References
- Programming Massively Parallel Processors
- CUDA Toolkit Documentation
- https://github.com/nvidia/cuda-samples
Contents
- CUDA Thread Organization
- Built-in variables : threadIdx, blockIdx, blockDim, gridDim
- Mapping threads to multidimensional data
CUDA Thread Organization
지난 포스팅에서 기본적인 CUDA 프로그래밍에 대한 것들을 살펴보고, 예제로 vector addition을 구현해보았습니다.
CUDA 프로그래밍 기초 (예제 : vector addition)
CUDA 프로그래밍 기초 (예제 : vector addition)
References CUDA Toolkit Documentation Programming Massively Parallel Processors Contents 간략한 GPU와 CUDA 요약 데이터 병렬화(Data Parallelism) CUDA 프로그램 구조 벡터 덧셈(vector addition) 예제 Ker..
junstar92.tistory.com
이번 포스팅에서 먼저 CUDA 스레드 구조를 다시 한번 살펴보겠습니다.
그리드 내부의 모든 CUDA 스레드는 같은 커널 함수를 수행합니다. 그리고 그 스레드들은 서로 구별하고 처리할 데이터에 접근하기 위해서 자체 좌표를 사용합니다. 이러한 스레드는 2-level의 계층으로 구성되어 있는데, 하나의 그리드(grid)는 블록(block)들로 구성되고, 각 블록은 하나 이상의 스레드(thread)들로 구성됩니다. 하나의 블록 안에 존재하는 모든 스레드는 동일한 블록 인덱스를 공유하고, 이 인덱스 값은 커널 안에서 blockIdx 변수의 값입니다. 또한, 각 스레드들은 스레드 인덱스를 갖는데, 이 인덱스의 값은 threadIdx 변수의 값입니다.
따라서, 스레드가 커널 함수를 수행할 때, blockIdx와 threadIdx 변수를 참조하여 해당 스레드의 좌표를 알 수 있습니다. 커널 실행(launch) 구문에서 execution configuration parameters(<<<...>>>)로 그리드와 각 블록의 dimension을 지정합니다. 이 dimension의 크기는 커널 함수 내에서 gridDim과 blockDim 변수로 확인할 수 있습니다.
Execution Configuration
일반적으로 그리드는 3차원 배열의 블록이고, 각 블록은 3차원 배열의 스레드로 구성됩니다. 커널 함수를 호출할 때, execution configuration parameter로 그리드의 크기와 블록의 크기를 지정해주어야 합니다.
다음의 커널 함수가 선언되어 있을 때,
__global__ void kernelFunc(float* parameter);해당 커널은 다음과 같이 호출될 수 있습니다.
kernelFunc<<<dimGrid, dimBlock, Ns, S>>>(parameter);각 execution configuration parameter는 다음과 같습니다.
- dimGrid : dim3 type, 그리드의 사이즈(x, y, z)를 지정합니다. dimGrid.x * dimGrid.y * dimGrid.z의 값은 블록의 크기와 같습니다.
- dimBlock : dim3 type, 각 블록의 사이즈(x, y, z)를 지정합니다. dimBlock.x * dimBlock.y * dimBlock.z의 값은 블록당 스레드의 개수와 같습니다.
- Ns : size_t type, 블록당 동적으로 할당되는 공유 메모리의 크기(byte 단위)를 지정합니다. 생략할 수 있으며, 기본값은 0입니다.
- S : cudaStream_t type, 연관된 stream을 지정합니다. 이 파라미터도 생략할 수 있으며, 기본값은 0으로 설정됩니다.
이번 포스팅에서 Ns와 S는 사용하지 않으므로, 자세한 설명은 생략하도록 하겠습니다.
이번 포스팅에서는 dimGrid와 dimBlock에 집중해보도록 하겠습니다. 이 파라미터는 dim3 타입이며, x,y,z 3개의 unsigned int를 갖는 구조체입니다.
