References
- Professional C++
- https://en.cppreference.com/w/
Contents
- C++ Algorithms
- find(), find_if(), accumulate()
- 알고리즘과 이동 의미론
- 알고리즘 콜백 복사 문제
표준 라이브러리에서는 여러 가지 유용한 제너릭 데이터 구조(컨테이너)를 제공합니다. 다른 라이브러리와는 달리 표준 라이브러리는 여기서 더 나아가 거의 모든 컨테이너에 적용할 수 있는 제너릭 알고리즘을 다양하게 제공합니다. 이러한 알고리즘을 활용하면 컨테이너에 담긴 원소를 검색하고, 정렬하고, 가공하고, 다양한 연산을 수행할 수 있습니다. 표준 라이브러리 알고리즘의 가장 큰 장점은 각 원소의 타입이나 컨테이너의 타입과는 독립적이라는 점입니다. 게다가 모든 작업을 반복자(iterator) 인터페이스만으로 처리합니다.
이번 포스팅에서는 이터레이터를 이미 알고 있다고 가정하고 알고리즘에 대해 알아 볼 예정입니다. 필요하시면 이전에 작성한 이터레이터 관련 포스팅을 참조하시면 조금이나마 도움이 될 것입니다 !
이처럼 표준 라이브러리의 알고리즘이 강력한 이유는 컨테이너를 직접 다루지 않고 이터레이터라는 매개체로 작동하기 때문입니다. 그러므로 컨테이너를 구현하는 방식과는 독립적입니다. 표준 라이브러리 알고리즘은 모두 함수 템플릿으로 구현되어 있으면 템플릿 타입 매개변수는 반복자 타입인 경우가 많습니다. 이터레이터 자체는 이 함수에 전달된 인수로 결정합니다. 함수 템플릿은 대부분 함수에 전달된 인수를 보고 템플릿 타입을 추론하기 때문에 알고리즘을 템플릿이 아닌 일반 함수처럼 사용할 수 있습니다.
이터레이터 인수는 주로 이터레이터의 범위(시작과 끝)로 표현합니다. 대부분의 경우에 이터레이터의 범위를 표현할 때는 첫 번째 원소는 포함하고 마지막 원소는 제외한 반개방(half-open) 범위로 받는 컨테이너가 많습니다. end 이터레이터는 실제로 '마지막 바로 다음' 원소를 가리킵니다.
알고리즘에 전달할 이터레이터는 일정한 조건을 갖추어야 합니다. 예를 들어, copy_backward()에는 양방향 이터레이터를 지정해야 하며, stable_sort()는 랜덤 액세스 이터레이터를 지정해야 합니다.
다시 말해서 이런 알고리즘은 조건을 갖추지 못한 이터레이터를 가진 컨테이너에 대해서는 동작하지 않습니다. 예를 들어 forward_list는 정방향 이터레이터만 제공하고, 양방향이나 랜덤 액세스 이터레이터는 제공하지 않습니다. 따라서 forward_list를 copy_backward()나 stable_sort()에 적용할 수 없습니다.
표준 라이브러리 알고리즘은 대부분 <algorithm> 헤더 파일에 정의되어 있습니다. 일부 수치 관련 알고리즘은 <numeric>에 정의되어 있으며, 두 헤더 파일 모두 std 네임스페이스에 속해 있습니다.
알고리즘을 익히기 위한 가장 좋은 방법은 예제를 살펴보는 것인데, 이번 포스팅에서 find(), find_if(), accumulate() 알고리즘의 실제 작동 과정을 살펴보도록 하겠습니다.
1. find() 와 find_if() 알고리즘
find()는 주어진 이터레이터 범위에서 특정한 원소를 검색합니다. 이 알고리즘은 모든 종류의 컨테이너 원소를 찾을 때 활용할 수 있습니다. find()는 원소를 찾으면 그 원소를 참조하는 반복자를 리턴하고, 원소를 찾지 못하면 주어진 범위의 끝을 가리키는 이터레이터(end)를 리턴합니다. 참고로 find()를 호출할 때는 컨테이너의 모든 범위로 지정하지 않아도 되며 부분 집합을 지정해도 됩니다.
find()에서 원소를 찾지 못하면, 내부 컨테이너의 end 이터레이터가 아닌 호출할 때 지정한 범위의 end 이터레이터를 리턴합니다.
std::find()를 사용하는 예제를 살펴보겠습니다. 여기서는 사용자가 항상 올바른 숫자만 입력한다고 가정하고, 입력에 대한 에러 체크는 생략했습니다.
