclusion
멀티스레드 프로그램을 작성할 때는 반드시 연산의 순서를 신중하게 결정해야 합니다. 스레드에서 공유 데이터를 읽거나 쓰면 문제가 발생할 수 있기 때문입니다. 이러한 문제를 방지하기 위한 방법은 다양합니다. 극단적으로 스레드끼리 데이터를 아예 공유하지 않게 만들 수도 있습니다. 하지만 공유를 막을 수 없다면 한 번에 한 스레드만 접근할 수 있도록 동기화 메커니즘을 제공해야 합니다.
부울값이나 정수값을 비롯한 스칼라값은 이전 포스팅에서 소개한 아토믹 연산만으로도 충분히 동기화할 수 있습니다. 하지만 복잡하게 구성된 데이터를 여러 스레드가 동시에 접근할 때는 동기화 메커니즘을 사용해야 합니다.
표준 라이브러리에는 mutex와 lock 클래스를 통해 상호 배제(mutual exclusion) 메커니즘을 제공합니다. 이를 활용하면 여러 스레드를 동기화하도록 구현할 수 있습니다.
각 클래스에 대해서 먼저 간단하게 알아본 후에 어떻게 사용하는지 알아보겠습니다.
4.1 mutex
뮤텍스(mutex)는 상호 배제를 뜻하는 mutual exclusion의 줄임말입니다. mutex의 기본 사용법은 다음과 같습니다.
- 다른 스레드와 공유하는 (read/write) 메모리를 사용하려면 먼저 mutex 객체에 락을 걸어서(잠금 요청) 합니다. 다른 스레드가 먼저 락을 걸어뒀다면 그 락이 해제되거나 타임아웃으로 지정도진 시간이 경과해야 쓸 수 있습니다.
- 스레드가 락을 걸었다면 공유 메모리를 마음껏 사용할 수 있습니다. 물론 공유 데이터를 사용하려는 스레드마다 뮤텍스에 대한 락을 걸고 해제하는 동작을 정확히 구분해야 합니다.
- 공유 메모리에 대한 read/write 작업이 끝나면 다른 스레드가 공유 메모리에 대한 락을 걸 수 있도록 락을 해제합니다. 두 개 이상의 스레드가 락을 기다리고 있다면 어느 스레드가 먼저 락을 걸어 작업을 진행할지 알 수 없습니다.
C++ 표준은 non-timed mutex(시간 제약이 없는 뮤텍스)와 timed mutex(시간 제약이 있는 뮤텍스) 클래스를 제공합니다. 이들에 대해 살펴보기 전에 먼저 spinlock이라는 개념을 먼저 살펴보겠습니다.
4.1.1 spinlock
스핀락(spinlock)은 busy loop(spinning)을 사용해서 락을 얻고 작업을 수행하고 락을 해제하는 뮤텍스의 한 형태입니다. spinning하는 동안 스레드는 active 상태로 남아있지만 어떠한 유용한 작업을 수행하지는 않습니다. 그럼에도, 스핀락은 코드로 완전히 구현될 수 있고, OS에 대한 비용이 큰 호출이나 스레드를 스위칭하는데 오버헤드를 겪지 않기 때문에 특정한 상황에서 유용하게 사용될 수 있습니다.
다음의 코드는 atomic_flag를 사용하여 구현된 스핀락을 보여줍니다.
#include <iostream> #include <thread> #include <vector> std::atomic_flag spinlock = ATOMIC_FLAG_INIT; // Unifor initialization is not allowed static const size_t NumberOfThreads{ 50 }; static const size_t LoopsPerThread{ 100 }; void dowork(size_t threadNumber, std::vector<size_t>& data) { for (size_t i = 0; i < LoopsPerThread; i++) { while (spinlock.test_and_set()) {} // Spins until lock is acquired // Save to handle shared data data.push_back(threadNumber); spinlock.clear(); // Release the acquired lock } } int main() { std::vector<size_t> data; std::vector<std::thread> threads; for (size_t i = 0; i < NumberOfThreads; ++i) { threads.push_back(std::thread{ dowork, i, std::ref(data) }); } for (auto& t : threads) { t.join(); } std::cout << "data contains " << data.size() << " elements, expected " << NumberOfThreads * LoopsPerThread << ".\n"; }
이 코드에서, 각 스레드는 반복적으로 atomic_flag에서 test_and_set()을 호출하면서 성공할 때까지 락을 얻으려고 시도합니다. 이것이 바로 busy loop 입니다.
실행 결과는 다음과 같습니다.

여기서 atomic_flag는 C++표준으로부터 보장받는 항상 lock-free인 atomic Boolean 입니다. 이는 atomic<bool>과는 다른데, 값을 저장하거나 로드하기 위한 메소드를 제공하지 않습니다.
4.1.2 Non-timed Mutex Classes
표준 라이브러리는 mutex, recursive_mutex, shared_mutex라는 세 종류의 시간 제약이 없는 뮤텍스(non-timed mutex) 클래스를 제공합니다. 그중 첫 번째와 두 번째는 <mutex> 헤더에 정의되어 있고, 세 번째 클래스는 C++17부터 추가된 <shared_mutex> 헤더에 정의되어 있습니다. 각 뮤텍스마다 다음과 같은 메소드를 제공합니다.
- lock() : 호출하는 측의 스레드가 락을 완전히 걸 때까지 대기합니다(블록됩니다). 이때 대기 시간에는 제한이 없습니다. 스레드가 블록되는 시간을 정하려면 아래에서 설명하는 timed mutex를 사용합니다.
- try_lock() : 호출하는 측의 스레드가 락을 걸도록 시도합니다. 현재 다른 스레드가 락을 걸었다면 호출이 즉시 리턴됩니다. 락을 걸었다면 try_lock()은 true를 리턴하고, 그렇지 않으면 false를 리턴합니다.
- unlock() : 호출하는 측의 스레드가 현재 걸어둔 락을 해제합니다. 그러면 다른 스레드가 락을 걸 수 있게 됩니다.
std::mutex는 소유권을 독점하는 기능을 제공하는 표준 뮤텍스 클래스입니다. 이 뮤텍스는 한 스레드만 가질 수 있습니다. 다른 스레드가 이 뮤텍스를 소유하려면 lock()을 호출하고 대기합니다. try_lock()을 호출하면 락을 거는데 실패해 곧바로 리턴됩니다. 뮤텍스를 이미 확보한 스레드가 같은 뮤텍스에 대해 lock()이나 try_lock()을 또 호출하면 데드락이 발생하므로 조심해야 합니다.
std::recursive_mutex는 mutex와 거의 비슷하지만, 이미 recursive_mutex를 확보한 스레드가 동일한 recursive_mutex에 대해 lock()이나 try_lock()을 또 다시 호출할 수 있습니다. recursive_mutex에 대한 락을 해제하려면 lock()이나 try_lock()을 호출한 횟수만큼 unlock() 메소드를 호출해야 합니다.
