References
- CUDA Toolkit Documentation
- Programming Massively Parallel Processors
Contents
- 간략한 GPU와 CUDA 요약
- 데이터 병렬화(Data Parallelism)
- CUDA 프로그램 구조
- 벡터 덧셈(vector addition) 예제
- Kernel Function
- Built-in variables (blockDim, threadIdx, blockIdx)
지난 포스팅에서 GPU와 CUDA에 대해서 간략하게 알아봤습니다.
GPU와 CUDA
References CUDA Toolkit Documentation Programming Massively Parallel Processors Contents CPU와 GPU, CUDA 도입 간략한 GPU Architecture 이번 포스팅을 시작으로 GPU에 관련하여 기본적인 것들을 먼저 알아..
junstar92.tistory.com
이번 포스팅에서는 CUDA Toolkit Documentation에서 언급하는 내용들을 통해 이전 포스팅의 내용들을 짧게 복습하고, CUDA 프로그래밍에 대해서 조금 알아보도록 하겠습니다.
The Benefits of Using GPUs
GPU는 비슷한 가격과 Power envelope을 갖는 CPU에 비해서 더 높은 명령어 처리량을 제공합니다. 이 때문에 많은 어플리케이션에서 CPU보다 GPU에서 더 빠르게 실행됩니다(데이터 연산이 많이 필요한 어플리케이션에서). FPGA와 같은 다른 연산 장치들도 에너지 효율이 매우 좋지만, GPU보다는 프로그래밍 유연성은 떨어집니다.
CPU와 GPU의 차이는 서로 다른 목표를 가지고 설계되었기 때문입니다. CPU는 multi-core(각 코어당 2개의 스레드)를 목표로 순차 프로그램의 속도, 즉 순차적인 명령(연산)을 빨리 실행하도록 설계되었지만, GPU는 수천 개의 스레드(CPU 스레드보다 더 느린)를 병렬로 실행하는데 특화되도록 설계되었습니다.
GPU는 병렬 연산에 특화되어 있어서 트랜지스터들이 data caching이나 flow control보다는 data processing에 집중하도록 설계되었습니다. 아래 이미지는 CPU와 GPU의 칩 설계를 보여줍니다.

위 설계에서 볼 수 있듯이 CPU에서는 명령어와 데이터 액세스 지연시간을 줄이기 위해서 대용량의 캐시 메모리가 제공됩니다. 아시다시피 캐시 메모리는 연산 속도에는 영향을 끼치지 못합니다.
GPU는 더 많은 트랜지스터를 데이터 처리(ex, 부동소수점 연산)에 할당하여 병렬 연산에 유용합니다.
일반적으로 어플리케이션에는 병렬로 실행되는 부분과 순차적으로 실행되는 부분이 혼합되어 있으므로, 시스템은 전반적인 성능을 극대화하기 위해서 GPU와 CPU를 혼합하여 설계됩니다. 병렬화가 높은 어플리케이션은 GPU의 대규모 병렬 연산 특성을 활용하여 CPU보다 더 높은 성능을 달성할 수 있습니다.
CUDA : 범용 병렬 컴퓨팅 플랫폼/모델
2006년 11월, NVIDIA는 NVIDIA GPU의 병렬 컴퓨팅 엔진을 활용하여 CPU보다 더 효율적인 방법으로 많은 복잡한 계산 문제를 해결할 수 있는 범용(general purpose) 병렬 컴퓨팅 플랫폼 및 프로그래밍 모델인 CUDA를 발표했습니다. CUDA는 C++과 같은 고수준 프로그래밍 언어를 사용할 수 있는 소프트웨어 환경을 갖추고 있고, 아래 이미지처럼 다른 언어나 다른 어플리케이션 프로그래밍 인터페이스 또는 지시어 기반(directive-based) 방식도 지원합니다. (ex, 포트란, DirectCompute, OpenACC 등)
CUDA 병렬 프로그래밍 모델은 C와 같은 표준 프로그래밍 언어에 익숙한 프로그래머들이 쉽게 배울 수 있도록 설계되었습니다. 그 중심에는 최소한의 확장으로 프로그래머가 간단하게 접근할 수 있는 thread group의 계층, shared memory, barrier synchronization라는 3가지의 key abstractions가 있습니다. 이러한 key abstractions는 세밀한 데이터 병렬화와 스레드 병렬화를 제공합니다. 이것들은 프로그래머가 주어진 문제를 스레드 블록에 의해 병렬화하여 독립적으로 해결할 수 있는 하위 문제들로 나누고, 각 하위 문제들은 블록 내의 스레드들에 의해 더 세부 문제로 분할하여 해결할 수 있도록 합니다.
각 하위 문제를 해결할 때 스레드가 서로 협력할 수 있도록 함으로써, 프로그래밍 언어 표현성을 유지하면서, 동시에 확장성을 가지도록 합니다. 실제로 각 스레드 블록은 GPU 내에서 사용가능한 multiprocessor들 중에 어느 것이라도 동시에 또는 순차적으로 스케줄링할 수 있습니다. 따라서 컴파일된 CUDA 프로그램은 몇 개의 multiprocessor들이 있던간에 실행될 수 있고, 오직 런타임 시스템만 사용가능한 물리적인 multiprocessor의 수를 알고 있으면 됩니다.
