References
- Fluent Python
Contents
- Python Data Model
- Special Methods
- String Representation (__repr__)
파이썬의 장점 중의 하나는 일관성(consistency)입니다. 즉, 파이썬을 어느 정도 사용하다보면, 새로운 기능에 대해서도 제대로 예측할 수 있습니다.
파이썬이 아닌 다른 객체지향 언어에 익숙하다면 collection.len()처럼 작성하는 대신 len(collection)을 사용하다는 점을 이상하게 생각할 수도 있습니다. 이는 파이썬에서 빙산의 일각이며, 이를 잘 이해하면 파이썬스러운(pythonic) 것의 핵심을 파악할 수 있습니다. 이 빙산을 '파이썬 데이터 모델'이라고 하며, 파이썬 데이터 모델이 제공하는 API를 이용해 커스텀 객체를 정의하면 파이썬에 맞게 적용할 수 있습니다.
데이터 모델은 일종의 프레임워크로 파이썬을 설명하는 것이라고 생각할 수 있습니다. 여기서 시퀀스(sequences), 반복자(iterators), 함수(functions), 클래스(classes), context managers 등 언어 자체의 building block에 대한 인터페이스를 공식적으로 정의합니다.
일반적으로 프레임워크를 이용해서 코딩할 때는 프레임워크에 의해서 호출되는 메소드를 구현하는데 많은 시간을 소비합니다. 파이썬 데이터 모델 또한 마찬가지입니다. 파이썬 인터프리터는 스페셜 메소드를 호출해서 기본적인 객체의 연산을 수행하는데, 일반적으로 특별한 문법(구문)을 통해 호출됩니다. 이러한 메소드는 __getitem__()처럼 항상 앞뒤에 이중 언더바(double underbar)를 가지고 있습니다. 예를 들어, obj[key] 형태의 문법은 __getitem__ 메소드에 의해서 지원됩니다. 인터프리터는 my_collection[key]를 만나면, my_collection.__getitem__(key)를 호출합니다.
이런 스페셜 메소드들은 우리가 구현한 객체가 다음과 같은 기본적인 언어 구성들을 구현하고 지원하고 사용할 수 있도록 해줍니다.
- Iteration
- Collections
- Attribute access
- Operator overloading
- Function and method invocation
- String representation and formatting
- Asynchronous programing using await;
- Object creation and destruction
- Managed contexts using with or async with statements
Python Data Model
이번에는 간단하지만 스페셜 메소드인 __getitem__과 __len__만으로도 강력한 기능을 구현할 수 있다는 것을 보여주는 코드를 살펴보겠습니다.
A Pythonic Card Deck
아래 코드는 카드놀이에 사용할 카드 한 벌을 표현하는 클래스입니다.
import collections Card = collections.namedtuple('Card', ['rank', 'suit']) class FrenchDeck: ranks = [str(n) for n in range(2, 11)] + list('JQKA') suits = 'spades diamonds clubs hearts'.split() def __init__(self): self._cards = [Card(rank, suit) for suit in self.suits for rank in self.ranks] def __len__(self): return len(self._cards) def __getitem__(self, position): return self._cards[position]
여기서 먼저 collections.namedtuple()을 사용해 개별 카드를 나타내는 클래스를 구현합니다. namedtuple()에 대한 자세한 내용은 생략하며, 일단 'rank', 'suit'라는 key를 가지는 'Card'라는 튜플 클래스 타입을 정의한다고 이해하면 됩니다.
이렇게 정의한 Card 클래스를 가지고 카드 한 장은 다음과 같이 표현할 수 있습니다. (저는 test.py 파일에 정의하고 import하여 사용했습니다.)

이 코드의 핵심은 FrenchDeck 클래스입니다. 이 코드는 매우 간단하지만 아주 많은 기능을 구현합니다.
먼저 일반적인 파이썬 컬렉션과 마찬가지로 len() 함수를 통해 자신이 가지고 있는 카드의 개수를 얻을 수 있습니다.
또한, 카드 한 벌(deck)에서 특정 카드를 읽을 수도 있습니다. 예를 들어, deck[0]은 첫 번째 카드, deck[-1]은 마지막 카드를 읽습니다. 이 기능은 __getitem__() 메소드가 제공합니다.
deck에서 임의의 카드를 골라내려면 메소드를 따로 구현해야 할까요? 파이썬에서는 그럴 필요가 없습니다. 파이썬은 시퀀스에서 항목을 무작위로 골라내는 random.choice()라는 메소드를 제공합니다. 따라서, deck 객체에 다음과 같이 적용만 해주면 됩니다.
여기서 스페셜 메소드를 통해 파이썬 데이터 모델을 사용하면 두 가지 장점이 있다는 것을 알 수 있습니다.