예를 들어, host 코드에서 커널 함수(kernelFunc)을 호출하여 각 블록은 128개의 스레드를 갖고, 32개의 블록으로 구성된 1차원의 그리드를 생성한다고 가정해봅시다. 그렇다면 그리드 안의 총 스레드 개수는 128 x 32 = 4096이 됩니다.
dim3 dimGrid(32, 1, 1); dim3 dimBlock(128, 1, 1); kernelFunc<<<dimGrid, dimBlock>>>(...);
이처럼 사용하지 않는 차원의 크기는 1로 설정하면 되는데, 사용하지 않는 차원의 값을 지정하지 않는다면 기본값으로 1로 설정되어서 해당 차원은 사용되지 않는 것으로 설정됩니다.
편의성을 위해서 CUDA에서는 그리드와 블록의 차원이 1차원인 경우에는 다음과 같이 스칼라 값을 사용할 수도 있습니다. 아래의 경우에서 CUDA 컴파일러는 주어진 값을 x 차원의 값으로 받아들이고, 나머지 차원의 값들은 1로 간주합니다.
kernelFunc<<<32, 128>>>(paramter);위 커널도 동일하게 총 4096개의 스레드를 생성합니다.
그리드와 블록의 차원은 다른 변수에 의해서 계산될 수도 있는데, 다음과 같이 사용할 수 있습니다.
dim3 dimGrid(ceil(n/256.0), 1, 1); dim3 dimBlock(256, 1, 1); vecAddKernel<<<dimGrid, dimBlock>>>(...);
vector addition을 위한 커널 함수를 예시로 사용했습니다. 위 코드는 블록의 사이즈를 256으로 고정시키고, 주어진 n에 따라서 그리드의 크기가 결정됩니다. n은 주어진 벡터의 크기이고, 만약 n이 1000이라면 그리드는 4개의 블록으로 구성될 것입니다. n이 4000이라면, 그리드는 16개의 블록을 갖게되겠죠.
커널 함수 내에서 gridDim과 blockDim의 x값은 execution configuration parameters에 의해서 미리 초기화됩니다. 만약 n이 4000이라면, vecAddKernel 함수 내에서 gridDim.x는 16으로 초기화되고, blockDim.x는 256으로 초기화됩니다. 즉, 커널에서의 gridDim과 blockDim은 그리드와 블록의 차원을 반영합니다.
CUDA에서 gridDim.x, gridDim.y, gridDim.z의 값은 1에서 65,536까지의 값이 허용됩니다. 한 블록 안의 모든 스레드들은 동일한 blockIdx.x, blockIdx.y, blockIdx.z 값을 공유합니다. 블록에 따라서, blockIdx.x의 값은 0부터 gridDim.x-1까지의 값을 가지고, blockIdx.y는 0에서 gridDim.y-1까지, blockIdx.z는 0에서 gridDim.z-1까지의 값을 가지게 됩니다.
각 블록은 3차원의 스레드 배열로 구성되어 있다고 했습니다. 그래서 2차원만 사용하는 블록의 경우에는 blockDim.z의 값이 1로 설정됩니다. 1차원만 사용하는 블록의 경우에는 blockDim.y, blockDim.z가 모두 1로 설정됩니다. 이 케이스가 바로 위에서 vecAddKernel 예제 코드에서 사용된 경우입니다.
한 블록의 크기가 1024 스레드라고 한다면, 1024를 벗어나지 않으면서 블록의 각 차원은 적절하게 분배할 수 있습니다. 예를 들어, 다음과 같이 다양한 차원의 블록 사이즈를 설정할 수 있지만, 마지막의 경우에는 총 스레드 수가 1024를 초과하므로 우리의 조건에서는 올바르지 않습니다.
blockDim(512, 1, 1) // total threads = 512 blockDim(8, 16, 4) // total threads = 8*16*4 = 512 blockDim(32, 16, 2) // total threads = 32*16*2 = 1024 blockDim(32, 32, 2) // impossible, total threads = 32*32*2 = 2048
작은 크기의 그리드와 블록 사이즈로 조금 더 자세하게 살펴보도록 하겠습니다.
dim3 dimGrid(2, 2, 1); dim3 dimBlock(4, 2, 2); kernelFunc<<<dimGrid, dimBlock>>>(...);
위의 경우, 4개의 블록으로 구성된 그리드는 2x2 배열로 구성됩니다. 각 블록은 아래 이미지의 Grid 1에 나와있는 것처럼 (blockIdx.y, blockIdx.x)로 라벨링되어 있습니다. Block(1,0)인 경우에는 blockIdx.y = 1, blockIdx.x = 0 입니다.