std::shared_mutex는 공유 락 소유권(shared lock ownership) 또는 읽기-쓰기 락(reader-writer lock)이란 개념을 구현한 것입니다. 스레드는 락에 대한 독점 소유권(exclusive ownership)이나 공유 소유권(shared ownership)을 얻습니다. 독점 소유권(or 쓰기 락(write lock))은 다른 스레드가 독점 소유권이나 공유 소유권을 가지고 있지 않을 때만 얻을 수 있습니다. 공유 소유권(or 읽기 락(read lock))은 다른 스레드가 독점 소유권을 가지고 있지 않거나 공유 소유권만 가지고 있을 때 얻을 수 있습니다. shared_mutex 클래스는 lock(), try_lock(), unlock() 메소드를 제공합니다. 이 메소드는 독점 락을 얻거나 해제합니다. 또한 lock_shared(), try_lock_shared(), unlock_shared()와 같은 공유 소유권 관련 메소드도 제공합니다. 공유 소유권 버전의 메소드도 기존 메소드와 비슷하지만 획득하고 해제하는 대상이 공유 소유권이라는 점이 다릅니다.
shared_mutex에 이미 락을 건 스레드는 같은 뮤텍스에 한 번 더 락을 걸 수 없으며, 이는 데드락이 발생하기 때문입니다.
위에서 소개한 뮤텍스 클래스에 대한 lock/unlock 메소드는 직접 호출하면 됩니다. 뮤텍스 락은 일종의 리소스라서 거의 대부분 RAII 원칙에 따라 독점적으로 획득합니다. C++ 표준은 RAII 락 클래스를 다양하게 제공합니다. 이에 대해서는 아래 부분에서 자세히 소개하도록 하겠습니다. 데드락을 방지하려면 반드시 락 클래스를 사용하는 것이 좋습니다. 락 객체가 스코프를 벗어나면 자동으로 뮤텍스를 unlock 해주기 때문에 unlock() 메소드를 일일히 정확한 시점에 호출하지 않아도 됩니다.
4.1.3 Timed Mutex Classes
위에서 언급한 뮤텍스 클래스에서 lock()을 호출할 때, 이 호출은 락을 얻을 때까지 블락됩니다. 반면에 try_lock()을 호출하면 락을 얻으려고 시도하지만 실패하는 경우 그 즉시 리턴합니다. 이처럼 락을 얻으려고 시도하면 특정 시간 이후에는 포기하는 timed mutex(시간 제약이 있는 뮤텍스)가 있습니다.
표준 라이브러리는 timed_mutex, recursive_timed_mutex, shared_timed_mutex라는 세 종류의 시간 제약이 있는 뮤텍스 클래스를 제공합니다. 그중 첫 번째와 두 번째는 <mutex> 헤더에, 세 번째는 <shared_mutex>에 정의되어 있습니다. 3가지 클래스 모두 lock(), try_lock(), unlock() 메소드를 제공하고, shared_time_mutex에는 lock_shared(), try_lock_shared(), unlock_shared()도 제공합니다. 이러한 메소드의 동작은 모두 위에서 설명한 방식과 같습니다.
여기에 추가로 다음의 메소드도 제공합니다.
- try_lock_for(rel_time) : 호출하는 측의 스레드는 주어진 상대 시간 동안 락을 획득하려 시도합니다. 주어진 타임아웃 시간 안에 락을 걸 수 없으면 호출은 실패하고 false를 리턴합니다. 주어진 타임아웃 시간에 락을 걸었다면 호출은 성공하고 true를 리턴합니다. 타임아웃은 std::chrono::duration 타입으로 지정합니다.
- try_lock_until(abs_time) : 호출하는 측의 스레드는 인수로 지정한 절대 시간이 시스템 시간과 같거나 초과하기 전까지 락을 걸도록 시도합니다. 그 시간 내에 락을 걸 수 있다면 true를 리턴합니다. 지정된 시간이 경과하면 이 함수는 더 이상 락을 걸려는 시도를 멈추고 false를 리턴합니다. 절대 시간도 마찬가지로 std::chrono::duration 타입으로 지정합니다.
shared_time_mutex는 try_lock_shared_for()과 try_lock_shared_until()도 제공합니다.
timed_mutex나 shared_timed_mutex의 소유권을 이미 확보한 스레드는 같은 뮤텍스에 대해 락을 중복해서 걸지 못하며, 그렇게 되면 데드락이 발생합니다.
recursive_timed_mutex를 이용하면 스레드가 락을 중복해서 걸 수 있으며, 사용방법은 recursive_mutex와 동일합니다.
4.2 Locks
lock 클래스는 RAII 원칙이 적용되는 클래스로서 뮤텍스에 락을 정확히 걸거나 해제하는 작업을 쉽게 처리해줍니다. lock 클래스의 소멸자는 확보했던 뮤텍스를 자동으로 해제시킵니다. C++ 표준에서는 lock_guard, unique_lock, shared_lock, scoped_lock 이라는 4가지 타입의 락을 제공합니다. scoped_lock은 C++17부터 추가되었습니다.
4.2.1 lock_guard
std::lock_guard는 <mutex> 헤더에 정의된 간단한 락으로서, 다음 두 가지 생성자를 제공합니다.
- explicit lock_guard(mutex_type& m);
뮤텍스에 대한 레퍼런스를 인수로 받는 생성자입니다. 이 생성자는 전달된 뮤텍스에 락을 걸려고 시도하고, 완전히 락이 걸릴 때까지 블락됩니다. - lock_guard(mutex_type& m, adopt_lock_t);
뮤텍스에 대한 레퍼런스와 std::adopt_lock_t의 인스턴스를 인수로 받는 생성자입니다. std::adopt_lock 이라는 이름으로 미리 정의된 adopt_lock_t 인스턴스가 제공됩니다. 이때 호출하는 측의 스레드는 인수로 지정한 뮤텍스에 대한 락을 이미 건 상태에서 추가로 락을 겁니다. 락이 제거되면 뮤텍스도 자동으로 해제됩니다.
4.2.2 unique_lock
std::unique_lock은 <mutex> 헤더에 정의된 락으로서, 락을 선언하고 한참 뒤 실행될 때 락을 걸도록 지연시키는 고급 기능을 제공합니다. 락이 제대로 걸렸는지 확인하려면 owns_lock() 메소드나 unique_lock에서 제공하는 bool 타입 변환 연산자를 사용합니다. 이러한 변환 연산자를 사용하는 방법은 아래에서 자세히 소개하겠습니다.
unique_lock은 다음과 같은 버전의 생성자를 제공합니다.