(위 이미지는 또한 GPU가 Streaming Multiprocessor들의 배열로 구성되는 모습을 보여주고 있습니다. 멀티스레딩된 프로그램은 스레드 블락들로 파티셔닝하는데, 더 많은 MPs를 가진 GPU는 더 빠르게 작업을 수행할 수 있습니다.)
Data Parallelism
현대 소프트웨어에서 수행 시간이 느린 경우, 문제는 보통 처리해야할 데이터가 너무 많기 때문입니다. 이미지나 비디오를 처리하는 프로그램은 수백만, 또는 수조 픽셀을 다루어야 하고, 유체동역학을 모델링하는 과학용 프로그램은 수십억의 격자들을 사용합니다. 분자동역학은 수억의 원자 사이의 상호작용을 시뮬레이션하고, 항공 스케쥴링은 수천의 비행기, 승무원 그리고 공항 게이트를 다룹니다.
중요한 것은, 픽셀이나 입자, 격자와 같은 데이터들은 크게 독립적으로 처리될 수 있습니다.
컬러 픽섹을 흑백으로 변경하는 것은 해당 픽셀 정보만 있으면 됩니다. 이미지를 블러(blur) 처리하는 것은 주변 픽셀들의 값들의 평균을 구하면 되는데, 이 경우에도 오직 매우 적은 주변 일부 픽셀들의 값들만 사용됩니다. 이미지의 모든 픽셀의 평균 밝기를 구하는 것과 같이 데이터 전체를 계산해야될 것처럼 보이는 작업도 독립적으로 병렬로 구할 수 있습니다. 이렇게 독립적으로 가능하다고 평가하는 것이 데이터 병렬화(Data Parallelism)의 기초입니다.
이번 포스팅에서 컬러 이미지를 흑백으로 변환하는 작업이 어떻게 데이터 병렬화 컨셉으로 가능한지 간단하게 살펴보겠습니다. 이후의 다른 포스팅에서 이미지 처리(흑백 변환, 블러 처리)를 위한 예제 코드를 작성해볼 예정입니다 !
위 이미지의 왼쪽은 각 픽셀이 R(red), G(green), B(blue)의 값들로 구성된 컬러 이미지이고, 오른쪽은 각 픽셀의 값이 0(black)에서 1(full intensity)사이의 값을 가지는 greyscale의 흑백 이미지입니다.
RGB Color Image Representation
RGB를 표현하는 방법 중 한 가지는 이미지의 각 픽셀을 (r, g, b) 값으로 이루어진 tuple로 저장하는 것이 있습니다.
컬러 이미지를 greyscale로 변경은 아래의 공식을 적용하면 가능합니다. r, g, b는 컬러 이미지에서 각 픽셀에서 해당되는 R,G,B 값이며, L은 greyscale에서 표현되는 픽셀의 값(휘도, luminance)입니다.
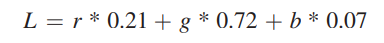
만약 input을 RGB 값들의 배열 I라고 하고, output을 휘도 값을 가지는 대응되는 배열 O라고 한다면, 우리는 아래 이미지와 같은 연산 구조를 얻을 수 있습니다.
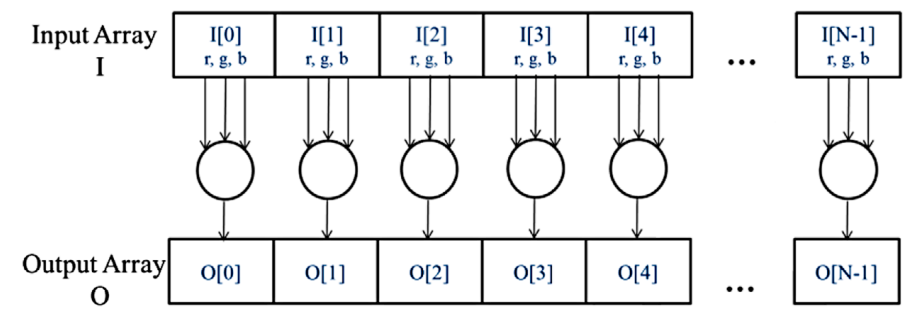
O[0]은 I[0]에서의 RGB 값들의 가중합으로 계산되고, O[1]은 I[1]으로부터, O[2]는 I[2]로부터 계산하여 구할 수 있습니다. 여기서 어떠한 픽셀도 서로에게 영향을 미치지 않으며, 모든 픽셀들이 독립적으로 계산될 수 있습니다. 따라서 컬러-흑백 변환은 데이터 병렬화가 가능합니다.
CUDA 프로그램 구조
이제 더 빠른 연산을 위해 데이터 병렬화를 활용하는 CUDA 프로그램에 대해서 조금 더 알아보도록 하겠습니다. CUDA 프로그램의 구조는 host(CPU)와 한 개 이상의 device(GPUs)로 구성됩니다. CUDA 소스코드는 host와 device 코드가 통합되어 있습니다. 기본적으로 전형적인 C 프로그램은 host 코드로만 구성된 CUDA 프로그램과 동일합니다. device 함수와 데이터를 소스 파일에 추가할 수 있는데, 이 device를 위한 함수나 데이터 선언은 특수한 CUDA C 키워드로 명확하게 표시됩니다.
device function이나 data 선언이 소스 파일에 추가되면, 더이상 일반적인 C 컴파일러로는 컴파일할 수 없습니다. 이 코드는 특수한 CUDA C 키워드를 인식하고 해석할 수 있는 컴파일러에 의해서 컴파일이 되어야하고, 이 컴파일러를 NVCC(NVIDIA C Compiler)라고 합니다.
