References
- 씹어먹는 C++ (https://modoocode.com/270)
Contents
- race condition (경쟁 상태)
- mutex
- deadlock (데드락)
2021.08.07 - [C & C++] - [C++] thread
[C++] thread
References 씹어먹는 C++ (https://modoocode.com/269) Contents thread join / detach thread에 인자 전달하기 single thread vs multi thread 쓰레드를 사용하면 병렬 수행이 가능한 작업들을 단일 쓰레드 프로..
junstar92.tistory.com
이전 게시글에서 thread에 대해서 알아봤습니다.
이번에는 서로 다른 쓰레드에서 같은 메모리를 공유할 때 발생할 수 있는 문제인 race condition에 대해서 알아보고 어떻게 이 문제를 해결하는지에 대해서 알아보도록 하겠습니다.
Race Condition
우선 아래 예제 코드를 실행시켜보겠습니다.
#include <iostream>
#include <thread>
#include <vector>
void worker(int& counter) {
for (int i = 0; i < 10000; i++) {
counter += 1;
}
}
int main(void) {
int counter = 0;
std::vector<std::thread> workers;
for (int i = 0; i < 4; i++) {
workers.push_back(std::thread(worker, std::ref(counter)));
}
for (int i = 0; i < 4; i++) {
workers[i].join();
}
std::cout << "Counter 최종 값 : " << counter << std::endl;
return 0;
}위 코드를 컴파일하고 실행시키면, Counter의 최종값이 40000이 나와야하지만 예상과는 다르게 다양한 값들이 나오게 됩니다. (물론 운이 좋게 40000이 나올 때도 있습니다.)

이러한 문제는 7번째 줄을 처리하는 과정에서 발생하게 됩니다.
counter += 1;위 코드는 우리가 보기에는 달랑 1줄이지만, CPU 측면에서 살펴보면 그렇지 않습니다.
CPU는 레지스터(register)라는 곳에 데이터를 기록한 다음 연산을 수행해야 하는데, 모든 데이터는 메모리에 저장되어 있고 연산할 때마다 메모리에서 레지스터로 값을 가져온 뒤에 빠르게 연산을 수행하고 다시 메모리에 가져다 놓는 식으로 동작합니다.
그래서 counter += 1은 실제로 아래와 같은 코드로 컴파일이 됩니다.
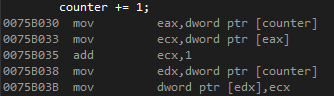
위와 같은 코드를 어셈블리(Assembly) 코드라고 부르며, 이 코드는 CPU가 실제로 수행하는 기계어와 1대1로 대응됩니다. 위 명령 한줄한줄을 CPU가 처리합니다. counter에 1을 더하기 위해서 레지스터로 값을 옮기고 더하는 과정들이 포함되어 있습니다. 우리가 보기에는 단순히 1을 더하는 작업이지만, CPU의 입장에서는 여러 작업들이 숨어 있습니다. (어셈블리 코드의 자세한 내용은 생략하도록 하겠습니다.)
그럼 이제 counter의 최종합이 이상하게 나왔는지 짐작이 가능합니다.

즉, counter(=0)에 1을 더하는 중간에 컨텍스트 스위칭이 발생하여 다른 쓰레드에서 counter의 값을 증가시켜 1이 되었지만, 다시 이전 쓰레드로 돌아왔을 때에 이전 counter 값이 0인 상태였기 때문에 다시 1이 counter에 저장되게 됩니다.
Mutex
위 문제가 발생하는 근본적인 원인은 counter를 1 증가시키는 부분을 여러 쓰레드에서 동시에 실행시켰기 때문입니다. 그렇다면, 이 부분은 오직 쓰레드 하나만 수행할 수 있도록 코드를 실행시키면 위 문제를 방지할 수 있습니다.
C++에서는 이러한 기능을 하는 객체를 제공하는데, 바로 뮤텍스(mutex) 입니다.
(뮤텍스는 Mutual Exclusion-상호 배제 라는 단어에서 따온 용어입니다.)
이전 예제에서 뮤텍스를 적용시켜 보겠습니다.
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
void worker(int& counter, std::mutex& m) {
for (int i = 0; i < 10000; i++) {
m.lock();
counter += 1;
m.unlock();
}
}
int main(void) {
int counter = 0;
std::mutex m;
std::vector<std::thread> workers;
for (int i = 0; i < 4; i++) {
workers.push_back(std::thread(worker, std::ref(counter), std::ref(m)));
}
for (int i = 0; i < 4; i++) {
workers[i].join();
}
std::cout << "Counter 최종 값 : " << counter << std::endl;
return 0;
}컴파일 후 실행시켜보면 정상적으로 최종 값이 40000으로 출력되는 것을 확인할 수 있습니다.