- 사용자가 표준 연산을 수행하기 위해 클래스 자체에 구현한 임의의 메소드를 암기할 필요가 없습니다.(ex, size() or length()와 같은 메소드)
- 파이썬 표준 라이브러리에서 제공하는 다양한 기능을 별도로 구현할 필요 없이 바로 사용할 수 있습니다.(ex, random.choice())
이것이 전부가 아닙니다.
__getitem__() 메소드는 self._cards의 []연산자에 작업을 위임하므로 deck 객체는 슬라이싱(slicing)도 자동으로 지원합니다. 새로 생성한 deck 객체에서 앞의 카드 세 장을 가져오고, 12번 인덱스에서 시작해서 13개씩 건너뛰어 에이스만 가져오려면 다음과 같이 작성해주면 됩니다.
__getitem__() 스페셜 메소드를 구현함으로써 deck을 반복할 수도 있습니다.
또한, reversed()를 사용해서 뒤에서부터 반복할 수도 있습니다.
반복은 암묵적으로 수행되는 경우도 많습니다. 컬렉션에 __contains__() 메소드가 없다면 in연산자는 차례대로 검색(sequential scan)합니다. 예를 들어 FrenchDeck 클래스의 경우 반복할 수 있으므로 in이 동작합니다.
정렬은 어떨까요? 일반적으로 카드는 숫자(rank)로 순위를 정하고(에이스가 가장 높음), 숫자가 같은 경우에는 스페이드, 하트, 다이아몬드, 클로버 순으로 정합니다. 이 규칙대로 카드 순위를 정하는 함수는 다음과 같이 구현할 수 있습니다. 클로버 2의 경우 0, 스페이드 에이스의 경우 51을 리턴합니다.
suit_values = dict(spades=3, hearts=2, diamonds=1, clubs=0) def spades_high(card): rank_value = FrenchDeck.ranks.index(card.rank) return rank_value * len(suit_values) + suit_values[card.suit]
이렇게 하면 다음과 같이 오름차순으로 나열할 수 있습니다.
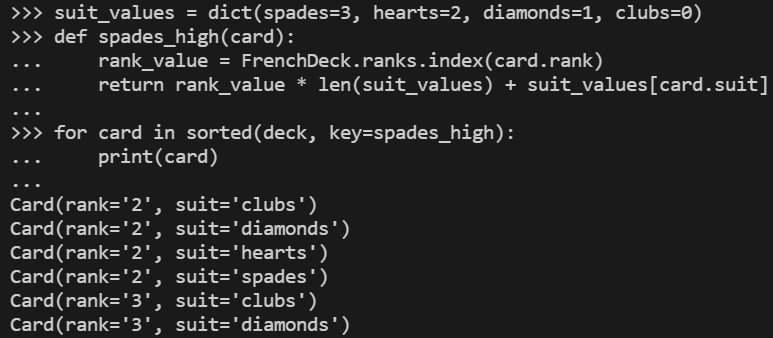
FrenchDeck이 암묵적으로 object를 상속받지만, 상속 대신 데이터 모델과 구성을 이용해서 기능을 가져옵니다. __len__()과 __getitem__() 스페셜 메소드를 구현함으로써 FrenchDeck은 표준 파이썬 시퀀스처럼 동작하므로 반복 및 슬라이싱 등의 언어의 핵심 기능 및 random의 choice(), reversed(), sorted()와 같은 표준 라이브러리를 사용할 수 있습니다. 이러한 구성 덕분에 __len__()과 __getitem__() 메소드는 모든 작업을 list 객체인 self._cards에 떠넘길 수 있습니다.
How Special Methods Are Used
스페셜 메소드에 대해 먼저 알아두어야 할 것은 이 메소드는 우리가 아닌 파이썬 인터프리터가 호출하기 위한 것이라는 점입니다. 소스 코드에서 my_object.__len__()으로 직접 호출하지 않고, len(my_object) 형태로 호출합니다. 만약 my_object가 사용자 정의 클래스의 객체면 파이썬은 우리가 구현한 __len__() 메소드를 호출합니다.
하지만, list, str, bytearray 등과 같은 내장 자료형이나 NumPy와 같은 extension의 경우 파이썬 인터프리터는 shortcut을 선택합니다. CPython의 경우 len() 메소드는 메모리에 있는 가변 크기의 내장 객체를 나타내는 PyVarObject C 구조체에 있는 ob_size 필드의 값을 리턴합니다. 이 방법은 메소드를 호출하는 것보다 빠릅니다.
종종 스페셜 메소드는 암묵적으로 호출됩니다. 예를 들어 for i in x: 문은 실제로 iter(x)를 호출하며, 이 함수는 다시 x.__iter__()를 호출합니다.