- explicit unique_lock(mutex_type& m);
이 생성자는 뮤텍스에 대한 레퍼런스를 인수로 받아서 그 뮤텍스에 락을 걸려고 시도하고, 완전히 락이 걸릴 때까지 블락시킵니다. - unique_lock(mutex_type& m, defer_lock_t) noexcept;
이 생성자는 뮤텍스에 대한 레퍼런스와 std::defer_lock_t의 인스턴스를 인수로 받습니다. std::defer_lock이라는 이름으로 미리 정의된 defer_lock_t 인스턴스도 제공합니다. unique_lock은 인수로 전달한 뮤텍스에 대한 레퍼런스를 저장하지만 곧바로 락을 걸지 않고 나중에 다시 걸도록 시도합니다. - unique_lock(mutex_type& m, try_to_lock_t);
이 생성자는 뮤텍스에 대한 레퍼런스와 std::try_to_lock_t의 인스턴스를 인수로 받습니다. std::try_to_lock이라는 이름으로 미리 정의된 try_to_lock_t 인스턴스도 제공합니다. 이 버전의 락은 레퍼런스가 가리키는 뮤텍스에 대해 락을 걸려고 시도합니다. 실패할 경우 블락하지 않고 나중에 다시 시도합니다. - unique_lock(mutex_type& m, adopt_lock_t);
이 생성자는 뮤텍스에 대한 레퍼런스와 std::adopt_lock_t의 인스턴스(ex, std::adopt_lock)를 인수로 받습니다. 이 락은 호출하는 측의 스레드가 레퍼런스로 지정된 뮤텍스에 대해 이미 락을 건 상태라고 가정하고, 그 락에 여기서 지정된 뮤텍스를 추가합니다. 락이 제거되면 뮤텍스도 자동으로 해제됩니다. - unique_lock(mutex_type& m, const chrono::time_point<Clock, Duration>& abs_time);
이 생성자는 뮤텍스에 대한 레퍼런스와 절대 시간에 대한 값을 인수로 받습니다. 그래서 지정된 절대 시간 안에 락을 걸려고 시도합니다. - unique_lock(mutex_type& m, const chrono::duration<Req, Period>& rel_time);
이 생성자는 뮤텍스에 대한 레퍼런스와 상대 시간을 인수로 받아서 주어진 시간 안에 인수로 지정한 뮤텍스에 락을 걸려고 시도합니다.
unique_lock 클래스는 lock(), try_lock(), try_lock_9for(), try_lock_until(), unlock() 메소드를 제공하며 동작은 Timed-Mutex에서 설명한 것과 같습니다.
4.2.3 shared_lock
shared_lock 클래스는 <shared_mutex> 헤더 파일에 정의되어 있으며, unique_lock과 똑같은 타입의 생성자와 메소드를 제공하고, 내부 공유 뮤텍스에 대해 공유 소유권에 관련된 메소드를 호출한다는 점만 다릅니다. 따라서 shared_lock 메소드는 lock(), try_lock()을 호출할 때 내부적으로 lock_shared(), try_lock_shared() 등과 같은 공유 뮤텍스에 대한 메소드를 호출합니다. 이는 shared_lock과 unique_lock의 인터페이스를 통일시키기 위함입니다.
4.2.4 Acquiring Multiple Locks at Once
C++은 두 가지 제네릭 락 함수를 제공합니다. 이 함수는 데드락이 발생할 걱정 없이 여러 개의 뮤텍스 객체를 한 번에 거는데 사용합니다. 두 함수 모두 std 네임스페이스에 정의되어 있으며 가변 인수 템플릿 함수로 정의되어 있습니다.
첫 번째 함수인 lock()은 인수로 지정된 뮤텍스 객체를 데드락 발생 걱정 없이 한꺼번에 락을 겁니다. 이때 락을 거는 순서는 알 수 없습니다. 그중에서 어느 하나의 뮤텍스 락에 대해 예외가 발생하면 이비 확보한 락에 대해 unlock()을 호출합니다. 이 함수의 프로토타입은 다음과 같습니다.
template<class L1, class L2, class... L3> void lock(L1&, L2&, L3&...);
try_lock()의 프로토타입도 이와 비슷하지만, 주어진 모든 뮤텍스 객체에 대해 락을 걸 때 try_lock()을 순차적으로 호출합니다. 모든 뮤텍스에 대해 try_lock()이 성공하면 -1을 리턴하고, 어느 하나라도 실패하면 이미 확보된 락에 대해 unlock()을 호출합니다. 그러면 뮤텍스 매개변수의 위치를 가리키는 인덱스(0-based)값을 리턴합니다.
다음 예제는 이러한 제네릭 lock() 함수를 사용하는 방법에 대해 보여줍니다. process() 함수는 먼저 두 뮤텍스에 대한 락을 하나씩 생성하고, std::defer_lock_t 인스턴스를 unique_lock의 두 번째 인수로 지정해서 그 시간 안에 락을 걸지 않도록 합니다. 그런 다음 std::lock()을 호출해서 데드락이 발생할 걱정 없이 두 락을 모두 겁니다.
#include <mutex> std::mutex mut1; std::mutex mut2; void process() { std::unique_lock lock1{ mut1, std::defer_lock }; std::unique_lock lock2{ mut2, std::defer_lock }; std::lock(lock1, lock2); // Locks acquired. } // Locks automatically released.
뮤텍스 사용 방법에 대한 다른 예제를 참고하시고 싶으시면 아래 포스팅 내용을 참조하시면 조금 도움이 되실 것 같습니다.. !
[C++] mutex
References 씹어먹는 C++ (https://modoocode.com/270) Contents race condition (경쟁 상태) mutex deadlock (데드락) 2021.08.07 - [C & C++] - [C++] thread [C++] thread References 씹어먹는 C++ (https://mo..
junstar92.tistory.com
4.2.5 scoped_lock
std::scoped_lock은 <mutex> 헤더 파일에 정의되어 있으며, lock_guard와 비슷하지만 뮤텍스를 지정하는 인수 개수에 제한이 없습니다. scoped_lock을 사용하면 여러 락을 한 번에 거는 코드를 훨씬 간결하게 작성할 수 있습니다. 예를 들어 scoped_lock을 사용하면 위에서 살펴본 process() 함수를 다음과 같이 구현할 수 있습니다.
std::mutex mut1; std::mutex mut2; void process() { std::scoped_lock locks(mut1, mut2); // Locks acquired. } // Locks automatically released.
4.3 std::call_once
std::call_once()와 std::once_flag를 함께 사용하면 같은 once_flag에 대해 여러 스레드가 call_once()를 호출하더라도 call_once의 인수로 지정한 함수나 메소드가 단 한 번만 호출되게 할 수 있습니다. 인수로 지정한 함수나 메소드에 대해 call_once가 단 한 번만 호출됩니다. 지정한 함수가 예외를 던지지 않을 때, 이렇게 호출하는 것을 effective call_once() 호출이라고 부릅니다. 지정한 함수가 예외를 던지면 그 예외는 호출한 측으로 전달되며, 다른 호출자를 골라서 함수를 실행시킵니다. 특정한 once_flag 인스턴스에 대한 이펙티브 호출은 동일한 once_flag에 대한 다른 call_once() 호출보다 먼저 끝납니다.
아래 그림은 스레드 3개로 이를 실행한 예를 보여줍니다.

스레드 1은 이펙티브 call_once() 호출을 수행하고, 스레드 2는 이러한 이펙티브 호출이 끝날 때까지 블록됩니다. 스레드 3은 스레드 1의 이펙티브 호출이 이미 끝났기 때문에 블록되지 않습니다.