각 threadIdx 또한 3개의 차원으로 구성됩니다. x 좌표는 threadIdx.x, y 좌표는 threadIdx.y, z 좌표는 threadIdx.z 입니다. 예시에서 각 블록은 4x2x2 스레드 배열로 구성되어 있습니다. 그리드 내에 모든 블록은 같은 차원이기 때문에 위 이미지에서 Block(1,1)만 확대하여 보여주고 있습니다. Block(1,1)에는 총 16개의 스레드가 있으며, Thread(1,0,2)는 threadIdx.z = 1, threadIdx.y = 0, threadIdx.x = 2입니다.
이 이미지는 각 16개의 스레드로 구성된 4개의 블록을 보여주고 있으며, 총 64개의 스레드가 그리드에 존재합니다.
위 예시의 좌표 표기는 z축부터 표기되어 있습니다. (z, y, x)
Mapping threads to multidimensional data
커널에 의해서 생성되는 스레드들이 어떤 구조를 갖는지 알아봤으니, 이제 각 스레드들을 어떻게 처리할 데이터에 매핑하는지에 대해서 알아보겠습니다. 이전 포스팅에서 스레드 구조의 차원을 선택할 때에는 보통 데이터의 차원에 맞추어서 선택한다고 언급했었습니다.
2차원 픽셀 배열의 이미지를 예제로 살펴보겠습니다. 그렇다면 데이터가 2차원 배열의 데이터가 되고, 우리는 2차원 블록으로 구성된 2차원의 그리드를 사용하여 이 이미지를 처리하는 것이 편리합니다. 아래 이미지는 76x62 픽셀의 이미지를 보여줍니다. (height : 76, width : 62)
만약 우리가 16x16 블록을 사용한다고 결정했다면, 이 블록은 x 방향으로 16스레드, y방향으로 16스레드를 가집니다. 계산해보면 x축 방향으로 총 5개의 블록이 필요하고, y축 방향으로는 총 4개의 블록이 필요하다는 것을 알 수 있습니다. 따라서, 위 이미지에서 알 수 있듯이 우리는 픽셀 데이터을 처리하기 위해서 총 5x4=20개의 블록이 필요합니다.
(위 이미지에서 굵은 선은 블록의 경계를 나타내고, 짙게 칠해진 부분이 픽셀 데이터입니다.)
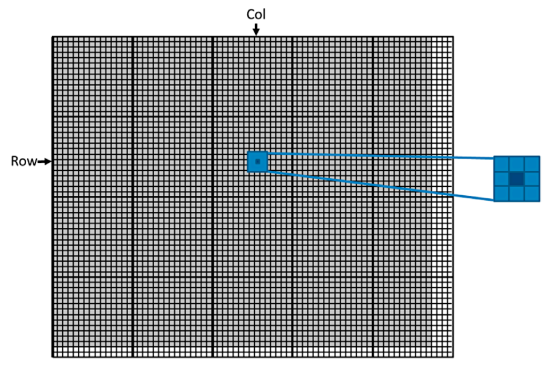
픽셀 데이터를 Pin 이라고 한다면, block(1,0)에 있는 thread(0,0)에서 처리되는 Pin element는 다음과 같이 계산할 수 있습니다.
살펴보면 우리가 처리해야되는 픽셀 데이터보다 스레드의 크기가 더 크다는 것을 볼 수 있습니다. 커널은 80x64 스레드를 생성하지만, 처리해야되는 데이터는 76x62 픽셀입니다. 위에서 vecAddKernel에 1차원의 256 스레드 블록을 사용하여 1000개의 요소를 가지는 벡터를 처리할 때와 유사한 경우입니다. 이 경우 나머지 24개의 스레드는 계산이 되지 않도록 if문으로 처리를 해주었습니다.
(vecAddKernel은 이전 포스팅을 참조해주세요:CUDA 프로그래밍 기초 (예제 : vector addition))
마찬가지로 픽셀 데이터 처리에서도 스레드 인덱스에 따라서 유효한 범위의 픽셀들만 처리가 되도록 해주어야 합니다.