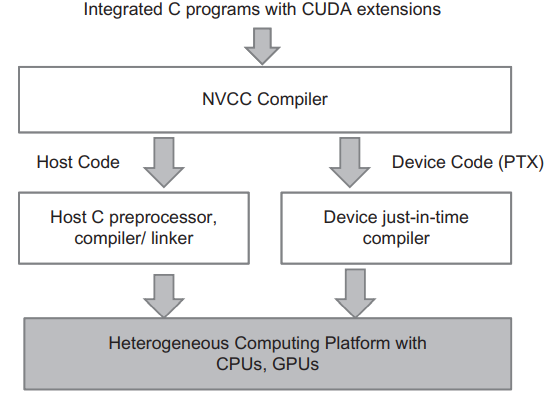
위 이미지는 NVCC 컴파일러가 CUDA 프로그램을 처리하는 것을 보여줍니다. host 코드는 ANSI C 코드이며, 호스트의 표준 C/C++ 컴파일러로 컴파일되고, 일반 CPU 프로세스로 수행됩니다. device 코드에는 커널(kernel)이라는 데이터 병렬화 함수와 관련 helper 함수와 data structures가 CUDA 키워드로 표시되어 있습니다. device 코드는 NVCC의 런타임 구성요소에 의해 컴파일되고 GPU에서 실행됩니다. 만약 사용가능한 device가 없거나 커널이 CPU에서 적절하게 실행될 수 있는 경우에는 MCUDA와 같은 도구를 사용하여 CPU에서 커널을 실행하도록 선택할 수 있습니다.
CUDA에서 커널(kernel)은 device에서 실행되는 함수를 뜻합니다.
CUDA 프로그램은 아래 그림처럼 실행됩니다.
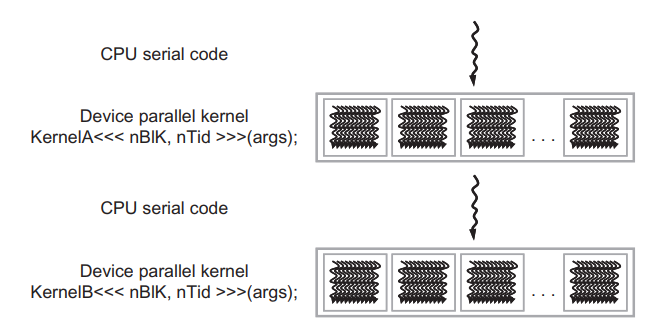
host 코드(CPU serial code)에서 프로그램이 시작되고, 커널 함수(parallel device code)가 호출되면(주로 lauched로 표현됩니다), device에서 수많은 스레드들에 의해서 커널 함수가 수행됩니다. 커널을 실행함으로서 생성되는 모든 스레드를 통칭하여 그리드(grid) 라고 합니다. 이 스레드들은 CUDA 플랫폼에서 병렬 실행을 위한 주요 수단입니다. 위 그림은 두 개의 그리드(by KernelA, KernelB)의 실행을 보여줍니다. 그리드의 구성은 잠시 후에 자세히 살펴보도록 하겠습니다.
아무튼 커널이 호출되고 모든 스레드들이 실행을 완료하여 해당 그리드가 종료되면 다른 커널이 호출될 때까지 host에서 프로그램 수행은 계속됩니다. 위 이미지에서는 CPU와 GPU가 서로 겹쳐져서 실행되지는 않습니다만, 많은 이종 컴퓨팅 프로그램에서는 실제로 CPU와 GPU의 모든 이점을 얻기 위해서 CPU와 GPU 작업 수행이 오버랩되어서 관리됩니다.
커널을 호출하면 일반적으로 데이터 병렬화를 활용하기 위해서 많은 수의 스레드를 생성합니다. 컬러-흑백 변환 예제에서 각 스레드는 output 배열 O의 한 픽셀의 연산에 사용될 수 있습니다. 이 경우 커널에 의해서 생성되는 스레드의 수는 이미지에서 픽셀의 수와 동일할 것입니다. 사이즈가 큰 이미지라면 더 많은 수의 스레드가 생성됩니다. 실제로는 효율성을 위해 각 스레드가 여러 픽셀을 처리하기도 합니다.
CUDA에서는 효율적인 하드웨어의 지원을 받기 때문에 스레드를 생성하고 스케쥴하는 데 단지 몇 사이클밖에 걸리지 않는다고 가정할 수 있습니다. 이는 일반적으로 스레드를 생성하고 스케쥴하는데 수천의 clock cycle이 소요되는 CPU와 대조됩니다.
Vector Addition
CUDA 프로그램 구조를 구체적으로 보여주는 간단한 벡터 덧셈(vector addition) 예제를 살펴보겠습니다. 벡터 덧셈은 매우 간단한 데이터 병렬화 연산의 예제입니다. 벡터 덧셈을 수행하는 커널 함수를 살펴보기 전에, 일반적인 C 프로그램에서 벡터 덧셈(host 코드에서)은 아래의 코드처럼 구현할 수 있습니다.