#include <iostream>
#include <vector>
#include <algorithm>
int main()
{
std::vector<int> myVector;
while (true) {
std::cout << "Enter a number to add (0 to stop): ";
int number;
std::cin >> number;
if (number == 0) { break; }
myVector.push_back(number);
}
while (true) {
std::cout << "Enter a number to lookup (0 to stop): ";
int number;
std::cin >> number;
if (number == 0) { break; }
auto endIt{ std::cend(myVector) };
auto it{ std::find(std::cbegin(myVector), endIt, number) };
if (it == endIt) {
std::cout << "Could not find " << number << std::endl;
}
else {
std::cout << "Found: " << *it << std::endl;
}
}
}find()를 호출할 때 cbegin(myVector)와 endIt을 인수로 지정했습니다 (std::cbegin()이나 std::cend() 대신 vector의 cbegin, cend 메소드를 사용해도 됩니다). 여기서는 vector의 모든 원소를 검색하기 위해서 endIt을 cend(myVector)로 정의했습니다. 일부 집합에서만 검색하려면 이 두 반복자를 적절하게 변경하면 됩니다.
앞서 작성한 코드를 실행한 결과는 다음과 같습니다.

C++17부터 추가된 if문에서의 이니셜라이저를 적용하면 find()를 호출하고 결과를 검사하는 작업을 다음과 같이 한 문장으로 표현할 수 있습니다.
if (auto it{ std::find(std::cbegin(myVector), endIt, number) }; it == endIt) {
std::cout << "Could not find " << number << std::endl;
}
else {
std::cout << "Found " << *it << std::endl;
}참고로 map과 set처럼 find()를 자체적으로 정의하여 클래스 메소드로 제공하는 컨테이너도 있습니다.
이처럼 제너릭 알고리즘과 동일한 기능을 제공하는 메소드가 컨테이너에 존재한다면 제너릭 알고리즘보다 컨테이너의 메소드를 사용하는 것이 더 좋은데, 컨테이너의 메소드가 더 빠르기 때문입니다. 예를 들어 제너릭 알고리즘인 find()는 map을 처리하는 속도가 선형 시간인 반면 map에서 제공하는 find()의 메소드는 처리 속도가 로그 시간입니다.
find_if()는 인수로 검색한 원소가 아닌 predicate function callback을 받는다는 점을 제외하면 find()와 같습니다. 이 콜백 함수는 true나 false를 리턴합니다. find_if() 알고리즘은 지정한 범위 안에 있는 원소에 대해 인수로 지정한 콜백 함수가 true를 리턴할 때까지 계속 호출합니다. 콜백 함수가 true를 리턴하면 find_if()는 그 원소를 가리키는 이터레이터를 리턴합니다.
다음 예제 코드는 사용자로부터 시험 점수를 입력받아서 만점이 있는지 검사합니다. 여기서 만점은 100점 이상인 것을 의미합니다.
#include <iostream>
#include <vector>
#include <algorithm>
bool perfectScore(int num) { return num >= 100; }
int main()
{
std::vector<int> myVector;
while (true) {
std::cout << "Enter a test score to add (0 to stop): ";
int score;
std::cin >> score;
if (score == 0) { break; }
myVector.push_back(score);
}
auto endIt{ myVector.cend() };
if (auto it{ std::find_if(myVector.cbegin(), endIt, perfectScore) }; it == endIt) {
std::cout << "No perfect scores" << std::endl;
}
else {
std::cout << "Found a \"perfect\" score of " << *it << std::endl;
}
}위 프로그램은 perfectScore() 함수에 대한 포인터를 find_it()의 인수로 전달합니다. 그러면 find_if() 알고리즘은 perfectScore()가 true를 리턴할 때까지 모든 원소에 대해 이 함수를 호출합니다.

find_if()를 호출할 때 다음과 같이 람다 표현식을 사용해도 됩니다. 여기서 람다 표현식의 강력함을 확인할 수 있는데, 이렇게 하면 perfectScore()란 함수를 따로 정의할 필요가 없습니다.
if (auto it{ std::find_if(myVector.cbegin(), endIt, [](int i) { return i >= 100; }) }; it == endIt) {
std::cout << "No perfect scores" << std::endl;
}
else {
std::cout << "Found a \"perfect\" score of " << *it << std::endl;
}
2. accumulate() 알고리즘
컨테이너에 있는 원소를 모두 더하는 연산을 적용할 때가 자주 있습니다. 이를 위해 accumulate() 함수를 제공합니다. 이 함수는 <algorithm>이 아닌 <numeric>에 정의되어 있습니다. 가장 기본적인 사용법은 지정한 범위에 있는 원소의 합을 구하는 것입니다.