처리해야될 이미지의 가로 픽셀의 수가 width이고, 세로 픽셀의 수가 height이라고 가정해봅시다. 2차원 커널을 실행하는 colorToGreyscaleConversion 커널 함수는 host 코드에서 다음과 같이 작성할 수 있습니다.
const int block_size = 16; dim3 threads(block_size, block_size); dim3 grid(ceil(width / (double)threads.x), ceil(height / (double)threads.y)); colorToGreyscaleConversion<<<grid, threads>>>(d_origImg, d_resultImg, width, height);
위 코드에서 블록의 사이즈는 16x16으로 고정하고, 그리드의 차원은 입력 이미지의 크기에 의해서 결정됩니다. 예를 들어, 2000x1500 크기를 가지는 이미지를 처리하기 위해서 우리는 125 x 94 차원 크기를 갖는 블록을 생성해야 합니다. 그렇다면 커널 안에서 gridDim.x, gridDim.y, blockDim.x, blockDim.y는 각각 125, 94, 16, 16의 값을 가지게 됩니다.
이제 colorToGreyscaleToConversion 커널 함수의 코드를 살펴보겠습니다. 커널의 코드는 컬러 이미지를 흑백으로 변환하기 위해서 다음의 공식을 사용합니다.
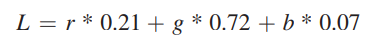
// Input image has 3 channels corresponding to RGB // The input image is encoded as unsigned characters [0, 255] __global__ void colorToGreyscaleConversion(unsigned char* in, unsigned char* out, int width, int height) { int Row = blockIdx.y * blockDim.y + threadIdx.y; int Col = blockIdx.x * blockDim.x + threadIdx.x; if (Row < height && Col < width) { int offset = Row*width + Col; int rgbOffset = offset*CHANNELS; unsigned char r = in[rgbOffset]; // red value for pixel unsigned char g = in[rgbOffset + 1]; // green value for pixel unsigned char b = in[rgbOffset + 2]; // blue value for pixel out[offset] = 0.21f * r + 0.71f * g + 0.07f * b; } }
각 스레드에서 처리되는 데이터의 Row, Col의 값은 line 6, 7의 식으로 계산할 수 있습니다. 이 Row, Col 값은 스레드의 위치를 의미하는 좌표이므로 픽셀 데이터의 크기(width, height)를 초과할 수 있다는 것에 주의해야합니다. 따라서, 유효한 범위의 픽셀 데이터만 처리할 수 있도록, line 9처럼 체크를 해주어야 합니다.
여기서 2차원의 배열은 C 스타일로 1차원으로 표현됩니다.
그리고 입력으로 주어지는 이미지는 r,g,b값을 가지고 있는 3채널의 컬러 이미지이고, 각 인덱스의 픽셀은 (r,g,b)의 값이 저장되어 있기 때문에 input image의 r,g,b 값에 접근할 때 grey 이미지 픽셀 인덱스의 3배를 곱해서 접근해야합니다.
따라서, 76x62의 입력 이미지를 사용할 때, block(1,0)의 thread(0,0)에서 처리되는 output 이미지의 픽셀 인덱스는
이고, 이에 해당되는 input 이미지의 픽셀 인덱스는
이 됩니다.
in[0]은 (0,0) 픽셀의 r, in[1]은 (0,0) 픽셀의 g, in[2]은 (0,0) 픽셀의 b, in[3]은 (0,1) 픽셀의 r,... 이런식으로 인덱싱됩니다.

위 이미지는 colorToGreyscaleConversion 커널 함수가 실행될 때 76x62크기의 이미지를 처리하는 것을 보여줍니다. 16x16 블록을 사용할 때, 이 커널은 80x64 스레드를 생성하고, x축 방향으로 5 블록, y축 방향으로 4 블록이므로 총 20개의 블록을 생성합니다.
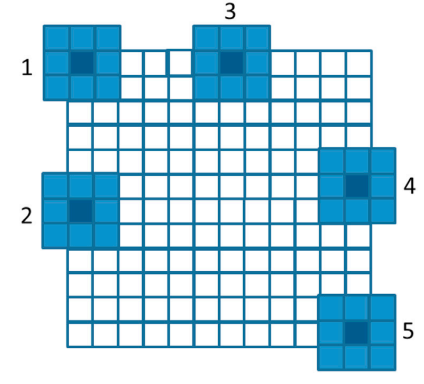
블록들의 스레드들이 수행될 때, 몇 가지 다른 케이스들을 위 이미지에서 표시해두었는데 하나씩 살펴보겠습니다.