일반적으로 사용자 코드에서 스페셜 메소드를 직접 호출하는 경우는 그리 많지 않습니다. 메타프로그래밍을 하는 경우가 아니라면 스페셜 메소드를 직접 호출하는 것보다, 이를 구현하는 시간이 더 많습니다. 사용자 코드에서 스페셜 메소드를 자주 호출하는 경우는 __init__() 메소드가 유일합니다.
스페셜 메소드를 호출해야 하는 경우에는 일반적으로 len(), iter(), str() 등의 관련된 내장 함수를 호출하는 것이 더 좋습니다. 이들 내장 함수가 해당 스페셜 메소드를 호출합니다. 하지만 내장 데이터형의 경우 스페셜 메소드를 호출하지 않는 경우도 있으며 이런 경우는 메소드 호출보다 빠릅니다.
Emulating Numeric Types
+와 같은 연산자에 사용자 정의 객체가 동작할 수 있도록 해주는 몇몇 스페셜 메소드가 있습니다. 자세한 내용은 다른 포스팅에서 다루도록 하며, 이번 포스팅에서는 예제를 통해 스페셜 메소드를 사용하는 방법을 간단하게 알아보겠습니다.
수학이나 물리학에서 사용되는 2차원 벡터를 표현하는 클래스 Vector를 구현해보도록 하겠습니다.
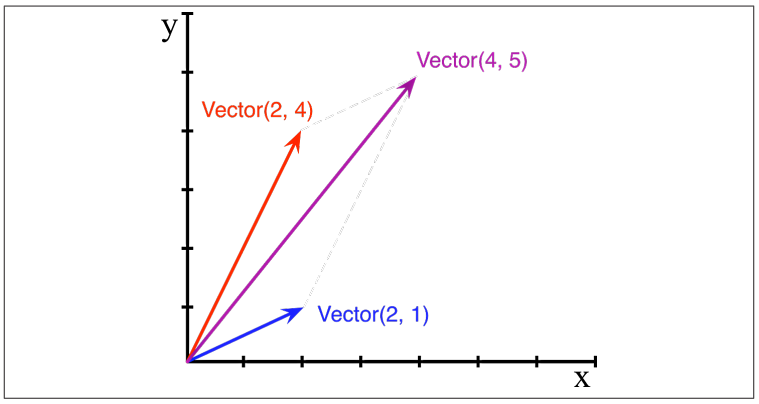
구현된 Vector는 다음과 같이 생성하고, 벡터 덧셈을 할 수 있어야 합니다.
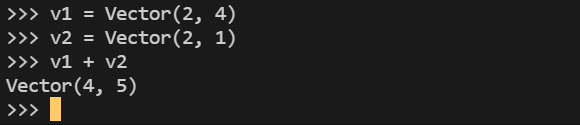
여기서 + 연산자의 결과로 Vector 타입이 생성된다는 것에 주의합니다. Vector 타입은 콘솔에서 Vector로 표현됩니다.
내장된 abs() 함수는 정수나 실수의 절댓값을 반환하며, complex 타입의 경우에도 값을 한 개만 반환합니다. 따라서 우리가 구현할 API 역시 벡터의 크기를 계산하는 데 abs() 함수를 사용하도록 할 것입니다.

또한, *연산자를 사용해서 스칼라곱을 수행할 수 있어야 합니다.

이제 Vector 클래스의 구현을 살펴보겠습니다. 아래 코드는 __repr__(), __abs__(), __add__(), __mul__() 스페셜 메소드를 이용하여 위에서 언급한 연산들을 구현한 Vector 클래스입니다.
from math import hypot class Vector: def __init__(self, x=0, y=0): self.x = x self.y = y def __repr__(self): return f"Vector({self.x!r}, {self.y!r})" def __abs__(self): return hypot(self.x, self.y) def __bool__(self): return bool(abs(self)) def __add__(self, other): x = self.x + other.x y = self.y + other.y return Vector(x, y) def __mul__(self, scalar): return Vector(self.x * scalar, self.y * scalar)
__init__()을 제외하고 5개의 스페셜 메소드를 구현했지만, 이 메소드들은 클래스 내부나 콘솔의 테스트 코드에서 직접 호출하지 않습니다. 앞서 설명한 것처럼 스페셜 메소드는 주로 파이썬 인터프리터가 호출합니다.
String Representation
__repr__() 스페셜 메소드는 객체를 문자열로 표현하기 위해 repr() 내장 메소드에 의해 호출됩니다. 만약 __repr__() 메소드를 구현하지 않으면 Vector 객체는 콘솔에 <Vector object at 0x10e100070>과 같은 형태로 출력됩니다.

