References
- Professional CUDA C Programming
- https://developer.nvidia.com/blog/unified-memory-in-cuda-6/
Contents
- Unified Memory
Zero-Copy Memory & Unified Virtual Addressing
Zero-Copy Memory & Unified Virtual Addressing
References Professional CUDA C Programming Contents Zero-Copy Memory Unified Virtual Addressing Zero-Copy Memory 일반적으로 host는 device 변수에 직접 액세스할 수 없고, device는 host 변수에 직접 액세..
junstar92.tistory.com
이전 포스팅에서 Zero-Copy Memory와 Unified Virtual Addressing에 대해서 알아보면서, CUDA 6부터는 Unified Memory를 지원한다고 언급했었습니다. 이번 포스팅에서는 Unified Memory를 어떻게 사용하고 어떠한 차이점이 있는지 알아보겠습니다.
일반적인 PC에서 CPU와 GPU의 메모리는 PCIe BUS에 의해서 물리적으로 구분되고 분리됩니다. CUDA 6 이전까지는 CPU와 GPU 간에 공유되는 데이터는 두 메모리에 모두 할당되어야 하며, 프로그램에서 명시적으로 전달되어야 했습니다.

하지만 Unified Memory는 CPU와 GPU 사이에서 공유되는 managed memory pool을 생성하며, CPU와 GPU를 연결시킵니다. Managed Memory는 하나의 포인터를 사용하여 CPU와 GPU에서 모두 액세스할 수 있습니다. 핵심은 Unified Memory에서 할당된 데이터를 Host와 Device 간에 자동으로 마이그레이션하여 CPU에서 동작할 때는 CPU 메모리처럼 보이게 하고, GPU에서 동작할 때는 GPU 메모리처럼 보이게 해줍니다.
우선 지금까지 살펴봤던 일반적인 CUDA 코드와 Unified Memory를 사용한 CUDA 코드가 어떻게 다른지 살펴보겠습니다. 비교를 위해 사용되는 커널은 간단한 matrix addition을 구현한 커널을 사용하도록 하겠습니다.
커널 함수는 다음과 같습니다.
__global__ void sumMatrixOnGPU(float* A, float* B, float* C, const int nx, const int ny) { unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x; unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y; unsigned int idx = iy * nx + ix; if (ix < nx && iy < ny) C[idx] = A[idx] + B[idx]; }
먼저 일반적인 CUDA 코드로 구현한 matrix addition 입니다. 전체 코드는 아래 링크를 참조해주세요.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
unified memory를 사용할 때와의 주요한 차이점은 CPU와 GPU에 메모리를 모두 할당하고, 초기화된 CPU 메모리의 데이터를 GPU 메모리로 전달해주는 것과 GPU에서 계산된 결과를 다시 CPU로 전달해주는 것입니다.
이를 위해서 위 코드의 main 함수에는 다음과 같이 GPU 메모리를 할당하고, CPU 데이터를 GPU로 전달해주는 것과 그 결과를 다시 CPU로 전달해주는 코드가 포함됩니다.
// matrixAdditionWithoutUnifiedMemory.cu int main(int argc, char** argv) { ... // malloc device global memory float *d_A, *d_B, *d_C; CUDA_CHECK(cudaMalloc((void**)&d_A, nBytes)); CUDA_CHECK(cudaMalloc((void**)&d_B, nBytes)); CUDA_CHECK(cudaMalloc((void**)&d_C, nBytes)); ... // transfer data from host to device CUDA_CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice)); CUDA_CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice)); ... // launch kernel sumMatrixOnGPU<<<grids, blocks>>>(d_A, d_B, d_C, nx, ny); CUDA_CHECK(cudaDeviceSynchronize()); ... // transfer result from device to host CUDA_CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost)); ... }
반면에 Unified Memory를 사용하면, 위와 같이 명시적인 데이터 전달을 하지 않아도 됩니다. 전체 코드는 아래의 링크를 참조해주세요.
GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
Study parallel programming - CUDA, OpenMP, MPI, Pthread - GitHub - junstar92/parallel_programming_study: Study parallel programming - CUDA, OpenMP, MPI, Pthread
github.com
Unified Memory를 사용하면 main 함수를 다음과 같이 간단하게 구현할 수 있습니다.
// matrixAdditionWithUnifiedMemory.cu int main(int argc, char** argv) { ... // malloc host memory float *A, *B, *hostRef, *gpuRef; CUDA_CHECK(cudaMallocManaged((void**)&A, nBytes)); CUDA_CHECK(cudaMallocManaged((void**)&B, nBytes)); CUDA_CHECK(cudaMallocManaged((void**)&hostRef, nBytes)); CUDA_CHECK(cudaMallocManaged((void**)&gpuRef, nBytes)); // launch kernel sumMatrixOnGPU<<<grids, blocks>>>(A, B, gpuRef, nx, ny); CUDA_CHECK(cudaDeviceSynchronize()); ... // free device global memory CUDA_CHECK(cudaFree(A)); CUDA_CHECK(cudaFree(B)); CUDA_CHECK(cudaFree(hostRef)); CUDA_CHECK(cudaFree(gpuRef)); ... }
CPU와 GPU 사이의 명시적인 데이터 전달이 사라졌습니다.
각각의 코드를 아래의 커맨드로 컴파일하고, 비교해보겠습니다.
nvcc -O3 -o manual matrixAddWithoutUnifiedMemory.cu -I.. nvcc -O3 -o managed matrixAddWithUnifiedMemory.cu -I..
Unified Memory를 사용하지 않은 코드를 실행하면 다음과 같은 출력 결과를 확인할 수 있습니다.
Unified Memory를 사용한 코드를 실행한 결과입니다.

결과를 살펴보면, Managed Memory의 커널 성능이 Host와 Device 간에 데이터를 명시적으로 전달해주는 것만큼 빠르지만, 프로그래밍은 더욱 간단하다는 것을 보여줍니다.
두 코드를 nvprof로 프로파일링 해보도록 하겠습니다.
nvprof --profile-api-trace runtime ./manual.exe nvprof --profile-api-trace runtime ./managed.exe
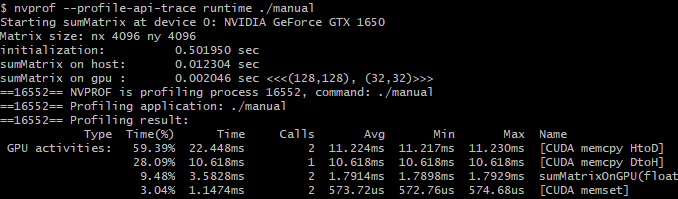
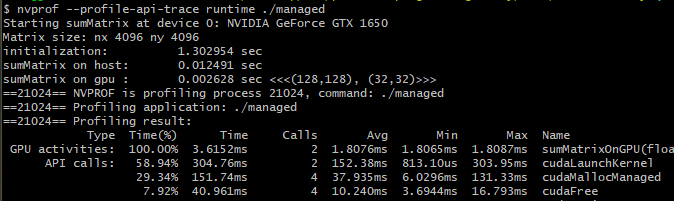
성능면에서 가장 큰 차이점은 CPU 데이터의 초기화 시간입니다. Managed Memory를 사용하면 초기화에 소요되는 시간이 훨씬 더 크다는 것을 볼 수 있습니다. 할당되는 메모리는 처음에는 GPU에서 할당되지만, 초기값을 설정하는 것은 CPU에서 이루어지기 때문에 CPU에서 먼저 참조됩니다. 이를 위해서 초기화를 수행하기 전에 시스템이 할당된 메모리 내용을 device에서 host로 전달해주어야 하는데, 이는 manual 코드에서는 수행되지 않는 것이며 이러한 동작 때문에 조금 더 시간이 더 소요됩니다.