다음 예제 코드는 call_once()를 사용하는 방법을 보여줍니다. 이 예제에서는 공유 자원을 사용하는 processingFunction()을 실행하는 스레드 3개를 생성합니다. 여기서 공유하는 자원은 반드시 initializeSharedResource()로 단 한 번만 호출해서 초기화해야 합니다. 이렇게 하려면 스레드마다 once_flag라는 전역 플래그에 대해 call_once()를 호출합니다. 코드를 실행하면 단 한 스레드만 initializeSharedResource()를 정확한 한 번 실행합니다. call_once() 호출이 진행되는 동안 다른 스레드는 initializeSharedResource()가 리턴할 때까지 블록됩니다.
std::once_flag g_onceFlag; void initializeSharedResource() { // initialize shared resources to be used by mutliple threads std::cout << "Shared resources initialized.\n"; } void processingFunction() { // Make sure the shared resources are initialized std::call_once(g_onceFlag, initializeSharedResource); // .. Do some work, including using the shared resources std::cout << "Processing\n"; } int main() { // Launch 3 threads std::vector<std::thread> threads{ 3 }; for (auto& t : threads) { t = std::thread{ processingFunction }; } // Join on all threads for (auto& t : threads) { t.join(); } }
위 코드를 실행한 출력은 다음과 같습니다.
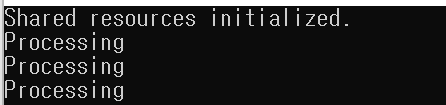
스레드 3개가 processingFuntion 함수를 호출하지만 initializeSharedResource 함수는 단 한 번 호출되었습니다.
4.4 뮤텍스 객체 사용 방법
이번에는 뮤텍스 객체로 여러 스레드를 동기화하는 방법에 대한 몇 가지 예제를 살펴보겠습니다.
4.4.1 Thread-Safe Writing to Streams
이전 포스팅에서 아래의 코드를 실행했을 때,
void counter(int id, int numIterations) { for (int i = 0; i < numIterations; i++) { std::cout << "Counter: " << id << " has value " << i << std::endl; } } int main() { std::thread t1(counter, 1, 6); std::thread t2(counter, 2, 4); t1.join(); t2.join(); }
출력이 뒤섞여서 나오는 것을 봤었습니다. 기본적으로 C++ 스트림에 대해서는 데이터 경쟁이 발생하지는 않지만 여러 스레드로 출력한 결과가 뒤섞일 수 있습니다. 이렇게 결과가 뒤섞이지 않게 하려면 뮤텍스 객체를 사용해서 스트림 객체에 읽거나 쓰는 작업을 한 번에 한 스레드만 수행하도록 만들면 됩니다.
하지만 그 전에 C++20에서 synchronized stream이 추가되었는데, 이를 먼저 살펴보도록 하겠습니다.. !
- Synchronized Streams
C++20에는 std::basic_osyncstream과 미리 정의된 타입 앨리어스인 osyncstream, wosyncstream(for char and wchar_t stream)이 추가되었습니다. 모두 <syncstream>에 정의되어 있습니다. 이들 클래스에서 'o'는 output을 의미합니다. 이 클래스들은 이들을 통해 나가는 모든 아웃풋이 동기화된 스트림이 파괴되는 순간 최종 output stream으로 나타나도록 보장합니다. 즉, 다른 스레드로부터의 다른 output들이 서로 끼어들지 않는다는 것을 보장합니다.
아래 코드는 방금 위의 counter 함수에서 osyncstream을 사용하여 출력이 서로 끼어들지 못하도록 합니다.
#include <syncstream> void counter(int id, int numIterations) { for (int i = 0; i < numIterations; i++) { std::osyncstream{ std::cout } << "Counter: " << id << " has value " << i << std::endl; } }
위와 동일한 main함수를 실행하면,
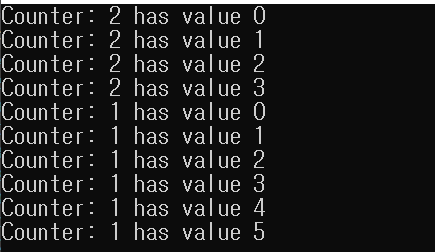
출력이 섞이지 않는 것을 볼 수 있습니다.
위의 counter 함수는 다음과 같이 작성할 수도 있습니다.
void counter(int id, int numIterations) { std::osyncstream syncedCout{ std::cout }; for (int i = 0; i < numIterations; i++) { syncedCout << "Counter: " << id << " has value " << i << std::endl; } }
- Using Mutex
방금 설명한 synchronized stream을 사용할 수 없다면, 아래 코드처럼 뮤텍스를 사용해서 cout에 대한 모든 접근을 동기화해야 합니다. 아래 코드는 전역으로 선언한 mutex 객체를 사용합니다.
#include <mutex> std::mutex mut; void counter(int id, int numIterations) { for (int i = 0; i < numIterations; i++) { std::lock_guard lock{ mut }; std::cout << "Counter: " << id << " has value " << i << std::endl; } } int main() { std::thread t1(counter, 1, 6); std::thread t2(counter, 2, 4); t1.join(); t2.join(); }
이 코드는 lock_guard 인스턴스를 매 반복마다 생성합니다. 이렇게 해야 가능한 락을 잡고 있는 시간을 제한할 수 있습니다. 그렇지 않으면 다른 스레드들을 너무 오랫동안 블록시키게 됩니다. 예를 들어, 만약 lock_guard는 for 루프가 시작되기 전에 생성한다면, 이 코드는 모든 멀티스레딩 효과를 잃어버립니다. 이는 한 스레드가 자신의 for 루프를 완전히 다 끝내는 동안 lock을 붙잡고 있기 때문입니다. 따라서 다른 스레드들은 이 lock이 풀릴 때까지 계속 대기합니다.
- Using Timed Locks
다음 예제는 시간 제약이 있는 뮤텍스를 사용하는 방법을 보여줍니다. 위에서 본 counter 함수와 거의 비슷하지만 이번에는 unique_lock과 timed_mutex를 조합해서 사용합니다. unique_lock 생성자에 200ms란 상대 시간을 인수로 지정해서 그 시간 동안 락 걸기를 시도합니다. 이 시간 안에 락을 걸지 못해도 unique_lock 생성자는 그냥 리턴합니다. 실제로 락이 걸렸는지는 나중에 lock 변수에 대한 if문으로 확인합니다. unique_lock은 bool 타입 변환 연산자를 제공하기 때문에 이렇게 할 수 있습니다.
std::timed_mutex mut; void counter(int id, int numIterations) { for (int i = 0; i < numIterations; i++) { std::unique_lock lock{ mut, 200ms }; if (lock) { std::cout << "Counter: " << id << " has value " << i << std::endl; } else { // Loock not acquired in 200ms, skip output } } }
(여기서 for 문 내부 수행 시간이 짧기 때문에 아마 출력이 스킵되는 경우는 거의 없을 것으로 예상됩니다.)