예를 들어 다음 함수는 vector에 담긴 정수의 산술 평균(arithmetic mean)을 구합니다.
double arithmeticMean(const std::vector<int>& values)
{
double sum{ std::accumulate(values.cbegin(), values.cend(), 0.0) };
return sum / values.size();
}accumulate() 알고리즘은 합에 대한 초기값을 세 번째 매개변수로 받습니다. 여기서는 처음부터 새로 구하도록 0.0을 지정했습니다.
accumulate()의 두 번째 형태는 디폴트 연산인 덧셈 대신 다른 연산을 직접 지정할 수 있습니다. 이때 연산은 이진 콜백(binary callback: 인수가 두 개인)로 표현합니다. 예를 들어 주어진 원소에 대해 기하 평균(geometric mean)을 구하도록 지정할 수 있습니다. 아래 코드에서 accumulate()는 덧셈 대신 곱셈 연산을 수행합니다.
int product(int value1, int value2) { return value1 * value2; }
double geometricMean(const std::vector<int>& values)
{
int mult{ std::accumulate(values.cbegin(), values.cend(), 1, product) };
return pow(mult, 1.0 / values.size()); // pow() needs <cmath>
}여기서 product() 함수를 accumulate()의 콜백으로 전달하고, accumulate()의 초기값을 0이 아닌 1(곱셈의 항등원)로 지정했습니다.
product() 함수 대신, 람다 표현식을 사용하면 다음과 같이 geometricMean() 함수를 작성할 수 있습니다.
double geometricMean(const std::vector<int>& values)
{
int mult{ std::accumulate(values.cbegin(), values.cend(), 1,
[](int value1, int value2) { return value1 * value2; }) };
return pow(mult, 1.0 / values.size()); // pow() needs <cmath>
}또한, 표준 라이브러리에서 제공하는 multiplies<> 함수 객체를 사용하여 geometricMean() 함수를 작성할 수도 있습니다.
double geometricMean(const std::vector<int>& values)
{
int mult{ std::accumulate(values.cbegin(), values.cend(), 1, std::multiplies<>{}) };
return pow(mult, 1.0 / values.size()); // pow() needs <cmath>
}
3. 알고리즘과 이동 의미론
표준 라이브러리의 컨테이너와 마찬가지로 알고리즘도 필요에 따라 이동 의미론(move semantics)을 적용해서 최적화할 수 있습니다. 즉, 무거운 복사 연산 대신 객체를 이동시킬 수 있다는 것입니다. 이는 특정 알고리즘의 속도를 향상시킬 수 있는데, 예를 들어, remove()와 같은 알고리즘에 이동 의미론을 적용시켜 속도를 향상시킬 수 있습니다. 그러므로, 컨테이너에 들어갈 원소의 클래스를 직접 정의할 때 가능하면 이동 의미론을 구현하는 것이 좋습니다. 이동 의미론을 구현하려면 클래스에 이동 생성자와 이동 대입 연산자를 구현하면 되는데, 이때 둘다 예외를 던지면 안되기 때문에 noexcept을 지정해주어야 합니다.
4. Algorithm Callbacks
콜백의 여러 복사본이 만들어질 수 있다는 사실은 이러한 콜백의 부작용에 대해 강력한 제약을 가합니다. 기본적으로 콜백은 반드시 stateless(상태가 없는)이어야 합니다. 함수에서 stateless의 의미는 함수 호출 연산자가 const로 지정되어야 한다는 것입니다. 그러므로 동일한 객체에서 함수 호출 간에 내부 상태에 영향을 미치는 함수는 작성할 수 없다는 것입니다. 람다 표현식도 유사한데, 람다 표현식에서 mutable이 지정될 수 없습니다.