Host에서 수행되는 matrix sum 함수가 실행될 때, 이미 전체 matrix가 이미 CPU에 상주하고 있기 때문에 실행 시간은 유사합니다. 그리고, 워밍업으로 커널이 한 번 수행되는데, 이때 사용되는 matrix가 device로 다시 마이그레이션합니다. 따라서 실제 수행 시간을 측정하는데 사용되는 커널이 실행될 때에는 해당 matrix 데이터가 GPU에 존재하는 상태입니다. 만약 워밍업 커널이 실행되지 않는다면 managed memory를 사용하는 커널의 실행 속도는 훨씬 더 느려질 것입니다.
Unified Memory 성능은 nvvp나 nvprof로 측정할 수 있습니다. 두 프로파일러 모두 시스템에서 각 GPU에 대한 Unified Memory 트래픽을 측정할 수 있습니다.
다음의 플래그를 사용하여 nvprof를 실행하면 Unified Memory 관련 메트릭을 사용할 수 있습니다.
nvprof --unified-memory-profiling per-process-device ./managed
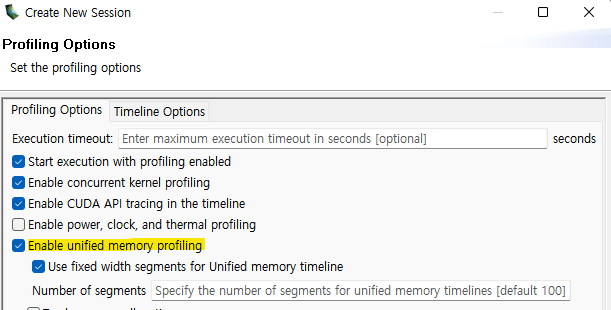
Nvidia Visual Profiler(nvvp)를 사용하면 시각적으로 살펴볼 수도 있습니다.
Session을 생성할 때, 아래처럼 Enable unified memory profiling을 체크해주면 됩니다.
결과 화면은 다음과 같습니다.
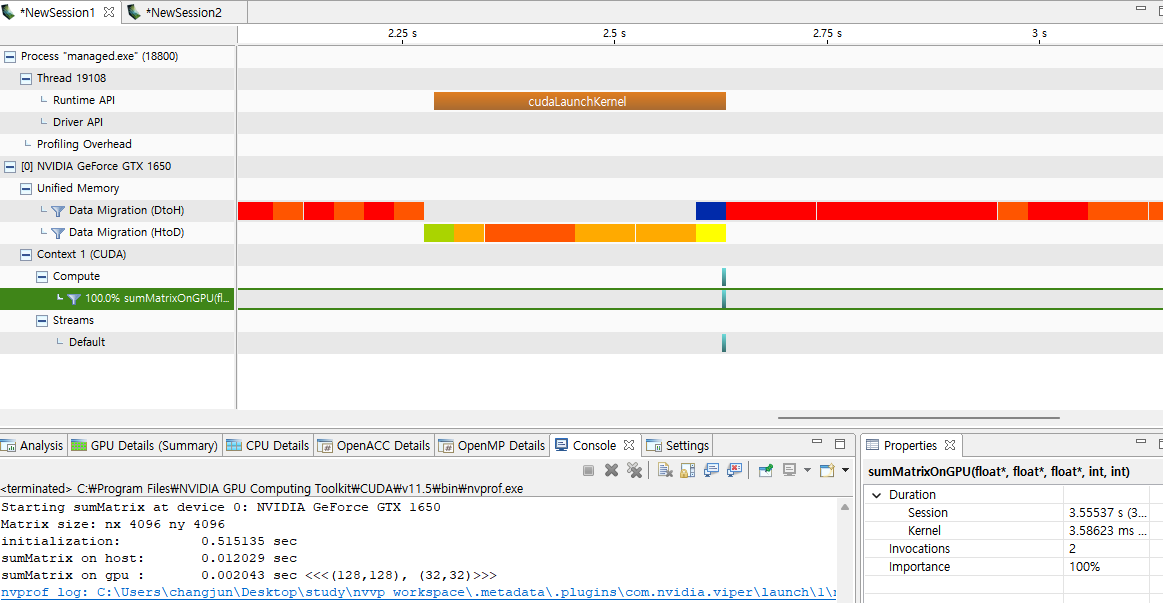
Unified Memory는 GPU로 데이터를 마이그레이션하여 성능을 최적화합니다. 기본 시스템은 host와 device 간의 일관성을 유지하며 데이터가 가장 효율적으로 액세스될 수 있는 곳에 데이터를 배치하려고 합니다.