5. Condition Variables
조건 변수(condition variable)을 이용하면 다른 스레드가 조건을 설정하기 전이나 따로 지정한 시간이 경과하기 전까지 스레드의 실행을 멈추고 기다리게 할 수 있습니다. 그래서 스레드 통신을 구현할 수 있습니다. Win32 API로 멀티스레드 프로그래밍 경험이 있다면 윈도우의 이벤트 객체(event object)와 비슷하다고 보면 됩니다.
C++에는 두 가지 조건 변수를 제공합니다. 둘 다 <condition_variable> 헤더 파일에 정의되어 있습니다.
- std::condition_variable: unique_lock<mutex>만 기다리는 조건 변수로서, C++ 표준에 의하면 특정한 플랫폼에서 효율을 최대로 이끌어낼 수 있습니다.
- std::condition_variable_any: 커스텀 락 타입을 비롯한 모든 종류의 객체를 기다릴 수 있는 조건 변수입니다.
condition_variable은 다음과 같은 메소드를 제공합니다.
- notify_one()
조건 변수를 기다리는 스레드 중 하나를 깨웁니다. - notify_all()
조건 변수를 기다리는 모든 스레드를 깨웁니다. - wait(unique_lock<mutex>& lk)
wait()를 호출하는 스레드는 반드시 lk에 대한 락을 걸고 있어야 합니다. wait()를 호출하면 lk.unlock()을 아토믹하게 호출해서 그 스레드를 블록시키고, 알림(notification)이 오길 기다립니다. 다른 스레드에서 호출한 notify_one()이나 notify_all()로 인해 블록된 스레드가 해제되면, lk.lock()을 다시 호출해서 락을 완전히 걸 때까지 블록시킨 뒤 리턴합니다. - wati_for(unique_lock<mutex>& lk, const chrono::duration<Rep, Preiod>& rel_time)
wait()와 비슷하지만, nofity_one()이나 nofity_all()이 호출되거나 지정된 시간이 만료하면 현재 스레드의 블록 상태를 해제합니다. - wait_until(unique_lock<mutex>& lk, const chrono::time_point<Clock, Duration>& abs_time)
wait()와 비슷하지만, nofity_one()이나 nofity_all()이 호출되거나 시스템 시간이 절대 시간으로 지정한 시간을 지나면 블록된 스레드가 해제됩니다.
이외에도 predicate 매개변수를 추가로 받는 버전의 wait(), wait_for(), wait_until()도 있습니다.
예를 들면, wait() 버전 중에는 predicate를 추가로 받아서, 다음 코드처럼 동작하는 것도 있습니다.
while (!predicate()) wait(lk);
condition_variable_any 클래스에서 제공하는 메소드는 condition_variable과 비슷하지만 unique_lock<mutex>뿐만 아니라 다른 모든 종류의 락 클래스도 인수로 받는다는 점이 다릅니다. 이렇게 받은 락 클래스는 반드시 lock()과 unlock() 메소드를 제공해야 합니다.
5.1 Spurious Wake-Ups
조건 변수를 기다리는 스레드는 다른 스레드가 nofity_one()이나 nofity_all()을 호출할 때까지 기다립니다. 기다리는 시간은 상대 시간이나 절대 시간(특정한 시스템 시간)으로 지정합니다. 그런데 이렇게 미리 지정된 시점에 다다르지 않았는데 비정상적으로 깨어날 수도 있습니다. 즉, notify_one()이나 nofity_all()을 호출한 스레드도 없고, 타임아웃도 발생하지 않았는데 스레드가 깨어나는 것입니다. 그러므로 조건 변수를 기다리도록 설정했던 스레드가 그 이전에 깨어나면 그 이유를 검사해야 합니다. 한 가지 방법은 프레디케이트를 인수로 받는 wait()를 사용하는 것이 있습니다.
5.2 Using Condition Variables
예를 들어 큐어 담긴 원소를 백그라운드로 처리할 때 조건 변수를 활용해보도록 하겠습니다. 먼저 처리할 원소를 추가할 큐에 정의합니다. 백그라운드 스레드는 큐에 원소가 들어올 때까지 기다렸다가 원소가 추가되면 스레드를 깨워서 그 원소를 처리하고 다음 원소가 들어올 때까지 다시 잠든 상태로 기다립니다.
큐는 다음과 같이 선언합니다.
std::queue<std::string> m_queue;주어진 시점에 오직 한 스레드만 이 큐를 수정해야 하므로, 이는 뮤텍스로 구현할 수 있습니다.
std::mutex m_mutex;원소가 추가된 사실을 백그라운드 스레드에 알려주도록 다음과 같이 조건 변수를 선언합니다.
std::condition_variable m_condVar;큐에 원소를 추가하는 스레드는 먼저 앞에서 선언한 뮤텍스에 락부터 걸어야 합니다. 그리고 나서 큐에 원소를 추가하고 백그라운드 스레드에 알려줍니다. 이때 실제로 락을 걸었는지에 관계없이 nofity_one()이나 notify_all()을 호출합니다.
// lock mutex and add entry to the queue std::unique_lock lock{ m_mutex }; m_queue.push(entry); // notify condition variable to wake up thread m_condVar.notify_all();
여기서 백그라운드 스레드는 무한 루프를 돌면서 알림이 오기는 기다립니다. 구현 코드는 다음과 같습니다. 이때 프레디케이트를 인수로 받는 wait()를 이용하여 비정상적으로 깨어나지 않게 만듭니다. 이 프레디케이트는 큐에 실제로 원소가 추가됬는지 확인합니다. wati()를 호출한 결과가 리턴되면 실제로 큐에 뭔가 추가되었다고 보장할 수 있습니다.
std::unique_lock lock{ m_mutex }; while (true) { // Wait for a notification m_condVar.wait(lock, [this]{ return !m_queue.empty(); }); // Condition variable is notified, so something is in the queue // Process queue item... }
구체적인 구현 방법은 아래에서 Logger 클래스 예제 코드를 통해 살펴보겠습니다. 또한, 이전 포스팅에서 한 번 다루어본 적이 있으니 해당 포스트의 예제를 참고해도 도움이 될 것 같습니다.
생산자(Producer) / 소비자(Consumer) 패턴
[C++] 생산자(Producer) / 소비자(Consumer) 패턴
References 씹어먹는 C++ (https://modoocode.com/270) Contents 생산자 / 소비자 패턴 Producer - Consumer 패턴 예시 생산자(Producer) - 소비자(Consumer) 패턴은 멀티 쓰레드 프로그램에서 자주 사용되는 패턴..
junstar92.tistory.com
C++ 표준은 std::notify_all_at_thread_exit(cond, lk)라는 헬퍼 함수도 제공합니다. 여기서 cond는 조건 변수이고, lk는 unique_lock<mutex> 인스턴스입니다. 이 함수를 호출하는 스레드는 lk라는 락을 이미 확보한 상태여야 합니다. 이 스레드가 종료하면 다음 코드가 자동으로 실행됩니다.
lk.unlock(); cond.notify_all();
6. Futures
어떤 값을 계산하는 스레드를 std::thread로 만들어서 실행하면 그 스레드가 종료된 후에는 최종 결과를 받기가 힘듭니다. 예외나 여러 가지 에러를 처리하는 데도 문제가 발생합니다. 스레드가 던진 예외를 그 스레드가 받지 않으면 C++ 런타임은 std::terminate()를 호출해서 어플리케이션 전체를 종료시킵니다.