먼저 host와 device 데이터를 구분할 필요가 있습니다. 이를 쉽게 파악하기 위해서 예제 코드에서는 host에서 처리되는 변수의 이름은 "h_"가 붙어있고, device에서 처리되는 변수의 이름에는 "d_"가 붙어있습니다. 위 코드는 host 코드만을 포함하기 때문에 "h_"가 붙은 변수만을 사용하고 있습니다. 위 코드에서는 많은 부분이 생략되어 있는데, 배열들의 메모리 할당이나 초기화는 main함수에서 수행된다고 가정하도록 하겠습니다. vecAdd 함수에서 벡터 A와 B의 덧셈을 구하는 for-loop로 벡터의 합을 구합니다. 크게 어렵지 않은 부분이니 시리얼 코드에서 자세한 설명은 넘어가도록 하겠습니다.
위 코드를 CUDA를 사용하여 병렬화하기 위해서는 vecAdd 함수를 다음과 같이 수정합니다.
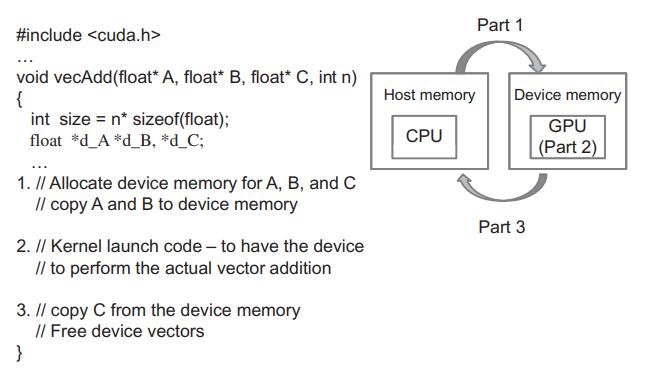
새롭게 수정된 코드는 다음과 같습니다.
먼저 CUDA 런타임 API와 내장된 변수들을 사용하기 위해서 <cuda_runtime.h> 헤더파일을 include합니다.
(Part 1)그리고 vecAdd 함수에서 먼저 device(GPU) 메모리에 A,B,C 벡터의 복사본을 저장하기 위한 공간을 할당합니다. device에 할당된 메모리(device memory)로 host(CPU) memory에 존재하는 A,B의 값을 복사합니다.
(Part 2)그 다음, 실제 벡터 덧셈을 병렬로 수행하는 device의 커널 함수를 호출(launch)합니다.
(Part 3)덧셈이 완료되면 device memory에 저장된 결과 벡터 C의 내용을 다시 host memory로 복사합니다. 그리고 사용이 완료된 device memory의 벡터 A,B,C를 위한 메모리를 해제합니다.
이처럼 CUDA를 사용하여 병렬로 벡터 덧셈을 수행하기 위해서 vecAdd 함수는 device로 input data를 전달하고, device에서의 계산을 수행시킨 다음, 다시 device에서 결과값을 host로 가지고 오는 역할을 합니다.
Device global memory와 data 전달
CUDA 시스템에서 device(GPU)는 device만의 DRAM을 가지고 있습니다. NVIDIA RTX 3080의 경우에는 10GB 메모리의 DRAM이 있으며, 이 메모리는 global memory라고 부릅니다. global memory는 device memory라고 부르기도 합니다. device에서 커널을 수행하기 위해서 프로그래머는 device에 global memory를 할당하고, host memory로부터 계산할 데이터를 전송해야합니다. 이 과정이 vecAdd 함수에서 Part 1에 해당합니다. 그리고 똑같이 device에서 계산이 완료되면, device memory에 있는 결과 데이터를 다시 host memory로 전달해주어야하고, 사용이 완료된 device memory는 더이상 필요가 없게 됩니다. 이 과정이 Part 3에 해당합니다.
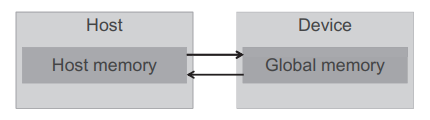
CUDA 런타임 시스템은 이렇게 메모리를 할당하고 전달하는 API를 제공합니다. 위 이미지는 CUDA에서의 host memory와 device memory 모델을 간략하게 보여줍니다. 특히 device memory에는 constand memory, shared memory 등 다양한 타입이 있는데, 이는 나중에 자세하게 알아보도록 하겠습니다. 지금은 global memory의 사용에만 집중하겠습니다.
Part 1과 Part 3에서 벡터 A, B, C를 위한 device memory를 할당하는 것과 사용이 끝난 메모리를 해제하는 API는 cudaMalloc()과 cudaFree()입니다.

두 API는 C언어에서 제공되는 malloc()과 free()와 닮았기 때문에, C언어에 대해서 어느 정도 지식이 있다면 CUDA는 쉽게 배울 수 있습니다.
cudaMalloc 함수의 첫 번째 파라미터는 포인터 변수의 주소값이며, 할당된 메모리를 가리키는 주소값입니다. C언어와 다르게 이 포인터 변수의 주소는 (void**)으로 캐스팅되어야 하는데, 이는 cudaMalloc 함수가 첫 번째 파라미터로 generic pointer를 받도록 되어있기 때문입니다 (즉, 할당되는 메모리 타입에 제한이 없습니다.). 두 번째 파라미터는 할당될 데이터의 크기이며, 단위는 byte입니다.
cudaFree 함수는 포인터 변수가 가리키는 주소, 즉, 포인터 변수를 그대로 파라미터로 전달합니다. 따라서 오직 d_A만 전달하며, d_A의 주소가 아니라는 것에 주의합니다.