뮤텍스는 <mutex> 헤더를 include해서 사용합니다.
void worker(int& counter, std::mutex& m);뮤텍스를 각 쓰레드에서 사용하기 위해서 뮤텍스 객체를 위와 같이 worker 함수의 인자로 전달하고 있고,
m.lock();
counter += 1;
m.unlock();위와 같이 사용합니다.
m.lock()은 뮤텍스 m을 현재 쓰레드에서 사용하도록 요청하는 것입니다.
이때, 한 번에 한 쓰레드에서만 m의 사용권한을 갖기 때문에 다른 쓰레드에서 이미 m.lock()을 한 상태라면, 뮤텍스 m을 소유한 쓰레드에서 이를 반환(m.unlock())할 때까지 무한정 기다리게됩니다.
따라서, worker 함수가 아무리 많은 쓰레드에서 돌아간다고 하더라도 결국 뮤텍스 m은 한번에 한 쓰레드에서만 얻을 수 있어서 counter += 1;은 결국 한 쓰레드에서만 유일하게 실행됩니다.
이렇게 m.lock()과 m.unlock() 사이에 한 쓰레드만이 유일하게 실행할 수 있는 코드 부분을 임계 영역(critical section)이라고 합니다.
Deadlock (데드락)
여기서 만약 m.unlock()을 잊고 넣어주지 않는다면 어떻게 될까요?
뮤텍스 m을 취한 쓰레드에서 unlock을 호출하지 않기 때문에, 다른 모든 쓰레드들이 기다리게 됩니다. 심지어 m을 소유했던 쓰레드에서도 다시 m.lock을 호출하게 되면, unlock을 하지 않았기 때문에 해당 쓰레드에서도 기다리게 됩니다.
결국 어떤 쓰레드도 연산을 진행하지 못하게 되고, 이러한 상황을 데드락(deadlock)이라고 합니다.
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
void worker(int& counter, std::mutex& m) {
for (int i = 0; i < 10000; i++) {
m.lock();
counter += 1;
}
}
int main(void) {
int counter = 0;
std::mutex m;
std::vector<std::thread> workers;
for (int i = 0; i < 4; i++) {
workers.push_back(std::thread(worker, std::ref(counter), std::ref(m)));
}
for (int i = 0; i < 4; i++) {
workers[i].join();
}
std::cout << "Counter 최종 값 : " << counter << std::endl;
return 0;
}위 코드를 실행하면 Visual Studio 경우에는 런타임 에러가 발생하며, 우분투에서는 프로그램이 종료되지 않게 됩니다.
위와 같은 문제를 해결하기 위해서는 소유권을 획득한 뮤텍스는 사용이 끝나면 반드시 소유권을 반환해야 합니다. 하지만 코드가 길어지게 되면 반환하는 것을 까먹을 수도 있는데, 메모리 할당한 객체의 메모리 해제를 까먹는 것과 동일하다고 볼 수 있습니다.
메모리 할당을 하고 사용 후에 반드시 해제하기 위해서 unique_ptr의 소멸자를 사용하는 것처럼 뮤텍스도 사용 후에 해제하기 위해서 unique_ptr처럼 소멸자에서 해제하도록 처리할 수 있습니다.
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
void worker(int& counter, std::mutex& m) {
for (int i = 0; i < 10000; i++) {
std::lock_guard<std::mutex> lock(m);
counter += 1;
}
}
int main(void) {
int counter = 0;
std::mutex m;
std::vector<std::thread> workers;
for (int i = 0; i < 4; i++) {
workers.push_back(std::thread(worker, std::ref(counter), std::ref(m)));
}
for (int i = 0; i < 4; i++) {
workers[i].join();
}
std::cout << "Counter 최종 값 : " << counter << std::endl;
return 0;
}따라서, 8번째 줄처럼 사용하게 되면, 사용자가 따로 unlock을 신경쓰지 않아도 됩니다.
lock_guard 객체는 뮤텍스를 인자로 받아서 생성하는데, 이 때 생성자에서 뮤텍스를 lock하게 됩니다. 그리고 lock_guard가 소멸될 때 알아서 lock 했던 뮤텍스를 unlock하게 됩니다.
하지만 이것으로 데드락 문제는 모두 해결되는 것은 아닙니다.
아래와 같은 상황을 살펴보겠습니다.
#include <iostream>
#include <mutex>
#include <thread>
void worker1(std::mutex& m1, std::mutex& m2) {
for (int i = 0; i < 10000; i++) {
std::lock_guard<std::mutex> lock1(m1);
std::lock_guard<std::mutex> lock2(m2);
//Do something
}
}
void worker2(std::mutex& m1, std::mutex& m2) {
for (int i = 0; i < 10000; i++) {
std::lock_guard<std::mutex> lock2(m2);
std::lock_guard<std::mutex> lock1(m1);
//Do something
}
}
int main(void) {
std::mutex m1, m2;
std::thread t1(worker1, std::ref(m1), std::ref(m2));
std::thread t2(worker2, std::ref(m1), std::ref(m2));
t1.join();
t2.join();
std::cout << "End of main\n";
return 0;
}위 코드를 컴파일 후, 실행시키면 프로그램이 종료되지 않고 계속 실행됩니다. 아까처럼 런타임 에러가 발생하지도 않습니다.
이 문제는 worker1과 worker2에서 뮤텍스를 얻는 순서 때문에 발생한 것입니다.
worker1에서는 m1을 먼저 lock하고, 그 다음에 m2를 lock하게 됩니다.
std::lock_guard<std::mutex> lock1(m1);
std::lock_guard<std::mutex> lock2(m2);반면에, worker2는 m2를 먼저 lock하고, m1을 lock하게 됩니다.
std::lock_guard<std::mutex> lock2(m2);
std::lock_guard<std::mutex> lock1(m1);
그렇기 때문에 위 문제는 worker1에서 m1을 lock하고, worker2에서 m2를 lock하게 되면서 발생하게 됩니다.
worker1에서 m1을 먼저 lock한 상태에서 worker2로 넘어와서 m2를 lock한 다음 m1을 lock하려니, worker1에서 먼저 m1을 lock했기 때문에 소유권을 얻지못하고 계속해서 기다리게 됩니다. 하지만 worker1에서도 m2를 lock하려니 worker2에서 m2를 먼저 lock했기 때문에 worker1에서도 계속해서 m2가 unlock되기를 기다리게 됩니다.
즉, 뮤텍스를 lock 했다면, unlock 해주도록 했음에도 worker1과 worker2에서 어떻게 할 수 없는 데드락 상황에 빠지게 됩니다.
위의 문제를 해결하기 위해서는 한 쓰레드에게 우선권을 먼저 주는 방법이 있습니다.
#include <iostream>
#include <mutex>
#include <thread>
void worker1(std::mutex& m1, std::mutex& m2) {
for (int i = 0; i < 10; i++) {
m1.lock();
m2.lock();
std::cout << "Worker 1 ! " << i << std::endl;
m2.unlock();
m1.unlock();
}
}
void worker2(std::mutex& m1, std::mutex& m2) {
for (int i = 0; i < 10; i++) {
while (true) {
m2.lock();
if (!m1.try_lock()) {
m2.unlock();
continue;
}
std::cout << "Worker 2 ! " << i << std::endl;
m1.unlock();
m2.unlock();
break;
}
}
}
int main(void) {
std::mutex m1, m2;
std::thread t1(worker1, std::ref(m1), std::ref(m2));
std::thread t2(worker2, std::ref(m1), std::ref(m2));
t1.join();
t2.join();
std::cout << "End of main\n";
return 0;
}즉, worker1에게 우선권을 먼저 주어서, worker2에서 m1을 lock하려고 시도할 때, 만약 이미 lock이 되어 있다면, m2를 unlock 하여서 worker1이 먼저 수행될 수 있도록 해줍니다.
위 코드를 컴파일 후 실행시키면 정상적으로 종료되는 것을 확인할 수 있습니다.