이때 future를 사용하면 스레드의 실행 결과를 쉽게 받아올 수 있을 뿐만 아니라 예외를 다른 스레드로 전달해서 원하는 방식으로 처리할 수 있습니다. 물론 예외가 발생한 스레드에서 벗어나지 않도록 항상 같은 스레드 안에서 예외를 처리하는 것이 바람직합니다.
스레드의 실행 결과를 promise에 담으면 future로 그 값을 가지고 있습니다. channel에 비유하면 promise는 입력 포트이고, future는 출력 포트인 셈입니다. 같은 스레드나 다른 스레드에서 실행하는 함수가 계산해서 리턴하는 값을 promise에 담으면 나중에 그 값을 future에서 가져갈 수 있습니다. 이 메커니즘은 결과에 대한 스레드 통신 채널로 볼 수 있습니다.
C++은 std::future라는 표준 future를 제공합니다. std::future에 있는 결과를 가져오는 방법은 다음과 같습니다. 여기서 T는 계산된 결과에 대한 타입입니다.
std::future<T> myFuture{ ... }; T result{ myFuture.get() };
여기서 get()을 호출해서 가져온 결과를 result 변수에 저장합니다. 이때 get()을 호출한 부분은 계산이 끝날 때까지 멈추고 기다립니다(블록됩니다). future하나에 대해 get()은 한 번만 호출할 수 있습니다. 두 번 호출하는 경우는 표준에 따로 정해져있지 않습니다.
코드가 블록되지 않게 하려면 다음과 같이 future를 검사해서 결과가 준비되었는지 확인부터 합니다.
if (myFuture.wait_for(0)) { // value is available T result{ myFuture.get() }; } else { ... }
6.1 std::promise and std::future
C++은 promise를 구현하는 std::promise 클래스를 제공합니다. future와 promise는 <future> 헤더 파일에 정의되어 있습니다. promise에 대해 set_value()를 호출해서 결과를 저장하거나, set_exception()을 호출해서 예외를 promise에 저장할 수 있습니다. 참고로 특정 promise에 대해 set_value()나 set_exception()을 단 한 번만 호출할 수 있습니다. 여러 번 호출하면 std::future_error 예외가 발생합니다.
A 스레드와 B 스레드가 있을 때 A 스레드가 어떤 계산을 B 스레드로 처리하기 위해 std::promise를 생성해서 B 스레드를 구동할 때 이 promise를 인수로 전달합니다. 이때 promise는 복사될 수 없고, 이동만 가능합니다. B 스레드는 이 promise에 값을 저장합니다. A 스레드는 promise를 B 스레드로 이동시키기 전에 생성된 promise에 get_future()를 호출합니다. 그러면 B가 실행을 마친 후, 나온 결과에 A가 접근할 수 있습니다. 이를 코드로 구현하면 다음과 같습니다.
void doWork(std::promise<int> thePromise) { // .. do some work // and ultimately store the result in the promise. thePromise.set_value(42); } int main() { // Create a promise to pass to the thread std::promise<int> myPromise; // Get the future of the promise auto theFuture{ myPromise.get_future() }; // Create a thread and move the promise into it std::thread theThread{ doWork, std::move(myPromise) }; // do some work.. // Get the result int result{ theFuture.get() }; std::cout << "Result: " << result << std::endl; // Make sure to join the thread theThread.join(); }
6.2 std::packaged_task
std::packaged_task를 사용하면 방금 소개한 std::promise를 명시적으로 사용하지 않고도 promise를 구현할 수 있습니다. 아래의 코드는 std::packaged_task를 사용하는 구체적인 방법을 보여줍니다. 여기서 먼저 packaged_task를 생성해서 ㅊcalculateSum()을 실행합니다. 이 packaged_task에 대해 get_future()를 호출해서 future를 가져옵니다.
그리고 스레드를 실행시키면서, packaged_task는 그 스레드로 이동(move)시킵니다. 이때, packaged_task는 복사될 수 없습니다. 스레드가 실행되고 나면 get_future()로 받아온 future에 대해 get()을 호출해서 결과를 가져옵니다. 이때 결과가 나오기 전까지는 블록됩니다.
여기서 calculateSum()은 promise에 저장하는 작업을 하지 않아도 됩니다. packaged_task가 promise를 자동으로 생성하고, 호출한 함수의 결과를 promise가 알아서 저장해줍니다. 이때 발생한 예외도 promise에 저장됩니다.
int calculateSum(int a, int b) { return a + b; } int main() { // Create a packaged task to run claculatedSum std::packaged_task<int(int, int)> task{ calculateSum }; // Get the future for the result of the packaged task auto theFuture{ task.get_future() }; // Create a thread, move the packaged task into it, and // execute the packaged task with the given arguments std::thread theThread{ std::move(task), 39, 3 }; // do some more work... // Get the result int result{ theFuture.get() }; std::cout << result << std::endl; // Make sure to join the thread theThread.join(); }
6.3 std::async
스레드로 계산하는 작업을 C++런타임이 스레드를 생성하고 계산하는 것을 조금 더 제어하도록 하려면 std::async()를 사용하면 됩니다. std::async()는 실행할 함수를 인수로 받아서 그 결과를 담은 future를 리턴합니다. 지정한 함수를 async()로 구동하는 방법은 두 가지입니다.
- 함수를 스레드로 만들어 비동기식으로 실행한다
- 스레드를 따로 만들지 않고, 리턴된 future에 대해 get()을 호출할 때까지 동기식으로 함수를 실행한다
async()에 인수를 주지 않고 호출하면 런타임이 앞에 나온 두 가지 방법 중 하나를 적절히 고릅니다. 이때 시스템에 장착된 CPU의 코어 수나 동시에 수행되는 작업의 양에 따라 방법이 결정됩니다. 아래와 같이 정책을 나타내는 인수를 지정하면 이러한 선택 과정에 가이드라인을 제시할 수 있습니다.
- launch::async: 주어진 함수를 다른 스레드에서 실행시킨다
- launch::deferred: get()을 호출할 때 주어진 함수를 현재 스레드와 동기식으로 실행시킨다
- launch::async | launch::deferred: C++ 런타임이 결정한다 (default)
async()를 사용하는 예는 다음과 같습니다.
int calculate() { return 123; } int main() { auto myFuture{ std::async(calculate) }; //auto myFuture{ std::async(std::launch::async, calculate) }; //auto myFuture{ std::async(std::launch::deferred, calculate) }; // do some more work... // Get the result int result{ myFuture.get() }; std::cout << result << std::endl; }
위 예제 코드에서 볼 수 있듯이 std::async()는 원하는 계산을 비동기식으로 처리하거나(다른 스레드에서), 동기식으로 처리해서(현재 스레드에서) 나중에 결과를 가져오도록 구현하는 가장 쉬운 방법입니다.
async()를 호출해서 리턴된 future는 실제 결과가 담길 때까지 소멸자에서 블록됩니다. 다시 말해 async()를 호출한 뒤 리턴된 future를 캡처하지 않으면 async()가 블록되는 효과가 발생합니다. 예를 들어 아래 코드는 calculate()를 동기식으로 호출합니다.
async(calculate);이 문장에서 async()는 future를 생성해서 리턴합니다. 이렇게 리턴된 future를 캡처하지 않으면 임시 future 객체가 생성됩니다. 그래서 이 문장이 끝나기 전에 소멸자가 호출되면서 결과가 나올 때까지 블록됩니다.