여기에 몇 가지 예외가 있습니다. generate()와 generate_n() 알고리즘은 상태가 있는 콜백을 전달받을 수 있습니다만, 이것은 콜백에 대해 하나의 복사본만 만듭니다. 게다가 복사본을 리턴하지 않으므로 알고리즘의 동작이 완료되었을 때, 변경된 상태에 액세스할 수 없습니다. 이에 대해 유일한 예외는 for_each() 알고리즘입니다. for_each()에 전달된 콜백은 한 번 복사되고, 복사된 것은 알고리즘이 완료되었을 때 리턴됩니다. 이 리턴된 값을 통해 변경된 상태에 액세스할 수 있습니다.
이렇게 알고리즘에 의해서 콜백의 복사본을 만들지 않도록 하기 위해서는 std::ref() 헬퍼 함수를 사용하여 콜백 레퍼런스를 알고리즘에 전달하면 됩니다. 이렇게 하면 알고리즘이 항상 동일한 콜백을 사용하도록 할 수 있습니다.
예를 들어, 다음의 코드는 위에서 살펴본 코드에서 isPerfectScore라는 변수에 저장된 람다 표현식을 사용하고 있습니다. 이 람다 표현식은 이 함수가 몇 번 호출되었는지 카운트하여 그 횟수를 출력합니다. isPerfectScor는 find_if() 알고리즘에 전달됩니다. 마지막 문장은 명시적으로 isPerfectScore는 한 번 더 호출하도록 합니다.
#include <iostream>
#include <vector>
#include <algorithm>
int main()
{
std::vector<int> myVector;
while (true) {
std::cout << "Enter a test score to add (0 to stop): ";
int score;
std::cin >> score;
if (score == 0) { break; }
myVector.push_back(score);
}
auto isPerfectScore{ [tally = 0] (int i) mutable {
std::cout << ++tally << std::endl;
return i >= 100; } };
auto endIt{ myVector.cend() };
auto it{ std::find_if(myVector.cbegin(), endIt, isPerfectScore) };
if (it != endIt) {
std::cout << "Found a \"perfect\" score of " << *it << std::endl;
}
isPerfectScore(1);
}위 코드의 출력은 다음과 같습니다.
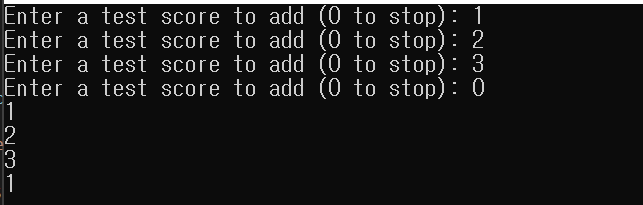
출력을 보면, find_if() 알고리즘은 isPerfectScore를 3번 호출하고, 1,2,3을 출력합니다. 마지막 문장은 명시적으로 isPerfectScore를 호출하는데, 이때 호출되는 isPerfectScore는 처음에 find_if()를 통해 호출된 것과 다른 인스턴스입니다. 따라서 마지막 문장에서 호출되는 isPerfectScore는 다시 1부터 시작하게 됩니다. (find_if()에 전달된 콜백이 복사됨)
만약 find_if()를 다음과 같이 호출하도록 변경하면,
auto it{ std::find_if(myVector.cbegin(), endIt, std::ref(isPerfectScore)) };출력은 1, 2, 3, 4되며, isPerfectScore의 복사본을 생성하지 않는다는 것을 확인할 수 있습니다.
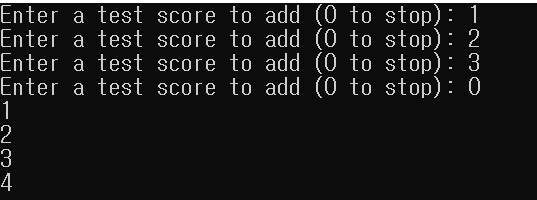
이번 포스팅에서는 표준 라이브러리 알고리즘에 대해 간략하게 알아봤습니다. 다음 포스팅에서는 주제 항목마다 자주 사용되는 대표 알고리즘들에 대해 예제와 함께 살펴보도록 하겠습니다.
'프로그래밍 > C & C++' 카테고리의 다른 글
| [C++] 알고리즘 (Algorithms) (3) (0) | 2022.02.26 |
|---|---|
| [C++] 알고리즘 (Algorithms) (2) (0) | 2022.02.26 |
| [C++] 템플릿 (Templates) (0) | 2022.02.24 |
| [C/C++] 가변 인자 리스트 (0) | 2022.02.23 |
| [C++] Lambda Expression (람다 표현식) (0) | 2022.02.23 |




댓글