다음은 Unified Memory를 사용하지 않은 manual.exe를 nvvp로 실행한 결과입니다.
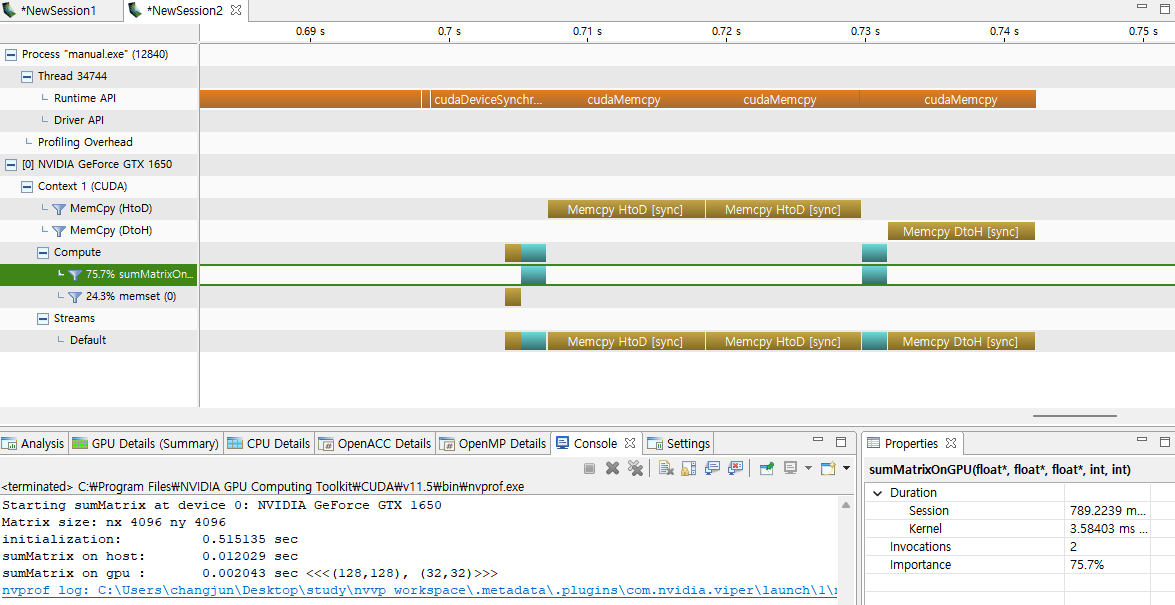
두 결과를 비교해보면, 명시적으로 데이터를 관리하는 manual.exe의 경우에는 Device To Host 전송을 한 번만 수행하지만, Unified Memory를 사용하는 managed.exe의 경우에는 두 번 수행됩니다.
이처럼 Unified Memory는 코딩을 더욱 효율적으로 할 수 있어서 생산성이 향상되도록 설계되었습니다.
여기서 초점은 성능이 아닌, 일관성과 정확성, 편리함을 강조한다는 것입니다. 결과적으로 살펴보면, 데이터 전달을 수동으로 최적화하면 Unified Memory보다 훨씬 더 좋은 성능을 가질 수 있습니다.
'NVIDIA > CUDA' 카테고리의 다른 글
| Shared Memory (2) - Square/Rectangular Shared Memory (0) | 2022.01.19 |
|---|---|
| Shared Memory (1) (0) | 2022.01.18 |
| Array of Structures 와 Structure of Arrays (0) | 2022.01.15 |
| Zero-Copy Memory & Unified Virtual Addressing (0) | 2022.01.15 |
| Pinned Memory (0) | 2022.01.14 |




댓글