6.4 Exception Handling
future의 가장 큰 장점은 스레드끼리 예외를 주고받는 데 활용할 수 있다는 것입니다. future에 대해 get()을 호출해서 계산된 결과를 리턴하거나, 이 future에 연결된 promise에 저장된 예외를 다시 던질 수 있습니다. packaged_task나 async()를 사용하면 실행된 함수에서 던진 예외가 자동으로 promise에 저장됩니다. 이때 promise를 std::promise로 구현하면 set_exception()을 호출해서 예외를 저장합니다.
async()를 사용하여 예외를 던지는 예는 다음과 같습니다.
int calculate() { throw std::runtime_error{ "Exception thrown from calculate()." }; } int main() { // use the launch::async policy to force asynchronous execution auto myFuture{ std::async(std::launch::async, calculate) }; // do some more work... // Get the result try { int result{ myFuture.get() }; std::cout << result << std::endl; } catch (const std::exception& ex) { std::cout << "Caught exception: " << ex.what() << std::endl; } }
6.5 std::shared_future
std::future<T>의 인수 T는 move-constructible(이동 생성)해야 합니다. future<T>에 대해 get()을 호출하면 future로부터 결과가 이동되어 리턴됩니다. 그러므로 future<T>에 대해 get()을 한 번만 호출할 수 있습니다.
get()을 여러 스레드에 대해 여러 번 호출하고 싶다면 std::shared_future<T>를 사용합니다. 이때 T는 복사 생성이 가능해야 합니다. shared_future는 std::future::share()로 생성하거나 shared_future 생성자에 future를 전달하는 방식으로 생성합니다. 이때 future는 복사될 수 없습니다. 따라서 shared_future 생성자에 이동(move)시켜야 합니다.
shared_future는 여러 스레드를 동시에 깨울 때 사용합니다. 예를 들어 아래에서 살펴볼 코드는 람다 표현식 두 개를 서로 다른 스레드에서 비동기식으로 실행합니다. 각 람다 표현식은 가장 먼저 promise에 값을 설정해서 스레드가 구동됬다는 사실을 알리는 작업부터 수행합니다. 그런 다음 signalFuture에 대해 get()을 호출해서 블록시켰다가 future를 통해 매개변수가 설정되면 각 스레드를 실행합니다. 각 람다 표현식은 promise를 레퍼런스로 캡처합니다. signalFuture은 값으로 캡처합니다. 따라서 두 표현식 모두 signalFuture의 복사본을 가지고 있습니다. 메인 스레드는 async()를 이용해 두 람다 표현식을 서로 다른 스레드에서 비동기식으로 실행시킵니다. 그리고 나서 두 스레드가 구동될 때까지 기다리다가 두 스레드 모두 깨우도록 signalPromise에 매개변수를 지정합니다.
int main() { std::promise<void> thread1Started, thread2Started; std::promise<int> signalPromise; auto signalFuture{ signalPromise.get_future().share() }; // std::shared_future<int> signalFuture{ signalPromise.get_future() }; auto function1{ [&thread1Started, signalFuture] { thread1Started.set_value(); // wait until parameter is set int parameter{ signalFuture.get() }; std::cout << parameter << std::endl; } }; auto function2{ [&thread2Started, signalFuture] { thread2Started.set_value(); // wait until parameter is set int parameter{ signalFuture.get() }; std::cout << parameter << std::endl; } }; // Run both lambda expressions asynchronously // Remember to capture the future retunred my async() auto result1{ std::async(std::launch::async, function1) }; auto result2{ std::async(std::launch::async, function2) }; // Wait until both threads have started thread1Started.get_future().wait(); thread2Started.get_future().wait(); // Both threads are now waiting for the parameter // Set the parameter to wake up both of them signalPromise.set_value(42); }
위 코드를 실행하면 마지막 문장을 실행한 후에 signalPromise로 설정한 값이 출력됩니다.
아래 포스팅은 promise/future, 그리고 async에 대한 내용을 조금 더 쉽게 정리한 것입니다. 필요하시면 참고바랍니다!
[C++] 비동기(Asynchronous) 실행
References 씹어먹는 C++ (https://modoocode.com/284) Contents std::future, std::promise std::shared_future std::packaged_task std::async 앞선 글들에서 이야기했던 쓰레드나 생성자-소비자 패턴의 경우을..
junstar92.tistory.com
7. Multithreaded Logger Class
이번 예제를 통해서 스레드, 뮤텍스 객체, 락, 조건 변수를 모두 활용하여 멀티스레딩 기반의 Logger 클래스를 만들어보도록 하겠습니다. 이 클래스는 여러 스레드를 이용하여 큐에 로그 메세지를 기록합니다. Logger 클래스는 이 큐를 백그라운드 스레드로 처리하며, 파일에 로그 메세지를 기록하는 작업을 순차적으로 처리합니다. 이 클래스는 멀티스레드 코드를 작성할 때 발생하기 쉬운 문제를 보여주기 위해서 두 가지 반복문을 사용하도록 구성되었습니다.
C++ 표준에서 제공하는 큐는 스레드에 안전하지 않습니다. 그래서 이렇게 여러 스레드가 큐를 읽고 쓸 때는 동시에 읽고 쓰지 못하도록 동기화 메커니즘을 구현해야 합니다. 예제 코드는 뮤텍스 객체와 조건 변수를 사용하여 동기화합니다.
이렇게 정의한 Logger 클래스는 다음과 같습니다.
#include <mutex> #include <condition_variable> #include <queue> #include <thread> #include <string> #include <fstream> #include <iostream> class Logger { public: // Starts a background thread writing log entries to a file Logger(); // Gracefully shut down background thread //virtual ~Logger(); // Prevent copy construction and assignment Logger(const Logger& src) = delete; Logger& operator=(const Logger& rhs) = delete; // Add log entry to the queue void log(std::string entry); private: // The function running in the background thread void processEntries(); // Helper method to process a queue of entries void processEntriesHelper(std::queue<std::string>& queue, std::ofstream& ofs) const; // Muext and condition variable to protect access to the queue std::mutex m_mutex; std::condition_variable m_condVar; std::queue<std::string> m_queue; // The background thread std::thread m_thread; // Boolean telling the background thread to terminate //bool m_exit{ false }; };
이 클래스의 구현 코드는 다음과 같습니다. 여기서 ~Logger()와 m_exit는 잠시 주석으로 처리해두었는데, 이것들이 없으면 실행했을 때 결과가 이상하게 나오거나 뻗어버릴 수 있습니다. 이를 해결하는 방법은 아래에서 다시 설명하겠습니다.