두 API를 사용하여 메모리 할당과 해제는 다음과 같이 작성할 수 있습니다. d_B와 d_C도 이와 동일하게 device에 메모리를 할당하고 해제하면 됩니다.

host code에서 device memory를 할당한 후에는 이제 host에서 device로 벡터 값을 전달해야합니다. 이는 cudaMemcpy 라는 CUDA 런타임 API를 사용하여 수행할 수 있습니다.

cudaMemcpy 함수는 4개의 파라미터를 입력받습니다. 첫 번째 파라미터는 데이터가 저장될 destination 메모리를 가리키는 포인터이고, 두 번째 파라미터는 저장할 데이터의 source 메모리를 가리키는 포인터입니다. 세 번째 파라미터는 복사할 데이터의 byte 사이즈입니다. 네 번째 파라미터는 어떤 타입의 메모리가 복사되는지 가리키는 값인데, host memory to device, device to host, 또는 device to device인지 알려주어야 합니다. 이 값은 CUDA에서 정의된 상수값을 사용하면 됩니다. (cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, ...)
따라서, host memory에서 h_A와 h_B의 값을 device memory인 d_A와 d_B로 복사할 때에는
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
위와 같이 코드를 작성하면 되고,
반대로 device memory의 d_C의 값을 host memory의 h_C로 복사할 때에는
cudaMemcpy(h_C, h_C, size, cudaMemcpyDeviceToHost);이와 같이 작성하면 됩니다.
따라서, vecAdd 함수는 다음과 같이 작성할 수 있습니다. 커널 함수는 아래에서 살펴보도록 하겠습니다.
void vecAdd(const float *h_A, const float *h_B, float *h_C, int numElements) { // Allocate the device input vectors A, B, C float *d_A, *d_B, *d_C; cudaMalloc((void**)&d_A, numElements * sizeof(float)); cudaMalloc((void**)&d_B, numElements * sizeof(float)); cudaMalloc((void**)&d_C, numElements * sizeof(float)); // Copy the host input vector A and B in host memory // to the device input vectors in device memory cudaMemcpy(d_A, h_A, numElements * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, numElements * sizeof(float), cudaMemcpyHostToDevice); // Launch the Vector Add CUDA Kernel ... // Copy the device result vector in device memory // to the host result vector in host memory cudaMemcpy(h_C, d_C, numElements * sizeof(float), cudaMemcpyDeviceToHost); // Free device global memory cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); }
Kernel Function
이제 실제로 벡터 덧셈을 병렬로 수행할 커널 함수에 대해서 알아보겠습니다.
CUDA에서 커널 함수는 여러 개의 스레드를 병렬로 실행하는 코드를 의미합니다. 이 스레드들은 모두 동일한 코드이기 때문에 CUDA 프로그래밍은 SPMD(Single-Program Multiple-Data), 또는 SIMD(Single-Instruction Multiple-Data) 병렬 프로그래밍 스타일로 잘 알려져 있습니다. 스레드들이 병렬로 수행되기 때문에 NVIDIA 문서에는 SIMT(Single-Instruction Multiple-Thread) 구조라고 합니다.
프로그램의 host code에서 커널 함수를 실행(launch)하면, CUDA 런타임 시스템은 2-level 계층으로 구성된 스레드들의 그리드(grid)를 생성합니다. 각 grid는 스레드 블록(block)의 배열로 구성되고, 이 스레드 블록은 간단하게 블록이라고 부릅니다. 그리드의 모든 블록은 같은 크기이며, 각 블록은 동일한 수의 스레드로 구성되어 있습니다. 아래 이미지는 256개의 스레드들로 구성된 블록들을 보여주고 있습니다.
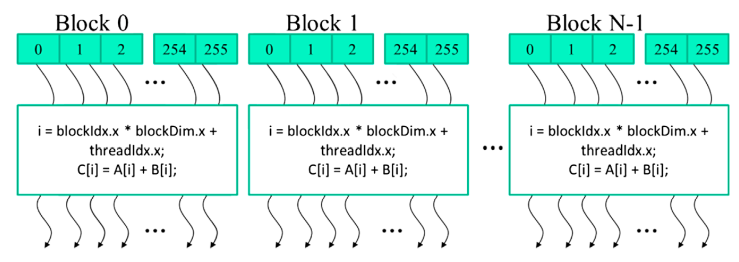
각 스레드 블록의 총 스레드 수는 커널이 실행될 때 host code에 의해서 지정됩니다. 따라서, 동일한 커널 함수를 실행하더라도 다른 수의 스레드를 지정하여 실행할 수도 있습니다. 커널에 의해서 주어진 그리드에서 한 블럭 안의 총 스레드의 수는 내장된 blockDim 변수를 통해 알 수 있습니다.
blockDim 변수는 3개의 정수 멤버(x, y, z)로 구성된 구조체입니다. 이 x,y,z 멤버를 통해 우리는 스레드가 1,2,3 차원 배열로 스레드를 구조화할 수 있습니다. 1차원 구조라면 x만 사용되고, 2차원 구조에서는 x와 y가 사용되고, 3차원 구조에서는 3개의 멤버가 모두 사용됩니다. 보통 스레드를 구조화할 때 사용되는 차원은 데이터의 차원을 반영하여 결정됩니다. 따라서, 위 이미지에서 각 스레드 블록은 1차원 배열의 스레드를 사용하는데, 이는 벡터 덧셈에서 사용되는 데이터가 1차원 벡터이기 때문입니다. blockDim.x 변수의 값은 각 블록의 스레드의 총 개수를 의미하며, 여기서는 256이 됩니다. 일반적으로 스레드 블록의 각 차원에서 스레드 수는 32배수를 권장하는데, 이는 하드웨어 효율 때문입니다.