출력 개수가 적어서 아마 한번에 한 쓰레드가 전부 돌아버리고 있는 것 같은데, 횟수를 증가시키면 더 자세하게 확인할 수 있습니다.
if (!m1.try_lock()) {
m2.unlock();
continue;
}위 코드에서 새로운 함수인 try_lock은 만약 뮤텍스를 lock 할 수 있다면 lock하고 true를 반환하고, 만약 lock을 할 수 없다면 기다리지 않고 false를 반환하게 됩니다. 따라서, 만약 false를 반환했다면 m1 lock을 실패했으므로, worker1에게 우선권을 주기 위해서 m2를 unlock해서 worker1이 m2의 소유권을 얻도록 해주고 있습니다.
하지만 이렇게 한쪽에 우선권을 주게 되면, 우선권을 얻을 쓰레드만 열심히 수행되고 다른 쓰레드는 수행될 수 없는 기아 상태(starvation)이 발생할 수도 있습니다.
이와 같이 데드락을 해결하는 것은 복잡하고 완벽하지 않습니다. 따라서 애초에 데드락이 발생할 수 없도록 프로그램을 잘 설계하는 것이 중요하고, C++ Concurrency In Action에서는 데드락 상황을 피하기 위해서 다음과 같은 가이드라인을 제시하고 있습니다.

'프로그래밍 > C & C++' 카테고리의 다른 글
| [C++] 우측값 참조(rvalue reference) (0) | 2021.08.11 |
|---|---|
| [C++] 생산자(Producer) / 소비자(Consumer) 패턴 (0) | 2021.08.09 |
| [C++] thread (0) | 2021.08.07 |
| [C++] 스마트 포인터(Smart Pointer) - (2) (3) | 2021.08.03 |
| [C++] 스마트 포인터(Smart Pointer) - (1) (3) | 2021.08.02 |




댓글