먼저 1로 마킹된 구역은 12개의 블록에 존재하는 모든 스레드들이 입력 이미지의 픽셀 데이터에 액세스하여 데이터를 처리합니다. 따라서 모든 스레드들이 if문의 조건을 만족하여 흑백변환을 위한 계산을 수행하게 됩니다.
두 번째로 2로 마킹된 구역은 커널 함수 내에서 Row의 값은 항상 만족하지만, Col의 값은 76(width)를 초과할 때가 있습니다. 2번 구역에서 짙게 칠해지지 않은 부분이 if문을 만족하지 못하여 데이터 처리가 수행되지 않는 스레드들을 나타냅니다. 3으로 마킹된 구역도 2번과 유사합니다. Col의 값은 항상 만족하지만, Row의 값은 62(height)를 초과하는 스레드가 있습니다. 마찬가지로 3번 구역에서 짙게 칠해지지 않은 부분이 이에 속하며, 이 스레드들은 데이터 처리 연산이 수행되지 않습니다.
마지막으로 4번으로 마킹된 구역은 모든 스레드들의 Col과 Row 값이 각각 width, height를 초과합니다. 따라서 4번 구역에 속하는 모든 스레드들은 픽셀 처리를 위한 연산을 수행하지 않습니다.
이제 구현한 커널 함수를 실행해보도록 하겠습니다.

위의 입력 이미지를 colorToGreyscaleConversion 커널 함수로 처리하면, 다음의 결과 이미지를 얻을 수 있습니다.

아래 코드는 colorToGreyscaleConversion 커널 함수를 실행하기 위한 host 코드인 main 함수입니다. 이미지를 읽고, 별도의 창으로 결과 이미지를 표시하기 위해서 OpenCV libarary(OpenCV 4.2.0)를 사용하였습니다.
int main(int argc, char** argv) { if (argc != 2) { Usage(argv[0]); } const char* file_name = argv[1]; int width, height, channels; unsigned char *h_origImg, *h_resultImg; // open image file cv::Mat origImg = cv::imread(file_name); width = origImg.cols; height = origImg.rows; channels = origImg.channels(); printf("Image size = (%d x %d x %d)\n", width, height, channels); assert(channels == CHANNELS); cv::Mat half; cv::resize(origImg, half, cv::Size(width/2, height/2)); cv::imshow("image", half); cv::waitKey(0); h_origImg = (unsigned char*)malloc(width * height * channels * sizeof(unsigned char)); h_resultImg = (unsigned char*)malloc(width * height * sizeof(unsigned char)); (void)memcpy(h_origImg, origImg.data, width * height * channels); unsigned char *d_origImg, *d_resultImg; CUDA_CHECK(cudaMalloc((void**)&d_origImg, width * height * channels * sizeof(unsigned char))); CUDA_CHECK(cudaMalloc((void**)&d_resultImg, width * height * sizeof(unsigned char))); // Copy the host input in host memory to the device input in device memory CUDA_CHECK(cudaMemcpy(d_origImg, h_origImg, width * height * channels * sizeof(unsigned char), cudaMemcpyHostToDevice)); // Launch the Matrix Add CUDA Kernel const int block_size = 16; dim3 threads(block_size, block_size); dim3 grid(ceil(width / (double)threads.x), ceil(height / (double)threads.y)); colorToGreyscaleConversion<<<grid, threads>>>(d_origImg, d_resultImg, width, height); // Copy the device result in device memory to the host result in host memory CUDA_CHECK(cudaMemcpy(h_resultImg, d_resultImg, width * height * sizeof(unsigned char), cudaMemcpyDeviceToHost)); cv::Mat resultImg(height, width, CV_8UC1); memcpy(resultImg.data, h_resultImg, width * height); // Free device global memory CUDA_CHECK(cudaFree(d_origImg)); CUDA_CHECK(cudaFree(d_resultImg)); // Free host memory free(h_origImg); free(h_resultImg); // show result //cv::Mat resizeImg; cv::resize(resultImg, resultImg, cv::Size(width/2, height/2)); cv::imshow("image", resultImg); cv::waitKey(0); return 0; }
전체 코드는 다음 링크를 참조해주시고, 코드의 세부 정보는 코드 내의 주석을 참조부탁드립니다 !