CUDA 커널에서는 threadIdx, blockIdx라는 2개의 내장된 변수에 액세스할 수 있습니다. 이 변수들은 스레드들을 구분짓고, 각 스레드에서 사용되는 데이터들을 결정하는데 사용됩니다.
threadIdx 변수는 블록 내에서 각 스레드의 고유한 좌표를 나타냅니다. 예를 들어, 위 이미지에서 우리는 1차원의 스레드 구조를 사용하는데, 오직 threadIdx.x만 사용됩니다. 그리고 각 스레드에서 threadIdx.x의 값은 이미지에서 블록 내의 청록색의 스레드 박스안에 있는 값이 됩니다. 첫 번째 스레드의 threadIdx.x는 0, 두 번째 스레드는 1, 세 번째는 2,... 등이 됩니다.
blockIdx 변수는 블록 내의 모든 스레드들에게 자신이 속한 블록의 좌표를 전달하는데 사용됩니다. 위 이미지에서 첫 번째 블록의 모든 스레드들은 blockIdx.x의 값이 0입니다. 두 번째 블록의 모든 스레드들의 blockIdx.x의 값은 1이 됩니다.
전화번호를 예로 들면, threadIdx.x는 지역의 전화번호가 되고, blockIdx.x는 02와 같은 지역번호이 됩니다. 그리고 지역번호와 전화번호를 조합하면 한 나라에서 사용되는 유일한 전화번호가 됩니다.
이처럼 두 변수를 같이 조합하면, 하나의 그리드에서 유일한 전역 인덱스를 만들 수 있습니다. 위 예시 이미지에서 유일한 전역 인덱스 i는
i = blockIdx.x * blockDim.x + threadIdx.x
를 계산하여 구할 수 있습니다. 우리 예제에서 blockDim.x의 값이 256이기 때문에 block 0의 스레드들의 i 값은 0에서 255 사이의 값을 가집니다. block 1의 스레드들의 i값은 256에서 511의 값을 가지고, block 2의 스레드들의 i 값은 512에서 767의 값이 됩니다. 3개의 블록에서 스레드들의 값은 0에서 767의 연속된 값을 가지고, 각 스레드는 자신의 i값을 사용하여 벡터 A, B, C의 값에 액세스할 수 있습니다. 이는 serial code에서 0에서 767까지 iteration하는 것과 같습니다.
이제 벡터 합을 구하기 위한 커널 함수를 살펴봅시다.
__global__ void vecAddKernel(const float *A, const float *B, float *C, int numElements) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < numElements) C[i] = A[i] + B[i]; }
벡터 합을 위한 커널 함수는 위와 같이 작성됩니다. 여기서 CUDA 키워드인 "__global__"이 함수 선언 앞에 사용되었습니다. 이 키워드는 vecAddKerenl 함수가 커널이라는 것을 나타내며, 이 함수는 host 함수에서만 호출될 수 있습니다.
CUDA에서는 함수 선언에서 사용할 수 있는 3개의 키워드(__device__, __global__, __host__)가 있고, 의미가 아래 표에 간략하게 정리되어 있습니다.
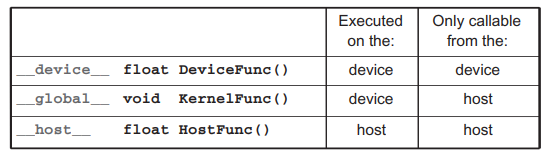
"__global__" 키워드는 선언된 함수가 CUDA 커널 함수라는 것을 나타냅니다. 이 커널 함수는 device에서 수행되며 오직 host code에서만 호출될 수 있습니다. (dynamic parallelism을 지원하는 CUDA 시스템에서는 예외입니다. 이는 추후에 알아보도록 하겠습니다.)
"__device__" 키워드는 선언된 함수가 CUDA device 함수라는 것을 나타냅니다. device 함수는 CUDA device에서 수행되며, 오직 커널 함수나 다른 device 함수에 의해서만 호출될 수 있습니다.
"__host__" 키워드는 선언된 함수가 CUDA host 함수라는 것을 나타냅니다. 호스트 함수는 일반적인 C 함수와 같으며, host에서 수행되고 오직 다른 host 함수에 의해서만 호출될 수 있습니다. CUDA 프로그램에서 3개의 키워드 중에 아무것도 사용되지 않으면, 기본적으로 호스트 함수로 간주됩니다.
또한, 3개의 키워드 중에 __host__와 __device__를 같이 사용할 수도 있습니다. 두 키워드를 같이 사용하면 컴파일러는 이 함수를 위해 두 버전의 object 파일을 생성합니다. 하나는 host에서 수행되고 호스트 함수에 의해서만 호출될 수 있고, 다른 하나는 device에서 수행되고 오직 device나 kernel 함수에 의해서만 호출될 수 있습니다. 이는 동일한 함수 소스 코드가 device version을 생성할 때, 코드 수정없이 컴파일만 다시 하도록 합니다.