Logger::Logger() { // Start background thread m_thread = std::thread{ &Logger::processEntries, this }; } void Logger::log(std::string entry) { // Lock mutex and add entry to the queue std::unique_lock lock{ m_mutex }; m_queue.push(std::move(entry)); // Notify condition variable to wake up thread m_condVar.notify_all(); } void Logger::processEntries() { // Open log file. std::ofstream logFile{ "log.txt" }; if (logFile.fail()) { std::cerr << "Failed to open logfile.\n"; return; } // Create a lock for m_mutex, but do not yet acquire a lock on it std::unique_lock lock{ m_mutex, std::defer_lock }; // Start processing loop while (true) { lock.lock(); // wait for a notification m_condVar.wait(lock); // Condition variable is notified, so something might be in the queue // While we still have the lock, swap the contents of the current queue // with an empty local queue on the stack std::queue<std::string> localQueue; localQueue.swap(m_queue); // Now that all entries have been moved from the current queue to the // local queue, we can release the lock so other threads are not blocked // while we process the entries lock.unlock(); // Process the entries in the local queue on the stack. This happens after // having released the lock, so other threads are not blocked anymore processEntriesHelper(localQueue, logFile); } } void Logger::processEntriesHelper(std::queue<std::string>& queue, std::ofstream& ofs) const { while (!queue.empty()) { ofs << queue.front() << std::endl; queue.pop(); } }
Logger 클래스를 사용하는 방법은 다음과 같습니다.
void logSomeMessages(int id, Logger& logger) { for (int i = 0; i < 10; i++) { logger.log(std::string{ "Log entry " + std::to_string(i) + " from thread " + std::to_string(id) }); } } int main() { Logger logger; std::vector<std::thread> threads; // Create a few threads all working with the same Logger instance for (int i = 0; i < 10; i++) { threads.emplace_back(logSomeMessages, i, std::ref(logger)); } // Wait for all threads to finish for (auto& t : threads) { t.join(); } }
이렇게 구현한 Logger를 가지고 위 코드를 실행하면 프로그램이 갑자기 죽습니다. 그 이유는 백그라운드 스레드에 대해서 join()이나 detach()를 호출하지 않았기 때문입니다. 앞서 설명했듯이 thread 객체의 소멸자가 여전히 joinable할 수 있기 때문에(즉, join()이나 detach()가 아직 호출되지 않았기 때문에) std::terminate()를 호출해서 현재 실행 중인 스레드뿐만 아니라 어플리케이션 자체도 종료시켜버립니다. 그래서 파일에 아직 기록되지 않은 메세지가 큐에 여전히 남아 있게 됩니다. 런타임 라이브러리에 따라 이렇게 어플리케이션이 갑자기 죽어버리면 에러 메세지를 출력하거나 메모리 덤프를 생성합니다. 따라서 백그라운드 스레드를 정상적으로 종료시키는 메커니즘을 추가하고, 어플리케이션을 종료할 때 백그라운드 스레드가 완전히 종료될 때까지 기다리게 구현해야 합니다. 이렇게 하기 위해서 위에서 주석 처리한 소멸자와 bool 타입의 멤버변수 m_exit를 사용하도록 수정합니다.
수정된 코드는 다음과 같습니다.
Logger::~Logger() { { std::unique_lock lock{ m_mutex }; // Gracefully shut down the thread by setting m_exit to true m_exit = true; } // Notify condition variable to wake up thread m_condVar.notify_all(); // Wait until thread is shut down. This should be outside the above code // block because the lock must be released before calling join() m_thread.join(); } void Logger::processEntries() { // Open log file. std::ofstream logFile{ "log.txt" }; if (logFile.fail()) { std::cerr << "Failed to open logfile.\n"; return; } // Create a lock for m_mutex, but do not yet acquire a lock on it std::unique_lock lock{ m_mutex, std::defer_lock }; // Start processing loop while (true) { lock.lock(); if (!m_exit) { // Only wait for notification if we don't have to exit m_condVar.wait(lock); } else { // We have to exit, process the remaining entries in the queue processEntriesHelper(m_queue, logFile); break; } // Condition variable is notified, so something might be in the queue // and/or we need to shut down this thread // While we still have the lock, swap the contents of the current queue // with an empty local queue on the stack std::queue<std::string> localQueue; localQueue.swap(m_queue); // Now that all entries have been moved from the current queue to the // local queue, we can release the lock so other threads are not blocked // while we process the entries lock.unlock(); // Process the entries in the local queue on the stack. This happens after // having released the lock, so other threads are not blocked anymore processEntriesHelper(localQueue, logFile); } }
여기서 주의할 점은 while 문 바깥에서 m_exit를 검사하면 안됩니다. m_exit가 true이어도 얼마든지 파일에 저장할 로그 항목이 큐에 남아 있을 수 있기 때문입니다.
멀티스레드로 실행되는 코드에 특정한 동작을 발생시키기 위해 일정 부분의 실행을 일부러 지연시킬 수 있습니다. 이때 테스트 용도로만 지연시키고, 최종 버전에서는 지연 코드를 삭제합니다. 예를 들어 소멸자에서 발생하던 데이터 경쟁 문제가 완전히 해결되었는지 확인하려면 메인 프로그램에서 log()를 호출하는 부분을 모두 삭제해서 Logger 클래스의 소멸자를 곧바로 호출하고 그 뒤에 실행을 지연시키는 코드를 추가합니다.
void Logger::processEntries() { // .. 나머지 코드 생략 // Create a lock for m_mutex, but do not yet acquire a lock on it std::unique_lock lock{ m_mutex, std::defer_lock }; // Start processing loop while (true) { lock.lock(); if (!m_exit) { // Only wait for notification if we don't have to exit std::this_thread::sleep_for(1000ms); m_condVar.wait(lock); } else { // We have to exit, process the remaining entries in the queue processEntriesHelper(m_queue, logFile); break; } // .. 나머지 코드 생략 } }
생성된 log.txt를 확인해보면 총 100개의 메세지가 로깅된 것을 확인할 수 있습니다.
지난 포스팅과 이번 포스팅을 통해서 표준 C++ 스레드 라이브러리로 멀티스레드 프로그램을 작성하는 방법에 대해 간략히 살펴봤습니다. 기초만 소개했기 때문에 고급 기법들에 대해서 다루지는 못했습니다. 기회가 되면 조금 더 자세하게 살펴보도록 하겠습니다.. !
'프로그래밍 > C & C++' 카테고리의 다른 글
| [C++] Error Handling (2) (0) | 2022.03.06 |
|---|---|
| [C++] Error Handling (1) (0) | 2022.03.06 |
| [C++] 멀티스레딩 프로그래밍 (1) (0) | 2022.03.03 |
| [C++] 템플릿(Template) 심화편 (2) (0) | 2022.03.01 |
| [C++] 템플릿(Template) 심화편 (1) (0) | 2022.03.01 |




댓글