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
Image Blur
3차원의 블록을 사용하여 이미지를 블러 처리하는 커널을 구현해봤습니다. 입력으로 사용되는 이미지는 위의 흑백 변환 예제와 동일한 방식으로 이미지 데이터가 인덱싱되어 있습니다.
다음 커널 함수 blurKernel은 z축 방향의 인덱스를 구한 Plane을 사용하여, 각 채널의 픽셀 값에 접근합니다.
__global__ void blurKernel(unsigned char* in, unsigned char* out, int width, int height, int channel) { int Plane = blockIdx.z * blockDim.z + threadIdx.z; int Row = blockIdx.y * blockDim.y + threadIdx.y; int Col = blockIdx.x * blockDim.x + threadIdx.x; if (Row < height && Col < width && Plane < channel) { int pixelVal = 0; int pixelCnt = 0; for (int bRow = -BLUR_SIZE; bRow < BLUR_SIZE; bRow++) { for (int bCol = -BLUR_SIZE; bCol < BLUR_SIZE; bCol++) { int curRow = Row + bRow; int curCol = Col + bCol; if (curRow >= 0 && curRow < height && curCol >= 0 && curCol < width) { pixelVal += in[(curRow * width + curCol) * channel + Plane]; pixelCnt++; } } } out[(Row * width + Col) * channel + Plane] = (unsigned char)(pixelVal / pixelCnt); } }
이미지 블러는 구하고자 하는 픽셀과 그 주변 픽셀들의 평균을 계산하여 적용할 수 있습니다. 그리고 구하고자 하는 픽셀에서 얼마만큼 떨어진 픽셀들까지의 평균을 구할 것인가를 결정해주는 필터 크기를 따로 정할 수 있는데, 아래 이미지에서는 3x3 patch를 사용한 예시 이미지입니다. 3x3 patch를 사용하면 구하고자하는 픽셀과 1만큼 떨어진 위치의 픽셀들과의 평균을 구하게 됩니다. (아래 이미지는 하나의 채널에서의 데이터 구조를 보여주고 있습니다.)
한 가지 주의해야 할 점은 이미지의 경계에 위치하는 픽셀들을 계산할 때입니다.
경계에 위치하는 픽셀들의 주변 픽셀은 유효하지 않은 범위가 포함되기 때문에 이를 확인해주는 방어 코드가 필요하고, 유효하지 않은 위치는 평균에 포함시키지 않아야 합니다. 이 확인 과정이 코드의 line 17에 위치하고 있습니다.
각 채널 별로 위 계산을 수행해주면 되는데, 각 채널은 Plane 변수로 구분됩니다.
커널의 그리드와 블록 사이즈는 host 코드에서 아래처럼 계산되어 커널을 호출합니다.
const int block_size = 16; dim3 threads(block_size, block_size, channels); dim3 grid(ceil(width / (double)threads.x), ceil(height / (double)threads.y)); blurKernel<<<grid, threads>>>(d_origImg, d_resultImg, width, height, channels);
각 블록의 사이즈는 16x16x3인 3차원의 스레드 블록이며, 그리드는 2차원의 사이즈입니다.
전체 코드는 아래 링크를 참조하시기 바랍니다.
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
위 코드를 컴파일하고 실행해주면, 다음과 같이 blur 처리된 이미지를 확인하실 수 있습니다.

'NVIDIA > CUDA' 카테고리의 다른 글
| CUDA의 메모리 Access와 Type (예제 : matrix multiplication) (0) | 2021.12.05 |
|---|---|
| CUDA Thread 동기화 및 스케쥴링 / 리소스 할당 (0) | 2021.12.04 |
| CUDA Programming Model (1) | 2021.12.03 |
| CUDA 프로그래밍 기초 (예제 : vector addition) (2) | 2021.12.02 |
| GPU와 CUDA (0) | 2021.11.30 |




댓글