또한, 위 코드에서 C코드의 확장으로 threadIdx.x와 blockIdx.x, blockDim.x가 사용되고 있습니다. 모든 스레드들은 모두 같은 커널 코드에서 수행되기 때문에 각 스레드가 데이터의 특정 부분에 접근하기 위해서 스레드들을 구별할 필요가 있습니다. 스레드들은 하드웨어 레지스터에 액세스하기 위해서 스레드의 좌표 값을 나타내는 내장된 변수들을 사용합니다. 다른 스레드는 서로 다른 값들을 가지는데, 편의상 스레드를 thread로 표기하도록 하겠습니다.
커널 코드에 지역 변수 i가 있는데, 커널 함수에서 지역 변수는 각 스레드에 private한 변수입니다. 즉, i는 모든 스레드에서 각각 생성됩니다. 만약 10,000개의 스레드가 커널에서 생성되면, 10,000가지 버전의 i가 각 스레드마다 생기게 됩니다. 각 스레드의 i 변수에 할당되는 값은 다른 스레드는 알 수 없습니다.
커널 함수를 다시 살펴보면,
__global__ void vecAddKernel(const float *A, const float *B, float *C, int numElements) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < numElements) C[i] = A[i] + B[i]; }
커널 함수에는 루프가 없습니다. 커널에서 루프는 이제 스레드의 그리드로 대체됩니다. 전체 그리드는 루프에 대응되고, 그리드 내의 각 스레드가 원래 루프에서 하나의 iteration에 대응됩니다. 이러한 타입의 데이터 병렬화는 loop parallelilsm이라고 불립니다.
또 한 가지 체크해야 될 것은 line 6에서 if (i < numElements)가 사용되는 것입니다. 이는 벡터의 크기가 블록 사이즈의 배수로 표현되지 않기 때문입니다. 예를 들어, 100개의 요소를 가지고 있는 벡터가 있다고 가정해봅시다. 효율성이 높으면서 가장 작은 블록의 스레드 차원은 32입니다. 블록 사이즈를 32로 설정하면, 100개의 벡터 요소를 처리하기 위해서 4개의 블록이 필요합니다. 그러나, 4개의 블록은 총 128개의 스레드를 가지고 있습니다. 따라서 우리는 프로그램에 영향을 미치지 않으면서 마지막 28개의 스레드를 비활성화해야 합니다. 모든 스레드가 동일한 커널 코드를 수행하기 때문에 i 변수의 값을 n과 비교하는 방법을 사용할 수 있습니다. if문에서 처음 100개의 스레드는 덧셈을 수행하지만, 나머지 28개의 스레드는 if문을 만족하지 못하므로 덧셈이 수행되지 않습니다.
커널 호출
host 코드에서 커널을 호출할 때, 그리드와 스레드 블록의 차원을 execution configuration parameters를 통해 설정할 수 있습니다. configuration parameters는 C 함수 argument 전에 "<<<"와 ">>>" 사이에 주어집니다. (line 7)
void vecAdd(const float *h_A, const float *h_B, float *h_C, int numElements) { // Allocate the device input vectors A, B, C ... int threadsPerBlock = 256; int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock; vecAddKernel<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements); ... }
첫 번째 configuration 파라미터는 그리드에서 스레드 블록의 수입니다. 그리고 두 번째 파라미터는 각 스레드 블록에서의 스레드 수입니다. 위 코드에서는 각 블록은 256개의 스레드를 가지고, 벡터의 모든 요소들을 커버하기 위해서 그리드에서 블록 수를 line 6에서 계산하고 있습니다. 예를 들어, 벡터 크기가 1000이라면 (1000 + 256 - 1) / 256 = 4로, 4개의 스레드 블록을 생성합니다. 결과적으로 4*256 = 1024 스레드를 실행하고, 커널 함수 내의 if (n < numElements) 조건을 통해 처음 1000개의 스레드만 덧셈을 수행하고 나머지 24개의 스레드는 덧셈을 수행하지 않게 됩니다.
vecAddKernel 커널 함수를 호출하는 vecAdd 함수는 최종적으로 다음과 같이 작성됩니다.