__repr__() 메소드는 f-string으로 작성된 문자열을 반환하는데, !r라는 변환 필드를 사용하고 있습니다. !r를 사용하면 표현식의 결과에 repr()을 호출합니다. 주로 출력한 속성의 표준 표현을 가져오기 위해 사용됩니다.
__repr__() 메소드가 반환한 문자열은 명확해야 하며, 가능하면 표현된 객체를 재생성하는 데 필요한 소스 코드와 일치해야 합니다. 따라서 여기서 선택한 표현은 Vector(3, 4)처럼 클래스 생성자를 호출하는 모습과 동일합니다.
__repr__()과 __str__()을 비교해보도록 하겠습니다. __str__() 메소드는 str() 생성자에 의해 호출되며 print() 함수에 의해 암묵적으로 사용됩니다. __str__() 메소드는 사용자에게 보여주기 적당한 형태의 문자열을 반환해야 합니다. 만약 두 스페셜 메소드 중 하나만 구현해야 한다면 __repr__() 메소드를 구현하면 됩니다. 파이썬 인터프리터는 __str__() 메소드가 구현되어 있지 않을 때, __repr__() 메소드를 호출하기 때문입니다.
아래 링크에서 __repr__()과 __str__()의 차이점에 대한 설명을 잘 해주고 있습니다.
python - What is the difference between __str__ and __repr__? - Stack Overflow
What is the difference between __str__ and __repr__?
What is the difference between __str__ and __repr__ in Python?
stackoverflow.com
Arithmetic Operators
Vector 클래스는 __add__()와 __mul__()의 기본 사용법을 살펴보기 위해 +와 * 연산자를 구현했습니다. 두 경우 모두 Vector 객체를 새로 만들어서 반환하며 두 개의 피연산자는 변경하지 않습니다. 중위 연산자는 의례적으로 피연산자를 변경하지 않고 객체를 새로 만듭니다.
참고로 Vector에 숫자를 곱할 수는 있지만, 숫자에 Vector를 곱할 수는 없습니다. 이 문제는 __rmul__() 스페셜 메소드를 이용하여 해결할 수 있습니다.
Boolean Value of a Custom Type
파이썬에도 bool 타입이 있지만, if나 while문, 혹은 and, or, not에 대한 피연산자로서 불리언형이 필요한 곳에는 어떠한 객체라도 사용할 수 있습니다. x가 true인지 false 값인지 판단하기 위해 파이썬은 bool(x)를 적용하며, 이 함수는 항상 True나 False를 반환해야 합니다.
__bool__()이나 __len__()을 구현하지 않은 경우, 기본적으로 사용자 정의 클래스의 객체는 참이라고 간주됩니다. bool(x)는 x.__bool__()을 호출한 결과를 이용합니다. __bool__()이 구현되어 있지 않으면 파이썬은 x.__len__()을 호출하며, 이 스페셜 메소드가 0을 반환하면 False, 그렇지 않다면 True를 리턴합니다.
Vector에서 구현할 __bool__()은 개념적으로 간단합니다. 벡터의 크기가 0이면 False를 반환하고 그렇지 않으면 True를 반환합니다. __bool__()은 불리언 타입을 반환해야 하므로 bool(abs(self))를 이용해서 크기를 불리언 타입으로 변환합니다.
위에서 구현한 것보다 조금 더 빠른 Vector.__bool__()의 구현은 다음과 같습니다.
def __bool__(self): return bool(self.x or self.y) 가독성은 떨어지지만, abs(), __abs__(), 제곱, 제곱근 연산을 수행하지 않습니다.
Overview of Special Methods
3. Data model — Python 3.10.2 documentation
3. Data model — Python 3.10.2 documentation
A class can implement certain operations that are invoked by special syntax (such as arithmetic operations or subscripting and slicing) by defining methods with special names. This is Python’s approach to operator overloading, allowing classes to define
docs.python.org
파이썬 공식 문서에는 80개가 넘는 스페셜 메소드가 있습니다. 그중 절반 이상이 산술,비트,비교 연산자를 구현하기 위해 사용됩니다.
궁금한 스페셜 메소드는 위 링크에서 찾아볼 수 있습니다.. !
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] 시퀀스 (Sequences) - (2) (0) | 2022.03.12 |
|---|---|
| [Python] 시퀀스 (Sequences) - (1) (0) | 2022.03.12 |
| [Python/파이썬] 클래스(Class) (0) | 2020.09.06 |
| [Python/파이썬] 모듈(Module)과 패키지(Package) (0) | 2020.08.29 |
| [Python/파이썬] 함수 / 람다표현식(Lambda Expression) (2) | 2020.08.21 |




댓글