void vecAdd(const float *h_A, const float *h_B, float *h_C, int numElements) { // Allocate the device input vectors A, B, C float *d_A, *d_B, *d_C; CUDA_CHECK(cudaMalloc((void**)&d_A, numElements * sizeof(float))); CUDA_CHECK(cudaMalloc((void**)&d_B, numElements * sizeof(float))); CUDA_CHECK(cudaMalloc((void**)&d_C, numElements * sizeof(float))); // Copy the host input vector A and B in host memory // to the device input vectors in device memory printf("Copy input data from the host memory to the CUDA device\n"); CUDA_CHECK(cudaMemcpy(d_A, h_A, numElements * sizeof(float), cudaMemcpyHostToDevice)); CUDA_CHECK(cudaMemcpy(d_B, h_B, numElements * sizeof(float), cudaMemcpyHostToDevice)); // Allocate CUDA events for estimating cudaEvent_t start, stop; CUDA_CHECK(cudaEventCreate(&start)); CUDA_CHECK(cudaEventCreate(&stop)); // Launch the Vector Add CUDA Kernel int threadsPerBlock = 256; int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock; printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock); CUDA_CHECK(cudaDeviceSynchronize()); CUDA_CHECK(cudaEventRecord(start)); vecAddKernel<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements); CUDA_CHECK(cudaDeviceSynchronize()); CUDA_CHECK(cudaEventRecord(stop)); CUDA_CHECK(cudaGetLastError()); // Copy the device result vector in device memory // to the host result vector in host memory printf("Copy output data from the CUDA device to the host memory\n"); CUDA_CHECK(cudaMemcpy(h_C, d_C, numElements * sizeof(float), cudaMemcpyDeviceToHost)); // Verify that the result vector is correct (sampling) printf("Verifying vector addition...\n"); for (int idx = 0; idx < numElements; idx++) { //printf("[INDEX %d] %f + %f = %f\n", idx, h_A[idx], h_B[idx], h_C[idx]); if (fabs(h_A[idx] + h_B[idx] - h_C[idx]) > 1e-5) { fprintf(stderr, "Result verification failed at element %d\n", idx); exit(EXIT_FAILURE); } } printf(".....\n"); printf("Test PASSED\n"); // Compute and Print the performance float msecTotal = 0.0f; CUDA_CHECK(cudaEventElapsedTime(&msecTotal, start, stop)); double flopsPerVecAdd = static_cast<double>(numElements); double gigaFlops = (flopsPerVecAdd * 1.0e-9f) / (msecTotal / 1000.0f); printf("Performance= %.2f GFlop/s, Time= %.3f msec, Size = %.0f Ops, " "WorkgroupSize= %u threads/block\n", gigaFlops, msecTotal, flopsPerVecAdd, threadsPerBlock); // Free device global memory CUDA_CHECK(cudaFree(d_A)); CUDA_CHECK(cudaFree(d_B)); CUDA_CHECK(cudaFree(d_C)); CUDA_CHECK(cudaEventDestroy(start)); CUDA_CHECK(cudaEventDestroy(stop)); }
전체 코드는 아래 링크에서 확인하실 수 있습니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/vectorAdd/vectorAdd.cu
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
위 코드를 nvcc 커맨드로 컴파일하고, 벡터 크기(4000)를 커맨드 라인에 추가하여 프로그램을 실행하면,
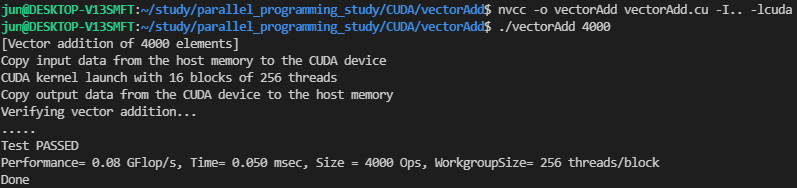
다음의 실행 결과를 얻을 수 있습니다.
vecAdd 함수 내에는 올바른 벡터 덧셈 결과를 확인하기 위한 코드가 있기 때문에, CUDA 커널로 계산한 덧셈 결과가 시리얼 코드로 계산한 결과와 동일한 값인지 확인합니다.
그리고 vecAdd 함수에는 위에서 설명한 메모리 할당, 메모리 복사, 메모리 해제, 커널 함수 호출 외에 몇 가지가 있는데, 간단하게 설명하고 마무리 하도록 하겠습니다.
먼저 CUDA_CHECK 매크로 입니다.
CUDA에서 제공되는 런타임 API는 cudaError enum 값을 리턴합니다. 함수가 성공적으로 수행되면 cudaSuccess(=0)을 리턴하고, 에러가 발생하면 에러에 해당하는 값을 리턴하게 됩니다. 일반적으로 GPU를 사용할 때, 다양한 에러가 발생할 수 있기 때문에 API를 호출할 때마다 에러값을 체크해야 하는데, 이를 편리하게 수행하기 위해서 주로 매크로나 함수로 정의하여 사용합니다.
#define CUDA_CHECK(val) { \ if (val != cudaSuccess) { \ fprintf(stderr, "Error %s at line %d in file %s\n", cudaGetErrorString(val), __LINE__, __FILE__); \ exit(1); \ } \ }
위 매크로는 common.h 에 정의되어 있습니다.
https://github.com/junstar92/parallel_programming_study/blob/master/CUDA/common/common.h
GitHub - junstar92/parallel_programming_study
Contribute to junstar92/parallel_programming_study development by creating an account on GitHub.
github.com
두 번째로 커널 함수의 수행 시간과 성능을 측정하기 위하여 cudaEvent_t를 사용했습니다. CUDA Event는 GPU에서의 정확한 커널 수행 시간을 측정하기 위해서 사용되고, 이에 대한 자세한 내용은 따로 포스팅하도록 하겠습니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| CUDA의 메모리 Access와 Type (예제 : matrix multiplication) (0) | 2021.12.05 |
|---|---|
| CUDA Thread 동기화 및 스케쥴링 / 리소스 할당 (0) | 2021.12.04 |
| CUDA Programming Model (1) | 2021.12.03 |
| CUDA Thread 구조와 Data Mapping (예제 : 이미지 흑백, Blur 처리) (7) | 2021.12.02 |
| GPU와 CUDA (0) | 2021.11.30 |




댓글